
1. Wprowadzenie
W tym ćwiczeniu zbudujesz otwartą architekturę data lakehouse w wielu chmurach, która łączy silosy danych w AWS, Google Cloud i AlloyDB bez konieczności stosowania złożonych procesów ETL. Będziesz używać Lakehouse jako centralnego centrum informacji, AlloyDB jako źródła danych operacyjnych i usługi zarządzanej dla Apache Spark do wydajnego przetwarzania wektorowego. Na koniec użyjesz Gemini, aby uzyskać z lakehouse wszechstronne statystyki biznesowe.
Załóżmy, że dane transakcyjne (users, orders, order items) znajdują się w operacyjnej bazie danych AlloyDB, dane product są przechowywane w zasobniku AWS S3, a ogromne ilości danych o kliknięciach event logs są przechowywane w Cloud Storage. Musisz połączyć te zbiory danych, aby określić docelową grupę demograficzną dla następnej kampanii marketingowej i wygenerować spersonalizowane e-maile do potencjalnych klientów.
Wymagania wstępne
- Znajomość podstawowych poleceń SQL i terminala.
- Projekt Google Cloud z włączonymi płatnościami.
Czego się nauczysz
- Jak zintegrować różne silosy danych za pomocą BigQuery zero-ETL (AlloyDB) i Lakehouse for Apache Iceberg.
- Jak uruchomić szybkie zadanie profilowania behawioralnego za pomocą usługi zarządzanej dla Apache Spark opartej na natywnym silniku Lightning Engine w C++.
- Jak używać agenta danych BigQuery do przeprowadzania złożonych analiz w języku naturalnym na ujednoliconych danych.
- Jak skonfigurować protokół Model Context Protocol (MCP), aby umożliwić interfejsowi wiersza poleceń Gemini odczytywanie danych z Lakehouse for Apache Iceberg i tworzenie treści marketingowych.
Czego potrzebujesz
- Konto Google Cloud i projekt Google Cloud
- przeglądarka, np. Chrome;
Czego potrzebujesz
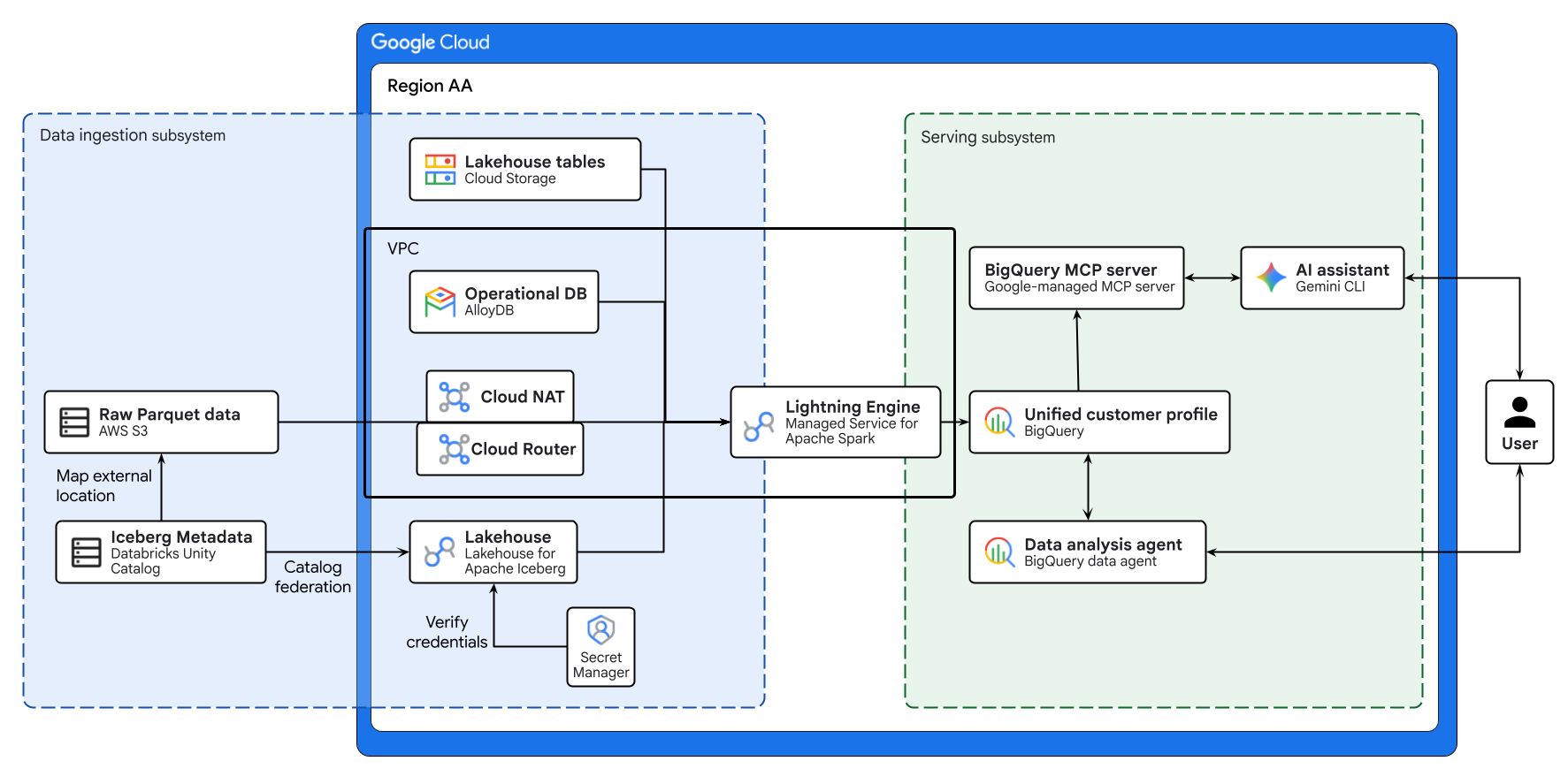
