
1. 소개
이 Codelab에서는 복잡한 ETL 없이 AWS, Google Cloud, AlloyDB 전반의 데이터 사일로를 통합하는 크로스 클라우드 개방형 데이터 레이크하우스를 빌드합니다. Lakehouse를 중앙 인텔리전스 허브로, AlloyDB를 운영 데이터 소스로, Managed Service for Apache Spark를 고성능 벡터화 처리용으로 사용합니다. 마지막으로 Gemini를 사용하여 레이크하우스에서 강력한 비즈니스 통계를 도출합니다.
트랜잭션 데이터 (users, orders, order items)가 운영 AlloyDB 데이터베이스에 있고 product 데이터가 AWS S3 버킷에 있으며 대규모 클릭스트림 event logs이 Cloud Storage에 저장되어 있다고 가정해 보겠습니다. 이러한 데이터 세트를 결합하여 다음 마케팅 캠페인의 타겟 인구통계를 파악하고 개인화된 이메일을 생성해야 합니다.
기본 요건
- 기본 SQL 및 터미널 명령어에 대한 지식
- 결제가 사용 설정된 Google Cloud 프로젝트.
학습할 내용
- BigQuery 제로 ETL (AlloyDB) 및 Lakehouse for Apache Iceberg를 사용하여 이질적인 데이터 사일로를 통합하는 방법
- C++ 네이티브 Lightning Engine으로 구동되는 Managed Service for Apache Spark를 사용하여 고속 행동 프로파일링 작업을 실행하는 방법
- BigQuery 데이터 에이전트를 사용하여 통합 데이터에 대해 복잡한 자연어 분석을 수행하는 방법
- Gemini CLI가 Apache Iceberg용 Lakehouse에서 읽고 마케팅 콘텐츠를 초안으로 작성할 수 있도록 모델 컨텍스트 프로토콜 (MCP)을 구성하는 방법
필요한 항목
- Google Cloud 계정 및 Google Cloud 프로젝트
- 웹브라우저(예: Chrome)
필요한 항목
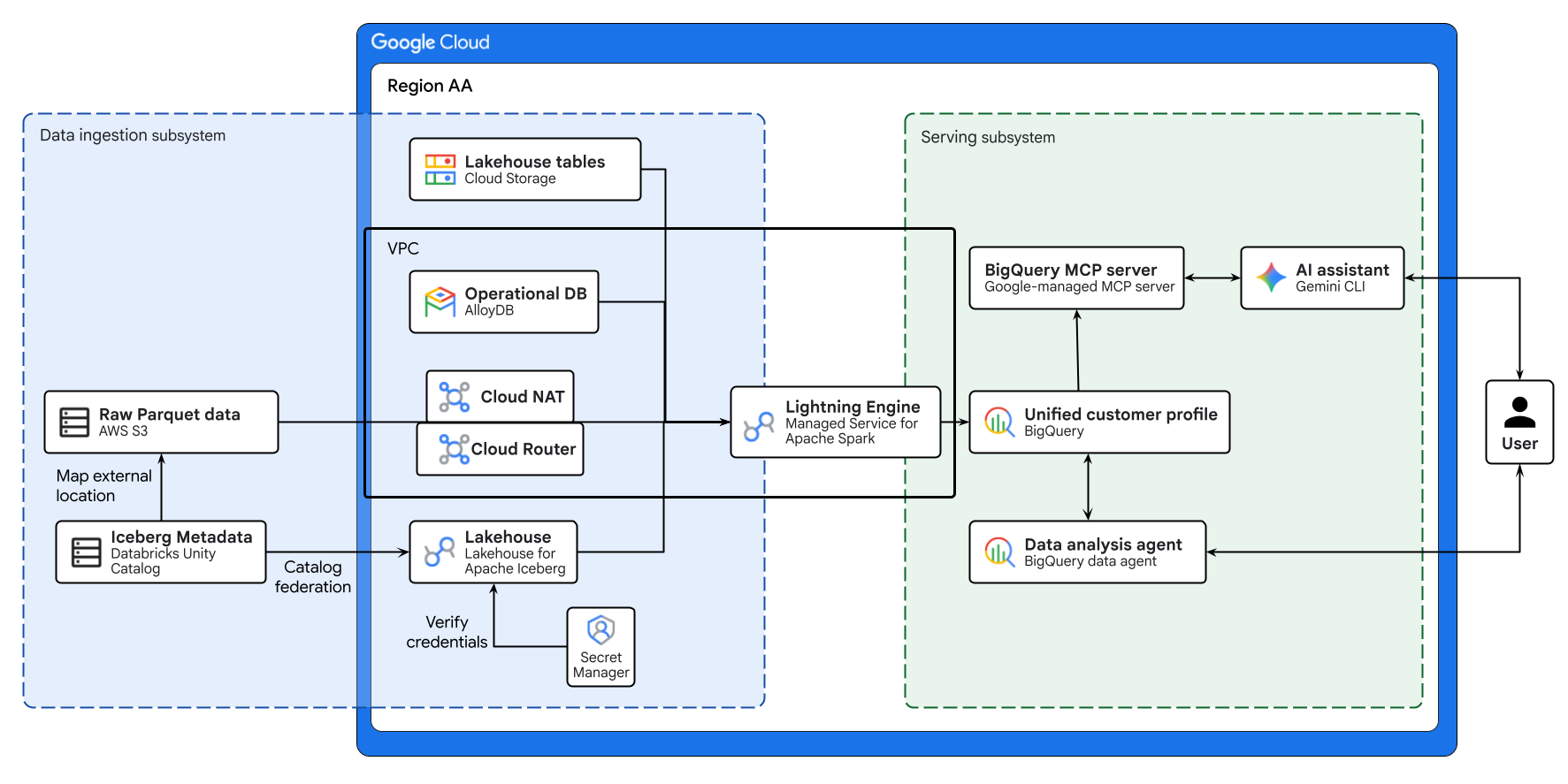
