
1. 简介
在此 Codelab 中,您将构建一个跨云的开放式数据湖仓,用于统一 AWS、Google Cloud 和 AlloyDB 中的数据孤岛,而无需复杂的 ETL。您将使用 Lakehouse 作为中央智能枢纽,使用 AlloyDB 作为操作数据源,并使用 Managed Service for Apache Spark 进行高性能矢量化处理。最后,您将使用 Gemini 从数据湖仓中获取强大的业务洞见。
假设您的事务性数据(users、orders、order items)位于操作型 AlloyDB 数据库中,product 数据位于 AWS S3 存储分区中,而海量点击流 event logs 存储在 Cloud Storage 中。您需要联接这些数据集,以确定下一个营销活动的受众特征,并生成个性化的主动联系电子邮件。
前提条件
- 熟悉基本的 SQL 和终端命令。
- 启用了结算功能的 Google Cloud 项目。
学习内容
- 如何使用 BigQuery 零 ETL (AlloyDB) 和 Lakehouse for Apache Iceberg 集成不同的数据孤岛。
- 如何使用由 C++ 原生 Lightning Engine 提供支持的 Managed Service for Apache Spark 运行高速行为分析作业。
- 如何使用 BigQuery 数据代理对统一数据执行复杂的自然语言分析。
- 如何配置 Model Context Protocol (MCP),以允许 Gemini CLI 从 Lakehouse for Apache Iceberg 读取数据并起草营销内容。
所需条件
- Google Cloud 账号和 Google Cloud 项目
- 网络浏览器,例如 Chrome
所需条件
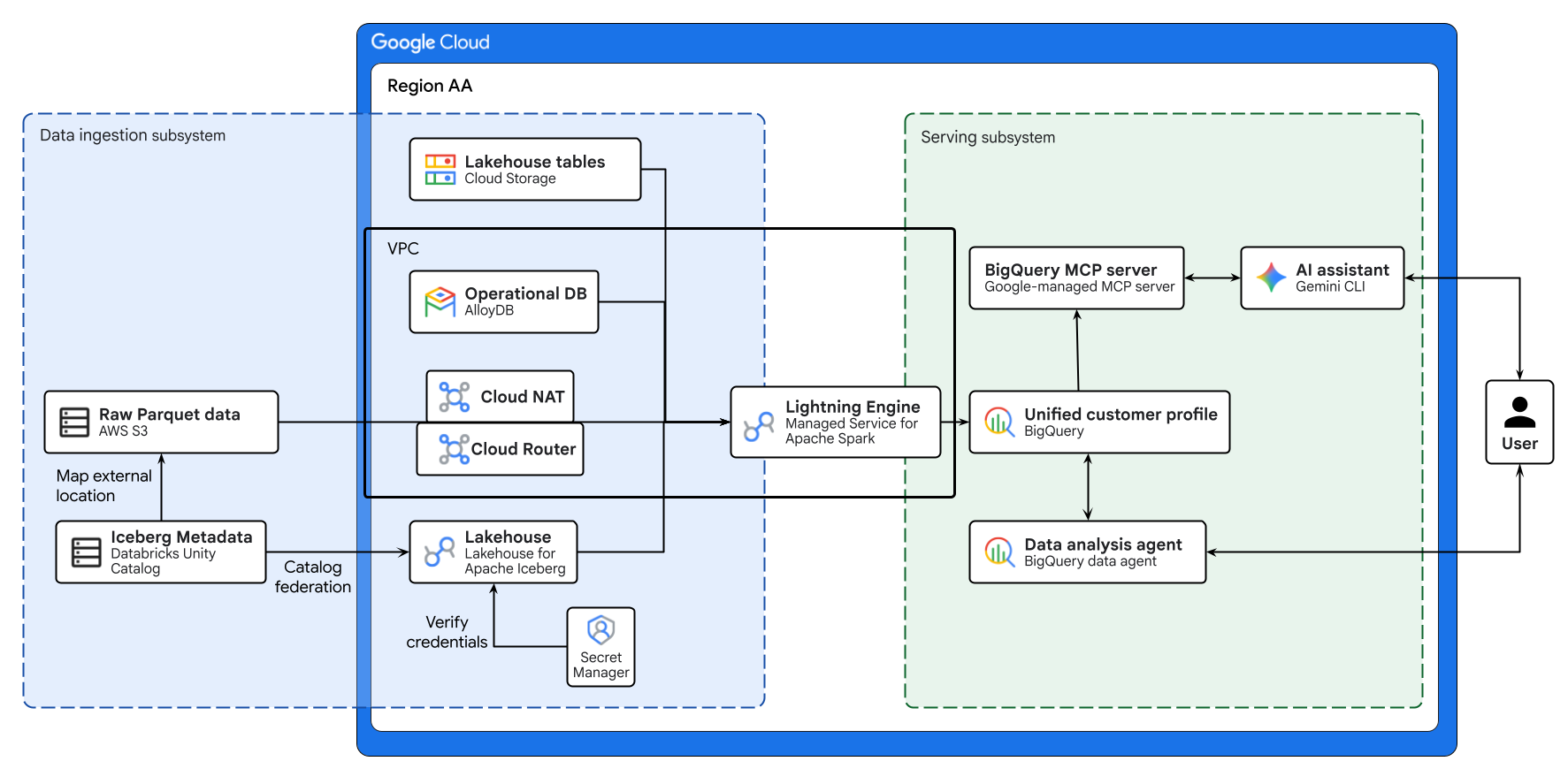
上图展示了在此 Codelab 中构建的跨云湖仓一体的端到端流程。借助 Lakehouse for Apache Iceberg,可以安全地联合使用来自 AlloyDB 的运营数据和来自 AWS S3 的远程数据。Managed Service for Apache Spark 会处理这些不同的来源,以便在 BigQuery 中构建统一的客户资料。最后,通过 Gemini CLI 使用 BigQuery Data Agent 和 Google 管理的 BigQuery MCP 服务器,可提供直观的 AI 驱动型界面,用于进行高级数据分析。
主要概念
- 跨云开放式数据湖仓一体:统一了 AWS、Google Cloud 和本地环境中的数据孤岛,无需复杂的 ETL。
- BigQuery 零 ETL:支持直接查询运营数据库,无需复杂的数据移动。
- Lakehouse for Apache Iceberg:使用 Apache Iceberg 格式,可在跨云存储空间中实现一致的安全性和治理。
- Lightning Engine:C++ 原生引擎,可实现高性能 Apache Spark 执行。
- Model Context Protocol (MCP):将 Gemini 直接连接到 BigQuery 数据湖仓。
2. 设置和要求
创建 Google Cloud 项目
- 在 Google Cloud 控制台的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的 Cloud 项目已启用结算功能。了解如何检查项目是否已启用结算功能。
启动 Cloud Shell
虽然可以通过笔记本电脑对 Google Cloud 进行远程操作,但在此 Codelab 中,您将使用 Google Cloud Shell,这是一个在云端运行的命令行环境。
在 Google Cloud 控制台 中,点击右上角工具栏中的 Cloud Shell 图标:
预配和连接到环境应该只需要片刻时间。完成后,您应该会看到如下内容:

这个虚拟机已加载了您需要的所有开发工具。它提供了一个持久的 5 GB 主目录,并且在 Google Cloud 中运行,大大增强了网络性能和身份验证功能。您在此 Codelab 中的所有工作都可以在浏览器中完成。您无需安装任何程序。
初始化环境
打开 Cloud Shell 并设置项目变量,以确保所有命令都指向正确的基础设施。
cat << 'EOF' > env.sh
#!/bin/bash
# env.sh: Environment variables
export PROJECT_ID=$(gcloud config get-value project)
export REGION="us-west1"
export NETWORK_NAME="default"
export BUCKET_NAME="lakehouse-data-${PROJECT_ID}"
export BQ_DATASET="demo_lakehouse"
export BQ_RESOURCE_CONN="lakehouse-iceberg-conn"
export BQ_ALLOYDB_CONN="alloydb-fed-conn"
export ALLOYDB_CLUSTER="demo-alloy-cluster"
export ALLOYDB_INSTANCE="demo-alloy-primary"
export ALLOYDB_PASSWORD="SuperSecretPassword123!"
export ALLOYDB_DB_NAME="retail_db"
# Multi-cloud configuration identifiers
export SECRET_NAME="dbx-oauth-secret"
export CATALOG_NAME="aws_dbx_catalog"
EOF
将变量应用于活跃会话:
source ./env.sh
启用 API
启用必要的 Google Cloud 服务。
gcloud services enable \
geminidataanalytics.googleapis.com \
cloudaicompanion.googleapis.com \
compute.googleapis.com \
biglake.googleapis.com \
bigquery.googleapis.com \
bigqueryconnection.googleapis.com \
alloydb.googleapis.com \
servicenetworking.googleapis.com \
secretmanager.googleapis.com \
dataplex.googleapis.com \
datacatalog.googleapis.com \
dataform.googleapis.com \
dataproc.googleapis.com --quiet
3. 设置核心基础架构
您将构建一个联合的跨云架构,而不是通过脆弱的 ETL 流水线将所有数据移至单个代码库。在实际的企业中,由于系统要求各不相同,数据本身就存在碎片化问题。您将编排以下数据源:
- AlloyDB(核心事务型数据库):存储用户、订单和 order_items 数据。作为实时运营数据库,它可保证金融交易和个人资料更新所需的 ACID 属性。
- AWS S3(主数据):存储
products目录。表示 AWS 上的旧版主数据管理 (MDM) 系统。 - Google Cloud Storage(海量数据湖):存储
events(点击流日志)。高吞吐量数据(例如 Web 日志)会导致关系型数据库崩溃。对象存储可提供无限的可伸缩性,将其存储在 Google Cloud 中可最大限度地提高分析引擎的计算本地性。
首先,配置底层网络。AlloyDB 等 Google Cloud 代管式数据库需要专用 VPC 对等互连连接,才能在项目网络内安全地通信。
# Allocate an IP range for Google Cloud managed services
gcloud compute addresses create google-managed-services-${NETWORK_NAME} \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Establish the VPC peering connection
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges=google-managed-services-${NETWORK_NAME} \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID}
