
۱. مقدمه
در این آزمایشگاه کد، شما یک Lakehouse داده باز بین ابری خواهید ساخت که سیلوهای داده را در AWS، Google Cloud و AlloyDB بدون نیاز به ETL پیچیده، یکپارچه میکند. شما از Lakehouse به عنوان مرکز اطلاعات مرکزی، AlloyDB به عنوان منبع داده عملیاتی و از Managed Service برای Apache Spark برای پردازش برداری با کارایی بالا استفاده خواهید کرد. در نهایت، از Gemini برای استخراج بینشهای تجاری قدرتمند از Lakehouse خود استفاده خواهید کرد.
تصور کنید دادههای تراکنشی شما ( users ، orders ، order items ) در یک پایگاه داده عملیاتی AlloyDB قرار دارد، دادههای product شما در یک مخزن AWS S3 است و event logs کلیکهای انبوه در فضای ذخیرهسازی ابری ذخیره میشوند. شما باید این مجموعه دادهها را به هم متصل کنید تا جمعیت هدف را برای کمپین بازاریابی بعدی خود شناسایی کنید و ایمیلهای تبلیغاتی شخصیسازیشده ایجاد کنید.
پیشنیازها
- آشنایی با دستورات پایه SQL و ترمینال
- یک پروژه گوگل کلود با قابلیت پرداخت.
آنچه یاد خواهید گرفت
- نحوه ادغام سیلوهای دادهای متفاوت با استفاده از BigQuery zero-ETL (AlloyDB) و Lakehouse برای Apache Iceberg.
- نحوه اجرای یک کار پروفایل رفتاری با سرعت بالا با استفاده از سرویس مدیریتشده برای آپاچی اسپارک که توسط موتور لایتنینگ بومی ++C پشتیبانی میشود.
- نحوه استفاده از عامل داده BigQuery برای انجام تحلیلهای پیچیده زبان طبیعی روی دادههای یکپارچه.
- نحوه پیکربندی پروتکل زمینه مدل (MCP) برای اینکه به رابط خط فرمان Gemini اجازه دهد محتوای بازاریابی Apache Iceberg و پیشنویس آن را از Lakehouse شما بخواند.
آنچه نیاز دارید
- یک حساب کاربری گوگل کلود و پروژه گوگل کلود
