
1. Введение
В этом практическом занятии вы создадите кросс-облачную платформу для работы с открытыми данными, которая объединит разрозненные хранилища данных в AWS, Google Cloud и AlloyDB без необходимости сложных ETL-процессов. Вы будете использовать Lakehouse в качестве центрального интеллектуального центра, AlloyDB — в качестве источника оперативных данных, а управляемый сервис Apache Spark — для высокопроизводительной векторизованной обработки. Наконец, вы используете Gemini для получения ценных бизнес-аналитических данных из вашей платформы.
Представьте, что ваши транзакционные данные ( users , orders , order items ) хранятся в работающей базе данных AlloyDB, данные product — в хранилище AWS S3, а огромные массивы event logs кликов — в Cloud Storage. Вам необходимо объединить эти наборы данных, чтобы определить целевую аудиторию для вашей следующей маркетинговой кампании и сгенерировать персонализированные электронные письма для рассылки.
Предварительные требования
- Знание основ SQL и команд терминала.
- Проект Google Cloud с включенной функцией выставления счетов.
Что вы узнаете
- Как интегрировать разрозненные хранилища данных с помощью BigQuery zero-ETL (AlloyDB) и Lakehouse для Apache Iceberg.
- Как запустить высокоскоростное задание поведенческого профилирования с использованием управляемой службы для Apache Spark на базе нативного C++ движка Lightning Engine.
- Как использовать агент данных BigQuery для выполнения сложного анализа естественного языка на основе объединенных данных.
- Как настроить протокол контекста модели (MCP), чтобы позволить интерфейсу командной строки Gemini считывать данные из вашего хранилища Lakehouse для Apache Iceberg и создавать черновики маркетингового контента.
Что вам понадобится
- Аккаунт Google Cloud и проект Google Cloud
- Веб-браузер, например Chrome.
Что вам понадобится
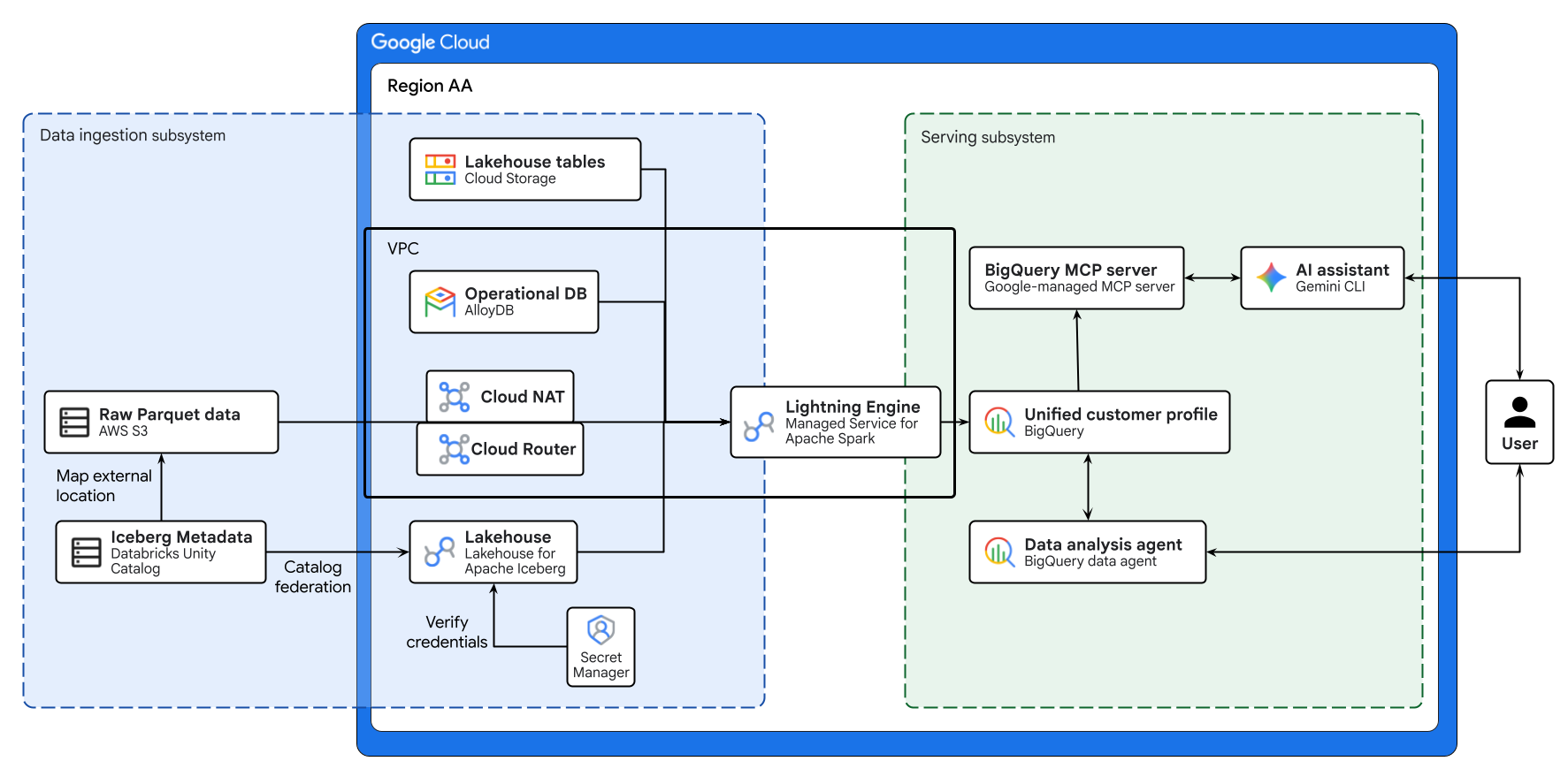
Приведенная выше диаграмма иллюстрирует сквозной поток кросс-облачной инфраструктуры Lakehouse, созданной в рамках этого практического занятия. Операционные данные из AlloyDB и удаленные данные из AWS S3 безопасно объединяются с помощью Lakehouse для Apache Iceberg. Управляемая служба для Apache Spark обрабатывает эти разрозненные источники для создания единого профиля клиента в BigQuery. Наконец, агент данных BigQuery и управляемый Google сервер BigQuery MCP через Gemini CLI обеспечивают интуитивно понятный интерфейс на основе искусственного интеллекта для расширенного анализа данных.
Ключевые понятия
