
1. Introduction
Dans cet atelier de programmation, vous allez créer un data lakehouse ouvert multicloud qui unifie les silos de données sur AWS, Google Cloud et AlloyDB sans avoir besoin d'un ETL complexe. Vous utiliserez Lakehouse comme plate-forme d'intelligence centrale, AlloyDB comme source de données opérationnelles et Managed Service pour Apache Spark pour le traitement vectorisé hautes performances. Enfin, vous utiliserez Gemini pour obtenir des insights commerciaux puissants à partir de votre lakehouse.
Imaginez que vos données transactionnelles (users, orders, order items) se trouvent dans une base de données opérationnelle AlloyDB, que vos données product se trouvent dans un bucket AWS S3 et que vos flux de clics massifs event logs sont stockés dans Cloud Storage. Vous devez joindre ces ensembles de données pour identifier les données démographiques cibles de votre prochaine campagne marketing et générer des e-mails de sensibilisation personnalisés.
Prérequis
- Vous connaissez les commandes SQL et de terminal de base.
- Un projet Google Cloud avec facturation activée.
Points abordés
- Découvrez comment intégrer des silos de données disparates à l'aide de BigQuery sans ETL (AlloyDB) et de Lakehouse pour Apache Iceberg.
- Découvrez comment exécuter un job de profilage comportemental à haute vitesse à l'aide de Managed Service pour Apache Spark optimisé par le moteur Lightning natif C++.
- Découvrez comment utiliser l'agent de données BigQuery pour effectuer des analyses complexes en langage naturel sur des données unifiées.
- Configurer le protocole Model Context Protocol (MCP) pour permettre à la CLI Gemini de lire les données de votre Lakehouse pour Apache Iceberg et de rédiger du contenu marketing
Prérequis
- Un compte Google Cloud et un projet Google Cloud
- Un navigateur Web tel que Chrome
Prérequis
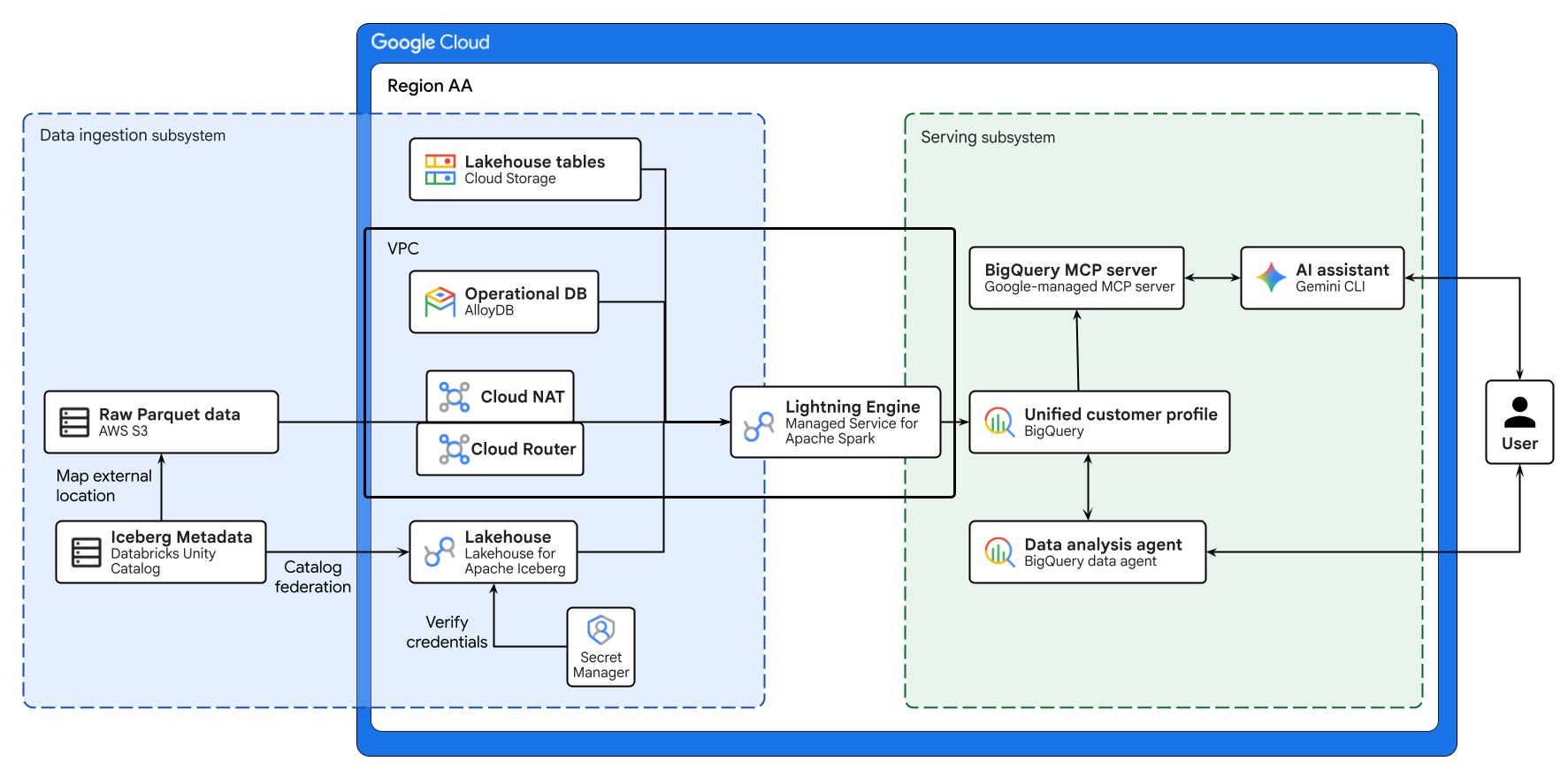
Le diagramme ci-dessus illustre le flux de bout en bout du lakehouse multicloud créé dans cet atelier de programmation. Les données opérationnelles d'AlloyDB et les données distantes d'AWS S3 sont fédérées de manière sécurisée à l'aide de Lakehouse pour Apache Iceberg. Managed Service pour Apache Spark traite ces sources disparates pour créer un profil client unifié dans BigQuery. Enfin, un agent de données BigQuery et un serveur MCP BigQuery géré par Google via Gemini CLI fournissent une interface intuitive basée sur l'IA pour l'analyse de données avancée.
Concepts clés
- Lakehouse de données multicloud ouvert : unifie les silos de données dans les environnements AWS, Google Cloud et sur site sans nécessiter d'ETL complexe.
- BigQuery zero-ETL : permet d'interroger directement les bases de données opérationnelles sans déplacement complexe des données.
- Lakehouse pour Apache Iceberg : permet d'assurer la cohérence de la sécurité et de la gouvernance dans le stockage multicloud à l'aide du format Apache Iceberg.
- Lightning Engine : moteur C++ natif pour l'exécution Apache Spark hautes performances.
- Model Context Protocol (MCP) : connecte Gemini directement à votre lakehouse BigQuery.
2. Préparation
Créer un projet Google Cloud
- Dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Démarrer Cloud Shell
Bien que Google Cloud puisse être utilisé à distance depuis votre ordinateur portable, nous allons nous servir de Google Cloud Shell pour cet atelier de programmation, un environnement de ligne de commande exécuté dans le cloud.
Dans la console Google Cloud, cliquez sur l'icône Cloud Shell dans la barre d'outils supérieure :
Le provisionnement et la connexion à l'environnement prennent quelques instants seulement. Une fois l'opération terminée, le résultat devrait ressembler à ceci :

Cette machine virtuelle contient tous les outils de développement nécessaires. Elle comprend un répertoire d'accueil persistant de 5 Go et s'exécute sur Google Cloud, ce qui améliore nettement les performances du réseau et l'authentification. Vous pouvez effectuer toutes les tâches de cet atelier de programmation dans un navigateur. Vous n'avez rien à installer.
