
1. はじめに
現代の小売業では、データは多様で広大なエコシステムです。確実なトランザクション データ(価格と在庫)、「複雑な」ポリモーフィック カタログ(電子機器の仕様とアパレルのサイズ)、ペタバイト単位の行動ログがあります。これらを単一のモノリスに強制的に統合すると、技術的負債が発生するだけでなく、ユーザー エクスペリエンスも損なわれます。
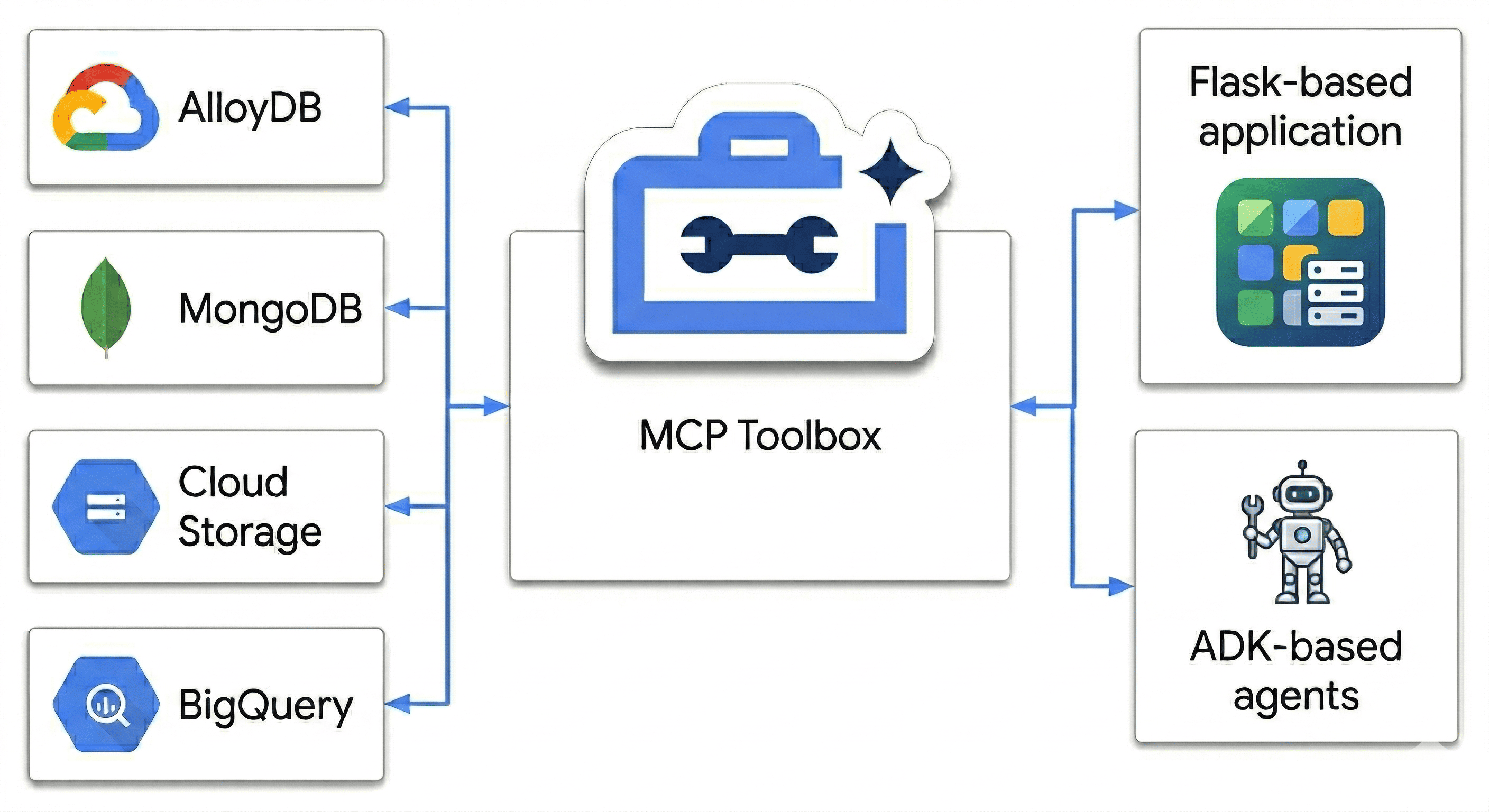
この Codelab では、次のものを調和させる Polyglot Powerhouse を設計します。
- AlloyDB: 高速な整合性と画像エンベディングを実現するトランザクション バックボーン。
- Google Cloud 上の MongoDB Atlas: 柔軟なスキーマレス カタログ レイヤ。
- Cloud Storage: リアルタイムのトレンド予測を行う分析脳。
- BigQuery: 高解像度のデジタル ウェアハウス。
その「秘伝のソース」とは何でしょうか?データベース向け MCP ツールボックスを使用して、Cloud Run で実行されているデータソースをセマンティック ブリッジとしてインテリジェントにオーケストレートして統合し、Agent Development Kit(ADK)を使用してマルチエージェント チャットアプリをデプロイします。検索バーを構築するだけでなく、コンテキストを理解し、制約を尊重し、生データと人間の意図のギャップを埋めるインテリジェントな小売業の頭脳を構築します。
不可能なユーザー クエリ
標準的な e コマース エージェントは、多次元推論(否定的な制約、視覚的な類似性、リアルタイムの在庫の組み合わせ)に失敗します。たとえば、通常は次のような小売サイトとやり取りしたいとします。
「高地での写真撮影旅行を計画しているんだけど、「AeroGlow Pro」と似たスタイルで、革製の部品が使われていない耐水性のバックパックをいくつか見せて。また、実際に在庫があるかどうか、他の写真家がレビューでストラップの耐久性について不満を述べているかどうかについても教えてください。」
このクエリが「エージェント キラー」である理由:
- ビジュアル類似性(AlloyDB + ベクトル検索): 「AeroGlow Pro と同じようなスタイル」では、画像エンベディングの比較が必要です。
- 否定制約(MongoDB): 「革を使用していない」という制約では、通常は標準 SQL スキーマに含まれない柔軟なネストされた属性でフィルタリングする必要があります。
- リアルタイム在庫(AlloyDB): 「実際に在庫がある」ことを確認するには、ライブ トランザクション チェック(古い検索インデックスではない)が必要です。
- セマンティック合成(BigQuery + マルチエージェント): 「ストラップの耐久性」に関するレビューを分析するには、エージェントが BigQuery からの非構造化フィードバックをその場で要約する必要があります。
ほとんどの小売業者のボットは「バックパック」と「レザー」だけを認識し、10 個のレザー バックパックを表示します。どのようにしてそれを防いでいるのか?
