
1. Introducción
En el comercio minorista moderno, tus datos son un ecosistema diverso y en expansión. Tienes datos transaccionales sólidos (precios y stock), catálogos polimórficos "desordenados" (especificaciones de electrónica frente a tallas de indumentaria) y petabytes de registros de comportamiento. Forzar la integración de todos estos elementos en un solo monolito no solo genera deuda técnica, sino que también afecta la experiencia del usuario.
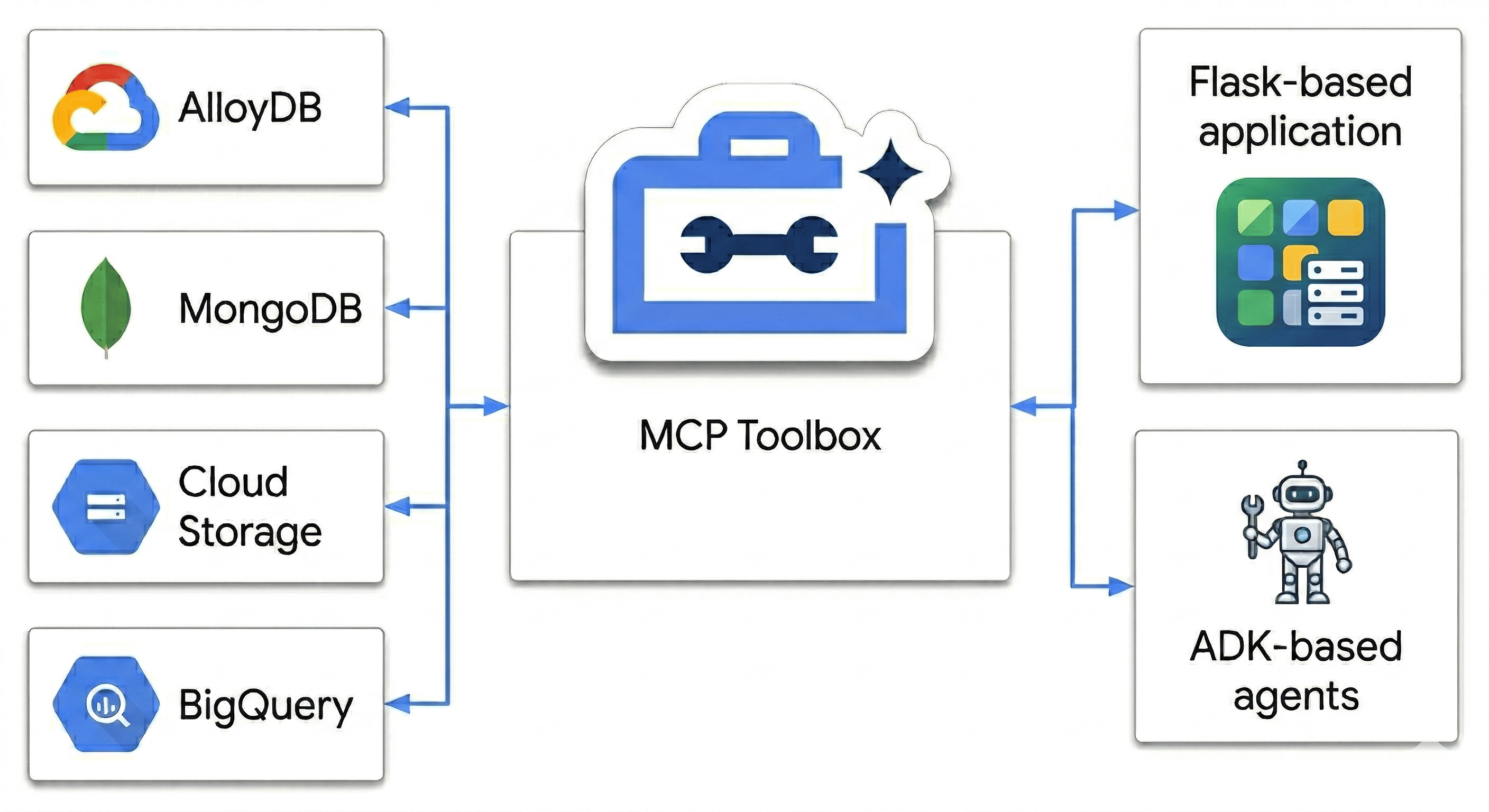
En este codelab, diseñarás un centro políglota que armonice lo siguiente:
- AlloyDB: Tu columna vertebral transaccional para la coherencia de alta velocidad y los embeddings de imágenes.
- MongoDB Atlas en Google Cloud: Tu capa de catálogo flexible y sin esquema.
- Cloud Storage: Tu cerebro analítico para la previsión de tendencias en tiempo real.
- BigQuery: Tu almacén digital de alta resolución.
¿Cuál es el “ingrediente secreto”? Usarás la MCP Toolbox para bases de datos para organizar y unificar de forma inteligente las fuentes de datos que se ejecutan en Cloud Run como un puente semántico y, luego, implementarás una app de chat multiagente con el Kit de desarrollo de agentes (ADK). No solo estás creando una barra de búsqueda, sino un cerebro inteligente de venta minorista que comprende el contexto, respeta las restricciones y une la brecha entre los datos sin procesar y la intención humana.
La consulta del usuario imposible
Los agentes de comercio electrónico estándar no logran realizar un razonamiento multidimensional (combinar restricciones negativas, similitud visual y el inventario en tiempo real). Por ejemplo, por lo general, quiero hablar con un sitio de venta minorista como este:
"Hola, estoy planeando un viaje para tomar fotografías a gran altitud. Muéstrame algunas mochilas resistentes a la intemperie con un estilo similar a la "AeroGlow Pro", pero sin componentes de cuero. Además, infórmame si están en stock y si otros fotógrafos se quejaron de la durabilidad de la correa en las opiniones".
Por qué esta búsqueda es "The Agent Killer":
- Similitud visual (AlloyDB + Búsqueda de vectores): "Similar en estilo a AeroGlow Pro" requiere la comparación de embeddings de imágenes.
- Restricción negativa (MongoDB): "Sin cuero" requiere filtrar a través de atributos flexibles y anidados que no suelen estar en un esquema SQL estándar.
- Inventario en tiempo real (AlloyDB): "En stock" requiere una verificación transaccional en vivo (no un índice de búsqueda desactualizado).
- Síntesis semántica (BigQuery + Multi-Agent): Analizar las opiniones sobre la "durabilidad de la correa" requiere que el agente resuma los comentarios no estructurados de BigQuery sobre la marcha.
La mayoría de los bots de venta minorista solo verían "mochila" y "cuero", y mostrarían 10 mochilas de cuero. ¿Cómo lo estamos deteniendo?
Porque no solo buscamos coincidencias para las palabras clave. Usamos MCP Toolbox para permitir que nuestros agentes "razonen" en todas estas fuentes la verdad transaccional en AlloyDB y los atributos flexibles en MongoDB de forma simultánea. Construyámoslo.
