
1. מבוא
ב-Codelab הזה תבנו lakehouse פתוח חוצה-עננים שמאחד את סילו הנתונים ב-AWS, ב-Google Cloud וב-AlloyDB בלי שתצטרכו לבצע תהליכי ETL מורכבים. תשתמשו ב-Lakehouse כמרכז המודיעין המרכזי, ב-AlloyDB כמקור נתונים תפעולי וב-Managed Service for Apache Spark לעיבוד וקטורי עם ביצועים גבוהים. לבסוף, תשתמשו ב-Gemini כדי להפיק תובנות עסקיות חשובות מ-lakehouse.
נניח שהנתונים הטרנזקציוניים שלכם (users, orders, order items) נמצאים במסד נתונים תפעולי של AlloyDB, נתוני product נמצאים בדלי AWS S3, ונתוני event logs של זרם קליקים עצום מאוחסנים ב-Cloud Storage. כדי לזהות את הדמוגרפיה של קהל היעד לקמפיין השיווקי הבא וליצור אימיילים בהתאמה אישית, צריך לצרף את קבוצות הנתונים האלה.
דרישות מוקדמות
- היכרות עם פקודות בסיסיות של SQL ופקודות טרמינל.
- פרויקט ב-Google Cloud שהחיוב בו מופעל.
מה תלמדו
- איך משלבים בין סילו נתונים שונים באמצעות BigQuery zero-ETL (AlloyDB) ו-Lakehouse for Apache Iceberg.
- איך מריצים עבודה של פרופיל התנהגותי במהירות גבוהה באמצעות Managed Service for Apache Spark שמבוסס על מנוע Lightning מקורי של C++.
- איך משתמשים בסוכן הנתונים של BigQuery כדי לבצע ניתוח מורכב של שפה טבעית על נתונים מאוחדים.
- איך מגדירים את Model Context Protocol (MCP) כדי לאפשר ל-Gemini CLI לקרוא מ-Lakehouse for Apache Iceberg ולנסח תוכן שיווקי.
מה תצטרכו
- חשבון Google Cloud ופרויקט Google Cloud
- דפדפן אינטרנט כמו Chrome
