
1. Introducción
En este codelab, compilarás un data lakehouse abierto entre nubes que unifica los silos de datos en AWS, Google Cloud y AlloyDB sin necesidad de un ETL complejo. Usarás Lakehouse como centro de inteligencia central, AlloyDB como fuente de datos operativos y Managed Service para Apache Spark para el procesamiento vectorizado de alto rendimiento. Por último, usarás Gemini para obtener estadísticas comerciales valiosas de tu lakehouse.
Imagina que tus datos transaccionales (users, orders, order items) se encuentran en una base de datos operativa de AlloyDB, tus datos de product están en un bucket de AWS S3 y los datos masivos de event logs de clickstream se almacenan en Cloud Storage. Debes unir estos conjuntos de datos para identificar los datos demográficos objetivo de tu próxima campaña de marketing y generar correos electrónicos personalizados de comunicación.
Requisitos previos
- Conocimientos básicos de SQL y comandos de terminal
- Un proyecto de Google Cloud con facturación habilitada.
Qué aprenderás
- Cómo integrar silos de datos dispares con la integración sin ETL de BigQuery (AlloyDB) y Lakehouse para Apache Iceberg
- Cómo ejecutar un trabajo de generación de perfiles de comportamiento de alta velocidad con Managed Service para Apache Spark con tecnología del motor Lightning nativo de C++.
- Cómo usar el agente de datos de BigQuery para realizar análisis complejos en lenguaje natural sobre datos unificados
- Cómo configurar el Protocolo de contexto del modelo (MCP) para permitir que Gemini CLI lea desde tu Lakehouse para Apache Iceberg y redacte contenido de marketing
Requisitos
- Una cuenta de Google Cloud y un proyecto de Google Cloud
- Un navegador web, como Chrome
Requisitos
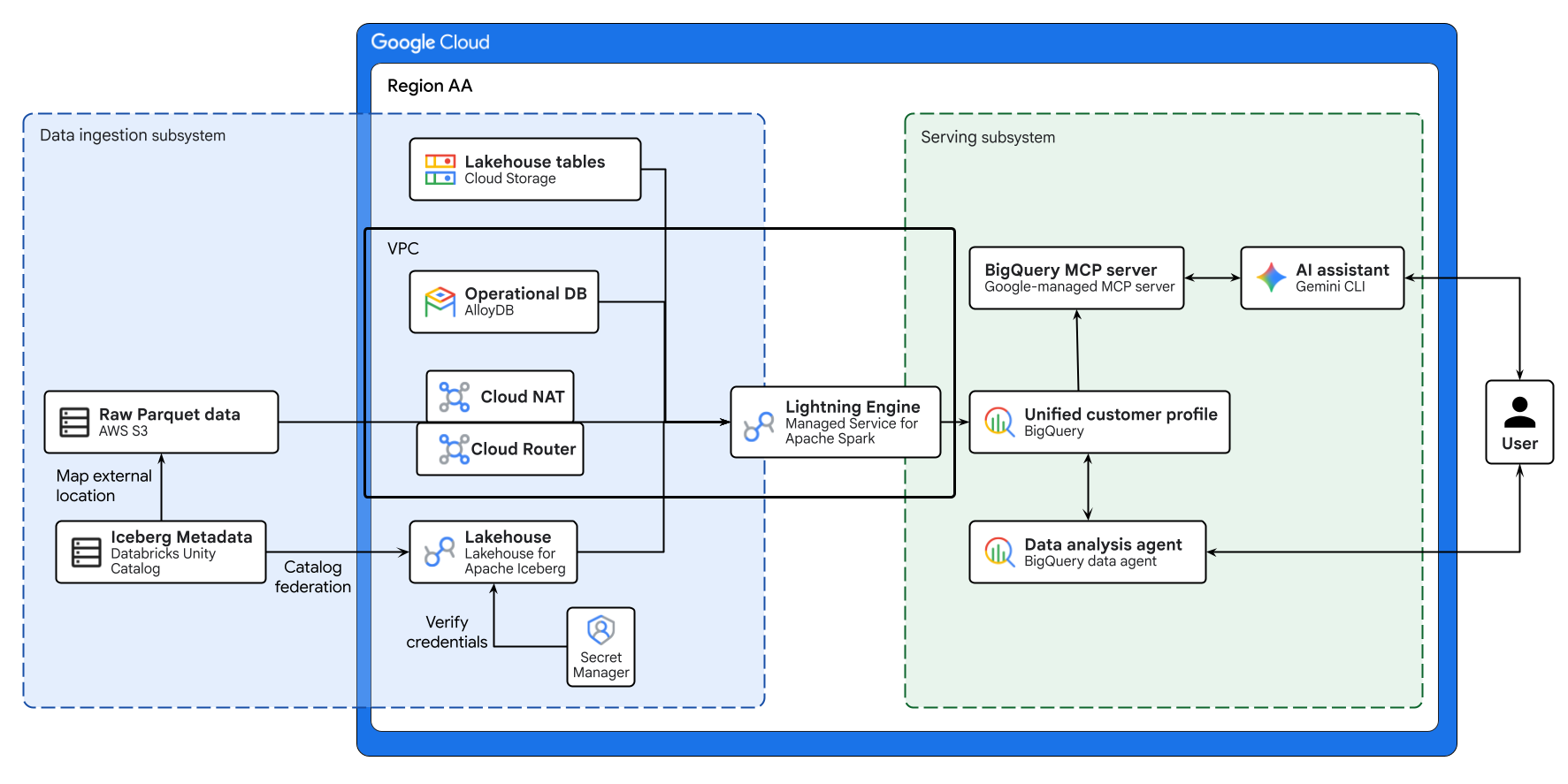
En el diagrama anterior, se ilustra el flujo de extremo a extremo del lakehouse entre nubes que se compila en este codelab. Los datos operativos de AlloyDB y los datos remotos de AWS S3 se federan de forma segura con Lakehouse para Apache Iceberg. Managed Service para Apache Spark procesa estas fuentes dispares para crear un perfil de clientes unificado en BigQuery. Por último, un agente de datos de BigQuery y un servidor de MCP de BigQuery administrado por Google a través de Gemini CLI proporcionan una interfaz intuitiva basada en IA para el análisis de datos avanzado.
Conceptos clave
- Lakehouse de datos abiertos en múltiples nubes: Unifica los silos de datos en AWS, Google Cloud y entornos locales sin necesidad de ETL complejas.