キーワードを照合するだけではないからです。MCP ツールボックスを使用して、エージェントが AlloyDB のトランザクションの真実と MongoDB の柔軟な属性を同時に推論できるようにしています。構築してみましょう。
演習内容
- コア商品データ用の AlloyDB クラスタをプロビジョニングする
- 半構造化された商品情報を保存するように Google Cloud 上の MongoDB Atlas を構成する
- 商品画像を提供する Cloud Storage バケットを作成する
- 均一なデータ アクセスを実現するために、データベース向け MCP ツールボックスを Cloud Run にデプロイする
- ETL プロセスを実行して、分析用に BigQuery にデータを push する
- AI エージェントと自然言語で会話します。
前提条件
- ウェブブラウザ(Chrome など)
- 課金を有効にした Google Cloud プロジェクト
- Google Cloud での MongoDB Atlas の無料アカウント
2. 始める前に
Google Cloud プロジェクトの作成
- Google Cloud コンソールのプロジェクト セレクタ ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Cloud Shell の起動
Cloud Shell は、必要なツールがプリロードされた Google Cloud で動作するコマンドライン環境です。
- Google Cloud コンソールの上部にある [Cloud Shell をアクティブにする] をクリックします。
- Cloud Shell に接続したら、認証を確認します。
gcloud auth list - プロジェクトが構成されていることを確認します。
gcloud config get project - プロジェクトが想定どおりに設定されていない場合は、設定します。
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
必要な API の有効化
次のコマンドを実行して、必要な API をすべて有効にします。
gcloud services enable \
alloydb.googleapis.com \
bigquery.googleapis.com \
storage.googleapis.com \
run.googleapis.com \
cloudbuild.googleapis.com \
artifactregistry.googleapis.com \
iam.googleapis.com \
secretmanager.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com \
aiplatform.googleapis.com
3. Cloud Storage を設定する
Cloud Storage は、商品画像などの非構造化メディア アセットの大規模なストアとして機能します。
- Google Cloud コンソールで、[Cloud Storage] に移動し、[バケットを作成] をクリックします。
- バケットにグローバルに一意の名前(
ecommerce-app-imagesなど)を付けます。 - [作成] をクリックします。
- デモ アプリケーションが認証なしで画像にアクセスできるようにするには、[このバケットに対する公開アクセス禁止を適用する] オプションをオフにして、[確認] をクリックします。
- [権限] タブに移動します。
- [権限] で、[アクセス権を付与] をクリックします。
- [新しいプリンシパル] に「
allUsers」と入力します。 - [ロールを選択] で、[Cloud Storage] > [Storage オブジェクト ユーザー] を選択します。
- [保存] をクリックし、[一般公開アクセスを許可] をクリックして、リソースを一般公開にすることを確認します。
プレースホルダ画像をアップロードする
BRK2-149-multidb-ecommerce では、最適な視覚的エクスペリエンスを実現するためにプレースホルダ画像を使用しています。
- Cloud Shell で、
next-26-sessionsリポジトリのクローンを作成します。git clone https://github.com/GoogleCloudPlatform/next-26-sessions.git UploadImagesフォルダに移動します。cd next-26-sessions/BRK2-149-multidb-ecommerce/UploadImages- Google Cloud コンソールで、[Cloud Storage] に移動し、[バケット] をクリックします。
- 新しく作成したバケットの名前をクリックします。
- [アップロード] > [ファイルをアップロード] をクリックし、ダウンロードしたサンプル画像を選択して、[開く] をクリックします。
4. AlloyDB を設定する
AlloyDB は、商品 ID、名前、SKU、価格、在庫などの構造化されたトランザクション データや重要なデータに関する信頼できる唯一の情報源として機能します。AlloyDB は、おすすめと自然言語クエリの類似性検索機能を備えた AI エージェントも強化します。
AlloyDB クラスタをプロビジョニングする
- Google Cloud コンソールで、AlloyDB for PostgreSQL に移動します。
- [クラスタを作成] をクリックします。
- [クラスタ ID] に「
ecommerce-cluster」と入力します。 postgresユーザーに安全なパスワードを設定します。学習目的でalloydbを使用できます。- [データベース バージョン] はデフォルトのままにします。
- [リージョン] で、
us-central1(または使用するリージョン)を選択します。
プライマリ インスタンスを構成する
- [インスタンス ID] に「
ecommerce-cluster-primary」と入力します。 - [ゾーンの可用性] で、[シングルゾーン] を選択します。
- [マシンタイプ] で、小規模なマシンタイプ(N2、4 vCPU、32 GB RAM など)を選択します。