Actividades
- Aprovisiona un clúster de AlloyDB para los datos principales del producto
- Configura MongoDB Atlas en Google Cloud para almacenar detalles de productos semiestructurados
- Crea un bucket de Cloud Storage para publicar imágenes de productos
- Implementa MCP Toolbox para bases de datos en Cloud Run para un acceso uniforme a los datos
- Ejecuta procesos de ETL para enviar datos a BigQuery para el análisis.
- Conversar con un agente de IA en lenguaje natural
Requisitos previos
- Un navegador web, como Chrome
- Un proyecto de Google Cloud con la facturación habilitada.
- Una cuenta gratuita de MongoDB Atlas en Google Cloud
2. Antes de comenzar
Crea un proyecto de Google Cloud
- En la consola de Google Cloud, en la página del selector de proyectos, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
Inicie Cloud Shell
Cloud Shell es un entorno de línea de comandos que se ejecuta en Google Cloud y que viene precargado con las herramientas necesarias.
- Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.
- Una vez que te conectes a Cloud Shell, verifica tu autenticación:
gcloud auth list - Confirma que tu proyecto esté configurado:
gcloud config get project - Si tu proyecto no está configurado como se esperaba, configúralo:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Habilita las APIs obligatorias
Ejecuta este comando para habilitar todas las APIs requeridas:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. Configura Cloud Storage
Cloud Storage funciona como un almacén masivo para recursos multimedia no estructurados, como imágenes de productos.
- En la consola de Google Cloud, navega a Cloud Storage y haz clic en Crear bucket.
- Asígnale a tu bucket un nombre único a nivel global (p.ej.,
ecommerce-app-images). - Haz clic en Crear.
- Para permitir que la aplicación de demostración acceda a las imágenes sin autenticación, desmarca la opción Aplicar la prevención de acceso público a este bucket y haz clic en Confirmar.
- Ve a la pestaña Permisos.
- En Permisos, haz clic en Otorgar acceso.
- En Principales nuevas, ingresa
allUsers. - En Selecciona un rol, elige Cloud Storage > Usuario de objetos de almacenamiento.
- Haz clic en Guardar y, luego, en Permitir acceso público para confirmar que el recurso será público.
Sube imágenes de marcador de posición
El BRK2-149-multidb-ecommerce usa imágenes de marcador de posición para brindar la mejor experiencia visual.
- En Cloud Shell, clona el repositorio
next-26-sessions:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - Navega a la carpeta
UploadImages:cd next-26-sessions/BRK2-149-multidb-ecommerce/UploadImages - En la consola de Google Cloud, navega a Cloud Storage y haz clic en Buckets.
- Haz clic en el nombre del bucket que acabas de crear.
- Haz clic en Subir > Subir archivos, selecciona las imágenes de muestra descargadas y haz clic en Abrir.
4. Configura AlloyDB
AlloyDB sirve como la única fuente de información para los datos estructurados, transaccionales y críticos, como los IDs, los nombres, los SKU, los precios y el inventario de los productos. AlloyDB también potencia el agente de IA con capacidades de búsqueda de similitud para recomendaciones y consultas en lenguaje natural.
Aprovisiona un clúster de AlloyDB
- En la consola de Google Cloud, navega a AlloyDB para PostgreSQL.
- Haz clic en Crear clúster.
- En ID de clúster, ingresa
ecommerce-cluster. - Establece una contraseña segura para el usuario
postgres. Para fines de aprendizaje, puedes usaralloydb. - En Versión de la base de datos, mantén la configuración predeterminada.
- En Región, selecciona
us-central1(o la región que prefieras).
Configurar la instancia principal
- En ID de instancia (Instance ID), ingresa
ecommerce-cluster-primary. - En Disponibilidad zonal, selecciona Zona única.
- En Tipo de máquina, elige un tipo de máquina pequeño (p.ej., N2, 4 CPU virtuales, 32 GB de RAM).
- En Conectividad de IP privada, selecciona Acceso privado a servicios (PSA) y, luego, la red
default.Si aún no se configuró la red predeterminada, haz clic en Confirmar configuración de red para crear una. - En Conectividad de IP pública, selecciona la casilla de verificación Habilitar IP pública para que la caja de herramientas de MCP se conecte correctamente en este codelab.
- En Redes externas autorizadas, ingresa
0.0.0.0/0. Selecciona la casilla de verificación Reconozco los riesgos y haz clic en Guardar. - Haz clic en Crear clúster.
Nota: Asegúrate de anotar tu dirección IP pública (se parece a 34.124.240.26).
Inicializa la base de datos
- Haz clic en AlloyDB Studio en el menú de navegación de la izquierda.
- En el menú desplegable Base de datos, selecciona
postgres. - Selecciona Autenticación integrada para acceder a la base de datos.
- En Nombre de usuario, usa el usuario
postgres. - En Contraseña, ingresa la contraseña que configuraste anteriormente.
- Haz clic en Autenticar.
- En la vista del editor, abre una nueva pestaña de consulta sin título.
- Copia el siguiente DDL y haz clic en Ejecutar:
CREATE TABLE products_core_table ( product_id UUID PRIMARY KEY, name VARCHAR(255) NOT NULL, sku VARCHAR(50) UNIQUE NOT NULL, price NUMERIC(10, 2) NOT NULL, stock INT NOT NULL ); - En Cloud Shell, navega a la carpeta
BRK2-149-multidb-ecommerce:cd next-26-sessions/BRK2-149-multidb-ecommerce - Abre el archivo
alloydb_insert_queries.sqlen Cloud Shell y copia las consultas de inserción.cat alloydb_insert_queries.sql - En una nueva pestaña de consulta sin título, pega solo las instrucciones
INSERTy haz clic en Ejecutar. - En una nueva pestaña de consulta sin título, copia el siguiente DDL y haz clic en Ejecutar para crear un índice en la tabla
products_core_table:CREATE INDEX idx_products_core_sku ON products_core_table(sku);
Crea embeddings de imágenes para que el agente de IA recupere productos similares
La integración del agente de IA usa embeddings de imágenes para recuperar productos similares. Los embeddings se generan con el modelo multimodalembedding@001 y se almacenan en la base de datos de AlloyDB. Los embeddings son vectores de 1,408 dimensiones y se almacenan en la columna img_embeddings.
Antes de generar incorporaciones, debemos otorgar los roles necesarios a la cuenta de servicio de AlloyDB para acceder a Cloud Storage.
Otorga roles a la cuenta de servicio de AlloyDB para acceder a Cloud Storage
Otorga los roles de Usuario de objetos de almacenamiento y Visualizador de objetos de Storage a la cuenta de servicio de AlloyDB para permitirle leer objetos del bucket de Cloud Storage.
- Navega a IAM y administración.
- Haz clic en Otorgar acceso.
- En el campo Principales nuevas, ingresa la búsqueda de la cuenta de servicio de AlloyDB. La cuenta de servicio se verá de la siguiente manera:
service-991742412753@gcp-sa-alloydb.iam.gserviceaccount.com. - Haz clic en Selecciona un rol.
