
1. Introducción
En este codelab, aprenderás a compilar la demostración de Living Memory, un asistente potenciado por IA que realiza un seguimiento de las "memorias" de tu conversación para brindar una experiencia personalizada.
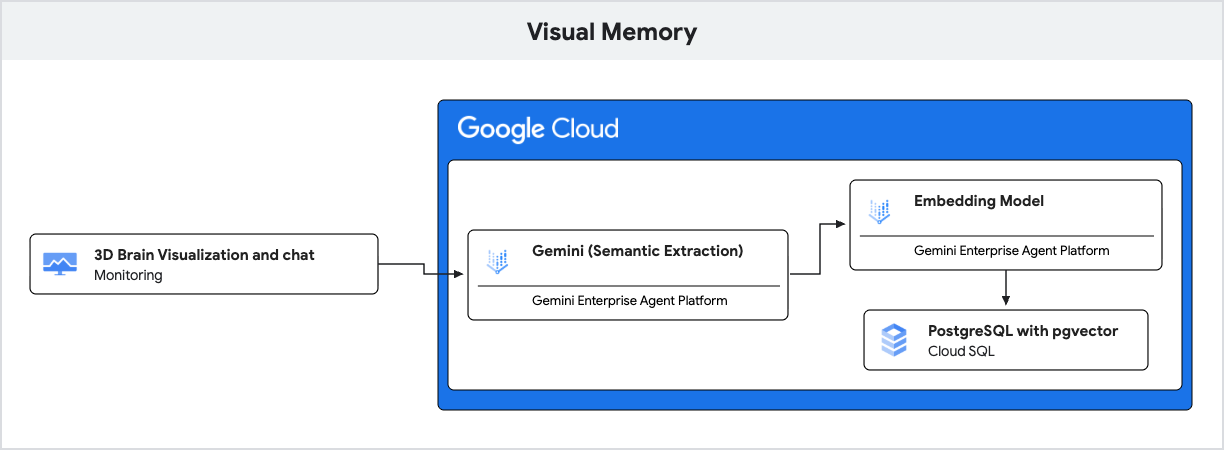
La aplicación usa Gemini para la comprensión del lenguaje natural y Cloud SQL para PostgreSQL con la extensión pgvector para almacenar y recuperar estas memorias en función de la similitud semántica.
Este codelab está destinado a desarrolladores de todos los niveles de habilidad interesados en la IA y las bases de datos, y debería tardar unos 60 minutos en completarse. Los recursos creados deberían costar menos de USD 5.
Actividades
- Cómo configurar una instancia de Cloud SQL para PostgreSQL con compatibilidad con
pgvector - Cómo usar Gemini para extraer de forma interactiva "memorias" de los mensajes del usuario
- Cómo realizar búsquedas vectoriales en PostgreSQL para recuperar el contexto pertinente para las respuestas de IA
Requisitos
- Un proyecto de Google Cloud con facturación habilitada.
- Conocimientos básicos de la línea de comandos y Node.js
2. Antes de comenzar
Configura el proyecto
Crea un proyecto de Google Cloud
- En la consola de Google Cloud, en la página del selector de proyectos, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud. Obtén información para verificar si la facturación está habilitada en un proyecto.
Inicie Cloud Shell
Cloud Shell es un entorno de línea de comandos que se ejecuta en Google Cloud y que viene precargado con las herramientas necesarias.
- Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.
- Una vez que te conectes a Cloud Shell, verifica tu autenticación:
gcloud auth list - Confirma que tu proyecto esté configurado:
gcloud config get project - Si tu proyecto no está configurado como se espera, configúralo:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Habilita las APIs
Ejecuta el siguiente comando en Cloud Shell para habilitar las APIs requeridas:
gcloud services enable sqladmin.googleapis.com \
aiplatform.googleapis.com
3. Clona el repositorio de demostración
Ahora, obtén el código de la demostración de Living Memory.
- Clona el repositorio en tu entorno de Cloud Shell:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git cd devrel-demos/codelabs/visual-memory-postgres-demo - Instala las dependencias:
npm install
4. Crea y configura la base de datos de Cloud SQL
En esta sección, crearás una instancia de Cloud SQL, inicializarás una base de datos y configurarás el esquema.
