
1. Introdução
Neste codelab, você vai criar um data lakehouse aberto entre nuvens que unifica silos de dados na AWS, no Google Cloud e no AlloyDB sem a necessidade de ETL complexo. Você vai usar o Lakehouse como o hub de inteligência central, o AlloyDB como uma fonte de dados operacionais e o Serviço Gerenciado para Apache Spark para processamento vetorizado de alta performance. Por fim, você vai usar o Gemini para extrair insights de negócios eficientes do seu lakehouse.
Imagine que seus dados transacionais (users, orders, order items) estão em um banco de dados operacional do AlloyDB, seus dados de product estão em um bucket do AWS S3 e um grande volume de event logs de clickstream está armazenado no Cloud Storage. É necessário unir esses conjuntos de dados para identificar os dados demográficos segmentados da sua próxima campanha de marketing e gerar e-mails de contato personalizados.
Pré-requisitos
- Familiaridade com comandos básicos de SQL e terminal.
- Ter um projeto do Google Cloud com o faturamento ativado.
O que você vai aprender
- Como integrar silos de dados diferentes usando o zero-ETL do BigQuery (AlloyDB) e o Lakehouse para Apache Iceberg.
- Como executar um job de criação de perfil comportamental de alta velocidade usando o Serviço Gerenciado para Apache Spark com tecnologia do Lightning Engine nativo em C++.
- Como usar o agente de dados do BigQuery para fazer análises complexas de linguagem natural em dados unificados.
- Como configurar o Protocolo de Contexto de Modelo (MCP) para permitir que a CLI do Gemini leia seu Lakehouse para Apache Iceberg e crie conteúdo de marketing.
O que é necessário
- Uma conta e um projeto do Google Cloud
- Um navegador da Web, como o Chrome
O que é necessário
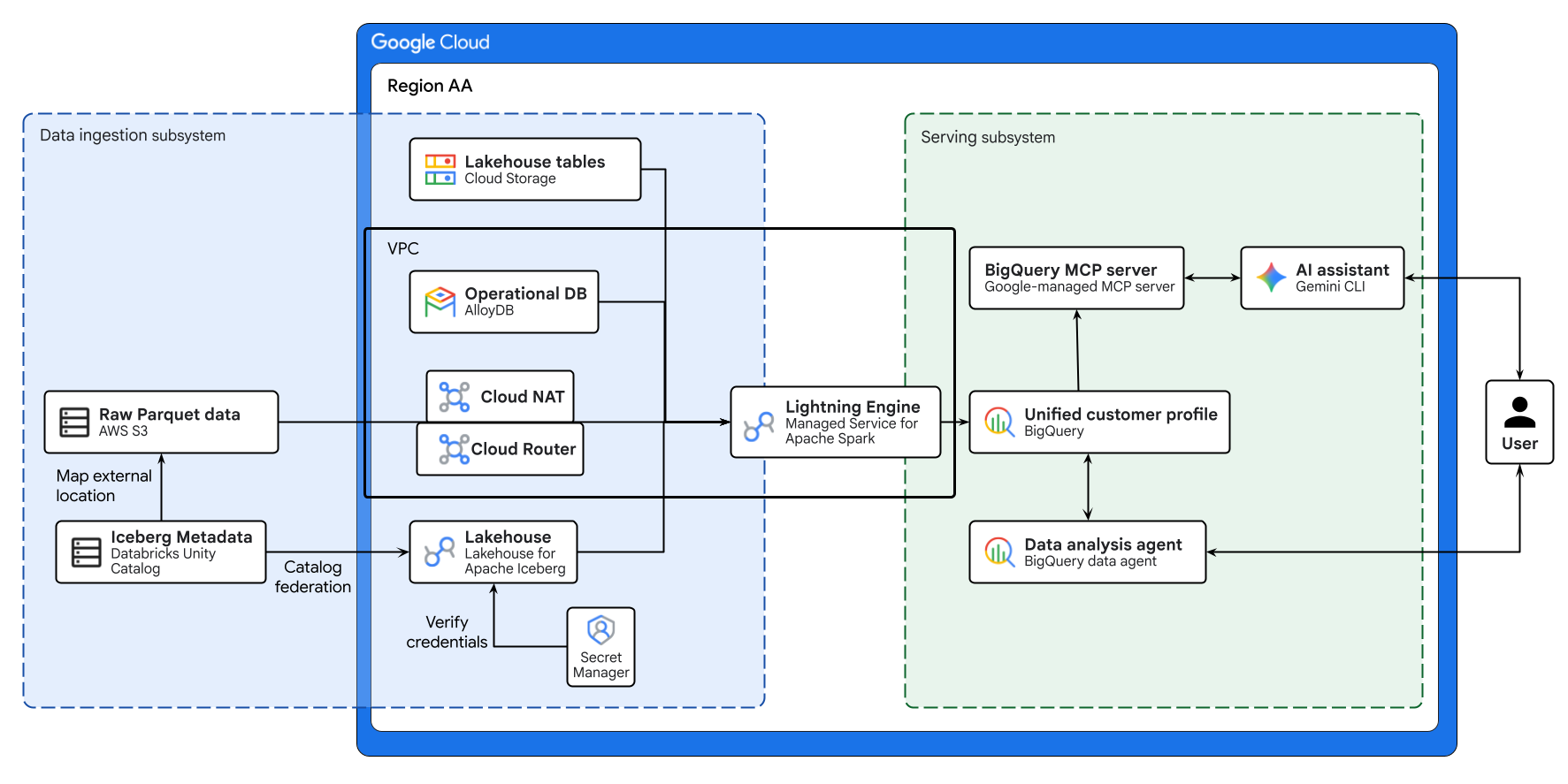
O diagrama acima ilustra o fluxo completo do lakehouse entre nuvens criado neste codelab. Os dados operacionais do AlloyDB e os dados remotos do AWS S3 são federados com segurança usando o Lakehouse para Apache Iceberg. O Serviço Gerenciado para Apache Spark processa essas fontes diferentes para criar um perfil de cliente unificado no BigQuery. Por fim, um agente de dados do BigQuery e um servidor MCP do BigQuery gerenciado pelo Google via CLI do Gemini oferecem uma interface intuitiva e baseada em IA para análise de dados avançada.
Conceitos principais
- Data lakehouse aberto entre nuvens:unifica silos de dados em ambientes da AWS, do Google Cloud e locais sem a necessidade de ETL complexo.