- Busca y selecciona el rol Usuario de objetos de almacenamiento.
- Haz clic en Agregar otro rol y selecciona el rol Visualizador de objetos de Storage.
- Haz clic en Agregar otro rol y selecciona el rol Usuario de Vertex AI.
- Haz clic en Guardar.
Habilita las extensiones
Para compilar esta app, usaremos las extensiones pgvector y google_ml_integration. La extensión pgvector te permite almacenar y buscar embeddings de vectores. La extensión google_ml_integration proporciona funciones que usas para acceder a los extremos de predicción de Vertex AI y obtener predicciones en SQL. Para habilitar estas extensiones, ejecuta los siguientes DDL:
- En la consola de Google Cloud, navega a AlloyDB para PostgreSQL.
- Haz clic en AlloyDB Studio en el menú de navegación de la izquierda.
- En la vista del editor, abre una nueva pestaña de consulta sin título.
- Copia el siguiente DDL y haz clic en Ejecutar:
CREATE EXTENSION IF NOT EXISTS vector; CREATE EXTENSION IF NOT EXISTS google_ml_integration;
Inicializa la base de datos con embeddings
- Agrega la columna img_embeddings a
products_core_table.ALTER TABLE products_core_table ADD COLUMN img_embeddings vector(1408); - Genera embeddings para las imágenes y almacénalos en la columna
img_embeddings.UPDATE products_core_table SET img_embeddings = google_ml.image_embedding( model_id => 'multimodalembedding@001', image => 'gs://<STORAGE_BUCKET_NAME>/' || sku || '.jpg', mimetype => 'image/jpeg') WHERE sku IN ( SELECT sku FROM products_core_table WHERE img_embeddings IS NULL AND sku IS NOT NULL LIMIT 10 ); - Repite la consulta anterior al menos 5 veces para generar incorporaciones de imágenes para todo el conjunto, ya que Studio tiene una limitación de 5 minutos. Si esta consulta agota el tiempo de espera, cambia
LIMITpor5y vuelve a ejecutar la consulta diez veces. Este paso puede tardar unos minutos en completarse.
5. Configura MongoDB Atlas en Google Cloud
MongoDB almacena detalles de productos enriquecidos y semiestructurados, y datos flexibles del comportamiento del usuario (como clics y vistas).\
Crea un clúster de MongoDB
- Ve a MongoDB Atlas en Google Cloud y selecciona una cuenta de nivel gratuito.
- Selecciona el nivel de clúster Gratis y, luego, ingresa un nombre para el clúster, por ejemplo,
ecommerce-cluster. - Selecciona Google Cloud como proveedor y asegúrate de que la región coincida con tu región de Google Cloud (p.ej.,
us-central1). - Haz clic en Create Deployment.
- Haz clic en Cerrar.
Configura el acceso a la red
- En la consola de Atlas, ve a Database & Network Access.
- Haz clic en Lista de acceso por IP.
- Haz clic en Agregar dirección IP.
- Agrega
0.0.0.0/0, que permite el acceso desde cualquier lugar. - Haz clic en Confirmar.
Crea un usuario de base de datos
- En la consola de Atlas, ve a Database & Network Access.
- Haz clic en Usuarios de la base de datos.
- Haz clic en Agregar usuario nuevo de la base de datos.
- Selecciona Contraseña como método de autenticación.
- Ingresa el nombre de usuario como
store-usery la contraseña comostoreuser. - Haz clic en Agregar rol integrado y selecciona Leer y escribir en cualquier base de datos.
- Haz clic en Agregar usuario.
Obtén la cadena de conexión
- Ve a Base de datos > Clústeres > Conectar.
- En Connect your application, haz clic en Drivers.
- Copia la cadena de conexión que se muestra en Agrega tu cadena de conexión al código de la aplicación. La cadena se ve de la siguiente manera:
mongodb+srv://store-user:<db_password>@ecommerce-cluster.g8vaekh.mongodb.net/?appName=ecommerce-clusterdb_passwordpor tu contraseña de MongoDB. En este codelab, esstoreuser.
Guarda esta cadena de conexión. La usarás más adelante para la variable de entorno MONGODB_CONNECTION_STRING.
Crea una base de datos y una colección
- En la consola de Atlas, ve a Database > Clusters > Browse Collections.
- Haz clic en Crear base de datos y, luego, ingresa los detalles:
- Nombre de la base de datos:
ecommerce_db - Nombre de la colección:
product_details_collection
- Nombre de la base de datos:
- Haz clic en Crear base de datos.
- En el Explorador de datos, selecciona el nombre de la colección.
- Haz clic en el ícono Agregar datos (+) y, luego, en Insertar documento.
- Copia el contenido JSON de product_details_export.json y pégalo en el diálogo del editor Insert Document.
- Haz clic en Insertar para insertar el array de documentos y verificar que se agregaron 192 documentos.
- En el Explorador de datos, haz clic en Crear colección (+) junto a la base de datos
ecommerce_db. - Ingresa
user_interactions_collectioncomo nombre de la colección y haz clic en Crear colección. - En el Explorador de datos, selecciona la colección
user_interactions_collection. - Haz clic en el ícono Agregar datos (+) y, luego, en Insertar documento.
- Copia el contenido JSON de user_interactions_export.json y pégalo en el diálogo del editor Insert Document.
- Haz clic en Insertar documento.
6. Configura BigQuery
BigQuery agrega y analiza el comportamiento histórico de los usuarios para generar informes y recomendaciones inteligentes.
Crea el conjunto de datos
- En la consola de Google Cloud, navega a BigQuery.
- Junto al ID de tu proyecto en el panel Explorador, haz clic en el menú de tres puntos y selecciona Crear conjunto de datos.
- Ingresa
ecommerce_analyticspara el ID del conjunto de datos. - Haz clic en Crear conjunto de datos.
Crea la tabla de Analytics
- Abre una consulta nueva en el espacio de trabajo de BigQuery.
- Ejecuta la siguiente sentencia de SQL para crear la tabla de resumen que vincula a los usuarios con las interacciones de productos:
CREATE TABLE ecommerce_analytics.user_product_interactions (
user_id STRING DEFAULT 'any user',
product_id STRING,
interaction_score INT
);
Otorga roles a la cuenta de servicio de Compute para MCP Toolbox
Otorga roles a la cuenta de servicio de Compute que se usa para nuestra Caja de herramientas. Esto se hace para permitir que la caja de herramientas de MCP acceda a BigQuery, Secret Manager y otros servicios en la nube.
Para otorgar roles, completa los siguientes pasos:
- Navega a IAM y administración.
- Haz clic en Otorgar acceso.
- En el campo Principales nuevas, ingresa la cuenta de servicio predeterminada de Compute llamada
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.com. ReemplazaYOUR_PROJECT_NUMBERpor tu número de proyecto de Google Cloud. - Haz clic en Selecciona un rol.
- Busca y selecciona el rol Editor de datos de BigQuery.
- Haz clic en Agregar otro rol y selecciona el rol Usuario de trabajo de BigQuery.