Diagram powyżej ilustruje kompleksowy przepływ danych w przypadku jeziora danych w wielu chmurach utworzonego w ramach tego ćwiczenia. Dane operacyjne z AlloyDB i dane zdalne z AWS S3 są bezpiecznie federowane przy użyciu Lakehouse dla Apache Iceberg. Usługa zarządzana dla Apache Spark przetwarza te różne źródła, aby utworzyć w BigQuery ujednolicony profil klienta. Agent danych BigQuery i zarządzany przez Google serwer MCP BigQuery udostępniane przez interfejs wiersza poleceń Gemini zapewniają intuicyjny interfejs oparty na AI do zaawansowanej analizy danych.
Kluczowe pojęcia
- Otwarta architektura data lakehouse w wielu chmurach: ujednolica silosy danych w środowiskach AWS, Google Cloud i lokalnych bez konieczności stosowania złożonych procesów ETL.
- BigQuery zero-ETL: umożliwia bezpośrednie wysyłanie zapytań do działających baz danych bez konieczności złożonego przenoszenia danych.
- Lakehouse for Apache Iceberg: umożliwia spójne zabezpieczenia i zarządzanie w przypadku przechowywania danych w różnych chmurach przy użyciu formatu Apache Iceberg.
- Lightning Engine: natywny silnik C++ do wykonywania zadań Apache Spark o wysokiej wydajności.
- Model Context Protocol (MCP): łączy Gemini bezpośrednio z Twoim jeziorem danych BigQuery.
2. Konfiguracja i wymagania
Tworzenie projektu Google Cloud
- W konsoli Google Cloud na stronie wyboru projektu wybierz lub utwórz projekt w chmurze Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Uruchamianie Cloud Shell
Z Google Cloud można korzystać zdalnie na laptopie, ale w tym ćwiczeniu użyjesz Google Cloud Shell, czyli środowiska wiersza poleceń działającego w chmurze.
W konsoli Google Cloud kliknij ikonę Cloud Shell na pasku narzędzi w prawym górnym rogu:
Uzyskanie dostępu do środowiska i połączenie się z nim powinno zająć tylko kilka chwil. Po zakończeniu powinno wyświetlić się coś takiego:

Ta maszyna wirtualna zawiera wszystkie potrzebne narzędzia dla programistów. Zawiera również stały katalog domowy o pojemności 5 GB i działa w Google Cloud, co znacznie zwiększa wydajność sieci i usprawnia proces uwierzytelniania. Wszystkie zadania w tym laboratorium możesz wykonać w przeglądarce. Nie musisz niczego instalować.