- یک مرورگر وب مانند کروم
آنچه نیاز دارید
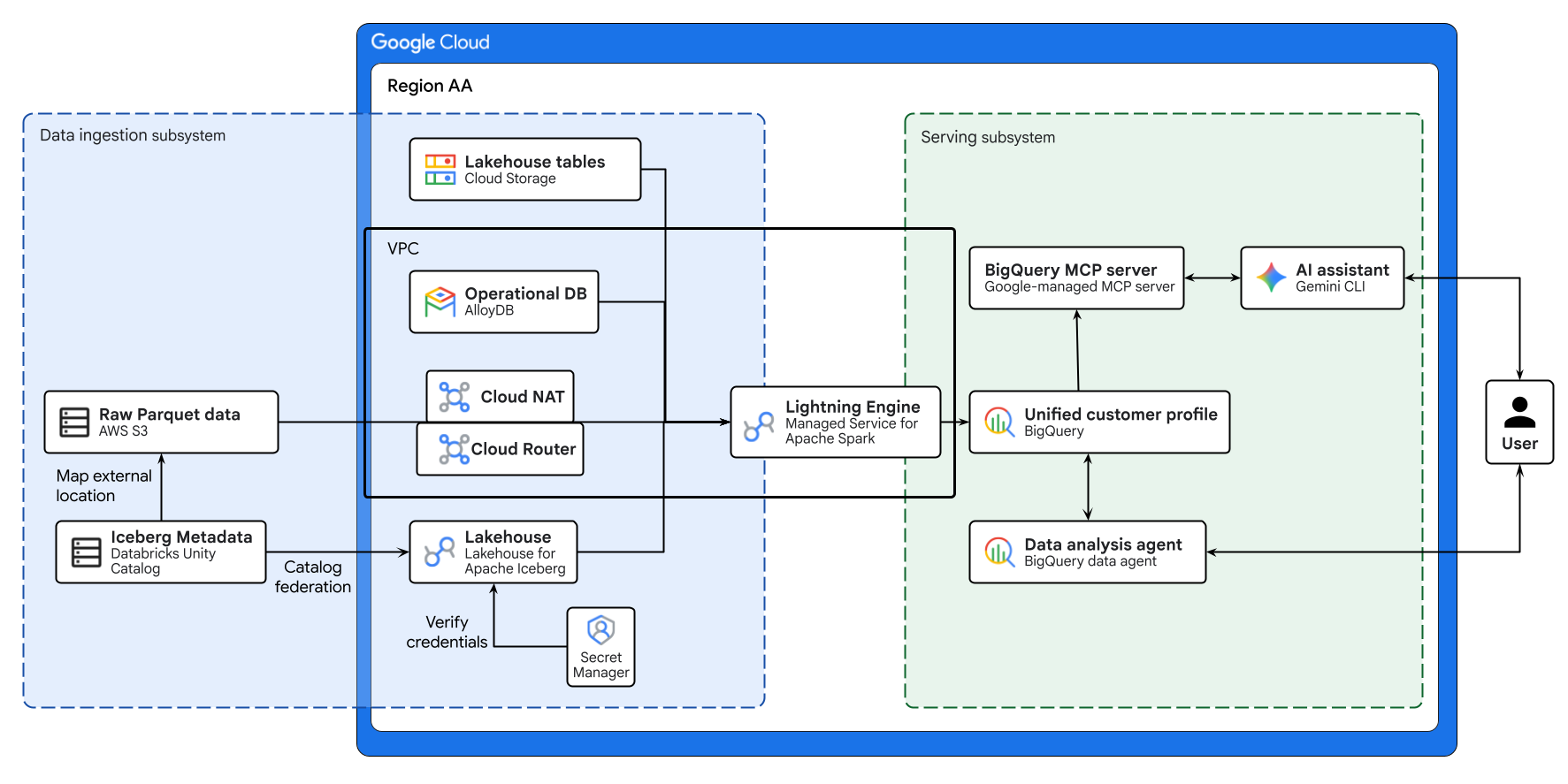
نمودار بالا جریان سرتاسری Lakehouse بین ابری ساخته شده در این آزمایشگاه کد را نشان میدهد. دادههای عملیاتی از AlloyDB و دادههای از راه دور از AWS S3 با استفاده از Lakehouse برای Apache Iceberg به طور ایمن یکپارچه شدهاند. سرویس مدیریتشده برای Apache Spark این منابع پراکنده را برای ایجاد یک پروفایل مشتری یکپارچه در BigQuery پردازش میکند. در نهایت، یک BigQuery Data Agent و سرور BigQuery MCP تحت مدیریت گوگل از طریق Gemini CLI یک رابط کاربری بصری و مبتنی بر هوش مصنوعی برای تجزیه و تحلیل پیشرفته دادهها ارائه میدهند.
مفاهیم کلیدی
- Lakehouse دادههای باز بین ابری: سیلوهای داده را در محیطهای AWS، Google Cloud و on-premises بدون نیاز به ETL پیچیده، یکپارچه میکند.
- BigQuery zero-ETL: امکان پرسوجوی مستقیم از پایگاههای داده عملیاتی را بدون جابجایی پیچیده دادهها فراهم میکند.
- Lakehouse برای Apache Iceberg: با استفاده از فرمت Apache Iceberg، امنیت و مدیریت پایدار را در فضای ذخیرهسازی ابری متقابل فعال میکند.
- موتور لایتنینگ: موتور بومی C++ برای اجرای آپاچی اسپارک با کارایی بالا.
- پروتکل زمینه مدل (MCP): Gemini را مستقیماً به Lakehouse BigQuery شما متصل میکند.
۲. تنظیمات و الزامات
ایجاد یک پروژه ابری گوگل
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید .
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
شروع پوسته ابری
اگرچه میتوان از راه دور و از طریق لپتاپ، گوگل کلود را مدیریت کرد، اما در این آزمایشگاه کد، از گوگل کلود شل ، یک محیط خط فرمان که در فضای ابری اجرا میشود، استفاده خواهید کرد.