מה תצטרכו
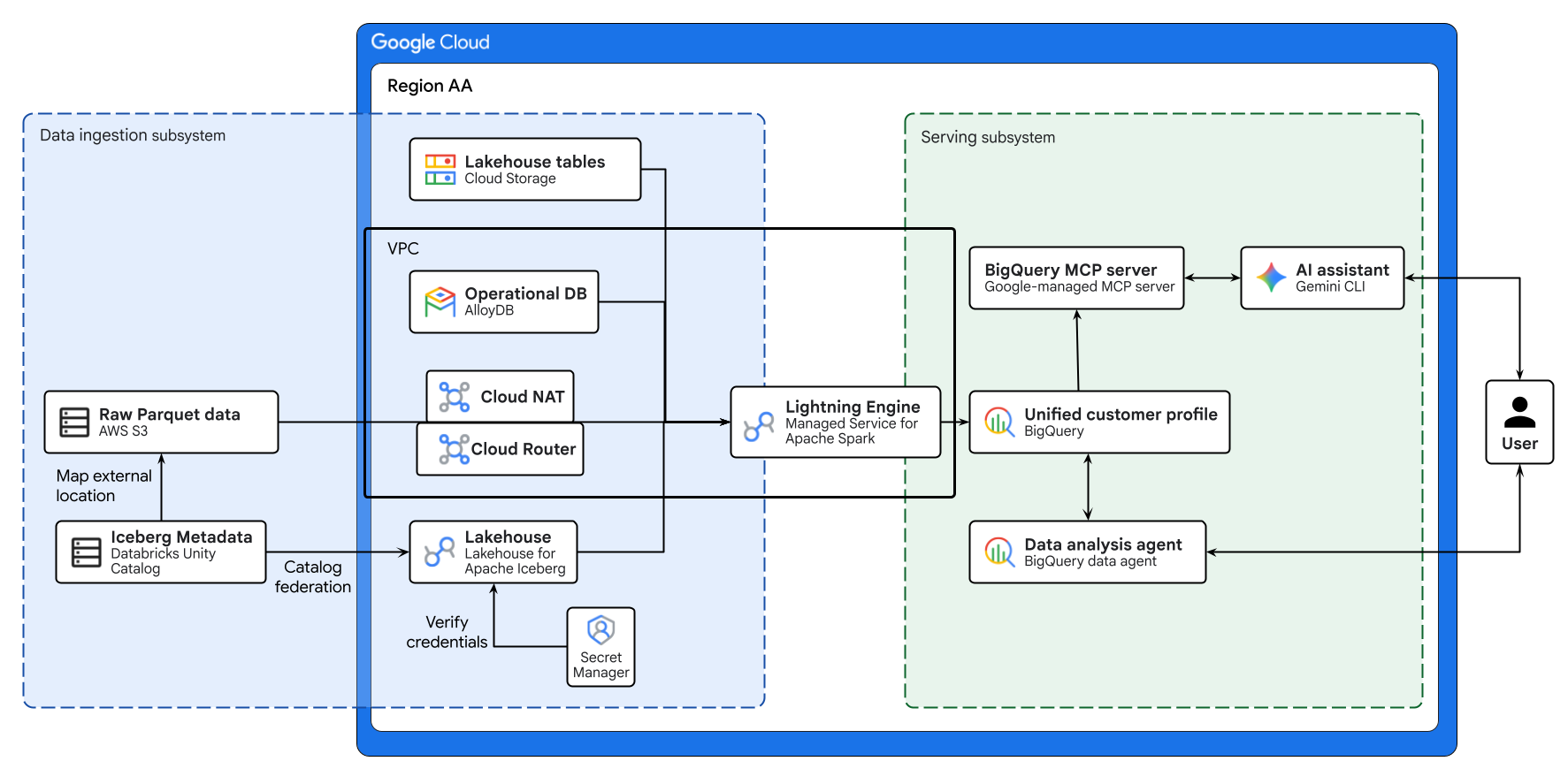
התרשים שלמעלה ממחיש את התהליך מקצה לקצה של lakehouse חוצה עננים שנבנה בשיעור Codelab הזה. נתונים תפעוליים מ-AlloyDB ונתונים מרוחקים מ-AWS S3 מאוחדים בצורה מאובטחת באמצעות Lakehouse for Apache Iceberg. Managed Service for Apache Spark מעבד את המקורות השונים האלה כדי ליצור פרופיל לקוח מאוחד ב-BigQuery. לבסוף, סוכן נתונים של BigQuery ושרת BigQuery MCP בניהול Google דרך Gemini CLI מספקים ממשק אינטואיטיבי מבוסס-AI לניתוח נתונים מתקדם.
מושגים מרכזיים
- Lakehouse נתונים פתוח חוצה-ענן: מאחד את סילו הנתונים בסביבות AWS, Google Cloud ומקומיות בלי צורך ב-ETL מורכב.
- BigQuery zero-ETL: מאפשרת להריץ שאילתות ישירות במסדי נתונים תפעוליים בלי להעביר נתונים בצורה מורכבת.
- Lakehouse for Apache Iceberg: מאפשר אבטחה וניהול עקביים באחסון חוצה-עננים באמצעות פורמט Apache Iceberg.
- Lightning Engine: מנוע C++ מקורי לביצוע Apache Spark בביצועים גבוהים.
- Model Context Protocol (MCP): מחבר את Gemini ישירות למאגר הנתונים שלכם ב-BigQuery.
2. הגדרה ודרישות
יצירת פרויקט ב-Google Cloud
- במסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים פרויקט ב-Google Cloud או יוצרים פרויקט.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
מפעילים את Cloud Shell
אפשר להפעיל את Google Cloud מרחוק מהמחשב הנייד, אבל ב-Codelab הזה נשתמש ב-Google Cloud Shell, סביבת שורת פקודה שפועלת בענן.
