
1. Pengantar
Dalam codelab ini, Anda akan membangun data lakehouse terbuka lintas cloud yang menyatukan silo data di AWS, Google Cloud, dan AlloyDB tanpa memerlukan ETL yang rumit. Anda akan menggunakan Lakehouse sebagai hub kecerdasan pusat, AlloyDB sebagai sumber data operasional, dan Managed Service for Apache Spark untuk pemrosesan tervektorisasi berperforma tinggi. Terakhir, Anda akan menggunakan Gemini untuk mendapatkan insight bisnis yang efektif dari lakehouse Anda.
Bayangkan data transaksi Anda (users, orders, order items) berada di database AlloyDB operasional, data product Anda berada di bucket AWS S3, dan event logs clickstream yang sangat besar disimpan di Cloud Storage. Anda perlu menggabungkan set data ini untuk mengidentifikasi demografi target untuk kampanye pemasaran berikutnya dan membuat email penjangkauan yang dipersonalisasi.
Prasyarat
- Pemahaman tentang perintah SQL dan terminal dasar.
- Project Google Cloud yang mengaktifkan penagihan.
Yang akan Anda pelajari
- Cara mengintegrasikan silo data yang berbeda menggunakan BigQuery zero-ETL (AlloyDB) dan Lakehouse untuk Apache Iceberg.
- Cara menjalankan tugas pembuatan profil perilaku berkecepatan tinggi menggunakan Managed Service untuk Apache Spark yang didukung oleh Lightning Engine native C++.
- Cara menggunakan agen data BigQuery untuk melakukan analisis bahasa alami yang kompleks pada data terpadu.
- Cara mengonfigurasi Model Context Protocol (MCP) agar Gemini CLI dapat membaca dari Lakehouse for Apache Iceberg dan membuat draf konten pemasaran.
Yang Anda butuhkan
- Akun Google Cloud dan Project Google Cloud
- Browser web seperti Chrome
Yang Anda butuhkan
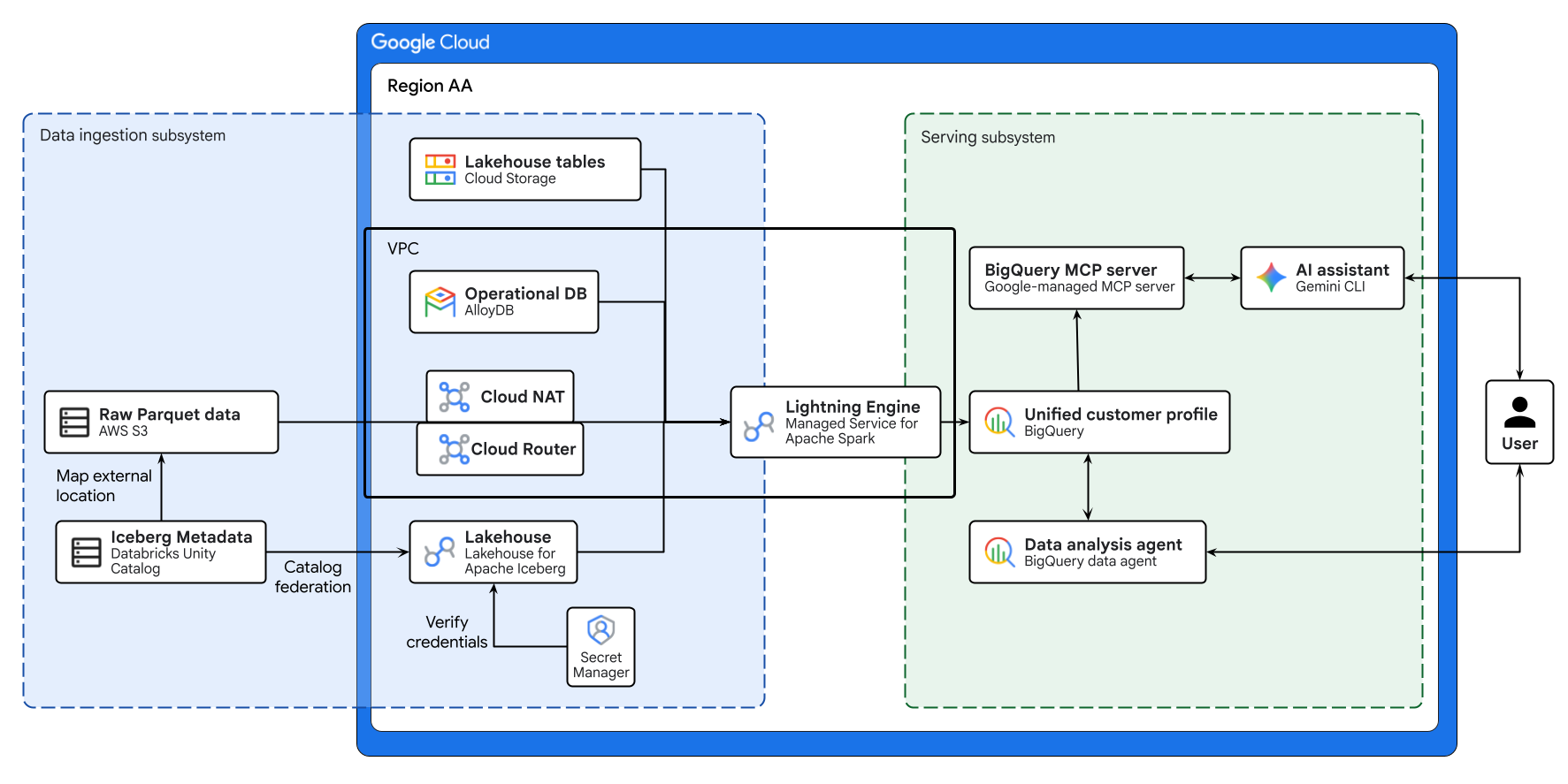