- Haz clic en Agregar otro rol y selecciona el rol Descriptor de acceso a secretos de Secret Manager.
- Haz clic en Agregar otro rol y selecciona el rol de Editor.
- Haz clic en Guardar.
7. Comprende la aplicación de extremo a extremo
Para aprender cómo funciona cada componente en conjunto, crearemos una aplicación de comercio electrónico simple que use varias bases de datos y servicios. La aplicación se compila con un backend de Python (Flask) y se integra con varias bases de datos y servicios de Google Cloud.
Comprende la estructura de directorios
En la siguiente sección, clonarás el repositorio BRK2-149-multidb-ecommerce y lo usarás para ejecutar la aplicación de forma local. Una vez que probemos la aplicación de forma local, implementaremos MCP Toolbox y la aplicación en Cloud Run.
Explora los archivos descargados en este directorio. Están presentes los siguientes directorios de alto nivel:
UploadImages: Almacena recursos de imagen y se usa principalmente para la documentación o el contenido visual del catálogo de productos de comercio electrónico.static: Almacena los recursos web estáticos de la aplicación, como los archivos CSS y JavaScript, que se usan para diseñar y agregar interactividad a la interfaz de usuario ( fuente).templates: Almacena las plantillas HTML (probablemente Jinja2 para Flask) que usa la aplicación de Python para renderizar de forma dinámica las páginas web del catálogo de comercio electrónico ( fuente).toolbox-implementation: Almacena detalles de configuración y de implementación de la caja de herramientas del Protocolo de contexto del modelo (MCP), lo que facilita las interacciones con bases de datos multidb a través de herramientas predefinidas.
Los archivos de este repositorio funcionan en conjunto para compilar, configurar e implementar una aplicación de comercio electrónico con varias bases de datos. Los archivos centrales, como app.py, organizan el backend integrando diversas fuentes de datos definidas en archivos SQL y JSON, mientras que los archivos de configuración garantizan una implementación sin problemas en entornos de nube:
app.py: Coordina el backend de Flask y las integraciones de varias bases de datos.agentengine.py: Lógica principal para inicializar y configurar agentes de Vertex AI..env: Almacena secretos para las conexiones de bases de datos y almacenamiento.tools.yaml: Configura MCP Toolbox para operaciones de bases de datos multidb.Dockerfile: Define la imagen de contenedor y la configuración del entorno.requirements.txt: Enumera las bibliotecas de Python necesarias para el tiempo de ejecución de la aplicación.tools.yaml: Son configuraciones para MCP Toolbox.Procfile: Especifica los comandos de ejecución de producción para la implementación.alloydb_insert_queries.sql: Contiene consultas en SQL para datos relacionales.product_details_export.jsonyuser_interactions_export.json: Proporcionan datos JSON de muestra para la base de datos NoSQL.README.md: Guía la configuración, la implementación y la comprensión del proyecto.
Flujo de extremo a extremo de la aplicación
- Configuración de AlloyDB: Aprovisiona un clúster de alto rendimiento y usa las secuencias de comandos de SQL proporcionadas para crear la tabla products_core_table con columnas de vectores para los embeddings de imágenes.
- Configuración de MongoDB Atlas: Implementa un clúster en Google Cloud para almacenar atributos de productos fluidos en product_details y registrar flujos de clics en tiempo real en user_interactions.
- BigQuery Analytics: Crea un conjunto de datos para agregar registros de interacción, lo que permite realizar consultas analíticas complejas que identifican los "5 principales" elementos de tendencia en millones de eventos.
- Repositorio de Cloud Storage: Crea un bucket público para alojar imágenes de productos de alta resolución y asegúrate de que se pueda acceder a cada recurso a través de una URL pública o firmada para el frontend.
- Implementación de MCP Toolbox: Implementa Toolbox en Cloud Run y establécela como el puente central de RESTful que traduce la intención en lenguaje natural en consultas de varias bases de datos.
- Configuración de Tools.yaml: Define tus "Herramientas", como get_product_core_data o get_top_5_views, que asignan operaciones específicas de SQL y NoSQL a nombres simples y legibles para el agente.
- Lógica de backend de Flask: Implementa rutas de app.py que interactúan con MCP Toolbox, controlan la coordinación de la recuperación de datos y actúan como la API de la IU.
- Organización de múltiples agentes: Configura los agentes del ADK dentro del código para razonar sobre la intención del usuario y seleccionar la "Herramienta" adecuada para resolver consultas complejas de venta minorista de múltiples fuentes.
- Integración de frontend: Crea una interfaz index.html que incluya el catálogo de productos con la función de grabación de interacciones, la pestaña Analytics para comprender las estadísticas de rendimiento de los productos y una “pestaña del agente” dedicada que use el chat multiagente del ADK para brindar una experiencia de compra conversacional fluida.
Ahora, implementemos la organización y las implementaciones.
8. Configura MCP Toolbox y realiza la implementación en Cloud Run
MCP Toolbox abstrae nuestras múltiples fuentes de datos, lo que permite que nuestra aplicación recupere y escriba datos de manera uniforme.
Instala MCP Toolbox de forma local
- En Cloud Shell, navega a la carpeta
toolbox-implementation:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - Descarga el objeto binario de MCP Toolbox y haz que sea ejecutable:
export VERSION=0.29.0 curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox chmod +x toolbox
Configura tools.yaml
Debes definir las abstracciones para AlloyDB, MongoDB y BigQuery. El archivo tools.yaml le indica a la caja de herramientas de MCP cómo interactuar entre sí.
- Crea y edita el archivo
tools.yamlcon el editor integrado:cloudshell edit tools.yamltools.yamlcompleto se puede encontrar en el repositorio de GitHub. Copia su contenido en el nuevo archivotools.yaml. - Actualiza el host, el usuario, las contraseñas, los IDs del proyecto y las cadenas de conexión para que coincidan con la infraestructura que aprovisionaste en los pasos anteriores:
Base de datos
Campo
Valor de ejemplo
AlloyDB/BigQuery
project_idYOUR_PROJECT_IDAlloyDB
regionus-central1AlloyDB
clusterecommerce-clusterAlloyDB
instanceecommerce-cluster-primaryAlloyDB
databasepostgresAlloyDB
passwordalloydbMongoDB
connection_stringmongodb+srv://store-user:storeuser@ecommerce-cluster.urcxr6q.mongodb.net
Otorga roles a la cuenta de servicio de Compute para MCP Toolbox
Otorga roles a la cuenta de servicio de Compute que se usa para nuestra Caja de herramientas. Esto se hace para permitir que MCP Toolbox acceda a AlloyDB.
- Navega a IAM y administración.
- Haz clic en Otorgar acceso.
- En el campo Principales nuevas, ingresa la cuenta de servicio predeterminada de Compute llamada
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.com. ReemplazaYOUR_PROJECT_NUMBERpor tu número de proyecto de Google Cloud. - Haz clic en Selecciona un rol.
- Busca y selecciona el rol Editor de datos de BigQuery.
- Haz clic en Agregar otro rol y selecciona el rol Cliente de AlloyDB.
- Haz clic en Agregar otro rol y selecciona el rol Consumidor de Service Usage.
- Haz clic en Agregar otro rol y selecciona el rol Visualizador de objetos de Storage.
- Haz clic en Guardar.
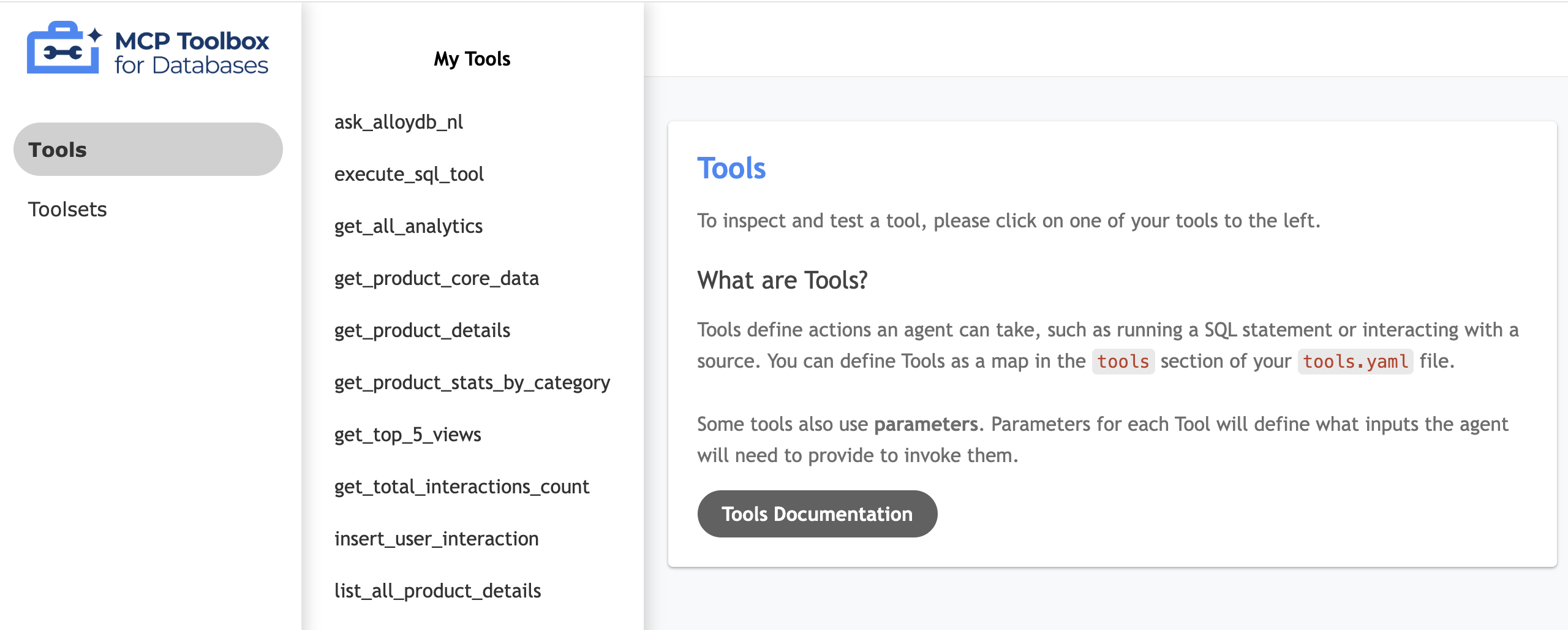
Prueba la IU de tu herramienta
- En la terminal de Cloud Shell, ejecuta la caja de herramientas de forma local para entregar la IU:
./toolbox --ui - Abre la vista previa en la Web en Cloud Shell en el puerto 5000 y navega a la página de herramientas. Por ejemplo, según la URL de tu sesión, puedes verla en
https://5000-cs-71152278760-default.cs-asia-southeast1-cash.cloudshell.dev/ui.
Se muestra la siguiente IU de MCP Toolbox:
Implementa en Cloud Run
Implementa MCP Toolbox en Cloud Run para que esté disponible como un servicio seguro y administrado que nuestra aplicación pueda usar para consultar las bases de datos. Almacenaremos la configuración en Secret Manager para proteger los detalles de conexión sensibles.
- Abre una nueva sesión de Cloud Shell.
- Navega a la carpeta
toolbox-implementation:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - Sube la configuración de
tools.yamla Google Secret Manager:gcloud secrets create tools --data-file=tools.yamlgcloud secrets versions add tools --data-file=tools.yaml - Implementa con la imagen de contenedor pública de MCP Toolbox:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:0.29.0 export PROJECT_ID=$(gcloud config get-value project) gcloud run deploy toolbox \ --image $IMAGE \ --region us-central1 \ --service-account $(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")-compute@developer.gserviceaccount.com \ --set-secrets "/app/tools.yaml=tools:latest" \ --args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080","--ui" \ --allow-unauthenticated - Una vez implementado, anota la URL del servicio de Cloud Run proporcionada. Debería verse como
https://toolbox-*********-uc.a.run.app/ui.
9. Configura la aplicación de comercio electrónico y, luego, impleméntala en Cloud Run
Con nuestras bases de datos en ejecución y la abstracción de MCP Toolbox implementada, podemos ejecutar la aplicación web de Flask.
Para publicar el catálogo de productos, la aplicación de Flask procesa los datos siguiendo estos pasos:
- Recuperar datos principales: Recupera la lista completa de productos de AlloyDB (
list_products_core). - Recuperar detalles extendidos: Recupera todos los detalles del producto de MongoDB (
list_all_product_details). - Combinar listas: Concatena las dos listas.
- Enrich with media: Agrega la URL de la imagen de Cloud Storage a cada elemento.
Genera la ruta de acceso a la aplicación del motor de inferencia
Para inicializar y registrar un agente de IA con el motor de razonamiento de Vertex AI de Google Cloud, ejecuta el siguiente comando:
- En la terminal de Cloud Shell, navega a la carpeta
BRK2-149-multidb-ecommerce.cd next-26-sessions/BRK2-149-multidb-ecommerce - Ejecuta requirements.txt para instalar las dependencias.