ב-מסוף Google Cloud, לוחצים על סמל Cloud Shell בסרגל הכלים שבפינה הימנית העליונה:
יחלפו כמה רגעים עד שההקצאה והחיבור לסביבת העבודה יושלמו. בסיום התהליך, אמור להופיע משהו כזה:

המכונה הווירטואלית הזו כוללת את כל הכלים שדרושים למפתחים. יש בה ספריית בית בנפח מתמיד של 5GB והיא פועלת ב-Google Cloud, מה שמשפר מאוד את הביצועים והאימות ברשת. אפשר לבצע את כל העבודה ב-codelab הזה בדפדפן. לא צריך להתקין שום דבר.
אתחול הסביבה
פותחים את Cloud Shell ומגדירים את משתני הפרויקט כדי לוודא שכל הפקודות מכוונות לתשתית הנכונה.
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
מחילים את המשתנים על הסשן הפעיל:
source ./env.sh
הפעלת ממשקי API
מפעילים את שירותי Google Cloud הנדרשים.
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3. הגדרת תשתית ליבה
במקום להעביר את כל הנתונים למאגר יחיד באמצעות צינורות ETL שעלולים להיפגע, תבנו ארכיטקטורה מאוחדת חוצת-עננים. בארגון אמיתי, הנתונים מפולגים באופן מובנה בגלל דרישות מערכת שונות. תנהלו את מקורות הנתונים הבאים:
- AlloyDB (מסד נתונים מרכזי של טרנזקציות): מאחסן נתוני משתמשים, הזמנות ופריטי הזמנה. כמסד נתונים תפעולי בזמן אמת, הוא מבטיח את מאפייני ה-ACID שנדרשים לעסקאות פיננסיות ולעדכוני פרופילים.
- AWS S3 (נתוני מאסטר): אחסון קטלוג
products. מייצג מערכת MDM מדור קודם ב-AWS. - Google Cloud Storage (אגם נתונים עצום): אחסון של
events(יומני נתוני קליקים). נתונים עם תפוקה גבוהה, כמו יומני אינטרנט, יגרמו לקריסה של מסד נתונים רלציוני. אחסון אובייקטים מספק יכולת הרחבה אינסופית, ואחסון ב-Google Cloud ממקסם את המיקום של המחשוב עבור מנועי הניתוח שלכם.
קודם כול, מגדירים את הרשת הבסיסית. מסדי נתונים מנוהלים של Google Cloud, כמו AlloyDB, דורשים חיבור פרטי של VPC Peering כדי לתקשר בצורה מאובטחת בתוך רשת הפרויקט.
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
לאחר מכן, יוצרים מערך נתונים ב-BigQuery וחיבור למשאב ענן של Lakehouse. מבחינה ארכיטקטונית, חיבור משאבים מעביר את הגישה לנתונים לחשבון שירות ייעודי בניהול Google, וכך אוכף את העיקרון של הרשאות מינימליות.
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. הקצאת מסד הנתונים התפעולי
הקצאת מופע ראשי של AlloyDB והזרקת נתונים טרנזקציונליים קריטיים.
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
אחרי שהמסד מוכן, צריך ליצור חיבור חיצוני ל-BigQuery אל AlloyDB. החיבור הזה מאחסן בצורה מאובטחת את פרטי הכניסה ונקודת הקצה של מסד הנתונים, ומאפשר ל-BigQuery להעביר את הביצוע של SQL ישירות למנוע החישוב של AlloyDB (zero-ETL).
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
דחיפה מאובטחת של טבלאות טרנזקציות ל-AlloyDB. משתמשים ב-AlloyDB Auth Proxy כדי לחבר באופן מאובטח את סשן Cloud Shell המקומי למכונה פרטית של AlloyDB. כך תוכלו לשלוח את הנתונים של העסקאות באמצעות כלי שורת פקודה מקומיים.
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5. איחוד נתוני האב (AWS spoke)
קטלוג המוצרים שלנו, שמכיל מטא-נתונים גולמיים של פריטים, נמצא באופן טבעי ב-AWS S3 כטבלאות Apache Iceberg. המטא-נתונים כפופים לקטלוג מרוחק.
במקום לבנות צינורות ETL שעלולים להיכשל כדי להעתיק את הנתונים האלה ל-Google Cloud, תשתמשו ב-Lakehouse for Apache Iceberg (REST catalog federation).
גישת ה-zero-ETL מאפשרת ל-Lakehouse ול-Managed Service for Apache Spark לגלות ולקרוא באופן דינמי את המטא-נתונים של Iceberg ואת קובצי ה-Parquet הבסיסיים ישירות מהסביבה המרוחקת.
אם יש לכם חשבון AWS פעיל ו-Databricks Unity Catalog מוגדר, אתם יכולים להשתמש בו. אחרת, אפשר ליצור סביבה מדמה באמצעות Google Cloud Storage. צריך לבחור באחת מהאפשרויות.
אפשרות א': שימוש ב-AWS משלכם (Native Apache Iceberg)
דרישה מוקדמת: האפשרות הזו מניחה שכבר הקציתם קטגוריית AWS S3, חיברתם אותה כמיקום חיצוני ב-Databricks Unity Catalog, מיפיתם טבלת Iceberg ויצרתם מנהל שירות OAuth עם גישת קריאה.
1. אחסון מאובטח של פרטי כניסה
קידוד קשיח של אסימוני גישה לטווח ארוך הוא דפוס נגד בארכיטקטורה. תאחסנו את מזהה הלקוח ואת הסוד של Databricks OAuth ב-Google Cloud Secret Manager. שירות Lakehouse יאחזר את האסימונים האלה באופן דינמי בזמן הריצה כדי להפיץ אסימונים לטווח קצר, וכך ירכז את ניהול פרטי הכניסה.
מריצים את הבלוק הבא כדי ליצור את הסקריפט. (אל תערכו שום דבר עדיין).
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
לאחר מכן, מריצים את הפקודה הבאה כדי לפתוח אוטומטית את הסקריפט שנוצר בעורך הקוד החזותי מעל הטרמינל.
cloudshell edit create_secret.sh
- בכלי העריכה, מחליפים את הערכים הזמניים לשמירת מקום
<YOUR_...>בפרטי הכניסה שלכם ב-Databricks. - מוודאים שכתובת ה-URL של סביבת העבודה לא כוללת
https://או לוכסנים בסוף (לדוגמה,123456789.cloud.databricks.com). - מקישים על
Ctrl+S(או עלCmd+Sב-Mac) כדי לשמור את הקובץ. - חוזרים לסשן הטרמינל ומריצים את הסקריפט:
source create_secret.sh
2. יצירת קטלוג מאוחד
כדי לפשט את התהליך בשיעור Codelab הזה, תגדירו את הקטלוג כך שיעבור בצורה מאובטחת באינטרנט הציבורי. עם זאת, עבור עומסי עבודה של ייצור, שליחת שאילתות במערכי נתונים גדולים מאוד באינטרנט הציבורי גורמת לעלויות מיותרות של תעבורת נתונים יוצאת (egress) ולחביון בלתי צפוי. השיטה המומלצת היא להגדיר חיבור פרטי של Cross-Cloud Interconnect (CCI) בין AWS לבין Google Cloud. כך אפשר לצמצם באופן משמעותי את עלויות התעבורה היוצאת ולהבטיח ביצועים דטרמיניסטיים של הרשת.
משתמשים ב-CLI של gcloud כדי להקצות את קטלוג ה-Lakehouse המאוחד:
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. החלת הרשאות מינימליות ב-IAM
כשמקצים את הקטלוג המאוחד בשלב הקודם, מערכת Google Cloud Lakehouse מפעילה אוטומטית משימת רענון ברקע כדי לסנכרן את מניפסטים של Iceberg כל 330 שניות.