接下来,创建 BigQuery 数据集和 Lakehouse Cloud 资源连接。从架构上讲,资源连接会将数据访问权限委托给专用的 Google 管理的服务账号,从而强制执行最小权限原则。
# Create the central data lakehouse dataset
bq mk --dataset --location=${REGION} ${PROJECT_ID}:${BQ_DATASET}
gcloud storage buckets create gs://${BUCKET_NAME} --location=${REGION}
# Create a Lakehouse resource connection
bq mk --connection --location=${REGION} \
--connection_type=CLOUD_RESOURCE ${BQ_RESOURCE_CONN}
# Retrieve the automatically provisioned service account
CONN_SA=$(bq show --connection --format=json ${PROJECT_ID}.${REGION}.${BQ_RESOURCE_CONN} | jq -r '.cloudResource.serviceAccountId')
# Grant the service account permissions to read/write to the data lake
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${CONN_SA}" \
--role="roles/storage.admin" \
--quiet
4. 预配运营数据库
预配 AlloyDB 主实例并注入关键任务事务数据。
# Create the AlloyDB cluster
gcloud alloydb clusters create ${ALLOYDB_CLUSTER} \
--region=${REGION} \
--password=${ALLOYDB_PASSWORD} \
--network=projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}
# Create the primary instance
gcloud alloydb instances create ${ALLOYDB_INSTANCE} \
--cluster=${ALLOYDB_CLUSTER} \
--region=${REGION} \
--instance-type=PRIMARY \
--cpu-count=2 \
--assign-inbound-public-ip=ASSIGN_IPV4 \
--database-flags=password.enforce_complexity=on
数据库准备就绪后,您必须创建 BigQuery 外部连接才能连接到 AlloyDB。此连接可安全地存储数据库凭据和端点,从而使 BigQuery 能够将 SQL 执行直接下推到 AlloyDB 计算引擎 (zero-ETL)。
# Create the BigQuery to AlloyDB connection
bq mk --connection --location=${REGION} --project_id=${PROJECT_ID} \
--connector_configuration "{
\"connector_id\": \"google-alloydb\",
\"asset\": {
\"database\": \"${ALLOYDB_DB_NAME}\",
\"google_cloud_resource\": \"//alloydb.googleapis.com/projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE}\"
},
\"authentication\": {
\"username_password\": {
\"username\": \"postgres\",
\"password\": { \"plaintext\": \"${ALLOYDB_PASSWORD}\" }
}
}
}" ${BQ_ALLOYDB_CONN}
# Grant the BigQuery connection service agent permission to access AlloyDB
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
BQ_SERVICE_AGENT="service-${PROJECT_NUMBER}@gcp-sa-bigqueryconnection.iam.gserviceaccount.com"
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${BQ_SERVICE_AGENT}" \
--role="roles/alloydb.client" \
--quiet
安全地将事务表推送到 AlloyDB。使用 AlloyDB Auth Proxy 将本地 Cloud Shell 会话安全地连接到私有 AlloyDB 实例。这样一来,您就可以使用本地命令行工具推送事务性数据。
# Extract full raw data to Cloud Storage using the BigQuery extract API
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.users" gs://${BUCKET_NAME}/tmp/users.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.orders" gs://${BUCKET_NAME}/tmp/orders.csv
bq extract --destination_format=CSV --print_header=true "bigquery-public-data:thelook_ecommerce.order_items" gs://${BUCKET_NAME}/tmp/order_items.csv
# Download the CSVs to the local Cloud Shell session
gcloud storage cp gs://${BUCKET_NAME}/tmp/users.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/orders.csv .
gcloud storage cp gs://${BUCKET_NAME}/tmp/order_items.csv .
# Download and start the AlloyDB auth proxy
curl -sL "https://storage.googleapis.com/alloydb-auth-proxy/v1.13.11/alloydb-auth-proxy.linux.amd64" -o alloydb-auth-proxy && chmod +x alloydb-auth-proxy
./alloydb-auth-proxy projects/${PROJECT_ID}/locations/${REGION}/clusters/${ALLOYDB_CLUSTER}/instances/${ALLOYDB_INSTANCE} --public-ip &
PROXY_PID=$!
sleep 15 # Wait for the proxy to fully initialize
# Create the database
export PGPASSWORD=${ALLOYDB_PASSWORD}
psql -h 127.0.0.1 -p 5432 -U postgres -c "CREATE DATABASE ${ALLOYDB_DB_NAME};" || true
# Load into AlloyDB mimicking the exact schema via heredoc
psql -h 127.0.0.1 -p 5432 -U postgres -d ${ALLOYDB_DB_NAME} << 'EOF'