pip install -r requirements.txt - Ejecuta la secuencia de comandos
agentengine.pypara generar la ruta de acceso a la aplicación de Reasoning Engine:python agentengine.py
El resultado será similar al siguiente ejemplo:
projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856
Configura las variables de entorno
- Crea un archivo
.envy edítalo:cloudshell edit .env - Reemplaza los valores por tus conexiones de base de datos específicas y la nueva URL de Cloud Run Toolbox:
# 1. MongoDB Connection String MONGODB_CONNECTION_STRING="mongodb+srv://<db_user>:<db_password>@cluster0.mongodb.net" # 2. MCP Toolbox Server Location # Must match the address where you run the toolbox server MCP_TOOLBOX_SERVER_URL="https://toolbox-*********-uc.a.run.app" # 3. Google Cloud Storage Bucket Name GCS_PRODUCT_BUCKET="ecommerce-app-images" # 4. Fallback image URL FALLBACK_IMAGE_URL="https://storage.googleapis.com/ecommerce-media-bold-circuit-492711-n9/fallback.jpg" # 5. Google Gen AI Vertex AI flag GOOGLE_GENAI_USE_VERTEXAI=TRUE # 6. Project ID PROJECT_ID=codelab-project-491117 # 7. Google Cloud Location of AlloyDB, BigQuery databases GOOGLE_CLOUD_LOCATION=us-central1 # 8. Reasoning engine application path APP_NAME=projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856 # 9. Model ID MODEL=gemini-1.5-flash-lite
Implementa el frontend en Cloud Run
- Implementa la aplicación web en Cloud Run para completar la arquitectura:
gcloud run deploy polyglot --source . --platform managed \ --region us-central1 \ --allow-unauthenticated \ --set-env-vars \ MONGODB_CONNECTION_STRING="<MONGODB_CONNECTION_STRING>", \ MCP_TOOLBOX_SERVER_URL="<MCP_TOOLBOX_SERVER_URL>", \ GCS_PRODUCT_BUCKET="<GCS_PRODUCT_BUCKET>", \ FALLBACK_IMAGE_URL="<FALLBACK_IMAGE_URL>", \ GOOGLE_GENAI_USE_VERTEXAI=TRUE, \ PROJECT_ID="YOUR_PROJECT_ID", \ GOOGLE_CLOUD_LOCATION=us-central1, \ APP_NAME="<YOUR_REASONING_ENGINE_APP_PATH>", \ MODEL="gemini-1.5-flash-lite"YOUR_PROJECT_ID: Es el ID de tu proyecto de Google Cloud.YOUR_REASONING_ENGINE_APP_PATH: Es el resultado de ejecutarpython agentengine.py, por ejemplo,projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856.MCP_TOOLBOX_SERVER_URL: Es la URL de tu servidor de MCP Toolbox, por ejemplo,https://toolbox-*********-uc.a.run.app.GCS_PRODUCT_BUCKET: Es el nombre de tu bucket de Google Cloud Storage, por ejemplo,ecommerce-app-images.MONGODB_CONNECTION_STRING: Es la cadena de conexión de tu base de datos de MongoDB, por ejemplo,mongodb+srv://store-user:storeuser@ecommerce-cluster.g8vaekh.mongodb.net.FALLBACK_IMAGE_URL: URL de la imagen de resguardo, por ejemplo,https://storage.googleapis.com/ecommerce-app-images/fallback.jpg
Tu aplicación ya está disponible. Abre la URL del servicio que proporciona Cloud Run para ver el catálogo de comercio electrónico de Multidb. La URL será similar a https://polyglot-*********-uc.a.run.app/.
10. Explora la aplicación
- Haz clic en Catálogo de productos para ver todos los productos.
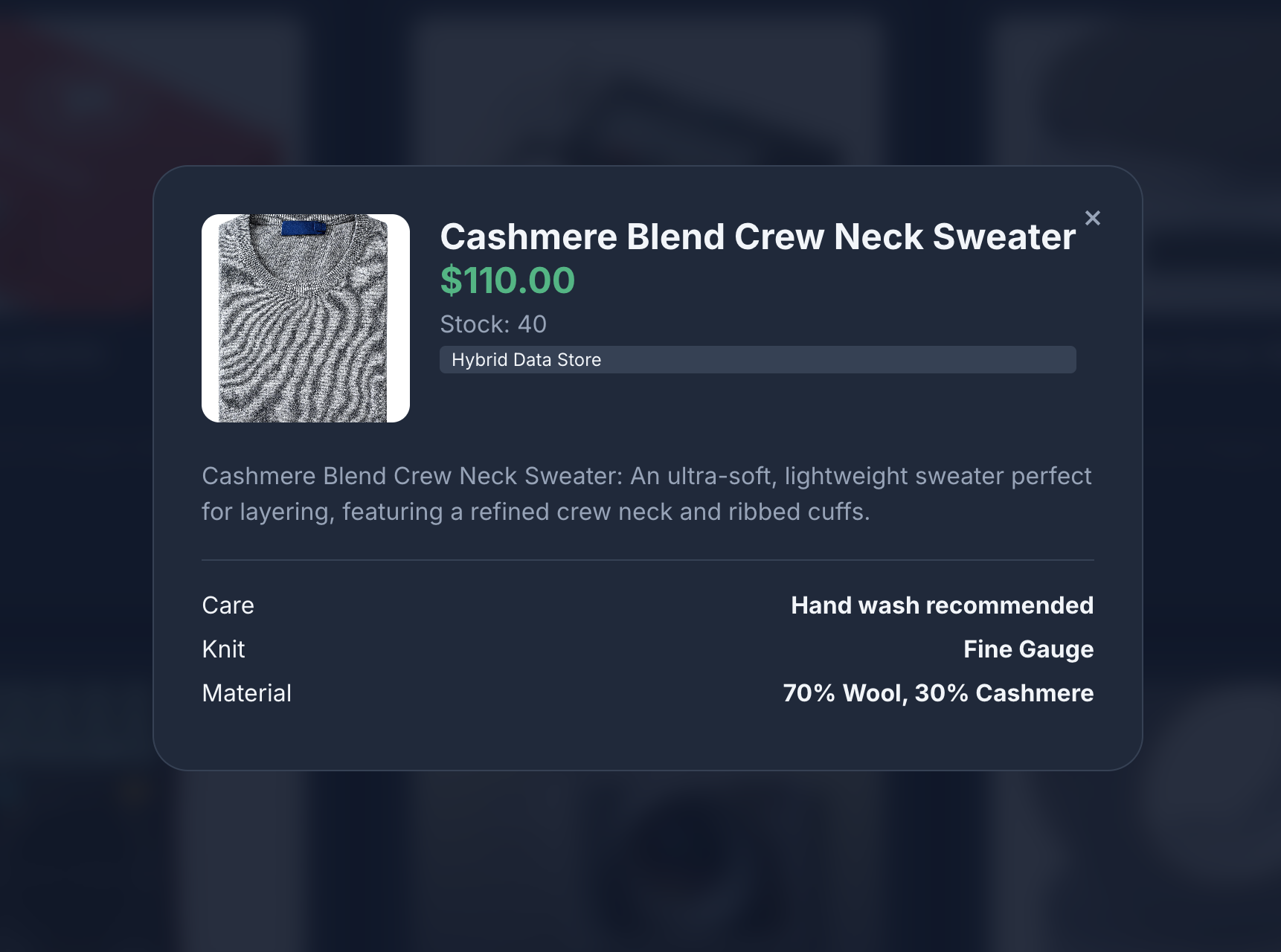
- Haz clic en el ícono de un producto para ver sus detalles. Notarás que las imágenes provienen de Cloud Storage, los detalles del producto se recuperan de MongoDB y el inventario del producto se recupera de AlloyDB.
- Interactúa con el catálogo de productos para generar vistas y escrituras simuladas que se envían a MongoDB.
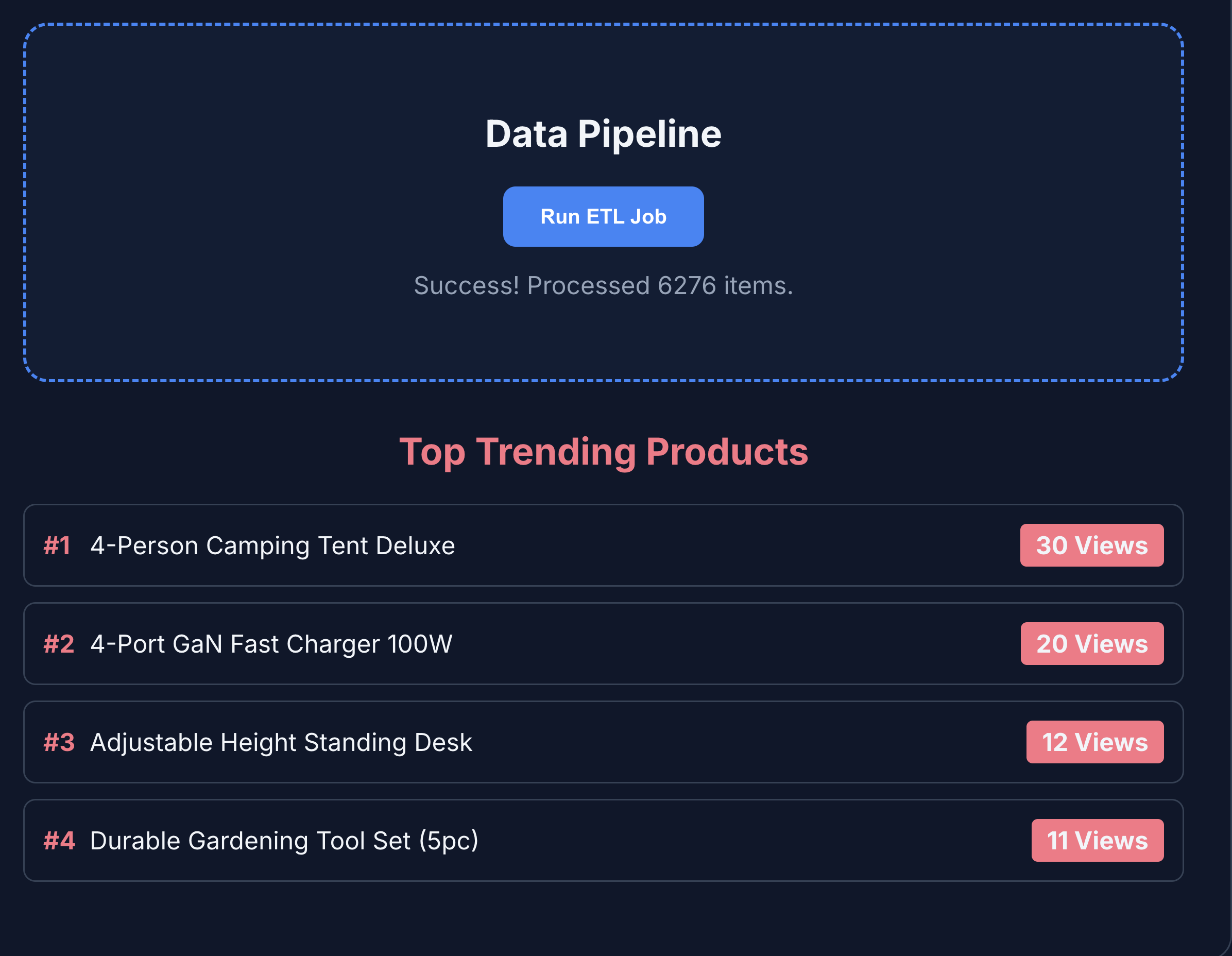
- Haz clic en ETL & Analytics para ver las estadísticas del producto. Notarás que las estadísticas del producto se recuperan de BigQuery.
- Haz clic en la pestaña Agente de IA para interactuar con el agente de IA. Haz preguntas en lenguaje natural, como las siguientes:
I'm planning a high-altitude photography trip. Show me some weather-resistant backpacks similar in style to aero glow pro but without any leather components. Also, let me know if they are actually in stock and if other photographers have complained about the strap durability in the reviews.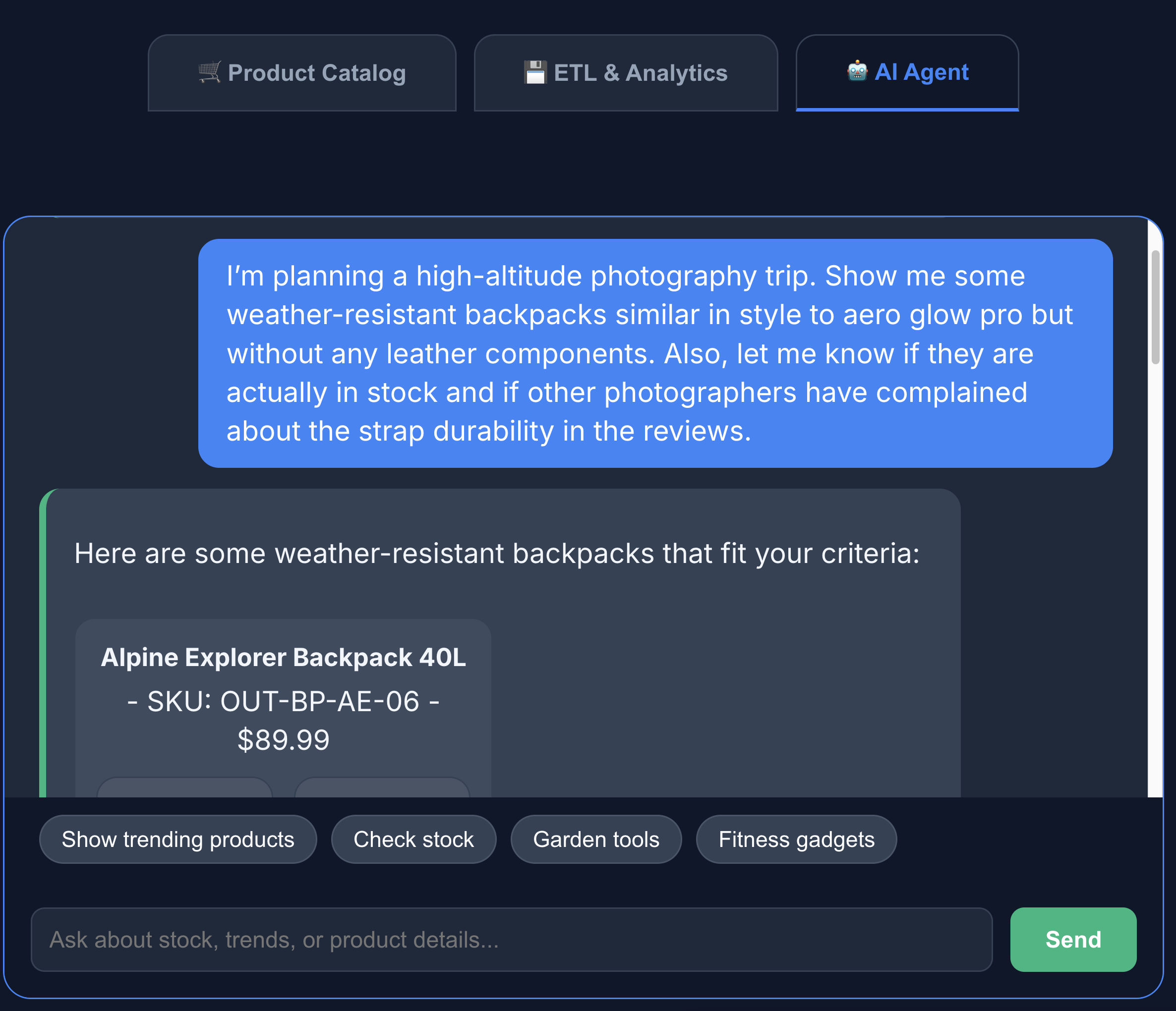
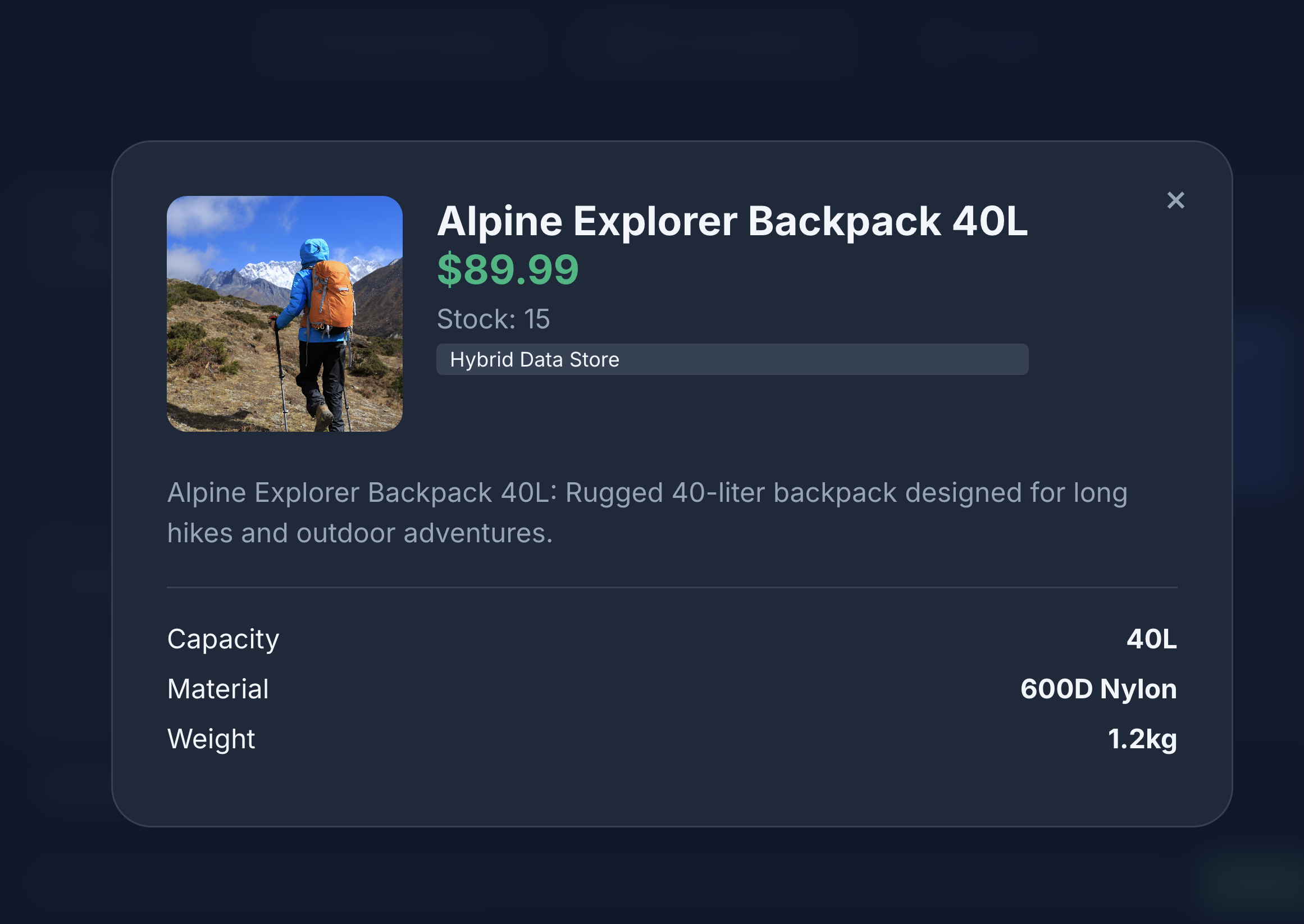
Puedes ver que la búsqueda devuelve exactamente lo que pedimos: una mochila sin componentes de cuero, en stock y sin quejas sobre la durabilidad de las correas en las opiniones.
11. Limpia
Para evitar que se apliquen cargos a tu cuenta de Google Cloud, borra los recursos que creaste durante este codelab.
Ejecuta los siguientes comandos de Cloud Shell:
gcloud run services delete toolbox --region us-central1 --quiet
gcloud run services delete multi-db-app --region us-central1 --quiet
bq rm -r -f -d $PROJECT_ID:ecommerce_analytics
gcloud storage rm --recursive gs://ecommerce-app-images
