
1. บทนำ
ใน Codelab นี้ คุณจะได้สร้าง Data Lakehouse แบบเปิดที่ทำงานข้ามระบบคลาวด์ซึ่งรวมข้อมูลที่แยกส่วนไว้ใน AWS, Google Cloud และ AlloyDB โดยไม่ต้องใช้ ETL ที่ซับซ้อน คุณจะใช้ Lakehouse เป็นฮับข้อมูลอัจฉริยะส่วนกลาง, AlloyDB เป็นแหล่งข้อมูลการดำเนินงาน และบริการที่มีการจัดการสำหรับ Apache Spark สำหรับการประมวลผลแบบเวกเตอร์ที่มีประสิทธิภาพสูง สุดท้าย คุณจะใช้ Gemini เพื่อดึงข้อมูลเชิงลึกทางธุรกิจที่มีประสิทธิภาพจาก Lakehouse
สมมติว่าข้อมูลธุรกรรม (users, orders, order items) อยู่ในฐานข้อมูล AlloyDB ที่ใช้งานอยู่ ข้อมูล product อยู่ในที่เก็บข้อมูล AWS S3 และระบบจัดเก็บคลิกสตรีมจำนวนมาก event logs ไว้ใน Cloud Storage คุณต้องรวมชุดข้อมูลเหล่านี้เพื่อระบุข้อมูลประชากรเป้าหมายสําหรับแคมเปญการตลาดถัดไป และสร้างอีเมลการติดต่อที่ปรับเปลี่ยนในแบบของคุณ
ข้อกำหนดเบื้องต้น
- คุ้นเคยกับคำสั่ง SQL และคำสั่งเทอร์มินัลพื้นฐาน
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
สิ่งที่คุณจะได้เรียนรู้
- วิธีผสานรวมข้อมูลที่แยกกันโดยใช้ BigQuery Zero-ETL (AlloyDB) และ Lakehouse สำหรับ Apache Iceberg
- วิธีเรียกใช้งานการสร้างโปรไฟล์พฤติกรรมความเร็วสูงโดยใช้ Managed Service สำหรับ Apache Spark ที่ขับเคลื่อนโดย Lightning Engine แบบเนทีฟ C++
- วิธีใช้ตัวแทนข้อมูล BigQuery เพื่อทำการวิเคราะห์ภาษาธรรมชาติที่ซับซ้อนกับข้อมูลแบบรวม
- วิธีกำหนดค่า Model Context Protocol (MCP) เพื่ออนุญาตให้ Gemini CLI อ่านจาก Lakehouse สำหรับ Apache Iceberg และร่างเนื้อหาทางการตลาด
สิ่งที่คุณต้องมี
- บัญชี Google Cloud และโปรเจ็กต์ Google Cloud
- เว็บเบราว์เซอร์ เช่น Chrome
สิ่งที่คุณต้องมี
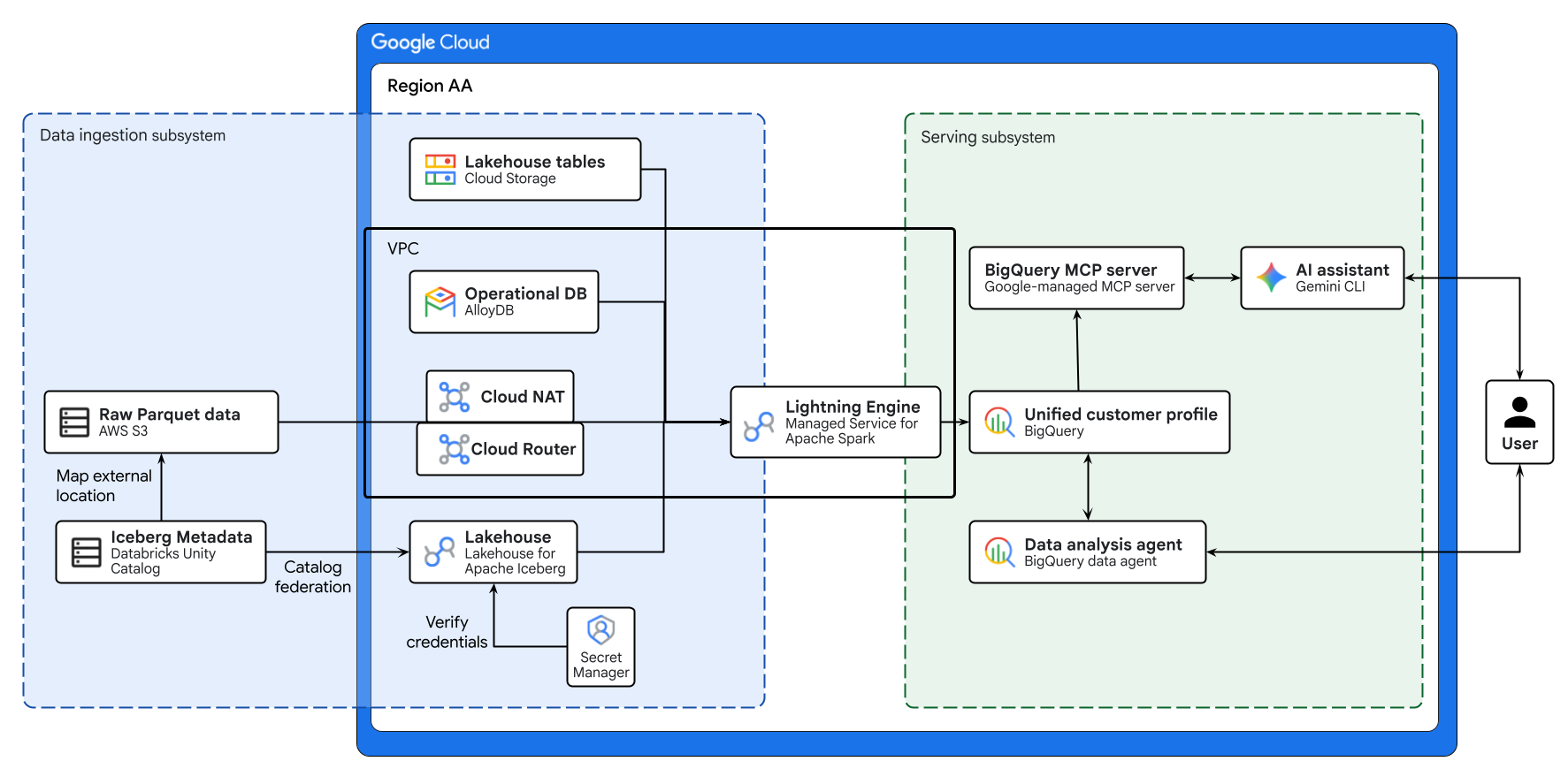
แผนภาพด้านบนแสดงโฟลว์แบบครบวงจรของ Lakehouse แบบข้ามระบบคลาวด์ที่สร้างขึ้นใน Codelab นี้ ระบบจะรวมข้อมูลการปฏิบัติงานจาก AlloyDB และข้อมูลระยะไกลจาก AWS S3 อย่างปลอดภัยโดยใช้ Lakehouse สำหรับ Apache Iceberg Managed Service สำหรับ Apache Spark จะประมวลผลแหล่งข้อมูลที่แตกต่างกันเหล่านี้เพื่อสร้างโปรไฟล์ลูกค้าแบบรวมใน BigQuery สุดท้ายนี้ BigQuery Data Agent และเซิร์ฟเวอร์ BigQuery MCP ที่ Google จัดการผ่าน Gemini CLI จะมีอินเทอร์เฟซที่ใช้งานง่ายซึ่งขับเคลื่อนด้วย AI สำหรับการวิเคราะห์ข้อมูลขั้นสูง
แนวคิดหลัก
- ที่เก็บข้อมูลแบบ Data Lakehouse แบบเปิดข้ามระบบคลาวด์: รวมไซโลข้อมูลในสภาพแวดล้อม AWS, Google Cloud และสภาพแวดล้อมภายในองค์กรโดยไม่ต้องใช้ ETL ที่ซับซ้อน
- BigQuery Zero-ETL: อนุญาตให้ค้นหาฐานข้อมูลการดำเนินงานได้โดยตรงโดยไม่ต้องมีการเคลื่อนย้ายข้อมูลที่ซับซ้อน
- Lakehouse สำหรับ Apache Iceberg: ช่วยให้มั่นใจได้ถึงความปลอดภัยและการกำกับดูแลที่สอดคล้องกันในที่เก็บข้อมูลข้ามระบบคลาวด์โดยใช้รูปแบบ Apache Iceberg
- Lightning Engine: เครื่องมือ C++ ดั้งเดิมสำหรับการดำเนินการ Apache Spark ที่มีประสิทธิภาพสูง
- Model Context Protocol (MCP): เชื่อมต่อ Gemini กับ Lakehouse ของ BigQuery โดยตรง
2. การตั้งค่าและข้อกำหนด
สร้างโปรเจ็กต์ Google Cloud
- ในคอนโซล Google Cloud ในหน้าตัวเลือกโปรเจ็กต์ ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
เริ่มต้น Cloud Shell
แม้ว่าคุณจะใช้งาน Google Cloud จากระยะไกลจากแล็ปท็อปได้ แต่ใน Codelab นี้คุณจะใช้ Google Cloud Shell ซึ่งเป็นสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานในระบบคลาวด์
จาก คอนโซล Google Cloud ให้คลิกไอคอน Cloud Shell ในแถบเครื่องมือด้านขวาบน
การจัดสรรและเชื่อมต่อกับสภาพแวดล้อมจะใช้เวลาเพียงไม่กี่นาที เมื่อเสร็จแล้ว คุณควรเห็นข้อความคล้ายกับตัวอย่างต่อไปนี้

เครื่องเสมือนนี้มาพร้อมเครื่องมือพัฒนาซอฟต์แวร์ทั้งหมดที่คุณต้องการ โดยมีไดเรกทอรีหลักแบบถาวรขนาด 5 GB และทำงานบน Google Cloud ซึ่งช่วยเพิ่มประสิทธิภาพเครือข่ายและการตรวจสอบสิทธิ์ได้อย่างมาก คุณสามารถทำงานทั้งหมดใน Codelab นี้ได้ภายในเบราว์เซอร์ คุณไม่จำเป็นต้องติดตั้งอะไร
เริ่มต้นสภาพแวดล้อม
เปิด Cloud Shell แล้วตั้งค่าตัวแปรโปรเจ็กต์เพื่อให้แน่ใจว่าคำสั่งทั้งหมดจะกำหนดเป้าหมายไปยังโครงสร้างพื้นฐานที่ถูกต้อง
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
ใช้ตัวแปรกับเซสชันที่ใช้งานอยู่
source ./env.sh
เปิดใช้ API
เปิดใช้บริการ Google Cloud ที่จำเป็น
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3. ตั้งค่าโครงสร้างพื้นฐานหลัก
คุณจะสร้างสถาปัตยกรรมแบบรวมศูนย์ข้ามระบบคลาวด์แทนที่จะย้ายข้อมูลทั้งหมดไปยังที่เก็บข้อมูลเดียวผ่านไปป์ไลน์ ETL ที่เปราะบาง ในองค์กรจริง ข้อมูลจะกระจัดกระจายโดยธรรมชาติเนื่องจากข้อกำหนดของระบบที่แตกต่างกัน คุณจะจัดระเบียบแหล่งข้อมูลต่อไปนี้
- AlloyDB (DB ธุรกรรมหลัก): จัดเก็บข้อมูลผู้ใช้ คำสั่งซื้อ และ order_items ในฐานะฐานข้อมูลการดำเนินงานแบบเรียลไทม์ ฐานข้อมูลนี้รับประกันคุณสมบัติ ACID ที่จำเป็นสำหรับธุรกรรมทางการเงินและการอัปเดตโปรไฟล์
- AWS S3 (ข้อมูลหลัก): จัดเก็บ
productsแคตตาล็อก แสดงถึงระบบการจัดการข้อมูลหลัก (MDM) เดิมใน AWS - Google Cloud Storage (ที่เก็บข้อมูลขนาดใหญ่): จัดเก็บ
events(บันทึกสตรีมการคลิก) ข้อมูลที่มีปริมาณงานสูง เช่น บันทึกของเว็บ จะทำให้ฐานข้อมูลเชิงสัมพันธ์ขัดข้อง ที่เก็บข้อมูลออบเจ็กต์มีความสามารถในการปรับขนาดได้ไม่จำกัด และการเก็บไว้ใน Google Cloud จะช่วยเพิ่มประสิทธิภาพการประมวลผลสำหรับเครื่องมือวิเคราะห์
ก่อนอื่นให้กำหนดค่าเครือข่ายพื้นฐาน ฐานข้อมูลที่มีการจัดการของ Google Cloud เช่น AlloyDB ต้องมีการเชื่อมต่อเพียร์ VPC ส่วนตัวเพื่อสื่อสารอย่างปลอดภัยภายในเครือข่ายโปรเจ็กต์