Inicjowanie środowiska
Otwórz Cloud Shell i ustaw zmienne projektu, aby mieć pewność, że wszystkie polecenia są kierowane do prawidłowej infrastruktury.
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
Zastosuj zmienne w aktywnej sesji:
source ./env.sh
włączyć interfejsy API,
Włącz niezbędne usługi Google Cloud.
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3. Konfigurowanie infrastruktury podstawowej
Zamiast przenosić wszystkie dane do jednego repozytorium za pomocą podatnych na awarie potoków ETL, zbudujesz federacyjną architekturę między chmurami. W prawdziwym przedsiębiorstwie dane są z natury pofragmentowane ze względu na różne wymagania systemowe. Będziesz koordynować te źródła danych:
- AlloyDB (podstawowa baza danych transakcyjnych): przechowuje dane użytkowników, zamówień i elementów zamówienia. Jako działająca na żywo baza danych operacyjnych gwarantuje właściwości ACID wymagane w przypadku transakcji finansowych i aktualizacji profili.
- AWS S3 (dane podstawowe): przechowuje katalog
products. Reprezentowanie starszego systemu zarządzania danymi podstawowymi (MDM) w AWS. - Google Cloud Storage (masywne jezioro danych): przechowuje
events(dzienniki strumieni kliknięć). Dane o wysokiej przepustowości, takie jak dzienniki internetowe, spowodowałyby awarię relacyjnej bazy danych. Pamięć obiektowa zapewnia nieograniczoną skalowalność, a przechowywanie jej w Google Cloud maksymalizuje lokalizację obliczeniową dla silników analitycznych.
Najpierw skonfiguruj sieć bazową. Zarządzane bazy danych Google Cloud, takie jak AlloyDB, wymagają prywatnego połączenia równorzędnego VPC, aby bezpiecznie komunikować się w sieci projektu.
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
Następnie utwórz zbiór danych BigQuery i połączenie z zasobem chmury Lakehouse. Pod względem architektury połączenie zasobu deleguje dostęp do danych na dedykowane konto usługi zarządzane przez Google, co wymusza zasadę jak najmniejszych uprawnień.
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. Aprowizowanie operacyjnej bazy danych
Zainicjuj instancję główną AlloyDB i wstrzyknij do niej kluczowe dane transakcyjne.
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
Gdy baza danych będzie gotowa, musisz utworzyć zewnętrzne połączenie BigQuery z AlloyDB. To połączenie bezpiecznie przechowuje dane logowania i punkt końcowy bazy danych, co umożliwia BigQuery przesyłanie wykonywania SQL bezpośrednio do silnika obliczeniowego AlloyDB (bez ETL).
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
Bezpiecznie przesyłaj tabele transakcyjne do AlloyDB. Użyj serwera proxy uwierzytelniania AlloyDB, aby bezpiecznie połączyć lokalną sesję Cloud Shell z prywatną instancją AlloyDB. Dzięki temu możesz przesyłać dane transakcyjne za pomocą lokalnych narzędzi wiersza poleceń.
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5. Federacja danych podstawowych (promień AWS)
Nasz katalog produktów, który zawiera nieprzetworzone metadane produktów, znajduje się natywnie w AWS S3 w postaci tabel Apache Iceberg. Metadane podlegają zdalnemu katalogowi.
Zamiast tworzyć niestabilne potoki ETL do kopiowania tych danych do Google Cloud, użyjesz Lakehouse dla Apache Iceberg (federacja katalogów REST).
To podejście bez ETL umożliwia Lakehouse i usłudze zarządzanej dla Apache Spark dynamiczne wykrywanie i odczytywanie metadanych Iceberg oraz bazowych plików Parquet bezpośrednio ze środowiska zdalnego.
Jeśli masz aktywne konto AWS i skonfigurowany katalog Databricks Unity, możesz z niego korzystać. W przeciwnym razie możesz zasymulować środowisko za pomocą Google Cloud Storage. Wybierz jedną z tych opcji.
Opcja A. Używanie własnego AWS (natywny Apache Iceberg)
Wymaganie wstępne: ta opcja zakłada, że masz już udostępniony zasobnik AWS S3, połączony jako lokalizacja zewnętrzna w Databricks Unity Catalog, zmapowaną tabelę Iceberg i wygenerowany podmiot zabezpieczeń usługi protokołu OAuth z dostępem do odczytu.