Initialiser l'environnement
Ouvrez Cloud Shell et définissez les variables de votre projet pour vous assurer que toutes les commandes ciblent la bonne infrastructure.
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
Appliquez les variables à votre session active :
source ./env.sh
Activer les API
Activez les services Google Cloud nécessaires.
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3. Configurer l'infrastructure de base
Au lieu de déplacer toutes les données dans un seul dépôt à l'aide de pipelines ETL fragiles, vous allez créer une architecture fédérée multicloud. Dans une entreprise réelle, les données sont intrinsèquement fragmentées en raison des différentes exigences système. Vous allez orchestrer les sources de données suivantes :
- AlloyDB (base de données transactionnelle principale) : stocke les données des utilisateurs, des commandes et des éléments de commande. En tant que base de données opérationnelle en direct, elle garantit les propriétés ACID requises pour les transactions financières et les mises à jour de profil.
- AWS S3 (données de référence) : stocke le catalogue
products. Représentation d'un ancien système de gestion des données de référence (MDM) sur AWS. - Google Cloud Storage (lac de données volumineux) : stocke
events(journaux de flux de clics). Les données à haut débit, comme les journaux Web, entraîneraient le plantage d'une base de données relationnelle. Le stockage d'objets offre une évolutivité infinie. Le conserver dans Google Cloud permet de maximiser la localité de calcul pour vos moteurs analytiques.
Commencez par configurer le réseau sous-jacent. Les bases de données gérées Google Cloud, comme AlloyDB, nécessitent une connexion d'appairage de VPC privé pour communiquer de manière sécurisée au sein du réseau de votre projet.
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
Ensuite, créez un ensemble de données BigQuery et une connexion de ressource cloud Lakehouse. D'un point de vue architectural, une connexion de ressource délègue l'accès aux données à un compte de service dédié géré par Google, ce qui applique le principe du moindre privilège.
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. Provisionner la base de données opérationnelle
Provisionnez une instance principale AlloyDB et injectez vos données transactionnelles critiques.
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
Une fois la base de données prête, vous devez créer une connexion externe BigQuery à AlloyDB. Cette connexion stocke de manière sécurisée les identifiants et le point de terminaison de la base de données, ce qui permet à BigQuery de transférer l'exécution SQL directement vers le moteur de calcul AlloyDB (sans ETL).
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
Transférez les tables transactionnelles de manière sécurisée dans AlloyDB. Utilisez le proxy d'authentification AlloyDB pour connecter de manière sécurisée votre session Cloud Shell locale à l'instance AlloyDB privée. Cela vous permet d'envoyer les données transactionnelles à l'aide d'outils de ligne de commande locaux.
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5. Fédérer les données de référence (spoke AWS)
Notre catalogue de produits, qui contient les métadonnées brutes des articles, réside de manière native sur AWS S3 sous forme de tables Apache Iceberg. Les métadonnées sont régies par un catalogue distant.
Au lieu de créer des pipelines ETL fragiles pour copier ces données dans Google Cloud, vous allez utiliser Lakehouse pour Apache Iceberg (fédération de catalogues REST).
Cette approche sans ETL permet à Lakehouse et Managed Service pour Apache Spark de découvrir et de lire de manière dynamique les métadonnées Iceberg et les fichiers Parquet sous-jacents directement depuis votre environnement distant.
Si vous disposez d'un compte AWS actif et que Databricks Unity Catalog est configuré, vous pouvez l'utiliser. Sinon, vous pouvez simuler votre environnement à l'aide de Google Cloud Storage. Choisissez l'une ou l'autre.
Option A : Apportez votre propre AWS (Apache Iceberg natif)
Prérequis : cette option suppose que vous avez déjà provisionné un bucket AWS S3, que vous l'avez connecté en tant qu'emplacement externe dans Databricks Unity Catalog, que vous avez mappé une table Iceberg et que vous avez généré un principal de service OAuth avec accès en lecture.