Diagram di atas mengilustrasikan alur end-to-end cross-cloud lakehouse yang dibangun dalam codelab ini. Data operasional dari AlloyDB dan data jarak jauh dari AWS S3 digabungkan secara aman menggunakan Lakehouse untuk Apache Iceberg. Managed Service for Apache Spark memproses berbagai sumber yang berbeda ini untuk membuat profil pelanggan terpadu di BigQuery. Terakhir, Agen Data BigQuery dan server MCP BigQuery yang dikelola Google melalui Gemini CLI menyediakan antarmuka intuitif yang didukung AI untuk analisis data tingkat lanjut.
Konsep utama
- Lakehouse data terbuka lintas cloud: Menyatukan data silo di seluruh lingkungan AWS, Google Cloud, dan lokal tanpa memerlukan ETL yang kompleks.
- BigQuery zero-ETL: Memungkinkan pembuatan kueri langsung pada database operasional tanpa pemindahan data yang rumit.
- Lakehouse untuk Apache Iceberg: Memungkinkan keamanan dan tata kelola yang konsisten di seluruh penyimpanan lintas cloud menggunakan format Apache Iceberg.
- Lightning Engine: Mesin native C++ untuk eksekusi Apache Spark berperforma tinggi.
- Model Context Protocol (MCP): Menghubungkan Gemini langsung ke lakehouse BigQuery Anda.
2. Penyiapan dan persyaratan
Membuat Project Google Cloud
- Di Konsol Google Cloud, di halaman pemilih project, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda. Pelajari cara memeriksa apakah penagihan telah diaktifkan pada suatu project.
Mulai Cloud Shell
Meskipun Google Cloud dapat dioperasikan dari jarak jauh menggunakan laptop Anda, dalam codelab ini, Anda akan menggunakan Google Cloud Shell, lingkungan command line yang berjalan di Cloud.
Dari Google Cloud Console, klik ikon Cloud Shell di toolbar kanan atas:
Hanya perlu waktu beberapa saat untuk penyediaan dan terhubung ke lingkungan. Jika sudah selesai, Anda akan melihat tampilan seperti ini:

Mesin virtual ini berisi semua alat pengembangan yang Anda perlukan. Layanan ini menawarkan direktori beranda tetap sebesar 5 GB dan beroperasi di Google Cloud, sehingga sangat meningkatkan performa dan autentikasi jaringan. Semua pekerjaan Anda dalam codelab ini dapat dilakukan di browser. Anda tidak perlu menginstal apa pun.
Lakukan inisialisasi lingkungan
Buka Cloud Shell dan tetapkan variabel project Anda untuk memastikan semua perintah menargetkan infrastruktur yang benar.
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
Terapkan variabel ke sesi aktif Anda:
source ./env.sh
Aktifkan API
Aktifkan layanan Google Cloud yang diperlukan.
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3. Menyiapkan infrastruktur inti
Alih-alih memindahkan semua data ke satu repositori melalui pipeline ETL yang rentan, Anda akan membangun arsitektur lintas cloud gabungan. Di perusahaan dunia nyata, data secara inheren terfragmentasi karena persyaratan sistem yang berbeda. Anda akan mengatur sumber data berikut:
- AlloyDB (DB transaksional inti): Menyimpan data pengguna, pesanan, dan item_pesanan. Sebagai database operasional aktif, database ini menjamin properti ACID yang diperlukan untuk transaksi keuangan dan pembaruan profil.
- AWS S3 (Data master): Menyimpan katalog
products. Merepresentasikan sistem pengelolaan data master (MDM) lama di AWS. - Google Cloud Storage (Data lake besar): Menyimpan
events(log clickstream). Data throughput tinggi seperti log web akan membuat database relasional error. Penyimpanan objek memberikan skalabilitas tanpa batas, dan menyimpannya di Google Cloud memaksimalkan lokalitas komputasi untuk mesin analisis Anda.
Pertama, konfigurasi jaringan yang mendasarinya. Database terkelola Google Cloud seperti AlloyDB memerlukan koneksi peering VPC pribadi untuk berkomunikasi dengan aman dalam jaringan project Anda.
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
Selanjutnya, buat set data BigQuery dan koneksi resource cloud Lakehouse. Secara arsitektur, koneksi resource mendelegasikan akses data ke akun layanan khusus yang dikelola Google, dengan menerapkan prinsip hak istimewa terendah.
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. Menyediakan database operasional
Sediakan instance utama AlloyDB dan masukkan data transaksional penting Anda.
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
Setelah database siap, Anda harus membuat koneksi eksternal BigQuery ke AlloyDB. Koneksi ini menyimpan kredensial dan endpoint database dengan aman, sehingga BigQuery dapat mendorong eksekusi SQL langsung ke mesin komputasi AlloyDB (zero-ETL).
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
Dorong tabel transaksional ke AlloyDB dengan aman. Gunakan Proxy Auth AlloyDB untuk menghubungkan sesi Cloud Shell lokal Anda secara aman ke instance AlloyDB pribadi. Dengan begitu, Anda dapat mengirimkan data transaksional menggunakan alat command line lokal.
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5. Gabungkan data master (spoke AWS)
Katalog produk kami, yang berisi metadata item mentah, secara native berada di AWS S3 sebagai tabel Apache Iceberg. Metadata diatur oleh katalog jarak jauh.
Alih-alih membangun pipeline ETL yang rentan untuk menyalin data ini ke Google Cloud, Anda akan menggunakan Lakehouse untuk Apache Iceberg (federasi katalog REST).
Pendekatan tanpa ETL ini memungkinkan Lakehouse dan Managed Service for Apache Spark menemukan dan membaca metadata Iceberg serta file Parquet yang mendasarinya secara dinamis langsung dari lingkungan jarak jauh Anda.
Jika Anda memiliki akun AWS yang aktif dan Databricks Unity Catalog yang dikonfigurasi, Anda dapat menggunakannya. Atau, Anda dapat meniru lingkungan menggunakan Google Cloud Storage. Pilih salah satu.
Opsi A: Bawa AWS Anda sendiri (Apache Iceberg Native)
Prasyarat: Opsi ini mengasumsikan bahwa Anda telah menyediakan bucket AWS S3, menghubungkannya sebagai lokasi eksternal di Databricks Unity Catalog, memetakan tabel Iceberg, dan membuat prinsipal layanan OAuth dengan akses baca.
1. Penyimpanan kredensial yang aman
Meng-hardcode token akses yang memiliki masa aktif yang lama adalah anti-pola arsitektur. Anda akan menyimpan ID dan rahasia klien OAuth Databricks di Google Cloud Secret Manager. Layanan Lakehouse akan mengambilnya secara dinamis saat runtime untuk menjual token berjangka pendek, sehingga memusatkan tata kelola kredensial Anda.
Jalankan blok berikut untuk membuat skrip. (Jangan edit apa pun dulu).
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
Kemudian, jalankan perintah berikut untuk membuka skrip yang dihasilkan secara otomatis di editor kode visual di atas terminal Anda.
cloudshell edit create_secret.sh
- Di editor, ganti placeholder
<YOUR_...>dengan kredensial Databricks Anda yang sebenarnya. - Pastikan URL ruang kerja Anda tidak menyertakan
https://atau garis miring di akhir (misalnya,123456789.cloud.databricks.com). - Tekan
Ctrl+S(atauCmd+Sdi Mac) untuk menyimpan file. - Kembali ke sesi terminal Anda dan jalankan skrip:
source create_secret.sh
2. Buat katalog gabungan
Agar lebih sederhana dalam codelab ini, Anda akan mengonfigurasi katalog untuk menjelajahi internet publik secara aman. Namun, untuk beban kerja produksi, mengkueri set data besar melalui internet publik akan menimbulkan biaya keluar yang tidak perlu dan latensi yang tidak dapat diprediksi. Praktik terbaik mengharuskan konfigurasi Cross-Cloud Interconnect (CCI) pribadi antara AWS dan Google Cloud, yang secara signifikan mengurangi biaya keluar dan memastikan performa jaringan yang deterministik.
Gunakan gcloud CLI untuk menyediakan katalog Lakehouse gabungan:
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. Menerapkan Binding IAM Hak Istimewa Terendah
Saat Anda menyediakan katalog gabungan pada langkah sebelumnya, Google Cloud Lakehouse secara otomatis meluncurkan tugas refresh di latar belakang untuk menyinkronkan manifes Iceberg setiap 330 detik.
Anda harus memberikan peran secretAccessor ke akun layanan katalog Lakehouse agar dapat mengambil token OAuth Databricks secara aman selama sinkronisasi latar belakang dan eksekusi kueri ini. Jika binding ini tidak ada, error 403 akan terjadi secara diam-diam saat Lakehouse mencoba memperbarui katalog.
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. Mengaktifkan Internet Keluar untuk Managed Service for Apache Spark
Pada langkah berikutnya, Managed Service untuk Apache Spark akan membaca data AWS jarak jauh. Karena Managed Service for Apache Spark Serverless berjalan sepenuhnya dalam jaringan VPC pribadi tanpa alamat IP eksternal, secara default, layanan ini tidak dapat menjangkau AWS S3 melalui internet. Anda harus menyediakan Cloud NAT untuk mengizinkan akses internet keluar bagi pekerja Spark.
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. Menentukan target hilir
Ekspor variabel ini agar tugas Apache Spark hilir mengetahui persis tempat untuk membuat kueri data AWS tanpa memerlukan perubahan kode manual.
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
Opsi B: Lingkungan AWS tiruan melalui Cloud Storage
Jika tidak memiliki akun AWS yang aktif, Anda dapat mensimulasikan silo lintas cloud secara native menggunakan tabel terkelola Lakehouse di Google Cloud Storage.
1. Buat tabel Iceberg tiruan
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. Menentukan target hilir
Set data BigQuery standar menggunakan struktur namespace 3 bagian (project.dataset.table). Ekspor variabel ini sehingga tugas Apache Spark hilir menargetkan data tiruan.
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. Menyerap log peristiwa (spoke Google Cloud)
Data clickstream berkembang secara eksponensial. Anda menyimpan peristiwa mentah yang lengkap dan tidak diagregasi secara lokal di Cloud Storage sebagai tabel Managed Lakehouse.
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. Membangun profil pelanggan terpadu
Setelah infrastruktur mentah Anda terisi sepenuhnya, saatnya membangun profil pelanggan terpadu.
Anda akan menggunakan Managed Service untuk Apache Spark yang didukung oleh Lightning Engine. Lightning Engine adalah akselerator kueri native C++ berperforma tinggi dari Google Cloud, yang dibangun di atas teknologi open source seperti Apache Gluten dan Velox, yang secara otomatis meningkatkan eksekusi dengan memaksimalkan efisiensi CPU dan melakukan caching data secara cerdas. Pendekatan ini ideal saat melakukan penggabungan multi-arah yang besar, windowing yang kompleks, atau agregasi perilaku di beberapa cloud.
Anda akan menggunakan konektor Spark BigQuery untuk membaca langsung kueri gabungan zero-ETL AlloyDB dan tabel Lakehouse, melakukan agregasi vektorisasi besar-besaran secara native di Spark, dan menulis profil terpadu yang dihasilkan kembali ke BigQuery.
Mengonfigurasi Izin IAM untuk Managed Service for Apache Spark
Secara default, Serverless Spark menjalankan tugas batch menggunakan akun layanan default Compute Engine. Sebelum mengirimkan tugas, Anda harus memberikan izin yang diperlukan ke akun layanan ini untuk menjalankan beban kerja dan mengelola tugas BigQuery.
(Catatan: Meskipun nama layanan telah berubah menjadi Managed Service for Apache Spark untuk mencerminkan terminologi standar industri, perintah API dan peran IAM yang mendasarinya masih menggunakan ID dataproc).
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
Membuat dan mengirimkan tugas
Pertama, buat skrip tugas PySpark. Skrip ini otomatis mendeteksi apakah Anda memilih Opsi A (AWS Federated Catalog) atau Opsi B (Google Cloud Mock) berdasarkan variabel lingkungan AWS_PRODUCTS_TABLE, menentukan logika Spark SQL, dan menggunakan manipulasi array native Spark untuk menghitung rentang RFM (recency, frequency, monetary).
Jalankan blok berikut di Cloud Shell.
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
Setelah skrip dirakit sepenuhnya dan konfigurasi yang diperlukan dimasukkan secara dinamis, kirimkan tugas batch ke Managed Apache Spark Serverless.
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
Memverifikasi eksekusi tugas di konsol
Setelah tugas batch dikirimkan, Anda dapat memverifikasi bahwa tugas tersebut menggunakan mesin eksekusi C++ yang dipercepat:
- Di konsol Google Cloud, buka Managed Service for Apache Spark > Serverless > Batches.
- Klik tugas yang sedang berjalan.
- Di panel detail tugas, pastikan properti Tier disetel ke
Premiumdan Engine disetel keLightning Engine.
8. Menganalisis dengan agen data BigQuery
Setelah Anda menggabungkan data lintas cloud yang terfragmentasi dan menjalankan agregasi perilaku yang berat menggunakan Managed Service untuk Apache Spark, langkah berikutnya adalah analisis data.
Pertama, periksa skema tabel profil terpadu yang baru dibuat di UI BigQuery untuk memahami struktur data yang Anda ekspos ke agen secara visual:
- Di konsol Google Cloud, buka BigQuery.
- Di panel Explorer di sebelah kiri, luaskan project dan set data
demo_lakehouse. - Klik tabel
unified_customer_profile. - Pilih tab Skema di ruang kerja utama.
Periksa skema tabel baru. Kolom top_preferences adalah REPEATED STRUCT (array rekaman yang berisi category, brand, dan sale_price). Biasanya, membuat kueri array bertingkat memerlukan SQL yang kompleks menggunakan fungsi UNNEST(), yang dapat menjadi hambatan bagi analis bisnis. Dengan mendasarkan agen data BigQuery pada tabel tertentu ini, agen secara inheren memahami skema dan menangani operasi Google Standard SQL yang kompleks di balik layar.
Buat agen data
Di bagian ini, Anda akan membuat dan berinteraksi dengan agen data BigQuery. Daripada menulis SQL yang kompleks secara manual untuk mengurai array dan menghitung metrik, Anda akan menyediakan agen AI yang dicakup secara khusus untuk profil terpadu yang baru dibuat, sehingga memungkinkan eksplorasi data bahasa alami.
- Di panel navigasi kiri, cari dan klik Agen.
- Klik + Agen Baru untuk menginisialisasi asisten AI baru.
- Mengonfigurasi Agen:
- Nama Agen:
Retail VIP Analysis Agent - Sumber Data: Klik Tambahkan Sumber, lalu telusuri tabel
unified_customer_profile.
- Klik Add dan tunggu beberapa detik hingga Agen menginisialisasi ruang kerjanya.
Setelah agen dibuat, menentukan Petunjuk Sistem eksplisit adalah praktik tata kelola data yang penting. Menggunakan Petunjuk Sistem sebagai Lapisan Semantik. Dengan menyematkan definisi bisnis di seluruh perusahaan, menangani kompleksitas skema, dan menetapkan batas aman analitis, Anda dapat menyederhanakan kompleksitas teknis bagi pengguna akhir dan mencegah LLM menarik kesimpulan dari data yang tidak signifikan secara statistik.
Tempelkan perintah berikut ke kolom Instruction:
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
Memberi perintah agen
Karena logika bisnis yang kompleks (definisi persis "VIP Berisiko") dan persyaratan penanganan skema diatur dengan aman oleh Petunjuk Sistem, analis data tidak perlu menulis perintah yang panjang dan penuh kondisi.
Di antarmuka chat, masukkan perintah berikut:
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
Mengevaluasi insight yang dihasilkan
Setelah mengirimkan perintah, tinjau dengan cermat output yang dibuat secara native untuk mengevaluasi cara Agen Data BigQuery menerapkan Petunjuk Sistem Anda, yang bertindak sebagai lapisan semantik yang diatur dan batas pengamanan analitis.
Pertama, baca teks ringkasan yang dibuat di atas data. Perhatikan bagaimana agen secara otomatis menerjemahkan permintaan sederhana Anda untuk "VIP Berisiko" ke dalam nilai minimum metrik yang tepat yang ditentukan dalam Petunjuk Sistem Anda (misalnya, merujuk lifetime_value > 100, cart_adds > 0, dan 90 hari tidak aktif). Hal ini mengonfirmasi bahwa agen telah menginternalisasi logika bisnis Anda, yang berarti pengguna akhir tidak perlu menghafal atau meng-hardcode logika yang kompleks dalam perintah sehari-hari mereka.
Selanjutnya, luaskan tampilan SQL untuk memeriksa kode yang dihasilkan. Agen harus membuat Google Standard SQL yang benar secara matematis berdasarkan petunjuk Anda:
- Rentang Waktu Dinamis: Cari penghitungan stempel waktu dalam klausa
WHERE(biasanya menggunakanTIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)). - Kepatuhan Skema yang Ketat: Konfirmasi bahwa agen mematuhi aturan skema ketat Anda dengan menerapkan fungsi
UNNEST()secara eksplisit ke arraytop_preferences. Untuk mengisolasi secara akurat satu kategori yang paling sering muncul per negara, Anda biasanya akan melihatnya menggunakan teknik lanjutan seperti fungsi jendelaROW_NUMBER() OVER()dalam Common Table Expression (CTE).
Tinjau diagram dan tabel data yang dirender secara otomatis. Data akan secara visual mengungkapkan pasar retensi inti Anda (biasanya menyoroti negara dengan volume tinggi seperti China atau Amerika Serikat) bersama dengan afinitas produk yang dominan secara universal (sering kali "Jeans"). Perhatikan bagaimana UI native menyusun output untuk segera digunakan tanpa memerlukan kode visualisasi eksplisit.
Baca teks Insight berbutir yang dihasilkan oleh agen. Karena Anda telah menetapkan Batas Analisis, cari secara khusus insight terkait Kualitas Data atau Signifikansi Statistik. Anda mungkin melihat agen secara eksplisit menandai negara di bagian bawah tabel dengan jumlah pengguna yang sangat rendah (misalnya, wilayah dengan hanya segelintir pengguna). Alih-alih berhalusinasi secara membabi buta tentang kampanye pemasaran yang ditargetkan berdasarkan satu titik data, agen akan dengan benar menyarankan bahwa anomali ini tidak signifikan secara statistik untuk strategi berskala besar. Hal ini menunjukkan cara menyematkan batas keamanan tata kelola langsung ke dalam agen secara efektif mencegah kesalahan perhitungan bisnis berbasis AI.
9. Membuat insight AI dengan Gemini dan MCP
Agen telah berhasil mengidentifikasi target demografis utama: VIP yang berisiko di negara tertentu. Namun, pekerjaan seorang analis berhenti pada insight. Untuk berinteraksi kembali dengan pengguna ini, tim pemasaran harus menjalankan kampanye.
Anda akan menggunakan Model Context Protocol (MCP) untuk menghubungkan asisten AI eksternal langsung ke daftar demografi tertentu ini di BigQuery, sehingga beralih dari analisis data ke tindakan yang didorong AI tanpa membuat API kustom.
Mengonfigurasi server BigQuery MCP
Jalankan blok di bawah untuk membuat file konfigurasi mcp.json. File ini menyediakan parameter koneksi yang diperlukan agar Gemini CLI dapat berinteraksi dengan BigQuery secara aman.
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
Membuat Email Pemasaran
Mulai alat Gemini CLI dari terminal Anda, dengan meneruskan flag konfigurasi MCP secara eksplisit agar dapat membaca lakehouse BigQuery Anda.
Jalankan Gemini CLI.
source env.sh
gemini
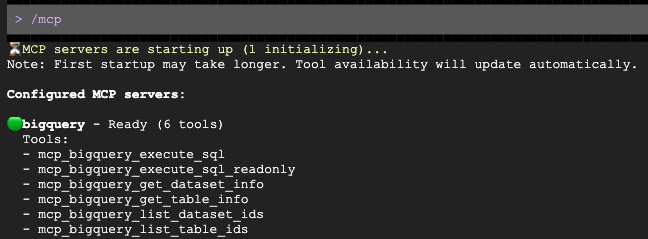
Setelah perintah terbuka, minta Gemini membuat draf pesan yang dipersonalisasi untuk target demografi Anda:
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
Gemini akan otomatis membuat kueri BigQuery melalui server MCP, mengidentifikasi demografi, dan membuat draf email untuk Anda.
10. Membersihkan lingkungan Anda
Untuk menghindari biaya berkelanjutan pada akun Google Cloud Anda dan mereset project dengan bersih untuk menjalankan di masa mendatang, Anda harus menghapus resource yang dibuat selama codelab ini.
Jalankan blok berikut untuk membuat skrip cleanup.sh. Skrip ini berfungsi sebagai mekanisme penonaktifan otomatis, yang menghapus cluster dan instance AlloyDB, set data BigQuery, dan bucket Cloud Storage Anda secara permanen untuk mencegah penagihan lebih lanjut.
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
Jalankan skrip pembersihan untuk menghapus resource Anda dengan aman:
bash cleanup.sh
11. Selamat!
Anda telah berhasil membangun dan membuat kueri cross-cloud open data lakehouse.
Anda telah mempelajari:
- Cara menggabungkan data dari berbagai sumber menggunakan BigQuery Zero-ETL dan Google Cloud Lakehouse.
- Cara memanfaatkan Lightning Engine native C++ dalam gabungan vektorisasi besar Managed Service untuk Apache Spark.
- Cara menggunakan Agen Data BigQuery untuk eksplorasi bahasa alami.
- Cara menghubungkan data Anda ke Gemini menggunakan Model Context Protocol (MCP) dan Gemini.
Apa Selanjutnya?
- Pelajari dokumentasi Lakehouse
- Pelajari lebih lanjut AlloyDB zero-ETL ke BigQuery
- Baca tentang Lightning Engine