צריך להעניק את התפקיד secretAccessor לחשבון השירות של קטלוג Lakehouse כדי שיוכל לאחזר בצורה מאובטחת את אסימון ה-OAuth של Databricks במהלך הסנכרונים האלה ברקע והרצת השאילתות. אם הקישור הזה חסר, יוצגו שגיאות 403 שקטות כש-Lakehouse ינסה לעדכן את הקטלוג.
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. הפעלת גישה לאינטרנט ל-Managed Service for Apache Spark
בשלב הבא, Managed Service for Apache Spark יקרא את הנתונים המרוחקים ב-AWS. מכיוון ש-Managed Service for Apache Spark Serverless פועל כולו בתוך רשת VPC פרטית ללא כתובות IP חיצוניות, הוא לא יכול להגיע ל-AWS S3 דרך האינטרנט כברירת מחדל. צריך להקצות Cloud NAT כדי לאפשר לעובדי Spark גישה לאינטרנט.
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. הגדרת יעד במורד הזרם
צריך לייצא את המשתנה הזה כדי שמשימות Apache Spark בהמשך ידעו בדיוק איפה לבצע שאילתות על נתוני AWS, בלי שיהיה צורך בשינויים ידניים בקוד.
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
אפשרות ב': סביבת AWS מדומה באמצעות Cloud Storage
אם אין לכם חשבון פעיל ב-AWS, אתם יכולים לדמות את הבידוד בין העננים באופן מקורי באמצעות טבלאות מנוהלות של Lakehouse ב-Google Cloud Storage.
1. יצירת טבלת Iceberg מדומה
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. הגדרת יעד במורד הזרם
מערכי נתונים סטנדרטיים ב-BigQuery משתמשים במבנה של מרחב שמות בן 3 חלקים (project.dataset.table). מייצאים את המשתנה הזה כדי שמשימת Apache Spark בהמשך תכוון לנתוני הדמה.
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. הטמעה של יומני אירועים (Google Cloud spoke)
הנתונים של נתוני הקליקים גדלים באופן אקספוננציאלי. אתם מאחסנים את האירועים המלאים והלא מצטברים באופן מקומי ב-Cloud Storage כטבלאות Managed Lakehouse.
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. יצירת פרופיל לקוח מאוחד
אחרי שמילאתם את כל הפרטים בתשתית הגולמית, הגיע הזמן ליצור פרופיל לקוח מאוחד.
תשתמשו ב-Managed Service for Apache Spark שמבוסס על Lightning Engine. Lightning Engine הוא מאיץ שאילתות מקוריות ב-C++ עם ביצועים גבוהים ב-Google Cloud. הוא מבוסס על טכנולוגיות קוד פתוח כמו Apache Gluten ו-Velox, ומשפר אוטומטית את הביצועים על ידי מיקסום היעילות של המעבד (CPU) ושמירת נתונים במטמון בצורה חכמה. הגישה הזו מתאימה במיוחד כשמבצעים צירופים מרובים מסיביים, חלונות מורכבים או צבירות התנהגותיות בכמה עננים.
תשתמשו במחבר Spark BigQuery כדי לקרוא ישירות את השאילתות המאוחדות של AlloyDB zero-ETL ואת טבלאות Lakehouse, לבצע את הצבירות הווקטוריות הנרחבות באופן מקורי ב-Spark ולכתוב את הפרופיל המאוחד שמתקבל בחזרה ל-BigQuery.
הגדרת הרשאות IAM ל-Managed Service for Apache Spark
כברירת מחדל, Serverless Spark מריץ משימות אצווה באמצעות חשבון השירות שמוגדר כברירת מחדל ב-Compute Engine. לפני ששולחים את העבודה, צריך לתת לחשבון השירות הזה את ההרשאות הנדרשות להפעלת עומס העבודה ולניהול עבודות BigQuery.
(הערה: שם השירות השתנה ל-Managed Service for Apache Spark כדי לשקף את המינוח המקובל בתעשייה, אבל פקודות ה-API ותפקידי ה-IAM הבסיסיים עדיין משתמשים במזהה dataproc).
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
יצירה ושליחה של העבודה
קודם כל, יוצרים את סקריפט העבודה של PySpark. הסקריפט הזה מזהה באופן אוטומטי אם בחרתם באפשרות א' (קטלוג מאוחד של AWS) או באפשרות ב' (Google Cloud Mock) על סמך משתנה הסביבה AWS_PRODUCTS_TABLE, מגדיר את הלוגיקה של Spark SQL ומשתמש במניפולציה של מערכים מקוריים של Spark כדי לחשב את חלונות ה-RFM (העדכניות, התדירות והערך הכספי).
מריצים את הבלוק הבא ב-Cloud Shell.
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
אחרי שהסקריפט מוכן וההגדרות הנדרשות מוזנות באופן דינמי, שולחים את המשימה באצווה אל Managed Apache Spark Serverless.
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
אימות הביצוע של העבודה במסוף
אחרי ששולחים את משימת האצווה, אפשר לוודא שהיא משתמשת במנוע ההרצה המואץ של C++:
- במסוף Google Cloud, עוברים אל Managed Service for Apache Spark > Serverless > Batches.
- לוחצים על העבודה שפועלת כרגע.
- בחלונית פרטי המשרה, מוודאים שהמאפיין Tier מוגדר ל-
Premiumוהמאפיין Engine מוגדר ל-Lightning Engine.
8. ניתוח באמצעות סוכן הנתונים של BigQuery
אחרי שאיחדתם את הנתונים המפוצלים בין העננים והפעלתם את הצבירות הכבדות של נתוני ההתנהגות באמצעות Managed Service for Apache Spark, השלב הבא הוא ניתוח הנתונים.
קודם כל, בודקים את הסכימה של טבלת הפרופילים המאוחדת החדשה בממשק המשתמש של BigQuery כדי להבין באופן ויזואלי את מבנה הנתונים שמוצג לסוכן:
- במסוף Google Cloud, עוברים אל BigQuery.
- בחלונית Explorer שמימין, מרחיבים את הפרויקט ואת מערך הנתונים
demo_lakehouse. - לוחצים על הטבלה
unified_customer_profile. - בוחרים בכרטיסייה Schema (סכימה) בסביבת העבודה הראשית.
בודקים את הסכימה של הטבלה החדשה. העמודה top_preferences היא REPEATED STRUCT (מערך של רשומות שמכילות category, brand ו-sale_price). בדרך כלל, כדי להריץ שאילתות על מערכים מקוננים צריך להשתמש ב-SQL מורכב עם הפונקציה UNNEST(), וזה יכול להיות מסובך לניתוח נתונים עסקיים. התבססות על הטבלה הספציפית הזו מאפשרת לסוכן הנתונים של BigQuery להבין את הסכימה ולטפל בפעולות מורכבות של Google Standard SQL מאחורי הקלעים.
יצירת סוכן נתונים
בקטע הזה תיצרו סוכן נתונים של BigQuery ותפעילו אותו. במקום לכתוב באופן ידני שאילתות SQL מורכבות כדי לבטל את הקינון של מערכים ולחשב מדדים, תוכלו להקצות סוכן AI שמוגדר במיוחד לפרופיל המאוחד החדש שיצרתם, וכך תוכלו לחקור את הנתונים בשפה טבעית.
- בחלונית הניווט הימנית, מאתרים את האפשרות סוכנים ולוחצים עליה.
- לוחצים על + סוכן חדש כדי להפעיל עוזר דיגיטלי חדש מבוסס-AI.
- מגדירים את הסוכן:
- שם הסוכן:
Retail VIP Analysis Agent - מקורות נתונים: לוחצים על הוספת מקור ומחפשים את הטבלה
unified_customer_profile.
- לוחצים על הוספה וממתינים כמה שניות עד שהסוכן יאתחל את סביבת העבודה שלו.
אחרי שהסוכן נוצר, הגדרה של הוראות מערכת מפורשות היא שיטה חשובה למשילות מידע. שימוש בהוראות המערכת כשכבה סמנטית. הטמעת הגדרות עסקיות בכל הארגון, טיפול במורכבויות של סכימות והגדרת אמצעי הגנה אנליטיים מאפשרים להסתיר את המורכבות הטכנית מהמשתמשים הסופיים ולמנוע ממודל ה-LLM להסיק מסקנות מנתונים לא משמעותיים מבחינה סטטיסטית.
מדביקים את הטקסט הבא בשדה Instruction (הוראה):
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
הנחיית הסוכן
מכיוון שהלוגיקה העסקית המורכבת (ההגדרה המדויקת של 'לקוח VIP בסיכון') ודרישות הטיפול בסכימה כפופות באופן מאובטח להוראות המערכת, מנתח הנתונים לא צריך לכתוב הנחיה מפורטת עם תנאים רבים.
בממשק הצ'אט, מזינים את ההנחיה הבאה:
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
הערכת התובנה שנוצרה
אחרי ששולחים את ההנחיה, חשוב לבדוק בקפידה את הפלט שנוצר באופן טבעי כדי להעריך איך סוכן הנתונים של BigQuery אכף את הוראות המערכת, ופעל כשכבה סמנטית מנוהלת וכאמצעי הגנה אנליטי.
קודם קוראים את טקסט הסיכום שנוצר מעל הנתונים. שימו לב איך הסוכן מתרגם באופן אוטומטי את הבקשה הפשוטה שלכם ל'לקוחות VIP בסיכון' לספי מדדים מדויקים שמוגדרים בהוראות המערכת (למשל, הפניה ל-lifetime_value > 100, cart_adds > 0 ו-90 ימים של חוסר פעילות). האישור הזה מעיד שהסוכן הפנים את הלוגיקה העסקית שלכם, כלומר משתמשי הקצה לא צריכים לזכור או לקודד לוגיקה מורכבת בהנחיות היומיות שלהם.
לאחר מכן, מרחיבים את תצוגת ה-SQL כדי לבדוק את הקוד שנוצר. הסוכן צריך ליצור Google Standard SQL תקין מבחינה מתמטית על סמך ההוראות שלכם:
- חלונות זמן דינמיים: מחפשים את חישוב חותמת הזמן בסעיף
WHERE(בדרך כלל באמצעותTIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)). - הקפדה על סכימה: מוודאים שהסוכן פעל לפי כללי הסכימה המחמירים שהגדרתם על ידי החלת הפונקציה
UNNEST()על המערךtop_preferencesבאופן מפורש. כדי לבודד בצורה מדויקת את הקטגוריה הכי נפוצה בכל מדינה, בדרך כלל תראו שימוש בטכניקות מתקדמות כמוROW_NUMBER() OVER()פונקציה אנליטית (window function) בתוך ביטוי טבלה נפוץ (CTE).
בודקים את התרשים ואת טבלת הנתונים שנוצרו באופן אוטומטי. הנתונים יציגו באופן חזותי את שווקי הליבה שלכם לשימור לקוחות (בדרך כלל יופיעו מדינות עם נפח גבוה כמו סין או ארצות הברית) לצד העדפות המוצרים הדומיננטיות שלהם (לרוב "מכנסי ג'ינס"). שימו לב איך ממשק המשתמש המקורי מארגן את הפלט לצריכה מיידית בלי לדרוש קוד ויזואליזציה מפורש.
קוראים את הטקסט של התובנות שנוצר על ידי הסוכן. מכיוון שהגדרתם אמצעי בקרה אנליטיים, כדאי לחפש תובנה שקשורה לאיכות הנתונים או למובהקות סטטיסטית. יכול להיות שהסוכן יסמן באופן מפורש מדינות בתחתית הטבלה עם מספר משתמשים נמוך מאוד (למשל, אזורים עם מספר קטן של משתמשים). במקום להזות קמפיין שיווק ממוקד על סמך נקודה על הגרף אחת, הסוכן יסביר בצורה נכונה שהחריגות האלה לא משמעותיות מבחינה סטטיסטית עבור אסטרטגיה רחבת היקף. ההדגמה הזו מראה איך הטמעה של אמצעי בקרה לממשל ישירות בסוכן מונעת ביעילות טעויות בחישובים עסקיים שמבוססים על AI.
9. יצירת תובנות מ-AI באמצעות Gemini ו-MCP
הסוכן זיהה בהצלחה את קבוצת היעד הדמוגרפית העיקרית: לקוחות VIP בסיכון במדינות ספציפיות. עם זאת, העבודה של אנליסט מסתיימת בתובנה. כדי לעודד את המשתמשים האלה לאינטראקציה חוזרת, צוות השיווק צריך להפעיל קמפיין.
תשתמשו ב-Model Context Protocol (MCP) כדי לחבר עוזר AI חיצוני ישירות לרשימה הדמוגרפית הספציפית הזו ב-BigQuery, ותעברו מניתוח נתונים לפעולה מבוססת-AI בלי ליצור ממשקי API בהתאמה אישית.
הגדרת שרת BigQuery MCP
מריצים את הבלוק שלמטה כדי ליצור את קובץ התצורה mcp.json. הקובץ הזה מספק את פרמטרי החיבור הדרושים כדי ש-Gemini CLI יוכל להתממשק עם BigQuery בצורה בטוחה.
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
יצירת אימייל שיווקי
מפעילים את הכלי Gemini CLI מהטרמינל, ומעבירים במפורש את דגל ההגדרה של MCP כדי לאפשר לו לקרוא את ה-lakehouse של BigQuery.
מריצים את Gemini CLI.
source env.sh
gemini
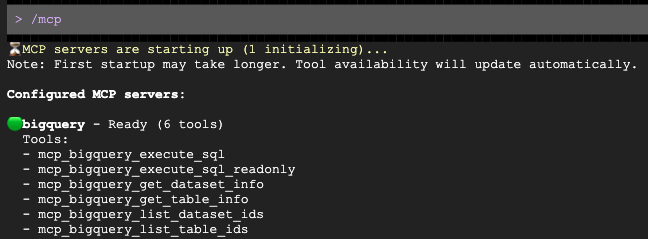
אחרי שפותחים את ההנחיה, מבקשים ממנה לנסח פנייה מותאמת אישית לדמוגרפיה של קהל היעד:
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
Gemini יצור שאילתה אוטומטית ב-BigQuery דרך שרת ה-MCP, יזהה את הנתונים הדמוגרפיים וינסח את האימייל בשבילכם.
10. פינוי מקום בסביבה
כדי להימנע מחיובים שוטפים בחשבון Google Cloud ולאפס את הפרויקט בצורה נקייה לקראת הפעלות עתידיות, צריך למחוק את המשאבים שנוצרו במהלך ה-Codelab הזה.
מריצים את הבלוק הבא כדי ליצור את הסקריפט cleanup.sh. הסקריפט הזה פועל כמנגנון אוטומטי להסרת משאבים, ומסיר לצמיתות את אשכול AlloyDB ואת המופע, את מערכי הנתונים של BigQuery ואת קטגוריית Cloud Storage כדי למנוע חיובים נוספים.
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
מריצים את סקריפט הניקוי כדי למחוק את המשאבים בצורה בטוחה:
bash cleanup.sh
11. מעולה!
יצרתם בהצלחה lakehouse נתונים פתוח חוצה-ענן והרצתם עליו שאילתות.
למדתם:
- איך מאחדים נתונים ממקורות שונים באמצעות BigQuery Zero-ETL ו-Google Cloud Lakehouse.
- איך משתמשים ב-Lightning Engine המקורי של C++ בחיבורים וקטוריים מסיביים של Managed Service for Apache Spark.
- איך משתמשים בסוכן הנתונים של BigQuery כדי לחקור נתונים בשפה טבעית.
- איך מגשרים בין הנתונים ל-Gemini באמצעות Model Context Protocol (MCP) ו-Gemini.