CREATE TABLE IF NOT EXISTS users (id INT PRIMARY KEY, first_name VARCHAR(255), last_name VARCHAR(255), email VARCHAR(255), age INT, gender VARCHAR(50), state VARCHAR(100), street_address VARCHAR(255), postal_code VARCHAR(50), city VARCHAR(100), country VARCHAR(100), latitude FLOAT, longitude FLOAT, traffic_source VARCHAR(100), created_at TIMESTAMP, user_geom TEXT);
CREATE TABLE IF NOT EXISTS orders (order_id INT PRIMARY KEY, user_id INT, status VARCHAR(50), gender VARCHAR(50), created_at TIMESTAMP, returned_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, num_of_item INT);
CREATE TABLE IF NOT EXISTS order_items (id INT PRIMARY KEY, order_id INT, user_id INT, product_id INT, inventory_item_id INT, status VARCHAR(50), created_at TIMESTAMP, shipped_at TIMESTAMP, delivered_at TIMESTAMP, returned_at TIMESTAMP, sale_price FLOAT);
\copy users FROM 'users.csv' WITH (FORMAT csv, HEADER true)
\copy orders FROM 'orders.csv' WITH (FORMAT csv, HEADER true)
\copy order_items FROM 'order_items.csv' WITH (FORMAT csv, HEADER true)
EOF
# Clean up local temporary files and Cloud Storage artifacts
kill $PROXY_PID && rm -f users.csv orders.csv order_items.csv alloydb-auth-proxy
gcloud storage rm gs://${BUCKET_NAME}/tmp/*.csv
5. 联合主数据(AWS Spoke)
我们的商品清单包含原始商品元数据,以 Apache Iceberg 表的形式原生存储在 AWS S3 上。元数据由远程目录管理。
您将使用 Lakehouse for Apache Iceberg(REST 目录联合),而不是构建脆弱的 ETL 流水线来将这些数据复制到 Google Cloud 中。
借助这种零 ETL 方法,Lakehouse 和 Managed Service for Apache Spark 可以直接从远程环境中动态发现和读取 Iceberg 元数据和底层 Parquet 文件。
如果您有有效的 AWS 账号并已配置 Databricks Unity Catalog,则可以使用该账号。否则,您可以使用 Google Cloud Storage 模拟环境。从中选择其一即可。
选项 A:自带 AWS(原生 Apache Iceberg)
前提条件:此选项假定您已预配 AWS S3 存储分区,已将其作为外部位置连接到 Databricks Unity Catalog,已映射 Iceberg 表,并且已生成具有读取权限的 OAuth 服务正文。
1. 安全凭证存储空间
对长期有效的访问令牌进行硬编码是一种架构反模式。您将 Databricks OAuth 客户端 ID 和密钥存储在 Google Cloud Secret Manager 中。Lakehouse 服务会在运行时动态提取这些凭据,以提供短期有效的令牌,从而集中管理您的凭据。
运行以下代码块以生成脚本。(暂时不要修改任何内容)。
cat << 'EOF' > create_secret.sh
#!/bin/bash
source ./env.sh
# Define your Databricks OAuth credentials
DATABRICKS_CLIENT_ID="<YOUR_DATABRICKS_CLIENT_ID>"
DATABRICKS_CLIENT_SECRET="<YOUR_DATABRICKS_CLIENT_SECRET>"
DATABRICKS_WORKSPACE="<YOUR_WORKSPACE>.cloud.databricks.com" # Exclude https://
DATABRICKS_CATALOG="google_lakehouse_catalog"
# Define the secure credentials payload
export CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/"
SECRET_PAYLOAD="{ \"client_id\": \"${DATABRICKS_CLIENT_ID}\", \"client_secret\": \"${DATABRICKS_CLIENT_SECRET}\" }"
# Pipe the JSON payload into Google Cloud Secret Manager
echo "$SECRET_PAYLOAD" | gcloud secrets create ${SECRET_NAME} \
--location=${REGION} \
--project=${PROJECT_ID} \
--data-file=-
EOF
然后,运行以下命令以在终端上方的可视化代码编辑器中自动打开生成的脚本。
cloudshell edit create_secret.sh
- 在编辑器中,将
<YOUR_...>占位符替换为您的实际 Databricks 凭据。 - 请确保您的工作区网址不包含
https://或尾随斜杠(例如123456789.cloud.databricks.com)。 - 按
Ctrl+S(在 Mac 上,按Cmd+S)保存文件。 - 返回到终端会话并执行脚本:
source create_secret.sh
2. 创建联合目录
为简单起见,在此 Codelab 中,您将配置目录以安全地遍历公共互联网。不过,对于生产工作负载,通过公共互联网查询海量数据集会产生不必要的出站流量费用和不可预测的延迟时间。最佳实践要求在 AWS 和 Google Cloud 之间配置专用 Cross-Cloud Interconnect (CCI),这可显著降低出站流量费用并确保确定性的网络性能。
使用 gcloud CLI 配置联邦 Lakehouse 目录:
# Execute the Lakehouse CLI to provision the federated catalog
gcloud alpha biglake iceberg catalogs create ${CATALOG_NAME} \
--project="${PROJECT_ID}" \
--primary-location="${REGION}" \
--catalog-type="federated" \
--federated-catalog-type="unity" \
--secret-name="projects/${PROJECT_ID}/locations/${REGION}/secrets/${SECRET_NAME}" \
--unity-instance-name="${DATABRICKS_WORKSPACE}" \
--unity-catalog-name="${DATABRICKS_CATALOG}" \
--refresh-interval="330s"
3. 应用最小权限 IAM 绑定
在上一步中预配联合目录时,Google Cloud Lakehouse 会自动启动后台刷新作业,以每 330 秒同步一次 Iceberg 清单。
您必须向 Lakehouse Catalog 服务账号授予 secretAccessor 角色,以便该服务账号能够在这些后台同步和查询执行期间安全地获取 Databricks OAuth 令牌。如果缺少此绑定,Lakehouse 在尝试更新目录时会遇到无提示的 403 错误。