- BigQuery zero-ETL: Permite consultar directamente bases de datos operativas sin un movimiento de datos complejo.
- Lakehouse para Apache Iceberg: Permite una seguridad y administración coherentes en el almacenamiento entre nubes con el formato de Apache Iceberg.
- Lightning Engine: Motor nativo de C++ para la ejecución de Apache Spark de alto rendimiento.
- Protocolo de contexto del modelo (MCP): Conecta Gemini directamente a tu lakehouse de BigQuery.
2. Configuración y requisitos
Crea un proyecto de Google Cloud
- En la página del selector de proyectos de la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
Inicia Cloud Shell
Si bien Google Cloud y Spanner se pueden operar de manera remota desde tu laptop, en este codelab usarás Google Cloud Shell, un entorno de línea de comandos que se ejecuta en la nube.
En Google Cloud Console, haz clic en el ícono de Cloud Shell en la barra de herramientas en la parte superior derecha:
El aprovisionamiento y la conexión al entorno deberían tomar solo unos minutos. Cuando termine el proceso, debería ver algo como lo siguiente:

Esta máquina virtual está cargada con todas las herramientas de desarrollo que necesitarás. Ofrece un directorio principal persistente de 5 GB y se ejecuta en Google Cloud, lo que permite mejorar considerablemente el rendimiento de la red y la autenticación. Todo tu trabajo en este codelab se puede hacer en un navegador. No es necesario que instales nada.
Inicializa el entorno
Abre Cloud Shell y configura las variables de tu proyecto para asegurarte de que todos los comandos se dirijan a la infraestructura correcta.
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
Aplica las variables a tu sesión activa:
source ./env.sh
Habilita las APIs
Habilita los servicios de Google Cloud necesarios.
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3. Configura la infraestructura principal
En lugar de mover todos los datos a un solo repositorio a través de canalizaciones de ETL frágiles, compilarás una arquitectura federada en varias nubes. En una empresa del mundo real, los datos están inherentemente fragmentados debido a los diferentes requisitos del sistema. Orquestarás las siguientes fuentes de datos:
- AlloyDB (base de datos transaccional principal): Almacena datos de usuarios, pedidos y elementos de pedidos. Como base de datos operativa en vivo, garantiza las propiedades ACID necesarias para las transacciones financieras y las actualizaciones de perfiles.