- [プライベート IP 接続] で、[プライベート サービス アクセス(PSA)] を選択し、
defaultネットワークを選択します。デフォルトのネットワークがまだ設定されていない場合は、[ネットワーク設定を確認] をクリックして作成します。 - [パブリック IP 接続] で、この Codelab で MCP ツールボックスが正しく接続されるように、[パブリック IP を有効にする] チェックボックスをオンにします。
- [承認済み外部ネットワーク] に
0.0.0.0/0を入力します。[リスクを理解しました] チェックボックスをオンにして、[保存] をクリックします。 - [クラスタを作成] をクリックします。
注: パブリック IP アドレス(34.124.240.26 のような形式)をメモしておきます。
データベースを初期化する
- 左側のナビゲーション メニューで [AlloyDB Studio] をクリックします。
- [データベース] プルダウンで、[
postgres] を選択します。 - [組み込み認証] を選択してデータベースにログインします。
- [ユーザー名] には、
postgresユーザーを使用します。 - [パスワード] に、先ほど設定したパスワードを入力します。
- [認証] をクリックします。
- エディタビューで、新しい [無題のクエリ] タブを開きます。
- 次の DDL をコピーして、[実行] をクリックします。
CREATE TABLE products_core_table ( product_id UUID PRIMARY KEY, name VARCHAR(255) NOT NULL, sku VARCHAR(50) UNIQUE NOT NULL, price NUMERIC(10, 2) NOT NULL, stock INT NOT NULL ); - Cloud Shell で、
BRK2-149-multidb-ecommerceフォルダに移動します。cd next-26-sessions/BRK2-149-multidb-ecommerce - Cloud Shell で
alloydb_insert_queries.sqlファイルを開き、挿入クエリをコピーします。cat alloydb_insert_queries.sql - 新しい [無題のクエリ] タブで、
INSERTステートメントのみを貼り付けて [実行] をクリックします。 - 新しい無題のクエリタブで、次の DDL をコピーして [実行] をクリックし、
products_core_tableテーブルにインデックスを作成します。CREATE INDEX idx_products_core_sku ON products_core_table(sku);
AI エージェントが類似商品を検索するための画像エンベディングを作成する
AI エージェントの統合では、画像エンベディングを使用して類似商品をフェッチします。エンベディングは multimodalembedding@001 モデルを使用して生成され、AlloyDB データベースに保存されます。エンベディングは 1,408 次元のベクトルで、img_embeddings 列に保存されます。
エンベディングを生成する前に、Cloud Storage にアクセスするために必要なロールを AlloyDB サービス アカウントに付与する必要があります。
Cloud Storage にアクセスする AlloyDB サービス アカウントにロールを付与する
AlloyDB サービス アカウントに Storage オブジェクト ユーザーと Storage オブジェクト閲覧者のロールを付与して、Cloud Storage バケットからオブジェクトを読み取れるようにします。
- [IAM と管理] に移動します。
- [アクセス権を付与] をクリックします。
- [新しいプリンシパル] フィールドに、AlloyDB サービス アカウントの検索を入力します。サービス アカウントは
service-991742412753@gcp-sa-alloydb.iam.gserviceaccount.comのようになります。 - [ロールを選択] をクリックします。
- [Storage オブジェクト ユーザー] ロールを見つけて選択します。
- [別のロールを追加] をクリックし、[ストレージ オブジェクト閲覧者] のロールを選択します。
- [別のロールを追加] をクリックし、[Vertex AI ユーザー] ロールを選択します。
- [保存] をクリックします。
拡張機能を有効にする
このアプリのビルドには、拡張機能 pgvector と google_ml_integration を使用します。pgvector 拡張機能を使用すると、ベクトル エンベディングを保存して検索できます。google_ml_integration 拡張機能は、Vertex AI 予測エンドポイントにアクセスして SQL で予測を取得するために使用する関数を提供します。次の DDL を実行して、これらの拡張機能を有効にします。
- Google Cloud コンソールで、AlloyDB for PostgreSQL に移動します。
- 左側のナビゲーション メニューで [AlloyDB Studio] をクリックします。
- エディタビューで、新しい [無題のクエリ] タブを開きます。
- 次の DDL をコピーして、[実行] をクリックします。
CREATE EXTENSION IF NOT EXISTS vector; CREATE EXTENSION IF NOT EXISTS google_ml_integration;
エンベディングを使用してデータベースを初期化する
- img_embeddings 列を
products_core_tableに追加します。ALTER TABLE products_core_table ADD COLUMN img_embeddings vector(1408); - 画像のエンベディングを生成し、