1. Stockage sécurisé des identifiants
Le codage en dur de jetons d'accès de longue durée est un anti-modèle architectural. Vous stockerez l'ID client et le code secret OAuth Databricks dans Google Cloud Secret Manager. Le service Lakehouse les récupérera de manière dynamique au moment de l'exécution pour fournir des jetons éphémères, ce qui centralisera la gestion de vos identifiants.
Exécutez le bloc suivant pour générer le script. (Ne modifiez rien pour l'instant.)
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
Exécutez ensuite la commande suivante pour ouvrir automatiquement le script généré dans l'éditeur de code visuel au-dessus de votre terminal.
cloudshell edit create_secret.sh
- Dans l'éditeur, remplacez les espaces réservés
<YOUR_...>par vos identifiants Databricks. - Assurez-vous que l'URL de votre espace de travail n'inclut pas
https://ni de barre oblique à la fin (par exemple,123456789.cloud.databricks.com). - Appuyez sur
Ctrl+S(ouCmd+Ssur Mac) pour enregistrer le fichier. - Revenez à votre session de terminal et exécutez le script :
source create_secret.sh
2. Créer le catalogue fédéré
Pour plus de simplicité dans cet atelier de programmation, vous allez configurer le catalogue pour qu'il parcoure l'Internet public de manière sécurisée. Cependant, pour les charges de travail de production, l'interrogation d'ensembles de données volumineux sur l'Internet public entraîne des coûts de sortie inutiles et une latence imprévisible. La bonne pratique consiste à configurer un Cross-Cloud Interconnect (CCI) privé entre AWS et Google Cloud, ce qui réduit considérablement les coûts de sortie et garantit des performances réseau déterministes.
Utilisez la gcloud CLI pour provisionner le catalogue Lakehouse fédéré :
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. Appliquer des liaisons IAM basées sur le principe du moindre privilège
Lorsque vous avez provisionné le catalogue fédéré à l'étape précédente, Google Cloud Lakehouse a automatiquement lancé un job d'actualisation en arrière-plan pour synchroniser les fichiers manifestes Iceberg toutes les 330 secondes.
Vous devez attribuer le rôle secretAccessor au compte de service du catalogue Lakehouse pour qu'il puisse récupérer de manière sécurisée le jeton OAuth Databricks lors de ces synchronisations en arrière-plan et exécutions de requêtes. Si cette liaison est manquante, des erreurs 403 silencieuses se produiront lorsque Lakehouse tentera de mettre à jour le catalogue.
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. Activer l'accès à Internet sortant pour Managed Service pour Apache Spark
Dans une étape ultérieure, Managed Service pour Apache Spark lira les données AWS à distance. Étant donné que Managed Service for Apache Spark Serverless s'exécute entièrement dans un réseau VPC privé sans adresses IP externes, il ne peut pas accéder à AWS S3 sur Internet par défaut. Vous devez provisionner un Cloud NAT pour permettre aux nœuds de calcul Spark d'accéder à Internet en sortie.
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. Définir la cible en aval
Exportez cette variable pour que les jobs Apache Spark en aval sachent exactement où interroger les données AWS sans nécessiter de modifications manuelles du code.
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
Option B : Simuler un environnement AWS via Cloud Storage
Si vous ne disposez pas d'un compte AWS actif, vous pouvez simuler le silo multicloud de manière native à l'aide des tables gérées Lakehouse sur Google Cloud Storage.
1. Créer la table Iceberg fictive
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. Définir la cible en aval
Les ensembles de données BigQuery standards utilisent une structure d'espace de noms en trois parties (project.dataset.table). Exportez cette variable afin que le job Apache Spark en aval cible les données fictives.
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. Ingérer des journaux d'événements (spoke Google Cloud)
Les données sur les flux de clics augmentent de façon exponentielle. Vous stockez les événements bruts complets et non agrégés en local dans Cloud Storage sous forme de tables Lakehouse gérées.