- La aplicación usa variables de entorno para la configuración. Ejecuta el siguiente bloque en tu terminal de Cloud Shell para establecer las variables requeridas para esta sesión:
export REGION="us-central1" export INSTANCE_NAME="living-memory-db" export DB_HOST=127.0.0.1 export DB_PORT=5432 export DB_USER=memory_app export DB_PASS=memory_app_password export DB_NAME=living_memory export PGPASSWORD=$DB_PASS - Crea la instancia. Por lo general, este paso tarda entre 5 y 10 minutos.
gcloud sql instances create $INSTANCE_NAME \ --database-version=POSTGRES_16 \ --cpu=1 \ --memory=3840MB \ --region=$REGION \ --root-password=$DB_PASS \ --edition=ENTERPRISEvectory crea varias tablas para admitir la aplicación:
users,conversations,messages: Tablas estándar para almacenar perfiles de usuario y el historial de conversaciones.memories: Esta es la tabla principal para la generación mejorada por recuperación (RAG). Cada fila representa una información extraída de la conversación (p.ej., "Al usuario le gusta el senderismo"). Almacena lo siguiente:content: El texto de la memoria.memory_type: El tipo de memoria (FACT,PREFoIMPLICIT).embedding: Una columnavectorde 768 dimensiones que contiene la representación semántica del contenido, generada por Gemini.
pgvectorÍndice: Se crea un índiceHNSW(Hierarchical Navigable Small World) en la columnaembedding. Esto es fundamental para optimizar las búsquedas de k-vecinos más cercanos (k-NN), lo que permite quepgvectorencuentre rápidamente las memorias más similares semánticamente con el operador de distancia coseno (<=>).
- Crea la base de datos
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME - Crea el usuario de la aplicación
gcloud sql users create $DB_USER --instance=$INSTANCE_NAME --password=$DB_PASS - Inicia el proxy de Cloud SQL Auth. El proxy proporciona acceso seguro a tu instancia sin necesidad de configurar la lista de entidades permitidas de IP.
(cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:us-central1:living-memory-db &) && sleep 2 && echo ""The proxy has started successfully and is ready for new connections!. - Aplica
schema.sqlpara habilitar la extensiónvectory crear las tablas necesarias. Como el proxy está en ejecución, ahora puedes conectarte a tu instancia en127.0.0.1.psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME < schema.sql - Verifica que la creación del esquema se haya realizado correctamente.
psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME -c "\dt"conversations,memories,messagesyusers.List of relations Schema | Name | Type | Owner --------+---------------+-------+------------ public | conversations | table | memory_app public | memories | table | memory_app public | messages | table | memory_app public | queries_log | table | memory_app public | users | table | memory_app (5 rows)
5. Comprende la recuperación semántica con pgvector
En esta sección, examinarás cómo la aplicación recupera el contexto pertinente para la IA antes de generar una respuesta. En el siguiente fragmento de server.js, se muestra el código responsable de esto en el extremo /api/chat:
// Retrieve Similar Memories for Context (Using pgvector)
const promptEmbeddingRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: message,
config: { outputDimensionality: 768 },
});
const promptEmbedding = promptEmbeddingRes.embeddings[0].values;
const embeddingStr = `[${promptEmbedding.join(',')}]`;
// Query DB for top 5 closest memories
const relevantMemories = await pool.query(
`SELECT id, content, memory_type, category
FROM memories
WHERE user_id = $1
ORDER BY embedding <=> $2::vector
LIMIT 5`,
[userId, embeddingStr]
);
Cómo funciona
- IA generativa (incorporación): La aplicación toma el mensaje entrante del usuario y usa el modelo
gemini-embedding-001para convertir el texto en un vector de 768 dimensiones. Este vector representa el significado semántico del mensaje. - Cloud SQL (pgvector): La aplicación pasa ese vector a Cloud SQL. Con el operador
<=>(distancia coseno) que proporciona la extensiónpgvector, Cloud SQL encuentra las 5 memorias más similares semánticamente a la instrucción. - El resultado: Esta es la generación mejorada por recuperación (RAG). La IA obtiene acceso a memorias específicas y pertinentes de la base de datos para personalizar su respuesta, sin necesidad de cargar todo el historial.
6. Comprende la extracción de memoria
A continuación, observa cómo aprende la aplicación de la conversación. El siguiente fragmento es de la función extractMemoriesAsync en server.js:
// MEMORY EXTRACTION LOGIC
async function extractMemoriesAsync(userMessage, userId, messageId) {
const extractionPrompt = `
Analyze the following user message. A memory profile is being built for this user.