img_embeddings列に保存します。UPDATE products_core_table SET img_embeddings = google_ml.image_embedding( model_id => 'multimodalembedding@001', image => 'gs://<STORAGE_BUCKET_NAME>/' || sku || '.jpg', mimetype => 'image/jpeg') WHERE sku IN ( SELECT sku FROM products_core_table WHERE img_embeddings IS NULL AND sku IS NOT NULL LIMIT 10 ); - Studio には 5 分間の制限があるため、前のクエリを少なくとも 5 回繰り返して、セット全体の画像エンベディングを生成します。このクエリがタイムアウトした場合は、
LIMITを5に変更して、クエリを 10 回再実行します。このステップが完了するまでに数分かかることがあります。
5. Google Cloud で MongoDB Atlas を設定する
MongoDB は、リッチな半構造化された商品の詳細と、クリックやビューなどの柔軟なユーザー行動データを保存します。
MongoDB クラスタを作成する
- Google Cloud での MongoDB Atlas に移動し、無料枠のアカウントを選択します。
- [無料] クラスタ階層を選択し、クラスタの名前(例:
ecommerce-cluster)を入力します。 - プロバイダとして [Google Cloud] を選択し、リージョンが Google Cloud リージョン(
us-central1など)と一致していることを確認します。 - [デプロイメントの作成] をクリックします。
- [閉じる] をクリックします。
ネットワーク アクセスを構成する
- Atlas コンソールで、[Database & Network Access] に移動します。
- [IP アクセスリスト] をクリックします。
- [IP アドレスを追加] をクリックします。
0.0.0.0/0を追加します。これにより、どこからでもアクセスできるようになります。- [確認] をクリックします。
データベース ユーザーを作成する
- Atlas コンソールで、[Database & Network Access] に移動します。
- [データベース ユーザー] をクリックします。
- [新しいデータベース ユーザーを追加] をクリックします。
- 認証方法として [パスワード] を選択します。
- ユーザー名に
store-user、パスワードにstoreuserを入力します。 - [Add Built In Role] をクリックし、[Read and write to any database] を選択します。
- [ユーザーを追加] をクリックします。
接続文字列を取得する
- [Database] > [Clusters] > [Connect] に移動します。
- [アプリケーションに接続する] で、[ドライバ] をクリックします。
- [アプリケーション コードに接続文字列を追加する] に表示されている接続文字列をコピーします。文字列は次のようになります。
mongodb+srv://store-user:<db_password>@ecommerce-cluster.g8vaekh.mongodb.net/?appName=ecommerce-clusterdb_passwordは、MongoDB のパスワードに置き換えます。この Codelab では、storeuserです。
この接続文字列を保存します。これは、後で MONGODB_CONNECTION_STRING 環境変数に使用します。
データベースとコレクションを作成する
- Atlas コンソールで、[Database] > [Clusters] > [Browse Collections] に移動します。
- [データベースを作成] をクリックして、次の詳細を入力します。
- データベース名:
ecommerce_db - コレクション名:
product_details_collection
- データベース名:
- [データベースを作成] をクリックします。
- データ エクスプローラで、コレクション名を選択します。
- [データを追加(+)] アイコンをクリックし、[ドキュメントを挿入] をクリックします。
- product_details_export.json から JSON コンテンツをコピーして、[ドキュメントを挿入] エディタ ダイアログに貼り付けます。
- [挿入] をクリックしてドキュメントの配列を挿入し、192 個のドキュメントが追加されたことを確認します。
- データ エクスプローラで、
ecommerce_dbデータベースの横にある [コレクションを作成(+)] をクリックします。 - コレクション名に「
user_interactions_collection」と入力し、[コレクションを作成] をクリックします。 - データ エクスプローラで、
user_interactions_collectionコレクションを選択します。 - [データを追加(+)] アイコンをクリックし、[ドキュメントを挿入] をクリックします。
- user_interactions_export.json から JSON コンテンツをコピーし、[ドキュメントを挿入] エディタ ダイアログに貼り付けます。
- [ドキュメントを挿入] をクリックします。
6. BigQuery を設定する
BigQuery は、過去のユーザー行動を集計して分析し、インテリジェントなレポートとレコメンデーションを生成します。
データセットの作成
- Google Cloud コンソールで [BigQuery] に移動します。
- [エクスプローラ] ペインで、プロジェクト ID の横にあるその他アイコンをクリックし、[データセットを作成] を選択します。
- [データセット ID] に「
ecommerce_analytics」と入力します。 - [データセットを作成] をクリックします。
分析テーブルを作成する
- BigQuery ワークスペースで新しいクエリを開きます。
- 次の SQL ステートメントを実行して、ユーザーと商品インタラクションをリンクする概要テーブルを作成します。
CREATE TABLE ecommerce_analytics.user_product_interactions (
user_id STRING DEFAULT 'any user',
product_id STRING,
interaction_score INT
);
MCP Toolbox の Compute サービス アカウントにロールを付与する
ツールボックスに使用される Compute サービス アカウントにロールを付与します。これは、MCP ツールボックスが BigQuery、Secret Manager、その他のクラウド サービスにアクセスできるようにするために行われます。
ロールを付与する手順は次のとおりです。
- [IAM と管理] に移動します。
- [アクセス権を付与] をクリックします。
- [新しいプリンシパル] フィールドに、
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.comという名前のデフォルトの Compute サービス アカウントを入力します。YOUR_PROJECT_NUMBERは、実際の Google Cloud プロジェクトの番号に置き換えます。 - [ロールを選択] をクリックします。
- [BigQuery データ編集者] ロールを見つけて選択します。
- [別のロールを追加] をクリックし、[BigQuery ジョブユーザー] ロールを選択します。
- [別のロールを追加] をクリックし、[Secret Manager のシークレット アクセサー] ロールを選択します。
- [別のロールを追加] をクリックし、[編集者] ロールを選択します。
- [保存] をクリックします。
7. アプリケーションのエンドツーエンドを理解する
各コンポーネントがどのように連携するかを理解するために、複数のデータベースとサービスを使用するシンプルな e コマース アプリケーションを作成します。このアプリケーションは Python(Flask)バックエンドで構築され、複数の Google Cloud サービスとデータベースを統合しています。
ディレクトリ構造を理解する
次のセクションでは、BRK2-149-multidb-ecommerce リポジトリのクローンを作成し、それを使用してアプリケーションをローカルで実行します。アプリケーションをローカルでテストしたら、MCP ツールボックスとアプリケーションの両方を Cloud Run にデプロイします。
このディレクトリでダウンロードしたファイルを確認します。次の上位ディレクトリが存在します。
UploadImages: 画像アセットを保存します。主に、e コマースの商品カタログのドキュメントやビジュアル コンテンツに使用されます。static: ユーザー インターフェースのスタイル設定とインタラクティブ機能の追加に使用される、CSS ファイルや JavaScript ファイルなどのアプリケーションの静的ウェブ アセットを保存します(ソース)。templates: Python アプリケーションが e コマース カタログのウェブページを動的にレンダリングするために使用する HTML テンプレート(Flask の場合は Jinja2)を保存します(ソース)。toolbox-implementation: Model Context Protocol(MCP)ツールボックスの構成と実装の詳細を保存し、事前定義されたツールを使用してマルチデータベースのデータベース操作を容易にします。
このリポジトリ内のファイルは連携して、マルチデータベースの e コマース アプリケーションをビルド、構成、デプロイします。app.py などの中央ファイルは、SQL ファイルと JSON ファイルで定義されたさまざまなデータソースを統合してバックエンドをオーケストレートします。構成ファイルは、クラウド環境へのシームレスなデプロイを保証します。
app.py: Flask バックエンドとマルチデータベースの統合をオーケストレートします。agentengine.py: Vertex AI エージェントの初期化と構成を行うコアロジック。.env: データベース接続とストレージ接続のシークレットを保存します。tools.yaml: multidb データベース オペレーション用に MCP ツールボックスを構成します。Dockerfile: コンテナ イメージと環境設定を定義します。requirements.txt: アプリケーションのランタイムに必要な Python ライブラリを一覧表示します。tools.yaml: MCP ツールボックスの構成。Procfile: デプロイの本番環境実行コマンドを指定します。alloydb_insert_queries.sql: リレーショナル データの SQL クエリが含まれます。product_details_export.jsonとuser_interactions_export.json: NoSQL データベースのサンプル JSON データを提供します。README.md: 設定、デプロイ、プロジェクトの理解をガイドします。
アプリケーションのエンドツーエンド フロー
- AlloyDB の設定: 高性能クラスタをプロビジョニングし、提供された SQL スクリプトを使用して、画像エンベディング用のベクトル列を含む products_core_table を作成します。
- MongoDB Atlas の設定: Google Cloud にクラスタをデプロイして、商品属性を product_details に保存し、リアルタイムのクリックストリームを user_interactions に記録します。
- BigQuery Analytics: データセットを作成してインタラクション ログを集計し、数百万件のイベントから「上位 5 件」のトレンド アイテムを特定する複雑な分析クエリを可能にします。
- Cloud Storage リポジトリ: 高解像度の商品画像を格納する公開バケットを作成し、各アセットにフロントエンド用の署名付き URL または公開 URL を介してアクセスできるようにします。
- MCP ツールボックスのデプロイ: ツールボックスを Cloud Run にデプロイし、自然言語の意図をマルチデータベース クエリに変換する中央の RESTful ブリッジとして確立します。
- Tools.yaml 構成: get_product_core_data や get_top_5_views などの「ツール」を定義し、特定の SQL オペレーションと NoSQL オペレーションをエージェントが読み取れる簡単な名前にマッピングします。
- Flask バックエンド ロジック: MCP ツールボックスと連携する app.py ルートを実装し、データ取得の調整を処理して、UI の API として機能します。
- マルチエージェント オーケストレーション: コード内で ADK エージェントを構成して、ユーザーの意図を推論し、複雑なマルチソースの小売クエリを解決するための適切な「ツール」を選択します。
- フロントエンドの統合: 商品カタログ、インタラクション記録機能、商品パフォーマンス分析を把握するための [分析] タブ、ADK マルチエージェント チャットを使用してシームレスな会話型ショッピング エクスペリエンスを提供する専用の [エージェント] タブを備えた index.html インターフェースを構築します。
次に、オーケストレーションとデプロイを実装します。
8. MCP ツールボックスを設定して Cloud Run にデプロイする
MCP ツールボックスは複数のデータソースを抽象化し、アプリケーションがデータを一様に取得して書き込めるようにします。
MCP ツールボックスをローカルにインストールする
- Cloud Shell で、
toolbox-implementationフォルダに移動します。cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementation - MCP ツールボックスのバイナリをダウンロードして実行可能にします。
export VERSION=0.29.0 curl -L -o toolbox https://storage.googleapis.com/genai-toolbox/v$VERSION/linux/amd64/toolbox chmod +x toolbox
tools.yaml を構成する
AlloyDB、MongoDB、BigQuery の抽象化を定義する必要があります。tools.yaml ファイルは、MCP ツールボックスが相互にやり取りする方法を指定します。
- 組み込みエディタを使用して
tools.yamlファイルを作成して編集します。cloudshell edit tools.yamltools.yamlファイルは、GitHub リポジトリで確認できます。その内容を新しいtools.yamlファイルにコピーします。 - ホスト、ユーザー、パスワード、プロジェクト ID、接続文字列を、前の手順でプロビジョニングしたインフラストラクチャと一致するように更新します。
データベース
フィールド
値の例
AlloyDB/BigQuery
project_idYOUR_PROJECT_IDAlloyDB
regionus-central1AlloyDB
clusterecommerce-clusterAlloyDB
instanceecommerce-cluster-primaryAlloyDB
databasepostgresAlloyDB
passwordalloydbMongoDB
connection_stringmongodb+srv://store-user:storeuser@ecommerce-cluster.urcxr6q.mongodb.net
MCP Toolbox の Compute サービス アカウントにロールを付与する
ツールボックスに使用される Compute サービス アカウントにロールを付与します。これは、MCP ツールボックスが AlloyDB にアクセスできるようにするために行われます。
- [IAM と管理] に移動します。
- [アクセス権を付与] をクリックします。
- [新しいプリンシパル] フィールドに、
YOUR_PROJECT_NUMBER-compute@developer.gserviceaccount.comという名前のデフォルトの Compute サービス アカウントを入力します。YOUR_PROJECT_NUMBERは、実際の Google Cloud プロジェクトの番号に置き換えます。 - [ロールを選択] をクリックします。
- [BigQuery データ編集者] ロールを見つけて選択します。
- [別のロールを追加] をクリックし、[AlloyDB クライアント] ロールを選択します。
- [別のロールを追加] をクリックし、[Service Usage コンシューマー] ロールを選択します。
- [別のロールを追加] をクリックし、[ストレージ オブジェクト閲覧者] のロールを選択します。
- [保存] をクリックします。
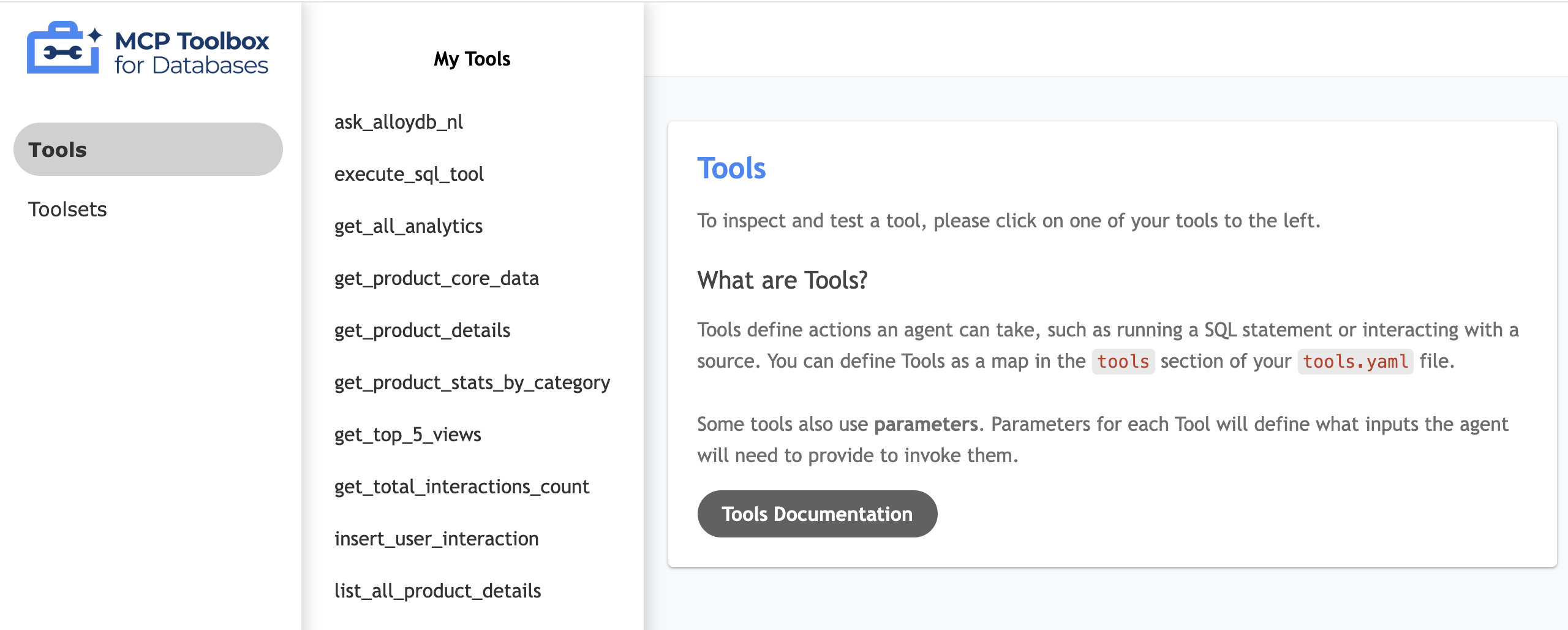
ツール UI をテストする
- Cloud Shell ターミナルで、ツールボックスをローカルで実行して UI を提供します。
./toolbox --ui - Cloud Shell でポート 5000 のウェブ プレビューを開き、ツールページに移動します。たとえば、セッション URL に応じて、
https://5000-cs-71152278760-default.cs-asia-southeast1-cash.cloudshell.dev/uiで確認できます。
次の MCP ツールボックス UI が表示されます。
Cloud Run へのデプロイ
MCP ツールボックスを Cloud Run にデプロイして、アプリケーションがデータベースのクエリに使用できる安全なマネージド サービスとして利用できるようにします。機密性の高い接続の詳細を保護するため、構成は Secret Manager に保存します。
- 新しい Cloud Shell セッションを開きます。
toolbox-implementationフォルダに移動します。cd next-26-sessions/BRK2-149-multidb-ecommerce/toolbox-implementationtools.yaml構成を Google Secret Manager にアップロードします。gcloud secrets create tools --data-file=tools.yamlgcloud secrets versions add tools --data-file=tools.yaml- 公開 MCP ツールボックス コンテナ イメージを使用してデプロイします。
export IMAGE=us-central1-docker.pkg.dev/database-toolbox/toolbox/toolbox:0.29.0 export PROJECT_ID=$(gcloud config get-value project) gcloud run deploy toolbox \ --image $IMAGE \ --region us-central1 \ --service-account $(gcloud projects describe $PROJECT_ID --format="value(projectNumber)")-compute@developer.gserviceaccount.com \ --set-secrets "/app/tools.yaml=tools:latest" \ --args="--tools-file=/app/tools.yaml","--address=0.0.0.0","--port=8080","--ui" \ --allow-unauthenticated - デプロイが完了したら、提供された Cloud Run サービス URL をメモします。
https://toolbox-*********-uc.a.run.app/uiのようになります。
9. e コマース アプリケーションを設定して Cloud Run にデプロイする
データベースが実行され、MCP ツールボックスの抽象化がデプロイされたので、Flask ウェブ アプリケーションを実行できます。
商品カタログを提供するために、Flask アプリケーションは次の手順でデータを処理します。
- コアデータを取得: AlloyDB(
list_products_core)から商品リスト全体を取得します。 - Fetch extended details: MongoDB(
list_all_product_details)からすべての商品詳細を取得します。 - リストの結合: 2 つのリストを連結します。
- メディアで拡充: Cloud Storage の画像 URL をすべての項目に追加します。
推論エンジン アプリケーションのパスを生成する
Google Cloud の Vertex AI Reasoning Engine を使用して AI エージェントを初期化して登録するには、次のコマンドを実行します。
- Cloud Shell ターミナルで、
BRK2-149-multidb-ecommerceフォルダに移動します。cd next-26-sessions/BRK2-149-multidb-ecommerce - requirements.txt を実行して依存関係をインストールする
pip install -r requirements.txt agentengine.pyスクリプトを実行して、推論エンジン アプリケーションのパスを生成します。python agentengine.py
出力は次のようになります。
projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856
環境変数を構成する
.envファイルを作成して編集します。cloudshell edit .env- 値を、特定のデータベース接続と新しい Cloud Run Toolbox の URL に置き換えます。
# 1. MongoDB Connection String MONGODB_CONNECTION_STRING="mongodb+srv://<db_user>:<db_password>@cluster0.mongodb.net" # 2. MCP Toolbox Server Location # Must match the address where you run the toolbox server MCP_TOOLBOX_SERVER_URL="https://toolbox-*********-uc.a.run.app" # 3. Google Cloud Storage Bucket Name GCS_PRODUCT_BUCKET="ecommerce-app-images" # 4. Fallback image URL FALLBACK_IMAGE_URL="https://storage.googleapis.com/ecommerce-media-bold-circuit-492711-n9/fallback.jpg" # 5. Google Gen AI Vertex AI flag GOOGLE_GENAI_USE_VERTEXAI=TRUE # 6. Project ID PROJECT_ID=codelab-project-491117 # 7. Google Cloud Location of AlloyDB, BigQuery databases GOOGLE_CLOUD_LOCATION=us-central1 # 8. Reasoning engine application path APP_NAME=projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856 # 9. Model ID MODEL=gemini-1.5-flash-lite
フロントエンドを Cloud Run にデプロイする
- ウェブ アプリケーションを Cloud Run にデプロイして、アーキテクチャを完成させます。
gcloud run deploy polyglot --source . --platform managed \ --region us-central1 \ --allow-unauthenticated \ --set-env-vars \ MONGODB_CONNECTION_STRING="<MONGODB_CONNECTION_STRING>", \ MCP_TOOLBOX_SERVER_URL="<MCP_TOOLBOX_SERVER_URL>", \ GCS_PRODUCT_BUCKET="<GCS_PRODUCT_BUCKET>", \ FALLBACK_IMAGE_URL="<FALLBACK_IMAGE_URL>", \ GOOGLE_GENAI_USE_VERTEXAI=TRUE, \ PROJECT_ID="YOUR_PROJECT_ID", \ GOOGLE_CLOUD_LOCATION=us-central1, \ APP_NAME="<YOUR_REASONING_ENGINE_APP_PATH>", \ MODEL="gemini-1.5-flash-lite"YOUR_PROJECT_ID: 実際の Google Cloud プロジェクト ID。YOUR_REASONING_ENGINE_APP_PATH:python agentengine.pyの実行結果(projects/991742412753/locations/us-central1/reasoningEngines/4933254136889081856など)。MCP_TOOLBOX_SERVER_URL: MCP ツールボックス サーバーの URL(例:https://toolbox-*********-uc.a.run.app)。GCS_PRODUCT_BUCKET: Google Cloud Storage バケットの名前(ecommerce-app-imagesなど)。MONGODB_CONNECTION_STRING: MongoDB データベースの接続文字列(例:mongodb+srv://store-user:storeuser@ecommerce-cluster.g8vaekh.mongodb.net)FALLBACK_IMAGE_URL: フォールバック画像の URL(https://storage.googleapis.com/ecommerce-app-images/fallback.jpgなど)
これで、アプリケーションが動作するようになりました。Cloud Run から提供されたサービス URL を開いて、Multidb Ecommerce カタログを表示します。URL は https://polyglot-*********-uc.a.run.app/ のようになります。
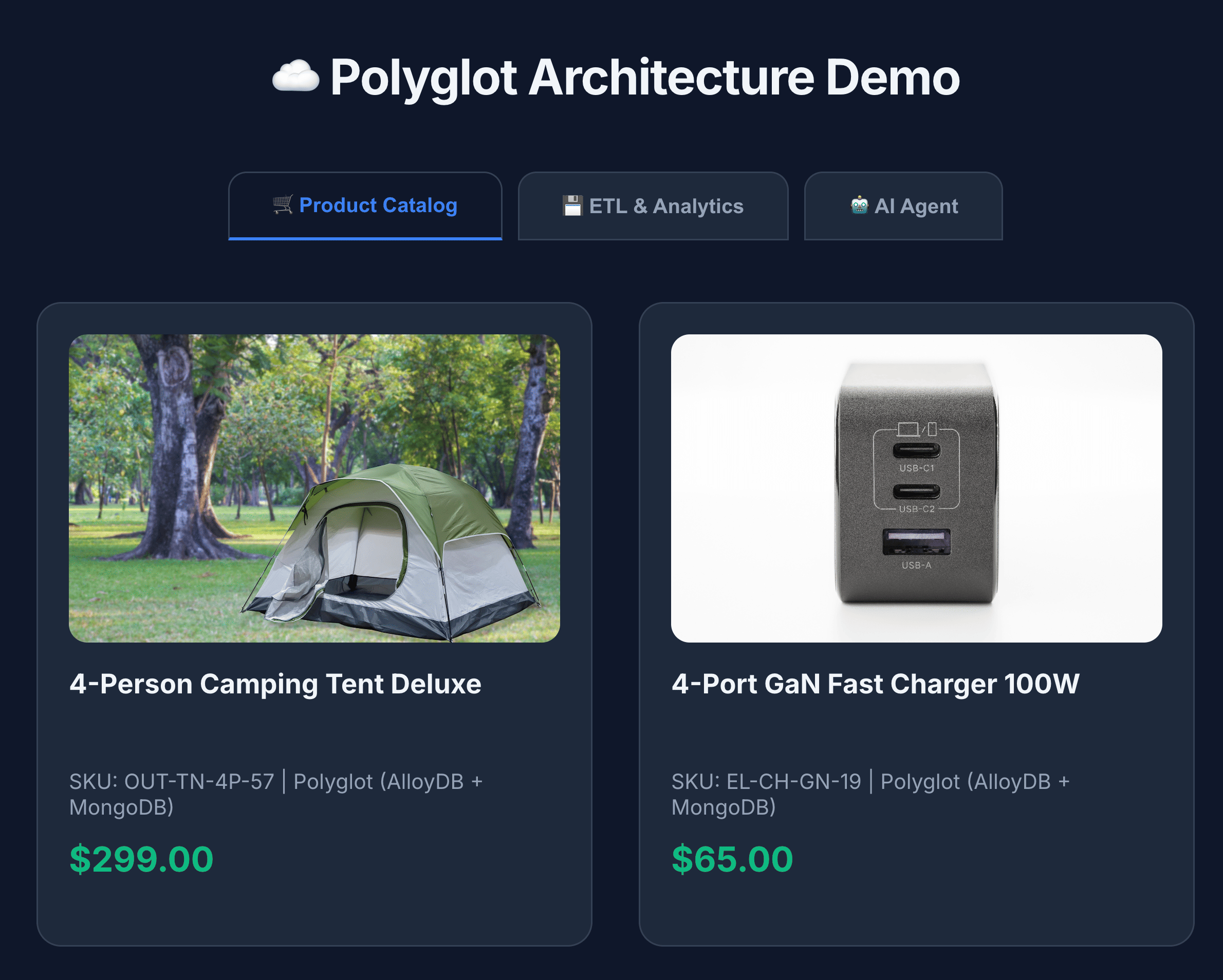
10. アプリケーションを探索する
- [商品カタログ] をクリックして、すべての商品を表示します。
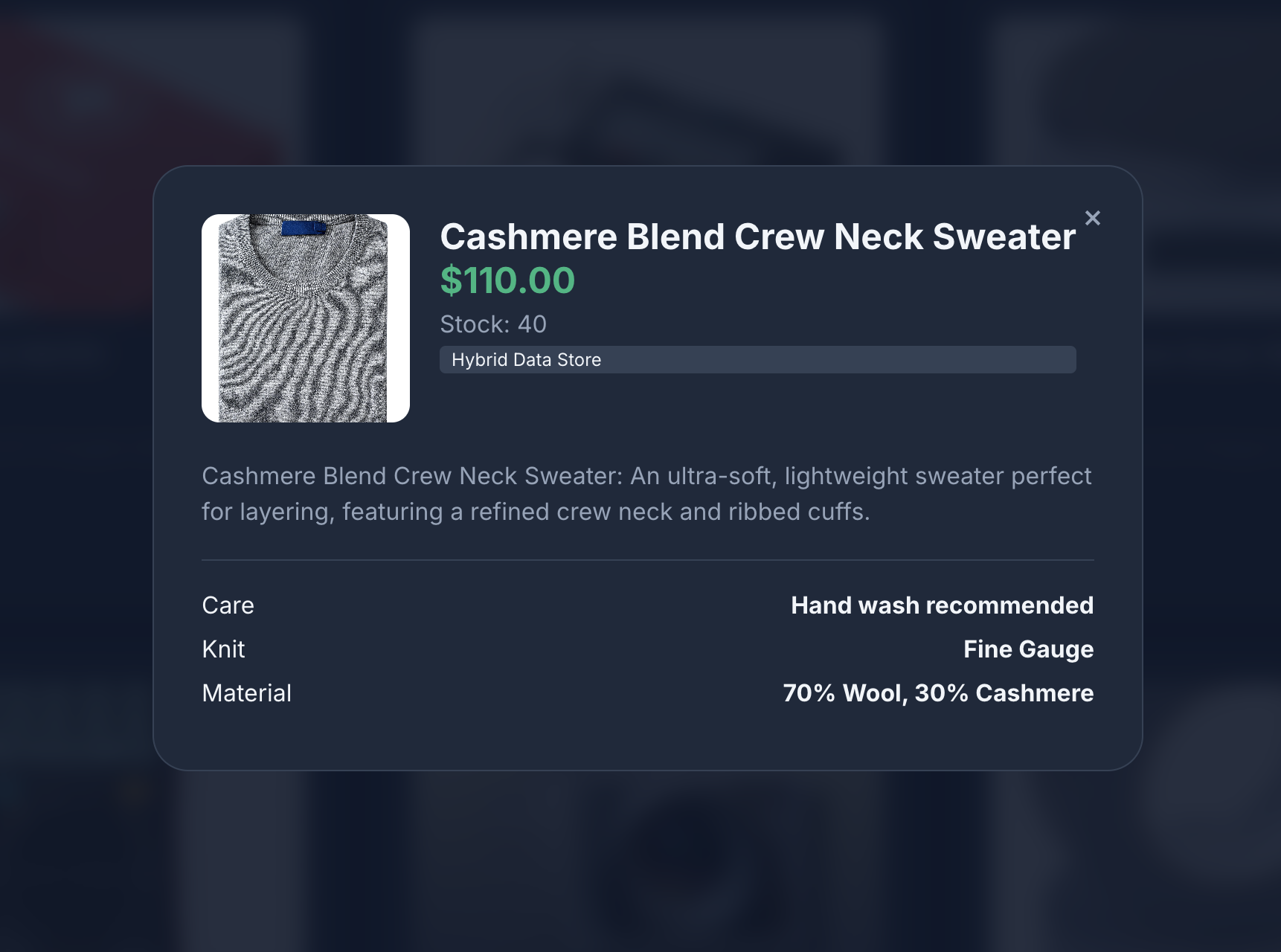
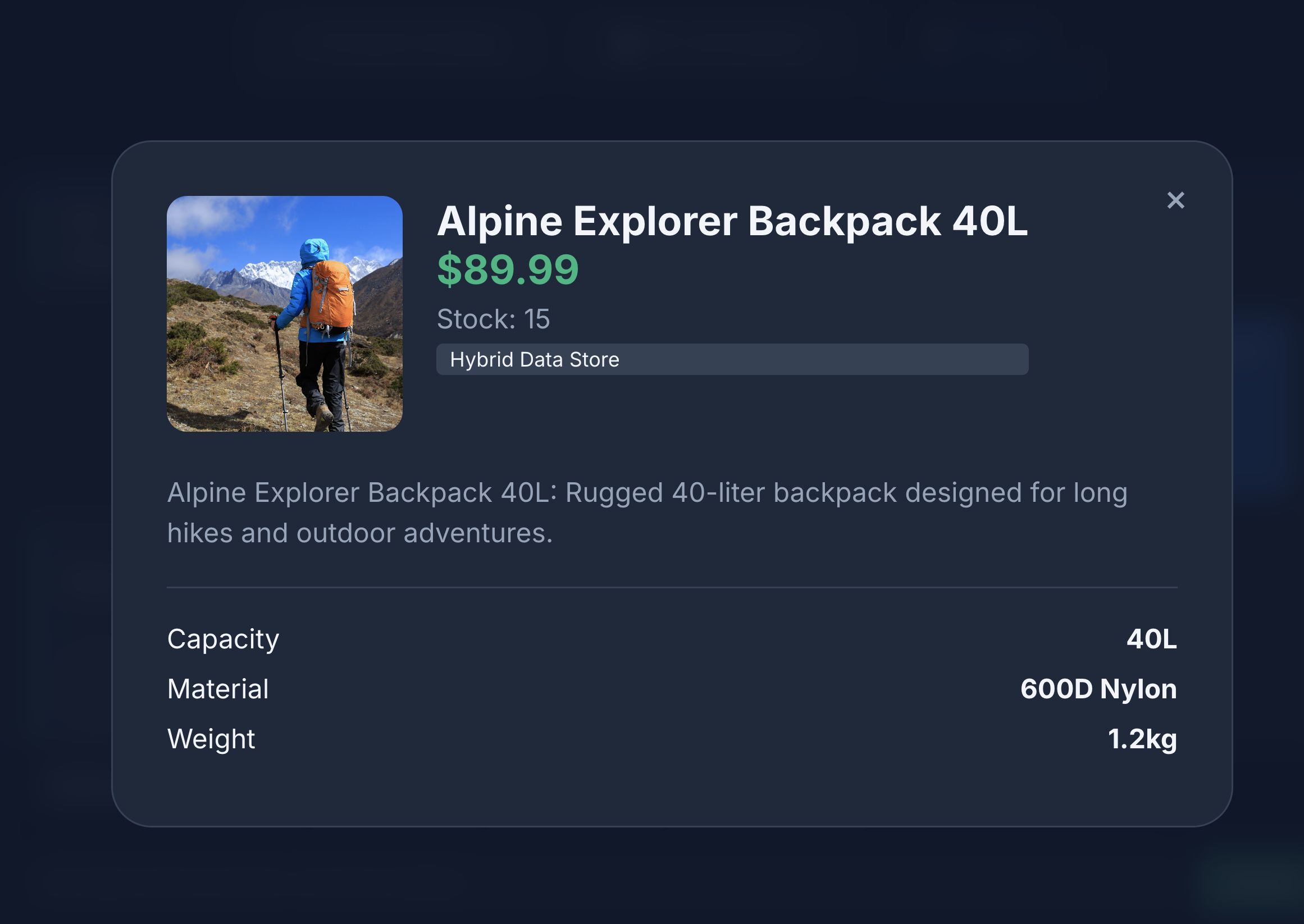
- 商品アイコンをクリックして商品の詳細を表示します。画像は Cloud Storage から取得され、商品の詳細は MongoDB から取得され、商品在庫は AlloyDB から取得されていることがわかります。
- 商品カタログを操作して、MongoDB に送信されるモックビューと書き込みを生成します。
- [ETL & Analytics] をクリックして、プロダクト分析を表示します。商品分析が BigQuery から取得されていることがわかります。
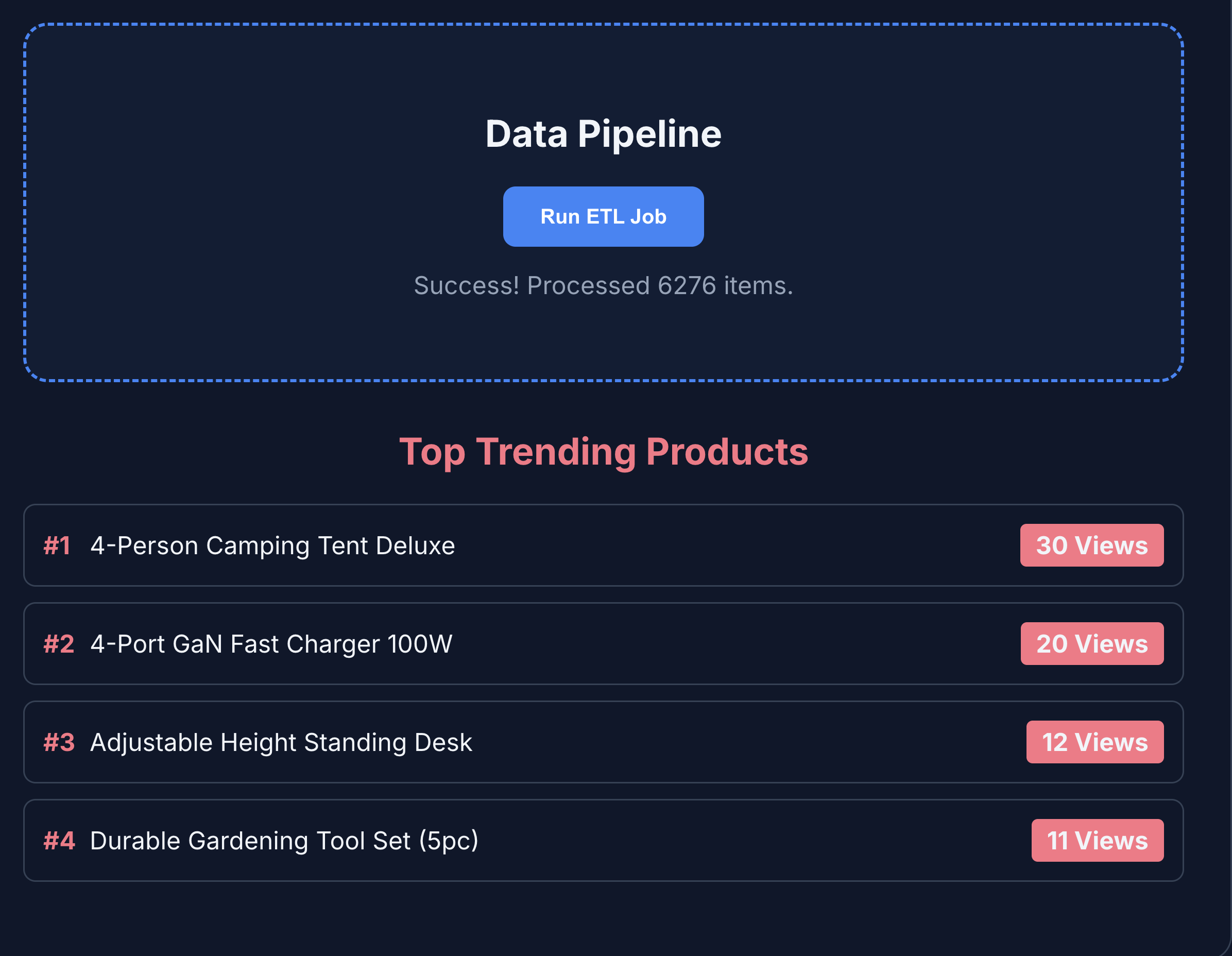
- [AI エージェント] タブをクリックして、AI エージェントとやり取りします。次のような自然言語の質問をします。
I'm planning a high-altitude photography trip. Show me some weather-resistant backpacks similar in style to aero glow pro but without any leather components. Also, let me know if they are actually in stock and if other photographers have complained about the strap durability in the reviews.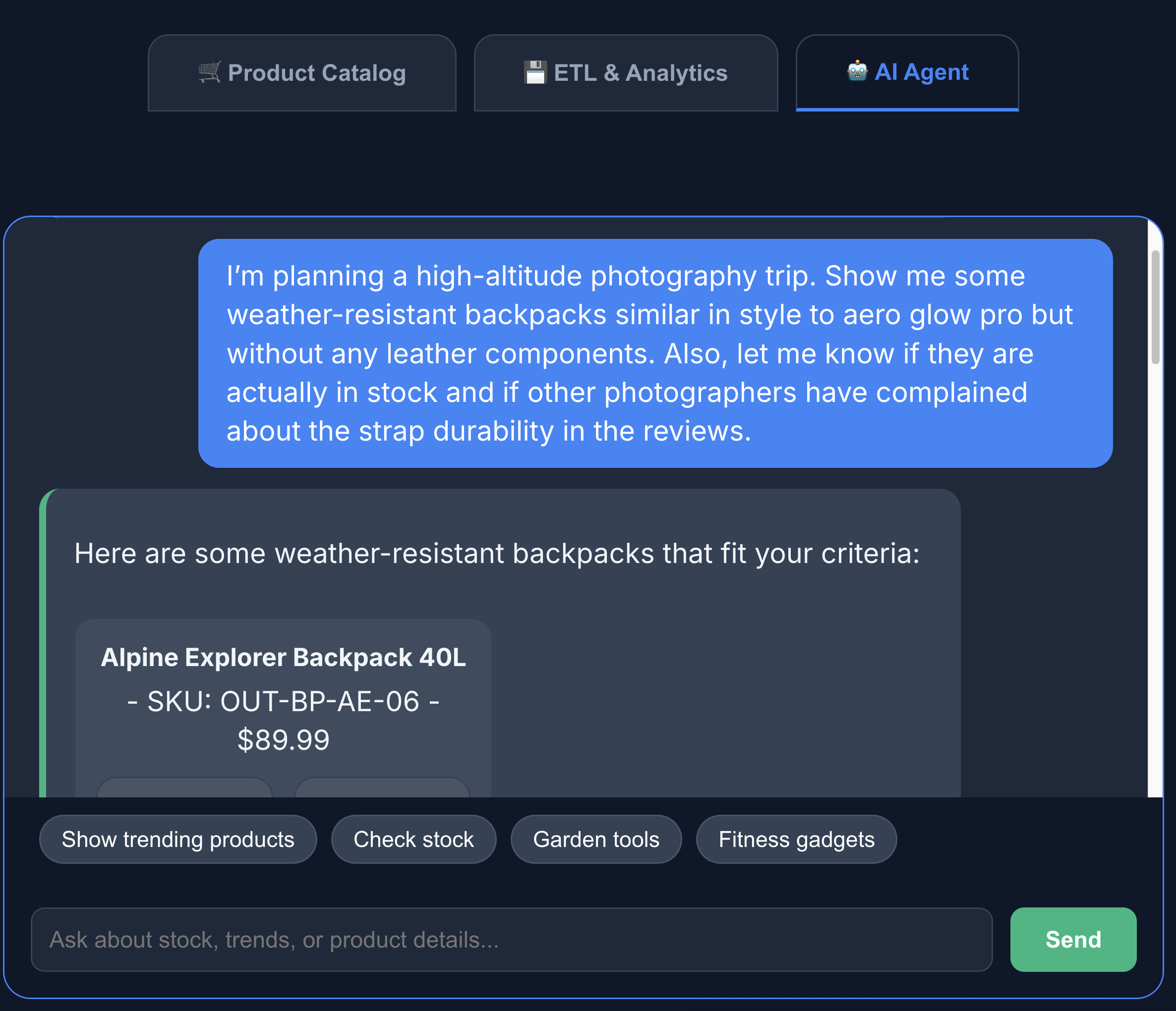
検索結果には、リクエストどおり、革製の部品がなく、在庫があり、レビューでストラップの耐久性について不満が寄せられていないバックパックが表示されています。
11. クリーンアップ
Google Cloud アカウントに継続的に課金されないようにするには、この Codelab で作成したリソースを削除します。
次の Cloud Shell コマンドを実行します。
gcloud run services delete toolbox --region us-central1 --quiet
gcloud run services delete multi-db-app --region us-central1 --quiet
bq rm -r -f -d $PROJECT_ID:ecommerce_analytics
gcloud storage rm --recursive gs://ecommerce-app-images
gcloud alloydb clusters delete ecommerce-cluster --region us-central1 --force --quiet
必要に応じて、Google Cloud プロジェクトとそのすべてのリソースを削除するには、次のコマンドを実行します。
gcloud projects delete $PROJECT_ID
12. 完了
おめでとうございます!クロスクラウド Multidb アーキテクチャを正常に構築しました。
MCP ツールボックスが最新の特殊なアプリケーションのアーキテクチャ上の接着剤として機能する方法を説明しました。適切なジョブに適切なデータベースを一致させることで、次のことが実現しました。
- 柔軟なデータ書き込み: イベントログ用の MongoDB。
- トランザクションの整合性: コアの整合性を確保する AlloyDB。
- 高性能分析: ビジネス インテリジェンス向けの BigQuery。
- 統合開発: MCP Toolbox を使用してすべての複雑さを抽象化する単一の Python バックエンド。
リファレンス ドキュメント
関連する Google Cloud プロダクトの詳細を確認し、次の Codelab をご覧ください。
- AlloyDB AI: AlloyDB AI でベクトル エンベディングを使ってみる
- AlloyDB AI: AlloyDB のマルチモーダル エンベディング
- MCP ツールボックス: AlloyDB でのデータベース向け MCP ツールボックスのインストールと設定
この Codelab で使用するプロダクトの詳細については、以下をご覧ください。