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. Créer un profil client unifié
Maintenant que votre infrastructure brute est entièrement renseignée, il est temps de créer un profil client unifié.
Vous utiliserez Managed Service pour Apache Spark, optimisé par Lightning Engine. Lightning Engine est un accélérateur de requêtes natif C++ hautes performances de Google Cloud, basé sur des technologies Open Source telles qu'Apache Gluten et Velox. Il améliore automatiquement l'exécution en maximisant l'efficacité du processeur et en mettant en cache les données de manière intelligente. Cette approche est idéale pour effectuer des jointures multidirectionnelles massives, des fenêtrages complexes ou des agrégations comportementales dans plusieurs clouds.
Vous utiliserez le connecteur Spark BigQuery pour lire directement les requêtes fédérées AlloyDB sans ETL et les tables Lakehouse, effectuer les agrégations vectorisées massives de manière native dans Spark et réécrire le profil unifié résultant dans BigQuery.
Configurer les autorisations IAM pour Managed Service pour Apache Spark
Par défaut, Serverless Spark exécute les jobs par lot à l'aide du compte de service Compute Engine par défaut. Avant de l'envoyer, vous devez accorder à ce compte de service les autorisations requises pour exécuter la charge de travail et gérer les jobs BigQuery.
(Remarque : Bien que le nom du service ait été remplacé par "Managed Service pour Apache Spark" afin de refléter la terminologie standard du secteur, les commandes API et les rôles IAM sous-jacents utilisent toujours l'identifiant "dataproc".)
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
Créer et envoyer le job
Commencez par créer le script de tâche PySpark. Ce script détecte automatiquement si vous avez choisi l'option A (catalogue fédéré AWS) ou l'option B (simulation Google Cloud) en fonction de votre variable d'environnement AWS_PRODUCTS_TABLE, définit la logique SparkSQL et utilise la manipulation de tableau natif de Spark pour calculer les fenêtres RFM (récence, fréquence, montant).
Exécutez le bloc suivant dans Cloud Shell.
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
Une fois le script entièrement assemblé et les configurations requises injectées de manière dynamique, envoyez le job par lot à Managed Apache Spark Serverless.
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
Vérifier l'exécution du job dans la console
Une fois le job par lot envoyé, vous pouvez vérifier qu'il utilise le moteur d'exécution C++ accéléré :
- Dans la console Google Cloud, accédez à Managed Service pour Apache Spark > Sans serveur > Lots.
- Cliquez sur le job en cours d'exécution.
- Dans le volet des détails du job, vérifiez que la propriété Niveau est définie sur
Premiumet que le moteur est défini surLightning Engine.
8. Analyser avec l'agent de données BigQuery
Maintenant que vous avez fédéré les données fragmentées multicloud et exécuté les agrégations comportementales lourdes à l'aide de Managed Service pour Apache Spark, l'étape suivante consiste à analyser les données.
Tout d'abord, inspectez le schéma de la table de profil unifiée que vous venez de créer dans l'UI BigQuery pour comprendre visuellement la structure de données que vous exposez à l'agent :
- Dans la console Google Cloud, accédez à BigQuery.
- Dans le volet "Explorateur" à gauche, développez votre projet et l'ensemble de données
demo_lakehouse. - Cliquez sur la table
unified_customer_profile. - Sélectionnez l'onglet "Schéma" dans l'espace de travail principal.
Vérifiez le schéma de la nouvelle table. La colonne top_preferences est un REPEATED STRUCT (tableau d'enregistrements contenant category, brand et sale_price). Traditionnellement, l'interrogation de tableaux imbriqués nécessite un code SQL complexe utilisant la fonction UNNEST(), ce qui peut être un obstacle pour les analystes commerciaux. En ancrant un agent de données BigQuery dans ce tableau spécifique, l'agent comprend intrinsèquement le schéma et gère les opérations complexes du langage SQL standard de Google en arrière-plan.
Créer l'agent de données
Dans cette section, vous allez créer un agent de données BigQuery et interagir avec lui. Au lieu d'écrire manuellement des requêtes SQL complexes pour annuler l'imbrication des tableaux et calculer les métriques, vous provisionnerez un agent d'IA spécifiquement adapté à votre profil unifié nouvellement créé, ce qui vous permettra d'explorer les données en langage naturel.
- Dans le panneau de navigation de gauche, recherchez et cliquez sur Agents.
- Cliquez sur + New Agent (+ Nouvel agent) pour initialiser un nouvel assistant IA.
- Configurez l'agent :
- Nom de l'agent :
Retail VIP Analysis Agent - Sources de données : cliquez sur Ajouter une source, puis recherchez le tableau
unified_customer_profile.
- Cliquez sur Ajouter et patientez quelques secondes que l'agent initialise son espace de travail.
Une fois l'agent établi, la définition d'instructions système explicites est une pratique essentielle de gouvernance des données. Utilisez les instructions système comme couche sémantique. En intégrant des définitions métier à l'échelle de l'entreprise, en gérant la complexité des schémas et en établissant des garde-fous analytiques, vous éliminez la complexité technique pour l'utilisateur final et empêchez le LLM de tirer des conclusions à partir de données statistiquement non significatives.
Collez le texte suivant dans le champ Instruction :
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
Envoyer une requête à l'agent
Étant donné que la logique métier complexe (la définition exacte d'un "VIP à risque") et les exigences de gestion des schémas sont régies de manière sécurisée par les instructions système, l'analyste de données n'a pas besoin d'écrire une requête verbeuse et comportant de nombreuses conditions.
Dans l'interface de chat, saisissez le prompt suivant :
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
Évaluer l'insight généré
Après avoir envoyé la requête, examinez attentivement le résultat généré en mode natif pour évaluer la façon dont l'agent de données BigQuery a appliqué vos instructions système, en agissant à la fois comme une couche sémantique régie et comme un garde-fou analytique.
Commencez par lire le texte récapitulatif généré au-dessus des données. Remarquez comment l'agent traduit automatiquement votre simple demande "VIP à risque" en seuils de métriques exacts définis dans vos instructions système (par exemple, en faisant référence à lifetime_value > 100, cart_adds > 0 et à 90 jours d'inactivité). Cela confirme que l'agent a internalisé votre logique métier, ce qui signifie que les utilisateurs finaux n'ont jamais besoin de mémoriser ni de coder en dur une logique complexe dans leurs requêtes quotidiennes.
Ensuite, développez la vue SQL pour inspecter le code généré. L'agent aurait dû construire un langage SQL standard Google mathématiquement correct en fonction de vos instructions :
- Périodes dynamiques : recherchez le calcul du code temporel dans la clause
WHERE(généralement à l'aide deTIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)). - Respect strict du schéma : vérifiez que l'agent a respecté vos règles strictes concernant le schéma en appliquant explicitement la fonction
UNNEST()au tableautop_preferences. Pour isoler précisément la catégorie la plus fréquente par pays, vous verrez généralement qu'il utilise des techniques avancées comme une fonction de fenêtrageROW_NUMBER() OVER()dans une expression de table courante (CTE).
Examinez le graphique et le tableau de données générés automatiquement. Les données révéleront visuellement vos principaux marchés de fidélisation (en mettant généralement en évidence les pays à fort volume comme la Chine ou les États-Unis) ainsi que leurs affinités produit universellement dominantes (souvent "Jeans"). Notez que l'UI native structure la sortie pour une consommation immédiate sans nécessiter de code de visualisation explicite.