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
จากนั้นสร้างชุดข้อมูล BigQuery และการเชื่อมต่อทรัพยากรระบบคลาวด์ Lakehouse ในเชิงสถาปัตยกรรม การเชื่อมต่อทรัพยากรจะมอบสิทธิ์การเข้าถึงข้อมูลให้กับบัญชีบริการที่มีการจัดการโดย Google โดยเฉพาะ ซึ่งเป็นการบังคับใช้หลักการให้สิทธิ์ขั้นต่ำที่สุด
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. จัดสรรฐานข้อมูลการดำเนินงาน
จัดสรรอินสแตนซ์หลักของ AlloyDB และแทรกข้อมูลธุรกรรมที่มีความสำคัญต่อการดำเนินงาน
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
เมื่อฐานข้อมูลพร้อมแล้ว คุณต้องสร้างการเชื่อมต่อภายนอก BigQuery กับ AlloyDB การเชื่อมต่อนี้จะจัดเก็บข้อมูลเข้าสู่ระบบและปลายทางของฐานข้อมูลอย่างปลอดภัย ทำให้ BigQuery สามารถส่งการดำเนินการ SQL ลงไปยังเครื่องมือประมวลผล AlloyDB ได้โดยตรง (zero-ETL)
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
ส่งตารางธุรกรรมไปยัง AlloyDB อย่างปลอดภัย ใช้พร็อกซีการตรวจสอบสิทธิ์ AlloyDB เพื่อเชื่อมต่อเซสชัน Cloud Shell ในเครื่องกับอินสแตนซ์ AlloyDB ส่วนตัวอย่างปลอดภัย ซึ่งจะช่วยให้คุณพุชข้อมูลธุรกรรมโดยใช้เครื่องมือบรรทัดคำสั่งในเครื่องได้
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5. รวมข้อมูลหลัก (AWS Spoke)
แคตตาล็อกสินค้าของเราซึ่งมีข้อมูลเมตาของสินค้าดิบจะอยู่ใน AWS S3 โดยเป็นตาราง Apache Iceberg ข้อมูลเมตาได้รับการควบคุมโดยแคตตาล็อกระยะไกล
แทนที่จะสร้างไปป์ไลน์ ETL ที่เปราะบางเพื่อคัดลอกข้อมูลนี้ไปยัง Google Cloud คุณจะใช้ Lakehouse สำหรับ Apache Iceberg (การรวมแคตตาล็อก REST)
แนวทางแบบไม่มี ETL นี้ช่วยให้ Lakehouse และ Managed Service สำหรับ Apache Spark ค้นหาและอ่านข้อมูลเมตาของ Iceberg และไฟล์ Parquet ที่เกี่ยวข้องจากสภาพแวดล้อมระยะไกลได้โดยตรง
หากมีบัญชี AWS ที่ใช้งานอยู่และกำหนดค่า Databricks Unity Catalog ไว้ คุณก็ใช้บัญชีนั้นได้ หรือคุณจะจำลองสภาพแวดล้อมโดยใช้ Google Cloud Storage ก็ได้ โปรดเลือกอย่างใดอย่างหนึ่ง
ตัวเลือก A: ใช้ AWS ของคุณเอง (Apache Iceberg แบบเนทีฟ)
ข้อกำหนดเบื้องต้น: ตัวเลือกนี้ถือว่าคุณได้จัดสรร Bucket AWS S3 เชื่อมต่อเป็นตำแหน่งภายนอกใน Databricks Unity Catalog แมปตาราง Iceberg และสร้างหลักการบริการ OAuth ที่มีสิทธิ์เข้าถึงแบบอ่านแล้ว
1. ที่เก็บข้อมูลเข้าสู่ระบบที่ปลอดภัย
การฮาร์ดโค้ดโทเค็นเพื่อการเข้าถึงที่ใช้ได้นานเป็นรูปแบบสถาปัตยกรรมที่ไม่ควรทำ คุณจะจัดเก็บรหัสไคลเอ็นต์และข้อมูลลับ OAuth ของ Databricks ไว้ใน Google Cloud Secret Manager บริการ Lakehouse จะดึงข้อมูลเหล่านี้แบบไดนามิกในขณะรันไทม์เพื่อจำหน่ายโทเค็นที่มีอายุสั้น ซึ่งจะช่วยรวมการกำกับดูแลข้อมูลเข้าสู่ระบบของคุณไว้ที่เดียว
เรียกใช้บล็อกต่อไปนี้เพื่อสร้างสคริปต์ (อย่าแก้ไขอะไรในตอนนี้)
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
จากนั้นเรียกใช้คำสั่งต่อไปนี้เพื่อเปิดสคริปต์ที่สร้างขึ้นโดยอัตโนมัติในตัวแก้ไขโค้ดแบบภาพเหนือเทอร์มินัล
cloudshell edit create_secret.sh
- ในโปรแกรมแก้ไข ให้แทนที่ตัวยึดตำแหน่ง
<YOUR_...>ด้วยข้อมูลเข้าสู่ระบบ Databricks จริงของคุณ - ตรวจสอบว่า URL ของพื้นที่ทํางานไม่มี
https://หรือเครื่องหมายทับต่อท้าย (เช่น123456789.cloud.databricks.com) - กด
Ctrl+S(หรือCmd+Sใน Mac) เพื่อบันทึกไฟล์ - กลับไปที่เซสชันเทอร์มินัลแล้วเรียกใช้สคริปต์
source create_secret.sh
2. สร้างแคตตาล็อกที่เชื่อมโยง
ใน Codelab นี้ คุณจะกำหนดค่าแคตตาล็อกให้ข้ามผ่านอินเทอร์เน็ตสาธารณะได้อย่างปลอดภัยเพื่อความสะดวก อย่างไรก็ตาม สำหรับภาระงานการผลิต การค้นหาชุดข้อมูลขนาดใหญ่ผ่านอินเทอร์เน็ตสาธารณะจะทำให้เกิดค่าใช้จ่ายขาออกที่ไม่จำเป็นและเวลาในการตอบสนองที่คาดเดาไม่ได้ แนวทางปฏิบัติแนะนำกำหนดให้กำหนดค่า Cross-Cloud Interconnect (CCI) แบบส่วนตัวระหว่าง AWS กับ Google Cloud ซึ่งจะช่วยลดต้นทุนขาออกได้อย่างมากและรับประกันประสิทธิภาพเครือข่ายที่แน่นอน
ใช้ gcloud CLI เพื่อจัดสรรแคตตาล็อก Lakehouse แบบรวมศูนย์
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. ใช้การเชื่อมโยง IAM ที่มีสิทธิ์ขั้นต่ำที่สุด
เมื่อจัดสรรแคตตาล็อกที่เชื่อมโยงในขั้นตอนก่อนหน้า Google Cloud Lakehouse จะเปิดใช้งานงานรีเฟรชข้อมูลเบื้องหลังโดยอัตโนมัติเพื่อซิงค์ไฟล์ Manifest ของ Iceberg ทุกๆ 330 วินาที
คุณต้องมอบบทบาท secretAccessor ให้กับบัญชีบริการแคตตาล็อก Lakehouse เพื่อให้ดึงโทเค็น OAuth ของ Databricks ได้อย่างปลอดภัยในระหว่างการซิงค์ข้อมูลเบื้องหลังและการดำเนินการค้นหาเหล่านี้ หากไม่มีการเชื่อมโยงนี้ จะเกิดข้อผิดพลาด 403 แบบเงียบเมื่อ Lakehouse พยายามอัปเดตแคตตาล็อก
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. เปิดใช้อินเทอร์เน็ตขาออกสำหรับ Managed Service สำหรับ Apache Spark
ในขั้นตอนถัดไป Managed Service สำหรับ Apache Spark จะอ่านข้อมูล AWS ที่อยู่ระยะไกล เนื่องจาก Managed Service สำหรับ Apache Spark แบบ Serverless ทำงานภายในเครือข่าย VPC ส่วนตัวโดยไม่มีที่อยู่ IP ภายนอก จึงไม่สามารถเข้าถึง AWS S3 ผ่านอินเทอร์เน็ตได้โดยค่าเริ่มต้น คุณต้องจัดสรร Cloud NAT เพื่ออนุญาตให้ Spark Worker เข้าถึงอินเทอร์เน็ตขาออก
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. กำหนดเป้าหมายปลายทาง
ส่งออกตัวแปรนี้เพื่อให้งาน Apache Spark ที่ดาวน์สตรีมทราบตำแหน่งที่แน่นอนในการค้นหาข้อมูล AWS โดยไม่ต้องทำการเปลี่ยนแปลงโค้ดด้วยตนเอง
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
ตัวเลือกที่ 2: จำลองสภาพแวดล้อม AWS ผ่าน Cloud Storage
หากไม่มีบัญชี AWS ที่ใช้งานอยู่ คุณสามารถจำลองไซโลข้ามระบบคลาวด์ได้โดยใช้ตารางที่จัดการของ Lakehouse ใน Google Cloud Storage
1. สร้างตาราง Iceberg จำลอง
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. กำหนดเป้าหมายปลายทาง
ชุดข้อมูล BigQuery มาตรฐานใช้โครงสร้างเนมสเปซ 3 ส่วน (project.dataset.table) ส่งออกตัวแปรนี้เพื่อให้งาน Apache Spark ที่ดาวน์สตรีมกำหนดเป้าหมายไปยังข้อมูลจำลอง
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. นำเข้าบันทึกเหตุการณ์ (Google Cloud Spoke)
ข้อมูลคลิกสตรีมเพิ่มขึ้นอย่างรวดเร็ว คุณจัดเก็บเหตุการณ์ดิบที่สมบูรณ์และไม่ได้รวบรวมไว้ในเครื่องใน Cloud Storage เป็นตาราง Lakehouse ที่มีการจัดการ
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. สร้างโปรไฟล์ลูกค้าแบบรวม
เมื่อโครงสร้างพื้นฐานดิบของคุณมีข้อมูลครบถ้วนแล้ว ก็ถึงเวลาสร้างโปรไฟล์ลูกค้าแบบรวม
คุณจะใช้บริการที่มีการจัดการสำหรับ Apache Spark ซึ่งขับเคลื่อนโดย Lightning Engine Lightning Engine คือตัวเร่งการค้นหาแบบเนทีฟ C++ ประสิทธิภาพสูงของ Google Cloud ซึ่งสร้างขึ้นจากเทคโนโลยีโอเพนซอร์ส เช่น Apache Gluten และ Velox ซึ่งจะเพิ่มประสิทธิภาพการดำเนินการโดยอัตโนมัติด้วยการเพิ่มประสิทธิภาพ CPU และแคชข้อมูลอย่างชาญฉลาด แนวทางนี้เหมาะอย่างยิ่งเมื่อทำการรวมหลายทางขนาดใหญ่ การจัดหน้าต่างที่ซับซ้อน หรือการรวบรวมเชิงพฤติกรรมในหลายระบบคลาวด์
คุณจะใช้เครื่องมือเชื่อมต่อ Spark BigQuery เพื่ออ่านการค้นหา AlloyDB แบบ Zero-ETL ที่รวมกันและตาราง Lakehouse โดยตรง ทำการรวมแบบเวกเตอร์ขนาดใหญ่ใน Spark โดยตรง และเขียนโปรไฟล์แบบรวมที่ได้กลับไปยัง BigQuery
กำหนดค่าสิทธิ์ IAM สำหรับ Managed Service สำหรับ Apache Spark
โดยค่าเริ่มต้น Serverless Spark จะเรียกใช้งานแบบกลุ่มโดยใช้บัญชีบริการเริ่มต้นของ Compute Engine ก่อนส่งงาน คุณต้องให้สิทธิ์ที่จำเป็นแก่บัญชีบริการนี้เพื่อเรียกใช้งานเวิร์กโหลดและจัดการงาน BigQuery
(หมายเหตุ: แม้ว่าชื่อบริการจะเปลี่ยนเป็น Managed Service for Apache Spark เพื่อให้สอดคล้องกับคำศัพท์มาตรฐานอุตสาหกรรม แต่คำสั่ง API และบทบาท IAM พื้นฐานยังคงใช้ตัวระบุ dataproc)
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
สร้างและส่งงาน
ก่อนอื่น ให้สร้างสคริปต์งาน PySpark สคริปต์นี้จะตรวจหาโดยอัตโนมัติว่าคุณเลือกตัวเลือก A (แคตตาล็อกแบบรวมของ AWS) หรือตัวเลือก B (การจำลอง Google Cloud) ตามAWS_PRODUCTS_TABLEตัวแปรสภาพแวดล้อมของคุณ กำหนดตรรกะ Spark SQL และใช้การจัดการอาร์เรย์ดั้งเดิมของ Spark เพื่อคำนวณช่วง RFM (ความใหม่ ความถี่ มูลค่า)
เรียกใช้บล็อกต่อไปนี้ใน Cloud Shell
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
เมื่อประกอบสคริปต์เสร็จสมบูรณ์และแทรกการกำหนดค่าที่จำเป็นแบบไดนามิกแล้ว ให้ส่งงานแบบกลุ่มไปยัง Managed Apache Spark Serverless
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
ยืนยันการเรียกใช้งานในคอนโซล
เมื่อส่งงานแบบกลุ่มแล้ว คุณจะยืนยันได้ว่างานนั้นใช้เครื่องมือการดำเนินการ C++ ที่เร่งความเร็วแล้วโดยทำดังนี้
- ในคอนโซล Google Cloud ให้ไปที่ Managed Service สำหรับ Apache Spark > Serverless > Batch
- คลิกงานที่กำลังทำงานอยู่
- ในบานหน้าต่างรายละเอียดงาน ให้ตรวจสอบว่าได้ตั้งค่าพร็อพเพอร์ตี้ระดับเป็น
Premiumและตั้งค่าเครื่องมือเป็นLightning Engine
8. วิเคราะห์ด้วยตัวแทนข้อมูล BigQuery
ตอนนี้คุณได้รวมข้อมูลข้ามระบบคลาวด์ที่กระจัดกระจายและดำเนินการรวบรวมพฤติกรรมที่ซับซ้อนโดยใช้ Managed Service สำหรับ Apache Spark แล้ว ขั้นตอนถัดไปคือการวิเคราะห์ข้อมูล
ก่อนอื่น ให้ตรวจสอบสคีมาของตารางโปรไฟล์แบบรวมที่สร้างขึ้นใหม่ใน UI ของ BigQuery เพื่อทำความเข้าใจโครงสร้างข้อมูลที่คุณแสดงต่อตัวแทนด้วยภาพ
- ไปที่ BigQuery ในคอนโซล Google Cloud
- ในแผง Explorer ทางด้านซ้าย ให้ขยายโปรเจ็กต์และชุดข้อมูล
demo_lakehouse - คลิก
unified_customer_profileตาราง - เลือกแท็บสคีมาในพื้นที่ทํางานหลัก
ตรวจสอบสคีมาของตารางใหม่ คอลัมน์ top_preferences คือ REPEATED STRUCT (อาร์เรย์ของระเบียนที่มี category, brand และ sale_price) โดยปกติแล้ว การค้นหาอาร์เรย์ที่ซ้อนกันต้องใช้ SQL ที่ซับซ้อนโดยใช้ฟังก์ชัน UNNEST() ซึ่งอาจเป็นอุปสรรคสำหรับนักวิเคราะห์ธุรกิจ การเชื่อมต่อแหล่งข้อมูลเอเจนต์ข้อมูล BigQuery เข้ากับตารางนี้โดยเฉพาะจะช่วยให้เอเจนต์เข้าใจสคีมาโดยธรรมชาติและจัดการการดำเนินการ SQL มาตรฐานของ Google ที่ซับซ้อนได้เบื้องหลัง
สร้าง Data Agent
ในส่วนนี้ คุณจะสร้างและโต้ตอบกับเอเจนต์ข้อมูล BigQuery แทนที่จะต้องเขียน SQL ที่ซับซ้อนด้วยตนเองเพื่อเลิกซ้อนอาร์เรย์และคำนวณเมตริก คุณจะจัดสรร AI Agent ที่กำหนดขอบเขตเฉพาะโปรไฟล์แบบรวมที่สร้างขึ้นใหม่ ซึ่งจะช่วยให้สำรวจข้อมูลด้วยภาษาธรรมชาติได้
- ค้นหาและคลิกตัวแทนในแผงการนำทางด้านซ้าย
- คลิก + Agent ใหม่เพื่อเริ่มต้นใช้งานผู้ช่วย AI ใหม่
- กำหนดค่า Agent
- ชื่อตัวแทน:
Retail VIP Analysis Agent - แหล่งข้อมูล: คลิกเพิ่มแหล่งข้อมูล แล้วค้นหาตาราง
unified_customer_profile
- คลิกเพิ่ม แล้วรอสักครู่เพื่อให้ Agent เริ่มต้นพื้นที่ทำงาน
เมื่อสร้างเอเจนต์แล้ว การกำหนดคำสั่งของระบบอย่างชัดเจนถือเป็นแนวทางปฏิบัติที่สำคัญในการกำกับดูแลข้อมูล ใช้คำสั่งของระบบเป็นเลเยอร์เชิงความหมาย การฝังคำจำกัดความทางธุรกิจทั่วทั้งองค์กร การจัดการความซับซ้อนของสคีมา และการกำหนดขอบเขตการวิเคราะห์จะช่วยให้คุณแยกความซับซ้อนทางเทคนิคออกจากผู้ใช้ปลายทาง และป้องกันไม่ให้ LLM สรุปจากข้อมูลที่ไม่มีนัยสำคัญทางสถิติ
วางข้อความต่อไปนี้ลงในช่องวิธีการ
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
พรอมต์ Agent
เนื่องจากตรรกะทางธุรกิจที่ซับซ้อน (คำจำกัดความที่แน่นอนของ "VIP ที่มีความเสี่ยง") และข้อกำหนดในการจัดการสคีมาได้รับการควบคุมอย่างปลอดภัยโดยคำสั่งของระบบ นักวิเคราะห์ข้อมูลจึงไม่จำเป็นต้องเขียนพรอมต์ที่ยาวและมีเงื่อนไขมากมาย
ในอินเทอร์เฟซแชท ให้ป้อนพรอมต์ต่อไปนี้
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
ประเมินข้อมูลเชิงลึกที่สร้างขึ้น
หลังจากส่งพรอมต์แล้ว ให้ตรวจสอบเอาต์พุตที่สร้างขึ้นโดยเนทีฟอย่างละเอียดเพื่อประเมินว่า BigQuery Data Agent บังคับใช้คำสั่งของระบบอย่างไร โดยทำหน้าที่ทั้งเลเยอร์เชิงความหมายที่มีการควบคุมและแนวทางวิเคราะห์
ก่อนอื่น ให้อ่านข้อความสรุปที่สร้างขึ้นเหนือข้อมูล โปรดสังเกตว่าเอเจนต์จะแปลคำขออย่างง่ายสำหรับ "VIP ที่มีความเสี่ยง" เป็นเกณฑ์เมตริกที่แน่นอนซึ่งกำหนดไว้ในคำสั่งของระบบโดยอัตโนมัติ (เช่น การอ้างอิง lifetime_value > 100, cart_adds > 0 และระยะเวลา 90 วันที่ไม่มีการใช้งาน) ซึ่งเป็นการยืนยันว่าเอเจนต์ได้นำตรรกะทางธุรกิจของคุณไปใช้ภายในแล้ว ซึ่งหมายความว่าผู้ใช้ปลายทางไม่จำเป็นต้องจดจำหรือฮาร์ดโค้ดตรรกะที่ซับซ้อนในพรอมต์ประจำวัน
จากนั้นขยายมุมมอง SQL เพื่อตรวจสอบโค้ดที่สร้างขึ้น Agent ควรสร้าง Google Standard SQL ที่ถูกต้องตามหลักคณิตศาสตร์ตามคำสั่งของคุณ ดังนี้
- กรอบเวลาแบบไดนามิก: มองหาการคำนวณการประทับเวลาในข้อความ
WHERE(โดยปกติจะใช้TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)) - การปฏิบัติตามสคีมาอย่างเคร่งครัด: ยืนยันว่าเอเจนต์ปฏิบัติตามกฎสคีมาอย่างเคร่งครัดโดยใช้ฟังก์ชัน
UNNEST()กับอาร์เรย์top_preferencesอย่างชัดเจน โดยปกติแล้ว คุณจะเห็นว่ามีการใช้เทคนิคขั้นสูง เช่นROW_NUMBER() OVER()ฟังก์ชันสร้างกรอบข้อมูล ภายใน Common Table Expression (CTE) เพื่อแยกหมวดหมู่ที่พบบ่อยที่สุดเพียงหมวดหมู่เดียวต่อประเทศอย่างถูกต้อง
ตรวจสอบแผนภูมิและตารางข้อมูลที่แสดงผลโดยอัตโนมัติ ข้อมูลจะแสดงให้เห็นภาพตลาดการรักษาลูกค้าหลัก (โดยปกติจะไฮไลต์ประเทศที่มีปริมาณสูง เช่น จีนหรือสหรัฐอเมริกา) ควบคู่ไปกับความเกี่ยวข้องของผลิตภัณฑ์ที่โดดเด่นในระดับสากล (มักจะเป็น "กางเกงยีนส์") สังเกตว่า UI เนทีฟจัดโครงสร้างเอาต์พุตเพื่อให้ผู้ใช้บริโภคได้ทันทีโดยไม่ต้องใช้โค้ดการแสดงภาพที่ชัดเจน
อ่านข้อความข้อมูลเชิงลึกแบบหัวข้อย่อยที่ Agent สร้างขึ้น เนื่องจากคุณได้กำหนดขอบเขตการวิเคราะห์ไว้แล้ว ให้มองหาข้อมูลเชิงลึกเกี่ยวกับคุณภาพของข้อมูลหรือนัยสำคัญทางสถิติโดยเฉพาะ คุณอาจเห็นเอเจนต์ติดธงประเทศอย่างชัดเจนที่ด้านล่างของตารางที่มีจำนวนผู้ใช้น้อยมาก (เช่น ภูมิภาคที่มีผู้ใช้เพียงไม่กี่ราย) แทนที่จะสร้างแคมเปญการตลาดที่กำหนดเป้าหมายโดยไม่พิจารณาจากจุดข้อมูลเดียว Agent จะแนะนำอย่างถูกต้องว่าความผิดปกติเหล่านี้ไม่มีนัยสำคัญทางสถิติสำหรับกลยุทธ์ขนาดใหญ่ ซึ่งแสดงให้เห็นว่าการฝังการ์ดเรลด้านการกำกับดูแลลงในเอเจนต์โดยตรงช่วยป้องกันการคำนวณทางธุรกิจที่เกิดจาก AI ได้อย่างมีประสิทธิภาพ
9. สร้างข้อมูลเชิงลึกจาก AI ด้วย Gemini และ MCP
เอเจนต์ระบุข้อมูลประชากรเป้าหมายหลักได้สำเร็จ ซึ่งก็คือ VIP ที่มีความเสี่ยงในบางประเทศ อย่างไรก็ตาม งานของนักวิเคราะห์จะสิ้นสุดที่ข้อมูลเชิงลึก หากต้องการดึงดูดผู้ใช้เหล่านี้ให้กลับมามีส่วนร่วมอีกครั้ง ทีมการตลาดต้องทําแคมเปญ
คุณจะใช้ Model Context Protocol (MCP) เพื่อเชื่อมต่อผู้ช่วย AI ภายนอกกับรายการข้อมูลประชากรที่เฉพาะเจาะจงนี้ใน BigQuery โดยตรง ซึ่งจะเปลี่ยนจากการวิเคราะห์ข้อมูลเป็นการดำเนินการที่ขับเคลื่อนด้วย AI โดยไม่ต้องสร้าง API ที่กำหนดเอง
กำหนดค่าเซิร์ฟเวอร์ MCP ของ BigQuery
เรียกใช้บล็อกด้านล่างเพื่อสร้างไฟล์การกำหนดค่า mcp.json ไฟล์นี้มีพารามิเตอร์การเชื่อมต่อที่จำเป็นเพื่อให้ Gemini CLI เชื่อมต่อกับ BigQuery ได้อย่างปลอดภัย
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
สร้างอีเมลการตลาด
เริ่มเครื่องมือ Gemini CLI จากเทอร์มินัล โดยส่งแฟล็กการกำหนดค่า MCP อย่างชัดเจนเพื่อให้เครื่องมืออ่าน Lakehouse ของ BigQuery ได้
เรียกใช้ Gemini CLI
source env.sh
gemini
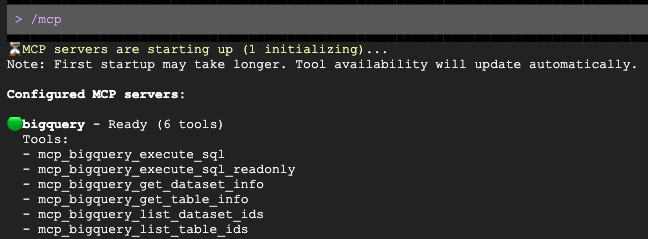
เมื่อพรอมต์เปิดขึ้นแล้ว ให้ขอให้ร่างการติดต่อส่วนบุคคลสำหรับกลุ่มประชากรเป้าหมาย
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
Gemini จะค้นหา BigQuery ผ่านเซิร์ฟเวอร์ MCP โดยอัตโนมัติ ระบุข้อมูลประชากร และร่างอีเมลให้คุณ
10. การทำความสะอาดสภาพแวดล้อม
หากต้องการหลีกเลี่ยงการเรียกเก็บเงินอย่างต่อเนื่องในบัญชี Google Cloud และรีเซ็ตโปรเจ็กต์อย่างหมดจดสำหรับการเรียกใช้ในอนาคต คุณต้องลบทรัพยากรที่สร้างขึ้นระหว่าง Codelab นี้
เรียกใช้บล็อกต่อไปนี้เพื่อสร้างสคริปต์ cleanup.sh สคริปต์นี้ทำหน้าที่เป็นกลไกการหยุดทำงานอัตโนมัติ โดยจะนำคลัสเตอร์และอินสแตนซ์ AlloyDB, ชุดข้อมูล BigQuery และ Bucket ของ Cloud Storage ออกอย่างถาวรเพื่อป้องกันการเรียกเก็บเงินเพิ่มเติม
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
เรียกใช้สคริปต์ล้างข้อมูลเพื่อลบทรัพยากรอย่างปลอดภัย
bash cleanup.sh
11. ยินดีด้วย
คุณสร้างและค้นหา Open Data Lakehouse แบบข้ามระบบคลาวด์เรียบร้อยแล้ว
คุณได้เรียนรู้สิ่งต่อไปนี้
- วิธีรวมข้อมูลจากแหล่งที่มาต่างๆ โดยใช้ BigQuery Zero-ETL และ Google Cloud Lakehouse
- วิธีใช้ประโยชน์จาก Lightning Engine แบบเนทีฟของ C++ ในการรวมแบบเวกเตอร์ขนาดใหญ่ของ Managed Service สำหรับ Apache Spark
- วิธีใช้เอเจนต์ข้อมูล BigQuery เพื่อการสำรวจภาษาธรรมชาติ
- วิธีเชื่อมต่อข้อมูลกับ Gemini โดยใช้ Model Context Protocol (MCP) และ Gemini
ขั้นตอนถัดไป
- สำรวจเอกสารประกอบเกี่ยวกับ Lakehouse
- ดูข้อมูลเพิ่มเติมเกี่ยวกับ AlloyDB zero-ETL ไปยัง BigQuery
- อ่านเกี่ยวกับ Lightning Engine