1. Bezpieczne przechowywanie danych logowania
Zakodowanie na stałe długoterminowych tokenów dostępu jest niekorzystnym rozwiązaniem architektonicznym. Identyfikator klienta OAuth Databricks i tajny klucz klienta zapiszesz w usłudze Google Cloud Secret Manager. Usługa Lakehouse będzie pobierać je dynamicznie w czasie działania, aby udostępniać krótkotrwałe tokeny, centralizując zarządzanie danymi logowania.
Aby wygenerować skrypt, uruchom ten blok. (Nie edytuj jeszcze niczego).
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
Następnie uruchom to polecenie, aby automatycznie otworzyć wygenerowany skrypt w edytorze kodu wizualnego nad terminalem.
cloudshell edit create_secret.sh
- W edytorze zastąp symbole zastępcze
<YOUR_...>rzeczywistymi danymi logowania do Databricks. - Sprawdź, czy adres URL Twojego obszaru roboczego nie zawiera znaku
https://ani ukośników na końcu (np.123456789.cloud.databricks.com). - Aby zapisać plik, naciśnij
Ctrl+S(lubCmd+Sna Macu). - Wróć do sesji terminala i wykonaj skrypt:
source create_secret.sh
2. Tworzenie katalogu sfederowanego
Aby uprościć to ćwiczenie, skonfigurujesz katalog tak, aby bezpiecznie przesyłać dane przez publiczny internet. W przypadku zadań produkcyjnych wykonywanie zapytań dotyczących ogromnych zbiorów danych w publicznym internecie wiąże się jednak z niepotrzebnymi kosztami ruchu wychodzącego i nieprzewidywalnymi opóźnieniami. Najlepsze praktyki wymagają skonfigurowania prywatnego połączenia międzychmurowego (CCI) między AWS a Google Cloud, co znacznie obniża koszty ruchu wychodzącego i zapewnia deterministyczną wydajność sieci.
Aby udostępnić sfederowany katalog Lakehouse, użyj interfejsu wiersza poleceń gcloud:
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. Stosowanie powiązań uprawnień z zasadą najmniejszych uprawnień
Gdy w poprzednim kroku utworzysz katalog sfederowany, Google Cloud Lakehouse automatycznie uruchomi zadanie odświeżania w tle, aby co 330 sekund synchronizować pliki manifestu Iceberg.
Musisz przyznać rolę secretAccessor kontu usługi katalogu Lakehouse, aby mogło bezpiecznie pobierać token OAuth Databricks podczas tych synchronizacji w tle i wykonywania zapytań. Brak tego powiązania spowoduje ciche błędy 403, gdy Lakehouse spróbuje zaktualizować katalog.
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. Włączanie wychodzącego dostępu do internetu w usłudze zarządzanej dla Apache Spark
W kolejnym kroku usługa zarządzana dla Apache Spark odczyta zdalne dane AWS. Usługa zarządzana dla Apache Spark Serverless działa w całości w prywatnej sieci VPC bez zewnętrznych adresów IP, więc domyślnie nie może uzyskać dostępu do AWS S3 przez internet. Musisz udostępnić Cloud NAT, aby umożliwić instancjom roboczym Sparka wychodzący dostęp do internetu.
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. Określanie docelowego systemu podrzędnego
Wyeksportuj tę zmienną, aby kolejne zadania Apache Spark dokładnie wiedziały, gdzie wysyłać zapytania o dane AWS, bez konieczności ręcznego wprowadzania zmian w kodzie.
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
Opcja B. Symulowanie środowiska AWS za pomocą Cloud Storage
Jeśli nie masz aktywnego konta AWS, możesz natywnie symulować silos między chmurami za pomocą tabel zarządzanych Lakehouse w Google Cloud Storage.
1. Utwórz tabelę testową Iceberg
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. Określanie docelowego systemu podrzędnego
Standardowe zbiory danych BigQuery używają 3-częściowej struktury przestrzeni nazw (project.dataset.table). Wyeksportuj tę zmienną, aby zadanie Apache Spark w dalszej części procesu było kierowane na dane testowe.
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. Pozyskiwanie logów zdarzeń (promień Google Cloud)
Dane clickstream rosną wykładniczo. Pełne, niezagregowane zdarzenia pierwotne przechowujesz lokalnie w Cloud Storage jako tabele zarządzane Lakehouse.
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. Tworzenie ujednoliconego profilu klienta
Po pełnym wypełnieniu infrastruktury podstawowej możesz utworzyć ujednolicony profil klienta.
Będziesz korzystać z usługi zarządzanej dla Apache Spark opartej na Lightning Engine. Lightning Engine to wydajny akcelerator zapytań w języku C++ w Google Cloud, który jest oparty na technologiach open source, takich jak Apache Gluten i Velox. Automatycznie zwiększa wydajność, maksymalizując efektywność procesora i inteligentnie buforując dane. To podejście jest idealne w przypadku wykonywania złożonych złączeń wielokierunkowych, złożonych funkcji okna lub agregacji behawioralnych w wielu chmurach.
Użyjesz oprogramowania sprzęgającego Spark BigQuery, aby bezpośrednio odczytywać sfederowane zapytania AlloyDB zero-ETL i tabele Lakehouse, wykonywać w Sparku masowe agregacje wektorowe i zapisywać wynikowy ujednolicony profil z powrotem w BigQuery.
Konfigurowanie uprawnień IAM dla usługi zarządzanej dla Apache Spark
Domyślnie Serverless Spark wykonuje zadania wsadowe przy użyciu domyślnego konta usługi Compute Engine. Przed przesłaniem zadania musisz przyznać temu kontu usługi wymagane uprawnienia do wykonywania zadań i zarządzania zadaniami BigQuery.
(Uwaga: nazwa usługi została zmieniona na Usługa zarządzana dla Apache Spark, aby odzwierciedlać standardową terminologię branżową, ale podstawowe polecenia interfejsu API i role IAM nadal używają identyfikatora dataproc).
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
Tworzenie i przesyłanie zadania
Najpierw utwórz skrypt zadania PySpark. Ten skrypt automatycznie wykrywa, czy wybrano opcję A (AWS Federated Catalog) czy opcję B (Google Cloud Mock), na podstawie zmiennej środowiskowej AWS_PRODUCTS_TABLE, definiuje logikę Spark SQL i wykorzystuje natywne funkcje Sparka do manipulowania tablicami w celu obliczenia przedziałów RFM (ostatnie zakupy, częstotliwość, wartość).
Uruchom w Cloud Shell ten blok:
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
Po pełnym złożeniu skryptu i dynamicznym wstrzyknięciu wymaganych konfiguracji prześlij zadanie wsadowe do usługi zarządzanej Apache Spark Serverless.
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
Sprawdzanie wykonania zadania w konsoli
Po przesłaniu zadania wsadowego możesz sprawdzić, czy korzysta ono z przyspieszonego silnika wykonawczego C++:
- W konsoli Google Cloud otwórz usługa zarządzana dla Apache Spark > Serverless > Batches.
- Kliknij zadanie, które jest obecnie uruchomione.
- W okienku szczegółów zadania sprawdź, czy właściwość Poziom ma wartość
Premium, a właściwość Silnik ma wartośćLightning Engine.
8. Analizowanie za pomocą agenta danych BigQuery
Po sfederowaniu rozproszonych danych w różnych chmurach i wykonaniu złożonych agregacji danych o zachowaniach za pomocą usługi zarządzanej dla Apache Spark kolejnym krokiem jest analiza danych.
Najpierw sprawdź schemat nowo utworzonej tabeli ujednoliconych profili w interfejsie BigQuery, aby wizualnie zrozumieć strukturę danych, którą udostępniasz agentowi:
- W konsoli Google Cloud otwórz BigQuery.
- W panelu Eksplorator po lewej stronie rozwiń projekt i zbiór danych
demo_lakehouse. - Kliknij tabelę
unified_customer_profile. - Wybierz kartę Schemat w głównym obszarze roboczym.
Sprawdź schemat nowej tabeli. Kolumna top_preferences to REPEATED STRUCT (tablica rekordów zawierająca category, brand i sale_price). Tradycyjnie wykonywanie zapytań dotyczących zagnieżdżonych tablic wymaga złożonego kodu SQL z użyciem funkcji UNNEST(), co może być trudne dla analityków biznesowych. Dzięki oparciu agenta danych BigQuery na tej konkretnej tabeli, agent rozumie schemat i obsługuje złożone operacje Google standardowa wersja SQL.