- AWS S3 (datos maestros): Almacena el catálogo de
products. Representa un sistema heredado de administración de datos maestros (MDM) en AWS. - Google Cloud Storage (data lake masivo): Almacena
events(registros de flujo de clics). Los datos de alta capacidad de procesamiento, como los registros web, fallarían en una base de datos relacional. El almacenamiento de objetos proporciona una escalabilidad infinita, y mantenerlo en Google Cloud maximiza la localidad de procesamiento para tus motores de análisis.
Primero, configura la red subyacente. Las bases de datos administradas de Google Cloud, como AlloyDB, requieren una conexión privada de intercambio de tráfico entre VPCs para comunicarse de forma segura dentro de la red de tu proyecto.
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
A continuación, crea un conjunto de datos de BigQuery y una conexión de recurso de Cloud de Lakehouse. Desde el punto de vista de la arquitectura, una conexión de recursos delega el acceso a los datos a una cuenta de servicio administrada por Google dedicada, lo que aplica el principio de privilegio mínimo.
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. Aprovisiona la base de datos operativa
Aprovisiona una instancia principal de AlloyDB y, luego, inserta tus datos transaccionales críticos para la misión.
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
Una vez que la base de datos esté lista, debes crear una conexión externa de BigQuery a AlloyDB. Esta conexión almacena de forma segura las credenciales y el extremo de la base de datos, lo que permite que BigQuery transfiera la ejecución de SQL directamente al motor de procesamiento de AlloyDB (cero ETL).
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
Enviar de forma segura las tablas transaccionales a AlloyDB Usa el proxy de autenticación de AlloyDB para conectar de forma segura tu sesión local de Cloud Shell a la instancia privada de AlloyDB. Esto te permite enviar los datos de transacciones con herramientas de línea de comandos locales.
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5. Federa los datos maestros (ruta de AWS)
Nuestro catálogo de productos, que contiene metadatos de elementos sin procesar, reside de forma nativa en AWS S3 como tablas de Apache Iceberg. Los metadatos se rigen por un catálogo remoto.
En lugar de compilar canalizaciones de ETL frágiles para copiar estos datos en Google Cloud, usarás Lakehouse para Apache Iceberg (federación de catálogos de REST).
Este enfoque sin ETL permite que Lakehouse y Managed Service para Apache Spark descubran y lean de forma dinámica los metadatos de Iceberg y los archivos Parquet subyacentes directamente desde tu entorno remoto.
Si tienes una cuenta de AWS activa y Unity Catalog de Databricks configurado, puedes usarlo. De lo contrario, puedes simular tu entorno con Google Cloud Storage. Elige una de ellas.
Opción A: Aporta tu propia cuenta de AWS (Apache Iceberg nativo)
Requisito previo: Esta opción supone que ya aprovisionaste un bucket de AWS S3, lo conectaste como una ubicación externa en Databricks Unity Catalog, asignaste una tabla de Iceberg y generaste un principal de servicio de OAuth con acceso de lectura.
1. Almacenamiento seguro de credenciales
Codificar de forma rígida tokens de acceso de larga duración es un antipatrón arquitectónico. Almacenarás el ID de cliente y el secreto de OAuth de Databricks en Secret Manager de Google Cloud. El servicio de Lakehouse los recuperará de forma dinámica en el tiempo de ejecución para vender tokens de corta duración, lo que centralizará la administración de tus credenciales.
Ejecuta el siguiente bloque para generar el script. (No edites nada todavía).
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
Luego, ejecuta el siguiente comando para abrir automáticamente la secuencia de comandos generada en el editor de código visual que se encuentra sobre la terminal.
cloudshell edit create_secret.sh
- En el editor, reemplaza los marcadores de posición
<YOUR_...>por tus credenciales reales de Databricks. - Asegúrate de que la URL de tu espacio de trabajo no incluya
https://ni barras diagonales finales (p.ej.,123456789.cloud.databricks.com). - Presiona
Ctrl+S(oCmd+Sen Mac) para guardar el archivo. - Regresa a tu sesión de terminal y ejecuta la secuencia de comandos:
source create_secret.sh
2. Crea el catálogo federado
Para simplificar este codelab, configurarás el catálogo para que atraviese de forma segura la Internet pública. Sin embargo, para las cargas de trabajo de producción, consultar conjuntos de datos masivos a través de Internet pública genera costos de salida innecesarios y latencia impredecible. La práctica recomendada exige configurar un Cross-Cloud Interconnect (CCI) privado entre AWS y Google Cloud, lo que reduce significativamente los costos de salida y garantiza un rendimiento determinístico de la red.