از کنسول گوگل کلود ، روی آیکون Cloud Shell در نوار ابزار بالا سمت راست کلیک کنید:
آمادهسازی و اتصال به محیط فقط چند لحظه طول میکشد. وقتی تمام شد، باید چیزی شبیه به این را ببینید:

این ماشین مجازی با تمام ابزارهای توسعهای که نیاز دارید، مجهز شده است. این ماشین مجازی یک دایرکتوری خانگی پایدار ۵ گیگابایتی ارائه میدهد و روی فضای ابری گوگل اجرا میشود که عملکرد شبکه و احراز هویت را تا حد زیادی بهبود میبخشد. تمام کارهای شما در این آزمایشگاه کد را میتوان در یک مرورگر انجام داد. نیازی به نصب چیزی ندارید.
مقداردهی اولیه محیط
Cloud Shell را باز کنید و متغیرهای پروژه خود را تنظیم کنید تا مطمئن شوید که همه دستورات زیرساخت صحیح را هدف قرار میدهند.
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
متغیرها را در جلسه فعال خود اعمال کنید:
source ./env.sh
فعال کردن APIها
سرویسهای ابری گوگل مورد نیاز را فعال کنید.
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
۳. زیرساخت اصلی را راهاندازی کنید
به جای انتقال همه دادهها به یک مخزن واحد از طریق خطوط لوله ETL شکننده، شما یک معماری ابر متقابل فدرال ایجاد خواهید کرد. در یک سازمان واقعی، دادهها ذاتاً به دلیل نیازهای مختلف سیستم، تکهتکه هستند. شما منابع داده زیر را هماهنگ خواهید کرد:
- AlloyDB (پایگاه داده تراکنشی اصلی): دادههای کاربران، سفارشات و اقلام سفارش را ذخیره میکند. به عنوان یک پایگاه داده عملیاتی زنده، ویژگیهای ACID مورد نیاز برای تراکنشهای مالی و بهروزرسانیهای پروفایل را تضمین میکند.
- AWS S3 (دادههای اصلی): کاتالوگ
productsرا ذخیره میکند. نمایانگر یک سیستم مدیریت دادههای اصلی (MDM) قدیمی در AWS است. - فضای ذخیرهسازی ابری گوگل (دریاچه داده عظیم):
events(لاگهای کلیک استریم) را ذخیره میکند. دادههای با توان عملیاتی بالا مانند لاگهای وب، یک پایگاه داده رابطهای را از کار میاندازند. فضای ذخیرهسازی شیءگرا مقیاسپذیری نامحدودی را فراهم میکند و نگهداری آن در فضای ابری گوگل، مکان محاسباتی را برای موتورهای تحلیلی شما به حداکثر میرساند.
ابتدا، شبکه اصلی را پیکربندی کنید. پایگاههای داده مدیریتشده توسط گوگل کلود مانند AlloyDB برای برقراری ارتباط ایمن در شبکه پروژه شما، به یک اتصال همتاسازی خصوصی VPC نیاز دارند.
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
در مرحله بعد، یک مجموعه داده BigQuery و یک اتصال منابع ابری Lakehouse ایجاد کنید. از نظر معماری، یک اتصال منابع، دسترسی به دادهها را به یک حساب کاربری اختصاصی تحت مدیریت گوگل واگذار میکند و اصل حداقل امتیاز را اجرا میکند.
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
۴. تهیه پایگاه داده عملیاتی
یک نمونه اولیه از AlloyDB تهیه کنید و دادههای تراکنشی حیاتی خود را در آن تزریق کنید.
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
پس از آماده شدن پایگاه داده، باید یک اتصال خارجی BigQuery به AlloyDB ایجاد کنید. این اتصال به طور ایمن اعتبارنامهها و نقطه پایانی پایگاه داده را ذخیره میکند و به BigQuery اجازه میدهد تا اجرای SQL را مستقیماً به موتور محاسباتی AlloyDB (بدون ETL) ارسال کند.
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
جداول تراکنشها را به صورت ایمن به AlloyDB وارد کنید. از AlloyDB Auth Proxy برای اتصال ایمن جلسه محلی Cloud Shell خود به نمونه خصوصی AlloyDB استفاده کنید. این به شما امکان میدهد دادههای تراکنشها را با استفاده از ابزارهای خط فرمان محلی وارد کنید.