- Кросс-облачное решение для работы с открытыми данными: объединяет разрозненные хранилища данных в средах AWS, Google Cloud и локальных средах без необходимости сложных процессов ETL.
- BigQuery zero-ETL: позволяет напрямую запрашивать данные из действующих баз данных без сложного перемещения данных.
- Lakehouse для Apache Iceberg: обеспечивает согласованную безопасность и управление в кросс-облачных хранилищах с использованием формата Apache Iceberg.
- Lightning Engine: нативный движок на C++ для высокопроизводительного выполнения Apache Spark.
- Протокол контекста модели (MCP): обеспечивает прямое подключение Gemini к вашему серверу BigQuery Lakehouse.
2. Настройка и требования
Создайте проект в Google Cloud.
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud .
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
Запустить Cloud Shell
Хотя Google Cloud можно управлять удаленно с ноутбука, в этом практическом занятии вы будете использовать Google Cloud Shell — среду командной строки, работающую в облаке.
В консоли Google Cloud нажмите на значок Cloud Shell на панели инструментов в правом верхнем углу:
Подготовка и подключение к среде займут всего несколько минут. После завершения вы должны увидеть что-то подобное:

Эта виртуальная машина содержит все необходимые инструменты разработки. Она предоставляет постоянный домашний каталог объемом 5 ГБ и работает в облаке Google, что значительно повышает производительность сети и аутентификацию. Вся работа в этом практическом задании может выполняться в браузере. Вам не нужно ничего устанавливать.
Инициализация среды
Откройте Cloud Shell и настройте переменные проекта, чтобы все команды были направлены на правильную инфраструктуру.
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
Примените переменные к активной сессии:
source ./env.sh
Включить API
Включите необходимые сервисы Google Cloud.
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3. Создание основной инфраструктуры
Вместо перемещения всех данных в единое хранилище с помощью ненадежных ETL-конвейеров, вы построите федеративную кросс-облачную архитектуру. В реальных условиях предприятия данные по своей природе фрагментированы из-за различных системных требований. Вам предстоит управлять следующими источниками данных:
- AlloyDB (базовая транзакционная база данных): хранит данные пользователей, заказов и позиций заказа. Будучи оперативной базой данных, она гарантирует свойства ACID, необходимые для финансовых транзакций и обновления профилей.
- AWS S3 (основные данные): хранит каталог
products. Представляет собой устаревшую систему управления основными данными (MDM) на платформе AWS. - Google Cloud Storage (озеро больших данных): хранит
events(журналы кликов). Высокопроизводительные данные, такие как веб-журналы, могут привести к сбою реляционной базы данных. Объектное хранилище обеспечивает неограниченную масштабируемость, а размещение его в Google Cloud максимизирует локальность вычислительных ресурсов для ваших аналитических систем.
Сначала настройте базовую сеть. Для работы управляемых баз данных Google Cloud, таких как AlloyDB, требуется частное пиринговое соединение VPC для безопасной связи внутри сети вашего проекта.
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
Далее создайте набор данных BigQuery и подключение к облачному ресурсу Lakehouse. С архитектурной точки зрения, подключение к ресурсу делегирует доступ к данным выделенной учетной записи службы, управляемой Google, обеспечивая принцип минимальных привилегий.
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. Создание операционной базы данных.
Создайте основной экземпляр AlloyDB и внедрите в него критически важные транзакционные данные.
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
После того, как база данных будет готова, необходимо создать внешнее соединение BigQuery с AlloyDB. Это соединение надежно хранит учетные данные базы данных и конечную точку, позволяя BigQuery передавать выполнение SQL-запросов непосредственно вычислительному движку AlloyDB (нулевая процедура ETL).
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
Безопасная передача транзакционных таблиц в AlloyDB. Используйте AlloyDB Auth Proxy для безопасного подключения вашей локальной сессии Cloud Shell к частному экземпляру AlloyDB. Это позволит вам передавать транзакционные данные с помощью локальных инструментов командной строки.
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5. Объединение основных данных (AWS Spoke)
Наш каталог продукции, содержащий исходные метаданные товаров, хранится в AWS S3 в виде таблиц Apache Iceberg. Метаданные управляются удаленным каталогом.
Вместо создания ненадежных ETL-конвейеров для копирования этих данных в Google Cloud, вы будете использовать Lakehouse для Apache Iceberg (федерация REST-каталогов).
Такой подход, исключающий необходимость ETL-процессов, позволяет Lakehouse и Managed Service for Apache Spark динамически обнаруживать и считывать метаданные Iceberg и базовые файлы Parquet непосредственно из удаленной среды.
Если у вас есть активная учетная запись AWS и настроенный Databricks Unity Catalog, вы можете использовать его. В противном случае вы можете имитировать свою среду с помощью Google Cloud Storage. Выберите один из вариантов.
Вариант А: Использовать собственную платформу AWS (собственный Apache Iceberg).
Предварительное условие: Этот вариант предполагает, что вы уже создали корзину AWS S3, подключили ее как внешнее местоположение в Databricks Unity Catalog, сопоставили таблицу Iceberg и сгенерировали субъект службы OAuth с правами на чтение.
1. Безопасное хранение учетных данных
Жесткое кодирование долгосрочных токенов доступа — это архитектурный антипаттерн. Вы будете хранить идентификатор клиента и секрет Databricks OAuth в Google Cloud Secret Manager. Сервис Lakehouse будет динамически получать их во время выполнения для выдачи краткосрочных токенов, централизуя управление учетными данными.
Выполните следующий блок кода для генерации скрипта. (Пока ничего не редактируйте).
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
Затем выполните следующую команду, чтобы автоматически открыть сгенерированный скрипт в визуальном редакторе кода над вашим терминалом.
cloudshell edit create_secret.sh
- В редакторе замените заполнители
<YOUR_...>на ваши фактические учетные данные Databricks. - Убедитесь, что URL-адрес вашей рабочей области не содержит
https://или косых черт в конце (например,123456789.cloud.databricks.com). - Нажмите
Ctrl+S(илиCmd+Sна Mac), чтобы сохранить файл. - Вернитесь в терминал и выполните скрипт:
source create_secret.sh
2. Создайте федеративный каталог.
Для упрощения в этом практическом задании вы настроите каталог для безопасной передачи данных через общедоступный интернет. Однако для производственных нагрузок запросы к большим наборам данных через общедоступный интернет приводят к ненужным затратам на исходящий трафик и непредсказуемой задержке. Рекомендуется настроить частное межоблачное соединение (CCI) между AWS и Google Cloud, что значительно снижает затраты на исходящий трафик и обеспечивает детерминированную производительность сети.
Используйте интерфейс командной строки gcloud для развертывания федеративного каталога Lakehouse:
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. Примените привязки IAM с минимальными привилегиями.