Usa la CLI de gcloud para aprovisionar el catálogo federado de Lakehouse:
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. Aplica vinculaciones de IAM de privilegio mínimo
Cuando aprovisionaste el catálogo federado en el paso anterior, Google Cloud Lakehouse lanzó automáticamente un trabajo de actualización en segundo plano para sincronizar los manifiestos de Iceberg cada 330 segundos.
Debes otorgar el rol secretAccessor a la cuenta de servicio del catálogo de Lakehouse para que pueda recuperar de forma segura el token de OAuth de Databricks durante estas sincronizaciones en segundo plano y ejecuciones de consultas. Si falta esta vinculación, se producirán errores 403 silenciosos cuando Lakehouse intente actualizar el catálogo.
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. Habilita el acceso a Internet saliente para Managed Service para Apache Spark
En un paso posterior, Managed Service para Apache Spark leerá los datos remotos de AWS. Dado que Managed Service para Apache Spark sin servidores se ejecuta por completo dentro de una red de VPC privada sin direcciones IP externas, no puede acceder a AWS S3 a través de Internet de forma predeterminada. Debes aprovisionar una instancia de Cloud NAT para permitir que los trabajadores de Spark tengan acceso saliente a Internet.
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. Define el objetivo de la transmisión
Exporta esta variable para que los trabajos de Apache Spark posteriores sepan exactamente dónde consultar los datos de AWS sin necesidad de realizar cambios manuales en el código.
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
Opción B: Simula el entorno de AWS a través de Cloud Storage
Si no tienes una cuenta de AWS activa, puedes simular el silo entre nubes de forma nativa con tablas administradas de Lakehouse en Google Cloud Storage.
1. Crea la tabla simulada de Iceberg
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. Define el objetivo de la transmisión
Los conjuntos de datos estándar de BigQuery usan una estructura de espacio de nombres de 3 partes (project.dataset.table). Exporta esta variable para que el trabajo de Apache Spark posterior se dirija a los datos simulados.
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. Transfiere registros de eventos (rama de Google Cloud)
Los datos de flujo de clics crecen de forma exponencial. Almacenas los eventos sin procesar completos y sin agregar de forma local en Cloud Storage como tablas administradas de Lakehouse.
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. Crea un perfil de cliente unificado
Una vez que tu infraestructura sin procesar esté completamente poblada, es hora de crear un perfil de cliente unificado.
Usarás Managed Service para Apache Spark con la tecnología de Lightning Engine. Lightning Engine es el acelerador de consultas nativo de C++ de alto rendimiento de Google Cloud, creado con tecnologías de código abierto como Apache Gluten y Velox, que aumenta automáticamente la ejecución maximizando la eficiencia de la CPU y almacenando en caché los datos de forma inteligente. Este enfoque es ideal cuando se realizan uniones masivas multidireccionales, ventanas complejas o agregaciones de comportamiento en varias nubes.
Usarás el conector de Spark BigQuery para leer directamente las consultas federadas de AlloyDB sin ETL y las tablas de Lakehouse, realizar las agregaciones vectorizadas masivas de forma nativa en Spark y escribir el perfil unificado resultante en BigQuery.
Configura los permisos de IAM para Managed Service para Apache Spark
De forma predeterminada, Serverless Spark ejecuta trabajos por lotes con la cuenta de servicio predeterminada de Compute Engine. Antes de enviar el trabajo, debes otorgar a esta cuenta de servicio los permisos necesarios para ejecutar la carga de trabajo y administrar los trabajos de BigQuery.
(Nota: Si bien el nombre del servicio cambió a Managed Service para Apache Spark para reflejar la terminología estándar de la industria, los comandos de la API subyacente y los roles de IAM aún usan el identificador dataproc).
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
Crea y envía el trabajo
Primero, crea la secuencia de comandos del trabajo de PySpark. Esta secuencia de comandos detecta automáticamente si elegiste la opción A (catálogo federado de AWS) o la opción B (simulación de Google Cloud) según tu variable de entorno AWS_PRODUCTS_TABLE, define la lógica de Spark SQL y utiliza la manipulación de arrays nativa de Spark para calcular los períodos de RFM (recencia, frecuencia y valor monetario).
Ejecuta el siguiente bloque en Cloud Shell.