Tworzenie agenta danych
W tej sekcji utworzysz agenta danych BigQuery i będziesz z nim wchodzić w interakcje. Zamiast ręcznie pisać złożone zapytania SQL, aby rozpakowywać tablice i obliczać dane, możesz udostępnić agenta AI, który będzie działać w zakresie nowo utworzonego ujednoliconego profilu, co umożliwi eksplorowanie danych w języku naturalnym.
- W panelu nawigacyjnym po lewej stronie znajdź i kliknij Agenci.
- Kliknij + Nowy agent, aby zainicjować nowego asystenta AI.
- Skonfiguruj agenta:
- Nazwa agenta:
Retail VIP Analysis Agent - Źródła danych: kliknij Dodaj źródło i wyszukaj tabelę
unified_customer_profile.
- Kliknij Dodaj i poczekaj kilka sekund, aż agent zainicjuje swój obszar roboczy.
Po utworzeniu agenta zdefiniowanie wyraźnych instrukcji systemowych jest kluczową praktyką zarządzania danymi. Użyj instrukcji systemowych jako warstwy semantycznej. Osadzając definicje biznesowe w całej firmie, radząc sobie ze złożonością schematów i ustalając wytyczne analityczne, odciągasz użytkownika od złożoności technicznej i uniemożliwiasz LLM wyciąganie wniosków z danych o statystycznie małej istotności.
Wklej ten tekst w polu Instrukcja:
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
Wydaj agentowi prompt
Złożona logika biznesowa (dokładna definicja „zagrożonego VIP-a”) i wymagania dotyczące obsługi schematu podlegają bezpiecznie instrukcjom systemowym, więc analityk danych nie musi pisać rozbudowanego prompta z wieloma warunkami.
W interfejsie czatu wpisz ten prompt:
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
Ocena wygenerowanych informacji
Po przesłaniu promptu dokładnie sprawdź wygenerowane dane wyjściowe, aby ocenić, jak agent danych BigQuery zastosował instrukcje systemowe, pełniąc funkcję zarówno zarządzanej warstwy semantycznej, jak i analitycznego zabezpieczenia.
Najpierw przeczytaj tekst podsumowania wygenerowany nad danymi. Zwróć uwagę, jak agent automatycznie tłumaczy Twoją prostą prośbę o „zagrożonych klientów VIP” na dokładne progi danych zdefiniowane w instrukcjach systemowych (np. odwołując się do lifetime_value > 100, cart_adds > 0 i 90 dni nieaktywności). Potwierdza to, że agent przyswoił logikę biznesową, co oznacza, że użytkownicy nie muszą zapamiętywać ani na stałe kodować złożonej logiki w codziennych promptach.
Następnie rozwiń widok SQL, aby sprawdzić wygenerowany kod. Agent powinien na podstawie Twoich instrukcji utworzyć poprawny pod względem matematycznym kod w standardowej wersji SQL Google:
- Dynamiczne przedziały czasowe: poszukaj obliczeń sygnatury czasowej w klauzuli
WHERE(zwykle z użyciemTIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)). - Ścisłe przestrzeganie schematu: sprawdź, czy agent przestrzegał ścisłych reguł schematu, jawnie stosując funkcję
UNNEST()do tablicytop_preferences. Aby dokładnie wyodrębnić najczęstszą kategorię w danym kraju, zwykle stosuje się zaawansowane techniki, takie jakROW_NUMBER() OVER()funkcja okna w zapytaniu CTE (Common Table Expression).
Sprawdź automatycznie wygenerowany wykres i tabelę danych. Dane te wizualnie ujawnią Twoje główne rynki utrzymania klientów (zwykle wyróżniając kraje o dużej liczbie klientów, takie jak Chiny czy Stany Zjednoczone) wraz z ich powszechnie dominującymi preferencjami produktowymi (często „dżinsy”). Zwróć uwagę, jak interfejs natywny strukturyzuje dane wyjściowe, aby można było z nich od razu korzystać bez konieczności pisania kodu wizualizacji.
Przeczytaj tekst Statystyki wygenerowany przez agenta. Ponieważ masz już ustalone zasady analityczne, poszukaj statystyk dotyczących jakości danych lub istotności statystycznej. U dołu tabeli możesz zobaczyć kraje wyraźnie oznaczone przez agenta, w których liczba użytkowników jest bardzo mała (np. regiony, w których jest tylko kilku użytkowników). Zamiast tworzyć ukierunkowaną kampanię marketingową na podstawie jednego punktu danych, agent prawidłowo poinformuje, że te anomalie są statystycznie nieistotne w przypadku strategii na dużą skalę. Pokazuje to, jak wbudowanie zabezpieczeń zarządzania bezpośrednio w agenta skutecznie zapobiega błędnym obliczeniom biznesowym opartym na AI.
9. Generowanie obserwacji AI za pomocą Gemini i MCP
Agentowi udało się zidentyfikować główną grupę docelową: osoby VIP w określonych krajach, które są narażone na ryzyko. Praca analityka kończy się jednak na wyciągnięciu wniosków. Aby ponownie zaangażować tych użytkowników, zespół marketingowy musi przeprowadzić kampanię.
Użyjesz protokołu Model Context Protocol (MCP), aby połączyć zewnętrznego asystenta AI bezpośrednio z tą konkretną listą danych demograficznych w BigQuery. Dzięki temu przejdziesz od analizy danych do działań opartych na AI bez tworzenia niestandardowych interfejsów API.
Konfigurowanie serwera BigQuery MCP
Uruchom blok poniżej, aby wygenerować plik konfiguracyjny mcp.json. Ten plik zawiera niezbędne parametry połączenia, dzięki którym interfejs wiersza poleceń Gemini może bezpiecznie komunikować się z BigQuery.
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
Generowanie e-maila marketingowego
Uruchom interfejs wiersza poleceń Gemini w terminalu, jawnie przekazując flagę konfiguracji MCP, aby umożliwić mu odczytanie architektury data lakehouse BigQuery.
Uruchom interfejs wiersza poleceń Gemini.
source env.sh
gemini
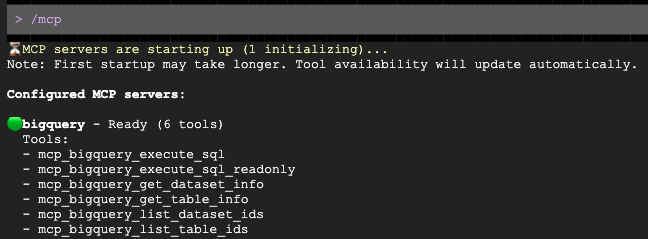
Gdy otworzy się prompt, poproś go o przygotowanie spersonalizowanego komunikatu do Twojej grupy docelowej:
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
Gemini automatycznie wyśle zapytanie do BigQuery za pomocą serwera MCP, zidentyfikuje dane demograficzne i przygotuje dla Ciebie e-maila.
10. Porządkowanie środowiska
Aby uniknąć obciążenia konta Google Cloud bieżącymi opłatami i przygotować projekt do przyszłych uruchomień, musisz usunąć zasoby utworzone podczas tego ćwiczenia.
Aby utworzyć skrypt cleanup.sh, uruchom ten blok. Ten skrypt działa jako automatyczny mechanizm zamykania, który trwale usuwa klaster i instancję AlloyDB, zbiory danych BigQuery oraz zasobnik Cloud Storage, aby zapobiec dalszemu naliczaniu opłat.
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
Uruchom skrypt czyszczenia, aby bezpiecznie usunąć zasoby:
bash cleanup.sh
11. Gratulacje!
Udało Ci się utworzyć otwartą architekturę data lakehouse w wielu chmurach i wykonać na niej zapytanie.
Wiesz już:
- Jak sfederować dane z różnych źródeł za pomocą BigQuery Zero-ETL i Google Cloud Lakehouse.
- Jak wykorzystać natywny silnik Lightning w C++ w przypadku ogromnych złączeń wektorowych w usłudze zarządzanej dla Apache Spark.
- Jak używać agenta danych BigQuery do eksplorowania danych za pomocą języka naturalnego.
- Jak połączyć dane z Gemini za pomocą protokołu Model Context Protocol (MCP) i Gemini.
Co dalej?
- Zapoznaj się z dokumentacją Lakehouse
- Więcej informacji o integracji AlloyDB z BigQuery bez ETL
- Dowiedz się więcej o Lightning Engine