
1. Einführung
In diesem Codelab erfahren Sie, wie Sie die Living Memory Demo erstellen, einen KI-basierten Assistenten, der „Erinnerungen“ an Ihre Unterhaltung speichert, um eine personalisierte Erfahrung zu bieten.
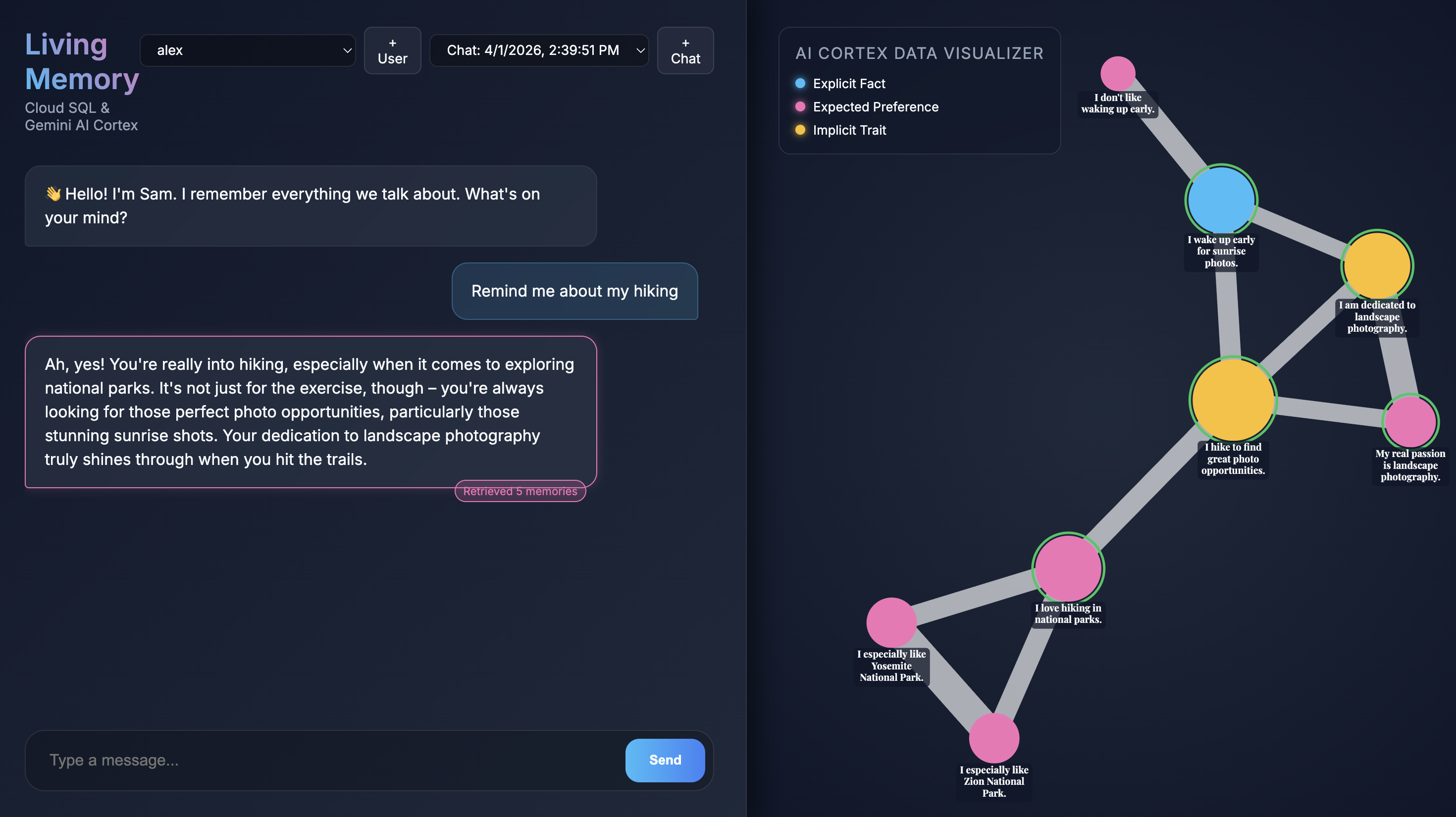
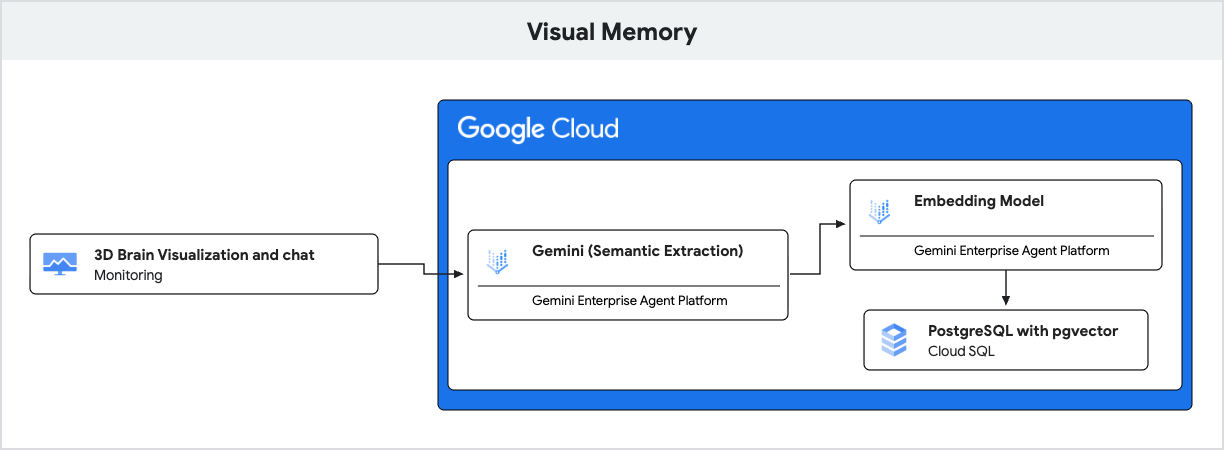
Die Anwendung verwendet Gemini für das Natural Language Understanding und Cloud SQL for PostgreSQL mit der pgvector-Erweiterung, um diese Erinnerungen basierend auf semantischer Ähnlichkeit zu speichern und abzurufen.
Dieses Codelab richtet sich an Entwickler aller Erfahrungsstufen, die sich für KI und Datenbanken interessieren. Es dauert etwa 60 Minuten. Die erstellten Ressourcen sollten weniger als 5 $kosten.
Aufgaben
- So richten Sie eine Cloud SQL for PostgreSQL-Instanz mit
pgvector-Unterstützung ein. - So können Sie mit Gemini interaktiv „Erinnerungen“ aus Nutzernachrichten extrahieren.
- Vektorsuchen in PostgreSQL durchführen, um relevanten Kontext für KI-Antworten abzurufen.
Voraussetzungen
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
- Grundkenntnisse zur Befehlszeile und zu Node.js.
2. Hinweis
Projekt einrichten
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console auf der Seite zur Projektauswahl ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein. So prüfen Sie, ob die Abrechnung für ein Projekt aktiviert ist.
Cloud Shell starten
Cloud Shell ist eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und mit den erforderlichen Tools vorinstalliert ist.
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren.
- Prüfen Sie nach der Verbindung mit Cloud Shell Ihre Authentifizierung:
gcloud auth list - Prüfen Sie, ob Ihr Projekt konfiguriert ist:
gcloud config get project - Wenn Ihr Projekt nicht wie erwartet festgelegt ist, legen Sie es fest:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
APIs aktivieren
Führen Sie den folgenden Befehl in der Cloud Shell aus, um die erforderlichen APIs zu aktivieren:
gcloud services enable sqladmin.googleapis.com \
aiplatform.googleapis.com
3. Demo-Repository klonen
Rufen Sie jetzt den Code für die Living Memory-Demo ab.
- Klonen Sie das Repository in Ihre Cloud Shell-Umgebung:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git cd devrel-demos/codelabs/visual-memory-postgres-demo - Installieren Sie die Abhängigkeiten:
npm install
4. Cloud SQL-Datenbank erstellen und konfigurieren
In diesem Abschnitt erstellen Sie eine Cloud SQL-Instanz, initialisieren eine Datenbank und richten das Schema ein.
- Die Anwendung verwendet Umgebungsvariablen für die Konfiguration. Führen Sie den folgenden Block in Ihrem Cloud Shell-Terminal aus, um die erforderlichen Variablen für diese Sitzung festzulegen:
export REGION="us-central1" export INSTANCE_NAME="living-memory-db" export DB_HOST=127.0.0.1 export DB_PORT=5432 export DB_USER=memory_app export DB_PASS=memory_app_password export DB_NAME=living_memory export PGPASSWORD=$DB_PASS - Instanz erstellen Dieser Schritt dauert in der Regel 5 bis 10 Minuten.
gcloud sql instances create $INSTANCE_NAME \ --database-version=POSTGRES_16 \ --cpu=1 \ --memory=3840MB \ --region=$REGION \ --root-password=$DB_PASS \ --edition=ENTERPRISEvectorund erstellt mehrere Tabellen zur Unterstützung der Anwendung:
users,conversations,messages: Standardtabellen zum Speichern von Nutzerprofilen und Konversationsverlauf.memories: Dies ist die Haupttabelle für Retrieval-Augmented Generation (RAG). Jede Zeile steht für eine aus der Unterhaltung extrahierte Information (z.B. „Nutzer mag Wandern“). Darin werden folgende Informationen gespeichert:content: Der Text des Kontextes.memory_type: Der Speichertyp (FACT,PREFoderIMPLICIT).embedding: Eine 768-dimensionalevector-Spalte mit der semantischen Darstellung des Inhalts, die von Gemini generiert wurde.
pgvector-Index: Für die Spalteembeddingwird einHNSW-Index (Hierarchical Navigable Small World) erstellt. Dies ist entscheidend für die Optimierung von k-Nearest Neighbor-Suchen (k-NN), dapgvectorso schnell die semantisch ähnlichsten Erinnerungen mithilfe des Kosinus-Abstandsoperators (<=>) finden kann.
- Datenbank erstellen
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME - Anwendungsnutzer erstellen
gcloud sql users create $DB_USER --instance=$INSTANCE_NAME --password=$DB_PASS - Starten Sie den Cloud SQL Auth-Proxy. Der Proxy bietet sicheren Zugriff auf Ihre Instanz, ohne dass Sie IP-Zulassungslisten konfigurieren müssen.
(cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:us-central1:living-memory-db &) && sleep 2 && echo ""The proxy has started successfully and is ready for new connections!sehen. - Wenden Sie
schema.sqlan, um die Erweiterungvectorzu aktivieren und die erforderlichen Tabellen zu erstellen. Da der Proxy ausgeführt wird, können Sie jetzt unter127.0.0.1eine Verbindung zu Ihrer Instanz herstellen.psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME < schema.sql - Prüfen Sie, ob das Schema erfolgreich erstellt wurde.
psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME -c "\dt"conversations,memories,messagesundusersenthalten.List of relations Schema | Name | Type | Owner --------+---------------+-------+------------ public | conversations | table | memory_app public | memories | table | memory_app public | messages | table | memory_app public | queries_log | table | memory_app public | users | table | memory_app (5 rows)
5. Semantisches Abrufen mit pgvector
In diesem Abschnitt sehen Sie, wie die Anwendung relevanten Kontext für die KI abruft, bevor eine Antwort generiert wird. Das folgende Snippet aus server.js zeigt den Code, der dafür im /api/chat-Endpunkt verantwortlich ist:
// Retrieve Similar Memories for Context (Using pgvector)
const promptEmbeddingRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: message,
config: { outputDimensionality: 768 },
});
const promptEmbedding = promptEmbeddingRes.embeddings[0].values;
const embeddingStr = `[${promptEmbedding.join(',')}]`;
// Query DB for top 5 closest memories
const relevantMemories = await pool.query(
`SELECT id, content, memory_type, category
FROM memories
WHERE user_id = $1
ORDER BY embedding <=> $2::vector
LIMIT 5`,
[userId, embeddingStr]
);
Funktionsweise
- Generative KI (Einbettung): Die Anwendung nimmt die eingehende Nachricht des Nutzers entgegen und verwendet das
gemini-embedding-001-Modell, um den Text in einen 768-dimensionalen Vektor zu konvertieren. Dieser Vektor stellt die semantische Bedeutung der Nachricht dar. - Cloud SQL (pgvector): Die Anwendung übergibt diesen Vektor an Cloud SQL. Mit dem von der
pgvector-Erweiterung bereitgestellten Operator<=>(Kosinus-Abstand) findet Cloud SQL die fünf Erinnerungen, die dem Prompt semantisch am ähnlichsten sind. - Das Ergebnis: Das ist Retrieval-Augmented Generation (RAG). Die KI greift auf bestimmte, relevante Erinnerungen aus der Datenbank zu, um ihre Antwort zu personalisieren, ohne den gesamten Verlauf laden zu müssen.
6. Speicherauszug
Als Nächstes sehen Sie, wie die Anwendung aus dem Gespräch lernt. Das folgende Snippet stammt aus der Funktion extractMemoriesAsync in server.js:
// MEMORY EXTRACTION LOGIC
async function extractMemoriesAsync(userMessage, userId, messageId) {
const extractionPrompt = `
Analyze the following user message. A memory profile is being built for this user.
Extract ANY explicit facts (Facts), preferences (Pref), or implicit behavioral traits/styles (Implicit).
Return the result as a raw JSON array of objects (NO Markdown blocks, just the JSON array).
Format: [{"content": "string fact/sentence", "type": "FACT|PREF|IMPLICIT", "category": "General|Travel|Hobby|Persona"}]
If nothing is found, return [].
Message: "${userMessage}"
`;
const result = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: extractionPrompt
});
let rawJson = result.text.replace(/^```json/g, '').replace(/```$/g, '').trim();
let extracted;
try {
extracted = JSON.parse(rawJson);
} catch (e) {
console.warn("Could not parse extracted JSON:", rawJson);
return;
}
if (Array.isArray(extracted) && extracted.length > 0) {
// Compute embeddings and save each to the DB
for (const memory of extracted) {
const embedRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: memory.content,
config: { outputDimensionality: 768 },
});
const vectorData = `[${embedRes.embeddings[0].values.join(',')}]`;
await pool.query(
`INSERT INTO memories (user_id, content, memory_type, category, embedding, source_message_id)
VALUES ($1, $2, $3, $4, $5, $6)`,
[userId, memory.content, memory.type.toUpperCase(), memory.category, vectorData, messageId]
);
console.log(`Saved new memory: ${memory.content}`);
}
}
}
Funktionsweise
- Generative KI (strukturierte Ausgabe): Die Anwendung verwendet das ultraschnelle Modell
gemini-2.5-flash, um die Nachricht des Nutzers zu analysieren und strukturierte Fakten und Einstellungen als JSON-Array zu extrahieren. - Cloud SQL (Hybrid Storage): Nachdem Einbettungen für diese neuen Fakten generiert wurden, werden sie in Cloud SQL gespeichert. Beachten Sie, dass standardmäßige relationale Daten (Nutzer-ID, Textinhalte, Kategorien) in einer einzelnen Zeile direkt neben den hochdimensionalen Vektordaten gespeichert werden.
- Das Ergebnis: Die App erstellt in Echtzeit ein sich selbst aktualisierendes Speicherprofil, das sowohl die Analysefunktionen von Gemini als auch die Speicherfunktionen von Cloud SQL nutzt.
7. Chatanwendung ausführen
- Datenbank mit einigen Beispielnutzern füllen
npm run seed
- Server ausführen
node server.js - Klicken Sie in Cloud Shell oben rechts in der Terminal-Symbolleiste auf Webvorschau und wählen Sie Port ändern aus. Geben Sie
3000als Portnummer ein und klicken Sie auf Ändern und Vorschau.
Mit dem Assistenten interagieren
Wenn die Anwendung in Ihrem Browser geöffnet wird, sehen Sie die Chat-Oberfläche von Living Memory. Rechts werden im AI Cortex Data Visualizer Erinnerungen als Knoten in einem Vektorraum angezeigt, die nach Typ (Fakt, Präferenz, implizites Merkmal) farblich codiert sind. Der Text auf Speicherknoten kann je nach Bildschirmauflösung klein sein. Verwenden Sie die Maus oder das Touchpad, um zu zoomen und zu schwenken, um sich die Knoten genauer anzusehen.
Vorhandene Erinnerungen abfragen
Mit dem Skript seed, das Sie zuvor ausgeführt haben, wurden zwei Beispielnutzer mit einigen vorab ausgefüllten Erinnerungen erstellt.
- Wählen Sie oben links im Drop-down-Menü einen Nutzer aus.
- Klicken Sie auf eine der Schnellchat-Schaltflächen oder geben Sie
Give me restaurant recommendations in New York Cityin die Chateingabe ein und drücken Sie auf Senden. - Wenn der Assistent antwortet, können Sie auf seine Nachricht klicken, um zu sehen, welche Erinnerungen er verwendet hat. Sie werden grün hervorgehoben und Sie können sie vergrößern, um zu sehen, wie sie zur Antwort beigetragen haben.
Neuen Nutzer erstellen
Erstellen wir jetzt einen neuen Nutzer.
- Klicken Sie neben dem Drop-down-Menü für Nutzer auf die Schaltfläche +, um eine neue Chatsitzung zu starten.
- Verwenden Sie den generierten Namen und die generierte Beschreibung oder bearbeiten Sie sie, um sich selbst zu beschreiben.
- Klicken Sie auf Erstellen. Die Anwendung beginnt dann mit dem Extrahieren von Erinnerungen. Nach etwa 30 Sekunden sollten rechts im Visualizer neue Knoten angezeigt werden. Diese stellen die Fakten und Einstellungen dar, die Gemini aus Ihrer Nachricht extrahiert und in der Cloud SQL-Datenbank gespeichert hat.
- Stellen Sie eine Folgefrage wie
What food do I like?, um zu sehen, wie der Assistent seine neu gewonnenen gemerkten Informationen in der Unterhaltung verwendet.
8. Bereinigen
Damit Ihrem Google Cloud-Konto die in diesem Codelab verwendeten Ressourcen nicht laufend in Rechnung gestellt werden, sollten Sie die erstellten Ressourcen löschen.
- Löschen Sie die Cloud SQL-Instanz:
gcloud sql instances delete $INSTANCE_NAME --quiet - Entfernen Sie das Demorepository:
rm -rf ~/devrel-demos
9. Glückwunsch
Sie haben einen KI‑Assistenten für „Living Memory“ erstellt und bereitgestellt.
Das haben Sie gelernt
- Cloud SQL pgvector für die semantische Suche verwenden
- Gemini für die dynamische Extraktion von Erinnerungen verwenden
Nächste Schritte
- Cloud SQL-Dokumentation zu pgvector
- Weitere Informationen zu den Funktionen der Gemini API
- Cloud SQL Auth-Proxy
- Passen Sie
extractionPromptinserver.jsan, um verschiedene Datentypen zu extrahieren.
Viel Spaß beim Erstellen mit Living Memory!