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
Con la secuencia de comandos completamente ensamblada y las configuraciones requeridas insertadas de forma dinámica, envía el trabajo por lotes a Managed Apache Spark Serverless.
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
Verifica la ejecución del trabajo en la consola
Una vez que se envía el trabajo por lotes, puedes verificar que esté utilizando el motor de ejecución acelerado de C++:
- En la consola de Google Cloud, navega a Managed Service para Apache Spark > Sin servidores > Lotes.
- Haz clic en el trabajo que se está ejecutando.
- En el panel de detalles del trabajo, verifica que la propiedad Nivel esté establecida en
Premiumy que el motor esté establecido enLightning Engine.
8. Realiza análisis con el agente de datos de BigQuery
Ahora que federaste los datos fragmentados en varias nubes y ejecutaste las agregaciones de comportamiento pesadas con Managed Service para Apache Spark, el siguiente paso es el análisis de datos.
Primero, inspecciona el esquema de la tabla de perfil unificado recién creada en la IU de BigQuery para comprender visualmente la estructura de datos que expones al agente:
- En la consola de Google Cloud, navega a BigQuery.
- En el panel Explorador de la izquierda, expande tu proyecto y el conjunto de datos
demo_lakehouse. - Haz clic en la tabla
unified_customer_profile. - Selecciona la pestaña Esquema en el espacio de trabajo principal.
Verifica el esquema de la tabla nueva. La columna top_preferences es un REPEATED STRUCT (un array de registros que contiene category, brand y sale_price). Tradicionalmente, consultar arrays anidados requiere un SQL complejo con la función UNNEST(), lo que puede ser un obstáculo para los analistas de negocios. Al fundamentar un agente de datos de BigQuery en esta tabla específica, el agente comprende de forma inherente el esquema y controla operaciones complejas de SQL estándar de Google de forma interna.
Crea el agente de datos
En esta sección, crearás un agente de datos de BigQuery y, luego, interactuarás con él. En lugar de escribir manualmente un código SQL complejo para anidar arrays y calcular métricas, aprovisionarás un agente de IA con un alcance específico para tu perfil unificado recién creado, lo que permitirá la exploración de datos en lenguaje natural.
- En el panel de navegación izquierdo, busca y haz clic en Agentes.
- Haz clic en + Agente nuevo para inicializar un nuevo asistente de IA.
- Configura el agente:
- Nombre del agente:
Retail VIP Analysis Agent - Fuentes de datos: Haz clic en Agregar fuente y busca la tabla
unified_customer_profile.
- Haz clic en Agregar y espera unos segundos para que el agente inicialice su espacio de trabajo.
Una vez que se establece el agente, definir instrucciones del sistema explícitas es una práctica fundamental de administración de datos. Usa las instrucciones del sistema como una capa semántica. Al incorporar definiciones comerciales en toda la empresa, controlar las complejidades del esquema y establecer parámetros de seguridad analíticos, abstraes la complejidad técnica del usuario final y evitas que el LLM extraiga conclusiones a partir de datos estadísticamente insignificantes.
Pega lo siguiente en el campo Instrucción:
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
Indícale al agente
Dado que las instrucciones del sistema rigen de forma segura la lógica empresarial compleja (la definición exacta de un "VIP en riesgo") y los requisitos de manejo del esquema, el analista de datos no necesita escribir una instrucción detallada y con muchas condiciones.
En la interfaz de chat, ingresa la siguiente instrucción:
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
Evalúa la estadística generada
Después de enviar la instrucción, revisa cuidadosamente el resultado generado de forma nativa para evaluar cómo el agente de datos de BigQuery aplicó tus instrucciones del sistema, actuando como una capa semántica gobernada y como un riel de seguridad analítico.
Primero, lee el texto de resumen que se generó sobre los datos. Observa cómo el agente traduce automáticamente tu solicitud simple de "VIPs en riesgo" en los umbrales exactos de las métricas definidos en tus instrucciones del sistema (p.ej., haciendo referencia a lifetime_value > 100, cart_adds > 0 y a 90 días de inactividad). Esto confirma que el agente internalizó tu lógica empresarial, lo que significa que los usuarios finales nunca necesitarán memorizar ni codificar de forma rígida lógica compleja en sus instrucciones diarias.
