
1. Giriş
Bu codelab'de, karmaşık ETL'ye gerek kalmadan AWS, Google Cloud ve AlloyDB'deki veri silolarını birleştiren bulutlar arası açık bir veri gölü ambarı oluşturacaksınız. Merkezi bilgi merkezi olarak Lakehouse'u, operasyonel veri kaynağı olarak AlloyDB'yi ve yüksek performanslı vektörel işleme için Apache Spark için Yönetilen Hizmet'i kullanacaksınız. Son olarak, lakehouse'unuzdan güçlü iş analizleri elde etmek için Gemini'ı kullanacaksınız.
İşlem verilerinizin (users, orders, order items) AlloyDB'de, product verilerinizin AWS S3 paketinde ve büyük tıklama akışı event logs verilerinizin Cloud Storage'da depolandığını düşünün. Bir sonraki pazarlama kampanyanız için hedef demografik grupları belirlemek ve kişiselleştirilmiş erişim e-postaları oluşturmak üzere bu veri kümelerini birleştirmeniz gerekir.
Ön koşullar
- Temel SQL ve terminal komutları hakkında bilgi sahibi olma.
- Faturalandırmanın etkin olduğu bir Google Cloud projesi.
Neler öğreneceksiniz?
- BigQuery zero-ETL (AlloyDB) ve Apache Iceberg için Lakehouse kullanarak farklı veri silolarını entegre etme
- C++ yerel Lightning Engine tarafından desteklenen Managed Service for Apache Spark'ı kullanarak yüksek hızlı davranış profili oluşturma işinin nasıl çalıştırılacağı
- Birleştirilmiş veriler üzerinde karmaşık doğal dil analizi yapmak için BigQuery veri aracısını kullanma
- Model Context Protocol'ü (MCP) yapılandırarak Gemini CLI'nın Apache Iceberg için Lakehouse'unuzdan okumasına ve pazarlama içeriği taslağı oluşturmasına izin verme
Gerekenler
- Google Cloud hesabı ve Google Cloud projesi