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
۵. دادههای اصلی را فدرال کنید (AWS صحبت کرد)
کاتالوگ محصولات ما، شامل فرادادههای خام اقلام، به صورت بومی در AWS S3 به عنوان جداول Apache Iceberg قرار دارد. این فرادادهها توسط یک کاتالوگ از راه دور مدیریت میشوند.
به جای ساخت خطوط لوله ETL شکننده برای کپی کردن این دادهها در Google Cloud، از Lakehouse برای Apache Iceberg (فدراسیون کاتالوگ REST) استفاده خواهید کرد.
این رویکرد بدون نیاز به ETL به Lakehouse و Managed Service for Apache Spark اجازه میدهد تا به صورت پویا، متادیتای Iceberg و فایلهای Parquet زیربنایی را مستقیماً از محیط راه دور شما کشف و مطالعه کنند.
اگر یک حساب کاربری AWS فعال دارید و Databricks Unity Catalog را پیکربندی کردهاید، میتوانید از آن استفاده کنید. در غیر این صورت، میتوانید محیط خود را با استفاده از Google Cloud Storage شبیهسازی کنید. یکی از این دو را انتخاب کنید.
گزینه الف: AWS خودتان (Apache Iceberg بومی) را بیاورید
پیشنیاز: این گزینه فرض میکند که شما قبلاً یک سطل AWS S3 را آماده کردهاید، آن را به عنوان یک مکان خارجی در Databricks Unity Catalog متصل کردهاید، یک جدول Iceberg را نگاشت کردهاید و یک مدیر سرویس OAuth با دسترسی خواندن ایجاد کردهاید.
۱. ذخیرهسازی امن اطلاعات کاربری
کدگذاری سخت توکنهای دسترسی با طول عمر بالا، یک الگوی معماری مخالف است. شما شناسه و رمز کلاینت OAuth مربوط به Databricks را در Google Cloud Secret Manager ذخیره خواهید کرد. سرویس Lakehouse این موارد را به صورت پویا در زمان اجرا دریافت میکند تا توکنهای با طول عمر کوتاه را بفروشد و مدیریت اعتبارنامه شما را متمرکز کند.
برای تولید اسکریپت، بلوک زیر را اجرا کنید. (هنوز چیزی را ویرایش نکنید).
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
سپس، دستور زیر را اجرا کنید تا اسکریپت تولید شده به طور خودکار در ویرایشگر کد بصری بالای ترمینال شما باز شود.
cloudshell edit create_secret.sh
- در ویرایشگر، متغیرهای
<YOUR_...>را با اعتبارنامههای واقعی Databricks خود جایگزین کنید. - مطمئن شوید که آدرس اینترنتی فضای کاری شما شامل
https://یا اسلشهای انتهایی نباشد (مثلاً123456789.cloud.databricks.com). - برای ذخیره فایل،
Ctrl+S(یاCmd+Sدر مک) را فشار دهید. - به بخش ترمینال خود برگردید و اسکریپت را اجرا کنید:
source create_secret.sh
۲. ایجاد کاتالوگ فدرال
برای سادگی در این آزمایشگاه کد، شما کاتالوگ را طوری پیکربندی خواهید کرد که به طور ایمن از اینترنت عمومی عبور کند. با این حال، برای بارهای کاری عملیاتی، پرس و جو از مجموعه دادههای عظیم از طریق اینترنت عمومی هزینههای خروجی غیرضروری و تأخیر غیرقابل پیشبینی را به همراه دارد. بهترین روش، پیکربندی یک اتصال متقابل ابری (CCI) خصوصی بین AWS و Google Cloud را الزامی میکند، که به طور قابل توجهی هزینههای خروجی را کاهش میدهد و عملکرد قطعی شبکه را تضمین میکند.
از رابط خط فرمان gcloud برای آمادهسازی کاتالوگ فدرال Lakehouse استفاده کنید:
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
۳. اعمال محدودیتهای IAM با حداقل امتیاز
وقتی در مرحله قبل کاتالوگ فدرال را آماده کردید، Google Cloud Lakehouse به طور خودکار هر 330 ثانیه یک کار بهروزرسانی پسزمینه را برای همگامسازی مانیفستهای Iceberg اجرا میکرد.
