
۱. مقدمه
در خردهفروشی مدرن، دادههای شما یک اکوسیستم متنوع و گسترده است. شما دادههای تراکنشی بسیار قوی (قیمتگذاری و موجودی)، کاتالوگهای چندریختی «نامرتب» (مشخصات لوازم الکترونیکی در مقابل اندازه پوشاک) و پتابایتها گزارش رفتاری دارید. اجبار این موارد به یک سیستم یکپارچه، نه تنها بدهی فنی ایجاد میکند، بلکه تجربه کاربری را نیز از بین میبرد.
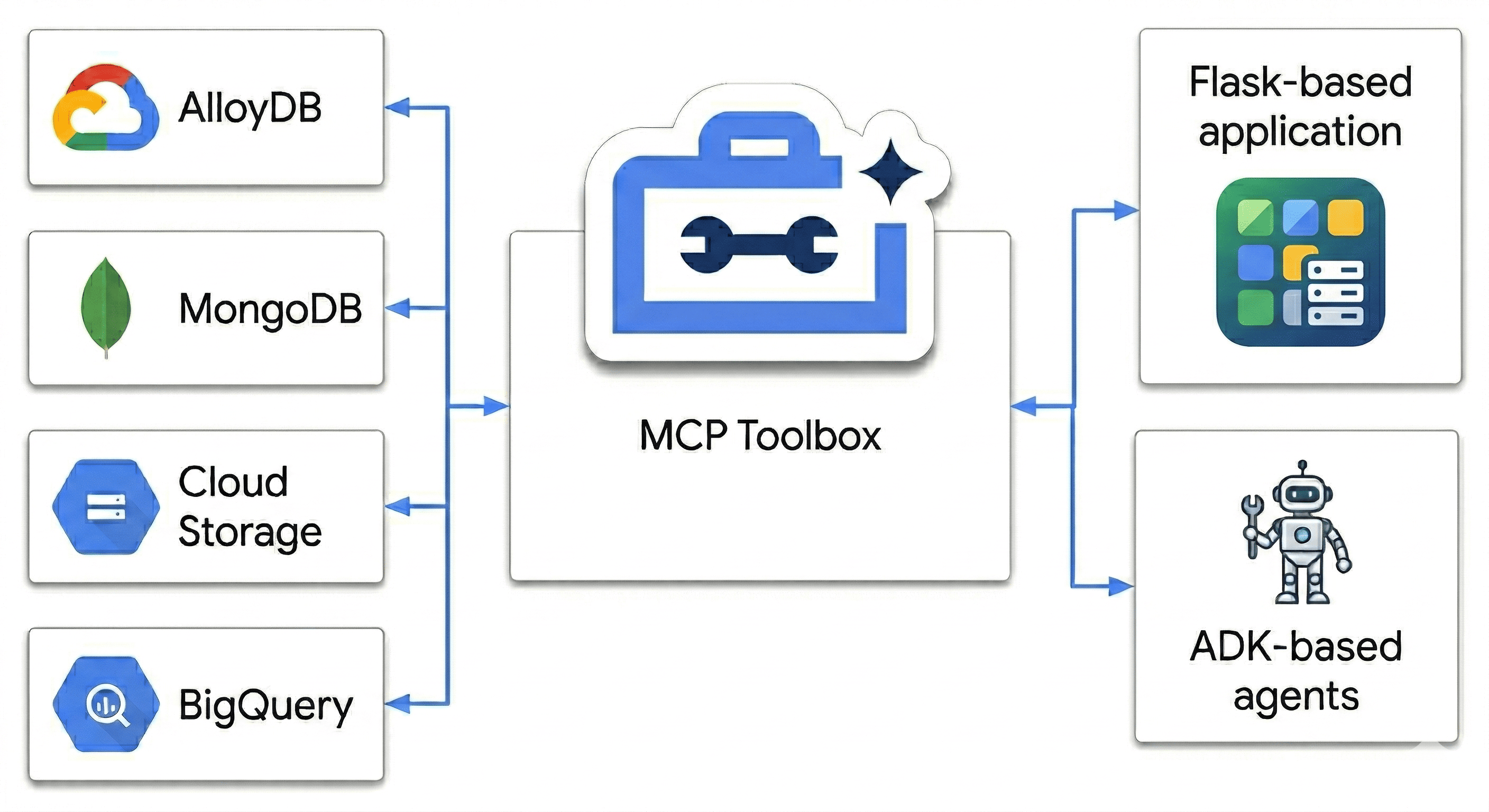
در این آزمایشگاه کد، شما یک نیروگاه چندزبانه (Polyglot Powerhouse) را طراحی خواهید کرد که موارد زیر را هماهنگ میکند:
- AlloyDB : ستون فقرات تراکنشی شما برای ثبات سرعت بالا و جاسازی تصاویر.
- اطلس MongoDB روی گوگل کلود : لایه کاتالوگ انعطافپذیر و مستقل از طرحواره شما.
- فضای ذخیرهسازی ابری : مغز تحلیلی شما برای پیشبینی روندها در لحظه.
- BigQuery : انبار داده دیجیتال با وضوح بالای شما.
«مخفیترین نکته» چیست؟ شما از جعبه ابزار MCP برای پایگاههای داده استفاده خواهید کرد تا منابع دادهای که روی Cloud Run اجرا میشوند را به عنوان یک پل معنایی به صورت هوشمندانه هماهنگ و یکپارچه کنید، سپس با استفاده از کیت توسعه عامل (ADK) یک برنامه چت چندعاملی مستقر کنید. شما فقط یک نوار جستجو نمیسازید؛ شما در حال ساخت یک مغز خردهفروشی هوشمند هستید که زمینه را درک میکند، محدودیتها را رعایت میکند و شکاف بین دادههای خام و قصد انسانی را پر میکند.
پرس و جوی غیرممکن کاربر
نمایندگان استاندارد تجارت الکترونیک در استدلال چندبعدی (ترکیب محدودیتهای منفی، شباهت بصری و موجودی در لحظه) شکست میخورند. برای مثال، من معمولاً میخواهم با یک سایت خردهفروشی به این شکل صحبت کنم:
«سلام، من دارم برای یک سفر عکاسی در ارتفاعات بالا برنامهریزی میکنم. چند کوله پشتی مقاوم در برابر آب و هوا، شبیه به «AeroGlow Pro» اما بدون هیچ گونه قطعه چرمی، به من نشان دهید. همچنین، به من اطلاع دهید که آیا واقعاً موجود هستند و آیا عکاسان دیگر در نظرات از دوام بند آنها شکایت کردهاند یا خیر.»
چرا این عبارت جستجو "قاتل مامور" است؟
- شباهت بصری (AlloyDB + جستجوی برداری): «از نظر سبک مشابه AeroGlow Pro» نیاز به مقایسه جاسازی تصویر دارد.
- محدودیت منفی (MongoDB): «بدون هیچ چرمی» نیاز به فیلتر کردن از طریق ویژگیهای انعطافپذیر و تو در تو دارد که معمولاً در یک طرحواره استاندارد SQL وجود ندارند.
- موجودی آنی (AlloyDB): عبارت «موجود در انبار» نیاز به بررسی تراکنشهای زنده دارد (نه یک فهرست جستجوی قدیمی).
- سنتز معنایی (BigQuery + چندعاملی): تجزیه و تحلیل نظرات برای «دوام تسمه» مستلزم آن است که عامل، بازخوردهای بدون ساختار از BigQuery را درجا خلاصه کند.
بیشتر رباتهای خردهفروشی فقط «کوله پشتی» و «چرم» را میبینند و 10 کوله پشتی چرمی را نشان میدهند. چطور میتوانیم جلوی این را بگیریم؟
چون ما فقط کلمات کلیدی را تطبیق نمیدهیم. ما از جعبه ابزار MCP استفاده میکنیم تا به عاملهایمان اجازه دهیم در تمام این منابع، حقیقت تراکنشی در AlloyDB و ویژگیهای انعطافپذیر در MongoDB را به طور همزمان «استدلال» کنند. بیایید آن را بسازیم.
کاری که انجام خواهید داد
- ارائه یک کلاستر AlloyDB برای دادههای اصلی محصول
- پیکربندی MongoDB Atlas در Google Cloud برای ذخیره جزئیات نیمه ساختاریافته محصول
- یک فضای ذخیرهسازی ابری برای ارائه تصاویر محصول ایجاد کنید
- برای دسترسی یکنواخت به دادهها ، جعبه ابزار MCP برای پایگاههای داده را روی Cloud Run مستقر کنید.