- Chrome gibi bir web tarayıcısı
Gerekenler
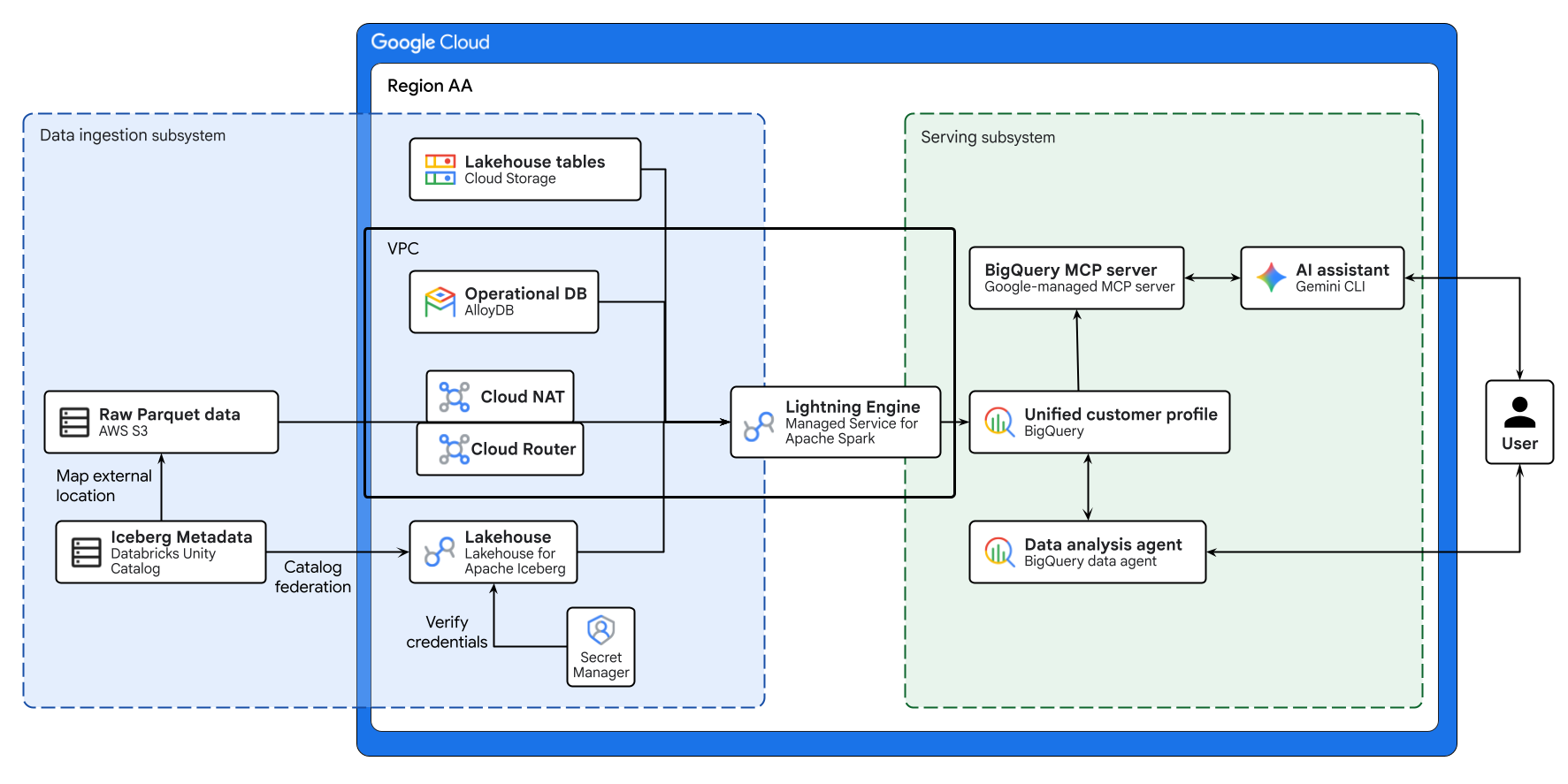
Yukarıdaki şemada, bu codelab'de oluşturulan bulutlar arası lakehouse'un uçtan uca akışı gösterilmektedir. AlloyDB'den alınan operasyonel veriler ve AWS S3'ten alınan uzak veriler, Apache Iceberg için Lakehouse kullanılarak güvenli bir şekilde birleştirilir. Managed Service for Apache Spark, BigQuery'de birleşik bir müşteri profili oluşturmak için bu farklı kaynakları işler. Son olarak, Gemini CLI aracılığıyla BigQuery Veri Aracısı ve Google tarafından yönetilen BigQuery MCP sunucusu, gelişmiş veri analizi için sezgisel ve yapay zeka destekli bir arayüz sağlar.
Temel kavramlar
- Bulutlar arası açık veri göl evi: Karmaşık ETL'ye gerek kalmadan AWS, Google Cloud ve şirket içi ortamlardaki veri silolarını birleştirir.
- BigQuery zero-ETL: Karmaşık veri taşıma işlemleri olmadan operasyonel veritabanlarının doğrudan sorgulanmasına olanak tanır.
- Apache Iceberg için veri gölü ambarı: Apache Iceberg biçimini kullanarak bulutlar arası depolama alanında tutarlı güvenlik ve yönetim sağlar.
- Lightning Engine: Yüksek performanslı Apache Spark yürütmesi için C++ yerel motoru.
- Model Context Protocol (MCP): Gemini'ı doğrudan BigQuery lakehouse'unuza bağlar.
2. Kurulum ve şartlar
Google Cloud projesi oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyi öğrenin.
Cloud Shell'i başlatma
Google Cloud, dizüstü bilgisayarınızdan uzaktan çalıştırılabilir ancak bu codelab'de Cloud'da çalışan bir komut satırı ortamı olan Google Cloud Shell'i kullanacaksınız.