شما باید نقش secretAccessor را به حساب سرویس کاتالوگ Lakehouse اعطا کنید تا بتواند توکن OAuth مربوط به Databricks را در حین این همگامسازیهای پسزمینه و اجرای کوئریها به طور ایمن دریافت کند. عدم وجود این اتصال منجر به خطاهای 403 خاموش هنگام تلاش Lakehouse برای بهروزرسانی کاتالوگ خواهد شد.
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
۴. فعال کردن اینترنت خروجی برای سرویس مدیریتشدهی آپاچی اسپارک
در مرحله بعدی، سرویس مدیریتشده برای آپاچی اسپارک، دادههای AWS از راه دور را میخواند. از آنجا که سرویس مدیریتشده برای آپاچی اسپارک بدون سرور، کاملاً در یک شبکه خصوصی VPC و بدون آدرسهای IP خارجی اجرا میشود، بهطور پیشفرض نمیتواند از طریق اینترنت به AWS S3 دسترسی پیدا کند. شما باید یک Cloud NAT فراهم کنید تا به کارگران اسپارک اجازه دسترسی به اینترنت از راه دور را بدهید.
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
۵. هدف پاییندستی را تعریف کنید
این متغیر را اکسپورت کنید تا کارهای آپاچی اسپارک پاییندستی دقیقاً بدانند که دادههای AWS را از کجا جستجو کنند، بدون اینکه نیاز به تغییرات دستی کد باشد.
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
گزینه ب: شبیهسازی محیط AWS از طریق فضای ذخیرهسازی ابری
اگر حساب کاربری AWS فعالی ندارید، میتوانید سیلوی بین ابری را به صورت بومی با استفاده از جداول مدیریتشده توسط Lakehouse در Google Cloud Storage شبیهسازی کنید.
۱. جدول شبیهسازیشدهی کوه یخ را ایجاد کنید
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
۲. هدف پاییندستی را تعریف کنید
مجموعه دادههای استاندارد BigQuery از یک ساختار فضای نام سه قسمتی ( project.dataset.table ) استفاده میکنند. این متغیر را export کنید تا کار آپاچی اسپارک در پاییندست، دادههای ساختگی را هدف قرار دهد.
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
۶. دریافت گزارشهای رویداد (به نقل از گوگل کلود)
دادههای کلیکاستریم به صورت تصاعدی رشد میکنند. شما رویدادهای خام کامل و تجمیعنشده را به صورت محلی در فضای ذخیرهسازی ابری به عنوان جداول مدیریتشده Lakehouse ذخیره میکنید.
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
۷. یک پروفایل مشتری یکپارچه بسازید
با تکمیل زیرساخت خام خود، زمان آن رسیده است که یک پروفایل مشتری یکپارچه ایجاد کنید.
شما از سرویس مدیریتشده برای آپاچی اسپارک که توسط موتور لایتنینگ پشتیبانی میشود، استفاده خواهید کرد. موتور لایتنینگ، شتابدهنده پرسوجوی بومی C++ با عملکرد بالا در گوگل کلود است که بر اساس فناوریهای متنباز مانند آپاچی گلوتن و ولوکس ساخته شده است و با به حداکثر رساندن بهرهوری CPU و ذخیرهسازی هوشمند دادهها، بهطور خودکار سرعت اجرا را افزایش میدهد. این رویکرد هنگام انجام اتصالات چندطرفه عظیم، پنجرهسازی پیچیده یا تجمیع رفتاری در چندین ابر، ایدهآل است.
شما از کانکتور Spark BigQuery برای خواندن مستقیم کوئریهای Federated AlloyDB zero-ETL و جداول Lakehouse، انجام تجمیعهای برداری عظیم به صورت بومی در Spark و نوشتن پروفایل یکپارچه حاصل در BigQuery استفاده خواهید کرد.
پیکربندی مجوزهای IAM برای سرویس مدیریتشده برای آپاچی اسپارک
به طور پیشفرض، Serverless Spark کارهای دستهای را با استفاده از حساب سرویس پیشفرض Compute Engine اجرا میکند. قبل از ارسال کار، باید به این حساب سرویس مجوزهای لازم برای اجرای بار کاری و مدیریت کارهای BigQuery را اعطا کنید.
(نکته: اگرچه نام سرویس برای انعکاس اصطلاحات استاندارد صنعتی به Managed Service for Apache Spark تغییر یافته است، اما دستورات API اصلی و نقشهای IAM همچنان از شناسه dataproc استفاده میکنند.)
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
ایجاد و ارسال شغل
ابتدا، اسکریپت کاری PySpark را ایجاد کنید. این اسکریپت به طور خودکار تشخیص میدهد که آیا شما گزینه A (AWS Federated Catalog) یا گزینه B (Google Cloud Mock) را بر اساس متغیر محیطی AWS_PRODUCTS_TABLE خود انتخاب کردهاید، منطق Spark SQL را تعریف میکند و از دستکاری آرایه بومی Spark برای محاسبه پنجرههای RFM (تازگی، فراوانی، پولی) استفاده میکند.
بلوک زیر را در Cloud Shell اجرا کنید.
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
پس از اینکه اسکریپت به طور کامل مونتاژ شد و پیکربندیهای مورد نیاز به صورت پویا تزریق شدند، کار دستهای را به Managed Apache Spark Serverless ارسال کنید.
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
تأیید اجرای کار در کنسول
پس از ارسال کار دستهای، میتوانید تأیید کنید که از موتور اجرای شتابیافته C++ استفاده میکند:
- در کنسول گوگل کلود، به مسیر Managed Service for Apache Spark > Serverless > Batches بروید.
- روی کاری که در حال حاضر در حال اجرا است کلیک کنید.
- در پنجره جزئیات کار، تأیید کنید که ویژگی Tier روی
Premiumو Engine رویLightning Engineتنظیم شده باشد.
۸. تجزیه و تحلیل با عامل داده BigQuery
اکنون که دادههای پراکنده بین ابری را یکپارچهسازی کردهاید و تجمیعهای رفتاری سنگین را با استفاده از سرویس مدیریتشده برای آپاچی اسپارک اجرا کردهاید، مرحله بعدی تجزیه و تحلیل دادهها است.
ابتدا، طرح جدول پروفایل یکپارچه تازه ایجاد شده در رابط کاربری BigQuery را بررسی کنید تا ساختار دادهای را که در اختیار عامل قرار میدهید، به صورت بصری درک کنید:
- در کنسول گوگل کلود، به BigQuery بروید.
- در پنل Explorer در سمت چپ، پروژه خود و مجموعه داده
demo_lakehouseرا باز کنید. - روی جدول
unified_customer_profileکلیک کنید. - در فضای کاری اصلی، تب Schema را انتخاب کنید.
طرح جدول جدید را بررسی کنید. ستون top_preferences یک REPEATED STRUCT است (آرایهای از رکوردها شامل category ، brand و sale_price ). به طور سنتی، پرسوجو از آرایههای تودرتو نیاز به SQL پیچیده با استفاده از تابع UNNEST() دارد که میتواند برای تحلیلگران کسبوکار یک مانع باشد. با قرار دادن یک عامل داده BigQuery در این جدول خاص، عامل ذاتاً طرح را درک میکند و عملیات پیچیده SQL استاندارد گوگل را در زیر کاپوت مدیریت میکند.
عامل داده را ایجاد کنید
در این بخش، شما یک عامل داده BigQuery ایجاد و با آن تعامل خواهید کرد. به جای نوشتن دستی SQL پیچیده برای باز کردن آرایهها و محاسبه معیارها، یک عامل هوش مصنوعی را که به طور خاص برای پروفایل یکپارچه تازه ایجاد شده شما در نظر گرفته شده است، فراهم خواهید کرد و امکان کاوش دادههای زبان طبیعی را فراهم میکند.
- در پنل ناوبری سمت چپ، گزینه Agents را پیدا کرده و روی آن کلیک کنید.
- برای راهاندازی یک دستیار هوش مصنوعی جدید، روی + New Agent کلیک کنید.
- پیکربندی عامل:
- نام نماینده :
Retail VIP Analysis Agent - منابع داده : روی افزودن منبع کلیک کنید و جدول
unified_customer_profileرا جستجو کنید.
- روی افزودن کلیک کنید و چند ثانیه صبر کنید تا عامل فضای کاری خود را مقداردهی اولیه کند.
پس از ایجاد عامل، تعریف دستورالعملهای صریح سیستم ، یک عمل حیاتی در مدیریت دادهها است. از دستورالعملهای سیستم به عنوان یک لایه معنایی استفاده کنید. با تعبیه تعاریف کسبوکار در سطح سازمان، مدیریت پیچیدگیهای طرحواره و ایجاد محافظهای تحلیلی، پیچیدگیهای فنی را از کاربر نهایی دور میکنید و مانع از نتیجهگیری LLM از دادههای آماری بیاهمیت میشوید.
موارد زیر را در قسمت دستورالعمل قرار دهید:
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
به نماینده اطلاع دهید
از آنجا که منطق پیچیده کسبوکار (تعریف دقیق یک «شخصیت مهم در معرض خطر») و الزامات مدیریت طرحواره به طور ایمن توسط دستورالعملهای سیستم اداره میشوند، تحلیلگر داده نیازی به نوشتن یک اعلان طولانی و پر از شرط ندارد.
در رابط چت، عبارت زیر را وارد کنید:
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
ارزیابی بینش ایجاد شده
پس از ارسال درخواست، خروجی تولید شده به صورت بومی را با دقت بررسی کنید تا ارزیابی کنید که چگونه BigQuery Data Agent دستورالعملهای سیستم شما را اجرا کرده است، که هم به عنوان یک لایه معنایی کنترلشده و هم به عنوان یک محافظ تحلیلی عمل میکند.
ابتدا، متن خلاصه تولید شده در بالای دادهها را بخوانید. توجه کنید که چگونه عامل به طور خودکار درخواست ساده شما برای "افراد مهم در معرض خطر" را به آستانههای دقیق متریک تعریف شده در دستورالعملهای سیستم شما (مثلاً با ارجاع به lifetime_value > 100, cart_adds > 0 و 90 روز عدم فعالیت) ترجمه میکند. این امر تأیید میکند که عامل منطق کسب و کار شما را درونیسازی کرده است، به این معنی که کاربران نهایی هرگز نیازی به حفظ کردن یا کدنویسی منطق پیچیده در درخواستهای روزانه خود ندارند.
در مرحله بعد، نمای SQL را باز کنید تا کد تولید شده را بررسی کنید. عامل باید بر اساس دستورالعملهای شما، Google Standard SQL را که از نظر ریاضی صحیح است، ساخته باشد:
- پنجرههای زمانی پویا: محاسبهی مهر زمانی را در عبارت
WHEREجستجو کنید (معمولاً با استفاده ازTIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)). - پایبندی دقیق به طرحواره: با اعمال صریح تابع
UNNEST()به آرایهtop_preferences، تأیید کنید که عامل از قوانین سختگیرانه طرحواره شما پیروی کرده است. برای جداسازی دقیق دستهای که بیشترین تکرار را در هر کشور دارد، معمولاً خواهید دید که از تکنیکهای پیشرفتهای مانند تابع پنجرهایROW_NUMBER() OVER()در یک عبارت جدولی مشترک (CTE) استفاده میکند.
نمودار و جدول دادههای رندر شده خودکار را بررسی کنید. دادهها به صورت بصری بازارهای اصلی حفظ مشتری شما (معمولاً کشورهای با حجم فروش بالا مانند چین یا ایالات متحده) را در کنار وابستگیهای جهانی محصول غالب آنها (اغلب "شلوار جین") نشان میدهند. توجه کنید که رابط کاربری بومی چگونه خروجی را برای مصرف فوری بدون نیاز به کد بصریسازی صریح، ساختاردهی میکند.
متن بینشهای نقطهگذاری شده توسط عامل را بخوانید. از آنجا که شما گاردریلهای تحلیلی را ایجاد کردهاید، به طور خاص به دنبال بینشی در مورد کیفیت دادهها یا اهمیت آماری باشید. ممکن است ببینید که عامل به صراحت کشورهایی را در پایین جدول با تعداد کاربران بسیار کم (مثلاً مناطقی با تعداد انگشتشماری کاربر) علامتگذاری میکند. به جای توهم کورکورانه یک کمپین بازاریابی هدفمند بر اساس یک نقطه داده واحد، عامل به درستی توصیه میکند که این ناهنجاریها برای یک استراتژی در مقیاس بزرگ از نظر آماری ناچیز هستند. این نشان میدهد که چگونه تعبیه گاردریلهای نظارتی به طور مستقیم در عامل به طور مؤثر از محاسبات اشتباه کسبوکار مبتنی بر هوش مصنوعی جلوگیری میکند.
