
1. مقدمة
في هذا الدرس التطبيقي حول الترميز، ستتعلّم كيفية إنشاء عرض Living Memory التوضيحي، وهو مساعد مستند إلى الذكاء الاصطناعي يتتبّع "ذكريات" محادثتك لتقديم تجربة مخصّصة.
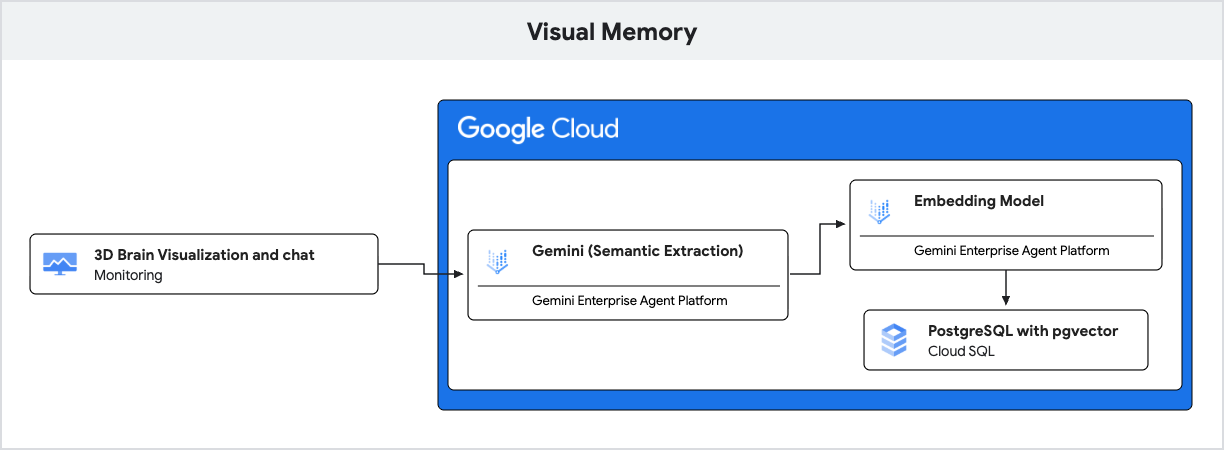
يستخدم التطبيق Gemini لفهم اللغة الطبيعية وCloud SQL for PostgreSQL مع إضافة pgvector لتخزين هذه الذكريات واسترجاعها استنادًا إلى التشابه الدلالي.
هذا الدرس التطبيقي حول الترميز مخصّص للمطوّرين من جميع مستويات المهارة المهتمين بالذكاء الاصطناعي وقواعد البيانات، ويستغرق إكماله حوالي 60 دقيقة. يجب أن تكون تكلفة الموارد التي تم إنشاؤها أقل من 5 دولارات أمريكية.
الإجراءات التي ستنفذّها
- كيفية إعداد مثيل PostgreSQL على Cloud SQL مع توفُّر
pgvector - كيفية استخدام Gemini لاستخراج "ذكريات" بشكل تفاعلي من رسائل المستخدمين
- كيفية إجراء عمليات بحث متّجهة في PostgreSQL لاسترداد السياق المناسب لردود الذكاء الاصطناعي
المتطلبات
- مشروع Google Cloud تم تفعيل الفوترة فيه
- معرفة أساسية بسطر الأوامر وNode.js
2. قبل البدء
إعداد المشروع
إنشاء مشروع على Google Cloud
- في Google Cloud Console، في صفحة اختيار المشروع، اختَر مشروعًا على Google Cloud أو أنشِئ مشروعًا.
- تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية. كيفية التحقّق مما إذا كانت الفوترة مفعَّلة في مشروع
بدء Cloud Shell
Cloud Shell هي بيئة سطر أوامر تعمل في Google Cloud ومحمّلة مسبقًا بالأدوات اللازمة.
- انقر على تفعيل Cloud Shell في أعلى "وحدة تحكّم Google Cloud".
- بعد الاتصال بـ Cloud Shell، تحقَّق من مصادقتك باتّباع الخطوات التالية:
gcloud auth list - تأكَّد من إعداد مشروعك باتّباع الخطوات التالية:
gcloud config get project - إذا لم يتم ضبط مشروعك على النحو المتوقّع، اضبطه باتّباع الخطوات التالية:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
تفعيل واجهات برمجة التطبيقات
نفِّذ الأمر التالي في Cloud Shell لتفعيل واجهات برمجة التطبيقات المطلوبة:
gcloud services enable sqladmin.googleapis.com \
aiplatform.googleapis.com
3- إنشاء نسخة طبق الأصل من مستودع العروض التوضيحية
الآن، احصل على رمز العرض التوضيحي لـ "الذكريات الحية".
- أنشئ نسخة طبق الأصل من المستودع إلى بيئة Cloud Shell:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git cd devrel-demos/codelabs/visual-memory-postgres-demo - ثبِّت التبعيات:
npm install
4. إنشاء قاعدة بيانات Cloud SQL وضبطها
في هذا القسم، ستنشئ مثيلاً من Cloud SQL، وستبدأ قاعدة بيانات، وستعدّ المخطط.
- يستخدم التطبيق متغيرات البيئة لإعداداته. شغِّل الحزمة التالية في وحدة Cloud Shell الطرفية لضبط المتغيرات المطلوبة لهذه الجلسة:
export REGION="us-central1" export INSTANCE_NAME="living-memory-db" export DB_HOST=127.0.0.1 export DB_PORT=5432 export DB_USER=memory_app export DB_PASS=memory_app_password export DB_NAME=living_memory export PGPASSWORD=$DB_PASS - أنشِئ المثيل. تستغرق هذه الخطوة عادةً من 5 إلى 10 دقائق.
gcloud sql instances create $INSTANCE_NAME \ --database-version=POSTGRES_16 \ --cpu=1 \ --memory=3840MB \ --region=$REGION \ --root-password=$DB_PASS \ --edition=ENTERPRISEvectorوإنشاء عدة جداول لدعم التطبيق:
usersوconversationsوmessages: جداول عادية لتخزين الملفات الشخصية للمستخدمين وسجلّ المحادثاتmemories: هذا هو الجدول الأساسي لعملية التوليد المعزّز بالاسترجاع (RAG). يمثّل كل صف جزءًا من المعلومات المستخرَجة من المحادثة (مثل "يحب المستخدم التنزه"). يخزّن هذا السجلّ ما يلي:-
content: نص الذكرى memory_type: نوع الذكرى (FACTأوPREFأوIMPLICIT)embedding: عمودvectorذو 768 بُعدًا يحتوي على التمثيل الدلالي للمحتوى، وهو من إنشاء Gemini.
-
pgvectorالفهرس: يتم إنشاء فهرسHNSW(Hierarchical Navigable Small World) في العمودembedding. هذا الأمر ضروري لتحسين عمليات البحث باستخدام خوارزمية الجار الأقرب (k-NN)، ما يتيحpgvectorالعثور بسرعة على الذكريات الأكثر تشابهًا من الناحية الدلالية باستخدام عامل مسافة جيب التمام (<=>).
- إنشاء قاعدة البيانات
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME - إنشاء مستخدم التطبيق
gcloud sql users create $DB_USER --instance=$INSTANCE_NAME --password=$DB_PASS - ابدأ الخادم الوكيل للمصادقة في Cloud SQL. يوفّر الخادم الوكيل وصولاً آمنًا إلى مثيلك بدون الحاجة إلى ضبط قائمة عناوين IP المسموح بها.
(cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:us-central1:living-memory-db &) && sleep 2 && echo ""The proxy has started successfully and is ready for new connections!. - طبِّق الإذن
schema.sqlلتفعيل الإضافةvectorوإنشاء الجداول اللازمة. بما أنّ الخادم الوكيل يعمل، يمكنك الآن الاتصال بمثيلك على127.0.0.1.psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME < schema.sql - تأكَّد من نجاح عملية إنشاء المخطط.
psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME -c "\dt"conversationsوmemoriesوmessagesوusers.List of relations Schema | Name | Type | Owner --------+---------------+-------+------------ public | conversations | table | memory_app public | memories | table | memory_app public | messages | table | memory_app public | queries_log | table | memory_app public | users | table | memory_app (5 rows)
5- فهم الاسترجاع الدلالي باستخدام pgvector
في هذا القسم، ستتعرّف على كيفية استرداد التطبيق للسياق المناسب للذكاء الاصطناعي قبل إنشاء ردّ. يوضّح المقتطف التالي من server.js الرمز البرمجي المسؤول عن ذلك في نقطة النهاية /api/chat:
// Retrieve Similar Memories for Context (Using pgvector)
const promptEmbeddingRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: message,
config: { outputDimensionality: 768 },
});
const promptEmbedding = promptEmbeddingRes.embeddings[0].values;
const embeddingStr = `[${promptEmbedding.join(',')}]`;
// Query DB for top 5 closest memories
const relevantMemories = await pool.query(
`SELECT id, content, memory_type, category
FROM memories
WHERE user_id = $1
ORDER BY embedding <=> $2::vector
LIMIT 5`,
[userId, embeddingStr]
);
آلية العمل
- الذكاء الاصطناعي التوليدي (التضمين): يتلقّى التطبيق رسالة المستخدم الواردة ويستخدم نموذج
gemini-embedding-001لتحويل النص إلى متّجه بـ 768 بُعدًا. يمثّل هذا المتّجه المعنى الدلالي للرسالة. - Cloud SQL (pgvector): يمرّر التطبيق هذا المتّجه إلى Cloud SQL. باستخدام عامل التشغيل
<=>(مسافة جيب التمام) الذي توفّره الإضافةpgvector، يعثر Cloud SQL على 5 ذكريات تتشابه مع الطلب من الناحية الدلالية. - النتيجة: هذا هو التوليد المعزّز بالاسترجاع (RAG). يصل الذكاء الاصطناعي إلى ذكريات محدّدة وذات صلة من قاعدة البيانات لتخصيص رده، بدون الحاجة إلى تحميل السجلّ بأكمله.
6. فهم ميزة استخراج الذاكرة
بعد ذلك، اطّلِع على كيفية تعلُّم التطبيق من المحادثة. المقتطف التالي مأخوذ من الدالة extractMemoriesAsync في server.js:
// MEMORY EXTRACTION LOGIC
async function extractMemoriesAsync(userMessage, userId, messageId) {
const extractionPrompt = `
Analyze the following user message. A memory profile is being built for this user.
Extract ANY explicit facts (Facts), preferences (Pref), or implicit behavioral traits/styles (Implicit).
Return the result as a raw JSON array of objects (NO Markdown blocks, just the JSON array).
Format: [{"content": "string fact/sentence", "type": "FACT|PREF|IMPLICIT", "category": "General|Travel|Hobby|Persona"}]
If nothing is found, return [].
Message: "${userMessage}"
`;
const result = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: extractionPrompt
});
let rawJson = result.text.replace(/^```json/g, '').replace(/```$/g, '').trim();
let extracted;
try {
extracted = JSON.parse(rawJson);
} catch (e) {
console.warn("Could not parse extracted JSON:", rawJson);
return;
}
if (Array.isArray(extracted) && extracted.length > 0) {
// Compute embeddings and save each to the DB
for (const memory of extracted) {
const embedRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: memory.content,
config: { outputDimensionality: 768 },
});
const vectorData = `[${embedRes.embeddings[0].values.join(',')}]`;
await pool.query(
`INSERT INTO memories (user_id, content, memory_type, category, embedding, source_message_id)
VALUES ($1, $2, $3, $4, $5, $6)`,
[userId, memory.content, memory.type.toUpperCase(), memory.category, vectorData, messageId]
);
console.log(`Saved new memory: ${memory.content}`);
}
}
}
آلية العمل
- الذكاء الاصطناعي التوليدي (النتائج المنظَّمة): يستخدم التطبيق نموذج
gemini-2.5-flashفائق السرعة لتحليل رسالة المستخدم واستخراج الحقائق والتفضيلات المنظَّمة كصفيف JSON. - Cloud SQL (التخزين المختلط): بعد إنشاء تضمينات لهذه الحقائق الجديدة، يتم تخزينها في Cloud SQL. يُرجى العِلم أنّه يتم تخزين البيانات العلائقية العادية (معرّف المستخدم والمحتوى النصي والفئات) بجانب بيانات المتجهات العالية الأبعاد في صف واحد.
- النتيجة: ينشئ التطبيق ملفًا شخصيًا للذاكرة يتم تعديله تلقائيًا في الوقت الفعلي، مستفيدًا من إمكانات Gemini التحليلية ومساحة التخزين في Cloud SQL.
7. تشغيل تطبيق المحادثة
- تعبئة قاعدة البيانات ببعض الأمثلة على المستخدمين
npm run seed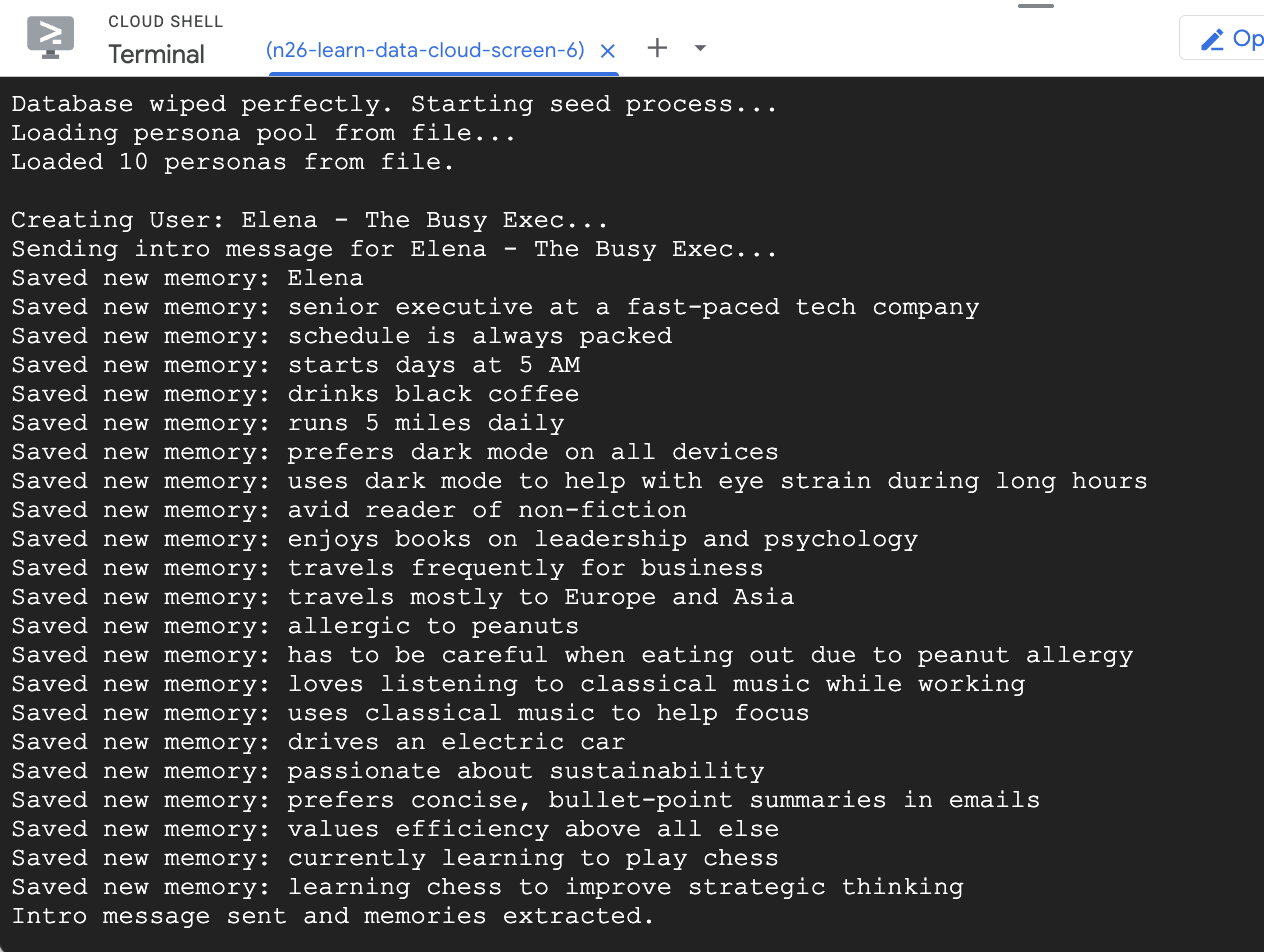
- بعد ذلك، شغِّل الخادم
node server.js - في Cloud Shell، انقر على معاينة الويب في أعلى يسار شريط أدوات الوحدة الطرفية، ثم اختَر تغيير المنفذ. أدخِل
3000لرقم المنفذ وانقر على تغيير ومعاينة.
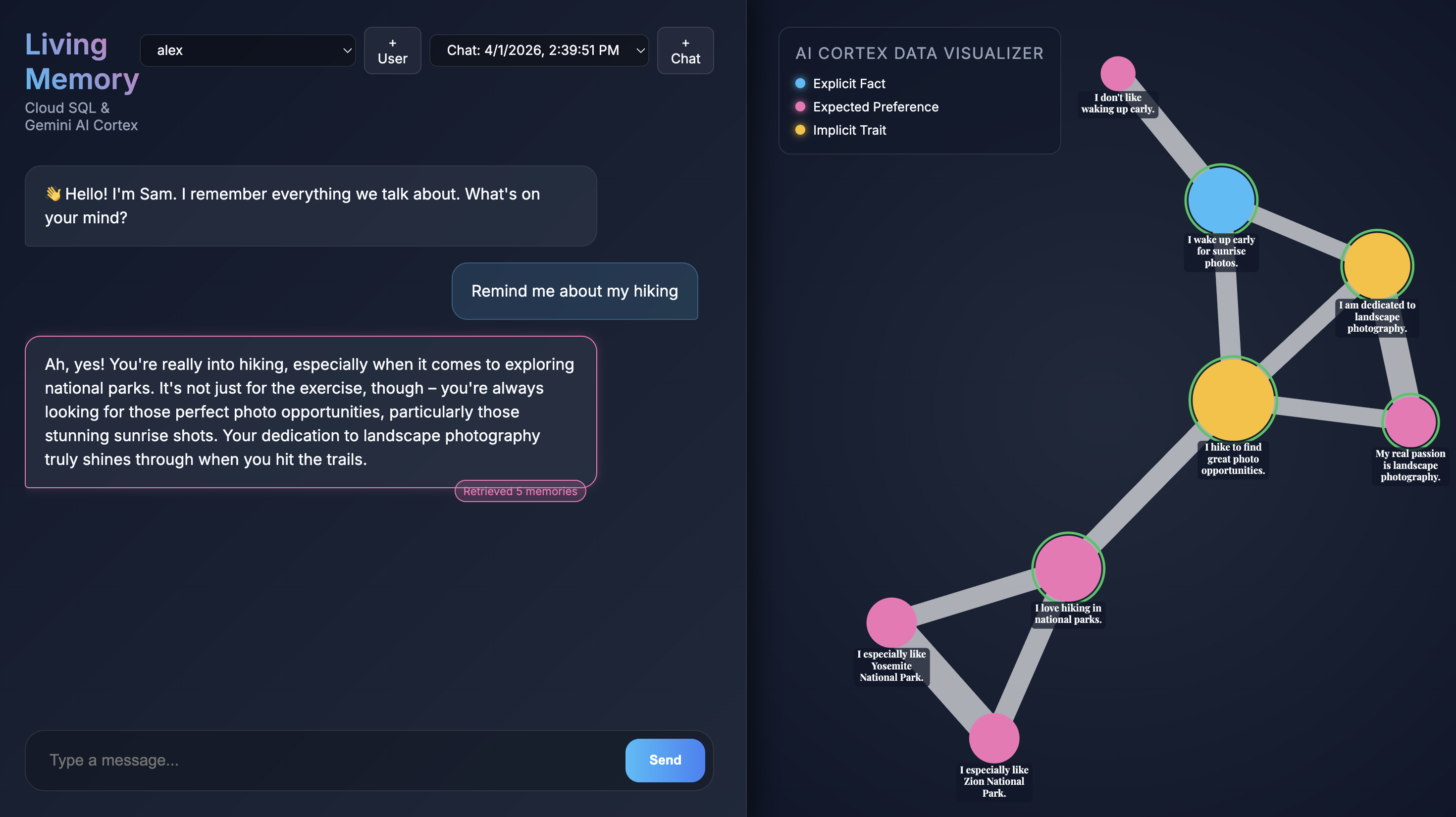
التفاعل مع المساعد
عند فتح التطبيق في المتصفّح، ستظهر لك واجهة محادثة "الذكرى الحية". على اليسار، يعرض AI Cortex Data Visualizer الذكريات كعُقد في مساحة متجهة، ويتم ترميزها بالألوان حسب النوع (حقيقة، تفضيل، سمة ضمنية). قد يكون النص في عُقد الذاكرة صغيرًا حسب دقة الشاشة، لذا استخدِم الماوس أو لوحة اللمس للتكبير والتصغير والتحريك لإلقاء نظرة أقرب.
الاستعلام عن الذكريات الحالية
أنشأ النص البرمجي seed الذي نفّذته سابقًا مستخدمَين نموذجيَين مع بعض الذكريات التي تم ملؤها مسبقًا.
- اختَر مستخدمًا من القائمة المنسدلة للمستخدمين في أعلى يمين الصفحة.
- استخدِم أحد أزرار المحادثة السريعة أو اكتب
Give me restaurant recommendations in New York Cityفي حقل إدخال المحادثة واضغط على إرسال. - عندما يردّ عليك "المساعد"، يمكنك النقر على رسالته للاطّلاع على الذكريات التي استخدمها. سيتم تمييزها باللون الأخضر ويمكنك تكبيرها والاطّلاع على كيفية مساعدتها في تكوين الردّ.
إنشاء مستخدم جديد
لننشئ الآن مستخدمًا جديدًا.
- انقر على الزر + بجانب القائمة المنسدلة الخاصة بالمستخدم لبدء جلسة محادثة جديدة.
- استخدِم الاسم والوصف اللذين تم إنشاؤهما أو عدِّلهما لوصف نفسك.
- انقر على إنشاء وشاهِد التطبيق يبدأ في استخراج الذكريات. بعد حوالي 30 ثانية، من المفترض أن تظهر عُقد جديدة في أداة العرض المرئي على يسار الشاشة. تمثّل هذه البيانات الحقائق والإعدادات المفضّلة التي استخرجها Gemini من رسالتك وخزّنها في قاعدة بيانات Cloud SQL.
- اطرح سؤالاً متابعًا، مثل
What food do I like?، لترى كيف يستخدم "مساعد Google" ذكرياته المكتسبة حديثًا في المحادثة.
8. تَنظيم
لتجنُّب فرض رسوم مستمرة على حسابك على Google Cloud مقابل الموارد المستخدَمة في هذا الدرس التطبيقي حول الترميز، عليك حذف الموارد التي أنشأتها.
- احذف مثيل Cloud SQL:
gcloud sql instances delete $INSTANCE_NAME --quiet - أزِل مستودع العروض التوضيحية:
rm -rf ~/devrel-demos
9- تهانينا
لقد أنشأت ونشرت بنجاح مساعدًا مستندًا إلى الذكاء الاصطناعي باسم "ذاكرة حية".
ما تعلّمته
- كيفية استخدام Cloud SQL pgvector للبحث الدلالي
- كيفية استخدام Gemini لاستخراج الذاكرة الديناميكية
الخطوات التالية
- اطّلِع على مستندات Cloud SQL pgvector.
- مزيد من المعلومات حول إمكانات Gemini API
- نظرة متعمّقة على الخادم الوكيل للمصادقة في Cloud SQL
- جرِّب تخصيص
extractionPromptفيserver.jsلاستخراج أنواع مختلفة من البيانات.
استمتِع بالبناء باستخدام "الذاكرة الحية"!