위 다이어그램은 이 Codelab에서 빌드한 크로스 클라우드 레이크하우스의 엔드 투 엔드 흐름을 보여줍니다. AlloyDB의 운영 데이터와 AWS S3의 원격 데이터는 Lakehouse for Apache Iceberg를 사용하여 안전하게 제휴됩니다. Managed Service for Apache Spark는 이러한 이질적인 소스를 처리하여 BigQuery에 통합된 고객 프로필을 빌드합니다. 마지막으로 Gemini CLI를 통한 BigQuery 데이터 에이전트와 Google 관리 BigQuery MCP 서버는 고급 데이터 분석을 위한 직관적인 AI 기반 인터페이스를 제공합니다.
주요 개념
- 크로스 클라우드 개방형 데이터 레이크하우스: 복잡한 ETL 없이 AWS, Google Cloud, 온프레미스 환경 전반의 데이터 사일로를 통합합니다.
- BigQuery 제로 ETL: 복잡한 데이터 이동 없이 운영 데이터베이스를 직접 쿼리할 수 있습니다.
- Lakehouse for Apache Iceberg: Apache Iceberg 형식을 사용하여 크로스 클라우드 스토리지 전반에서 일관된 보안 및 거버넌스를 지원합니다.
- Lightning Engine: 고성능 Apache Spark 실행을 위한 C++ 네이티브 엔진입니다.
- 모델 컨텍스트 프로토콜 (MCP): Gemini를 BigQuery 레이크하우스에 직접 연결합니다.
2. 설정 및 요건
Google Cloud 프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
Cloud Shell 시작
Google Cloud를 노트북에서 원격으로 실행할 수 있지만, 이 Codelab에서는 Cloud에서 실행되는 명령줄 환경인 Google Cloud Shell을 사용합니다.
Google Cloud Console의 오른쪽 상단 툴바에 있는 Cloud Shell 아이콘을 클릭합니다.
환경을 프로비저닝하고 연결하는 데 몇 분 정도 소요됩니다. 완료되면 다음과 같이 표시됩니다.

가상 머신에는 필요한 개발 도구가 모두 들어있습니다. 영구적인 5GB 홈 디렉터리를 제공하고 Google Cloud에서 실행되므로 네트워크 성능과 인증이 크게 개선됩니다. 이 Codelab의 모든 작업은 브라우저 내에서 수행할 수 있습니다. 아무것도 설치할 필요가 없습니다.
환경 초기화
Cloud Shell을 열고 프로젝트 변수를 설정하여 모든 명령어가 올바른 인프라를 타겟팅하도록 합니다.