۹. با Gemini و MCP بینشهای هوش مصنوعی ایجاد کنید
این نماینده با موفقیت جمعیت هدف اصلی را شناسایی کرده است: افراد مهم در معرض خطر در کشورهای خاص. با این حال، کار یک تحلیلگر در حد بینش است. برای جذب مجدد این کاربران، تیم بازاریابی باید یک کمپین اجرا کند.
شما از پروتکل Model Context (MCP) برای اتصال مستقیم یک دستیار هوش مصنوعی خارجی به این لیست جمعیتی خاص در BigQuery استفاده خواهید کرد و بدون ساخت API های سفارشی، از تجزیه و تحلیل داده به اقدام مبتنی بر هوش مصنوعی منتقل خواهید شد.
پیکربندی سرور BigQuery MCP
بلوک زیر را اجرا کنید تا فایل پیکربندی mcp.json ایجاد شود. این فایل پارامترهای اتصال لازم را فراهم میکند تا رابط خط فرمان Gemini بتواند با BigQuery به طور ایمن ارتباط برقرار کند.
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
ایجاد ایمیل بازاریابی
ابزار Gemini CLI را از ترمینال خود اجرا کنید و به صراحت پرچم پیکربندی MCP را برای خواندن BigQuery lakehouse خود وارد کنید.
رابط خط فرمان Gemini را اجرا کنید.
source env.sh
gemini
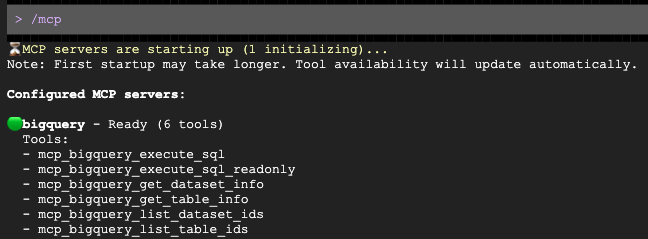
پس از باز شدن فرم، از آن بخواهید که یک پیام شخصیسازیشده برای جمعیت هدف شما تهیه کند:
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
Gemini به طور خودکار از طریق سرور MCP به BigQuery پرس و جو میکند، جمعیتشناسی را شناسایی میکند و ایمیل را برای شما پیشنویس میکند!
۱۰. تمیز کردن محیط زیست
برای جلوگیری از هزینههای مداوم برای حساب Google Cloud خود و تنظیم مجدد پروژه برای اجراهای بعدی، باید منابع ایجاد شده در طول این codelab را حذف کنید.
بلوک زیر را برای ایجاد اسکریپت cleanup.sh اجرا کنید. این اسکریپت به عنوان یک مکانیزم خودکار حذف (teardown) عمل میکند و خوشه و نمونه AlloyDB، مجموعه دادههای BigQuery و مخزن ذخیرهسازی ابری شما را برای جلوگیری از هزینههای بیشتر، به طور دائم حذف میکند.
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
اسکریپت پاکسازی را اجرا کنید تا منابع خود را با خیال راحت حذف کنید:
bash cleanup.sh
۱۱. تبریک میگویم!
شما با موفقیت یک Lakehouse داده باز بین ابری ساخته و پرسوجو کردهاید.
شما یاد گرفتید:
- چگونه میتوان دادهها را از منابع مختلف با استفاده از BigQuery Zero-ETL و Google Cloud Lakehouse یکپارچهسازی کرد.
- چگونه میتوان از موتور لایتنینگ بومی C++ در سرویس مدیریتشده برای اتصالات برداری عظیم آپاچی اسپارک بهره برد.
- نحوه استفاده از BigQuery Data Agent برای کاوش زبان طبیعی.
- چگونه با استفاده از پروتکل زمینه مدل (MCP) و جمینی، دادههای خود را به جمینی متصل کنید.
قدم بعدی چیست؟
- مستندات Lakehouse را بررسی کنید
- درباره AlloyDB zero-ETL to BigQuery بیشتر بدانید
- درباره موتور لایتنینگ بخوانید