
1. Giới thiệu
Trong lớp học lập trình này, bạn sẽ xây dựng một hồ dữ liệu mở trên nhiều đám mây, hợp nhất các dữ liệu được lưu trữ tách biệt trên AWS, Google Cloud và AlloyDB mà không cần đến quy trình ETL phức tạp. Bạn sẽ sử dụng Lakehouse làm trung tâm thông tin tình báo, AlloyDB làm nguồn dữ liệu hoạt động và Dịch vụ được quản lý cho Apache Spark để xử lý theo vectơ hiệu suất cao. Cuối cùng, bạn sẽ sử dụng Gemini để rút ra thông tin chi tiết hữu ích về hoạt động kinh doanh từ lakehouse của mình.
Hãy tưởng tượng dữ liệu giao dịch của bạn (users, orders, order items) nằm trong cơ sở dữ liệu AlloyDB hoạt động, dữ liệu product nằm trong một vùng chứa AWS S3 và luồng dữ liệu nhấp chuột event logs khổng lồ được lưu trữ trong Cloud Storage. Bạn cần kết hợp các tập dữ liệu này để xác định thông tin nhân khẩu học mục tiêu cho chiến dịch tiếp thị tiếp theo và tạo email liên hệ được cá nhân hoá.
Điều kiện tiên quyết
- Quen thuộc với các lệnh cơ bản về SQL và thiết bị đầu cuối.
- Một dự án trên Google Cloud đã bật tính năng thanh toán.
Kiến thức bạn sẽ học được
- Cách tích hợp các kho dữ liệu riêng biệt bằng cách sử dụng BigQuery zero-ETL (AlloyDB) và Lakehouse cho Apache Iceberg.
- Cách chạy một công việc lập hồ sơ hành vi tốc độ cao bằng Dịch vụ được quản lý cho Apache Spark dựa trên Lightning Engine gốc C++.
- Cách sử dụng tác nhân dữ liệu BigQuery để thực hiện phân tích ngôn ngữ tự nhiên phức tạp trên dữ liệu hợp nhất.
- Cách định cấu hình Giao thức ngữ cảnh mô hình (MCP) để cho phép Gemini CLI đọc từ Lakehouse cho Apache Iceberg và soạn thảo nội dung tiếp thị.
Bạn cần có
- Tài khoản Google Cloud và dự án trên Google Cloud
- Một trình duyệt web như Chrome
Bạn cần có