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
활성 세션에 변수를 적용합니다.
source ./env.sh
API 사용 설정
필요한 Google Cloud 서비스를 사용 설정합니다.
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3. 핵심 인프라 설정
취약한 ETL 파이프라인을 통해 모든 데이터를 단일 저장소로 이동하는 대신 연합된 크로스 클라우드 아키텍처를 빌드합니다. 실제 엔터프라이즈에서는 시스템 요구사항이 다르기 때문에 데이터가 본질적으로 조각화됩니다. 다음 데이터 소스를 오케스트레이션합니다.
- AlloyDB (핵심 트랜잭션 DB): 사용자, 주문, order_items 데이터를 저장합니다. 라이브 운영 데이터베이스로서 금융 거래 및 프로필 업데이트에 필요한 ACID 속성을 보장합니다.
- AWS S3 (마스터 데이터):
products카탈로그를 저장합니다. AWS의 기존 마스터 데이터 관리 (MDM) 시스템을 나타냅니다. - Google Cloud Storage (대규모 데이터 레이크):
events(클릭스트림 로그)을 저장합니다. 웹 로그와 같은 처리량이 높은 데이터는 관계형 데이터베이스를 비정상 종료시킵니다. 객체 스토리지는 무한한 확장성을 제공하며 Google Cloud에 보관하면 분석 엔진의 컴퓨팅 지역성을 극대화할 수 있습니다.
먼저 기본 네트워크를 구성합니다. AlloyDB와 같은 Google Cloud 관리 데이터베이스는 프로젝트 네트워크 내에서 안전하게 통신하기 위해 비공개 VPC 피어링 연결이 필요합니다.
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
다음으로 BigQuery 데이터 세트와 Lakehouse Cloud 리소스 연결을 만듭니다. 아키텍처 측면에서 리소스 연결은 전용 Google 관리 서비스 계정에 데이터 액세스 권한을 위임하여 최소 권한의 원칙을 시행합니다.
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. 운영 데이터베이스 프로비저닝
AlloyDB 기본 인스턴스를 프로비저닝하고 비즈니스에 중요한 트랜잭션 데이터를 삽입합니다.
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
데이터베이스가 준비되면 AlloyDB에 대한 BigQuery 외부 연결을 만들어야 합니다. 이 연결은 데이터베이스 사용자 인증 정보와 엔드포인트를 안전하게 저장하므로 BigQuery가 SQL 실행을 AlloyDB 컴퓨팅 엔진으로 직접 푸시할 수 있습니다 (제로 ETL).
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
트랜잭션 테이블을 AlloyDB에 안전하게 푸시합니다. AlloyDB 인증 프록시를 사용하여 로컬 Cloud Shell 세션을 비공개 AlloyDB 인스턴스에 안전하게 연결합니다. 이를 통해 로컬 명령줄 도구를 사용하여 트랜잭션 데이터를 푸시할 수 있습니다.
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5. 마스터 데이터 연동 (AWS 스포크)
원시 상품 메타데이터가 포함된 Google의 제품 카탈로그는 AWS S3에 Apache Iceberg 테이블로 기본적으로 저장됩니다. 메타데이터는 원격 카탈로그에 의해 관리됩니다.
이 데이터를 Google Cloud에 복사하기 위해 취약한 ETL 파이프라인을 빌드하는 대신 Lakehouse for Apache Iceberg (REST 카탈로그 페더레이션)를 사용합니다.
이 제로 ETL 접근 방식을 사용하면 Lakehouse와 Managed Service for Apache Spark가 원격 환경에서 직접 Iceberg 메타데이터와 기본 Parquet 파일을 동적으로 검색하고 읽을 수 있습니다.
활성 AWS 계정과 Databricks Unity Catalog가 구성되어 있는 경우 이를 사용할 수 있습니다. 그렇지 않으면 Google Cloud Storage를 사용하여 환경을 모의로 만들 수 있습니다. 둘 중 하나를 선택합니다.
옵션 A: 자체 AWS 사용 (네이티브 Apache Iceberg)
기본 요건: 이 옵션은 이미 AWS S3 버킷을 프로비저닝하고, Databricks Unity Catalog에서 외부 위치로 연결하고, Iceberg 테이블을 매핑하고, 읽기 액세스 권한이 있는 OAuth 서비스 주체를 생성했다고 가정합니다.
1. 보안 사용자 인증 정보 저장소
수명이 긴 액세스 토큰을 하드코딩하는 것은 아키텍처 안티 패턴입니다. Databricks OAuth 클라이언트 ID와 보안 비밀을 Google Cloud Secret Manager에 저장합니다. 레이크하우스 서비스는 런타임에 이를 동적으로 가져와 단기 토큰을 판매하여 사용자 인증 정보 거버넌스를 중앙 집중화합니다.
다음 블록을 실행하여 스크립트를 생성합니다. (아직 아무것도 수정하지 마세요.)
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
그런 다음 다음 명령어를 실행하여 터미널 위의 시각적 코드 편집기에서 생성된 스크립트를 자동으로 엽니다.
cloudshell edit create_secret.sh
- 편집기에서
<YOUR_...>자리표시자를 실제 Databricks 사용자 인증 정보로 바꿉니다. - 작업공간 URL에
https://또는 후행 슬래시 (예:123456789.cloud.databricks.com)가 포함되지 않아야 합니다. Ctrl+S(또는 Mac의 경우Cmd+S)를 눌러 파일을 저장합니다.- 터미널 세션으로 돌아가서 스크립트를 실행합니다.
source create_secret.sh
2. 제휴 카탈로그 만들기
이 Codelab에서는 간단하게 카탈로그가 공개 인터넷을 안전하게 탐색하도록 구성합니다. 하지만 프로덕션 워크로드의 경우 공개 인터넷을 통해 대규모 데이터 세트를 쿼리하면 불필요한 이그레스 비용과 예측할 수 없는 지연 시간이 발생합니다. 권장사항에 따라 AWS와 Google Cloud 간에 비공개 Cross-Cloud Interconnect (CCI)를 구성해야 합니다. 이렇게 하면 이그레스 비용이 크게 절감되고 결정적인 네트워크 성능이 보장됩니다.
gcloud CLI를 사용하여 제휴 Lakehouse 카탈로그를 프로비저닝합니다.
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. 최소 권한 IAM 바인딩 적용
이전 단계에서 통합 카탈로그를 프로비저닝하면 Google Cloud Lakehouse에서 330초마다 Iceberg 매니페스트를 동기화하는 백그라운드 새로고침 작업을 자동으로 실행했습니다.
이러한 백그라운드 동기화 및 쿼리 실행 중에 Databricks OAuth 토큰을 안전하게 가져오고 쿼리를 실행할 수 있도록 Lakehouse 카탈로그 서비스 계정에 secretAccessor 역할을 부여해야 합니다. 이 바인딩이 누락되면 Lakehouse가 카탈로그를 업데이트하려고 할 때 403 오류가 자동으로 발생합니다.
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. Managed Service for Apache Spark의 아웃바운드 인터넷 사용 설정
후속 단계에서 Managed Service for Apache Spark가 원격 AWS 데이터를 읽습니다. Managed Service for Apache Spark 서버리스는 외부 IP 주소 없이 비공개 VPC 네트워크 내에서 완전히 실행되므로 기본적으로 인터넷을 통해 AWS S3에 연결할 수 없습니다. Spark 작업자가 아웃바운드 인터넷 액세스를 할 수 있도록 Cloud NAT를 프로비저닝해야 합니다.
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. 다운스트림 타겟 정의
다운스트림 Apache Spark 작업이 수동 코드 변경 없이 AWS 데이터를 정확히 어디에서 쿼리해야 하는지 알 수 있도록 이 변수를 내보냅니다.
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
옵션 B: Cloud Storage를 통해 AWS 환경 모의
활성 AWS 계정이 없는 경우 Google Cloud Storage에서 Lakehouse 관리 테이블을 사용하여 크로스 클라우드 사일로를 기본적으로 시뮬레이션할 수 있습니다.
1. 모의 Iceberg 테이블 만들기
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. 다운스트림 타겟 정의
표준 BigQuery 데이터 세트는 3부분 네임스페이스 구조 (project.dataset.table)를 사용합니다. 다운스트림 Apache Spark 작업이 모의 데이터를 타겟팅하도록 이 변수를 내보냅니다.
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. 이벤트 로그 수집 (Google Cloud 스포크)
클릭스트림 데이터가 기하급수적으로 증가합니다. 완전하고 집계되지 않은 원시 이벤트를 관리형 Lakehouse 테이블로 Cloud Storage에 로컬로 저장합니다.
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. 통합 고객 프로필 구축
원시 인프라가 완전히 채워졌으므로 이제 통합 고객 프로필을 빌드할 차례입니다.
Lightning Engine으로 구동되는 Managed Service for Apache Spark를 사용합니다. Lightning Engine은 Apache Gluten 및 Velox와 같은 오픈소스 기술을 기반으로 구축된 Google Cloud의 고성능 C++ 네이티브 쿼리 가속기로, CPU 효율성을 극대화하고 데이터를 지능적으로 캐싱하여 실행을 자동으로 향상합니다. 이 접근 방식은 여러 클라우드에서 대규모 다방향 조인, 복잡한 윈도우, 동작 집계를 실행할 때 적합합니다.
Spark BigQuery 커넥터를 사용하여 페더레이션된 AlloyDB 제로 ETL 쿼리 및 레이크하우스 테이블을 직접 읽고, Spark에서 대규모 벡터화된 집계를 기본적으로 실행하고, 결과로 생성된 통합 프로필을 BigQuery에 다시 씁니다.
Managed Service for Apache Spark의 IAM 권한 구성
기본적으로 서버리스 Spark는 Compute Engine 기본 서비스 계정을 사용하여 배치 작업을 실행합니다. 작업을 제출하기 전에 이 서비스 계정에 워크로드를 실행하고 BigQuery 작업을 관리하는 데 필요한 권한을 부여해야 합니다.
(참고: 업계 표준 용어를 반영하기 위해 서비스 이름이 Managed Service for Apache Spark로 변경되었지만 기본 API 명령어와 IAM 역할은 여전히 dataproc 식별자를 사용합니다).
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
작업 생성 및 제출
먼저 PySpark 작업 스크립트를 만듭니다. 이 스크립트는 AWS_PRODUCTS_TABLE 환경 변수를 기반으로 옵션 A (AWS 페더레이션 카탈로그) 또는 옵션 B (Google Cloud 모의)를 선택했는지 자동으로 감지하고, Spark SQL 로직을 정의하고, Spark의 기본 배열 조작을 활용하여 RFM (최근성, 빈도, 금액) 기간을 계산합니다.
Cloud Shell에서 다음 블록을 실행합니다.
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
스크립트가 완전히 조립되고 필요한 구성이 동적으로 삽입되면 관리형 Apache Spark 서버리스에 일괄 작업을 제출합니다.
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
콘솔에서 작업 실행 확인
일괄 작업이 제출되면 가속화된 C++ 실행 엔진을 사용하고 있는지 확인할 수 있습니다.
- Google Cloud 콘솔에서 Managed Service for Apache Spark > 서버리스 > 일괄로 이동합니다.
- 현재 실행 중인 작업을 클릭합니다.
- 작업 세부정보 창에서 등급 속성이
Premium로 설정되어 있고 엔진이Lightning Engine로 설정되어 있는지 확인합니다.
8. BigQuery 데이터 에이전트를 사용한 분석
이제 조각화된 크로스 클라우드 데이터를 통합하고 Managed Service for Apache Spark를 사용하여 대규모 행동 집계를 실행했으므로 다음 단계는 데이터 분석입니다.
먼저 BigQuery UI에서 새로 생성된 통합 프로필 테이블의 스키마를 검사하여 에이전트에 노출하는 데이터 구조를 시각적으로 파악합니다.
- Google Cloud 콘솔에서 BigQuery로 이동합니다.
- 왼쪽의 탐색기 창에서 프로젝트와
demo_lakehouse데이터 세트를 펼칩니다. unified_customer_profile테이블을 클릭합니다.- 기본 작업공간에서 스키마 탭을 선택합니다.
새 테이블의 스키마를 확인합니다. top_preferences 열은 REPEATED STRUCT (category, brand, sale_price이 포함된 레코드 배열)입니다. 일반적으로 중첩된 배열을 쿼리하려면 UNNEST() 함수를 사용하는 복잡한 SQL이 필요하며 이는 비즈니스 분석가에게 장애물이 될 수 있습니다. 이 특정 테이블을 기반으로 BigQuery 데이터 에이전트를 그라운딩하면 에이전트가 스키마를 이해하고 복잡한 Google 표준 SQL 작업을 내부적으로 처리합니다.
데이터 에이전트 만들기
이 섹션에서는 BigQuery 데이터 에이전트를 만들고 상호작용합니다. 배열을 펼치고 측정항목을 계산하기 위해 복잡한 SQL을 수동으로 작성하는 대신 새로 만든 통합 프로필에 맞게 범위가 지정된 AI 에이전트를 프로비저닝하여 자연어 데이터 탐색을 지원합니다.
- 왼쪽 탐색 창에서 상담사를 찾아 클릭합니다.
- + 새 에이전트를 클릭하여 새 AI 어시스턴트를 초기화합니다.
- 에이전트 구성:
- 상담사 이름:
Retail VIP Analysis Agent - 데이터 소스: 소스 추가를 클릭하고
unified_customer_profile테이블을 검색합니다.
- 추가를 클릭하고 에이전트가 작업공간을 초기화할 때까지 몇 초 정도 기다립니다.
에이전트가 설정되면 명시적인 시스템 요청 사항을 정의하는 것이 중요한 데이터 거버넌스 관행입니다. 시스템 요청 사항을 시맨틱 레이어로 사용하세요. 전사적 비즈니스 정의를 삽입하고, 스키마 복잡성을 처리하고, 분석 가드레일을 설정하면 최종 사용자로부터 기술적 복잡성을 추상화하고 LLM이 통계적으로 유의미하지 않은 데이터에서 결론을 도출하지 못하도록 방지할 수 있습니다.
지침 필드에 다음을 붙여넣습니다.
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
에이전트 프롬프트
복잡한 비즈니스 로직('위험 VIP'의 정확한 정의)과 스키마 처리 요구사항은 시스템 안내에 의거하여 안전하게 관리되므로 데이터 분석가는 장황하고 조건이 많은 프롬프트를 작성할 필요가 없습니다.
채팅 인터페이스에 다음 프롬프트를 입력합니다.
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
생성된 인사이트 평가하기
프롬프트를 제출한 후 기본적으로 생성된 출력을 주의 깊게 검토하여 BigQuery 데이터 에이전트가 관리되는 시맨틱 레이어와 분석 가이드라인 역할을 하면서 시스템 지침을 어떻게 적용했는지 평가합니다.
먼저 데이터 위에 생성된 요약 텍스트를 읽습니다. 에이전트가 '위험에 처한 VIP'라는 간단한 요청을 시스템 요청 사항에 정의된 정확한 측정항목 기준 (예: lifetime_value > 100, cart_adds > 0 및 90일간의 비활성 상태 참조)으로 자동 변환하는 방법을 확인하세요. 이를 통해 에이전트가 비즈니스 로직을 내재화했음을 확인할 수 있으므로 최종 사용자는 일상적인 프롬프트에서 복잡한 로직을 기억하거나 하드코딩할 필요가 없습니다.
그런 다음 SQL 뷰를 펼쳐 생성된 코드를 검사합니다. 에이전트가 사용자의 요청에 따라 수학적으로 타당한 Google 표준 SQL을 구성해야 합니다.
- 동적 시간 범위:
WHERE절에서 타임스탬프 계산을 찾습니다 (일반적으로TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)사용). - 엄격한 스키마 준수:
UNNEST()함수를top_preferences배열에 명시적으로 적용하여 에이전트가 엄격한 스키마 규칙을 준수했는지 확인합니다. 국가별로 가장 빈번한 단일 카테고리를 정확하게 분리하기 위해 일반적으로 공통 테이블 표현식 (CTE) 내에서ROW_NUMBER() OVER()윈도우 함수와 같은 고급 기술을 활용합니다.
자동으로 렌더링된 차트와 데이터 표를 검토합니다. 이 데이터를 통해 핵심 유지 시장 (일반적으로 중국이나 미국과 같은 거래량이 많은 국가가 강조 표시됨)과 보편적으로 우세한 제품 선호도('청바지'가 자주 표시됨)를 시각적으로 확인할 수 있습니다. 네이티브 UI가 명시적인 시각화 코드가 없어도 즉시 사용할 수 있도록 출력을 구조화하는 방식을 확인하세요.
에이전트가 생성한 글머리 기호 형식의 인사이트 텍스트를 읽습니다. 분석 가이드라인을 설정했으므로 데이터 품질 또는 통계적 유의성에 관한 통계를 구체적으로 확인하세요. 상담사가 사용자 수가 매우 적은 국가 (예: 사용자가 몇 명에 불과한 지역)를 표 하단에 명시적으로 표시할 수 있습니다. 단일 데이터 포인트를 기반으로 타겟팅된 마케팅 캠페인을 무작정 환각하는 대신, 에이전트는 이러한 이상치가 대규모 전략에 통계적으로 중요하지 않다고 올바르게 조언합니다. 이를 통해 거버넌스 가드레일을 에이전트에 직접 삽입하면 AI 기반 비즈니스 오산이 효과적으로 방지되는 것을 알 수 있습니다.
9. Gemini 및 MCP로 AI 통계 생성
상담사가 특정 국가의 위험에 처한 VIP라는 기본 타겟 인구통계학적 특성을 성공적으로 식별했습니다. 하지만 분석가의 업무는 통찰력에서 멈춥니다. 이러한 사용자의 재참여를 유도하려면 마케팅팀에서 캠페인을 실행해야 합니다.
모델 컨텍스트 프로토콜 (MCP)을 사용하여 외부 AI 어시스턴트를 BigQuery의 특정 인구통계 목록에 직접 연결하여 맞춤 API를 빌드하지 않고도 데이터 분석에서 AI 기반 작업으로 전환합니다.
BigQuery MCP 서버 구성
아래 블록을 실행하여 mcp.json 구성 파일을 생성합니다. 이 파일은 Gemini CLI가 BigQuery와 안전하게 인터페이스할 수 있도록 필요한 연결 매개변수를 제공합니다.
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
마케팅 이메일 생성
터미널에서 Gemini CLI 도구를 시작하고 BigQuery 레이크하우스를 읽을 수 있도록 MCP 구성 플래그를 명시적으로 전달합니다.
Gemini CLI를 실행합니다.
source env.sh
gemini
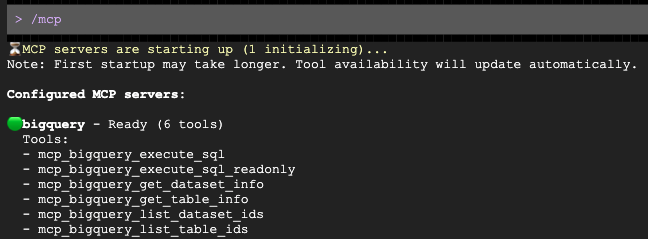
프롬프트가 열리면 타겟 인구통계에 맞는 맞춤형 아웃리치를 작성해 달라고 요청합니다.
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
Gemini가 MCP 서버를 통해 BigQuery를 자동으로 쿼리하고, 인구통계를 파악하고, 이메일을 초안으로 작성합니다.
10. 환경 정리
Google Cloud 계정에 지속적으로 청구되지 않도록 하고 향후 실행을 위해 프로젝트를 완전히 재설정하려면 이 Codelab 중에 생성된 리소스를 삭제해야 합니다.
다음 블록을 실행하여 cleanup.sh 스크립트를 만듭니다. 이 스크립트는 자동 해체 메커니즘 역할을 하여 AlloyDB 클러스터와 인스턴스, BigQuery 데이터 세트, Cloud Storage 버킷을 영구적으로 삭제하여 추가 청구를 방지합니다.
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
정리 스크립트를 실행하여 리소스를 안전하게 삭제합니다.
bash cleanup.sh
11. 축하합니다.
크로스 클라우드 개방형 데이터 레이크하우스를 빌드하고 쿼리했습니다.
배운 내용은 다음과 같습니다.
- BigQuery 제로 ETL 및 Google Cloud Lakehouse를 사용하여 다양한 소스의 데이터를 통합하는 방법
- Managed Service for Apache Spark의 대규모 벡터화된 조인에서 C++ 네이티브 Lightning Engine을 활용하는 방법
- 자연어 탐색을 위해 BigQuery 데이터 에이전트를 사용하는 방법
- 모델 컨텍스트 프로토콜 (MCP)과 Gemini를 사용하여 데이터를 Gemini에 연결하는 방법
다음 단계
- 레이크하우스 문서 살펴보기
- AlloyDB에서 BigQuery로의 제로 ETL 자세히 알아보기
- Lightning Engine에 대해 알아보기