A continuación, expande la vista SQL para inspeccionar el código generado. El agente debería haber construido un SQL estándar de Google matemáticamente sólido según tus instrucciones:
- Intervalos dinámicos: Busca el cálculo de la marca de tiempo en la cláusula
WHERE(por lo general, conTIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)). - Cumplimiento estricto del esquema: Confirma que el agente cumplió con tus reglas estrictas del esquema aplicando de forma explícita la función
UNNEST()al arraytop_preferences. Para aislar con precisión la categoría más frecuente por país, por lo general, verás que utiliza técnicas avanzadas, como una función analíticaROW_NUMBER() OVER()dentro de una expresión de tabla común (CTE).
Revisa el gráfico y la tabla de datos renderizados automáticamente. Los datos revelarán visualmente tus principales mercados de retención (por lo general, destacarán países con un volumen alto, como China o Estados Unidos) junto con sus afinidades de productos dominantes a nivel universal (con frecuencia, "Jeans"). Observa cómo la IU nativa estructura el resultado para su consumo inmediato sin necesidad de código de visualización explícito.
Lee el texto con viñetas de Estadísticas que generó el agente. Como estableciste medidas de protección analíticas, busca específicamente una estadística sobre la calidad de los datos o la significancia estadística. Es posible que veas que el agente marca explícitamente los países en la parte inferior de la tabla con recuentos de usuarios muy bajos (p.ej., regiones con solo un puñado de usuarios). En lugar de alucinar ciegamente una campaña de marketing segmentada basada en un solo punto de datos, el agente aconsejará correctamente que estas anomalías no son estadísticamente significativas para una estrategia a gran escala. Esto demuestra cómo la incorporación de medidas de protección de la administración directamente en el agente evita de manera eficaz los errores de cálculo empresariales basados en IA.
9. Genera estadísticas basadas en IA con Gemini y MCP
El agente identificó correctamente el público objetivo principal: VIP en riesgo en países específicos. Sin embargo, el trabajo de un analista termina con la estadística. Para volver a atraer a estos usuarios, el equipo de marketing debe ejecutar una campaña.
Usarás el Protocolo de contexto del modelo (MCP) para conectar un asistente externo de IA directamente a esta lista demográfica específica en BigQuery, lo que te permitirá pasar del análisis de datos a la acción impulsada por IA sin compilar APIs personalizadas.
Configura el servidor de MCP de BigQuery
Ejecuta el siguiente bloque para generar el archivo de configuración mcp.json. Este archivo proporciona los parámetros de conexión necesarios para que Gemini CLI pueda interactuar de forma segura con BigQuery.
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
Genera un correo electrónico de marketing
Inicia la herramienta de Gemini CLI desde tu terminal y pasa de forma explícita la marca de configuración de MCP para permitir que lea tu data lakehouse de BigQuery.
Ejecuta Gemini CLI.
source env.sh
gemini
Una vez que se abra la instrucción, pídele que redacte un mensaje personalizado para tu público objetivo demográfico:
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
Gemini consultará automáticamente BigQuery a través del servidor de MCP, identificará el grupo demográfico y redactará el correo electrónico por ti.
10. Limpia tu entorno
Para evitar que se apliquen cargos a tu cuenta de Google Cloud y restablecer tu proyecto de forma limpia para ejecuciones futuras, debes borrar los recursos que creaste durante este codelab.
Ejecuta el siguiente bloque para crear la secuencia de comandos cleanup.sh. Esta secuencia de comandos actúa como un mecanismo de cierre automatizado que quita de forma permanente el clúster y la instancia de AlloyDB, los conjuntos de datos de BigQuery y tu bucket de Cloud Storage para evitar más facturación.
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
Ejecuta la secuencia de comandos de limpieza para borrar tus recursos de forma segura:
bash cleanup.sh
11. ¡Felicitaciones!
Creaste y consultaste correctamente un data lakehouse abierto en varias nubes.
Aprendiste lo siguiente:
- Cómo federar datos de fuentes dispares con BigQuery Zero-ETL y Google Cloud Lakehouse
- Cómo aprovechar el motor Lightning nativo de C++ en las uniones vectorizadas masivas de Managed Service para Apache Spark
- Cómo usar el agente de datos de BigQuery para la exploración en lenguaje natural
- Cómo conectar tus datos a Gemini con el Protocolo de contexto del modelo (MCP) y Gemini
Próximos pasos
- Explora la documentación de Lakehouse
- Obtén más información sobre AlloyDB Zero-ETL a BigQuery
- Obtén información sobre Lightning Engine