Extract ANY explicit facts (Facts), preferences (Pref), or implicit behavioral traits/styles (Implicit).
Return the result as a raw JSON array of objects (NO Markdown blocks, just the JSON array).
Format: [{"content": "string fact/sentence", "type": "FACT|PREF|IMPLICIT", "category": "General|Travel|Hobby|Persona"}]
If nothing is found, return [].
Message: "${userMessage}"
`;
const result = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: extractionPrompt
});
let rawJson = result.text.replace(/^```json/g, '').replace(/```$/g, '').trim();
let extracted;
try {
extracted = JSON.parse(rawJson);
} catch (e) {
console.warn("Could not parse extracted JSON:", rawJson);
return;
}
if (Array.isArray(extracted) && extracted.length > 0) {
// Compute embeddings and save each to the DB
for (const memory of extracted) {
const embedRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: memory.content,
config: { outputDimensionality: 768 },
});
const vectorData = `[${embedRes.embeddings[0].values.join(',')}]`;
await pool.query(
`INSERT INTO memories (user_id, content, memory_type, category, embedding, source_message_id)
VALUES ($1, $2, $3, $4, $5, $6)`,
[userId, memory.content, memory.type.toUpperCase(), memory.category, vectorData, messageId]
);
console.log(`Saved new memory: ${memory.content}`);
}
}
}
Cómo funciona
- IA generativa (salida estructurada): La aplicación usa el modelo ultrarrápido
gemini-2.5-flashpara analizar el mensaje del usuario y extraer hechos y preferencias estructurados como un array JSON. - Cloud SQL (almacenamiento híbrido): Después de generar incorporaciones para estos hechos nuevos, se almacenan en Cloud SQL. Ten en cuenta que los datos relacionales estándar (ID de usuario, contenido de texto, categorías) se almacenan junto con los datos vectoriales de alta dimensión en una sola fila.
- El resultado: La app compila un perfil de memoria de actualización automática en tiempo real, aprovechando la potencia analítica de Gemini y las capacidades de almacenamiento de Cloud SQL.
7. Ejecuta la aplicación de chat
- Propaga la base de datos con algunos usuarios de ejemplo.
npm run seed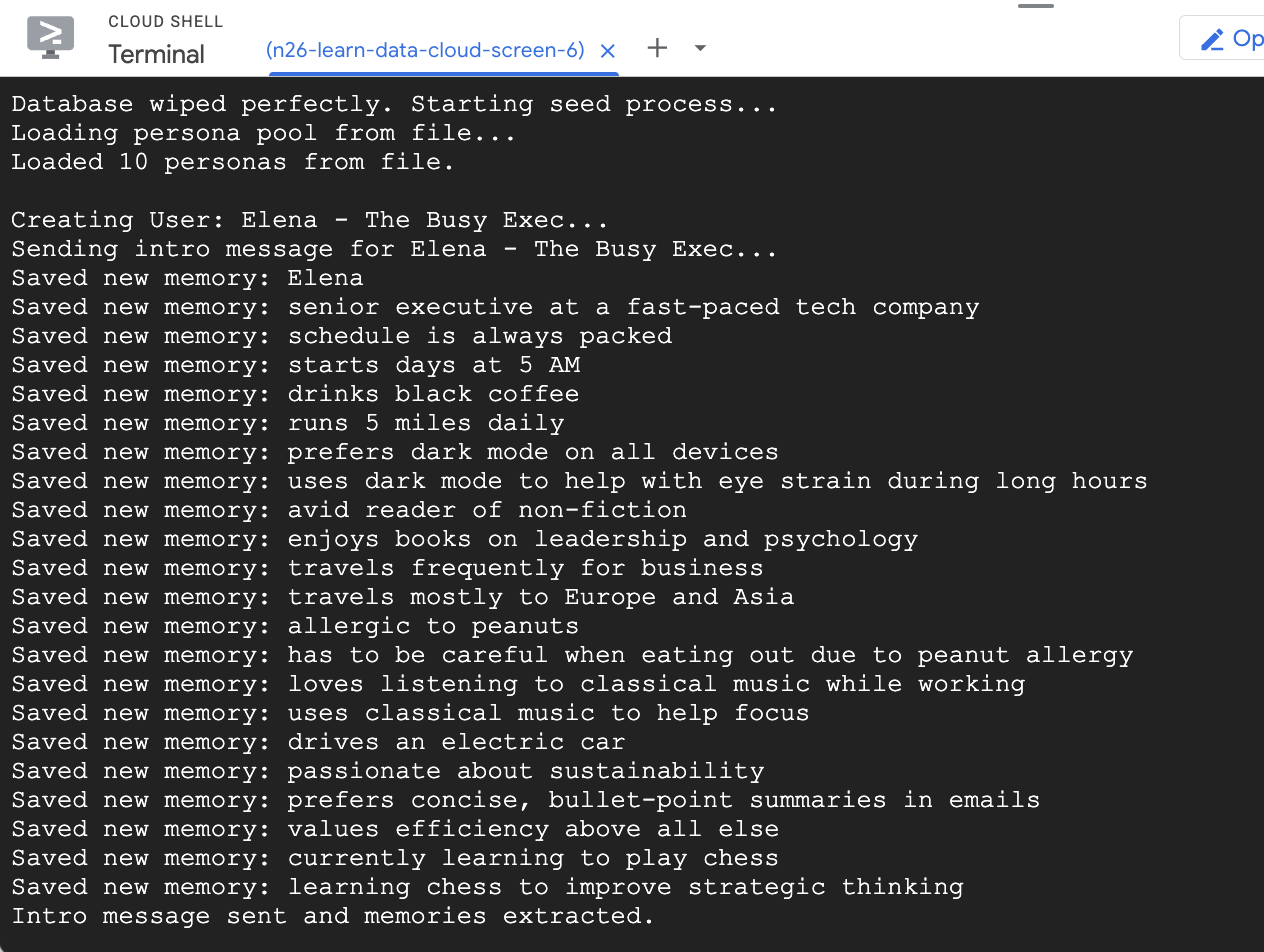
- Luego, ejecuta el servidor.
node server.js - En Cloud Shell, haz clic en Vista previa web en la parte superior derecha de la barra de herramientas de la terminal y selecciona Cambiar puerto. Ingresa
3000para el número de puerto y haz clic en Cambiar y obtener vista previa.
Interactúa con el asistente
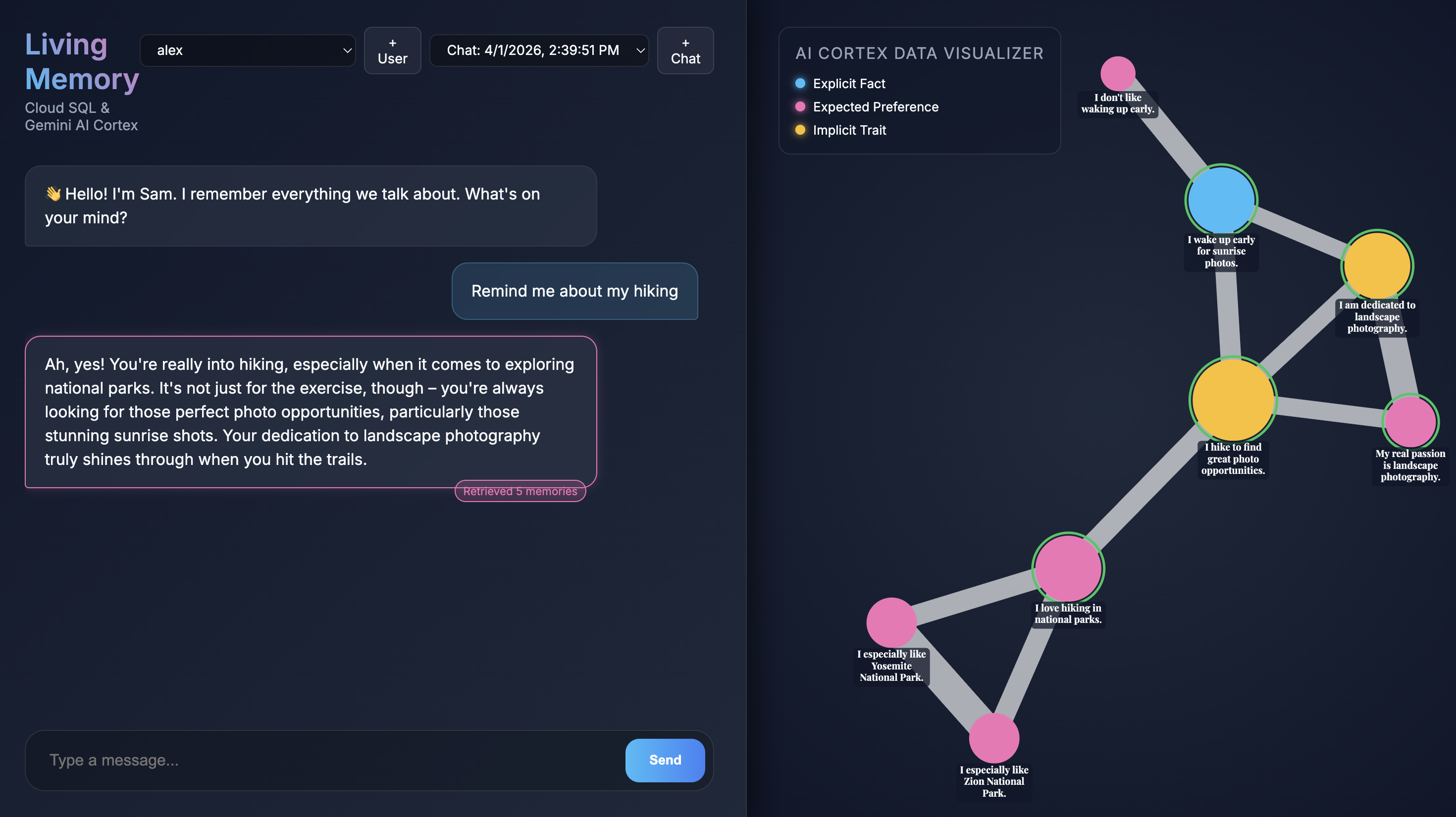
Cuando se abra la aplicación en tu navegador, verás la interfaz de chat de Living Memory. A la derecha, el Visualizador de datos de AI Cortex muestra las memorias como nodos en un espacio vectorial, codificados por color según el tipo (hecho, preferencia, rasgo implícito). El texto de los nodos de memoria puede ser pequeño según la resolución de la pantalla. Usa el mouse o el panel táctil para acercar y desplazar la imagen para verla más de cerca.
Consulta memorias existentes
La secuencia de comandos seed que ejecutaste antes creó dos usuarios de muestra con algunas memorias propagadas previamente.
- Selecciona un usuario en el menú desplegable de usuario en la parte superior izquierda.
- Usa uno de los botones de chat rápido o escribe
Give me restaurant recommendations in New York Cityen la entrada de chat y presiona Enviar. - Cuando el asistente responda, puedes hacer clic en su mensaje para ver qué memorias usó. Se destacarán en verde, y puedes acercarte a ellas y ver cómo ayudaron a formar la respuesta.
Crea un usuario nuevo
Ahora, creemos un usuario nuevo.
- Haz clic en el botón + junto al menú desplegable de usuario para iniciar una nueva sesión de chat.
- Usa el nombre y la descripción generados, o bien edítalos para describirte.
- Haz clic en Crear y observa cómo la aplicación comienza a extraer memorias. En unos 30 segundos, deberías ver que aparecen nodos nuevos en el visualizador de la derecha. Estos representan los hechos y las preferencias que Gemini extrajo de tu mensaje y almacenó en la base de datos de Cloud SQL.
- Haz una pregunta de seguimiento como
What food do I like?para ver cómo el asistente usa sus memorias recién adquiridas en la conversación.
8. Liberar espacio
Para evitar cargos continuos en tu cuenta de Google Cloud por los recursos que se usaron en este codelab, debes borrar los recursos que creaste.
- Borra la instancia de Cloud SQL:
gcloud sql instances delete $INSTANCE_NAME --quiet - Quita el repositorio de demostración:
rm -rf ~/devrel-demos
9. Felicitaciones
Compilaste e implementaste correctamente un asistente de IA de "Living Memory".
Qué aprendiste
- Cómo usar Cloud SQL pgvector para la búsqueda semántica
- Cómo usar Gemini para la extracción de memoria dinámica
Próximos pasos
- Explora la documentación de Cloud SQL pgvector.
- Obtén más información sobre las capacidades de la API de Gemini.
- Profundiza en el proxy de Cloud SQL Auth.
- Intenta personalizar el
extractionPromptenserver.jspara extraer diferentes tipos de datos.
Disfruta de la compilación con Living Memory.