gcloud alloydb clusters delete ecommerce-cluster --region us-central1 --force --quiet
De manera opcional, para borrar todo el proyecto de Google Cloud y todos sus recursos, ejecuta el siguiente comando:
gcloud projects delete $PROJECT_ID
12. ¡Felicitaciones!
¡Felicitaciones! Creaste correctamente una arquitectura de Multidb en varias nubes.
Demostraste cómo MCP Toolbox sirve como nexo arquitectónico para una aplicación moderna y especializada. Al hacer coincidir la base de datos correcta con el trabajo adecuado, lograste lo siguiente:
- Escrituras de datos flexibles: MongoDB para registros de eventos.
- Coherencia transaccional: AlloyDB para la integridad principal.
- High-Performance Analytics: BigQuery para la inteligencia empresarial
- Desarrollo unificado: Un solo backend de Python que abstrae toda la complejidad con MCP Toolbox.
Documentos de referencia
Obtén más información sobre los productos relacionados de Google Cloud y explora estos codelabs:
- AlloyDB AI: Comienza a usar embeddings de vectores con AlloyDB AI
- AlloyDB AI: Incorporaciones multimodales en AlloyDB
- MCP Toolbox: Instala y configura MCP Toolbox para bases de datos en AlloyDB
Para obtener más información sobre los productos que se usan en este codelab, consulta los siguientes recursos: