
1. परिचय
इस कोडलैब में, आपको क्रॉस-क्लाउड ओपन डेटा लेकहाउस बनाने का तरीका बताया गया है. यह AWS, Google Cloud, और AlloyDB के डेटा साइलो को एक साथ जोड़ता है. इसके लिए, आपको जटिल ईटीएल की ज़रूरत नहीं होती. आपके पास Lakehouse को सेंट्रल इंटेलिजेंस हब के तौर पर, AlloyDB को ऑपरेशनल डेटा सोर्स के तौर पर, और Managed Service for Apache Spark को हाई-परफ़ॉर्मेंस वेक्टर प्रोसेसिंग के लिए इस्तेमाल करने का विकल्प होगा. आखिर में, आपको Gemini का इस्तेमाल करके अपने लेकहाउस से कारोबार के बारे में अहम जानकारी निकालनी होगी.
मान लें कि आपका लेन-देन से जुड़ा डेटा (users, orders, order items) AlloyDB के ऑपरेशनल डेटाबेस में है, आपका product डेटा AWS S3 बकेट में है, और बड़े पैमाने पर क्लिकस्ट्रीम event logs, Cloud Storage में सेव है. आपको इन डेटासेट को जोड़ना होगा, ताकि अपने अगले मार्केटिंग कैंपेन के लिए टारगेट डेमोग्राफ़िक की पहचान की जा सके. साथ ही, लोगों की दिलचस्पी के हिसाब से आउटरीच ईमेल जनरेट किए जा सकें.
ज़रूरी शर्तें
- आपको एसक्यूएल और टर्मिनल कमांड के बारे में बुनियादी जानकारी होनी चाहिए.
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट.
आपको क्या सीखने को मिलेगा
- BigQuery के ज़ीरो-ईटीएल (AlloyDB) और Apache Iceberg के लिए Lakehouse का इस्तेमाल करके, अलग-अलग डेटा साइलो को इंटिग्रेट करने का तरीका.
- C++ नेटिव लाइटनिंग इंजन की मदद से, Managed Service for Apache Spark का इस्तेमाल करके, व्यवहार की प्रोफ़ाइलिंग से जुड़ा हाई-स्पीड जॉब कैसे चलाया जाता है.
- यूनिफ़ाइड डेटा पर जटिल नैचुरल लैंग्वेज का विश्लेषण करने के लिए, BigQuery डेटा एजेंट का इस्तेमाल कैसे करें.
- Gemini CLI को Apache Iceberg के लिए, Lakehouse से डेटा पढ़ने और मार्केटिंग कॉन्टेंट का ड्राफ़्ट बनाने की अनुमति देने के लिए, मॉडल कॉन्टेक्स्ट प्रोटोकॉल (एमसीपी) को कैसे कॉन्फ़िगर करें.
आपको इन चीज़ों की ज़रूरत होगी
- Google Cloud खाता और Google Cloud प्रोजेक्ट
- कोई वेब ब्राउज़र, जैसे कि Chrome
आपको इन चीज़ों की ज़रूरत होगी
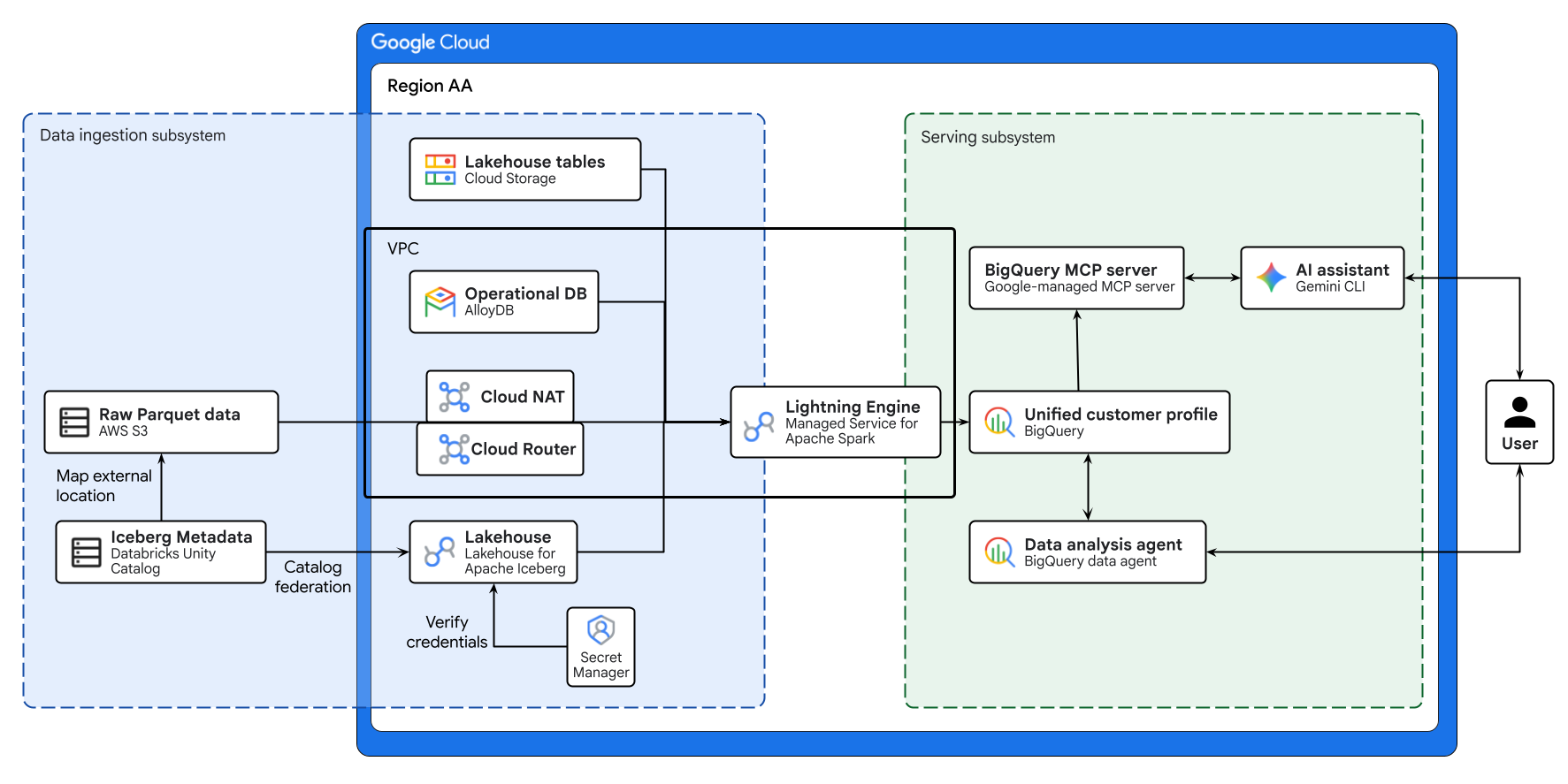
