
1. はじめに
この Codelab では、複雑な ETL を必要とせずに、AWS、Google Cloud、AlloyDB 全体でデータサイロを統合するクロスクラウド オープン データ レイクハウスを構築します。Lakehouseを中央インテリジェンス ハブとして、AlloyDB を運用データソースとして、Managed Service for Apache Spark を高パフォーマンスのベクトル化処理に使用します。最後に、Gemini を使用して、レイクハウスから強力なビジネス分析情報を導き出します。
トランザクション データ(users、orders、order items)が運用中の AlloyDB データベースにあり、product データが AWS S3 バケットにあり、大量のクリックストリーム event logs が Cloud Storage に保存されているとします。これらのデータセットを結合して、次のマーケティング キャンペーンのターゲット層を特定し、パーソナライズされたアウトリーチ メールを生成する必要があります。
前提条件
- 基本的な SQL とターミナル コマンドに精通していること。
- 課金を有効にした Google Cloud プロジェクト
学習内容
- BigQuery zero-ETL(AlloyDB)と Lakehouse for Apache Iceberg を使用して、異なるデータサイロを統合する方法。
- C++ ネイティブの Lightning Engine を搭載した Managed Service for Apache Spark を使用して、高速な行動プロファイリング ジョブを実行する方法。
- BigQuery データ エージェントを使用して、統合データに対して複雑な自然言語分析を行う方法。
- Gemini CLI が Lakehouse for Apache Iceberg から読み取ってマーケティング コンテンツを作成できるように、Model Context Protocol(MCP)を構成する方法。
必要なもの
- Google Cloud アカウントと Google Cloud プロジェクト
- ウェブブラウザ(Chrome など)
必要なもの
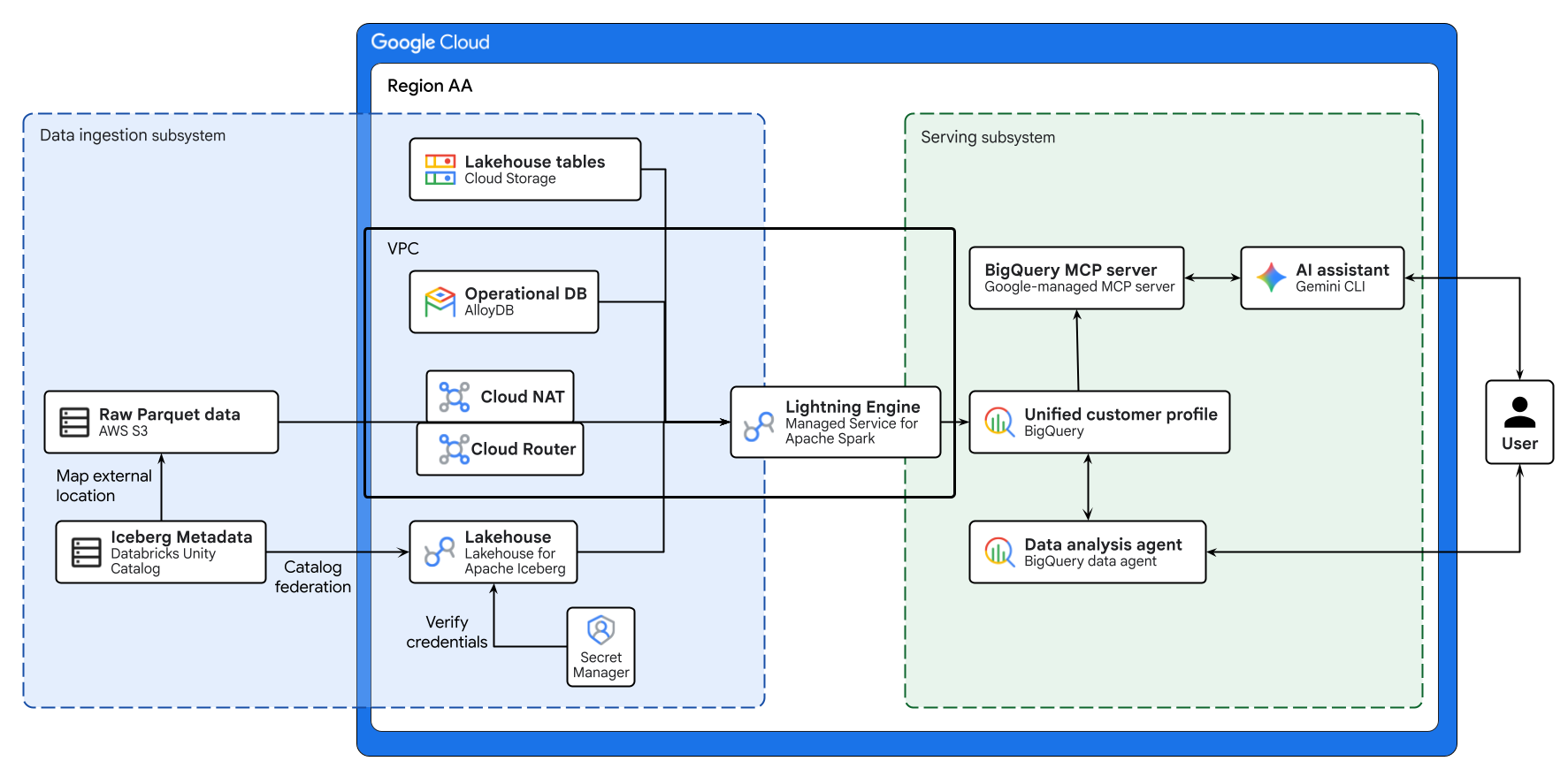
上の図は、この Codelab で構築するクロスクラウド レイクハウスのエンドツーエンドのフローを示しています。AlloyDB の運用データと AWS S3 のリモートデータは、Lakehouse for Apache Iceberg を使用して安全に統合されます。Managed Service for Apache Spark は、これらの異なるソースを処理して、BigQuery に統合された顧客プロファイルを作成します。最後に、Gemini CLI を介した BigQuery データ エージェントと Google マネージド BigQuery MCP サーバーにより、高度なデータ分析のための直感的な AI 駆動型インターフェースが提供されます。
主なコンセプト
- クロスクラウド オープン データ レイクハウス: 複雑な ETL を必要とせずに、AWS、Google Cloud、オンプレミス環境全体のデータサイロを統合します。
- BigQuery ゼロ ETL: 複雑なデータ移動を行わずに、運用データベースを直接クエリできます。
- Lakehouse for Apache Iceberg: Apache Iceberg 形式を使用して、クロスクラウド ストレージ全体で一貫したセキュリティとガバナンスを実現します。
- Lightning Engine: 高パフォーマンスの Apache Spark 実行用の C++ ネイティブ エンジン。
- Model Context Protocol(MCP): Gemini を BigQuery レイクハウスに直接接続します。
2. 設定と要件
Google Cloud プロジェクトの作成
- Google Cloud コンソールのプロジェクト セレクタ ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Cloud Shell の起動
Google Cloud はノートパソコンからリモートで操作できますが、この Codelab では、Google Cloud Shell(Cloud 上で動作するコマンドライン環境)を使用します。
Google Cloud Console で、右上のツールバーにある Cloud Shell アイコンをクリックします。
プロビジョニングと環境への接続にはそれほど時間はかかりません。完了すると、次のように表示されます。

この仮想マシンには、必要な開発ツールがすべて用意されています。永続的なホーム ディレクトリが 5 GB 用意されており、Google Cloud で稼働します。そのため、ネットワークのパフォーマンスと認証機能が大幅に向上しています。この Codelab での作業はすべて、ブラウザ内から実行できます。インストールは不要です。
環境を初期化する
Cloud Shell を開き、プロジェクト変数を設定して、すべてのコマンドが正しいインフラストラクチャをターゲットにしていることを確認します。
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
変数をアクティブ セッションに適用します。
source ./env.sh
API を有効にする
必要な Google Cloud サービスを有効にします。
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3. コア インフラストラクチャを設定する
脆弱な ETL パイプラインを介してすべてのデータを単一のリポジトリに移動するのではなく、フェデレーション クロスクラウド アーキテクチャを構築します。実際の企業では、システム要件が異なるため、データが本質的に断片化されています。次のデータソースをオーケストレートします。
- AlloyDB(コア トランザクション DB): ユーザー、注文、order_items データを保存します。ライブ オペレーショナル データベースとして、金融取引とプロファイル更新に必要な ACID プロパティを保証します。
- AWS S3(マスターデータ):
productsカタログを保存します。AWS でレガシー マスターデータ マネジメント(MDM)システムを表す。 - Google Cloud Storage(大規模なデータレイク):
events(クリックストリーム ログ)を保存します。ウェブログなどの高スループットのデータは、リレーショナル データベースをクラッシュさせます。オブジェクト ストレージは無限のスケーラビリティを提供します。また、Google Cloud に保存することで、分析エンジンのコンピューティング ローカリティを最大化できます。
まず、基盤となるネットワークを構成します。AlloyDB などの Google Cloud マネージド データベースでは、プロジェクト ネットワーク内で安全に通信するために、プライベート VPC ピアリング接続が必要です。
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
次に、BigQuery データセットと Lakehouse Cloud リソース接続を作成します。アーキテクチャ的には、リソース接続はデータアクセスを専用の Google 管理サービス アカウントに委任し、最小権限の原則を適用します。
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. 運用データベースをプロビジョニングする
AlloyDB プライマリ インスタンスをプロビジョニングし、ミッション クリティカルなトランザクション データを挿入します。
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
データベースの準備ができたら、AlloyDB への BigQuery 外部接続を作成する必要があります。この接続により、データベースの認証情報とエンドポイントが安全に保存され、BigQuery が SQL 実行を AlloyDB コンピューティング エンジンに直接プッシュダウンできます(ゼロ ETL)。
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
トランザクション テーブルを AlloyDB に安全に push します。AlloyDB Auth Proxy を使用して、ローカル Cloud Shell セッションをプライベート AlloyDB インスタンスに安全に接続します。これにより、ローカル コマンドライン ツールを使用してトランザクション データを push できます。
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5. マスターデータを連携する(AWS スポーク)
商品カタログ(未加工の商品メタデータを含む)は、Apache Iceberg テーブルとして AWS S3 にネイティブに存在します。メタデータはリモート カタログによって管理されます。
このデータを Google Cloud にコピーする脆弱な ETL パイプラインを構築する代わりに、Lakehouse for Apache Iceberg(REST カタログ連携)を使用します。
このゼロ ETL アプローチにより、Lakehouse と Managed Service for Apache Spark は、Iceberg メタデータと基盤となる Parquet ファイルをリモート環境から動的に検出して直接読み取ることができます。
アクティブな AWS アカウントと Databricks Unity Catalog が構成されている場合は、それを使用できます。それ以外の場合は、Google Cloud Storage を使用して環境をモックできます。どちらか一方を選択します。
オプション A: 独自の AWS を使用する(ネイティブ Apache Iceberg)
前提条件: このオプションでは、AWS S3 バケットをすでにプロビジョニングし、Databricks Unity Catalog の外部ロケーションとして接続し、Iceberg テーブルをマッピングし、読み取りアクセス権を持つ OAuth サービス プリンシパルを生成していることを前提としています。
1. 安全な認証情報ストレージ
有効期間の長いアクセス トークンをハードコードすることは、アーキテクチャのアンチパターンです。Databricks OAuth クライアント ID とシークレットは Google Cloud Secret Manager に保存します。Lakehouse サービスは、実行時にこれらを動的に取得して有効期間の短いトークンを販売し、認証情報のガバナンスを一元化します。
次のブロックを実行してスクリプトを生成します。(まだ何も編集しないでください)。
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
次のコマンドを実行して、生成されたスクリプトをターミナルの上のビジュアル コードエディタで自動的に開きます。
cloudshell edit create_secret.sh
- エディタで、
<YOUR_...>プレースホルダを実際の Databricks 認証情報に置き換えます。 - ワークスペースの URL に
https://や末尾のスラッシュ(123456789.cloud.databricks.comなど)が含まれていないことを確認します。 Ctrl+S(Mac ではCmd+S)を押してファイルを保存します。- ターミナル セッションに戻り、スクリプトを実行します。
source create_secret.sh
2. 連携カタログを作成する
この Codelab では、わかりやすくするために、パブリック インターネットを安全に通過するようにカタログを構成します。ただし、本番環境のワークロードでは、公共のインターネット経由で大規模なデータセットに対してクエリを実行すると、不要な下り(外向き)費用が発生し、レイテンシが予測できなくなります。ベスト プラクティスでは、AWS と Google Cloud 間のプライベート Cross-Cloud Interconnect(CCI)を構成することが推奨されています。これにより、下り(外向き)費用が大幅に削減され、ネットワーク パフォーマンスが決定論的に保証されます。
gcloud CLI を使用して、フェデレーション レイクハウス カタログをプロビジョニングします。
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. 最小権限の IAM バインディングを適用する
前の手順でフェデレーション カタログをプロビジョニングすると、Google Cloud Lakehouse はバックグラウンド更新ジョブを自動的に起動し、330 秒ごとに Iceberg マニフェストを同期します。
これらのバックグラウンド同期とクエリ実行中に Databricks OAuth トークンを安全に取得できるように、Lakehouse カタログ サービス アカウントに secretAccessor ロールを付与する必要があります。このバインディングがないと、Lakehouse がカタログを更新しようとしたときに 403 エラーが返されます。
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. Managed Service for Apache Spark のアウトバウンド インターネットを有効にする
次のステップで、Managed Service for Apache Spark がリモートの AWS データを読み取ります。Managed Service for Apache Spark Serverless は、外部 IP アドレスのないプライベート VPC ネットワーク内で完全に実行されるため、デフォルトではインターネット経由で AWS S3 にアクセスできません。Spark ワーカーがインターネットにアクセスできるように、Cloud NAT をプロビジョニングする必要があります。
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. ダウンストリーム ターゲットを定義する
この変数をエクスポートして、下流の Apache Spark ジョブが AWS データをクエリする場所を正確に把握できるようにします。これにより、手動でコードを変更する必要がなくなります。
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
オプション B: Cloud Storage を介して AWS 環境をモックする
アクティブな AWS アカウントがない場合は、Google Cloud Storage の Lakehouse 管理テーブルを使用して、クロスクラウド サイロをネイティブにシミュレートできます。
1. モック Iceberg テーブルを作成する
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. ダウンストリーム ターゲットを定義する
標準の BigQuery データセットは、3 部構成の名前空間構造(project.dataset.table)を使用します。この変数をエクスポートして、ダウンストリームの Apache Spark ジョブがモックデータをターゲットにできるようにします。
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. イベントログを取り込む(Google Cloud スポーク)
クリックストリーム データは指数関数的に増加します。完全な未集計の生イベントは、Cloud Storage にマネージド Lakehouse テーブルとしてローカルに保存します。
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. 統合された顧客プロファイルを作成する
未加工のインフラストラクチャが完全に設定されたら、統合された顧客プロファイルを作成します。
Lightning Engine を搭載した Managed Service for Apache Spark を使用します。Lightning Engine は、Apache Gluten や Velox などのオープンソース テクノロジー上に構築された Google Cloud の高性能 C++ ネイティブ クエリ アクセラレータです。CPU の効率を最大化し、データをインテリジェントにキャッシュに保存することで、実行を自動的に高速化します。このアプローチは、複数のクラウドにわたる大規模な多方向結合、複雑なウィンドウ処理、行動集計を行う場合に最適です。
Spark BigQuery コネクタを使用して、連携された AlloyDB zero-ETL クエリと Lakehouse テーブルを直接読み取り、Spark で大規模なベクトル化された集計をネイティブに実行し、結果の統合プロファイルを BigQuery に書き戻します。
Managed Service for Apache Spark の IAM 権限を構成する
デフォルトでは、サーバーレス Spark は Compute Engine のデフォルトのサービス アカウントを使用してバッチジョブを実行します。ジョブを送信する前に、このサービス アカウントにワークロードの実行と BigQuery ジョブの管理に必要な権限を付与する必要があります。
(注: 業界標準の用語を反映するためにサービス名が Managed Service for Apache Spark に変更されましたが、基盤となる API コマンドと IAM ロールでは引き続き dataproc 識別子が使用されます)。
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
ジョブを作成して送信する
まず、PySpark ジョブ スクリプトを作成します。このスクリプトは、AWS_PRODUCTS_TABLE 環境変数に基づいて オプション A(AWS 連携カタログ)または オプション B(Google Cloud モック)のどちらを選択したかを自動的に検出し、Spark SQL ロジックを定義し、Spark のネイティブ配列操作を使用して RFM(最終購入日、購入頻度、購入金額)ウィンドウを計算します。
Cloud Shell で次のブロックを実行します。
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
スクリプトが完全に組み立てられ、必要な構成が動的に挿入されたら、バッチジョブを Managed Apache Spark Serverless に送信します。
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
コンソールでジョブの実行を確認する
バッチジョブを送信したら、高速化された C++ 実行エンジンが使用されていることを確認できます。
- Google Cloud コンソールで、[Managed Service for Apache Spark] > [サーバーレス] > [バッチ] に移動します。
- 現在実行中のジョブをクリックします。
- ジョブの詳細ペインで、[ティア] プロパティが
Premiumに設定され、[エンジン] がLightning Engineに設定されていることを確認します。
8. BigQuery データ エージェントで分析する
断片化されたクロスクラウド データを統合し、Managed Service for Apache Spark を使用して重い行動集計を実行したので、次のステップはデータ分析です。
まず、BigQuery UI で新しく作成された統合プロファイル テーブルのスキーマを調べて、エージェントに公開するデータ構造を視覚的に理解します。
- Google Cloud コンソールで [BigQuery] に移動します。
- 左側の [エクスプローラ] ペインで、プロジェクトと
demo_lakehouseデータセットを開きます。 - [
unified_customer_profile] テーブルをクリックします。 - メイン ワークスペースで [スキーマ] タブを選択します。
新しいテーブルのスキーマを確認します。top_preferences 列は REPEATED STRUCT(category、brand、sale_price を含むレコードの配列)です。従来、ネストされた配列のクエリには UNNEST() 関数を使用する複雑な SQL が必要であり、ビジネス アナリストにとってハードルとなる可能性があります。この特定のテーブルに BigQuery データ エージェントを配置することで、エージェントはスキーマを本質的に理解し、複雑な Google 標準 SQL オペレーションを内部で処理します。
データ エージェントを作成する
このセクションでは、BigQuery データ エージェントを作成して操作します。配列のネスト解除や指標の計算を行う複雑な SQL を手動で記述する代わりに、新しく作成した統合プロファイルにスコープ設定された AI エージェントをプロビジョニングして、自然言語によるデータ探索を可能にします。
- 左側のナビゲーション パネルで、[エージェント] を見つけてクリックします。
- [+ 新しいエージェント] をクリックして、新しい AI アシスタントを初期化します。
- エージェントを構成します。
- Agent Name:
Retail VIP Analysis Agent - データソース: [ソースを追加] をクリックして、
unified_customer_profileテーブルを検索します。
- [追加] をクリックし、エージェントがワークスペースを初期化するまで数秒待ちます。
エージェントが確立されたら、明示的なシステム指示を定義することが、重要なデータ ガバナンスの実践となります。システム指示をセマンティック レイヤとして使用します。企業全体のビジネス定義を埋め込み、スキーマの複雑さを処理し、分析のガードレールを確立することで、技術的な複雑さをエンドユーザーから抽象化し、LLM が統計的に有意でないデータから結論を導き出すのを防ぎます。
[手順] フィールドに次の内容を貼り付けます。
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
エージェントにプロンプトを表示する
複雑なビジネス ロジック(「リスクの高い VIP」の正確な定義)とスキーマ処理の要件はシステム指示に則って安全に管理されるため、データ アナリストは冗長で条件の多いプロンプトを作成する必要はありません。
チャット インターフェースに次のプロンプトを入力します。
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
生成された分析情報を評価する
プロンプトを送信したら、ネイティブに生成された出力を注意深く確認し、BigQuery Data Agent がガバナンスされたセマンティック レイヤと分析ガードレールの両方として機能し、システム指示をどのように適用したかを評価します。
まず、データの上に生成された要約テキストを読みます。エージェントが「At-Risk VIPs」という簡単なリクエストを、システム指示で定義されている正確な指標のしきい値(lifetime_value > 100, cart_adds > 0 の参照や 90 日間の非アクティブなど)に自動的に変換していることに注目してください。これにより、エージェントがビジネス ロジックを内部化したことが確認されます。つまり、エンドユーザーは複雑なロジックを毎日のプロンプトで記憶したり、ハードコードしたりする必要がなくなります。
次に、SQL ビューを開いて、生成されたコードを調べます。エージェントは、指示に基づいて数学的に健全な Google 標準 SQL を構築しているはずです。
- 動的期間:
WHERE句でタイムスタンプの計算を探します(通常はTIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)を使用します)。 - 厳格なスキーマの遵守:
top_preferences配列にUNNEST()関数を明示的に適用して、エージェントが厳格なスキーマ ルールに従ったことを確認します。国ごとに最も頻繁なカテゴリを正確に分離するには、通常、共通テーブル式(CTE)内のROW_NUMBER() OVER()ウィンドウ関数などの高度な手法が使用されます。
自動的にレンダリングされたグラフとデータテーブルを確認します。データから、主要なリテンション マーケット(通常は中国や米国などのボリュームの多い国がハイライト表示されます)と、普遍的に優勢な商品アフィニティ(多くの場合「ジーンズ」)が視覚的に明らかになります。ネイティブ UI は、明示的な可視化コードを必要とせずに、すぐに使用できる出力構造を生成します。
エージェントによって生成された箇条書きの分析情報のテキストを読みます。分析ガードレールを設定したため、データ品質または統計的有意性に関する分析情報を探します。エージェントが、ユーザー数が非常に少ない国(ユーザーが数人しかいない地域など)を明示的にテーブルの下部にフラグ付けしている場合があります。エージェントは、単一のデータポイントに基づいてターゲット マーケティング キャンペーンを盲目的に幻覚するのではなく、これらの異常値は大規模な戦略にとって統計的に有意ではないと正しくアドバイスします。これは、ガバナンス ガードレールをエージェントに直接組み込むことで、AI 主導のビジネス上の誤算を効果的に防ぐ方法を示しています。
9. Gemini と MCP で AI 分析情報を生成する
エージェントは、特定の国に住むリスクの高い VIP という主要なターゲット ユーザー層を特定することに成功しました。ただし、アナリストの仕事は分析情報で終わります。こうしたユーザーに再度アプローチするには、マーケティング チームがキャンペーンを実施する必要があります。
Model Context Protocol(MCP)を使用して、外部 AI アシスタントを BigQuery のこの特定のユーザー属性リストに直接接続し、カスタム API を構築することなく、データ分析から AI 主導のアクションに移行します。
BigQuery MCP サーバーを構成する
次のブロックを実行して、mcp.json 構成ファイルを生成します。このファイルは、Gemini CLI が BigQuery と安全にやり取りするために必要な接続パラメータを提供します。
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
マーケティング メールを生成する
ターミナルから Gemini CLI ツールを起動し、BigQuery レイクハウスを読み取れるように、MCP 構成フラグを明示的に渡します。
Gemini CLI を実行します。
source env.sh
gemini
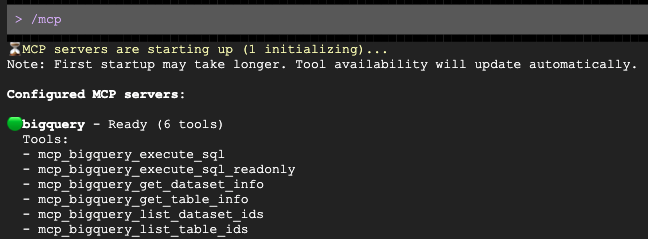
プロンプトが開いたら、ターゲット層に合わせたアウトリーチの草案を作成するようリクエストします。
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
Gemini は、MCP サーバーを介して BigQuery を自動的にクエリし、ユーザーの属性を特定して、メールのドラフトを作成します。
10. 環境をクリーンアップする
Google Cloud アカウントへの継続的な課金を回避し、将来の実行のためにプロジェクトをクリーンにリセットするには、この Codelab で作成したリソースを削除する必要があります。
次のブロックを実行して cleanup.sh スクリプトを作成します。このスクリプトは、自動化された削除メカニズムとして機能し、AlloyDB クラスタとインスタンス、BigQuery データセット、Cloud Storage バケットを完全に削除して、それ以降の課金を防ぎます。
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
クリーンアップ スクリプトを実行して、リソースを安全に削除します。
bash cleanup.sh
11. 完了
これで、クロスクラウドのオープン データ レイクハウスを構築してクエリを実行できました。
学習した内容は以下のとおりです。
- BigQuery Zero-ETL と Google Cloud Lakehouse を使用して、異なるソースのデータを統合する方法。
- Managed Service for Apache Spark の大規模なベクトル化結合で C++ ネイティブ Lightning Engine を活用する方法。
- 自然言語探索に BigQuery データ エージェントを使用する方法。
- Model Context Protocol(MCP)と Gemini を使用してデータを Gemini にブリッジする方法。
次のステップ
- Lakehouse のドキュメントを確認する
- AlloyDB から BigQuery へのゼロ ETL の詳細を確認する
- Lightning Engine について読む