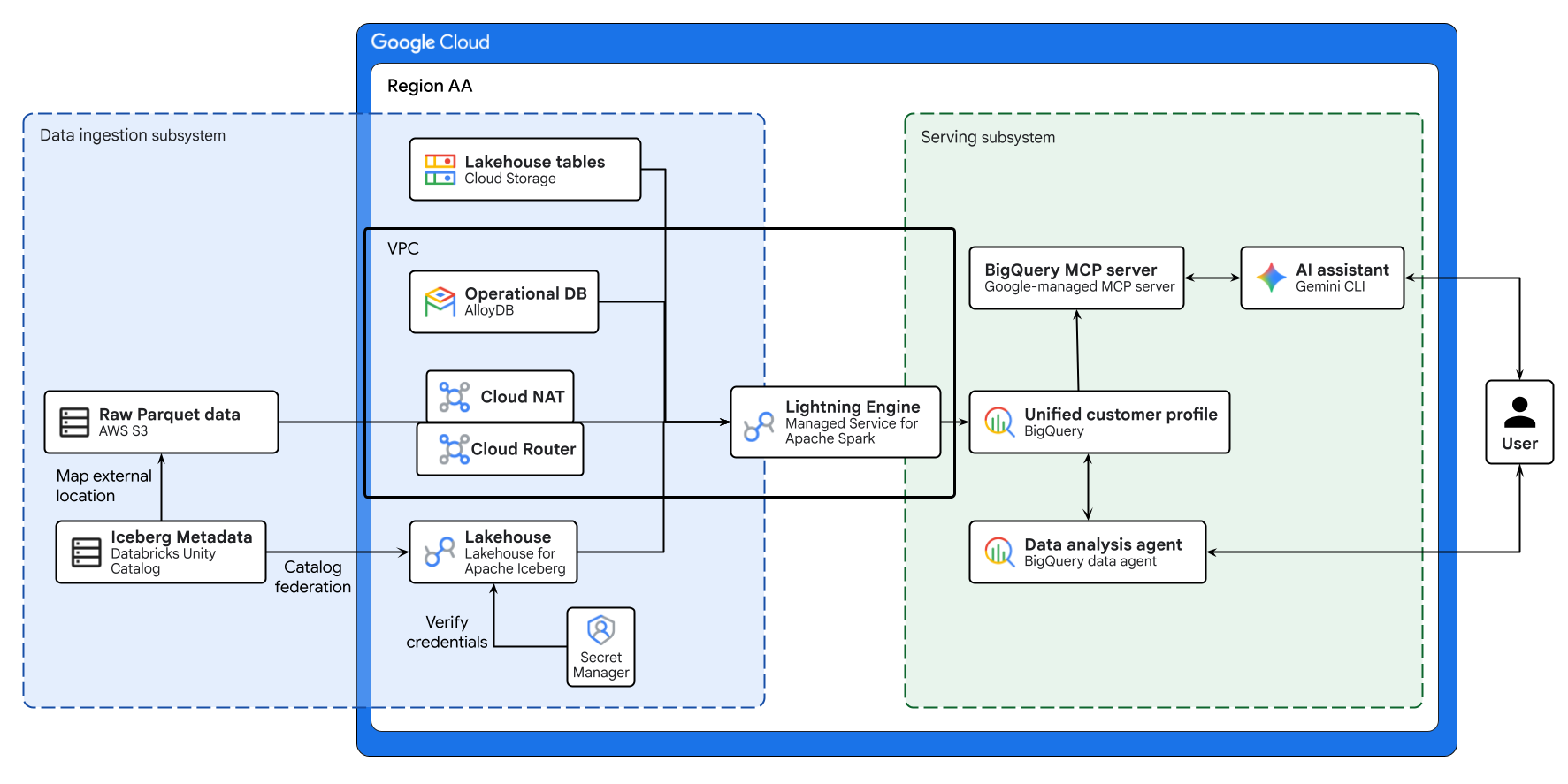
Sơ đồ ở trên minh hoạ quy trình xuyên suốt của lakehouse trên nhiều đám mây được xây dựng trong lớp học lập trình này. Dữ liệu vận hành từ AlloyDB và dữ liệu từ xa từ AWS S3 được liên kết một cách an toàn bằng Lakehouse cho Apache Iceberg. Dịch vụ được quản lý cho Apache Spark xử lý những nguồn dữ liệu riêng biệt này để tạo hồ sơ khách hàng hợp nhất trong BigQuery. Cuối cùng, một BigQuery Data Agent và máy chủ MCP BigQuery do Google quản lý thông qua Gemini CLI sẽ cung cấp một giao diện trực quan, dựa trên AI để phân tích dữ liệu nâng cao.
Các khái niệm chính
- Data lakehouse mở trên nhiều đám mây: Hợp nhất các kho dữ liệu riêng biệt trên AWS, Google Cloud và môi trường tại chỗ mà không cần ETL phức tạp.
- ETL bằng 0 của BigQuery: Cho phép truy vấn trực tiếp các cơ sở dữ liệu hoạt động mà không cần di chuyển dữ liệu phức tạp.
- Lakehouse cho Apache Iceberg: Cho phép bảo mật và quản trị nhất quán trên bộ nhớ đa đám mây bằng cách sử dụng định dạng Apache Iceberg.
- Lightning Engine: Công cụ gốc C++ để thực thi Apache Spark hiệu suất cao.
- Giao thức ngữ cảnh mô hình (MCP): Kết nối Gemini trực tiếp với lakehouse BigQuery của bạn.
2. Thiết lập và yêu cầu
Tạo một dự án trên Google Cloud
- Trong Google Cloud Console, trên trang chọn dự án, hãy chọn hoặc tạo một dự án trên Google Cloud.
- Đảm bảo rằng bạn đã bật tính năng thanh toán cho dự án trên Cloud. Tìm hiểu cách kiểm tra xem tính năng thanh toán có được bật trên một dự án hay không.
Khởi động Cloud Shell
Mặc dù có thể vận hành Google Cloud từ xa trên máy tính xách tay, nhưng trong lớp học lập trình này, bạn sẽ sử dụng Google Cloud Shell, một môi trường dòng lệnh chạy trên Cloud.
Trên Bảng điều khiển Google Cloud, hãy nhấp vào biểu tượng Cloud Shell trên thanh công cụ ở trên cùng bên phải:
Quá trình này chỉ mất vài phút để cung cấp và kết nối với môi trường. Khi quá trình này kết thúc, bạn sẽ thấy như sau:

Máy ảo này được trang bị tất cả các công cụ phát triển mà bạn cần. Nền tảng này cung cấp một thư mục chính có dung lượng 5 GB và chạy trên Google Cloud, giúp tăng cường đáng kể hiệu suất mạng và hoạt động xác thực. Bạn có thể thực hiện mọi thao tác trong lớp học lập trình này trong trình duyệt. Bạn không cần cài đặt bất cứ thứ gì.
Khởi chạy môi trường
Mở Cloud Shell và đặt các biến dự án để đảm bảo tất cả các lệnh đều nhắm đến cơ sở hạ tầng phù hợp.
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
Áp dụng các biến cho phiên hoạt động:
source ./env.sh
Cho phép API
Bật các dịch vụ cần thiết của Google Cloud.
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3. Thiết lập cơ sở hạ tầng cốt lõi
Thay vì di chuyển tất cả dữ liệu vào một kho lưu trữ duy nhất thông qua các pipeline ETL dễ bị lỗi, bạn sẽ xây dựng một cấu trúc liên kết trên nhiều đám mây. Trong một doanh nghiệp thực tế, dữ liệu vốn dĩ bị phân mảnh do các yêu cầu về hệ thống khác nhau. Bạn sẽ điều phối các nguồn dữ liệu sau:
- AlloyDB (Cơ sở dữ liệu giao dịch cốt lõi): Lưu trữ dữ liệu người dùng, đơn đặt hàng và mặt hàng trong đơn đặt hàng. Là một cơ sở dữ liệu hoạt động trực tiếp, nó đảm bảo các thuộc tính ACID cần thiết cho các giao dịch tài chính và thông tin cập nhật về hồ sơ.
- AWS S3 (Dữ liệu chính): Lưu trữ danh mục
products. Đại diện cho một hệ thống quản lý dữ liệu chính (MDM) cũ trên AWS. - Google Cloud Storage (Hồ dữ liệu khổng lồ): Lưu trữ
events(nhật ký luồng nhấp). Dữ liệu có thông lượng cao như nhật ký web sẽ làm hỏng cơ sở dữ liệu quan hệ. Bộ nhớ đối tượng có khả năng mở rộng vô hạn và việc lưu trữ bộ nhớ này trong Google Cloud sẽ tối đa hoá khả năng tính toán cục bộ cho các công cụ phân tích của bạn.
Trước tiên, hãy định cấu hình mạng cơ bản. Các cơ sở dữ liệu do Google Cloud quản lý như AlloyDB yêu cầu có một kết nối ngang hàng VPC riêng tư để giao tiếp an toàn trong mạng dự án của bạn.
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
Tiếp theo, hãy tạo một tập dữ liệu BigQuery và một mối kết nối tài nguyên đám mây Lakehouse. Về mặt cấu trúc, một kết nối tài nguyên sẽ uỷ quyền truy cập dữ liệu cho một tài khoản dịch vụ chuyên dụng do Google quản lý, thực thi nguyên tắc về đặc quyền tối thiểu.
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. Cung cấp cơ sở dữ liệu hoạt động
Cung cấp một phiên bản chính của AlloyDB và chèn dữ liệu giao dịch quan trọng.
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
Sau khi cơ sở dữ liệu sẵn sàng, bạn phải tạo một kết nối bên ngoài BigQuery với AlloyDB. Kết nối này lưu trữ an toàn thông tin đăng nhập và điểm cuối của cơ sở dữ liệu, cho phép BigQuery chuyển việc thực thi SQL trực tiếp xuống công cụ tính toán AlloyDB (không cần ETL).
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
Đẩy các bảng giao dịch vào AlloyDB một cách an toàn. Sử dụng AlloyDB Auth Proxy để kết nối an toàn phiên Cloud Shell cục bộ với thực thể AlloyDB riêng tư. Nhờ đó, bạn có thể đẩy dữ liệu giao dịch bằng các công cụ dòng lệnh cục bộ.
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5. Liên kết dữ liệu chính (AWS spoke)
Danh mục sản phẩm của chúng tôi (chứa siêu dữ liệu thô của mặt hàng) nằm trên AWS S3 dưới dạng các bảng Apache Iceberg. Siêu dữ liệu được quản lý bằng một danh mục từ xa.
Thay vì xây dựng các quy trình ETL dễ bị lỗi để sao chép dữ liệu này vào Google Cloud, bạn sẽ sử dụng Lakehouse cho Apache Iceberg (liên kết danh mục REST).
Phương pháp ETL bằng 0 này cho phép Lakehouse và Dịch vụ được quản lý cho Apache Spark tự động khám phá và đọc siêu dữ liệu Iceberg cũng như các tệp Parquet cơ bản ngay từ môi trường từ xa của bạn.
Nếu có tài khoản AWS đang hoạt động và đã thiết lập Databricks Unity Catalog, bạn có thể sử dụng tài khoản đó. Nếu không, bạn có thể mô phỏng môi trường bằng Google Cloud Storage. Hãy chọn một trong hai.
Lựa chọn A: Sử dụng AWS của riêng bạn (Apache Iceberg gốc)
Điều kiện tiên quyết: Lựa chọn này giả định rằng bạn đã cung cấp một bộ chứa AWS S3, kết nối bộ chứa đó dưới dạng một vị trí bên ngoài trong Danh mục hợp nhất Databricks, ánh xạ một bảng Iceberg và tạo một chủ thể dịch vụ OAuth có quyền đọc.
1. Vùng lưu trữ thông tin xác thực an toàn
Mã hoá cứng mã truy cập có thời hạn dài là một mẫu chống kiến trúc. Bạn sẽ lưu trữ mã ứng dụng OAuth và khoá bí mật của Databricks trong Google Cloud Secret Manager. Dịch vụ Lakehouse sẽ tìm nạp những thông tin này một cách linh động trong thời gian chạy để cung cấp các mã thông báo ngắn hạn, tập trung việc quản lý thông tin đăng nhập của bạn.
Chạy khối sau để tạo tập lệnh. (Chưa chỉnh sửa nội dung nào).
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
Sau đó, hãy chạy lệnh sau để tự động mở tập lệnh đã tạo trong trình soạn thảo mã ở phía trên thiết bị đầu cuối.
cloudshell edit create_secret.sh
- Trong trình chỉnh sửa, hãy thay thế phần giữ chỗ
<YOUR_...>bằng thông tin đăng nhập thực tế của bạn trên Databricks. - Đảm bảo URL của không gian làm việc không chứa
https://hoặc dấu gạch chéo ở cuối (ví dụ:123456789.cloud.databricks.com). - Nhấn
Ctrl+S(hoặcCmd+Strên máy Mac) để lưu tệp. - Quay lại phiên thiết bị đầu cuối và thực thi tập lệnh:
source create_secret.sh
2. Tạo danh mục liên kết
Để đơn giản hoá lớp học lập trình này, bạn sẽ định cấu hình danh mục để di chuyển an toàn trên Internet công cộng. Tuy nhiên, đối với các khối lượng công việc sản xuất, việc truy vấn các tập dữ liệu lớn qua Internet công cộng sẽ phát sinh chi phí truyền dữ liệu không cần thiết và độ trễ không thể đoán trước. Phương pháp hay nhất là định cấu hình một Cloud Interconnect riêng tư giữa các đám mây (CCI) giữa AWS và Google Cloud. Việc này giúp giảm đáng kể chi phí truyền dữ liệu ra ngoài và đảm bảo hiệu suất mạng xác định.
Sử dụng gcloud CLI để cung cấp danh mục Lakehouse được liên kết:
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. Áp dụng các mối liên kết IAM có đặc quyền tối thiểu
Khi bạn cung cấp danh mục liên kết ở bước trước, Google Cloud Lakehouse sẽ tự động chạy một tác vụ làm mới ở chế độ nền để đồng bộ hoá các tệp kê khai Iceberg sau mỗi 330 giây.
Bạn phải cấp vai trò secretAccessor cho tài khoản dịch vụ danh mục Lakehouse để tài khoản này có thể tìm nạp mã thông báo OAuth của Databricks một cách an toàn trong quá trình đồng bộ hoá trong nền và thực thi truy vấn. Việc thiếu liên kết này sẽ dẫn đến lỗi 403 âm thầm khi Lakehouse cố gắng cập nhật danh mục.
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. Bật Internet đi ra cho Dịch vụ được quản lý cho Apache Spark
Trong bước tiếp theo, Dịch vụ được quản lý cho Apache Spark sẽ đọc dữ liệu AWS từ xa. Vì Managed Service for Apache Spark Serverless chạy hoàn toàn trong mạng VPC riêng tư mà không có địa chỉ IP ngoài, nên theo mặc định, dịch vụ này không thể truy cập vào AWS S3 qua Internet. Bạn phải cung cấp một NAT đám mây để cho phép các worker Spark truy cập vào Internet từ bên ngoài.
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. Xác định mục tiêu hạ nguồn
Xuất biến số này để các công việc Apache Spark ở hạ nguồn biết chính xác vị trí cần truy vấn dữ liệu AWS mà không cần thay đổi mã theo cách thủ công.
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
Lựa chọn B: Mô phỏng môi trường AWS thông qua Cloud Storage
Nếu không có tài khoản AWS đang hoạt động, bạn có thể mô phỏng silo trên nhiều đám mây một cách tự nhiên bằng cách sử dụng các bảng được quản lý Lakehouse trên Google Cloud Storage.
1. Tạo bảng Iceberg mô phỏng
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. Xác định mục tiêu hạ nguồn
Tập dữ liệu BigQuery tiêu chuẩn sử dụng cấu trúc không gian tên gồm 3 phần (project.dataset.table). Xuất biến này để công việc Apache Spark ở hạ nguồn nhắm đến dữ liệu mô phỏng.
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. Truy cập nhật ký sự kiện (vùng Google Cloud)
Dữ liệu luồng nhấp tăng theo cấp số nhân. Bạn lưu trữ các sự kiện thô, chưa được tổng hợp hoàn chỉnh trên thiết bị trong Cloud Storage dưới dạng các bảng Managed Lakehouse.
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. Xây dựng hồ sơ khách hàng hợp nhất
Sau khi cơ sở hạ tầng thô của bạn được điền đầy đủ, đã đến lúc xây dựng một hồ sơ khách hàng hợp nhất.
Bạn sẽ sử dụng Dịch vụ được quản lý cho Apache Spark do Lightning Engine cung cấp. Lightning Engine là trình tăng tốc truy vấn gốc C++ hiệu suất cao của Google Cloud, được xây dựng trên các công nghệ nguồn mở như Apache Gluten và Velox, tự động tăng cường quá trình thực thi bằng cách tối đa hoá hiệu suất CPU và lưu dữ liệu vào bộ nhớ đệm một cách thông minh. Phương pháp này lý tưởng khi thực hiện các thao tác kết hợp nhiều chiều trên quy mô lớn, phân cửa sổ phức tạp hoặc tổng hợp hành vi trên nhiều đám mây.
Bạn sẽ sử dụng trình kết nối Spark BigQuery để đọc trực tiếp các truy vấn liên kết AlloyDB không cần ETL và các bảng Lakehouse, thực hiện các phép tổng hợp được vectơ hoá quy mô lớn một cách tự nhiên trong Spark và ghi hồ sơ hợp nhất thu được trở lại BigQuery.
Định cấu hình quyền IAM cho Dịch vụ được quản lý cho Apache Spark
Theo mặc định, Serverless Spark sẽ thực thi các công việc hàng loạt bằng tài khoản dịch vụ mặc định của Compute Engine. Trước khi gửi công việc, bạn phải cấp cho tài khoản dịch vụ này các quyền cần thiết để thực thi khối lượng công việc và quản lý các công việc BigQuery.
(Lưu ý: Mặc dù tên dịch vụ đã thay đổi thành Dịch vụ được quản lý cho Apache Spark để phản ánh thuật ngữ tiêu chuẩn trong ngành, nhưng các lệnh API cơ bản và vai trò IAM vẫn sử dụng giá trị nhận dạng dataproc).
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
Tạo và gửi lệnh
Trước tiên, hãy tạo tập lệnh công việc PySpark. Tập lệnh này tự động phát hiện xem bạn đã chọn Lựa chọn A (Danh mục liên kết AWS) hay Lựa chọn B (Google Cloud Mock) dựa trên biến môi trường AWS_PRODUCTS_TABLE, xác định logic Spark SQL và sử dụng thao tác mảng gốc của Spark để tính toán các khoảng thời gian RFM (mức độ gần đây, tần suất, giá trị tiền tệ).
Chạy khối sau trong Cloud Shell.
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
Sau khi tập lệnh được lắp ráp hoàn chỉnh và các cấu hình bắt buộc được chèn động, hãy gửi công việc hàng loạt đến Managed Apache Spark Serverless.
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
Xác minh quá trình thực thi công việc trong bảng điều khiển
Sau khi gửi lệnh hàng loạt, bạn có thể xác minh rằng lệnh đó đang sử dụng công cụ thực thi C++ tăng tốc:
- Trong bảng điều khiển Cloud, hãy chuyển đến Dịch vụ được quản lý cho Apache Spark > Không máy chủ > Batch.
- Nhấp vào lệnh đang chạy.
- Trong ngăn thông tin chi tiết về công việc, hãy xác minh rằng thuộc tính Cấp được đặt thành
Premiumvà Công cụ được đặt thànhLightning Engine.
8. Phân tích bằng tác nhân dữ liệu BigQuery
Giờ đây, bạn đã liên kết dữ liệu phân tán trên nhiều đám mây và thực hiện các hoạt động tổng hợp hành vi phức tạp bằng Managed Service for Apache Spark, bước tiếp theo là phân tích dữ liệu.
Trước tiên, hãy kiểm tra giản đồ của bảng hồ sơ hợp nhất mới tạo trong giao diện người dùng BigQuery để hiểu rõ cấu trúc dữ liệu mà bạn đang hiển thị cho tác nhân:
- Trong bảng điều khiển Cloud, hãy chuyển đến BigQuery.
- Trong ngăn Explorer (Trình khám phá) ở bên trái, hãy mở rộng dự án và tập dữ liệu
demo_lakehouse. - Nhấp vào bảng
unified_customer_profile. - Chọn thẻ Giản đồ trong không gian làm việc chính.
Kiểm tra giản đồ của bảng mới. Cột top_preferences là một REPEATED STRUCT (một mảng gồm các bản ghi chứa category, brand và sale_price). Theo truyền thống, việc truy vấn các mảng lồng nhau đòi hỏi phải có SQL phức tạp bằng cách sử dụng hàm UNNEST(). Đây có thể là một trở ngại đối với các nhà phân tích kinh doanh. Bằng cách liên kết thực tế một tác nhân dữ liệu BigQuery trong bảng cụ thể này, tác nhân sẽ hiểu rõ giản đồ và xử lý các thao tác phức tạp của SQL chuẩn của Google một cách tự nhiên.
Tạo tác nhân dữ liệu
Trong phần này, bạn sẽ tạo và tương tác với một tác nhân dữ liệu BigQuery. Thay vì viết SQL phức tạp theo cách thủ công để huỷ lồng mảng và tính toán các chỉ số, bạn sẽ cung cấp một tác nhân AI được giới hạn phạm vi cụ thể cho hồ sơ hợp nhất mới tạo, cho phép khám phá dữ liệu bằng ngôn ngữ tự nhiên.
- Trong ngăn điều hướng bên trái, hãy tìm và nhấp vào Nhân viên hỗ trợ.
- Nhấp vào + New Agent (+ Tác nhân mới) để khởi tạo một trợ lý AI mới.
- Định cấu hình Agent:
- Tên tác nhân:
Retail VIP Analysis Agent - Nguồn dữ liệu: Nhấp vào Thêm nguồn rồi tìm kiếm bảng
unified_customer_profile.
- Nhấp vào Thêm rồi chờ vài giây để Trợ lý khởi động không gian làm việc của mình.
Sau khi thiết lập tác nhân, việc xác định rõ ràng Hướng dẫn hệ thống là một hoạt động quan trọng trong việc quản trị dữ liệu. Sử dụng Chỉ dẫn hệ thống làm Lớp ngữ nghĩa. Bằng cách nhúng các định nghĩa kinh doanh trên toàn doanh nghiệp, xử lý các độ phức tạp của giản đồ và thiết lập các biện pháp bảo vệ phân tích, bạn sẽ loại bỏ độ phức tạp về kỹ thuật khỏi người dùng cuối và ngăn LLM rút ra kết luận từ dữ liệu không đáng kể về mặt thống kê.
Dán nội dung sau vào trường Hướng dẫn:
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
Đưa ra câu lệnh cho nhân viên hỗ trợ
Vì logic nghiệp vụ phức tạp (định nghĩa chính xác về "Khách hàng VIP có nguy cơ") và các yêu cầu xử lý giản đồ chịu sự điều chỉnh của Chỉ dẫn hệ thống một cách an toàn, nên nhà phân tích dữ liệu không cần viết một câu lệnh dài dòng và có nhiều điều kiện.
Trong giao diện trò chuyện, hãy nhập câu lệnh sau:
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
Đánh giá thông tin chi tiết được tạo
Sau khi gửi câu lệnh, hãy xem xét kỹ lưỡng kết quả được tạo tự nhiên để đánh giá cách BigQuery Data Agent thực thi Chỉ dẫn hệ thống của bạn, đóng vai trò là cả lớp ngữ nghĩa được quản lý và hàng rào phân tích.
Trước tiên, hãy đọc văn bản tóm tắt được tạo ở phía trên dữ liệu. Lưu ý cách tác nhân tự động dịch yêu cầu đơn giản của bạn về "Khách hàng VIP có nguy cơ" thành các ngưỡng chỉ số chính xác được xác định trong Chỉ dẫn hệ thống (ví dụ: tham chiếu đến lifetime_value > 100, cart_adds > 0 và 90 ngày không hoạt động). Điều này xác nhận rằng tác nhân đã nội bộ hoá logic nghiệp vụ của bạn, tức là người dùng cuối không bao giờ cần ghi nhớ hoặc mã hoá cứng logic phức tạp trong các câu lệnh hằng ngày.
Tiếp theo, hãy mở rộng chế độ xem SQL để kiểm tra mã đã tạo. Dựa trên hướng dẫn của bạn, tác nhân phải tạo ra SQL chuẩn của Google một cách chính xác về mặt toán học:
- Khoảng thời gian linh hoạt: Tìm phép tính dấu thời gian trong mệnh đề
WHERE(thường dùngTIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY)). - Tuân thủ nghiêm ngặt lược đồ: Xác nhận rằng tác nhân đã tuân thủ các quy tắc nghiêm ngặt về lược đồ của bạn bằng cách áp dụng rõ ràng hàm
UNNEST()cho mảngtop_preferences. Để tách biệt chính xác danh mục thường xuyên nhất cho mỗi quốc gia, bạn thường thấy danh mục này sử dụng các kỹ thuật nâng cao như hàm cửa sổROW_NUMBER() OVER()trong Biểu thức bảng chung (CTE).
Xem biểu đồ và bảng dữ liệu được hiển thị tự động. Dữ liệu này sẽ cho thấy một cách trực quan các thị trường giữ chân khách hàng cốt lõi của bạn (thường làm nổi bật những quốc gia có số lượng lớn như Trung Quốc hoặc Hoa Kỳ) cùng với những sản phẩm được ưa chuộng nhất trên toàn cầu (thường là "Quần jean"). Lưu ý cách cấu trúc giao diện người dùng gốc cho đầu ra để sử dụng ngay mà không cần mã trực quan hoá rõ ràng.
Đọc kỹ văn bản Thông tin chi tiết dạng gạch đầu dòng do tác nhân tạo. Vì bạn đã thiết lập Analytical Guardrails, hãy tìm thông tin chi tiết cụ thể về Chất lượng dữ liệu hoặc Ý nghĩa thống kê. Bạn có thể thấy tác nhân gắn cờ rõ ràng các quốc gia ở cuối bảng có số lượng người dùng rất thấp (ví dụ: những khu vực chỉ có một số ít người dùng). Thay vì tạo ra một chiến dịch tiếp thị nhắm mục tiêu một cách mù quáng dựa trên một điểm dữ liệu duy nhất, tác nhân sẽ tư vấn chính xác rằng những điểm bất thường này không có ý nghĩa thống kê đối với một chiến lược quy mô lớn. Điều này minh hoạ cách nhúng các biện pháp bảo vệ quản trị trực tiếp vào tác nhân một cách hiệu quả giúp ngăn chặn các lỗi tính toán sai do AI gây ra trong hoạt động kinh doanh.
9. Tạo thông tin chi tiết dựa trên AI bằng Gemini và MCP
Nhân viên hỗ trợ đã xác định thành công nhóm đối tượng nhân khẩu học mục tiêu chính: khách hàng VIP có nguy cơ ở một số quốc gia cụ thể. Tuy nhiên, công việc của nhà phân tích chỉ dừng lại ở thông tin chi tiết. Để thu hút lại những người dùng này, nhóm tiếp thị phải thực hiện một chiến dịch.
Bạn sẽ sử dụng Giao thức ngữ cảnh mô hình (MCP) để kết nối trực tiếp một trợ lý AI bên ngoài với danh sách nhân khẩu học cụ thể này trong BigQuery, chuyển từ phân tích dữ liệu sang hành động dựa trên AI mà không cần xây dựng API tuỳ chỉnh.
Định cấu hình máy chủ MCP BigQuery
Chạy khối bên dưới để tạo tệp cấu hình mcp.json. Tệp này cung cấp các thông số kết nối cần thiết để Gemini CLI có thể giao tiếp an toàn với BigQuery.
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
Tạo email tiếp thị
Khởi động công cụ Gemini CLI từ cửa sổ dòng lệnh, truyền rõ ràng cờ cấu hình MCP để cho phép công cụ này đọc lakehouse BigQuery của bạn.
Chạy Gemini CLI.
source env.sh
gemini
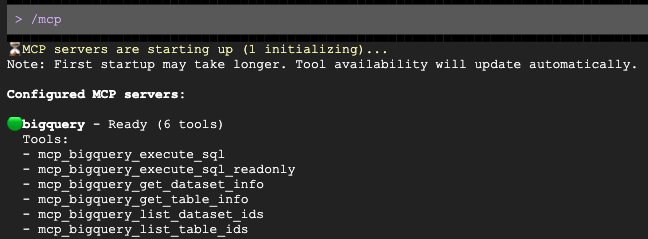
Sau khi lời nhắc mở ra, hãy yêu cầu lời nhắc đó soạn thảo một thông tin liên hệ được cá nhân hoá cho nhóm nhân khẩu học mục tiêu của bạn:
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
Gemini sẽ tự động truy vấn BigQuery thông qua máy chủ MCP, xác định thông tin nhân khẩu học và soạn thảo email cho bạn!
10. Dọn dẹp môi trường
Để tránh các khoản phí liên tục cho tài khoản Google Cloud của bạn và thiết lập lại dự án một cách gọn gàng cho các lần chạy trong tương lai, bạn phải xoá các tài nguyên đã tạo trong lớp học lập trình này.
Chạy khối sau để tạo tập lệnh cleanup.sh. Tập lệnh này đóng vai trò là cơ chế tháo dỡ tự động, xoá vĩnh viễn cụm và phiên bản AlloyDB, tập dữ liệu BigQuery và vùng chứa Cloud Storage của bạn để ngăn phát sinh thêm chi phí.
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
Chạy tập lệnh dọn dẹp để xoá tài nguyên một cách an toàn:
bash cleanup.sh
11. Xin chúc mừng!
Bạn đã tạo và truy vấn thành công một kho dữ liệu mở đa đám mây.
Bạn đã tìm hiểu:
- Cách liên kết dữ liệu từ nhiều nguồn bằng BigQuery Zero-ETL và Google Cloud Lakehouse.
- Cách tận dụng Lightning Engine gốc C++ trong các hoạt động kết hợp được vectơ hoá quy mô lớn của Dịch vụ được quản lý cho Apache Spark.
- Cách sử dụng BigQuery Data Agent để khám phá bằng ngôn ngữ tự nhiên.
- Cách kết nối dữ liệu của bạn với Gemini bằng Giao thức ngữ cảnh mô hình (MCP) và Gemini.
Các bước tiếp theo
- Khám phá tài liệu về Lakehouse
- Tìm hiểu thêm về AlloyDB zero-ETL đến BigQuery
- Đọc về Lightning Engine