- BigQuery zero-ETL:permite consultar diretamente bancos de dados operacionais sem movimentação complexa de dados.
- Lakehouse para Apache Iceberg:permite segurança e governança consistentes no armazenamento entre nuvens usando o formato Apache Iceberg.
- Lightning Engine:mecanismo nativo em C++ para execução de alto desempenho do Apache Spark.
- Protocolo de Contexto de Modelo (MCP): conecta o Gemini diretamente ao seu lakehouse do BigQuery.
2. Configuração e requisitos
Criar um projeto do Google Cloud
- No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto na nuvem do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
Inicie o Cloud Shell
Embora o Google Cloud e o Spanner possam ser operados remotamente do seu laptop, neste codelab usaremos o Google Cloud Shell, um ambiente de linha de comando executado no Cloud.
No Console do Google Cloud, clique no ícone do Cloud Shell na barra de ferramentas superior à direita:
O provisionamento e a conexão com o ambiente levarão apenas alguns instantes para serem concluídos: Quando o processamento for concluído, você verá algo como:

Essa máquina virtual contém todas as ferramentas de desenvolvimento necessárias. Ela oferece um diretório principal persistente de 5 GB, além de ser executada no Google Cloud. Isso aprimora o desempenho e a autenticação da rede. Neste codelab, todo o trabalho pode ser feito com um navegador. Você não precisa instalar nada.
Inicializar o ambiente
Abra o Cloud Shell e defina as variáveis do projeto para garantir que todos os comandos sejam direcionados à infraestrutura correta.
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
Aplique as variáveis à sua sessão ativa:
source ./env.sh
Ativar APIs
Ative os serviços necessários do Google Cloud.
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3. Configurar a infraestrutura principal
Em vez de mover todos os dados para um único repositório usando pipelines de ETL frágeis, você vai criar uma arquitetura federada entre nuvens. Em uma empresa real, os dados são inerentemente fragmentados devido a diferentes requisitos do sistema. Você vai orquestrar as seguintes fontes de dados:
- AlloyDB (banco de dados transacional principal): armazena dados de usuários, pedidos e itens de pedidos. Como um banco de dados operacional ativo, ele garante as propriedades ACID necessárias para transações financeiras e atualizações de perfil.
- AWS S3 (dados principais): armazena o catálogo
products. Representa um sistema legado de gerenciamento de dados mestres (MDM) na AWS. - Google Cloud Storage (data lake massivo): armazena
events(registros de clickstream). Dados de alto desempenho, como registros da Web, falhariam em um banco de dados relacional. O armazenamento de objetos oferece escalonabilidade infinita, e mantê-lo no Google Cloud maximiza a localidade de computação para seus mecanismos de análise.
Primeiro, configure a rede subjacente. Os bancos de dados gerenciados do Google Cloud, como o AlloyDB, exigem uma conexão de peering de VPC privada para se comunicar com segurança na rede do projeto.
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
Em seguida, crie um conjunto de dados do BigQuery e uma conexão a recursos do Cloud do Lakehouse. Arquiteturalmente, uma conexão de recurso delega o acesso aos dados a uma conta de serviço dedicada gerenciada pelo Google, aplicando o princípio de privilégio mínimo.
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. Provisionar o banco de dados operacional
Provisione uma instância principal do AlloyDB e injete seus dados transacionais essenciais.
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
Depois que o banco de dados estiver pronto, crie uma conexão externa do BigQuery com o AlloyDB. Essa conexão armazena com segurança as credenciais e o endpoint do banco de dados, permitindo que o BigQuery envie a execução de SQL diretamente para o mecanismo de computação do AlloyDB (zero-ETL).
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
Envie as tabelas transacionais com segurança para o AlloyDB. Use o proxy de autenticação do AlloyDB para conectar com segurança sua sessão local do Cloud Shell à instância privada do AlloyDB. Isso permite enviar os dados transacionais usando ferramentas de linha de comando locais.
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5. Federar os dados mestre (hub da AWS)
Nosso catálogo de produtos, que contém metadados de itens brutos, reside nativamente no AWS S3 como tabelas do Apache Iceberg. Os metadados são regidos por um catálogo remoto.
Em vez de criar pipelines de ETL frágeis para copiar esses dados para o Google Cloud, você vai usar o Lakehouse para Apache Iceberg (federação de catálogo REST).
Essa abordagem de zero ETL permite que o Lakehouse e o Serviço Gerenciado para Apache Spark descubram e leiam dinamicamente os metadados do Iceberg e os arquivos Parquet subjacentes diretamente do seu ambiente remoto.
Se você tiver uma conta da AWS ativa e o Catálogo do Unity do Databricks configurado, poderá usar isso. Caso contrário, crie um ambiente simulado usando o Google Cloud Storage. Escolha uma delas.
Opção A: usar sua própria AWS (Apache Iceberg nativo)
Pré-requisito: essa opção pressupõe que você já provisionou um bucket do AWS S3, o conectou como um local externo no catálogo do Unity do Databricks, mapeou uma tabela do Iceberg e gerou uma entidade de serviço OAuth com acesso de leitura.
1. Armazenamento seguro de credenciais
Codificar tokens de acesso de longa duração é um antipadrão de arquitetura. Você vai armazenar o ID do cliente OAuth e a chave secreta do Databricks no Secret Manager do Google Cloud. O serviço Lakehouse vai buscar esses dados dinamicamente no ambiente de execução para vender tokens de curta duração, centralizando a governança de credenciais.
Execute o bloco a seguir para gerar o script. (Não edite nada ainda).
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
Em seguida, execute o comando a seguir para abrir automaticamente o script gerado no editor de código visual acima do terminal.
cloudshell edit create_secret.sh
- No editor, substitua os marcadores de posição
<YOUR_...>pelas suas credenciais reais do Databricks. - Verifique se o URL do espaço de trabalho não inclui
https://ou barras à direita (por exemplo,123456789.cloud.databricks.com). - Pressione
Ctrl+S(ouCmd+Sno Mac) para salvar o arquivo. - Volte à sessão do terminal e execute o script:
source create_secret.sh
2. Criar o catálogo federado
Para simplificar este codelab, você vai configurar o catálogo para percorrer a Internet pública com segurança. No entanto, para cargas de trabalho de produção, consultar grandes conjuntos de dados pela Internet pública gera custos de saída desnecessários e latência imprevisível. A prática recomendada exige a configuração de um Cross-Cloud Interconnect (CCI) privado entre a AWS e o Google Cloud, o que reduz significativamente os custos de saída e garante um desempenho de rede determinístico.
Use a CLI gcloud para provisionar o catálogo federado do Lakehouse:
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. Aplicar vinculações de privilégio mínimo do IAM
Quando você provisionou o catálogo federado na etapa anterior, o Google Cloud Lakehouse iniciou automaticamente um job de atualização em segundo plano para sincronizar os manifestos do Iceberg a cada 330 segundos.
É necessário conceder o papel secretAccessor à conta de serviço do catálogo do Lakehouse para que ela possa buscar com segurança o token OAuth do Databricks durante essas sincronizações em segundo plano e execuções de consultas. A falta dessa vinculação vai resultar em erros 403 silenciosos quando o Lakehouse tentar atualizar o catálogo.
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. Ativar a Internet de saída para o Serviço Gerenciado para Apache Spark
Em uma etapa posterior, o Serviço Gerenciado para Apache Spark vai ler os dados remotos da AWS. Como o Serviço Gerenciado para Apache Spark sem servidor é executado inteiramente em uma rede VPC particular sem endereços IP externos, ele não pode acessar o AWS S3 pela internet por padrão. É necessário provisionar um Cloud NAT para permitir que os trabalhadores do Spark tenham acesso à Internet de saída.
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. Defina o destino downstream
Exporte essa variável para que os jobs downstream do Apache Spark saibam exatamente onde consultar os dados da AWS sem exigir mudanças manuais no código.
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
Opção B: simular o ambiente da AWS usando o Cloud Storage
Se você não tiver uma conta ativa da AWS, poderá simular o silo entre nuvens de forma nativa usando tabelas gerenciadas do Lakehouse no Google Cloud Storage.
1. Criar a tabela Iceberg simulada
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. Defina o destino downstream
Os conjuntos de dados padrão do BigQuery usam uma estrutura de namespace de três partes (project.dataset.table). Exporte essa variável para que o job downstream do Apache Spark tenha como destino os dados simulados.
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. Ingerir registros de eventos (hub do Google Cloud)
Os dados de clickstream crescem exponencialmente. Você armazena os eventos brutos completos e não agregados localmente no Cloud Storage como tabelas gerenciadas do Lakehouse.
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. Criar um perfil unificado do cliente
Com sua infraestrutura bruta totalmente preenchida, é hora de criar um perfil unificado do cliente.
Você vai usar o Serviço Gerenciado para Apache Spark com tecnologia do Lightning Engine. O Lightning Engine é o acelerador de consultas nativo de C++ de alto desempenho do Google Cloud, criado com base em tecnologias de código aberto como Apache Gluten e Velox, que aumenta automaticamente a execução maximizando a eficiência da CPU e armazenando dados em cache de maneira inteligente. Essa abordagem é ideal para realizar junções massivas de várias vias, janelas complexas ou agregações comportamentais em várias nuvens.
Você vai usar o conector do Spark BigQuery para ler diretamente as consultas federadas do AlloyDB zero-ETL e as tabelas do Lakehouse, realizar as agregações vetorizadas massivas de forma nativa no Spark e gravar o perfil unificado resultante de volta no BigQuery.
Configurar permissões do IAM para o Serviço Gerenciado para Apache Spark
Por padrão, o Serverless Spark executa jobs em lote usando a conta de serviço padrão do Compute Engine. Antes de enviar o job, conceda a essa conta de serviço as permissões necessárias para executar a carga de trabalho e gerenciar jobs do BigQuery.
Observação: embora o nome do serviço tenha mudado para Serviço Gerenciado para Apache Spark para refletir a terminologia padrão do setor, os comandos da API e os papéis do IAM ainda usam o identificador dataproc.
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
Criar e enviar o job
Primeiro, crie o script do job do PySpark. Esse script detecta automaticamente se você escolheu a Opção A (catálogo federado da AWS) ou a Opção B (simulação do Google Cloud) com base na variável de ambiente AWS_PRODUCTS_TABLE, define a lógica do Spark SQL e usa a manipulação de matrizes nativa do Spark para calcular as janelas de RFM (recência, frequência e valor monetário).
Execute o bloco a seguir no Cloud Shell.
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
Com o script totalmente montado e as configurações necessárias injetadas dinamicamente, envie o job em lote para o Managed Apache Spark Serverless.
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
Verificar a execução do job no console
Depois que o job em lote for enviado, verifique se ele está usando o mecanismo de execução acelerada em C++:
- No console do Google Cloud, acesse Serviço gerenciado para Apache Spark > Sem servidor > Lotes.
- Clique no job que está em execução.
- No painel de detalhes do job, verifique se a propriedade Nível está definida como
Premiume se o mecanismo está definido comoLightning Engine.
8. Analisar com o agente de dados do BigQuery
Agora que você federou os dados fragmentados entre nuvens e executou as agregações comportamentais pesadas usando o Serviço Gerenciado para Apache Spark, a próxima etapa é a análise de dados.
Primeiro, inspecione o esquema da tabela de perfil unificado recém-criada na interface do BigQuery para entender visualmente a estrutura de dados que você está expondo ao agente:
- No console do Google Cloud, acesse BigQuery.
- No painel "Explorer" à esquerda, expanda seu projeto e o conjunto de dados
demo_lakehouse. - Clique na tabela
unified_customer_profile. - Selecione a guia "Esquema" no espaço de trabalho principal.
Verifique o esquema da nova tabela. A coluna top_preferences é um REPEATED STRUCT (uma matriz de registros que contém category, brand e sale_price). Tradicionalmente, a consulta de matrizes aninhadas exige um SQL complexo usando a função UNNEST(), o que pode ser um obstáculo para analistas de negócios. Ao embasar um agente de dados do BigQuery nessa tabela específica, o agente entende o esquema e processa operações complexas do SQL padrão do Google nos bastidores.
Criar o agente de dados
Nesta seção, você vai criar e interagir com um agente de dados do BigQuery. Em vez de escrever manualmente um SQL complexo para desagrupar matrizes e calcular métricas, você vai provisionar um agente de IA com escopo específico para o perfil unificado recém-criado, permitindo a análise de dados em linguagem natural.
- No painel de navegação à esquerda, localize e clique em Agentes.
- Clique em + Novo agente para inicializar um novo assistente de IA.
- Configure o agente:
- Nome do agente:
Retail VIP Analysis Agent - Fontes de dados: clique em Adicionar fonte e pesquise a tabela
unified_customer_profile.
- Clique em Adicionar e aguarde alguns segundos para que o agente inicialize o espaço de trabalho.
Depois que o agente é estabelecido, definir instruções do sistema explícitas é uma prática essencial de governança de dados. Use as instruções do sistema como uma camada semântica. Ao incorporar definições de negócios em toda a empresa, lidar com complexidades de esquema e estabelecer restrições analíticas, você abstrai a complexidade técnica do usuário final e impede que o LLM tire conclusões de dados estatisticamente insignificantes.
Cole o seguinte no campo Instrução:
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
Comandar o agente
Como a lógica de negócios complexa (a definição exata de um "VIP em risco") e os requisitos de processamento de esquema são regidos com segurança pelas instruções do sistema, o analista de dados não precisa escrever um comando detalhado e com muitas condições.
Na interface de chat, insira o seguinte comando:
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
Avalie o insight gerado
Depois de enviar o comando, revise cuidadosamente a saída gerada nativamente para avaliar como o agente de dados do BigQuery aplicou suas instruções do sistema, atuando como uma camada semântica governada e um controle de segurança analítico.
Primeiro, leia o texto de resumo gerado acima dos dados. Observe como o agente traduz automaticamente seu pedido simples de "VIPs em risco" nos limites exatos de métricas definidos nas instruções do sistema (por exemplo, referenciando lifetime_value > 100, cart_adds > 0 e 90 dias de inatividade). Isso confirma que o agente internalizou sua lógica de negócios, o que significa que os usuários finais nunca precisam memorizar ou codificar uma lógica complexa nos comandos diários.
Em seguida, expanda a visualização SQL para inspecionar o código gerado. O agente precisa ter criado um SQL padrão do Google matematicamente correto com base nas suas instruções:
- Períodos dinâmicos:procure o cálculo do carimbo de data/hora na cláusula
WHERE(normalmente usandoTIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)). - Adesão estrita ao esquema:confirme se o agente obedeceu às suas regras de esquema estritas aplicando explicitamente a função
UNNEST()à matriztop_preferences. Para isolar com precisão a categoria mais frequente por país, geralmente são usadas técnicas avançadas, como uma função de janelaROW_NUMBER() OVER()em uma expressão de tabela comum (CTE, na sigla em inglês).
Analise o gráfico e a tabela de dados renderizados automaticamente. Os dados vão revelar visualmente seus principais mercados de retenção (geralmente destacando países de alto volume, como China ou Estados Unidos) e as afinidades de produto dominantes em todo o mundo (com frequência "Jeans"). Observe como a interface nativa estrutura a saída para consumo imediato sem exigir um código de visualização explícito.
Leia o texto com marcadores Insights gerado pelo agente. Como você estabeleceu restrições analíticas, procure um insight sobre Qualidade dos dados ou Significância estatística. O agente pode sinalizar explicitamente países na parte de baixo da tabela com contagens de usuários muito baixas (por exemplo, regiões com apenas alguns usuários). Em vez de alucinar cegamente uma campanha de marketing segmentada com base em um único ponto de dados, o agente vai aconselhar corretamente que essas anomalias são estatisticamente insignificantes para uma estratégia em grande escala. Isso demonstra como incorporar proteções de governança diretamente no agente evita cálculos incorretos de negócios baseados em IA.
9. Gerar insights de IA com o Gemini e o MCP
O agente identificou com sucesso o principal grupo demográfico de destino: VIPs em risco em países específicos. No entanto, o trabalho de um analista termina com o insight. Para engajar novamente esses usuários, a equipe de marketing precisa executar uma campanha.
Você vai usar o Protocolo de Contexto de Modelo (MCP) para conectar um assistente de IA externo diretamente a essa lista demográfica específica no BigQuery, fazendo a transição da análise de dados para a ação orientada por IA sem criar APIs personalizadas.
Configurar o servidor da MCP do BigQuery
Execute o bloco abaixo para gerar o arquivo de configuração mcp.json. Esse arquivo fornece os parâmetros de conexão necessários para que a CLI do Gemini possa interagir com o BigQuery de maneira segura.
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
Gerar um e-mail de marketing
Inicie a ferramenta da CLI do Gemini no seu terminal, transmitindo explicitamente a flag de configuração da MCP para permitir que ela leia seu data lakehouse do BigQuery.
Execute a CLI do Gemini.
source env.sh
gemini
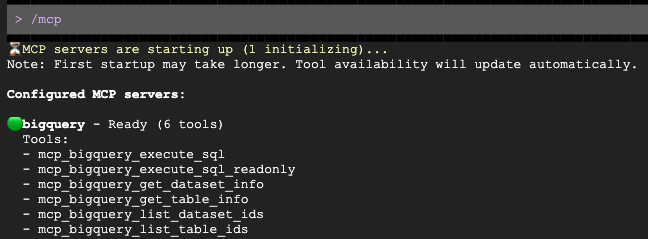
Quando o comando abrir, peça para ele criar uma abordagem personalizada para seu grupo demográfico desejado:
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
O Gemini vai consultar automaticamente o BigQuery pelo servidor MCP, identificar a demografia e criar o e-mail para você.
10. Limpar o ambiente
Para evitar cobranças contínuas na sua conta do Google Cloud e redefinir o projeto para execuções futuras, exclua os recursos criados durante este codelab.
Execute o bloco a seguir para criar o script cleanup.sh. Esse script funciona como um mecanismo de encerramento automatizado, removendo permanentemente o cluster e a instância do AlloyDB, os conjuntos de dados do BigQuery e o bucket do Cloud Storage para evitar mais faturamento.
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
Execute o script de limpeza para excluir seus recursos com segurança:
bash cleanup.sh
11. Parabéns!
Você criou e consultou um data lakehouse aberto entre nuvens.
Abordamos os seguintes assuntos:
- Como federar dados de fontes diferentes usando o BigQuery Zero-ETL e o Google Cloud Lakehouse.
- Como aproveitar o Lightning Engine nativo em C++ nas junções vetorizadas massivas do Serviço Gerenciado para Apache Spark.
- Como usar o agente de dados do BigQuery para exploração em linguagem natural.
- Como conectar seus dados ao Gemini usando o Protocolo de Contexto de Modelo (MCP) e o Gemini.
A seguir
- Consulte a documentação do lakehouse.
- Saiba mais sobre o ETL zero do AlloyDB para o BigQuery
- Leia sobre o Lightning Engine