ऊपर दिए गए डायग्राम में, इस कोडलैब में बनाए गए क्रॉस-क्लाउड लेकहाउस का एंड-टू-एंड फ़्लो दिखाया गया है. Lakehouse for Apache Iceberg का इस्तेमाल करके, AlloyDB से ऑपरेशनल डेटा और AWS S3 से रिमोट डेटा को सुरक्षित तरीके से फ़ेडरेट किया जाता है. Managed Service for Apache Spark, इन अलग-अलग सोर्स से मिले डेटा को प्रोसेस करता है, ताकि BigQuery में ग्राहक की एक यूनिफ़ाइड प्रोफ़ाइल बनाई जा सके. आखिर में, BigQuery डेटा एजेंट और Google के मैनेज किए गए BigQuery MCP सर्वर के ज़रिए Gemini सीएलआई, बेहतर डेटा विश्लेषण के लिए एआई पर आधारित इंटरफ़ेस उपलब्ध कराता है.
मुख्य सिद्धांत
- क्रॉस-क्लाउड ओपन डेटा लेकहाउस: यह AWS, Google Cloud, और ऑन-प्रिमाइसेस एनवायरमेंट में मौजूद डेटा साइलो को एक साथ लाता है. इसके लिए, जटिल ईटीएल की ज़रूरत नहीं होती.
- BigQuery में ज़ीरो-ईटीएल: इसकी मदद से, डेटा को एक जगह से दूसरी जगह ले जाए बिना सीधे तौर पर ऑपरेशनल डेटाबेस से क्वेरी की जा सकती है.
- Apache Iceberg के लिए लेकहाउस: Apache Iceberg फ़ॉर्मैट का इस्तेमाल करके, अलग-अलग क्लाउड स्टोरेज में एक जैसी सुरक्षा और गवर्नेंस की सुविधा देता है.
- Lightning Engine: यह C++ नेटिव इंजन है. इसका इस्तेमाल, Apache Spark को बेहतर तरीके से चलाने के लिए किया जाता है.
- मॉडल कॉन्टेक्स्ट प्रोटोकॉल (एमसीपी): यह Gemini को सीधे आपके BigQuery लेकहाउस से कनेक्ट करता है.
2. सेटअप और ज़रूरी शर्तें
Google Cloud प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें.
Cloud Shell शुरू करें
Google Cloud को अपने लैपटॉप से रिमोटली ऐक्सेस किया जा सकता है. हालांकि, इस कोडलैब में Google Cloud Shell का इस्तेमाल किया जाएगा. यह क्लाउड में चलने वाला कमांड लाइन एनवायरमेंट है.
Google Cloud Console में, सबसे ऊपर दाएं कोने में मौजूद टूलबार पर, Cloud Shell आइकॉन पर क्लिक करें:
इसे चालू करने और एनवायरमेंट से कनेक्ट करने में सिर्फ़ कुछ सेकंड लगेंगे. यह प्रोसेस पूरी होने के बाद, आपको कुछ ऐसा दिखेगा:

इस वर्चुअल मशीन में, डेवलपमेंट के लिए ज़रूरी सभी टूल पहले से मौजूद होते हैं. यह 5 जीबी की होम डायरेक्ट्री उपलब्ध कराता है. साथ ही, Google Cloud पर काम करता है. इससे नेटवर्क की परफ़ॉर्मेंस और पुष्टि करने की प्रोसेस बेहतर होती है. इस कोडलैब में मौजूद सभी टास्क, ब्राउज़र में किए जा सकते हैं. आपको कुछ भी इंस्टॉल करने की ज़रूरत नहीं है.
एनवायरमेंट शुरू करें
Cloud Shell खोलें और अपने प्रोजेक्ट के वैरिएबल सेट करें, ताकि यह पक्का किया जा सके कि सभी कमांड सही इंफ़्रास्ट्रक्चर को टारगेट कर रही हैं.
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
अपने चालू सेशन में वैरिएबल लागू करें:
source ./env.sh
एपीआई चालू करना
Google Cloud की ज़रूरी सेवाएं चालू करें.
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3. कोर इन्फ़्रास्ट्रक्चर सेट अप करना
कमज़ोर ईटीएल पाइपलाइन के ज़रिए, सारा डेटा एक ही रिपॉज़िटरी में ले जाने के बजाय, फ़ेडरेटेड क्रॉस-क्लाउड आर्किटेक्चर बनाया जाएगा. असल दुनिया में मौजूद किसी एंटरप्राइज़ में, सिस्टम की अलग-अलग ज़रूरी शर्तों की वजह से डेटा अपने-आप अलग-अलग हिस्सों में बंट जाता है. आपको इन डेटा सोर्स को व्यवस्थित करना होगा:
- AlloyDB (कोर ट्रांज़ैक्शनल डीबी): इसमें उपयोगकर्ताओं, ऑर्डर, और order_items का डेटा सेव होता है. यह एक लाइव ऑपरेशनल डेटाबेस है. यह वित्तीय लेन-देन और प्रोफ़ाइल अपडेट के लिए ज़रूरी ACID प्रॉपर्टी की गारंटी देता है.
- AWS S3 (मास्टर डेटा): इसमें
productsकैटलॉग सेव होता है. AWS पर लेगसी मास्टर डेटा मैनेजमेंट (एमडीएम) सिस्टम को दिखाया गया है. - Google Cloud Storage (बड़ा डेटा लेक): यह
events(क्लिकस्ट्रीम लॉग) सेव करता है. वेब लॉग जैसे ज़्यादा थ्रूपुट वाले डेटा की वजह से, रिलेशनल डेटाबेस क्रैश हो जाएगा. ऑब्जेक्ट स्टोरेज में डेटा को ज़रूरत के हिसाब से बढ़ाया जा सकता है. साथ ही, इसे Google Cloud में रखने से, आपके विश्लेषण इंजन के लिए कंप्यूट लोकैलिटी ज़्यादा से ज़्यादा हो जाती है.
सबसे पहले, नेटवर्क को कॉन्फ़िगर करें. AlloyDB जैसे Google Cloud के मैनेज किए गए डेटाबेस को, आपके प्रोजेक्ट नेटवर्क में सुरक्षित तरीके से कम्यूनिकेट करने के लिए, प्राइवेट वीपीसी पियरिंग कनेक्शन की ज़रूरत होती है.
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
इसके बाद, BigQuery डेटासेट और Lakehouse क्लाउड रिसॉर्स कनेक्शन बनाएं. आर्किटेक्चर के हिसाब से, संसाधन कनेक्शन, डेटा ऐक्सेस करने की अनुमति को Google के मैनेज किए गए सेवा खाते को सौंपता है. इससे, कम से कम ज़रूरी अनुमतियों के सिद्धांत का पालन होता है.
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. ऑपरेशनल डेटाबेस उपलब्ध कराना
AlloyDB का प्राइमरी इंस्टेंस उपलब्ध कराएं और उसमें लेन-देन से जुड़ा मिशन-क्रिटिकल डेटा डालें.
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
डेटाबेस तैयार होने के बाद, आपको AlloyDB से BigQuery का बाहरी कनेक्शन बनाना होगा. यह कनेक्शन, डेटाबेस के क्रेडेंशियल और एंडपॉइंट को सुरक्षित तरीके से सेव करता है. इससे BigQuery, SQL को सीधे तौर पर AlloyDB Compute Engine (ज़ीरो-ईटीएल) पर पुश कर पाता है.
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
लेन-देन की टेबल को सुरक्षित तरीके से AlloyDB में पुश करें. AlloyDB Auth प्रॉक्सी का इस्तेमाल करके, अपने लोकल Cloud Shell सेशन को निजी AlloyDB इंस्टेंस से सुरक्षित तरीके से कनेक्ट करें. इससे आपको स्थानीय कमांड-लाइन टूल का इस्तेमाल करके, लेन-देन का डेटा पुश करने की सुविधा मिलती है.
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5. मास्टर डेटा को फ़ेडरेट करना (AWS स्पोक)
हमारा प्रॉडक्ट कैटलॉग, जिसमें आइटम का रॉ मेटाडेटा होता है, Apache Iceberg टेबल के तौर पर AWS S3 पर सेव होता है. मेटाडेटा को रिमोट कैटलॉग से कंट्रोल किया जाता है.
इस डेटा को Google Cloud में कॉपी करने के लिए, कमज़ोर ईटीएल पाइपलाइन बनाने के बजाय, Lakehouse for Apache Iceberg (REST कैटलॉग फ़ेडरेशन) का इस्तेमाल किया जाएगा.
ज़्यादा डेटा ट्रांसफ़र किए बिना डेटा इंटिग्रेट करने की इस सुविधा की मदद से, Lakehouse और Managed Service for Apache Spark, Iceberg के मेटाडेटा और उससे जुड़ी Parquet फ़ाइलों को सीधे तौर पर आपके रिमोट एनवायरमेंट से खोज और पढ़ सकते हैं.
अगर आपके पास चालू AWS खाता है और Databricks Unity Catalog कॉन्फ़िगर किया गया है, तो उसका इस्तेमाल किया जा सकता है. इसके अलावा, Google Cloud Storage का इस्तेमाल करके अपने एनवायरमेंट को मॉक किया जा सकता है. इनमें से किसी एक को चुनें.
विकल्प A: अपना AWS (नेटिव Apache Iceberg) इस्तेमाल करना
ज़रूरी शर्तें: इस विकल्प के लिए, यह माना जाता है कि आपने पहले ही AWS S3 बकेट को प्रोविज़न कर लिया है. साथ ही, इसे Databricks Unity Catalog में बाहरी लोकेशन के तौर पर कनेक्ट कर लिया है. इसके अलावा, आपने Iceberg टेबल को मैप कर लिया है और पढ़ने के ऐक्सेस के साथ OAuth सेवा प्रिंसिपल जनरेट कर लिया है.
1. क्रेडेंशियल को सुरक्षित तरीके से सेव करना
लंबे समय तक चलने वाले ऐक्सेस टोकन को हार्डकोड करना, आर्किटेक्चर के लिहाज़ से सही नहीं माना जाता. Databricks OAuth क्लाइंट आईडी और सीक्रेट को Google Cloud Secret Manager में सेव किया जाएगा. Lakehouse सेवा, इन टोकन को रनटाइम के दौरान डाइनैमिक तौर पर फ़ेच करेगी, ताकि कम समय के लिए मान्य टोकन बेचे जा सकें. इससे आपके क्रेडेंशियल के इस्तेमाल पर बेहतर तरीके से कंट्रोल किया जा सकेगा.
स्क्रिप्ट जनरेट करने के लिए, इस ब्लॉक को चलाएं. (अभी किसी भी चीज़ में बदलाव न करें).
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
इसके बाद, जनरेट की गई स्क्रिप्ट को अपने-आप खोलने के लिए, यहां दी गई कमांड चलाएं. यह स्क्रिप्ट, आपके टर्मिनल के ऊपर मौजूद विज़ुअल कोड एडिटर में खुलेगी.
cloudshell edit create_secret.sh
- एडिटर में,
<YOUR_...>प्लेसहोल्डर को अपने Databricks के असली क्रेडेंशियल से बदलें. - पक्का करें कि आपके वर्कस्पेस के यूआरएल में
https://या ट्रेलिंग स्लैश (जैसे,123456789.cloud.databricks.com) शामिल न हों. - फ़ाइल सेव करने के लिए,
Ctrl+S(या Mac परCmd+S) दबाएं. - अपने टर्मिनल सेशन पर वापस जाएं और स्क्रिप्ट को एक्ज़ीक्यूट करें:
source create_secret.sh
2. फ़ेडरेटेड कैटलॉग बनाना
इस कोडलैब में, कैटलॉग को कॉन्फ़िगर किया जाएगा, ताकि वह सार्वजनिक इंटरनेट पर सुरक्षित तरीके से काम कर सके. हालांकि, प्रोडक्शन वर्कलोड के लिए, सार्वजनिक इंटरनेट पर बड़े डेटासेट को क्वेरी करने से, डेटा ट्रांसफ़र करने का गैर-ज़रूरी शुल्क लगता है और अनुमान से ज़्यादा समय लगता है. सबसे सही तरीका यह है कि AWS और Google Cloud के बीच एक प्राइवेट क्रॉस-क्लाउड इंटरकनेक्ट (सीसीआई) कॉन्फ़िगर किया जाए. इससे, डेटा ट्रांसफ़र करने की लागत काफ़ी कम हो जाती है और नेटवर्क की परफ़ॉर्मेंस बेहतर होती है.
फ़ेडरेट किए गए लेकहाउस कैटलॉग को प्रोविज़न करने के लिए, gcloud सीएलआई का इस्तेमाल करें:
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. कम से कम विशेषाधिकार वाली IAM बाइंडिंग लागू करें
पिछले चरण में फ़ेडरेटेड कैटलॉग को प्रोविज़न करने पर, Google Cloud Lakehouse ने बैकग्राउंड में रीफ़्रेश करने का काम अपने-आप शुरू कर दिया था. इससे हर 330 सेकंड में Iceberg मेनिफ़ेस्ट सिंक हो जाते हैं.
आपको Lakehouse catalog सेवा खाते को secretAccessor की भूमिका असाइन करनी होगी, ताकि वह बैकग्राउंड में सिंक होने और क्वेरी के एक्ज़ीक्यूशन के दौरान, Databricks OAuth टोकन को सुरक्षित तरीके से फ़ेच कर सके. इस बाइंडिंग के न होने पर, Lakehouse को कैटलॉग अपडेट करते समय 403 गड़बड़ियां दिखेंगी.
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. Managed Service for Apache Spark के लिए, इंटरनेट से बाहर जाने वाले कनेक्शन चालू करना
इसके बाद, Managed Service for Apache Spark, AWS पर मौजूद डेटा को पढ़ेगा. Managed Service for Apache Spark Serverless, बाहरी आईपी पतों के बिना पूरी तरह से प्राइवेट वीपीसी नेटवर्क में काम करता है. इसलिए, यह डिफ़ॉल्ट रूप से इंटरनेट पर AWS S3 तक नहीं पहुंच सकता. आपको Cloud NAT की सुविधा चालू करनी होगी, ताकि Spark वर्कर को आउटबाउंड इंटरनेट ऐक्सेस करने की अनुमति मिल सके.
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. डाउनस्ट्रीम टारगेट तय करना
इस वैरिएबल को एक्सपोर्ट करें, ताकि डाउनस्ट्रीम Apache Spark जॉब को यह पता चल सके कि AWS डेटा को कहां से क्वेरी करना है. इसके लिए, कोड में मैन्युअल तरीके से बदलाव करने की ज़रूरत नहीं होती.
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
विकल्प B: Cloud Storage की मदद से, AWS एनवायरमेंट को मॉक करना
अगर आपके पास चालू AWS खाता नहीं है, तो Google Cloud Storage पर Lakehouse की मैनेज की गई टेबल का इस्तेमाल करके, क्रॉस-क्लाउड साइलो को नेटिव तौर पर सिम्युलेट किया जा सकता है.
1. मॉक आइसबर्ग टेबल बनाना
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. डाउनस्ट्रीम टारगेट तय करना
स्टैंडर्ड BigQuery डेटासेट, तीन हिस्सों वाले नेमस्पेस स्ट्रक्चर (project.dataset.table) का इस्तेमाल करते हैं. इस वैरिएबल को एक्सपोर्ट करें, ताकि डाउनस्ट्रीम Apache Spark जॉब, मॉक डेटा को टारगेट कर सके.
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. इवेंट लॉग को इकट्ठा करना (Google Cloud स्पोक)
क्लिकस्ट्रीम डेटा बहुत तेज़ी से बढ़ता है. आपके पास पूरे, बिना एग्रीगेट किए गए रॉ इवेंट को Cloud Storage में मैनेज की गई लेकहाउस टेबल के तौर पर सेव करने का विकल्प होता है.
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. ग्राहक की यूनीफ़ाइड प्रोफ़ाइल बनाना
कच्चे इंफ़्रास्ट्रक्चर में पूरी जानकारी भरने के बाद, अब समय है कि एक यूनीफ़ाइड ग्राहक प्रोफ़ाइल बनाई जाए.
आपको Lightning Engine की मदद से, Managed Service for Apache Spark का इस्तेमाल करना होगा. Lightning Engine, Google Cloud का हाई-परफ़ॉर्मेंस C++ नेटिव क्वेरी ऐक्सलरेटर है. इसे Apache Gluten और Velox जैसी ओपन-सोर्स टेक्नोलॉजी पर बनाया गया है. यह सीपीयू की परफ़ॉर्मेंस को बेहतर बनाकर और डेटा को स्मार्ट तरीके से कैश करके, अपने-आप एक्ज़ीक्यूशन को बेहतर बनाता है. यह तरीका तब सबसे सही होता है, जब कई क्लाउड पर बड़े पैमाने पर मल्टी-वे जॉइन, जटिल विंडोइंग या व्यवहार से जुड़े एग्रीगेशन किए जा रहे हों.
फ़ेडरेट की गई AlloyDB ज़ीरो-ईटीएल क्वेरी और लेकहाउस टेबल को सीधे तौर पर पढ़ने के लिए, Spark BigQuery कनेक्टर का इस्तेमाल किया जाएगा. साथ ही, Spark में बड़े पैमाने पर वेक्टर वाले एग्रीगेशन किए जाएंगे और यूनीफ़ाइड प्रोफ़ाइल को वापस BigQuery में लिखा जाएगा.
Managed Service for Apache Spark के लिए, IAM अनुमतियां कॉन्फ़िगर करना
डिफ़ॉल्ट रूप से, Serverless Spark, Compute Engine के डिफ़ॉल्ट सेवा खाते का इस्तेमाल करके बैच जॉब को एक्ज़ीक्यूट करता है. जॉब सबमिट करने से पहले, आपको इस सेवा खाते को ज़रूरी अनुमतियां देनी होंगी, ताकि वह वर्कलोड को लागू कर सके और BigQuery जॉब मैनेज कर सके.
(ध्यान दें: इंडस्ट्री के स्टैंडर्ड के हिसाब से नाम रखने के लिए, सेवा का नाम बदलकर Managed Service for Apache Spark कर दिया गया है. हालांकि, एपीआई कमांड और IAM भूमिकाएं अब भी dataproc आइडेंटिफ़ायर का इस्तेमाल करती हैं).
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
नौकरी का विज्ञापन बनाना और उसे सबमिट करना
सबसे पहले, PySpark जॉब स्क्रिप्ट बनाएं. यह स्क्रिप्ट, आपकी AWS_PRODUCTS_TABLE एनवायरमेंट वैरिएबल के आधार पर अपने-आप पता लगाती है कि आपने विकल्प A (AWS फ़ेडरेटेड कैटलॉग) या विकल्प B (Google Cloud मॉक) चुना है. साथ ही, यह Spark SQL लॉजिक को तय करती है और RFM (हाल ही में, फ़्रीक्वेंसी, मॉनेटरी) विंडो का हिसाब लगाने के लिए, Spark के नेटिव ऐरे मैनिपुलेशन का इस्तेमाल करती है.
Cloud Shell में यहां दिया गया ब्लॉक चलाएं.
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
स्क्रिप्ट को पूरी तरह से असेंबल करने और ज़रूरी कॉन्फ़िगरेशन को डाइनैमिक तरीके से इंजेक्ट करने के बाद, बैच जॉब को Managed Apache Spark Serverless पर सबमिट करें.
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
कंसोल में जॉब के एक्ज़ीक्यूट होने की पुष्टि करना
बैच जॉब सबमिट करने के बाद, यह पुष्टि की जा सकती है कि यह ऐक्सेलरेटेड C++ एक्ज़ीक्यूशन इंजन का इस्तेमाल कर रहा है या नहीं:
- Google Cloud console में, Managed Service for Apache Spark > Serverless > बैच पर जाएं.
- फ़िलहाल चल रहे जॉब पर क्लिक करें.
- नौकरी की जानकारी वाले पैनल में, पुष्टि करें कि टियर प्रॉपर्टी
Premiumपर सेट हो और इंजनLightning Engineपर सेट हो.
8. BigQuery डेटा एजेंट की मदद से विश्लेषण करना
आपने अलग-अलग क्लाउड पर मौजूद डेटा को फ़ेडरेट कर लिया है. साथ ही, Managed Service for Apache Spark का इस्तेमाल करके, व्यवहार से जुड़े डेटा को एग्रीगेट कर लिया है. अब अगला चरण डेटा का विश्लेषण करना है.
सबसे पहले, BigQuery के यूज़र इंटरफ़ेस (यूआई) में जाकर, नई बनाई गई यूनिफ़ाइड प्रोफ़ाइल टेबल के स्कीमा की जांच करें. इससे आपको यह समझने में मदद मिलेगी कि एजेंट को कौनसी डेटा स्ट्रक्चर दिख रही है:
- Google Cloud Console में, BigQuery पर जाएं.
- बाईं ओर मौजूद एक्सप्लोरर पैनल में, अपने प्रोजेक्ट और
demo_lakehouseडेटासेट को बड़ा करें. unified_customer_profileटेबल पर क्लिक करें.- मुख्य वर्कस्पेस में, स्कीमा टैब चुनें.
नई टेबल का स्कीमा देखें. top_preferences कॉलम एक REPEATED STRUCT है. यह category, brand, और sale_price वाले रिकॉर्ड का कलेक्शन होता है. आम तौर पर, नेस्ट किए गए कलेक्शन के लिए क्वेरी करने के लिए, UNNEST() फ़ंक्शन का इस्तेमाल करके कॉम्प्लेक्स एसक्यूएल की ज़रूरत होती है. यह कारोबार के विश्लेषकों के लिए एक मुश्किल काम हो सकता है. BigQuery डेटा एजेंट को इस टेबल के बारे में जानकारी देने से, एजेंट को स्कीमा के बारे में अपने-आप पता चल जाता है. साथ ही, वह Google Standard SQL की मुश्किल कार्रवाइयों को पर्दे के पीछे हैंडल करता है.
डेटा एजेंट बनाना
इस सेक्शन में, BigQuery डेटा एजेंट बनाया जाएगा और उसके साथ इंटरैक्ट किया जाएगा. ऐरे को अननेस्ट करने और मेट्रिक का हिसाब लगाने के लिए, मैन्युअल तरीके से मुश्किल एसक्यूएल लिखने के बजाय, आपको एक एआई एजेंट उपलब्ध कराया जाएगा. यह एजेंट, खास तौर पर आपकी नई यूनीफ़ाइड प्रोफ़ाइल के लिए होगा. इससे नैचुरल लैंग्वेज में डेटा एक्सप्लोर किया जा सकेगा.
- बाएं नेविगेशन पैनल में, एजेंट ढूंढें और उस पर क्लिक करें.
- नया एआई असिस्टेंट शुरू करने के लिए, + नया एजेंट पर क्लिक करें.
- एजेंट को कॉन्फ़िगर करें:
- एजेंट का नाम:
Retail VIP Analysis Agent - डेटा सोर्स: सोर्स जोड़ें पर क्लिक करें. इसके बाद,
unified_customer_profileटेबल खोजें.
- जोड़ें पर क्लिक करें. इसके बाद, एजेंट के फ़ाइल फ़ोल्डर को शुरू होने में कुछ सेकंड लगेंगे.
एजेंट सेट अप हो जाने के बाद, साफ़ तौर पर सिस्टम के निर्देश तय करना, डेटा गवर्नेंस की एक अहम प्रोसेस है. सिस्टम के निर्देशों को सिमैंटिक लेयर के तौर पर इस्तेमाल करें. एंटरप्राइज़-वाइड कारोबार की परिभाषाएं एम्बेड करके, स्कीमा की जटिलताओं को मैनेज करके, और विश्लेषण के लिए दिशा-निर्देश तय करके, तकनीकी जटिलता को असली उपयोगकर्ता से दूर किया जा सकता है. साथ ही, एलएलएम को ऐसे डेटा से नतीजे निकालने से रोका जा सकता है जो आंकड़ों के हिसाब से अहम नहीं है.
निर्देश फ़ील्ड में यह चिपकाएं:
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
एजेंट को प्रॉम्प्ट देना
कारोबार के जटिल लॉजिक ("At-Risk VIP" की सटीक परिभाषा) और स्कीमा हैंडलिंग से जुड़ी ज़रूरी शर्तों को सिस्टम के निर्देशों के तहत सुरक्षित तरीके से मैनेज किया जाता है. इसलिए, डेटा विश्लेषक को ज़्यादा शब्दों वाला और शर्तों से भरा प्रॉम्प्ट लिखने की ज़रूरत नहीं होती.
चैट इंटरफ़ेस में, यह प्रॉम्प्ट डालें:
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
जनरेट की गई इनसाइट का आकलन करना
प्रॉम्प्ट सबमिट करने के बाद, नेटिव तौर पर जनरेट किए गए आउटपुट की ध्यान से समीक्षा करें. इससे आपको यह पता चलेगा कि BigQuery डेटा एजेंट ने आपके सिस्टम निर्देशों को कैसे लागू किया. साथ ही, यह भी पता चलेगा कि यह एक नियंत्रित सिमैंटिक लेयर और विश्लेषण से जुड़ी गाइडलाइन, दोनों के तौर पर कैसे काम करता है.
सबसे पहले, डेटा के ऊपर जनरेट किया गया खास जानकारी वाला टेक्स्ट पढ़ें. ध्यान दें कि एजेंट, "जोखिम में मौजूद वीआईपी" के आपके सामान्य अनुरोध को, सिस्टम के निर्देशों में तय की गई मेट्रिक थ्रेशोल्ड में अपने-आप कैसे बदल देता है. उदाहरण के लिए, lifetime_value > 100, cart_adds > 0 और 90 दिनों तक गतिविधि न होने का रेफ़रंस देना. इससे पुष्टि होती है कि एजेंट ने आपके कारोबार के लॉजिक को समझ लिया है. इसका मतलब है कि असली उपयोगकर्ताओं को रोज़ाना के प्रॉम्प्ट में, मुश्किल लॉजिक को याद रखने या हार्डकोड करने की ज़रूरत नहीं होती.
इसके बाद, जनरेट किए गए कोड की जांच करने के लिए, SQL व्यू को बड़ा करें. एजेंट को आपके निर्देशों के आधार पर, गणित के हिसाब से सही Google स्टैंडर्ड एसक्यूएल बनाना चाहिए:
- डाइनैमिक टाइम विंडो:
WHEREक्लॉज़ में टाइमस्टैंप कैलकुलेशन देखें. आम तौर पर, इसके लिएTIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)का इस्तेमाल किया जाता है. - स्कीमा के नियमों का सख्ती से पालन करना: पुष्टि करें कि एजेंट ने स्कीमा के नियमों का सख्ती से पालन किया है. इसके लिए,
top_preferencesकलेक्शन परUNNEST()फ़ंक्शन को साफ़ तौर पर लागू किया गया हो. हर देश के लिए सबसे ज़्यादा बार इस्तेमाल की गई कैटगरी का सटीक पता लगाने के लिए, आम तौर पर इसमेंROW_NUMBER() OVER()विंडो फ़ंक्शन जैसी ऐडवांस तकनीकों का इस्तेमाल किया जाता है. यह फ़ंक्शन, कॉमन टेबल एक्सप्रेशन (सीटीई) के अंदर होता है.
अपने-आप रेंडर हुए चार्ट और डेटा टेबल की समीक्षा करें. डेटा से आपको उन मुख्य देशों के बारे में पता चलेगा जहां खरीदार आपके प्रॉडक्ट में दिलचस्पी दिखाते हैं. आम तौर पर, इसमें चीन या अमेरिका जैसे ज़्यादा आबादी वाले देशों को हाइलाइट किया जाता है. साथ ही, इसमें उन देशों में सबसे ज़्यादा पसंद किए जाने वाले प्रॉडक्ट (जैसे, "जींस") के बारे में भी जानकारी मिलती है. ध्यान दें कि नेटिव यूज़र इंटरफ़ेस (यूआई), आउटपुट को तुरंत इस्तेमाल करने के लिए कैसे स्ट्रक्चर करता है. इसके लिए, विज़ुअलाइज़ेशन कोड की ज़रूरत नहीं होती.
एजेंट की ओर से जनरेट किए गए, बुलेट वाले अहम जानकारी टेक्स्ट को पढ़ें. आपने विश्लेषण से जुड़े दिशा-निर्देश तय किए हैं. इसलिए, खास तौर पर डेटा क्वालिटी या आंकड़ों के हिसाब से अहम जानकारी खोजें. आपको टेबल में सबसे नीचे, एजेंट के उन देशों को साफ़ तौर पर फ़्लैग करते हुए दिख सकता है जहां उपयोगकर्ताओं की संख्या बहुत कम है. उदाहरण के लिए, ऐसे इलाके जहां सिर्फ़ कुछ उपयोगकर्ता हैं. एजेंट, सिर्फ़ एक डेटा पॉइंट के आधार पर टारगेट किए गए मार्केटिंग कैंपेन के बारे में गलत जानकारी देने के बजाय, यह सही सलाह देगा कि ये अनियमितताएं, बड़े पैमाने पर लागू की जाने वाली रणनीति के लिए आंकड़ों के हिसाब से अहम नहीं हैं. इससे पता चलता है कि एआई एजेंट में सीधे तौर पर गवर्नेंस के सिद्धांतों को शामिल करने से, एआई की मदद से कारोबार से जुड़ी गलत कैलकुलेशन को कैसे रोका जा सकता है.
9. Gemini और एमसीपी की मदद से, एआई से मिली अहम जानकारी जनरेट करना
एजेंट ने मुख्य टारगेट डेमोग्राफ़िक की पहचान कर ली है: कुछ देशों में वीआईपी के तौर पर शामिल ऐसे लोग जो जोखिम में हैं. हालांकि, किसी विश्लेषक का काम इनसाइट पर खत्म हो जाता है. इन उपयोगकर्ताओं को फिर से जोड़ने के लिए, मार्केटिंग टीम को एक कैंपेन चलाना होगा.
आपको मॉडल कॉन्टेक्स्ट प्रोटोकॉल (एमसीपी) का इस्तेमाल करके, बाहरी एआई असिस्टेंट को सीधे तौर पर BigQuery में मौजूद इस डेमोग्राफ़िक लिस्ट से कनेक्ट करना होगा. इससे, डेटा विश्लेषण से लेकर एआई की मदद से कार्रवाई करने तक का काम आसानी से किया जा सकेगा. इसके लिए, आपको कस्टम एपीआई बनाने की ज़रूरत नहीं होगी.
BigQuery MCP सर्वर को कॉन्फ़िगर करना
mcp.json कॉन्फ़िगरेशन फ़ाइल जनरेट करने के लिए, नीचे दिए गए ब्लॉक को चलाएं. यह फ़ाइल, कनेक्शन के ज़रूरी पैरामीटर उपलब्ध कराती है, ताकि Gemini CLI, BigQuery के साथ सुरक्षित तरीके से इंटरफ़ेस कर सके.
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
मार्केटिंग ईमेल जनरेट करना
अपने टर्मिनल से Gemini CLI टूल शुरू करें. साथ ही, MCP कॉन्फ़िगरेशन फ़्लैग को साफ़ तौर पर पास करें, ताकि यह आपके BigQuery लेकहाउस को पढ़ सके.
Gemini CLI चलाएं.
source env.sh
gemini
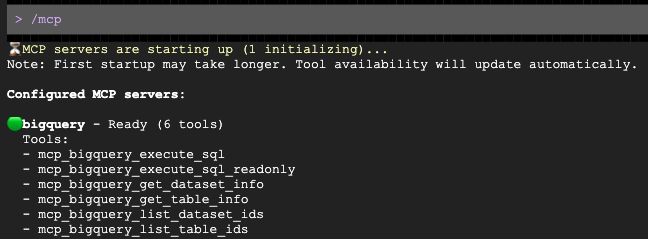
प्रॉम्प्ट खुलने के बाद, उससे अपनी टारगेट डेमोग्राफ़िक के हिसाब से, लोगों तक पहुंचने के लिए एक ईमेल का ड्राफ़्ट बनाने के लिए कहें:
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
Gemini, एमसीपी सर्वर के ज़रिए BigQuery से अपने-आप क्वेरी करेगा, डेमोग्राफ़िक की पहचान करेगा, और आपके लिए ईमेल का ड्राफ़्ट तैयार करेगा!
10. अपने एनवायरमेंट को क्लीन अप करना
अपने Google Cloud खाते से लगातार शुल्क लिए जाने से बचने और आने वाले समय में प्रोजेक्ट को फिर से शुरू करने के लिए, आपको इस कोडलैब के दौरान बनाई गई सभी संसाधन मिटाने होंगे.
cleanup.sh स्क्रिप्ट बनाने के लिए, इस ब्लॉक को चलाएं. यह स्क्रिप्ट, अपने-आप काम करने वाले सिस्टम की तरह काम करती है. इससे AlloyDB क्लस्टर और इंस्टेंस, BigQuery डेटासेट, और Cloud Storage बकेट को हमेशा के लिए हटा दिया जाता है, ताकि आगे होने वाली बिलिंग को रोका जा सके.
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
अपने संसाधनों को सुरक्षित तरीके से मिटाने के लिए, क्लीनअप स्क्रिप्ट चलाएं:
bash cleanup.sh
11. बधाई हो!
आपने अलग-अलग क्लाउड पर मौजूद ओपन डेटा लेकहाउस को सफलतापूर्वक बनाया और उससे क्वेरी की.
आपने सीखा:
- BigQuery Zero-ETL और Google Cloud Lakehouse का इस्तेमाल करके, अलग-अलग सोर्स से डेटा को फ़ेडरेट करने का तरीका.
- Managed Service for Apache Spark में, बड़े पैमाने पर वेक्टर किए गए जॉइन में C++ नेटिव लाइटनिंग इंजन का इस्तेमाल कैसे करें.
- नैचुरल लैंग्वेज एक्सप्लोरेशन के लिए, BigQuery डेटा एजेंट का इस्तेमाल कैसे करें.
- मॉडल कॉन्टेक्स्ट प्रोटोकॉल (एमसीपी) और Gemini का इस्तेमाल करके, अपने डेटा को Gemini से कैसे कनेक्ट करें.
आगे क्या करना है?
- Lakehouse के दस्तावेज़ देखें
- AlloyDB से BigQuery में ज़ीरो-ईटीएल के बारे में ज़्यादा जानें
- Lightning Engine के बारे में पढ़ें