Google Cloud Console'da sağ üstteki araç çubuğunda Cloud Shell simgesini tıklayın:
Ortamın temel hazırlığı ve bağlantı kurulması yalnızca birkaç dakikanızı alır. İşlem tamamlandığında aşağıdakine benzer bir ekranla karşılaşırsınız:

Bu sanal makine, ihtiyaç duyacağınız tüm geliştirme araçlarıyla birlikte gelir. 5 GB boyutunda kalıcı bir ana dizin sunar ve Google Cloud üzerinde çalışır. Bu sayede ağ performansı ve kimlik doğrulama önemli ölçüde güçlenir. Bu codelab'deki tüm çalışmalarınızı tarayıcıda yapabilirsiniz. Herhangi bir şey yüklemeniz gerekmez.
Ortamı başlatma
Cloud Shell'i açın ve tüm komutların doğru altyapıyı hedeflediğinden emin olmak için proje değişkenlerinizi ayarlayın.
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
Değişkenleri etkin oturumunuza uygulayın:
source ./env.sh
API'leri etkinleştirme
Gerekli Google Cloud hizmetlerini etkinleştirin.
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3. Temel altyapıyı ayarlama
Tüm verileri hassas ETL işlem hatları aracılığıyla tek bir depoya taşımak yerine, birleştirilmiş bulutlar arası mimari oluşturursunuz. Gerçek dünyadaki bir işletmede, farklı sistem gereksinimleri nedeniyle veriler doğası gereği parçalanmıştır. Aşağıdaki veri kaynaklarını düzenleyeceksiniz:
- AlloyDB (Temel işlemsel veritabanı): Kullanıcı, sipariş ve sipariş öğeleri verilerini depolar. Canlı bir operasyonel veritabanı olarak, finansal işlemler ve profil güncellemeleri için gereken ACID özelliklerini garanti eder.
- AWS S3 (Ana veriler):
productskataloğunu depolar. AWS'de eski bir ana veri yönetimi (MDM) sistemini temsil eder. - Google Cloud Storage (Büyük veri gölü):
events(tıklama akışı günlükleri) depolar. Web günlükleri gibi yüksek hızlı veriler, ilişkisel veritabanının çökmesine neden olur. Nesne depolama alanı sonsuz ölçeklenebilirlik sağlar ve Google Cloud'da tutulması, analitik motorlarınız için işlem yerelliğini en üst düzeye çıkarır.
Öncelikle temel ağı yapılandırın. AlloyDB gibi Google Cloud tarafından yönetilen veritabanlarının, proje ağınızda güvenli bir şekilde iletişim kurmak için özel bir VPC eşleme bağlantısı gerekir.
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
Ardından, bir BigQuery veri kümesi ve bir Lakehouse bulut kaynağı bağlantısı oluşturun. Mimaride, kaynak bağlantısı veri erişimini özel bir Google tarafından yönetilen hizmet hesabına devreder ve en az ayrıcalık ilkesini zorunlu kılar.
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. Operasyonel veritabanını sağlama
AlloyDB birincil örneği sağlayın ve iş açısından kritik işlem verilerinizi ekleyin.
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
Veritabanı hazır olduğunda AlloyDB'ye BigQuery harici bağlantısı oluşturmanız gerekir. Bu bağlantı, veritabanı kimlik bilgilerini ve uç noktasını güvenli bir şekilde saklar. Böylece BigQuery, SQL yürütmeyi doğrudan AlloyDB işlem motoruna gönderebilir (sıfır ETL).
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
İşlem tablolarını AlloyDB'ye güvenli bir şekilde aktarın. Yerel Cloud Shell oturumunuzu özel AlloyDB örneğine güvenli bir şekilde bağlamak için AlloyDB Auth Proxy'yi kullanın. Bu sayede, yerel komut satırı araçlarını kullanarak işlemsel verileri gönderebilirsiniz.
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5. Ana verileri birleştirme (AWS spoke)
Ham öğe meta verilerini içeren ürün kataloğumuz, Apache Iceberg tabloları olarak AWS S3'te yer alır. Meta veriler, uzak bir katalog tarafından yönetilir.
Bu verileri Google Cloud'a kopyalamak için kırılgan ETL ardışık düzenleri oluşturmak yerine Lakehouse for Apache Iceberg (REST katalog federasyonu)'u kullanacaksınız.
Bu sıfır ETL yaklaşımı, Lakehouse ve Managed Service for Apache Spark'ın Iceberg meta verilerini ve temel alınan Parquet dosyalarını doğrudan uzak ortamınızdan dinamik olarak keşfetmesine ve okumasına olanak tanır.
Etkin bir AWS hesabınız ve Databricks Unity Catalog yapılandırmanız varsa bunu kullanabilirsiniz. Aksi takdirde, Google Cloud Storage'ı kullanarak ortamınızı taklit edebilirsiniz. Birini veya diğerini seçin.
A seçeneği: Kendi AWS'nizi getirin (Yerel Apache Iceberg)
Ön koşul: Bu seçenekte, bir AWS S3 paketi sağladığınız, bunu Databricks Unity Catalog'da harici bir konum olarak bağladığınız, bir Iceberg tablosu eşlediğiniz ve okuma erişimi olan bir OAuth hizmeti sorumlusu oluşturduğunuz varsayılır.
1. Güvenli kimlik bilgisi depolama
Uzun ömürlü erişim jetonlarının sabit kodlanması, mimari açıdan kötü bir uygulamadır. Databricks OAuth istemci kimliğini ve gizli anahtarını Google Cloud Secret Manager'da saklayacaksınız. Lakehouse hizmeti, kısa ömürlü jetonlar sağlamak için bunları çalışma zamanında dinamik olarak getirir ve kimlik bilgisi yönetiminizi merkezileştirir.
Komut dosyasını oluşturmak için aşağıdaki bloğu çalıştırın. (Henüz hiçbir şeyi düzenlemeyin).
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
Ardından, oluşturulan komut dosyasını terminalinizin üzerindeki görsel kod düzenleyicide otomatik olarak açmak için aşağıdaki komutu çalıştırın.
cloudshell edit create_secret.sh
- Düzenleyicideki
<YOUR_...>yer tutucularını gerçek Databricks kimlik bilgilerinizle değiştirin. - Çalışma alanı URL'nizin
https://veya sondaki eğik çizgiler (ör.123456789.cloud.databricks.com) içermediğinden emin olun. - Dosyayı kaydetmek için
Ctrl+S(veya Mac'teCmd+S) tuşuna basın. - Terminal oturumunuza dönün ve komut dosyasını çalıştırın:
source create_secret.sh
2. Birleştirilmiş kataloğu oluşturma
Bu codelab'de, kataloğu herkese açık internette güvenli bir şekilde gezinmek üzere yapılandıracaksınız. Ancak üretim iş yükleri için herkese açık internet üzerinden büyük veri kümelerini sorgulamak gereksiz çıkış maliyetlerine ve öngörülemeyen gecikmeye neden olur. En iyi uygulama, AWS ile Google Cloud arasında özel bir Cross-Cloud Interconnect (CCI) yapılandırmayı zorunlu kılar. Bu yapılandırma, çıkış maliyetlerini önemli ölçüde azaltır ve deterministik ağ performansı sağlar.
Birleşik Lakehouse kataloğunu sağlamak için gcloud CLI'yı kullanın:
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. En az ayrıcalığa dayalı IAM bağlamaları uygulama
Önceki adımda birleştirilmiş kataloğu sağladığınızda Google Cloud Lakehouse, Iceberg manifestlerini her 330 saniyede bir senkronize etmek için otomatik olarak bir arka plan yenileme işi başlattı.
Bu arka plan senkronizasyonları ve sorgu yürütmeleri sırasında Databricks OAuth jetonunu güvenli bir şekilde getirebilmesi için Lakehouse kataloğu hizmet hesabına secretAccessor rolünü vermeniz gerekir. Bu bağlamanın eksik olması, Lakehouse kataloğu güncellemeye çalıştığında sessiz 403 hatalarına neden olur.
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. Managed Service for Apache Spark için giden interneti etkinleştirme
Sonraki bir adımda, Managed Service for Apache Spark, uzak AWS verilerini okur. Apache Spark Serverless için Yönetilen Hizmet tamamen harici IP adresleri olmadan özel bir VPC ağında çalıştığından, varsayılan olarak internet üzerinden AWS S3'e ulaşamaz. Spark çalışanlarının giden internet erişimine izin vermek için bir Cloud NAT sağlamanız gerekir.
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. Aşağı akış hedefi tanımlama
Bu değişkeni dışa aktararak, aşağı akış Apache Spark işlerinin AWS verilerini tam olarak nereden sorgulayacağını bilmesini sağlayın. Böylece, manuel kod değişikliği yapmanız gerekmez.
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
2. seçenek: Cloud Storage aracılığıyla AWS ortamını taklit etme
Etkin bir AWS hesabınız yoksa Google Cloud Storage'daki Lakehouse yönetilen tabloları kullanarak bulutlar arası bağımsız veri havuzunu yerel olarak simüle edebilirsiniz.
1. Sahte Iceberg tablosunu oluşturma
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. Aşağı akış hedefi tanımlama
Standart BigQuery veri kümelerinde 3 bölümlü bir ad alanı yapısı (project.dataset.table) kullanılır. Bu değişkeni, aşağı akış Apache Spark işinin sahte verileri hedeflemesi için dışa aktarın.
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. Etkinlik günlüklerini alma (Google Cloud spoke)
Tıklama akışı verileri katlanarak büyür. Tamamlanmış, toplanmamış ham etkinlikleri Cloud Storage'da yönetilen Lakehouse tabloları olarak yerel olarak depolarsınız.
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. Birleşik müşteri profili oluşturma
Ham altyapınız tamamen doldurulduğunda birleşik müşteri profili oluşturma zamanı gelmiş demektir.
Lightning Engine tarafından desteklenen Managed Service for Apache Spark'ı kullanacaksınız. Lightning Engine, Google Cloud'un yüksek performanslı C++ yerel sorgu hızlandırıcısıdır. Apache Gluten ve Velox gibi açık kaynak teknolojileri üzerine kurulmuştur. CPU verimliliğini en üst düzeye çıkararak ve verileri akıllıca önbelleğe alarak yürütmeyi otomatik olarak hızlandırır. Bu yaklaşım, birden fazla bulutta büyük ölçekli çok yönlü birleştirmeler, karmaşık pencereleme veya davranışsal toplamalar gerçekleştirirken idealdir.
Birleştirilmiş AlloyDB sıfır ETL sorgularını ve Lakehouse tablolarını doğrudan okumak, büyük vektörel toplamaları Spark'ta yerel olarak gerçekleştirmek ve ortaya çıkan birleştirilmiş profili BigQuery'ye geri yazmak için Spark BigQuery bağlayıcısını kullanacaksınız.
Managed Service for Apache Spark için IAM izinlerini yapılandırma
Sunucusuz Spark, varsayılan olarak toplu işleri Compute Engine varsayılan hizmet hesabını kullanarak yürütür. İşi göndermeden önce bu hizmet hesabına iş yükünü yürütmek ve BigQuery işlerini yönetmek için gerekli izinleri vermeniz gerekir.
(Not: Hizmet adı, sektör standardı terminolojisini yansıtacak şekilde Managed Service for Apache Spark olarak değiştirilmiş olsa da temel API komutları ve IAM rolleri hâlâ dataproc tanımlayıcısını kullanır.)
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
İşi oluşturma ve gönderme
Öncelikle PySpark iş komut dosyasını oluşturun. Bu komut dosyası, AWS_PRODUCTS_TABLE ortam değişkeninize göre A seçeneğini (AWS Federated Catalog) veya B seçeneğini (Google Cloud Mock) seçip seçmediğinizi otomatik olarak algılar, Spark SQL mantığını tanımlar ve RFM (yenilik, sıklık, parasal) aralıklarını hesaplamak için Spark'ın yerel dizi işleme özelliğini kullanır.
Cloud Shell'de aşağıdaki kodu çalıştırın.
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
Komut dosyası tamamen birleştirildikten ve gerekli yapılandırmalar dinamik olarak eklendikten sonra toplu işi Managed Apache Spark Serverless'a gönderin.
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
Konsolda iş yürütmeyi doğrulama
Toplu iş gönderildikten sonra hızlandırılmış C++ yürütme motorunu kullandığını doğrulayabilirsiniz:
- Google Cloud Console'da Managed Service for Apache Spark > Serverless > Batches'e (Toplu İşler) gidin.
- Şu anda çalışmakta olan işi tıklayın.
- İş ayrıntıları bölmesinde Katman özelliğinin
Premium, Motor'un iseLightning Engineolarak ayarlandığını doğrulayın.
8. BigQuery veri aracısı ile analiz etme
Parçalanmış bulutlar arası verileri birleştirdikten ve Apache Spark için Yönetilen Hizmet'i kullanarak yoğun davranışsal toplamaları yürüttükten sonraki adım veri analizidir.
Öncelikle, aracıya sunduğunuz veri yapısını görsel olarak anlamak için BigQuery kullanıcı arayüzünde yeni oluşturulan birleştirilmiş profil tablosunun şemasını inceleyin:
- Google Cloud Console'da BigQuery'ye gidin.
- Soldaki Explorer (Gezgin) bölmesinde projenizi ve
demo_lakehouseveri kümesini genişletin. unified_customer_profiletablosunu tıklayın.- Ana çalışma alanında Şema sekmesini seçin.
Yeni tablonun şemasını kontrol edin. top_preferences sütunu bir REPEATED STRUCT (category, brand ve sale_price içeren kayıt dizisi) değeridir. Geleneksel olarak, iç içe geçmiş dizileri sorgulamak için UNNEST() işlevinin kullanıldığı karmaşık SQL gerekir. Bu da iş analistleri için bir engel olabilir. BigQuery veri aracısını bu belirli tabloda temellendirerek aracı, şemayı doğal olarak anlar ve karmaşık Google Standart SQL işlemlerini arka planda gerçekleştirir.
Veri aracısını oluşturma
Bu bölümde, bir BigQuery veri aracısı oluşturup bu aracıyla etkileşimde bulunacaksınız. Dizileri açmak ve metrikleri hesaplamak için karmaşık SQL'i manuel olarak yazmak yerine, yeni oluşturduğunuz birleşik profilinizle sınırlı bir yapay zeka aracısı sağlayacaksınız. Bu sayede, doğal dil veri keşfi mümkün olacak.
- Sol gezinme bölmesinde Aracılar'ı bulun ve tıklayın.
- Yeni bir yapay zeka asistanı başlatmak için + Yeni Temsilci'yi tıklayın.
- Aracıyı yapılandırın:
- Ajan Adı:
Retail VIP Analysis Agent - Veri Kaynakları: Kaynak Ekle'yi tıklayın ve
unified_customer_profiletablosunda arama yapın.
- Ekle'yi tıklayın ve aracının çalışma alanını başlatması için birkaç saniye bekleyin.
Aracı oluşturulduktan sonra açık Sistem Talimatları tanımlamak kritik bir veri yönetimi uygulamasıdır. Sistem Talimatlarını Anlamsal Katman olarak kullanma Kuruluş genelinde işletme tanımlarını yerleştirerek, şema karmaşıklıklarını ele alarak ve analitik koruma önlemleri oluşturarak teknik karmaşıklığı son kullanıcıdan uzaklaştırır ve LLM'nin istatistiksel olarak önemsiz verilerden sonuç çıkarmasını önlersiniz.
Aşağıdakileri Talimat alanına yapıştırın:
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
Temsilciye istem girme
Karmaşık iş mantığı ("Risk Altındaki Önemli Müşteri"nin tam tanımı) ve şema işleme koşulları, Sistem Talimatları tarafından güvenli bir şekilde yönetildiğinden veri analistinin ayrıntılı ve koşul ağırlıklı bir istem yazması gerekmez.
Sohbet arayüzüne aşağıdaki istemi girin:
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
Oluşturulan analizleri değerlendirme
İstemi gönderdikten sonra, BigQuery Data Agent'ın hem yönetilen bir anlamsal katman hem de analitik bir koruma bariyeri olarak hareket ederek Sistem Talimatlarınızı nasıl uyguladığını değerlendirmek için yerel olarak oluşturulan çıkışı dikkatlice inceleyin.
Öncelikle verilerin üzerinde oluşturulan özet metni okuyun. Aracının, "Risk altındaki VIP'ler" şeklindeki basit isteğinizi, sistem talimatlarınızda tanımlanan tam metrik eşiklerine (ör. lifetime_value > 100, cart_adds > 0 ve 90 günlük etkinliksizlik) nasıl otomatik olarak çevirdiğine dikkat edin. Bu, aracının iş mantığınızı içselleştirdiğini onaylar. Bu sayede son kullanıcıların günlük istemlerinde karmaşık mantığı ezberlemesi veya sabit kodlaması gerekmez.
Ardından, oluşturulan kodu incelemek için SQL görünümünü genişletin. Aracı, talimatlarınıza göre matematiksel olarak sağlam bir Google Standard SQL oluşturmalıdır:
- Dinamik Zaman Aralığı:
WHEREifadesindeki zaman damgası hesaplamasını bulun (genellikleTIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)kullanılır). - Şemaya Kesin Uygunluk: Aracının,
UNNEST()işlevinitop_preferencesdizisine açıkça uygulayarak katı şema kurallarınıza uyduğunu onaylayın. Ülke başına en sık kullanılan tek kategoriyi doğru şekilde ayırmak için genellikle Common Table Expression (CTE) içindeROW_NUMBER() OVER()pencere işlevi gibi gelişmiş tekniklerin kullanıldığını görürsünüz.
Otomatik olarak oluşturulan grafiği ve veri tablosunu inceleyin. Veriler, temel elde tutma pazarlarınızı (genellikle Çin veya ABD gibi yüksek hacimli ülkeleri vurgular) ve evrensel olarak baskın ürün yakınlıklarını (sıklıkla "Kot") görsel olarak ortaya çıkarır. Yerel kullanıcı arayüzünün, açık görselleştirme kodu gerektirmeden çıktıyı anında kullanıma hazır hale getirmek için nasıl yapılandırdığına dikkat edin.
Aracı tarafından oluşturulan madde işaretli Analizler metnini okuyun. Analitik koruma sınırları oluşturduğunuz için özellikle veri kalitesi veya istatistiksel önem ile ilgili bir analiz arayın. Aracı, tablonun en altında, kullanıcı sayısı çok düşük olan ülkeleri (ör. yalnızca birkaç kullanıcının bulunduğu bölgeler) açıkça işaretleyebilir. Ajan, tek bir veri noktasına dayalı olarak hedefli bir pazarlama kampanyası hakkında rastgele yanıltıcı bilgiler vermek yerine, bu anormalliklerin büyük ölçekli bir strateji için istatistiksel olarak önemsiz olduğu konusunda doğru tavsiyede bulunur. Bu, yönetim koruma bantlarının doğrudan ajana yerleştirilmesinin, yapay zeka destekli işletme yanlış hesaplamalarını nasıl etkili bir şekilde önlediğini gösterir.
9. Gemini ve MCP ile yapay zeka analizleri oluşturma
Ajan, birincil hedef demografiyi (belirli ülkelerdeki risk altındaki VIP'ler) başarıyla belirledi. Ancak analistlerin işi analizle sınırlıdır. Bu kullanıcılarla yeniden etkileşim kurmak için pazarlama ekibinin bir kampanya yürütmesi gerekir.
Model Context Protocol'ü (MCP) kullanarak harici bir yapay zeka asistanını doğrudan BigQuery'deki bu belirli demografik listeye bağlayacak, özel API'ler oluşturmadan veri analizinden yapay zeka destekli işleme geçiş yapacaksınız.
BigQuery MCP sunucusunu yapılandırma
mcp.json yapılandırma dosyasını oluşturmak için aşağıdaki kodu çalıştırın. Bu dosya, Gemini CLI'nin BigQuery ile güvenli bir şekilde etkileşim kurabilmesi için gerekli bağlantı parametrelerini sağlar.
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
Pazarlama e-postası oluşturma
BigQuery lakehouse'unuzu okumasına izin vermek için MCP yapılandırma işaretini açıkça ileterek Gemini CLI aracını terminalinizden başlatın.
Gemini CLI'yi çalıştırın.
source env.sh
gemini
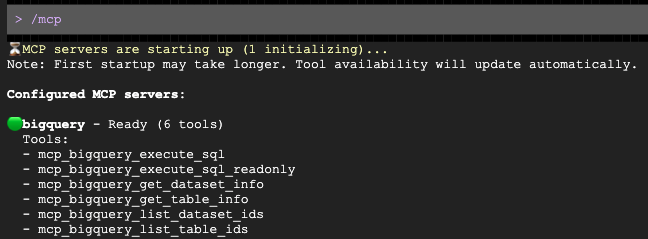
İstem açıldıktan sonra hedef demografik kitleniz için kişiselleştirilmiş bir erişim taslağı oluşturmasını isteyin:
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
Gemini, MCP sunucusu aracılığıyla BigQuery'yi otomatik olarak sorgular, demografik bilgileri tanımlar ve sizin için e-postayı taslak olarak hazırlar.
10. Ortamınızı temizleme
Google Cloud hesabınızın sürekli olarak ücretlendirilmesini önlemek ve projenizi gelecekteki çalıştırmalar için temiz bir şekilde sıfırlamak istiyorsanız bu codelab sırasında oluşturulan kaynakları silmeniz gerekir.
cleanup.sh komut dosyasını oluşturmak için aşağıdaki bloğu çalıştırın. Bu komut dosyası, otomatik bir sökme mekanizması gibi davranarak daha fazla faturalandırmayı önlemek için AlloyDB kümesini ve örneğini, BigQuery veri kümelerini ve Cloud Storage paketinizi kalıcı olarak kaldırır.
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
Kaynaklarınızı güvenli bir şekilde silmek için temizleme komut dosyasını çalıştırın:
bash cleanup.sh
11. Tebrikler!
Bulutlar arası açık bir veri gölü evi oluşturup sorguladınız.
Öğrendikleriniz:
- BigQuery Zero-ETL ve Google Cloud Lakehouse kullanarak farklı kaynaklardaki verileri nasıl birleştireceğinizi öğrenin.
- Managed Service for Apache Spark'ın büyük vektörel birleştirme işlemlerinde C++ yerel Lightning Engine'den nasıl yararlanılır?
- Doğal dil keşfi için BigQuery Veri Aracısı'nı kullanma
- Model Context Protocol (MCP) ve Gemini'ı kullanarak verilerinizi Gemini'a nasıl bağlayacağınızı öğrenin.
Sırada ne var?
- Lakehouse belgelerini inceleyin.
- AlloyDB'den BigQuery'ye sıfır ETL hakkında daha fazla bilgi edinin.
- Lightning Engine hakkında bilgi edinin.