- اجرای فرآیندهای ETL برای ارسال دادهها به BigQuery جهت تجزیه و تحلیل
- با یک عامل هوش مصنوعی به زبان طبیعی صحبت کنید.
پیشنیازها
- یک مرورگر وب مانند کروم
- یک پروژه گوگل کلود با قابلیت پرداخت صورتحساب
- یک حساب کاربری رایگان MongoDB Atlas در گوگل کلود
۲. قبل از شروع
ایجاد یک پروژه ابری گوگل
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید .
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
شروع پوسته ابری
Cloud Shell یک محیط خط فرمان است که در Google Cloud اجرا میشود و ابزارهای لازم از قبل روی آن بارگذاری شدهاند.
- روی فعال کردن Cloud Shell در بالای کنسول Google Cloud کلیک کنید.
- پس از اتصال به Cloud Shell، احراز هویت خود را تأیید کنید:
gcloud auth list - تأیید کنید که پروژه شما پیکربندی شده است:
gcloud config get project - اگر پروژه شما مطابق انتظار تنظیم نشده است، آن را تنظیم کنید:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
فعال کردن API های مورد نیاز
برای فعال کردن تمام API های مورد نیاز، این دستور را اجرا کنید:
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
۳. فضای ذخیرهسازی ابری را راهاندازی کنید
فضای ذخیرهسازی ابری به عنوان یک فروشگاه عظیم برای داراییهای رسانهای بدون ساختار، مانند تصاویر محصول، عمل میکند.
- در کنسول گوگل کلود، به فضای ذخیرهسازی ابری (Cloud Storage ) بروید و روی ایجاد سطل (Create bucket) کلیک کنید.
- به سطل خود یک نام منحصر به فرد جهانی بدهید (مثلاً
ecommerce-app-images). - روی ایجاد کلیک کنید.
- برای اینکه به برنامه آزمایشی اجازه دهید بدون احراز هویت به تصاویر دسترسی داشته باشد، گزینه Enforce public access prevention on this bucket را غیرفعال کنید و روی Confirm کلیک کنید.
- به برگه مجوزها بروید.
- در بخش مجوزها ، روی اعطای دسترسی کلیک کنید.
- در بخش New principals ،
allUsersرا وارد کنید. - در بخش «انتخاب یک نقش» ، گزینه «فضای ابری» > «کاربر شیء ذخیرهسازی» را انتخاب کنید.
- روی ذخیره کلیک کنید و سپس برای تأیید عمومی کردن منبع، روی اجازه دسترسی عمومی کلیک کنید.
تصاویر جایگزین را بارگذاری کنید
فروشگاه اینترنتی BRK2-149-multidb-ecommerce از تصاویر جایگزین برای بهترین تجربه بصری استفاده میکند.
- در Cloud Shell خود، مخزن
next-26-sessionsرا کلون کنید:git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git - به پوشه
UploadImagesبروید:cd next-26-sessions/BRK2-149-multidb-ecommerce/UploadImages - در کنسول گوگل کلود، به بخش فضای ذخیرهسازی ابری (Cloud Storage) بروید و روی گزینهی «باکتس» (Buckets) کلیک کنید.
- روی نام سطل تازه ایجاد شده خود کلیک کنید.
- روی آپلود > آپلود فایلها کلیک کنید، تصاویر نمونه دانلود شده را انتخاب کنید و روی باز کردن کلیک کنید.
۴. راهاندازی AlloyDB
AlloyDB به عنوان تنها منبع حقیقت برای دادههای ساختاریافته، تراکنشی و حیاتی مانند شناسههای محصول، نامها، SKUها، قیمتها و موجودی عمل میکند. AlloyDB همچنین عامل هوش مصنوعی را با قابلیتهای جستجوی شباهت برای توصیهها و پرسوجوهای زبان طبیعی توانمند میسازد.
ارائه یک کلاستر AlloyDB
- در کنسول گوگل کلود، به AlloyDB برای PostgreSQL بروید.
- روی ایجاد خوشه کلیک کنید.
- برای Cluster ID ،
ecommerce-clusterرا وارد کنید. - یک رمز عبور قوی برای کاربر
postgresتنظیم کنید. برای اهداف یادگیری، میتوانیدalloydbاستفاده کنید. - برای نسخه پایگاه داده ، مقدار پیشفرض را نگه دارید.
- برای منطقه ،
us-central1(یا منطقه مورد نظر خود) را انتخاب کنید.
پیکربندی نمونه اولیه
- برای شناسه نمونه ،
ecommerce-cluster-primaryرا وارد کنید. - در بخش «دسترسی منطقهای» ، گزینه «منطقه واحد» را انتخاب کنید.
- برای نوع ماشین ، یک نوع ماشین کوچک (مثلاً N2، 4 vCPU، 32 گیگابایت رم) انتخاب کنید.
- در بخش اتصال IP خصوصی ، گزینه Private Services Access (PSA) را انتخاب کنید و شبکه
defaultرا انتخاب کنید. اگر شبکه پیشفرض از قبل تنظیم نشده است، برای ایجاد آن، روی تأیید تنظیم شبکه کلیک کنید. - در بخش اتصال IP عمومی ، گزینه فعال کردن IP عمومی را انتخاب کنید تا جعبه ابزار MCP بتواند به درستی در این آزمایشگاه کد متصل شود.
- در قسمت «شبکههای خارجی مجاز» ،
0.0.0.0/0را وارد کنید. کادر «من خطرات را میپذیرم» را علامت بزنید و روی «ذخیره» کلیک کنید. - روی ایجاد خوشه کلیک کنید.
توجه: حتماً آدرسهای IP عمومی خود را یادداشت کنید (به نظر میرسد چیزی شبیه به 34.124.240.26 باشد).
مقداردهی اولیه پایگاه داده
- از منوی ناوبری سمت چپ، روی AlloyDB Studio کلیک کنید.
- در منوی کشویی Database ، گزینه
postgresرا انتخاب کنید. - برای ورود به پایگاه داده، احراز هویت داخلی (Built-in authentication) را انتخاب کنید.
- برای نام کاربری ، از کاربر
postgresاستفاده کنید. - برای رمز عبور ، رمز عبوری را که قبلاً تنظیم کردهاید وارد کنید.
- روی تأیید اعتبار کلیک کنید.
- در نمای ویرایشگر، یک برگه پرس و جوی بدون عنوان جدید باز کنید.
- DDL زیر را کپی کرده و روی Run کلیک کنید:
CREATE TABLE products_core_table ( product_id UUID PRIMARY KEY, name VARCHAR(255) NOT NULL, sku VARCHAR(50) UNIQUE NOT NULL, price NUMERIC(10, 2) NOT NULL, stock INT NOT NULL ); - در Cloud Shell خود، به پوشه
BRK2-149-multidb-ecommerceبروید:cd next-26-sessions/BRK2-149-multidb-ecommerce - فایل
alloydb_insert_queries.sqlرا در Cloud Shell خود باز کنید و کوئریهای درج را کپی کنید.cat alloydb_insert_queries.sql - در یک تب کوئری جدید بدون عنوان، فقط عبارات
INSERTرا وارد کنید و روی Run کلیک کنید. - در یک تب جدید بدون عنوان کوئری، DDL زیر را کپی کرده و روی Run کلیک کنید تا یک اندیس در جدول
products_core_tableایجاد شود:CREATE INDEX idx_products_core_sku ON products_core_table(sku);
ایجاد جاسازیهای تصویر برای عامل هوش مصنوعی جهت دریافت محصولات مشابه
یکپارچهسازی عامل هوش مصنوعی از جاسازیهای تصویر برای دریافت محصولات مشابه استفاده میکند. جاسازیها با استفاده از مدل multimodalembedding@001 تولید شده و در پایگاه داده AlloyDB ذخیره میشوند. جاسازیها بردارهای ۱۴۰۸ بعدی هستند و در ستون img_embeddings ذخیره میشوند.
قبل از اینکه بتوانیم جاسازیها را ایجاد کنیم، باید نقشهای لازم را به حساب سرویس AlloyDB اعطا کنیم تا به فضای ذخیرهسازی ابری دسترسی داشته باشد.
اعطای نقش به حساب سرویس AlloyDB برای دسترسی به فضای ذخیرهسازی ابری
ما نقشهای Storage Object User و Storage Object Viewer را به حساب سرویس AlloyDB اعطا میکنیم تا آن را قادر به خواندن اشیاء از مخزن ذخیرهسازی ابری کنیم.
- به IAM و admin بروید.
- روی اعطای دسترسی کلیک کنید.
- در فیلد New principals ، عبارت حساب سرویس AlloyDB را جستجو کنید. حساب سرویس شبیه به
service-991742412753@gcp-sa-alloydb.iam.gserviceaccount.comاست. - روی انتخاب نقش کلیک کنید.
- نقش کاربری شیء ذخیرهسازی (Storage Object User) را پیدا کرده و انتخاب کنید.
- روی «افزودن یک نقش دیگر» کلیک کنید و نقش « نمایشگر شیء ذخیرهسازی» را انتخاب کنید.
- روی «افزودن یک نقش دیگر» کلیک کنید و نقش کاربر Vertex AI را انتخاب کنید.
- روی ذخیره کلیک کنید.
فعال کردن افزونهها
برای ساخت این برنامه، از افزونههای pgvector و google_ml_integration استفاده خواهیم کرد. افزونه pgvector به شما امکان ذخیره و جستجوی جاسازیهای برداری را میدهد. افزونه google_ml_integration توابعی را ارائه میدهد که برای دسترسی به نقاط پایانی پیشبینی هوش مصنوعی Vertex برای دریافت پیشبینیها در SQL استفاده میکنید. این افزونهها را با اجرای DDL های زیر فعال کنید:
- در کنسول گوگل کلود، به AlloyDB برای PostgreSQL بروید.
- از منوی ناوبری سمت چپ، روی AlloyDB Studio کلیک کنید.
- در نمای ویرایشگر، یک برگه پرس و جوی بدون عنوان جدید باز کنید.
- DDL زیر را کپی کرده و روی Run کلیک کنید:
CREATE EXTENSION IF NOT EXISTS vector; CREATE EXTENSION IF NOT EXISTS google_ml_integration;
مقداردهی اولیه پایگاه داده با جاسازیها
- ستون img_embeddings را به
products_core_tableاضافه کنید.ALTER TABLE products_core_table ADD COLUMN img_embeddings vector(1408); - برای تصاویر، جاسازی ایجاد کنید و آنها را در ستون
img_embeddingsذخیره کنید.UPDATE products_core_table SET img_embeddings = google_ml.image_embedding( model_id => 'multimodalembedding@001', image => 'gs://<STORAGE_BUCKET_NAME>/' || sku || '.jpg', mimetype => 'image/jpeg') WHERE sku IN ( SELECT sku FROM products_core_table WHERE img_embeddings IS NULL AND sku IS NOT NULL LIMIT 10 ); - پرسوجوی قبلی را حداقل ۵ بار تکرار کنید تا جاسازیهای تصویر برای کل مجموعه ایجاد شود، زیرا استودیو محدودیت ۵ دقیقهای دارد. اگر زمان این پرسوجو تمام شد،
LIMITبه5تغییر دهید و پرسوجو را ده بار تکرار کنید. تکمیل این مرحله ممکن است چند دقیقه طول بکشد.
۵. راهاندازی MongoDB Atlas روی Google Cloud
MongoDB جزئیات غنی و نیمهساختاریافتهی محصول و دادههای رفتار کاربر انعطافپذیر (مانند کلیکها و بازدیدها) را ذخیره میکند.
ایجاد کلاستر MongoDB
- به MongoDB Atlas در Google Cloud بروید، یک حساب کاربری رایگان انتخاب کنید.
- ردیف خوشه رایگان را انتخاب کنید و یک نام برای خوشه وارد کنید، برای مثال
ecommerce-cluster. - Google Cloud را به عنوان ارائه دهنده انتخاب کنید و مطمئن شوید که منطقه با منطقه Google Cloud شما همسو است (مثلاً
us-central1). - روی ایجاد استقرار کلیک کنید.
- روی بستن کلیک کنید.
پیکربندی دسترسی به شبکه
- در کنسول Atlas، به بخش Database & Network Access بروید.
- روی فهرست دسترسی IP کلیک کنید.
- روی افزودن آدرس IP کلیک کنید.
-
0.0.0.0/0را اضافه کنید که امکان دسترسی از هر مکانی را فراهم میکند. - روی تأیید کلیک کنید.
ایجاد کاربر پایگاه داده
- در کنسول Atlas، به بخش Database & Network Access بروید.
- روی کاربران پایگاه داده کلیک کنید.
- روی افزودن کاربر جدید پایگاه داده کلیک کنید.
- رمز عبور را به عنوان روش احراز هویت انتخاب کنید.
- نام کاربری را
store-userو رمز عبور راstoreuserوارد کنید. - روی «افزودن نقش داخلی» کلیک کنید، گزینه «خواندن و نوشتن در هر پایگاه داده» را انتخاب کنید.
- روی افزودن کاربر کلیک کنید.
رشته اتصال را دریافت کنید
- به پایگاه داده > خوشهها > اتصال بروید.
- در پنجرهی «اتصال برنامه» ، روی «درایورها» کلیک کنید.
- رشته اتصالی که در بخش «افزودن رشته اتصال» نشان داده شده است را در کد برنامه خود کپی کنید. این رشته چیزی شبیه به این خواهد بود:
mongodb+srv://store-user:<db_password>@ecommerce-cluster.g8vaekh.mongodb.net/?appName=ecommerce-clusterdb_passwordبا رمز عبور MongoDB خود جایگزین کنید. در این codelab، اینstoreuserاست.
این رشته اتصال را ذخیره کنید. بعداً از آن برای متغیر محیطی MONGODB_CONNECTION_STRING استفاده خواهید کرد.
ایجاد پایگاه داده و مجموعه
- در کنسول Atlas، به مسیر Database > Clusters > Browse Collections بروید.
- روی ایجاد پایگاه داده کلیک کنید و جزئیات را وارد کنید:
- نام پایگاه داده:
ecommerce_db - نام مجموعه:
product_details_collection
- نام پایگاه داده:
- روی ایجاد پایگاه داده کلیک کنید.
- در Data Explorer، نام مجموعه (Collection Name) را انتخاب کنید.
- روی نماد افزودن داده (+) کلیک کنید و سپس روی درج سند کلیک کنید.
- محتوای JSON را از product_details_export.json کپی کرده و آن را در پنجره ویرایشگر درج سند (Insert Document) قرار دهید.
- برای درج آرایه اسناد و تأیید اضافه شدن ۱۹۲ سند، روی «افزودن » کلیک کنید.
- در پنجرهی Data Explorer، روی گزینهی Create collection (+) در کنار پایگاه دادهی
ecommerce_dbکلیک کنید. - برای نام مجموعه،
user_interactions_collectionرا وارد کنید و روی ایجاد مجموعه کلیک کنید. - در پنجرهی Data Explorer، مجموعهی
user_interactions_collectionرا انتخاب کنید. - روی نماد افزودن داده (+) کلیک کنید و سپس روی درج سند کلیک کنید.
- محتوای JSON را از user_interactions_export.json کپی کرده و آن را در پنجره ویرایشگر درج سند (Insert Document) قرار دهید.
- روی درج سند کلیک کنید.
۶. تنظیم BigQuery
بیگکوئری (BigQuery) رفتار کاربران را جمعآوری و تحلیل میکند تا گزارشها و پیشنهادهای هوشمندی ارائه دهد.
ایجاد مجموعه داده
- در کنسول گوگل کلود، به BigQuery بروید.
- در کنار شناسه پروژه خود در پنل اکسپلورر، روی منوی سه نقطه کلیک کنید و گزینه «ایجاد مجموعه داده» را انتخاب کنید.
- برای شناسه مجموعه داده،
ecommerce_analyticsرا وارد کنید. - روی ایجاد مجموعه داده کلیک کنید.
جدول تحلیلی را ایجاد کنید
- یک کوئری جدید در فضای کاری BigQuery باز کنید.
- دستور SQL زیر را برای ایجاد جدول خلاصهای که کاربران را به تعاملات محصول مرتبط میکند، اجرا کنید:
CREATE TABLE ecommerce_analytics.user_product_interactions (
user_id STRING DEFAULT 'any user',
product_id STRING,
interaction_score INT
);
اعطای نقش به حساب سرویس Compute برای MCP Toolbox
ما به حساب سرویس Compute که برای Toolbox ما استفاده میشود، نقشهایی اعطا میکنیم. این کار برای فعال کردن MCP Toolbox برای دسترسی به BigQuery، Secret Manager و سایر سرویسهای ابری انجام میشود.
برای اعطای نقشها، مراحل زیر را انجام دهید:
- به IAM و admin بروید.
- روی اعطای دسترسی کلیک کنید.
- در فیلد New principals ، حساب کاربری پیشفرض سرویس Compute با نام
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.comرا وارد کنید.YOUR_PROJECT_NUMBERرا با شماره پروژه Google Cloud خود جایگزین کنید. - روی انتخاب نقش کلیک کنید.
- نقش BigQuery Data Editor را پیدا کرده و انتخاب کنید.
- روی «افزودن یک نقش دیگر» کلیک کنید و نقش کاربر BigQuery Job را انتخاب کنید.
- روی «افزودن یک نقش دیگر» کلیک کنید و نقش « مدیر مخفی، دسترسی مخفی» را انتخاب کنید.
- روی «افزودن یک نقش دیگر» کلیک کنید و نقش ویرایشگر را انتخاب کنید.
- روی ذخیره کلیک کنید.
۷. برنامه را از ابتدا تا انتها درک کنید
برای آشنایی با نحوهی عملکرد هر جزء با یکدیگر، یک برنامهی تجارت الکترونیک ساده ایجاد خواهیم کرد که از چندین پایگاه داده و سرویس استفاده میکند. این برنامه با استفاده از یک backend پایتون (Flask) ساخته شده و چندین سرویس و پایگاه دادهی Google Cloud را ادغام میکند.
ساختار دایرکتوری را درک کنید
در بخش بعدی، مخزن BRK2-149-multidb-ecommerce را کلون کرده و از آن برای اجرای برنامه به صورت محلی استفاده خواهید کرد. پس از آزمایش برنامه به صورت محلی، MCP Toolbox و برنامه را در Cloud Run مستقر خواهیم کرد.
فایلهای دانلود شده در این دایرکتوری را بررسی کنید. دایرکتوریهای سطح بالای زیر موجود هستند:
-
UploadImages: فایلهای تصویری را ذخیره میکند که عمدتاً برای مستندسازی یا محتوای بصری برای کاتالوگ محصولات تجارت الکترونیک استفاده میشوند. -
static: داراییهای وب استاتیک برنامه، مانند فایلهای CSS و جاوا اسکریپت را ذخیره میکند که برای استایلدهی و افزودن تعامل به رابط کاربری (source) استفاده میشوند. -
templates: قالبهای HTML (احتمالاً Jinja2 برای Flask) را ذخیره میکند که توسط برنامه پایتون برای رندر پویای صفحات وب برای کاتالوگ تجارت الکترونیک (منبع) استفاده میشود. -
toolbox-implementation: جزئیات پیکربندی و پیادهسازی را برای جعبه ابزار Model Context Protocol (MCP) ذخیره میکند و تعاملات پایگاه داده چند پایگاه دادهای را با استفاده از ابزارهای از پیش تعریف شده تسهیل میکند.
فایلهای موجود در این مخزن با هم کار میکنند تا یک برنامه تجارت الکترونیک چند پایگاه دادهای را بسازند، پیکربندی کنند و مستقر سازند. فایلهای مرکزی مانند app.py با ادغام منابع داده متنوع تعریف شده در فایلهای SQL و JSON، backend را هماهنگ میکنند، در حالی که فایلهای پیکربندی، استقرار یکپارچه در محیطهای ابری را تضمین میکنند:
-
app.py: هماهنگسازی بکاند فلاسک و یکپارچهسازی چندپایگاهدادهای را انجام میدهد. -
agentengine.py: منطق اصلی برای مقداردهی اولیه و پیکربندی عاملهای هوش مصنوعی Vertex. -
.env: اطلاعات محرمانه مربوط به پایگاه داده و اتصالات ذخیرهسازی را ذخیره میکند. -
tools.yaml: جعبه ابزار MCP را برای عملیات پایگاه داده چند پایگاه داده پیکربندی میکند. -
Dockerfile: تصویر کانتینر و تنظیمات محیط را تعریف میکند. -
requirements.txt: فهرستی از کتابخانههای پایتون مورد نیاز برای زمان اجرای برنامه را ارائه میدهد. -
tools.yaml: پیکربندیهای مربوط به جعبه ابزار MCP. -
Procfile: دستورات اجرایی محیط عملیاتی را برای استقرار مشخص میکند. -
alloydb_insert_queries.sql: شامل کوئریهای SQL برای دادههای رابطهای است. -
product_details_export.jsonوuser_interactions_export.json: دادههای نمونه JSON را برای پایگاه داده NoSQL ارائه میدهد. -
README.md: راهنمای راهاندازی، استقرار و درک پروژه.
جریان سرتاسری برنامه
- راهاندازی AlloyDB : یک کلاستر با کارایی بالا فراهم کنید و از اسکریپتهای SQL ارائه شده برای ایجاد جدول products_core_table با ستونهای برداری برای جاسازی تصاویر استفاده کنید.
- راهاندازی MongoDB Atlas : یک کلاستر روی Google Cloud مستقر کنید تا ویژگیهای سیال محصول را در product_details ذخیره کند و جریانهای کلیک بلادرنگ را در user_interactions ثبت کند.
- BigQuery Analytics : یک مجموعه داده برای جمعآوری گزارشهای تعامل ایجاد میکند و امکان پرسوجوهای تحلیلی پیچیده را فراهم میکند که «۵ مورد برتر» را در میلیونها رویداد شناسایی میکنند.
- مخزن ذخیرهسازی ابری : یک مخزن عمومی برای نگهداری تصاویر محصول با وضوح بالا ایجاد کنید و اطمینان حاصل کنید که هر دارایی از طریق یک URL امضا شده یا عمومی برای رابط کاربری قابل دسترسی است.
- استقرار جعبه ابزار MCP : جعبه ابزار را در Cloud Run مستقر کنید و آن را به عنوان پل مرکزی RESTful که قصد زبان طبیعی را به پرسوجوهای چند پایگاه دادهای ترجمه میکند، قرار دهید.
- پیکربندی Tools.yaml : «ابزارهای» خود را تعریف کنید - مانند get_product_core_data یا get_top_5_views - که عملیات خاص SQL و NoSQL را به نامهای ساده و قابل خواندن برای عامل نگاشت میکنند.
- منطق Backend فلاسک : مسیرهای app.py را پیادهسازی کنید که با جعبه ابزار MCP در ارتباط هستند، هماهنگی بازیابی دادهها را مدیریت میکنند و به عنوان API برای رابط کاربری عمل میکنند.
- هماهنگسازی چندعاملی : عاملهای ADK را در کد پیکربندی کنید تا از طریق قصد کاربر استدلال کنند و "ابزار" مناسب را برای حل پرسوجوهای پیچیده و چندمنبعی خردهفروشی انتخاب کنید.
- یکپارچهسازی فرانتاند : یک رابط کاربری index.html بسازید که شامل کاتالوگ محصولات با قابلیت ثبت تعاملات، تب Analytics برای درک تحلیل عملکرد محصول و یک "تب Agent" اختصاصی باشد که از چت چند-عاملی ADK برای ارائه یک تجربه خرید مکالمهای یکپارچه استفاده میکند.
حالا بیایید هماهنگی و استقرارها را پیادهسازی کنیم.
۸. راهاندازی جعبه ابزار MCP و استقرار در Cloud Run
جعبه ابزار MCP منابع داده چندگانه ما را خلاصه میکند و به برنامه ما اجازه میدهد دادهها را به طور یکنواخت دریافت و بنویسد.
جعبه ابزار MCP را به صورت محلی نصب کنید
- در Cloud Shell خود، به پوشه
toolbox-implementationبروید:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - فایل باینری MCP Toolbox را دانلود کنید و آن را قابل اجرا کنید:
export VERSION=0.29.0 curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox chmod +x toolbox
پیکربندی tools.yaml
شما باید انتزاعها را برای AlloyDB، MongoDB و BigQuery تعریف کنید. فایل tools.yaml به جعبه ابزار MCP میگوید که چگونه با یکدیگر تعامل داشته باشند.
- فایل
tools.yamlرا با استفاده از ویرایشگر تعبیهشده ایجاد و ویرایش کنید:cloudshell edit tools.yamltools.yamlرا میتوانید در مخزن گیتهاب پیدا کنید. محتویات آن را در فایل جدیدtools.yamlخود کپی کنید. - میزبان، کاربر، رمزهای عبور، شناسههای پروژه و رشتههای اتصال را بهروزرسانی کنید تا با زیرساختی که در مراحل قبلی فراهم کردهاید، مطابقت داشته باشند:
پایگاه داده
میدان
مقدار مثال
AlloyDB/BigQuery
project_idYOUR_PROJECT_IDآلیاژ دیبی
regionus-central1آلیاژ دیبی
clusterecommerce-clusterآلیاژ دیبی
instanceecommerce-cluster-primaryآلیاژ دیبی
databasepostgresآلیاژ دیبی
passwordalloydbمونگو دیبی
connection_stringmongodb+srv://store-user:storeuser@ecommerce-cluster.urcxr6q.mongodb.net
اعطای نقش به حساب سرویس Compute برای MCP Toolbox
ما به حساب سرویس Compute که برای Toolbox ما استفاده میشود، نقشهایی اعطا میکنیم. این کار برای فعال کردن MCP Toolbox برای دسترسی به AlloyDB انجام میشود.
- به IAM و admin بروید.
- روی اعطای دسترسی کلیک کنید.
- در فیلد New principals ، حساب کاربری پیشفرض سرویس Compute با نام
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.comرا وارد کنید.YOUR_PROJECT_NUMBERرا با شماره پروژه Google Cloud خود جایگزین کنید. - روی انتخاب نقش کلیک کنید.
- نقش BigQuery Data Editor را پیدا کرده و انتخاب کنید.
- روی افزودن یک نقش دیگر کلیک کنید و نقش AlloyDB Client را انتخاب کنید.
- روی «افزودن یک نقش دیگر» کلیک کنید و نقش «مصرفکنندهی استفاده از خدمات» را انتخاب کنید.
- روی «افزودن یک نقش دیگر» کلیک کنید و نقش «نمایشگر شیء ذخیرهسازی» را انتخاب کنید.
- روی ذخیره کلیک کنید.
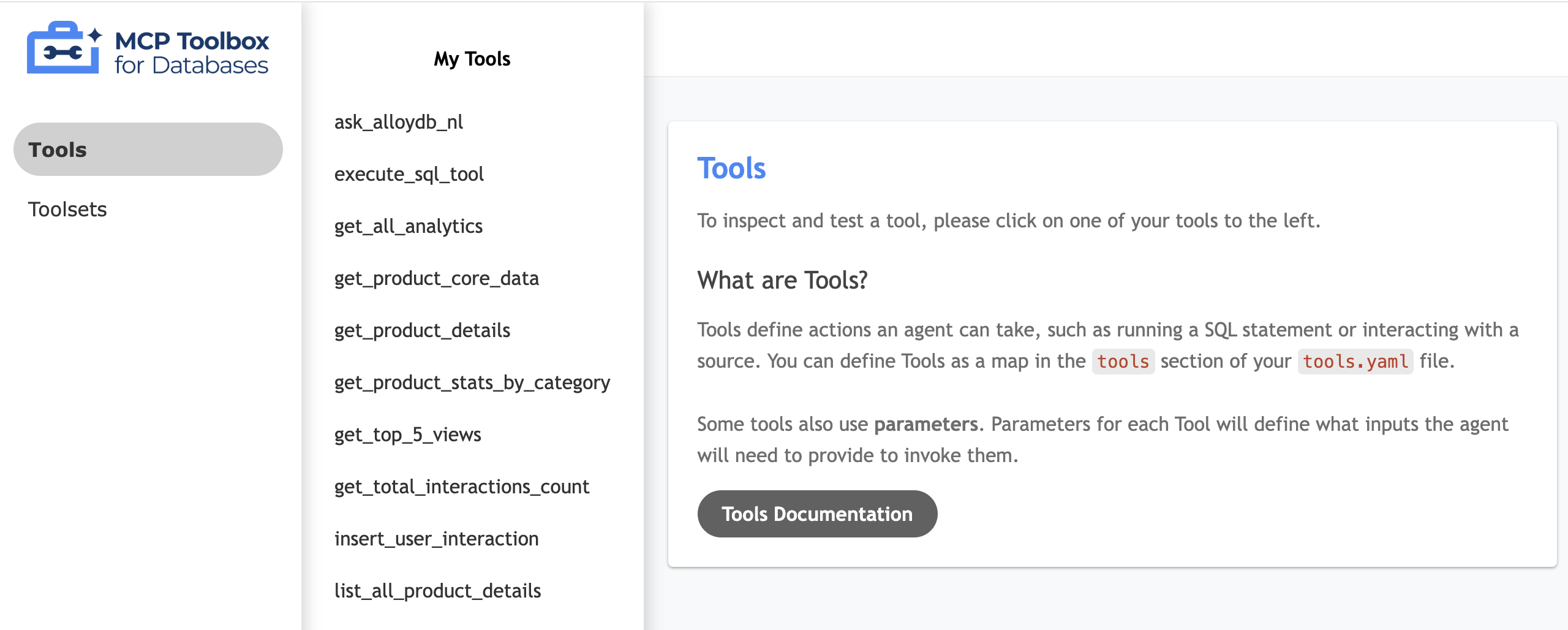
رابط کاربری ابزار خود را آزمایش کنید
- در ترمینال cloudshell خود، جعبه ابزار را به صورت محلی اجرا کنید تا رابط کاربری را ارائه دهد:
./toolbox --ui - پیشنمایش وب را در Cloud Shell روی پورت ۵۰۰۰ باز کنید و به صفحه ابزارها بروید. برای مثال، بسته به URL جلسه خود، میتوانید آن را در آدرس زیر مشاهده کنید:
https://5000-cs-71152278760-default.cs-asia-southeast1-cash.cloudshell.dev/ui
رابط کاربری جعبه ابزار MCP زیر دیده میشود:
استقرار در Cloud Run
جعبه ابزار MCP را در Cloud Run مستقر کنید تا به عنوان یک سرویس امن و مدیریتشده در دسترس قرار گیرد که برنامه ما بتواند از آن برای پرسوجو از پایگاههای داده استفاده کند. ما پیکربندی را در Secret Manager ذخیره خواهیم کرد تا از جزئیات حساس اتصال محافظت شود.
- یک جلسه جدید Cloud Shell باز کنید.
- به پوشه
toolbox-implementationبروید:cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - فایل پیکربندی
tools.yamlرا در Google Secret Manager آپلود کنید:gcloud secrets create tools --data-file=tools.yamlgcloud secrets versions add tools --data-file=tools.yaml - با استفاده از تصویر کانتینر عمومی MCP Toolbox مستقر کنید:
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:0.29.0 export PROJECT_ID=$(gcloud config get-value project) gcloud run deploy toolbox \ --image $IMAGE \ --region us-central1 \ --service-account $(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")-compute@developer.gserviceaccount.com \ --set-secrets "/app/tools.yaml=tools:latest" \ --args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080","--ui" \ --allow-unauthenticated - پس از استقرار، آدرس اینترنتی سرویس Cloud Run ارائه شده را یادداشت کنید. این آدرس باید چیزی شبیه به
https://toolbox-*********-uc.a.run.app/uiباشد.
۹. اپلیکیشن تجارت الکترونیک را راهاندازی کنید و روی Cloud Run مستقر کنید
با اجرای پایگاههای داده و پیادهسازی انتزاع جعبه ابزار MCP، میتوانیم برنامه وب Flask را اجرا کنیم!
برای ارائه کاتالوگ محصولات، برنامه Flask با انجام مراحل زیر دادهها را پردازش میکند:
- واکشی دادههای اصلی : لیست کامل محصولات را از AlloyDB (
list_products_core) بازیابی میکند. - دریافت جزئیات توسعهیافته : تمام جزئیات محصول را از MongoDB (
list_all_product_details) بازیابی میکند. - ترکیب لیستها : دو لیست را به هم متصل میکند.
- غنیسازی با رسانهها : آدرس اینترنتی تصویر فضای ذخیرهسازی ابری را به هر مورد اضافه میکند.
مسیر برنامه موتور استدلال را تولید کنید
برای مقداردهی اولیه و ثبت یک عامل هوش مصنوعی با استفاده از موتور استدلال هوش مصنوعی Vertex گوگل کلود، دستور زیر را اجرا کنید:
- در ترمینال cloudshell خود، به پوشه
BRK2-149-multidb-ecommerceبروید.cd next-26-sessions/BRK2-149-multidb-ecommerce - برای نصب وابستگیها، فایل requirements.txt را اجرا کنید.
pip install -r requirements.txt - اسکریپت
agentengine.pyرا اجرا کنید تا مسیر برنامه موتور استدلال ایجاد شود:python agentengine.py
خروجی مشابه زیر خواهد بود:
projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856
پیکربندی متغیرهای محیطی
- یک فایل
.envایجاد کنید و آن را ویرایش کنید:cloudshell edit .env - مقادیر را با اتصالات پایگاه داده خاص خود و URL جدید Cloud Run Toolbox خود جایگزین کنید:
# 1. MongoDB Connection String MONGODB_CONNECTION_STRING="mongodb+srv://<db_user>:<db_password>@cluster0.mongodb.net" # 2. MCP Toolbox Server Location # Must match the address where you run the toolbox server MCP_TOOLBOX_SERVER_URL="https://toolbox-*********-uc.a.run.app" # 3. Google Cloud Storage Bucket Name GCS_PRODUCT_BUCKET="ecommerce-app-images" # 4. Fallback image URL FALLBACK_IMAGE_URL="https://storage.googleapis.com/ecommerce-media-bold-circuit-492711-n9/fallback.jpg" # 5. Google Gen AI Vertex AI flag GOOGLE_GENAI_USE_VERTEXAI=TRUE # 6. Project ID PROJECT_ID=codelab-project-491117 # 7. Google Cloud Location of AlloyDB, BigQuery databases GOOGLE_CLOUD_LOCATION=us-central1 # 8. Reasoning engine application path APP_NAME=projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856 # 9. Model ID MODEL=gemini-1.5-flash-lite
استقرار Frontend روی Cloud Run
- برای تکمیل معماری، برنامه وب را در Cloud Run مستقر کنید:
gcloud run deploy polyglot --source . --platform managed \ --region us-central1 \ --allow-unauthenticated \ --set-env-vars \ MONGODB_CONNECTION_STRING="<MONGODB_CONNECTION_STRING>", \ MCP_TOOLBOX_SERVER_URL="<MCP_TOOLBOX_SERVER_URL>", \ GCS_PRODUCT_BUCKET="<GCS_PRODUCT_BUCKET>", \ FALLBACK_IMAGE_URL="<FALLBACK_IMAGE_URL>", \ GOOGLE_GENAI_USE_VERTEXAI=TRUE, \ PROJECT_ID="YOUR_PROJECT_ID", \ GOOGLE_CLOUD_LOCATION=us-central1, \ APP_NAME="<YOUR_REASONING_ENGINE_APP_PATH>", \ MODEL="gemini-1.5-flash-lite"-
YOUR_PROJECT_ID: شناسه پروژه گوگل کلود شما. -
YOUR_REASONING_ENGINE_APP_PATH: خروجی حاصل از اجرایpython agentengine.py، برای مثال،projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856. -
MCP_TOOLBOX_SERVER_URL: آدرس اینترنتی سرور MCP Toolbox شما، برای مثالhttps://toolbox-*********-uc.a.run.app. -
GCS_PRODUCT_BUCKET: نام باکت فضای ذخیرهسازی ابری گوگل شما، برای مثالecommerce-app-images. -
MONGODB_CONNECTION_STRING: رشته اتصال برای پایگاه داده MongoDB شما، برای مثالmongodb+srv://store-user:storeuser@ecommerce-cluster.g8vaekh.mongodb.net -
FALLBACK_IMAGE_URL: آدرس تصویر جایگزین، برای مثالhttps://storage.googleapis.com/ecommerce-app-images/fallback.jpg
-
برنامه شما اکنون فعال است! برای مشاهده کاتالوگ Multidb Ecommerce، آدرس اینترنتی (URL) سرویس ارائه شده توسط Cloud Run را باز کنید. این آدرس اینترنتی مشابه https://polyglot-*********-uc.a.run.app/ خواهد بود.
۱۰. اپلیکیشن را بررسی کنید
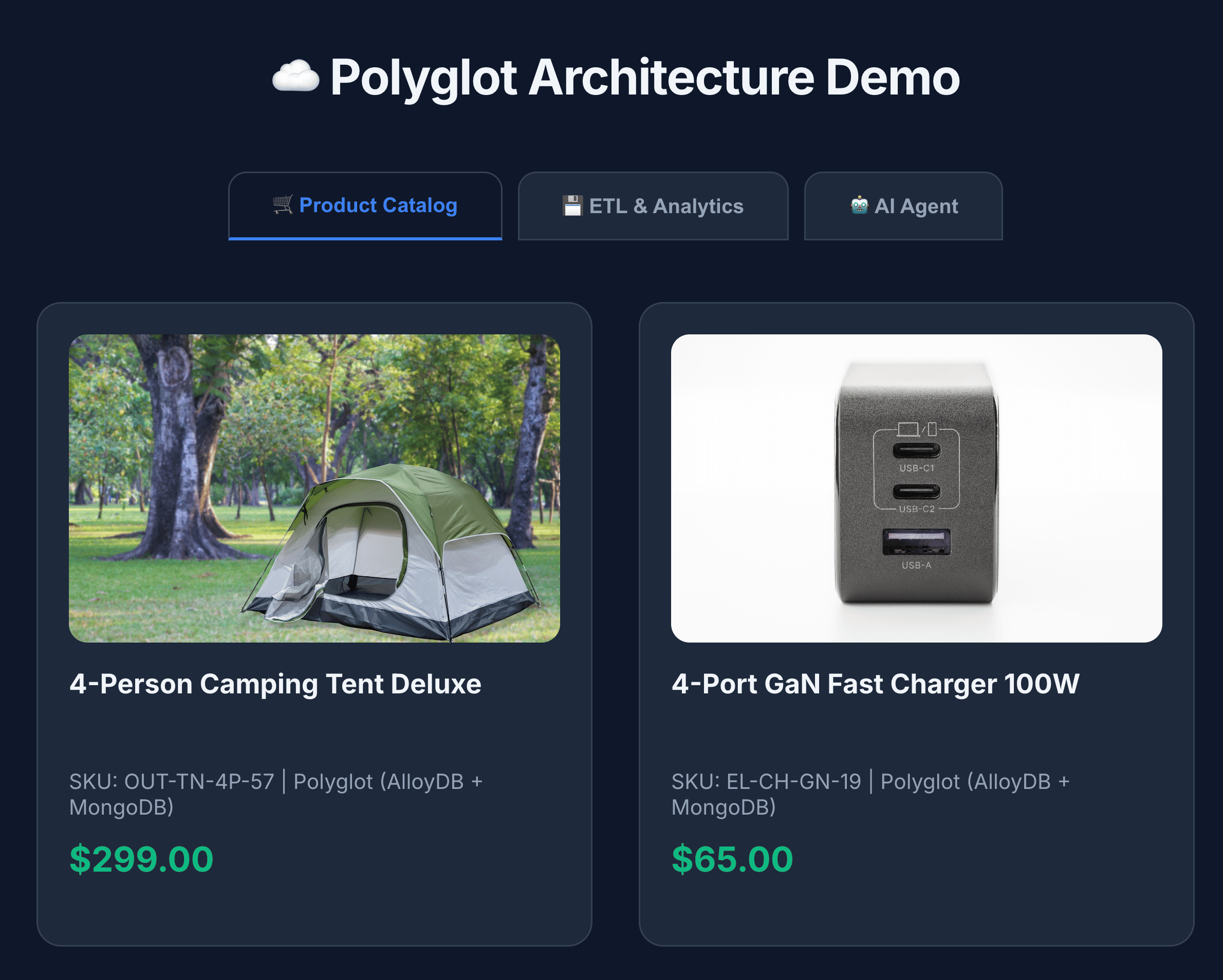
- برای مشاهده همه محصولات، روی کاتالوگ محصولات کلیک کنید.
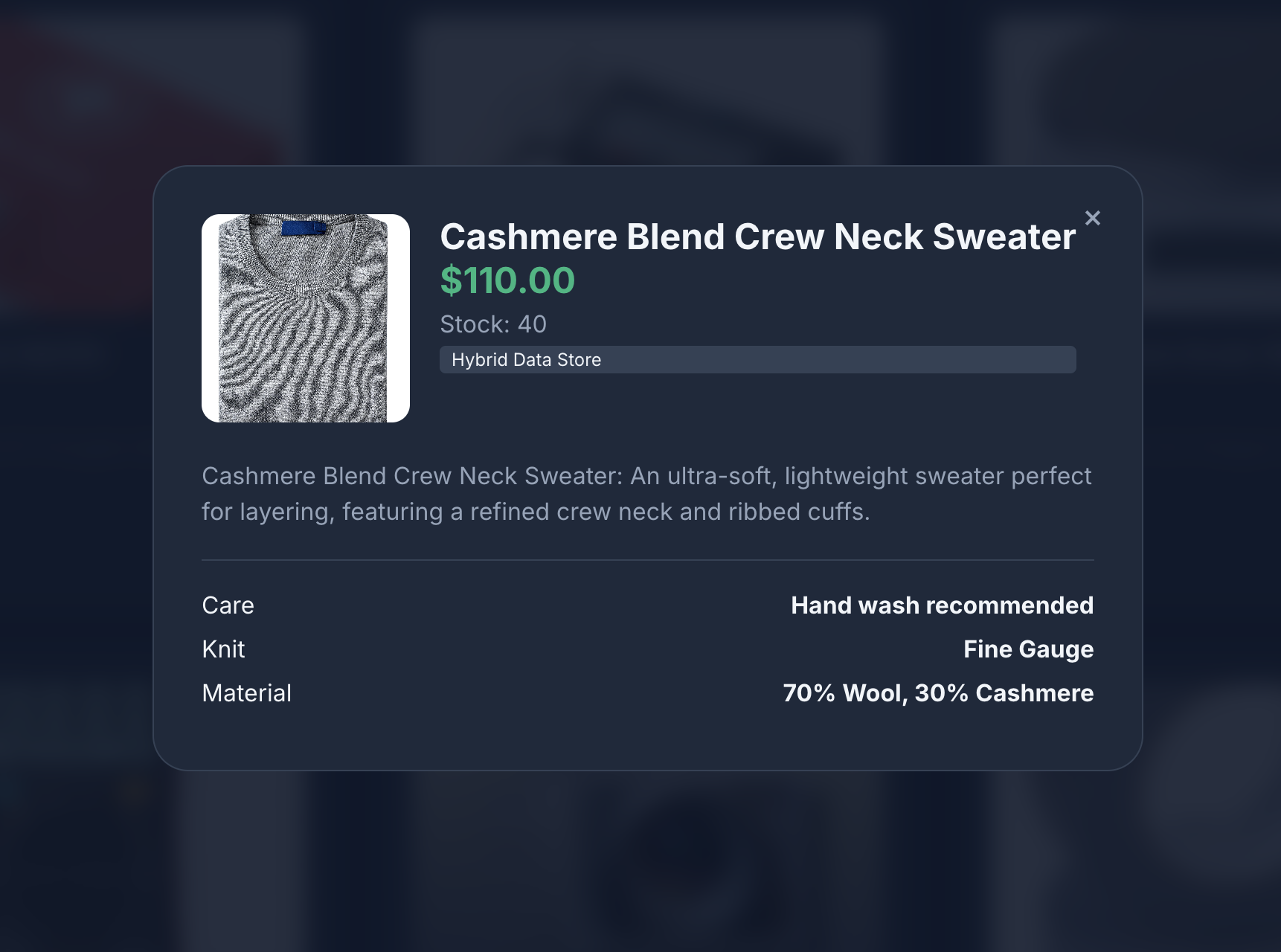
- برای مشاهده جزئیات محصول، روی آیکون محصول کلیک کنید. متوجه خواهید شد که تصاویر از Cloud Storage، جزئیات محصول از MongoDB و موجودی محصول از AlloyDB گرفته شدهاند.
- با کاتالوگ محصول تعامل داشته باشید تا نماها و نوشتههای آزمایشی ایجاد کرده و به MongoDB ارسال کنید.
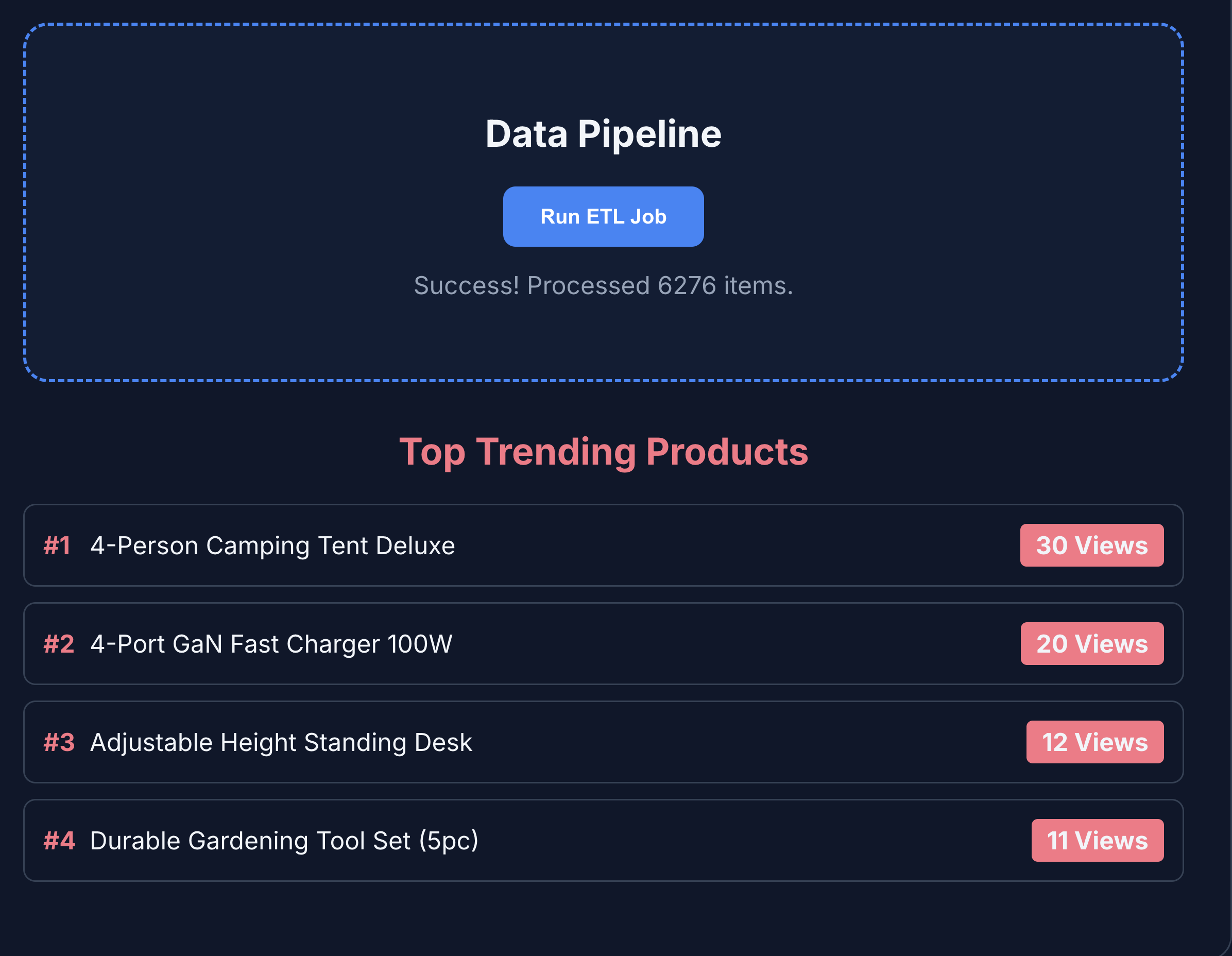
- برای مشاهده تحلیل محصول، روی ETL & Analytics کلیک کنید. متوجه خواهید شد که تحلیل محصول از BigQuery گرفته شده است.
- برای تعامل با عامل هوش مصنوعی، روی برگه عامل هوش مصنوعی کلیک کنید. سوالات زبان طبیعی مانند موارد زیر را بپرسید:
I'm planning a high-altitude photography trip. Show me some weather-resistant backpacks similar in style to aero glow pro but without any leather components. Also, let me know if they are actually in stock and if other photographers have complained about the strap durability in the reviews.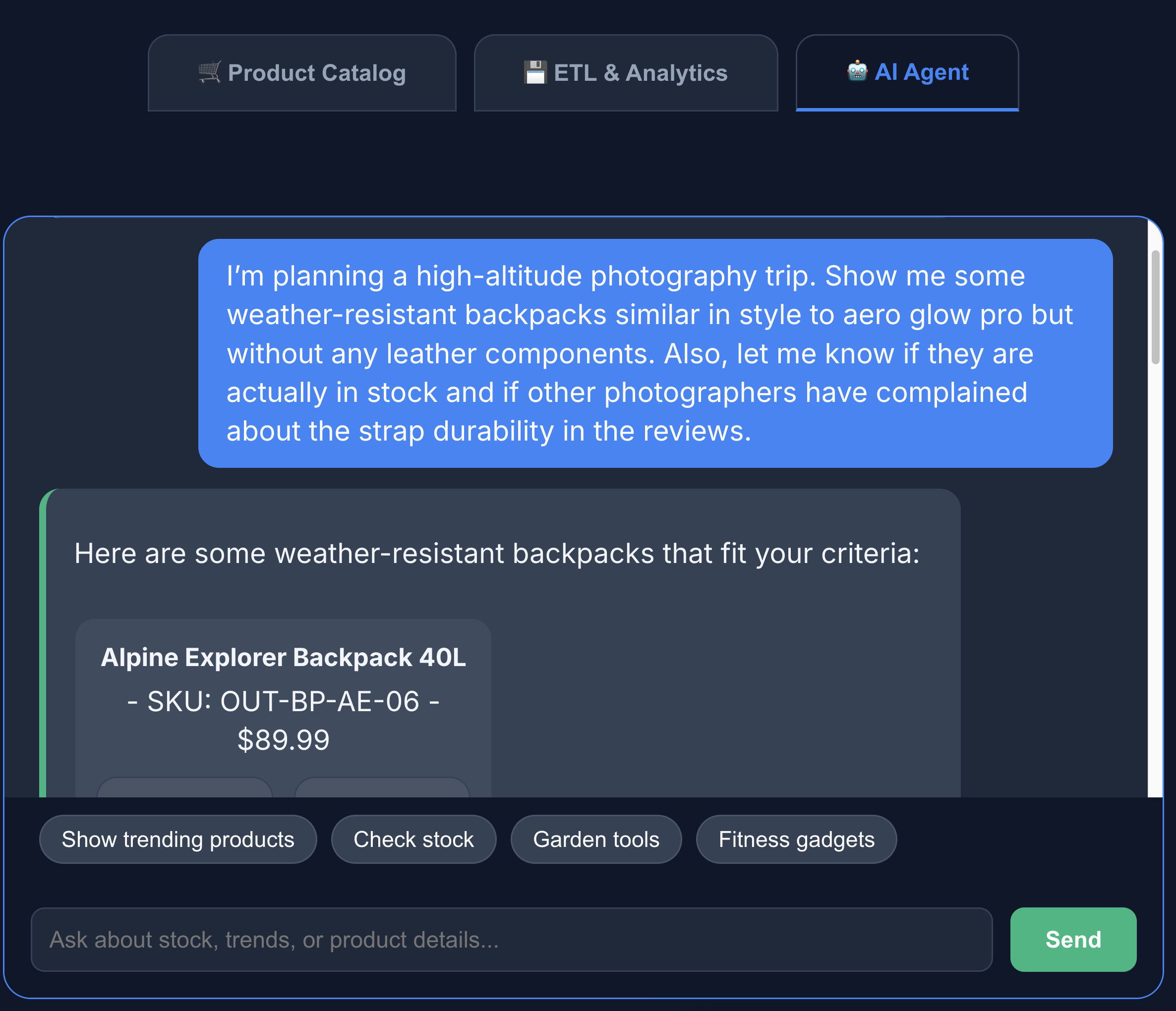
میبینید که جستجو دقیقاً همان چیزی را که ما درخواست کرده بودیم، نشان میدهد - یک کوله پشتی بدون اجزای چرمی، موجود در انبار و بدون هیچ شکایتی در مورد دوام بند در بررسیها.
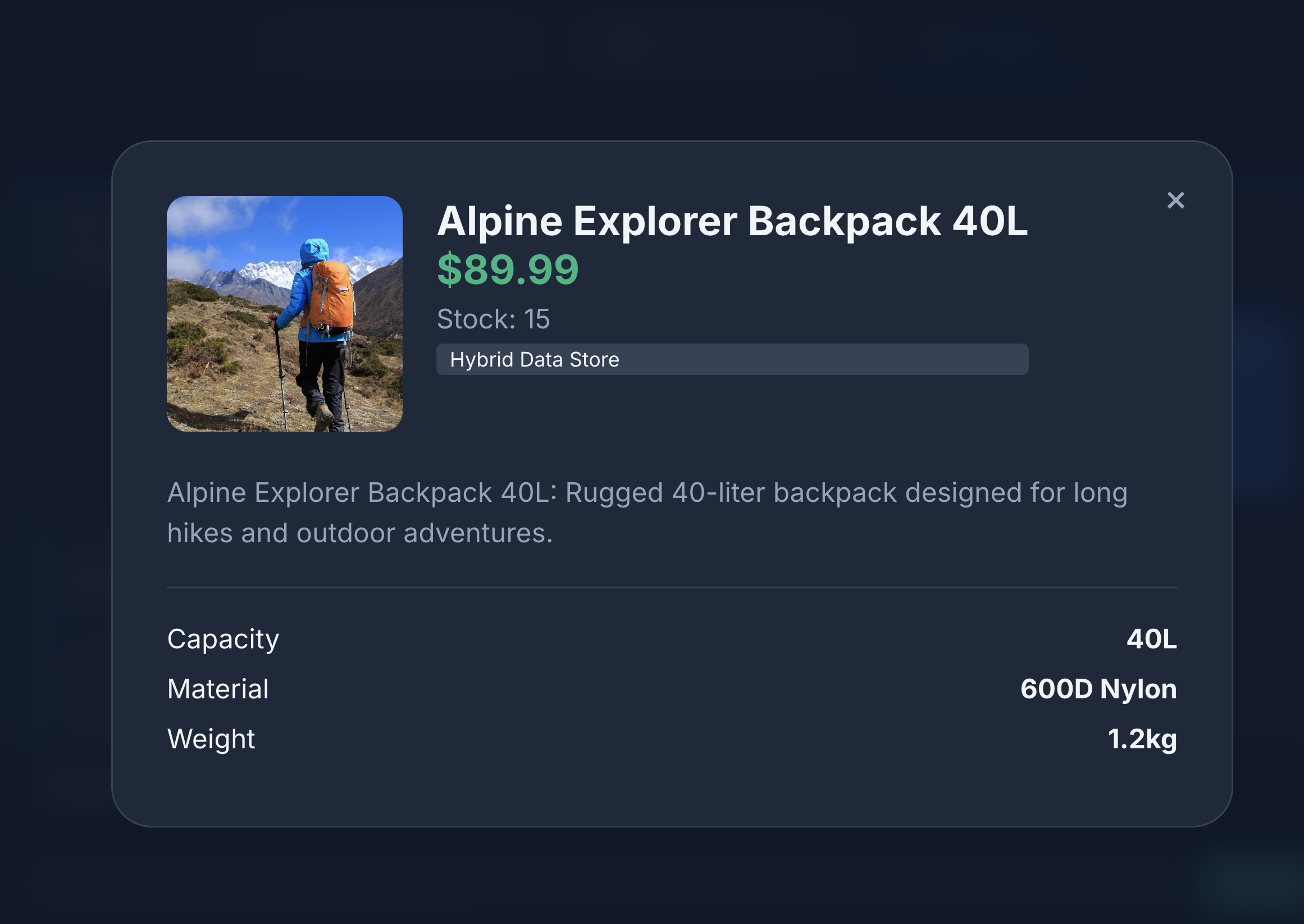
۱۱. تمیز کردن
برای جلوگیری از هزینههای مداوم برای حساب Google Cloud خود، منابع ایجاد شده در طول این codelab را حذف کنید.
این دستورات پوسته ابری را اجرا کنید:
gcloud run services delete toolbox --region us-central1 --quiet
gcloud run services delete multi-db-app --region us-central1 --quiet
bq rm -r -f -d $PROJECT_ID:ecommerce_analytics
gcloud storage rm --recursive gs://ecommerce-app-images
gcloud alloydb clusters delete ecommerce-cluster --region us-central1 --force --quiet
در صورت تمایل، برای حذف کل پروژه Google Cloud و تمام منابع آن، دستور زیر را اجرا کنید:
gcloud projects delete $PROJECT_ID
۱۲. تبریک
تبریک میگویم! شما با موفقیت یک معماری چنددیتابی بین ابری ساختید.
شما نشان دادید که چگونه جعبه ابزار MCP به عنوان چسب معماری برای یک برنامه مدرن و تخصصی عمل میکند. با تطبیق پایگاه داده مناسب با کار مناسب، به موارد زیر دست یافتید:
- نوشتن دادههای انعطافپذیر : MongoDB برای گزارشهای رویداد.
- ثبات تراکنشی : AlloyDB برای یکپارچگی هسته.
- تجزیه و تحلیل با عملکرد بالا : BigQuery برای هوش تجاری
- توسعه یکپارچه : یک بکاند پایتون واحد که تمام پیچیدگیها را با استفاده از جعبه ابزار MCP خلاصه میکند.
اسناد مرجع
درباره محصولات مرتبط با Google Cloud بیشتر بدانید و این آزمایشگاههای کد را بررسی کنید:
- AlloyDB AI: شروع کار با جاسازیهای برداری با AlloyDB AI
- هوش مصنوعی AlloyDB: جاسازیهای چندوجهی در AlloyDB
- جعبه ابزار MCP: نصب و راهاندازی جعبه ابزار MCP برای پایگاههای داده روی AlloyDB
برای اطلاعات بیشتر در مورد محصولات مورد استفاده در این آزمایشگاه کد، به موارد زیر مراجعه کنید: