
1. Introduzione
In questo codelab, creerai una data lakehouse aperta cross-cloud che unifica i silo di dati in AWS, Google Cloud e AlloyDB senza la necessità di ETL complessi. Utilizzerai Lakehouse come hub di intelligence centrale, AlloyDB come origine dati operativa e Managed Service for Apache Spark per l'elaborazione vettorizzata ad alte prestazioni. Infine, utilizzerai Gemini per estrarre informazioni aziendali approfondite dal tuo lakehouse.
Immagina che i tuoi dati transazionali (users, orders, order items) si trovino in un database AlloyDB operativo, i tuoi dati product in un bucket AWS S3 e i massicci clickstream event logs siano archiviati in Cloud Storage. Devi unire questi set di dati per identificare i dati demografici target per la tua prossima campagna di marketing e generare email di contatto personalizzate.
Prerequisiti
- Familiarità con i comandi SQL e del terminale di base.
- Un progetto Google Cloud con la fatturazione abilitata.
Cosa imparerai a fare
- Come integrare silo di dati disparati utilizzando BigQuery zero-ETL (AlloyDB) e Lakehouse per Apache Iceberg.
- Come eseguire un job di profilazione comportamentale ad alta velocità utilizzando Managed Service for Apache Spark basato su Lightning Engine nativo in C++.
- Come utilizzare l'agente di dati BigQuery per eseguire un'analisi complessa del linguaggio naturale sui dati unificati.
- Come configurare il Model Context Protocol (MCP) per consentire a Gemini CLI di leggere da Lakehouse per Apache Iceberg e creare contenuti di marketing.
Che cosa ti serve
- Un account Google Cloud e un progetto Google Cloud
- Un browser web come Chrome
Che cosa ti serve
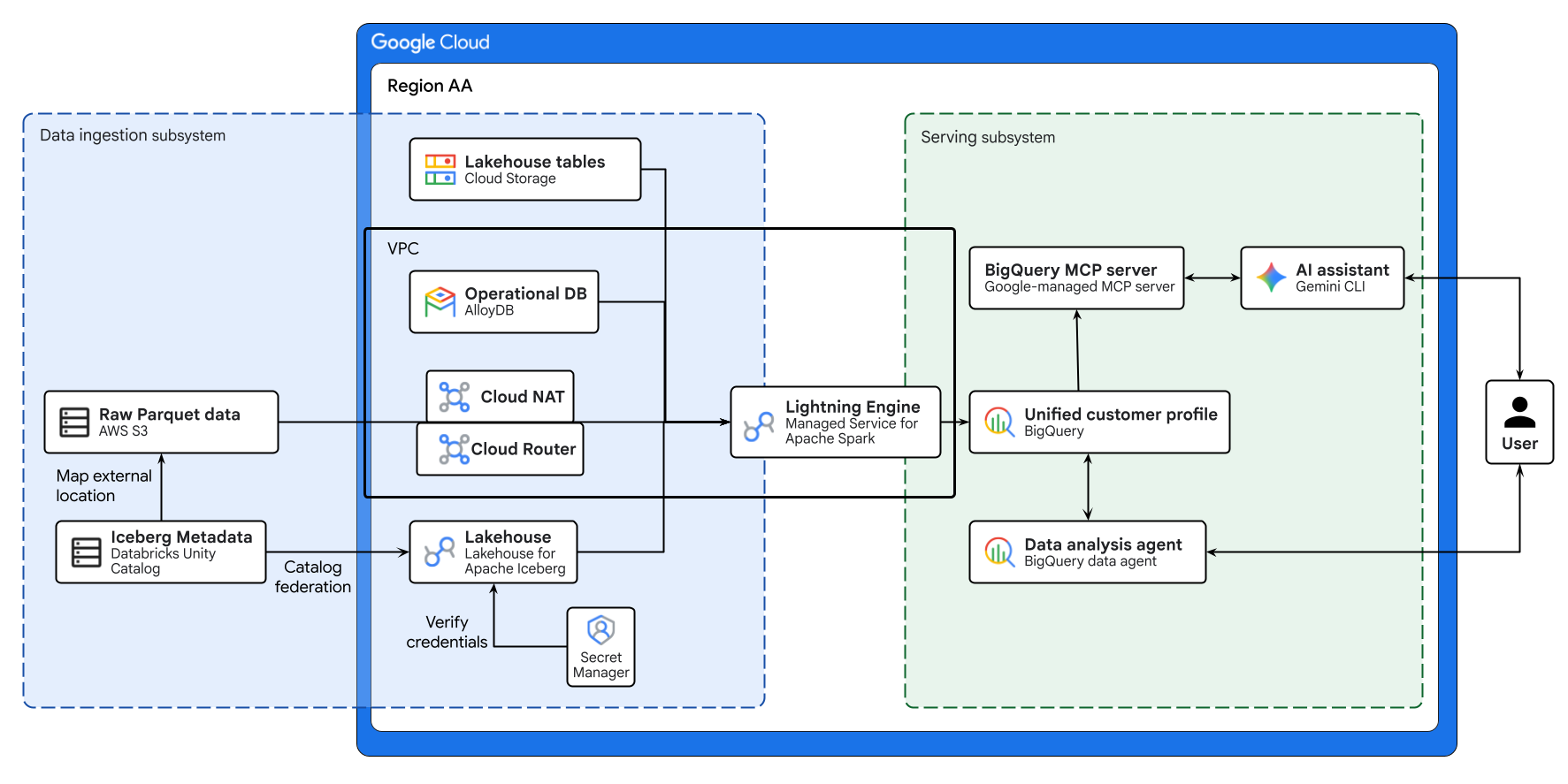
Il diagramma riportato sopra illustra il flusso end-to-end del lakehouse cross-cloud creato in questo codelab. I dati operativi di AlloyDB e i dati remoti di AWS S3 vengono federati in modo sicuro utilizzando Lakehouse per Apache Iceberg. Managed Service for Apache Spark elabora queste origini disparate per creare un profilo cliente unificato in BigQuery. Infine, un agente dati BigQuery e un server MCP BigQuery gestito da Google tramite Gemini CLI forniscono un'interfaccia intuitiva basata sull'AI per l'analisi avanzata dei dati.
Concetti fondamentali
- Data lakehouse aperto cross-cloud:unifica i silos di dati in AWS, Google Cloud e ambienti on-premise senza la necessità di ETL complessi.
- BigQuery zero-ETL:consente di eseguire query dirette sui database operativi senza spostare dati complessi.
- Lakehouse for Apache Iceberg:consente una sicurezza e una governance coerenti nell'archiviazione cross-cloud utilizzando il formato Apache Iceberg.
- Lightning Engine: motore C++ nativo per l'esecuzione di Apache Spark ad alte prestazioni.
- Model Context Protocol (MCP): collega Gemini direttamente al tuo lakehouse BigQuery.
2. Configurazione e requisiti
Crea un progetto Google Cloud
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
Avvia Cloud Shell
Sebbene Google Cloud possa essere gestito da remoto dal tuo laptop, in questo codelab utilizzerai Google Cloud Shell, un ambiente a riga di comando in esecuzione nel cloud.
Nella console Google Cloud, fai clic sull'icona di Cloud Shell nella barra degli strumenti in alto a destra:
Bastano pochi istanti per eseguire il provisioning e connettersi all'ambiente. Al termine, dovresti vedere un risultato simile a questo:

Questa macchina virtuale è caricata con tutti gli strumenti per sviluppatori di cui avrai bisogno. Offre una home directory permanente da 5 GB e viene eseguita su Google Cloud, migliorando notevolmente le prestazioni e l'autenticazione della rete. Tutto il lavoro in questo codelab può essere svolto all'interno di un browser. Non devi installare nulla.
Inizializza l'ambiente
Apri Cloud Shell e imposta le variabili del progetto per assicurarti che tutti i comandi siano indirizzati all'infrastruttura corretta.
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
Applica le variabili alla sessione attiva:
source ./env.sh
Abilita le API
Attiva i servizi Google Cloud necessari.
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3. Configura l'infrastruttura di base
Anziché spostare tutti i dati in un unico repository tramite pipeline ETL fragili, creerai un'architettura federata cross-cloud. In un'azienda reale, i dati sono intrinsecamente frammentati a causa dei diversi requisiti di sistema. Orchestrerai le seguenti origini dati:
- AlloyDB (DB transazionale principale): archivia i dati di utenti, ordini e order_items. In quanto database operativo live, garantisce le proprietà ACID richieste per le transazioni finanziarie e gli aggiornamenti dei profili.
- AWS S3 (dati master): archivia il catalogo
products. Rappresentazione di un sistema legacy di gestione dei dati master (MDM) su AWS. - Google Cloud Storage (data lake massivo): archivia
events(log clickstream). Dati ad alta velocità effettiva come i log web causerebbero l'arresto anomalo di un database relazionale. L'archiviazione di oggetti offre una scalabilità infinita e la sua conservazione in Google Cloud massimizza la località di calcolo per i tuoi motori di analisi.
Per prima cosa, configura la rete sottostante. I database gestiti Google Cloud come AlloyDB richiedono una connessione di peering VPC privato per comunicare in modo sicuro all'interno della rete del progetto.
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
Poi, crea un set di dati BigQuery e una connessione alla risorsa cloud Lakehouse. Dal punto di vista dell'architettura, una connessione alle risorse delega l'accesso ai dati a un service account dedicato gestito da Google, applicando il principio del privilegio minimo.
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. Esegui il provisioning del database operativo
Esegui il provisioning di un'istanza principale di AlloyDB e inserisci i dati transazionali mission critical.
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
Una volta pronto il database, devi creare una connessione esterna BigQuery ad AlloyDB. Questa connessione archivia in modo sicuro le credenziali e l'endpoint del database, consentendo a BigQuery di eseguire il pushdown dell'esecuzione SQL direttamente nel motore di calcolo AlloyDB (zero-ETL).
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
Trasferisci in modo sicuro le tabelle transazionali in AlloyDB. Utilizza il proxy di autenticazione AlloyDB per connettere in modo sicuro la sessione Cloud Shell locale all'istanza AlloyDB privata. In questo modo, puoi eseguire il push dei dati transazionali utilizzando gli strumenti a riga di comando locali.
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5. Federare i dati master (spoke AWS)
Il nostro catalogo dei prodotti, contenente i metadati degli articoli non elaborati, risiede in modo nativo su AWS S3 come tabelle Apache Iceberg. I metadati sono regolati da un catalogo remoto.
Anziché creare pipeline ETL fragili per copiare questi dati in Google Cloud, utilizzerai Lakehouse for Apache Iceberg (federazione del catalogo REST).
Questo approccio zero-ETL consente a Lakehouse e Managed Service for Apache Spark di rilevare e leggere dinamicamente i metadati Iceberg e i file Parquet sottostanti direttamente dal tuo ambiente remoto.
Se hai un account AWS attivo e Databricks Unity Catalog configurato, puoi utilizzarlo. In caso contrario, puoi simulare l'ambiente utilizzando Google Cloud Storage. Scegli una delle due opzioni.
Opzione A: porta il tuo AWS (Apache Iceberg nativo)
Prerequisito: questa opzione presuppone che tu abbia già eseguito il provisioning di un bucket AWS S3, lo abbia connesso come posizione esterna in Databricks Unity Catalog, abbia mappato una tabella Iceberg e abbia generato un service principal OAuth con accesso in lettura.
1. Archivio credenziali sicuro
L'hardcoding dei token di accesso di lunga durata è un anti-pattern architetturale. Memorizzerai l'ID client OAuth e il secret di Databricks in Google Cloud Secret Manager. Il servizio Lakehouse li recupererà in modo dinamico in fase di runtime per vendere token di breve durata, centralizzando la gestione delle credenziali.
Esegui il seguente blocco per generare lo script. Non modificare ancora nulla.
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
Quindi, esegui questo comando per aprire automaticamente lo script generato nell'editor di codice visivo sopra il terminale.
cloudshell edit create_secret.sh
- Nell'editor, sostituisci i segnaposto
<YOUR_...>con le tue credenziali Databricks effettive. - Assicurati che l'URL dello spazio di lavoro non includa
https://o barre finali (ad es.123456789.cloud.databricks.com). - Premi
Ctrl+S(oCmd+Ssu Mac) per salvare il file. - Torna alla sessione del terminale ed esegui lo script:
source create_secret.sh
2. Crea il catalogo federato
Per semplicità in questo codelab, configurerai il catalogo in modo che attraversi in modo sicuro la rete internet pubblica. Tuttavia, per i carichi di lavoro di produzione, l'esecuzione di query su set di dati di grandi dimensioni tramite internet pubblico comporta costi di uscita non necessari e latenza imprevedibile. La best practice prevede la configurazione di un'interconnessione Cross-Cloud Interconnect (CCI) privata tra AWS e Google Cloud, che riduce significativamente i costi in uscita e garantisce prestazioni di rete deterministiche.
Utilizza gcloud CLI per eseguire il provisioning del catalogo Lakehouse federato:
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. Applica associazioni IAM con privilegio minimo
Quando hai eseguito il provisioning del catalogo federato nel passaggio precedente, Google Cloud Lakehouse ha avviato automaticamente un job di aggiornamento in background per sincronizzare i manifest Iceberg ogni 330 secondi.
Devi concedere il ruolo secretAccessor al service account del catalogo Lakehouse in modo che possa recuperare in modo sicuro il token OAuth di Databricks durante queste sincronizzazioni in background e l'esecuzione delle query. Se questo binding non è presente, si verificheranno errori 403 invisibili quando Lakehouse tenta di aggiornare il catalogo.
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. Abilita l'accesso a internet in uscita per Managed Service for Apache Spark
In un passaggio successivo, Managed Service for Apache Spark leggerà i dati AWS remoti. Poiché Managed Service for Apache Spark Serverless viene eseguito interamente all'interno di una rete VPC privata senza indirizzi IP esterni, non può raggiungere AWS S3 su internet per impostazione predefinita. Devi eseguire il provisioning di Cloud NAT per consentire ai worker Spark l'accesso a internet in uscita.
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. Definisci la destinazione downstream
Esporta questa variabile in modo che i job Apache Spark downstream sappiano esattamente dove eseguire query sui dati AWS senza richiedere modifiche manuali al codice.
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
Opzione B: ambiente AWS simulato tramite Cloud Storage
Se non hai un account AWS attivo, puoi simulare il silo cross-cloud in modo nativo utilizzando le tabelle gestite Lakehouse su Google Cloud Storage.
1. Crea la tabella Iceberg simulata
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. Definisci la destinazione downstream
I set di dati BigQuery standard utilizzano una struttura dello spazio dei nomi in tre parti (project.dataset.table). Esporta questa variabile in modo che il job Apache Spark downstream abbia come target i dati simulati.
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. Importare i log degli eventi (spoke Google Cloud)
I dati clickstream crescono in modo esponenziale. Archivi gli eventi non elaborati completi e non aggregati localmente in Cloud Storage come tabelle Managed Lakehouse.
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. Creare un profilo cliente unificato
Ora che l'infrastruttura non elaborata è completamente compilata, è il momento di creare un profilo cliente unificato.
Utilizzerai Managed Service for Apache Spark basato su Lightning Engine. Lightning Engine è l'acceleratore di query nativo C++ ad alte prestazioni di Google Cloud, basato su tecnologie open source come Apache Gluten e Velox, che aumenta automaticamente l'esecuzione massimizzando l'efficienza della CPU e memorizzando in modo intelligente i dati nella cache. Questo approccio è ideale quando si eseguono unioni massive a più vie, finestre complesse o aggregazioni comportamentali su più cloud.
Utilizzerai il connettore Spark BigQuery per leggere direttamente le query federate zero-ETL e le tabelle Lakehouse di AlloyDB, eseguire le aggregazioni vettoriali massive in modo nativo in Spark e scrivere il profilo unificato risultante in BigQuery.
Configurare le autorizzazioni IAM per Managed Service for Apache Spark
Per impostazione predefinita, Serverless Spark esegue i job batch utilizzando il service account predefinito di Compute Engine. Prima di inviare il job, devi concedere a questo service account le autorizzazioni necessarie per eseguire il workload e gestire i job BigQuery.
(Nota: anche se il nome del servizio è stato modificato in Managed Service for Apache Spark per riflettere la terminologia standard del settore, i comandi API e i ruoli IAM sottostanti utilizzano ancora l'identificatore dataproc).
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
Crea e invia il job
Innanzitutto, crea lo script del job PySpark. Questo script rileva automaticamente se hai scelto l'opzione A (catalogo federato AWS) o l'opzione B (mock di Google Cloud) in base alla variabile di ambiente AWS_PRODUCTS_TABLE, definisce la logica Spark SQL e utilizza la manipolazione nativa degli array di Spark per calcolare le finestre RFM (recency, frequency, monetary).
Esegui il seguente blocco in Cloud Shell.
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
Con lo script completamente assemblato e le configurazioni richieste inserite dinamicamente, invia il job batch a Managed Apache Spark Serverless.
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
Verifica l'esecuzione del job nella console
Una volta inviato il job batch, puoi verificare che utilizzi il motore di esecuzione C++ accelerato:
- Nella console Google Cloud, vai a Managed Service for Apache Spark > Serverless > Batch.
- Fai clic sul job attualmente in esecuzione.
- Nel riquadro dei dettagli del lavoro, verifica che la proprietà Livello sia impostata su
Premiume che il motore sia impostato suLightning Engine.
8. Analizzare con l'agente di dati BigQuery
Ora che hai federato i dati cross-cloud frammentati ed eseguito le aggregazioni comportamentali pesanti utilizzando Managed Service for Apache Spark, il passaggio successivo è l'analisi dei dati.
Innanzitutto, esamina lo schema della tabella del profilo unificato appena creata nell'interfaccia utente BigQuery per comprendere visivamente la struttura dei dati che stai esponendo all'agente:
- Nella console Google Cloud, vai a BigQuery.
- Nel riquadro Explorer a sinistra, espandi il progetto e il set di dati
demo_lakehouse. - Fai clic sulla tabella
unified_customer_profile. - Seleziona la scheda Schema nello spazio di lavoro principale.
Controlla lo schema della nuova tabella. La colonna top_preferences è un REPEATED STRUCT (un array di record contenenti category, brand e sale_price). Tradizionalmente, l'esecuzione di query su array nidificati richiede un SQL complesso che utilizza la funzione UNNEST(), che può essere un ostacolo per gli analisti aziendali. Se si basa un agente di dati BigQuery su questa tabella specifica, l'agente comprende intrinsecamente lo schema e gestisce operazioni SQL standard complesse di Google.
Crea l'agente dati
In questa sezione, creerai un agente di dati BigQuery e interagirai con lui. Anziché scrivere manualmente un codice SQL complesso per estrarre gli array e calcolare le metriche, verrà eseguito il provisioning di un agente AI con ambito specifico per il profilo unificato appena creato, consentendo l'esplorazione dei dati in linguaggio naturale.
- Nel riquadro di navigazione a sinistra, individua e fai clic su Agenti.
- Fai clic su + Nuovo agente per inizializzare un nuovo assistente AI.
- Configura l'agente:
- Nome agente:
Retail VIP Analysis Agent - Origini dati: fai clic su Aggiungi origine e cerca la tabella
unified_customer_profile.
- Fai clic su Aggiungi e attendi qualche secondo che l'agente inizializzi il proprio workspace.
Una volta stabilito l'agente, la definizione di istruzioni di sistema esplicite è una pratica fondamentale di governance dei dati. Utilizza le istruzioni di sistema come livello semantico. Incorporando definizioni aziendali a livello aziendale, gestendo le complessità dello schema e stabilendo misure di salvaguardia analitiche, puoi astrarre la complessità tecnica dall'utente finale e impedire al LLM di trarre conclusioni da dati statisticamente insignificanti.
Incolla quanto segue nel campo Istruzione:
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
Chiedere all'agente
Poiché la complessa logica di business (la definizione esatta di un "VIP a rischio") e i requisiti di gestione dello schema sono regolati in modo sicuro dalle istruzioni di sistema, l'analista dei dati non deve scrivere un prompt prolisso e ricco di condizioni.
Nell'interfaccia della chat, inserisci il seguente prompt:
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
Valuta l'insight generato
Dopo aver inviato il prompt, esamina attentamente l'output generato in modo nativo per valutare in che modo BigQuery Data Agent ha applicato le istruzioni di sistema, fungendo sia da livello semantico controllato sia da protezione analitica.
Innanzitutto, leggi il testo di riepilogo generato sopra i dati. Nota come l'agente traduce automaticamente la tua semplice richiesta di "VIP a rischio" nelle soglie esatte delle metriche definite nelle istruzioni di sistema (ad es. facendo riferimento a lifetime_value > 100, cart_adds > 0 e a 90 giorni di inattività). Ciò conferma che l'agente ha interiorizzato la logica di business, il che significa che gli utenti finali non devono mai memorizzare o codificare in modo rigido una logica complessa nei loro prompt quotidiani.
Poi, espandi la visualizzazione SQL per esaminare il codice generato. L'agente deve aver creato un SQL standard di Google matematicamente valido in base alle tue istruzioni:
- Finestre temporali dinamiche:cerca il calcolo del timestamp nella clausola
WHERE(in genere utilizzandoTIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)). - Rigoroso rispetto dello schema:verifica che l'agente abbia rispettato le regole dello schema applicando esplicitamente la funzione
UNNEST()all'arraytop_preferences. Per isolare con precisione la categoria più frequente per paese, in genere vengono utilizzate tecniche avanzate come una funzione finestraROW_NUMBER() OVER()all'interno di un'espressione di tabella comune (CTE).
Esamina il grafico e la tabella dei dati visualizzati automaticamente. I dati riveleranno visivamente i tuoi mercati principali per la fidelizzazione (in genere evidenziando paesi con volumi elevati come Cina o Stati Uniti) insieme alle loro affinità di prodotto universalmente dominanti (spesso "Jeans"). Nota come la UI nativa strutturi l'output per un consumo immediato senza richiedere codice di visualizzazione esplicito.
Leggi il testo puntato Approfondimenti generato dall'agente. Poiché hai stabilito delle barriere protettive analitiche, cerca in particolare un insight relativo alla qualità dei dati o alla significatività statistica. Potresti notare che l'agente segnala esplicitamente i paesi in fondo alla tabella con un numero di utenti molto basso (ad es. regioni con solo una manciata di utenti). Anziché creare una campagna di marketing mirata basata su un singolo punto dati, l'agente consiglierà correttamente che queste anomalie sono statisticamente insignificanti per una strategia su larga scala. Ciò dimostra come l'incorporamento di misure di salvaguardia della governance direttamente nell'agente impedisca in modo efficace errori di calcolo aziendali basati sull'AI.
9. Generare insight AI con Gemini e MCP
L'agente ha identificato correttamente il gruppo demografico target principale: VIP a rischio in paesi specifici. Tuttavia, il lavoro di un analista si ferma all'insight. Per coinvolgere nuovamente questi utenti, il team di marketing deve eseguire una campagna.
Utilizzerai il Model Context Protocol (MCP) per connettere un assistente AI esterno direttamente a questo elenco demografico specifico in BigQuery, passando dall'analisi dei dati all'azione basata sull'AI senza creare API personalizzate.
Configurare il server BigQuery MCP
Esegui il blocco riportato di seguito per generare il file di configurazione mcp.json. Questo file fornisce i parametri di connessione necessari affinché la CLI Gemini possa interfacciarsi in modo sicuro con BigQuery.
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
Generare un'email di marketing
Avvia lo strumento Gemini CLI dal terminale, passando esplicitamente il flag di configurazione MCP per consentirgli di leggere la tua data lakehouse BigQuery.
Esegui Gemini CLI.
source env.sh
gemini
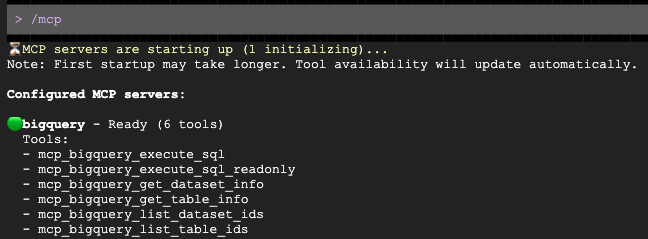
Una volta aperto il prompt, chiedi di creare una comunicazione personalizzata per il tuo gruppo demografico di destinazione:
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
Gemini eseguirà automaticamente query su BigQuery tramite il server MCP, identificherà i dati demografici e creerà una bozza dell'email per te.
10. Pulizia dell'ambiente
Per evitare addebiti continui al tuo account Google Cloud e reimpostare correttamente il progetto per le esecuzioni future, devi eliminare le risorse create durante questo codelab.
Esegui il seguente blocco per creare lo script cleanup.sh. Questo script funge da meccanismo di smantellamento automatizzato, rimuovendo definitivamente il cluster e l'istanza AlloyDB, i set di dati BigQuery e il bucket Cloud Storage per evitare ulteriore fatturazione.
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
Esegui lo script di pulizia per eliminare in modo sicuro le risorse:
bash cleanup.sh
11. Complimenti!
Hai creato ed eseguito query su una data lakehouse aperta cross-cloud.
Hai imparato a:
- Come federare i dati da origini disparate utilizzando BigQuery Zero-ETL e Google Cloud Lakehouse.
- Come sfruttare il motore Lightning nativo C++ nei join vettoriali massicci di Managed Service for Apache Spark.
- Come utilizzare l'agente di dati BigQuery per l'esplorazione in linguaggio naturale.
- Come collegare i tuoi dati a Gemini utilizzando Model Context Protocol (MCP) e Gemini.
Passaggi successivi
- Esplora la documentazione di Lakehouse
- Scopri di più su AlloyDB zero-ETL a BigQuery
- Scopri di più su Lightning Engine.