Когда вы на предыдущем шаге создали федеративный каталог, Google Cloud Lakehouse автоматически запустил фоновое обновление для синхронизации манифестов Iceberg каждые 330 секунд.
Необходимо предоставить учетной записи службы каталога Lakehouse роль secretAccessor , чтобы она могла безопасно получать токен OAuth Databricks во время фоновой синхронизации и выполнения запросов. Отсутствие этой привязки приведет к скрытым ошибкам 403 при попытке Lakehouse обновить каталог.
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. Включите исходящий интернет-трафик для управляемой службы Apache Spark.
На следующем этапе управляемая служба для Apache Spark прочитает удаленные данные из AWS. Поскольку управляемая служба для Apache Spark Serverless работает полностью в частной сети VPC без внешних IP-адресов, она по умолчанию не может получить доступ к AWS S3 через Интернет. Необходимо настроить Cloud NAT, чтобы разрешить рабочим процессам Spark исходящий доступ в Интернет.
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. Определите целевую группу на последующих этапах.
Экспортируйте эту переменную, чтобы последующие задания Apache Spark точно знали, куда запрашивать данные AWS, без необходимости вносить изменения в код вручную.
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
Вариант B: Имитация среды AWS с помощью облачного хранилища.
Если у вас нет активной учетной записи AWS, вы можете имитировать межоблачное разрозненное хранилище непосредственно в облаке, используя управляемые таблицы Lakehouse в Google Cloud Storage.
1. Создайте фиктивную таблицу «Айсберг».
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. Определите целевую группу на последующих этапах.
Стандартные наборы данных BigQuery используют трехкомпонентную структуру пространства имен ( project.dataset.table ). Экспортируйте эту переменную, чтобы последующее задание Apache Spark использовало в качестве целевой модели данные.
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. Прием журналов событий (Google Cloud Spoke)
Объем данных о кликах растет экспоненциально. Полные, неагрегированные необработанные события хранятся локально в облачном хранилище в виде управляемых таблиц Lakehouse.
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. Создайте единый профиль клиента.
После того, как ваша исходная инфраструктура полностью заполнена, настало время создать единый профиль клиента.
Вы будете использовать управляемый сервис для Apache Spark на базе Lightning Engine . Lightning Engine — это высокопроизводительный ускоритель запросов на C++ от Google Cloud, построенный на основе технологий с открытым исходным кодом, таких как Apache Gluten и Velox, который автоматически повышает эффективность выполнения за счет максимальной эффективности использования ЦП и интеллектуального кэширования данных. Такой подход идеально подходит для выполнения масштабных многосторонних объединений, сложных оконных операций или поведенческой агрегации в нескольких облаках.
Вы будете использовать коннектор Spark BigQuery для прямого чтения объединенных запросов AlloyDB с нулевым временем выполнения (zero-ETL) и таблиц Lakehouse, выполнения масштабных векторизованных агрегаций непосредственно в Spark и записи полученного унифицированного профиля обратно в BigQuery.
Настройка разрешений IAM для управляемой службы Apache Spark
По умолчанию Serverless Spark выполняет пакетные задания, используя учетную запись службы Compute Engine по умолчанию. Перед отправкой задания необходимо предоставить этой учетной записи службы необходимые разрешения для выполнения рабочей нагрузки и управления заданиями BigQuery.
(Примечание: Хотя название службы изменилось на Managed Service for Apache Spark в соответствии со стандартной отраслевой терминологией, в базовых командах API и ролях IAM по-прежнему используется идентификатор dataproc).
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
Создайте и отправьте вакансию
Сначала создайте скрипт задания PySpark. Этот скрипт автоматически определяет, выбрали ли вы вариант A (AWS Federated Catalog) или вариант B (Google Cloud Mock) на основе переменной среды AWS_PRODUCTS_TABLE , определяет логику Spark SQL и использует встроенные функции Spark для работы с массивами, чтобы рассчитать окна RFM (давность, частота, денежная стоимость).
Выполните следующий блок кода в Cloud Shell.
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
После полной сборки скрипта и динамического внедрения необходимых конфигураций отправьте пакетное задание в управляемый бессерверный Apache Spark.
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
Проверьте выполнение задания в консоли.
После отправки пакетного задания вы можете убедиться, что оно использует механизм ускоренного выполнения C++:
- В консоли Google Cloud перейдите в раздел «Управляемые сервисы для Apache Spark» > «Бессерверные вычисления » > «Пакеты» .
- Щёлкните по заданию, которое выполняется в данный момент.
- В панели сведений о задании убедитесь, что для свойства Tier установлено значение
Premium, а для свойства Engine —Lightning Engine.
8. Анализ с помощью агента данных BigQuery.
Теперь, когда вы объединили разрозненные данные из разных облаков и выполнили ресурсоемкие агрегации поведенческих данных с помощью управляемой службы для Apache Spark, следующим шагом является анализ данных.
Для начала изучите схему только что созданной унифицированной таблицы профиля в пользовательском интерфейсе BigQuery, чтобы визуально понять структуру данных, которую вы предоставляете агенту:
- В консоли Google Cloud перейдите в раздел BigQuery .
- В левой панели Проводника разверните свой проект и набор данных
demo_lakehouse. - Щелкните по таблице
unified_customer_profile. - В главном рабочем пространстве выберите вкладку «Схема».
Проверьте схему новой таблицы. Столбец top_preferences представляет собой REPEATED STRUCT (массив записей, содержащий category , brand и sale_price ). Традиционно запросы к вложенным массивам требуют сложного SQL-запроса с использованием функции UNNEST() , что может стать препятствием для бизнес-аналитиков. Привязка агента данных BigQuery к этой конкретной таблице позволяет агенту автоматически понимать схему и обрабатывать сложные операции стандартного SQL Google.
Создайте агент данных.
В этом разделе вы создадите агент обработки данных BigQuery и будете с ним взаимодействовать. Вместо того чтобы вручную писать сложные SQL-запросы для разворачивания массивов и вычисления метрик, вы настроите агента ИИ, специально адаптированного под ваш новый унифицированный профиль, что позволит вам проводить анализ данных на естественном языке.
- В левой панели навигации найдите и щелкните «Агенты» .
- Нажмите кнопку «+ Новый агент» , чтобы инициализировать нового ИИ-помощника.
- Настройте агента:
- Имя агента :
Retail VIP Analysis Agent - Источники данных : Нажмите «Добавить источник» и выполните поиск в таблице
unified_customer_profile.
- Нажмите «Добавить» и подождите несколько секунд, пока агент инициализирует свое рабочее пространство.
После установки агента определение четких системных инструкций является критически важной практикой управления данными. Используйте системные инструкции в качестве семантического слоя. Внедряя общекорпоративные бизнес-определения, обрабатывая сложности схем и устанавливая аналитические ограничения, вы абстрагируете техническую сложность от конечного пользователя и предотвращаете выводы LLM на основе статистически незначимых данных.
Вставьте следующее в поле «Инструкция» :
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
Попросите агента
Поскольку сложная бизнес-логика (точное определение «персонального уязвимого пользователя») и требования к обработке схем надежно регулируются системными инструкциями, аналитику данных не нужно писать многословный, перегруженный условиями запрос.
В интерфейсе чата введите следующую команду:
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
Оцените полученные данные.
После отправки запроса внимательно изучите сгенерированный вывод, чтобы оценить, как агент данных BigQuery выполнил ваши системные инструкции, выступая одновременно в качестве управляемого семантического слоя и аналитического механизма контроля.
Сначала прочтите сгенерированный над данными сводный текст. Обратите внимание, как агент автоматически преобразует ваш простой запрос к «VIP-клиентам, находящимся в группе риска» в точные пороговые значения метрик, определенные в ваших системных инструкциях (например, lifetime_value > 100, cart_adds > 0 и 90 дней неактивности). Это подтверждает, что агент усвоил вашу бизнес-логику, а значит, конечным пользователям никогда не нужно запоминать или жестко прописывать сложную логику в своих ежедневных запросах.
Далее разверните представление SQL, чтобы просмотреть сгенерированный код. Агент должен был составить математически корректный стандартный SQL-код Google на основе ваших инструкций:
- Динамические временные окна: найдите вычисление метки времени в предложении
WHERE(обычно используетсяTIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)). - Строгое соблюдение схемы: Убедитесь, что агент соблюдал ваши строгие правила схемы, явно применив функцию
UNNEST()к массивуtop_preferences. Для точного выделения единственной наиболее часто встречающейся категории для каждой страны обычно используются более сложные методы, такие как оконная функцияROW_NUMBER() OVER()в рамках общего табличного выражения (CTE).
Просмотрите автоматически сгенерированный график и таблицу данных. Данные визуально покажут ваши основные рынки удержания клиентов (обычно выделяются страны с высоким объемом продаж, такие как Китай или США) наряду с их общепризнанными предпочтениями в отношении товаров (часто это «джинсы»). Обратите внимание, как встроенный пользовательский интерфейс структурирует вывод для немедленного просмотра без необходимости написания явного кода визуализации.
Внимательно прочтите текст с аналитическими выводами, сгенерированный агентом. Поскольку вы установили аналитические ограничения, обратите особое внимание на выводы, касающиеся качества данных или статистической значимости . Вы можете увидеть, как агент явно отмечает страны внизу таблицы с очень низким количеством пользователей (например, регионы с небольшим числом пользователей). Вместо того чтобы слепо прогнозировать целевую маркетинговую кампанию на основе одной точки данных, агент правильно укажет, что эти аномалии статистически незначимы для крупномасштабной стратегии. Это демонстрирует, как внедрение аналитических ограничений непосредственно в работу агента эффективно предотвращает ошибки в бизнесе, вызванные ИИ.
9. Получайте аналитические данные с помощью ИИ, используя Gemini и MCP.
Агент успешно определил основную целевую демографическую группу: VIP-персоны, находящиеся в группе риска, в определенных странах. Однако работа аналитика заканчивается на этом выводе. Для повторного привлечения этих пользователей маркетинговая команда должна запустить кампанию.
Вы будете использовать протокол контекста модели (MCP) для прямого подключения внешнего ИИ-помощника к этому конкретному списку демографических данных в BigQuery, переходя от анализа данных к действиям, управляемым ИИ, без создания пользовательских API.
Настройте сервер BigQuery MCP.
Выполните приведенный ниже блок кода, чтобы сгенерировать конфигурационный файл mcp.json. Этот файл содержит необходимые параметры подключения, позволяющие Gemini CLI безопасно взаимодействовать с BigQuery.
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
Создать маркетинговое письмо
Запустите инструмент Gemini CLI из терминала, явно передав флаг конфигурации MCP, чтобы разрешить ему считывать данные из вашей базы данных BigQuery Lakehouse.
Запустите Gemini CLI.
source env.sh
gemini
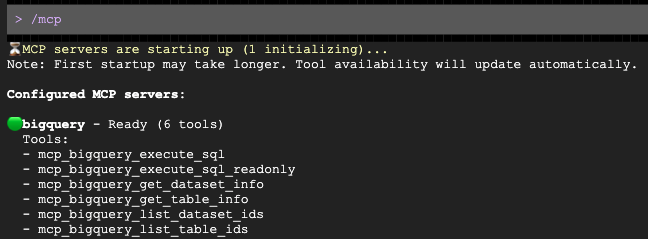
После открытия окна запроса попросите его составить персонализированное обращение к вашей целевой аудитории:
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
Gemini автоматически выполнит запрос к BigQuery через сервер MCP, определит демографические данные и составит для вас электронное письмо!
10. Очистка окружающей среды
Чтобы избежать постоянных списаний средств с вашего аккаунта Google Cloud и корректно запустить проект в будущем, необходимо удалить ресурсы, созданные в ходе выполнения этого практического задания.
Выполните следующий блок кода, чтобы создать скрипт cleanup.sh . Этот скрипт действует как автоматический механизм очистки, навсегда удаляя кластер и экземпляр AlloyDB, наборы данных BigQuery и ваш сегмент Cloud Storage, чтобы предотвратить дальнейшее выставление счетов.
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
Запустите скрипт очистки, чтобы безопасно удалить ваши ресурсы:
bash cleanup.sh
11. Поздравляем!
Вы успешно создали и выполнили запросы к межоблачной платформе для хранения открытых данных.
Вы узнали:
- Как объединить данные из разрозненных источников с помощью BigQuery Zero-ETL и Google Cloud Lakehouse.
- Как использовать встроенный в C++ механизм Lightning Engine в управляемых сервисах для выполнения масштабных векторизованных объединений в Apache Spark.
- Как использовать BigQuery Data Agent для анализа естественного языка.
- Как связать ваши данные с Gemini, используя протокол контекста модели (MCP) и Gemini.
Что дальше?
- Изучите документацию Lakehouse
- Узнайте больше об AlloyDB zero-ETL для BigQuery
- Почитайте о двигателе Lightning Engine.