# Extract the automatically provisioned Lakehouse catalog service account
LAKEHOUSE_SA=$(curl -s -X GET "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/${CATALOG_NAME}" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" | jq -r '."biglake-service-account"')
# Grant the secretAccessor role for background metadata synchronization and query execution
gcloud secrets add-iam-policy-binding ${SECRET_NAME} \
--project=${PROJECT_ID} --location=${REGION} \
--member="serviceAccount:${LAKEHOUSE_SA}" \
--role="roles/secretmanager.secretAccessor" --quiet
4. 为 Managed Service for Apache Spark 启用出站互联网
在后续步骤中,Managed Service for Apache Spark 将读取远程 AWS 数据。由于 Managed Service for Apache Spark 无服务器版完全在没有外部 IP 地址的专用 VPC 网络中运行,因此默认情况下无法通过互联网访问 AWS S3。您必须预配 Cloud NAT,以允许 Spark worker 出站互联网访问。
# Create a Cloud Router
gcloud compute routers create lakehouse-router \
--network=${NETWORK_NAME} \
--region=${REGION}
# Create a Cloud NAT attached to the router
gcloud compute routers nats create lakehouse-nat \
--router=lakehouse-router \
--auto-allocate-nat-external-ips \
--nat-all-subnet-ip-ranges \
--region=${REGION}
5. 定义下游目标
导出此变量,以便下游 Apache Spark 作业确切知道在何处查询 AWS 数据,而无需手动更改代码。
# Assuming your schema is 'retail' and table is 'aws_products'
export AWS_PRODUCTS_TABLE="${CATALOG_NAME}.retail.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
方案 B:通过 Cloud Storage 模拟 AWS 环境
如果您没有有效的 AWS 账号,可以使用 Google Cloud Storage 上的 Lakehouse 受管理表原生模拟跨云数据孤岛。
1. 创建模拟 Iceberg 表
# Copy raw products data to a temporary BigQuery table
bq cp --force bigquery-public-data:thelook_ecommerce.products ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
# Create an open Iceberg table using the Lakehouse cloud resource connection
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.aws_products\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/aws_products')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_products_raw\`;"
# Cleanup temporary table
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_products_raw
2. 定义下游目标
标准 BigQuery 数据集使用 3 部分命名空间结构 (project.dataset.table)。导出此变量,以便下游 Apache Spark 作业以模拟数据为目标。
export AWS_PRODUCTS_TABLE="${PROJECT_ID}.${BQ_DATASET}.aws_products"
# Persist the variable for future shell sessions
echo "export AWS_PRODUCTS_TABLE=\"${AWS_PRODUCTS_TABLE}\"" >> env.sh
6. 注入事件日志(Google Cloud Spoke)
点击流数据呈指数级增长。您将完整、未汇总的原始事件以受管理的 Lakehouse 表的形式存储在 Cloud Storage 中。
bq cp --force bigquery-public-data:thelook_ecommerce.events ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
bq query --use_legacy_sql=false "
CREATE OR REPLACE TABLE \`${PROJECT_ID}.${BQ_DATASET}.google_events\`
WITH CONNECTION \`${REGION}.${BQ_RESOURCE_CONN}\`
OPTIONS (file_format = 'PARQUET', table_format = 'ICEBERG', storage_uri = 'gs://${BUCKET_NAME}/google_events')
AS SELECT * FROM \`${PROJECT_ID}.${BQ_DATASET}.temp_events_raw\`;"
bq rm -f -t ${PROJECT_ID}:${BQ_DATASET}.temp_events_raw
7. 构建统一的客户资料
在原始基础架构完全填充后,就可以开始构建统一的客户资料了。
您将使用由 Lightning Engine 提供支持的 Managed Service for Apache Spark。Lightning Engine 是 Google Cloud 的高性能 C++ 原生查询加速器,基于 Apache Gluten 和 Velox 等开源技术构建,可通过最大限度地提高 CPU 效率和智能缓存数据来自动提升执行速度。如果需要在多个云中执行大规模多路联接、复杂的窗口化或行为聚合,此方法非常适合。
您将使用 Spark BigQuery 连接器直接读取联合 AlloyDB 零 ETL 查询和 Lakehouse 表,在 Spark 中以原生方式执行大规模矢量化聚合,并将生成的统一配置文件写回 BigQuery。
为 Managed Service for Apache Spark 配置 IAM 权限
默认情况下,无服务器 Spark 使用 Compute Engine 默认服务账号执行批处理作业。在提交作业之前,您必须向此服务账号授予执行工作负载和管理 BigQuery 作业所需的权限。
(注意:虽然服务名称已更改为 Managed Service for Apache Spark,以反映行业标准术语,但底层 API 命令和 IAM 角色仍使用 dataproc 标识符)。
# Retrieve the project number to construct the Compute Engine default service account
PROJECT_NUMBER=$(gcloud projects describe ${PROJECT_ID} --format="value(projectNumber)")
export COMPUTE_SA="${PROJECT_NUMBER}-compute@developer.gserviceaccount.com"
# Grant the Managed Service for Apache Spark Worker role to allow job execution
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/dataproc.worker" \
--quiet
# Grant the BigQuery Admin role to allow reading, writing, and querying external connections
gcloud projects add-iam-policy-binding ${PROJECT_ID} \
--member="serviceAccount:${COMPUTE_SA}" \
--role="roles/bigquery.admin" \
--quiet
创建并提交作业
首先,创建 PySpark 作业脚本。此脚本会根据您的 AWS_PRODUCTS_TABLE 环境变量自动检测您选择的是选项 A (AWS 联合目录) 还是选项 B (Google Cloud 模拟),定义 Spark SQL 逻辑,并利用 Spark 的原生数组操作来计算 RFM(新近度、频次、货币)窗口。
在 Cloud Shell 中运行以下代码块。
# Determine which option was selected based on the AWS_PRODUCTS_TABLE variable
if [[ "${AWS_PRODUCTS_TABLE}" == *"${CATALOG_NAME:-undefined}"* ]]; then
echo "=> Option A (AWS Federated Catalog) detected."
export IS_AWS_CATALOG="True"
export OAUTH_TOKEN=$(gcloud auth print-access-token)
else
echo "=> Option B (Google Cloud Mock) detected."
export IS_AWS_CATALOG="False"
export OAUTH_TOKEN=""
fi
# Create the PySpark script with safely injected variables
cat << EOF > spark_lakehouse_join.py
from pyspark.sql import SparkSession
# --- Environment Variables dynamically injected ---
PROJECT_ID = "${PROJECT_ID}"
CATALOG_NAME = "${CATALOG_NAME}"
OAUTH_TOKEN = "${OAUTH_TOKEN}"
BUCKET_NAME = "${BUCKET_NAME}"
BQ_DATASET = "${BQ_DATASET}"
REGION = "${REGION}"
BQ_ALLOYDB_CONN = "${BQ_ALLOYDB_CONN}"
AWS_PRODUCTS_TABLE = "${AWS_PRODUCTS_TABLE}"
IS_AWS_CATALOG = ${IS_AWS_CATALOG}
# ---------------------------------------------------
# 1. Initialize SparkSession (Dynamic Configuration)
packages =[
"org.apache.iceberg:iceberg-spark-runtime-3.5_2.12:1.4.3",
"org.apache.iceberg:iceberg-aws-bundle:1.4.3",
"org.apache.hadoop:hadoop-aws:3.3.4",
"com.amazonaws:aws-java-sdk-bundle:1.12.262",
"com.google.cloud.spark:spark-bigquery-with-dependencies_2.12:0.36.1"
]
builder = SparkSession.builder \\
.config("spark.sql.extensions", "org.apache.iceberg.spark.extensions.IcebergSparkSessionExtensions") \\
.config("spark.dataproc.lightningEngine.runtime", "native") \\
.config("spark.hadoop.fs.gs.velox.client.table-cache-max-size", "0") \\
.config("spark.jars.packages", ",".join(packages))
# Conditionally configure Lakehouse REST Catalog for Option A
if IS_AWS_CATALOG:
builder = builder \\
.config(f"spark.sql.catalog.{CATALOG_NAME}", "org.apache.iceberg.spark.SparkCatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.type", "rest") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.uri", "https://biglake.googleapis.com/iceberg/v1/restcatalog") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.warehouse", f"bl://projects/{PROJECT_ID}/catalogs/{CATALOG_NAME}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.io-impl", "org.apache.iceberg.aws.s3.S3FileIO") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.X-Iceberg-Access-Delegation", "vended-credentials") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.x-goog-user-project", PROJECT_ID) \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.header.Authorization", f"Bearer {OAUTH_TOKEN}") \\
.config(f"spark.sql.catalog.{CATALOG_NAME}.rest-metrics-reporting-enabled", "false")
spark = builder.getOrCreate()
spark.conf.set("temporaryGcsBucket", BUCKET_NAME)
spark.conf.set("viewsEnabled", "true")
spark.conf.set("materializationDataset", BQ_DATASET)
# 2. Extract operational data via AlloyDB Zero-ETL
users_df = spark.read.format("bigquery").option("query", f"""SELECT id AS user_id, age, country FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT id, age, country FROM users")""").load()
orders_df = spark.read.format("bigquery").option("query", f"""SELECT user_id, order_id, CAST(created_at AS TIMESTAMP) AS order_date FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT user_id, order_id, created_at FROM orders WHERE status = 'Complete'")""").load()
items_df = spark.read.format("bigquery").option("query", f"""SELECT order_id, product_id, sale_price FROM EXTERNAL_QUERY("{REGION}.{BQ_ALLOYDB_CONN}", "SELECT order_id, product_id, sale_price FROM order_items")""").load()
# 3. Read AWS Products (Option A vs B) & Google Cloud Logs
if IS_AWS_CATALOG:
products_df = spark.table(AWS_PRODUCTS_TABLE)
else:
products_df = spark.read.format("bigquery").option("table", AWS_PRODUCTS_TABLE).load()
events_df = spark.read.format("bigquery").option("table", f"{PROJECT_ID}.{BQ_DATASET}.google_events").load()
# Register Temp Views
users_df.createOrReplaceTempView("live_user_profiles")
orders_df.createOrReplaceTempView("live_transactions")
items_df.createOrReplaceTempView("live_order_items")
products_df.createOrReplaceTempView("raw_aws_products")
events_df.createOrReplaceTempView("google_events")
# 4. Multi-cloud Distributed Join
unified_profile_df = spark.sql("""
WITH aws_master_catalog AS (
SELECT id AS product_id, category, brand
FROM raw_aws_products
),
google_behavioral_logs AS (
SELECT user_id,
COUNT(DISTINCT session_id) AS total_sessions,
COUNT(CASE WHEN event_type = 'cart' THEN 1 END) AS cart_adds
FROM google_events
WHERE user_id IS NOT NULL
GROUP BY user_id
),
user_purchases AS (
SELECT
t.user_id, t.order_date, t.order_id, oi.sale_price,
COALESCE(p.category, 'Unknown') AS category,
COALESCE(p.brand, 'Unknown') AS brand
FROM live_transactions t
JOIN live_order_items oi ON t.order_id = oi.order_id
LEFT JOIN aws_master_catalog p ON oi.product_id = p.product_id
),
rfm_base AS (
SELECT
user_id,
MAX(order_date) AS last_purchase_date,
COUNT(DISTINCT order_id) AS total_orders,
SUM(sale_price) AS lifetime_value
FROM user_purchases
GROUP BY user_id
),
ranked_items AS (
SELECT
user_id, category, brand, sale_price,
ROW_NUMBER() OVER(PARTITION BY user_id ORDER BY sale_price DESC) as rn
FROM user_purchases
),
top_items AS (
SELECT
user_id,
COLLECT_LIST(NAMED_STRUCT('category', category, 'brand', brand, 'sale_price', sale_price)) AS top_preferences
FROM ranked_items
WHERE rn <= 3
GROUP BY user_id
)
SELECT
CURRENT_TIMESTAMP() AS snapshot_date,
u.user_id, u.age, u.country,
r.last_purchase_date,
COALESCE(r.total_orders, 0) AS total_orders,
COALESCE(ROUND(r.lifetime_value, 2), 0.0) AS lifetime_value,
COALESCE(b.total_sessions, 0) AS total_sessions,
COALESCE(b.cart_adds, 0) AS cart_adds,
t.top_preferences
FROM live_user_profiles u
LEFT JOIN rfm_base r ON u.user_id = r.user_id
LEFT JOIN top_items t ON u.user_id = t.user_id
LEFT JOIN google_behavioral_logs b ON u.user_id = b.user_id
""")
unified_profile_df.show()
# 5. Write back to BigQuery native partitioned table
(unified_profile_df.write
.format("bigquery")
.option("table", f"{PROJECT_ID}.{BQ_DATASET}.unified_customer_profile")
.option("partitionField", "snapshot_date")
.option("partitionType", "DAY")
.option("writeMethod", "direct")
.mode("overwrite")
.save())
EOF
在完全组装脚本并动态注入所需配置后,将批量作业提交到 Managed Apache Spark Serverless。
gcloud dataproc batches submit pyspark spark_lakehouse_join.py \
--project=${PROJECT_ID} \
--region=${REGION} \
--version=2.3 \
--subnet=${NETWORK_NAME} \
--deps-bucket=${BUCKET_NAME} \
--properties="dataproc.tier=premium,spark.dataproc.lightningEngine.runtime=native"
在控制台中验证作业执行情况
提交批量作业后,您可以验证该作业是否正在使用加速的 C++ 执行引擎:
- 在 Google Cloud 控制台中,依次前往 Managed Service for Apache Spark > 无服务器 > 批处理。
- 点击当前正在运行的作业。
- 在作业详情窗格中,验证层级属性是否已设置为
Premium,以及引擎是否已设置为Lightning Engine。
8. 使用 BigQuery 数据智能体进行分析
现在,您已联合分散的跨云数据,并使用 Managed Service for Apache Spark 执行了繁重的行为汇总,下一步是数据分析。
首先,在 BigQuery 界面中检查新创建的统一个人资料表的架构,直观了解您向代理公开的数据结构:
- 在 Google Cloud 控制台中,前往 BigQuery。
- 在左侧的“探索器”窗格中,展开您的项目和
demo_lakehouse数据集。 - 点击
unified_customer_profile表。 - 在主工作区中选择“架构”标签页。
检查新表的架构。top_preferences 列是一个 REPEATED STRUCT(包含 category、brand 和 sale_price 的记录数组)。传统上,查询嵌套数组需要使用 UNNEST() 函数编写复杂的 SQL,这可能会成为业务分析师的障碍。通过将 BigQuery 数据代理锚定到此特定表格,代理可以自然而然地了解架构,并在后台处理复杂的 Google 标准 SQL 操作。
创建数据智能体
在本部分中,您将创建 BigQuery 数据代理并与之互动。您无需手动编写复杂的 SQL 来取消嵌套数组和计算指标,只需预配一个专门针对新创建的统一资料的 AI 智能体,即可使用自然语言探索数据。
- 在左侧导航窗格中,找到并点击代理。
- 点击 + 新代理以初始化新的 AI 助理。
- 配置代理:
- 代理名称:
Retail VIP Analysis Agent - 数据源:点击添加来源,然后搜索
unified_customer_profile表格。
- 点击添加,然后等待几秒钟,让代理初始化其工作区。
在代理建立后,明确定义系统指令是一项关键的数据治理实践。将系统指令用作语义层。通过嵌入企业范围内的业务定义、处理架构复杂性以及建立分析护栏,您可以向最终用户隐藏技术复杂性,并防止 LLM 从统计上不显著的数据中得出结论。
将以下内容粘贴到指令字段中:
You are an expert Data Analyst specializing in e-commerce customer retention.
Your primary data source is the `unified_customer_profile` table.
Strict Schema Rules:
- The `top_preferences` column is a REPEATED STRUCT (ARRAY).
- Whenever you analyze product categories, brands, or prices, you MUST explicitly use the UNNEST() function on `top_preferences` to access the underlying fields.
Semantic Layer & Business Definitions:
- "At-Risk VIP": Define this specific user cohort as anyone meeting ALL of the following criteria: `lifetime_value` > 100, `cart_adds` > 0, and `last_purchase_date` is more than 90 days ago.
Analytical Guardrails:
- Prioritize statistical significance. When generating business insights based on geographic or demographic groupings, explicitly ignore or deprioritize segments with negligible sample sizes (e.g., countries with very few users) to prevent skewed marketing strategies.
向代理发出提示
由于复杂的业务逻辑(“高风险 VIP”的确切定义)和架构处理要求受到系统指令的严格约束,因此数据分析师无需编写冗长且包含大量条件的提示。
在聊天界面中,输入以下提示:
Find the total count of At-Risk VIPs grouped by country. For each country, extract the single most frequent product category based on their top preferences. Order the results by the user count in descending order.
评估生成的分析洞见
提交提示后,请仔细检查原生生成的输出,评估 BigQuery Data Agent 如何强制执行您的系统指令,同时充当受监管的语义层和分析护栏。
首先,阅读数据上方生成的摘要文本。请注意,智能体如何自动将您关于“高风险 VIP”的简单请求转换为系统指令中定义的精确指标阈值(例如,引用 lifetime_value > 100, cart_adds > 0 和 90 天的非活跃期)。这可确认智能体已将您的业务逻辑内化,这意味着最终用户无需在日常提示中记住或硬编码复杂的逻辑。
接下来,展开 SQL 视图以检查生成的代码。智能体应已根据您的指令构建了在数学上合理的 Google 标准 SQL:
- 动态时间窗口:在
WHERE子句中查找时间戳计算(通常使用TIMESTAMP_SUB(CURRENT_TIMESTAMP(), INTERVAL 90 DAY))。 - 严格遵守架构:通过将
UNNEST()函数明确应用于top_preferences数组,确认智能体遵守了严格的架构规则。为了准确隔离每个国家/地区最频繁的单个类别,您通常会看到它在通用表表达式 (CTE) 中使用ROW_NUMBER() OVER()窗口函数等高级技术。
查看自动呈现的图表和数据表。这些数据将直观地显示您的核心用户留存市场(通常会突出显示中国或美国等高流量国家/地区),以及这些市场中普遍占主导地位的产品偏好(通常是“牛仔裤”)。请注意,原生界面如何构建输出,以便立即使用,而无需显式可视化代码。
仔细阅读代理生成的带项目符号的数据分析文本。由于您设置了分析防护栏,因此请特别留意与数据质量或统计显著性相关的分析洞见。您可能会看到代理在表格底部明确标记用户数量极少的国家/地区(例如,只有少数用户的地区)。该代理不会仅根据单个数据点盲目生成有针对性的营销活动,而是会正确建议,对于大规模策略而言,这些异常情况在统计上并不显著。这表明,将治理护栏直接嵌入到智能体中可有效防止 AI 驱动的业务误算。
9. 使用 Gemini 和 MCP 生成 AI 分析洞见
代理已成功确定主要目标人群:特定国家/地区的高风险 VIP。不过,分析师的工作止于数据洞见。为了重新吸引这些用户,营销团队必须开展广告系列。
您将使用 Model Context Protocol (MCP) 将外部 AI 助理直接连接到 BigQuery 中的这个特定人口统计列表,从而无需构建自定义 API 即可从数据分析过渡到 AI 驱动的操作。
配置 BigQuery MCP 服务器
运行以下代码块以生成 mcp.json 配置文件。此文件提供必要的连接参数,以便 Gemini CLI 可以安全地与 BigQuery 交互。
mkdir -p ~/.gemini
cat << EOF > ~/.gemini/settings.json
{
"mcpServers": {
"bigquery": {
"httpUrl": "https://bigquery.googleapis.com/mcp",
"authProviderType": "google_credentials",
"oauth": {
"scopes": [
"https://www.googleapis.com/auth/bigquery"
]
}
}
}
}
EOF
生成营销电子邮件
从终端启动 Gemini CLI 工具,明确传递 MCP 配置标志,以允许其读取 BigQuery 湖仓一体。
运行 Gemini CLI。
source env.sh
gemini
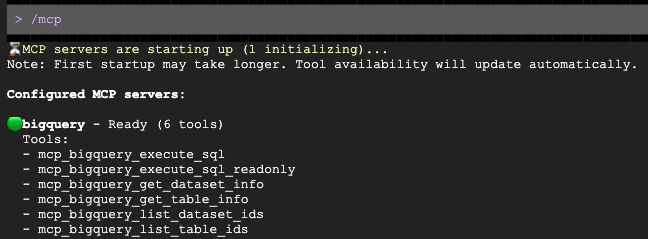
提示打开后,让 Gemini 为您的目标受众群体撰写个性化的推介内容:
Analyze the demo_lakehouse.unified_customer_profile table in BigQuery. Find exactly one 'country and age group' target demographic that has a high average order value (sale_price >= $80) but a relatively low total revenue compared to others. Then, draft a highly engaging, premium VIP promotional email tailored to this specific demographic. Use $PROJECT_ID to get the current project id.
Gemini 将通过 MCP 服务器自动查询 BigQuery,识别人口统计信息,并为您起草电子邮件!
10. 清理环境
为避免系统向您的 Google Cloud 账号持续收取费用,并为以后的运行干净利落地重置项目,您必须删除在此 Codelab 期间创建的资源。
运行以下代码块以创建 cleanup.sh 脚本。此脚本充当自动拆解机制,可永久移除 AlloyDB 集群和实例、BigQuery 数据集以及您的 Cloud Storage 存储分区,以防止产生进一步的账单。
cat << 'EOF' > cleanup.sh
#!/bin/bash
source ./env.sh
echo "=> Deleting BigQuery Dataset (${BQ_DATASET})..."
bq rm -r -f -d ${PROJECT_ID}:${BQ_DATASET} || true
echo "=> Deleting Lakehouse resource connection (${BQ_RESOURCE_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_RESOURCE_CONN} || true
echo "=> Deleting AlloyDB connection (${BQ_ALLOYDB_CONN})..."
bq rm --connection --project_id=${PROJECT_ID} --location=${REGION} ${BQ_ALLOYDB_CONN} || true
echo "=> Deleting AlloyDB Instance (${ALLOYDB_INSTANCE}) - This takes a few minutes..."
gcloud alloydb instances delete ${ALLOYDB_INSTANCE} --cluster=${ALLOYDB_CLUSTER} --region=${REGION} --quiet || true
echo "=> Deleting AlloyDB Cluster (${ALLOYDB_CLUSTER})..."
gcloud alloydb clusters delete ${ALLOYDB_CLUSTER} --region=${REGION} --force --quiet || true
echo "=> Deleting Cloud Storage bucket (${BUCKET_NAME})..."
gcloud storage rm -r gs://${BUCKET_NAME} || true
echo "=> Deleting Lakehouse Federated Catalog (if created in Option A)..."
curl -s -X DELETE "https://biglake.googleapis.com/iceberg/v1/restcatalog/extensions/projects/${PROJECT_ID}/catalogs/aws_dbx_catalog" \
-H "Authorization: Bearer $(gcloud auth application-default print-access-token)" || true
echo "=> Deleting Secret Manager Regional Secret (if created in Option A)..."
CLOUDSDK_API_ENDPOINT_OVERRIDES_SECRETMANAGER="https://secretmanager.${REGION}.rep.googleapis.com/" \
gcloud secrets delete dbx-oauth-secret --location=${REGION} --project=${PROJECT_ID} --quiet || true
echo "=> Deleting Cloud NAT and Router (if created in Option A)..."
gcloud compute routers nats delete lakehouse-nat --router=lakehouse-router --region=${REGION} --quiet || true
gcloud compute routers delete lakehouse-router --region=${REGION} --quiet || true
echo "=> Deleting Service Networking VPC Peering..."
gcloud compute networks peerings delete servicenetworking-googleapis-com \
--network=${NETWORK_NAME} \
--project=${PROJECT_ID} --quiet || true
echo "=> Deleting Allocated IP Range for Managed Services..."
gcloud compute addresses delete google-managed-services-${NETWORK_NAME} \
--global \
--project=${PROJECT_ID} --quiet || true
echo "=> Removing local temporary files..."
rm -f spark_lakehouse_join.py users.csv orders.csv order_items.csv alloydb-auth-proxy env.sh cleanup.sh ~/.gemini/settings.json
echo "============================================="
echo " TEARDOWN COMPLETED."
echo "============================================="
EOF
运行清理脚本以安全地删除资源:
bash cleanup.sh
11. 恭喜!
您已成功构建并查询了跨云开放数据湖仓一体架构。
您已完成以下内容的学习:
- 如何使用 BigQuery Zero-ETL 和 Google Cloud Lakehouse 将来自不同来源的数据进行联合。
- 如何在 Managed Service for Apache Spark 的大规模矢量化联接中利用 C++ 原生 Lightning Engine。
- 如何使用 BigQuery 数据代理进行自然语言探索。
- 如何使用 Model Context Protocol (MCP) 和 Gemini 将数据桥接到 Gemini。
接下来该怎么做?
- 浏览湖仓一体文档
- 详细了解 AlloyDB 零 ETL 到 BigQuery
- 了解 Lightning Engine