Lisez le texte Insights généré par l'agent sous forme de liste à puces. Comme vous avez défini des garde-fous analytiques, recherchez plus particulièrement un insight concernant la qualité des données ou la pertinence statistique. Il est possible que l'agent signale explicitement les pays en bas du tableau qui comptent très peu d'utilisateurs (par exemple, les régions avec seulement quelques utilisateurs). Au lieu de générer aveuglément une campagne marketing ciblée basée sur un seul point de données, l'agent indiquera à juste titre que ces anomalies sont statistiquement insignifiantes pour une stratégie à grande échelle. Cela montre comment l'intégration de garde-fous de gouvernance directement dans l'agent permet d'éviter efficacement les erreurs de calcul commerciales basées sur l'IA.
9. Générer des insights d'IA avec Gemini et MCP
L'agent a correctement identifié la principale catégorie démographique cible : les VIP à risque dans des pays spécifiques. Toutefois, le travail d'un analyste s'arrête à l'insight. Pour réengager ces utilisateurs, l'équipe marketing doit exécuter une campagne.
Vous utiliserez le protocole MCP (Model Context Protocol) pour connecter un assistant IA externe directement à cette liste démographique spécifique dans BigQuery, en passant de l'analyse des données à l'action basée sur l'IA sans créer d'API personnalisées.
Configurer le serveur BigQuery MCP
Exécutez le bloc ci-dessous pour générer le fichier de configuration mcp.json. Ce fichier fournit les paramètres de connexion nécessaires pour que Gemini CLI puisse interagir de manière sécurisée avec BigQuery.
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
Générer un e-mail marketing
Démarrez l'outil Gemini CLI depuis votre terminal, en transmettant explicitement le flag de configuration MCP pour lui permettre de lire votre lakehouse BigQuery.
Exécutez Gemini CLI.
source env.sh
gemini
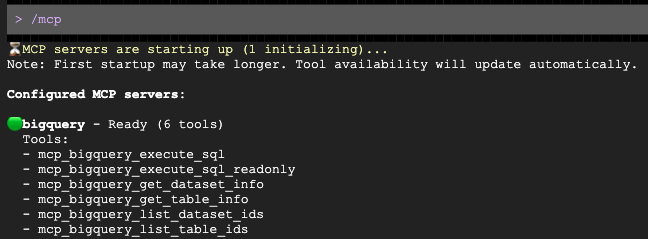
Une fois la requête ouverte, demandez-lui de rédiger un message personnalisé pour votre catégorie démographique cible :
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
Gemini interrogera automatiquement BigQuery via le serveur MCP, identifiera la tranche démographique et rédigera l'e-mail pour vous.
10. Nettoyer votre environnement
Pour éviter que les ressources créées lors de cet atelier de programmation ne soient facturées en permanence sur votre compte Google Cloud et pour réinitialiser correctement votre projet pour les futures exécutions, vous devez supprimer ces ressources.
Exécutez le bloc suivant pour créer le script cleanup.sh. Ce script sert de mécanisme de suppression automatisé. Il supprime définitivement le cluster et l'instance AlloyDB, les ensembles de données BigQuery et votre bucket Cloud Storage pour éviter toute facturation supplémentaire.
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
Exécutez le script de nettoyage pour supprimer vos ressources de manière sécurisée :
bash cleanup.sh
11. Félicitations !
Vous avez créé et interrogé un data lakehouse ouvert multicloud.
Les points suivants ne devraient maintenant plus avoir de secrets pour vous :
- Fédérer des données provenant de sources disparates à l'aide de BigQuery Zero-ETL et de Google Cloud Lakehouse.
- Découvrez comment exploiter le moteur Lightning natif C++ dans les jointures vectorisées massives de Managed Service pour Apache Spark.
- Découvrez comment utiliser l'agent de données BigQuery pour explorer les données en langage naturel.
- Découvrez comment transférer vos données vers Gemini à l'aide du protocole MCP (Model Context Protocol) et de Gemini.
Et ensuite ?
- Consulter la documentation Lakehouse
- En savoir plus sur AlloyDB sans ETL vers BigQuery
- En savoir plus sur Lightning Engine