
۱. مقدمه
در این آزمایشگاه کد، شما یاد خواهید گرفت که چگونه Living Memory Demo را بسازید، یک دستیار مبتنی بر هوش مصنوعی که «خاطرات» مکالمه شما را ردیابی میکند تا یک تجربه شخصیسازیشده ارائه دهد.
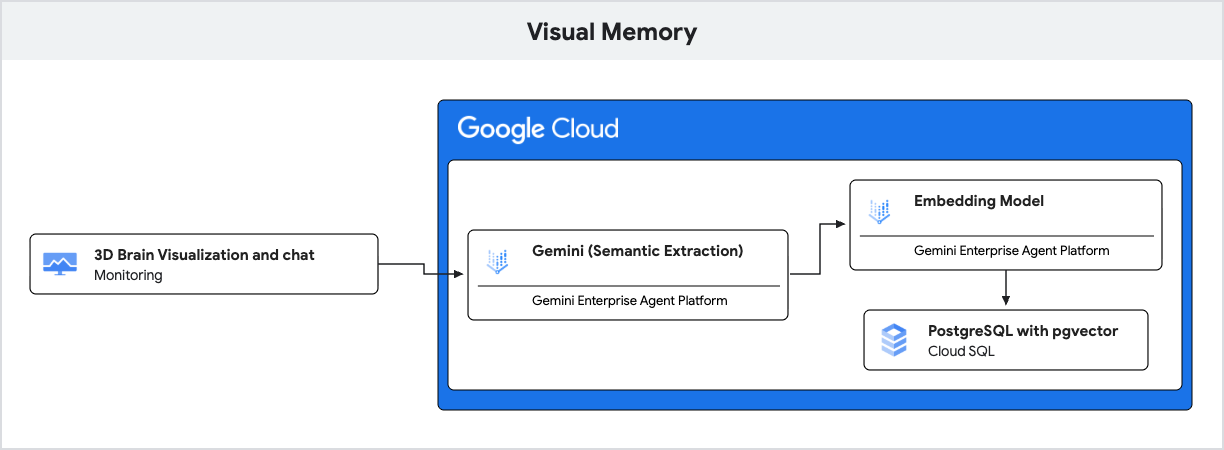
این برنامه از Gemini برای درک زبان طبیعی و از Cloud SQL برای PostgreSQL با افزونه pgvector برای ذخیره و بازیابی این خاطرات بر اساس شباهت معنایی استفاده میکند.
این آزمایشگاه کد برای توسعهدهندگانی با تمام سطوح مهارت و علاقهمند به هوش مصنوعی و پایگاههای داده در نظر گرفته شده است و تکمیل آن حدود ۶۰ دقیقه طول میکشد. منابع ایجاد شده باید کمتر از ۵ دلار هزینه داشته باشند.
کاری که انجام خواهید داد
- نحوه راهاندازی یک Cloud SQL برای نمونه PostgreSQL با پشتیبانی
pgvector. - نحوه استفاده از Gemini برای استخراج تعاملی "خاطرات" از پیامهای کاربر.
- نحوه انجام جستجوهای برداری در PostgreSQL برای بازیابی زمینه مرتبط برای پاسخهای هوش مصنوعی.
آنچه نیاز دارید
- یک پروژه گوگل کلود با قابلیت پرداخت.
- دانش اولیه از خط فرمان و Node.js.
۲. قبل از شروع
راهاندازی پروژه
ایجاد یک پروژه ابری گوگل
- در کنسول گوگل کلود ، در صفحه انتخاب پروژه، یک پروژه گوگل کلود را انتخاب یا ایجاد کنید .
- مطمئن شوید که صورتحساب برای پروژه ابری شما فعال است. یاد بگیرید که چگونه بررسی کنید که آیا صورتحساب در یک پروژه فعال است یا خیر .
شروع پوسته ابری
Cloud Shell یک محیط خط فرمان است که در Google Cloud اجرا میشود و ابزارهای لازم از قبل روی آن بارگذاری شدهاند.
- روی فعال کردن Cloud Shell در بالای کنسول Google Cloud کلیک کنید.
- پس از اتصال به Cloud Shell، احراز هویت خود را تأیید کنید:
gcloud auth list - تأیید کنید که پروژه شما پیکربندی شده است:
gcloud config get project - اگر پروژه شما مطابق انتظار تنظیم نشده است، آن را تنظیم کنید:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
فعال کردن APIها
برای فعال کردن API های مورد نیاز، دستور زیر را در Cloud Shell اجرا کنید:
gcloud services enable sqladmin.googleapis.com \
aiplatform.googleapis.com
۳. مخزن نسخه آزمایشی را کلون کنید
حالا، کد مربوط به نسخه آزمایشی Living Memory را دریافت کنید.
- مخزن را به محیط Cloud Shell خود کلون کنید:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git cd devrel-demos/codelabs/visual-memory-postgres-demo - وابستگیها را نصب کنید:
npm install
۴. پایگاه داده Cloud SQL را ایجاد و پیکربندی کنید
در این بخش، یک نمونه Cloud SQL ایجاد خواهید کرد، یک پایگاه داده را مقداردهی اولیه میکنید و طرحواره را تنظیم خواهید کرد.
- این برنامه از متغیرهای محیطی برای پیکربندی استفاده میکند. برای تنظیم متغیرهای مورد نیاز برای این جلسه، بلوک زیر را در ترمینال Cloud Shell خود اجرا کنید:
export REGION="us-central1" export INSTANCE_NAME="living-memory-db" export DB_HOST=127.0.0.1 export DB_PORT=5432 export DB_USER=memory_app export DB_PASS=memory_app_password export DB_NAME=living_memory export PGPASSWORD=$DB_PASS - نمونه را ایجاد کنید. این مرحله معمولاً ۵ تا ۱۰ دقیقه طول میکشد.
gcloud sql instances create $INSTANCE_NAME \ --database-version=POSTGRES_16 \ --cpu=1 \ --memory=3840MB \ --region=$REGION \ --root-password=$DB_PASS \ --edition=ENTERPRISEvectorرا فعال میکند و چندین جدول برای پشتیبانی از برنامه ایجاد میکند:
-
users،conversations،messages: جداول استاندارد برای ذخیره پروفایلهای کاربران و تاریخچه مکالمات. -
memories: این جدول اصلی برای بازیابی-تقویت تولید (RAG) است. هر ردیف نشان دهنده بخشی از اطلاعات استخراج شده از مکالمه است (مثلاً "کاربر پیادهروی را دوست دارد"). این جدول موارد زیر را ذخیره میکند:-
content: متن خاطره. -
memory_type: نوع حافظه (FACT،PREFیاIMPLICIT). -
embedding: یک ستونvector۷۶۸ بعدی که شامل نمایش معنایی محتوا است و توسط Gemini تولید شده است.
-
- شاخص
pgvector: یک شاخصHNSW(جهان کوچک قابل پیمایش سلسله مراتبی) روی ستونembeddingایجاد میشود. این برای بهینهسازی جستجوهای k-نزدیکترین همسایه (k-NN) بسیار مهم است وpgvectorاجازه میدهد تا با استفاده از عملگر فاصله کسینوسی (<=>) به سرعت حافظههایی را که از نظر معنایی بیشترین شباهت را دارند، پیدا کند.
-
- ایجاد پایگاه داده
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME - ایجاد کاربر برنامه
gcloud sql users create $DB_USER --instance=$INSTANCE_NAME --password=$DB_PASS - پروکسی احراز هویت Cloud SQL را اجرا کنید. این پروکسی بدون نیاز به پیکربندی لیست مجاز IP، دسترسی امن به نمونه شما را فراهم میکند.
(cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:us-central1:living-memory-db &) && sleep 2 && echo ""The proxy has started successfully and is ready for new connections! - برای فعال کردن افزونهی
vectorو ایجاد جداول لازم،schema.sqlرا اعمال کنید. از آنجایی که پروکسی در حال اجرا است، اکنون میتوانید به نمونهی خود در127.0.0.1متصل شوید.psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME < schema.sql - تأیید کنید که ایجاد طرحواره با موفقیت انجام شده است.
psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME -c "\dt"conversations،memories،messagesوusersرا فهرست میکند.List of relations Schema | Name | Type | Owner --------+---------------+-------+------------ public | conversations | table | memory_app public | memories | table | memory_app public | messages | table | memory_app public | queries_log | table | memory_app public | users | table | memory_app (5 rows)
۵. بازیابی معنایی را با pgvector درک کنید
در این بخش، بررسی خواهید کرد که چگونه برنامه، قبل از تولید پاسخ، زمینهی مرتبط با هوش مصنوعی را بازیابی میکند. قطعه کد زیر از server.js کد مسئول این کار را در نقطهی انتهایی /api/chat نشان میدهد:
// Retrieve Similar Memories for Context (Using pgvector)
const promptEmbeddingRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: message,
config: { outputDimensionality: 768 },
});
const promptEmbedding = promptEmbeddingRes.embeddings[0].values;
const embeddingStr = `[${promptEmbedding.join(',')}]`;
// Query DB for top 5 closest memories
const relevantMemories = await pool.query(
`SELECT id, content, memory_type, category
FROM memories
WHERE user_id = $1
ORDER BY embedding <=> $2::vector
LIMIT 5`,
[userId, embeddingStr]
);
چگونه کار میکند؟
- هوش مصنوعی نسل جدید (جاسازی) : برنامه پیام ورودی کاربر را دریافت کرده و با استفاده از مدل
gemini-embedding-001متن را به یک بردار ۷۶۸ بعدی تبدیل میکند. این بردار نشاندهنده معنای معنایی پیام است. - Cloud SQL (pgvector) : برنامه آن بردار را به Cloud SQL ارسال میکند. با استفاده از عملگر
<=>(فاصله کسینوسی) که توسط افزونهpgvectorارائه شده است، Cloud SQL 5 حافظهای را که از نظر معنایی بیشترین شباهت را به اعلان دارند، پیدا میکند. - نتیجه : این نسل بازیابی-تقویتشده (RAG) است. هوش مصنوعی به خاطرات خاص و مرتبط از پایگاه داده دسترسی پیدا میکند تا پاسخ خود را شخصیسازی کند، بدون اینکه نیازی به بارگذاری کل تاریخچه باشد.
۶. استخراج حافظه را درک کنید
در مرحله بعد، به نحوه یادگیری برنامه از مکالمه نگاه کنید. قطعه کد زیر از تابع extractMemoriesAsync در server.js گرفته شده است:
// MEMORY EXTRACTION LOGIC
async function extractMemoriesAsync(userMessage, userId, messageId) {
const extractionPrompt = `
Analyze the following user message. A memory profile is being built for this user.
Extract ANY explicit facts (Facts), preferences (Pref), or implicit behavioral traits/styles (Implicit).
Return the result as a raw JSON array of objects (NO Markdown blocks, just the JSON array).
Format: [{"content": "string fact/sentence", "type": "FACT|PREF|IMPLICIT", "category": "General|Travel|Hobby|Persona"}]
If nothing is found, return [].
Message: "${userMessage}"
`;
const result = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: extractionPrompt
});
let rawJson = result.text.replace(/^```json/g, '').replace(/```$/g, '').trim();
let extracted;
try {
extracted = JSON.parse(rawJson);
} catch (e) {
console.warn("Could not parse extracted JSON:", rawJson);
return;
}
if (Array.isArray(extracted) && extracted.length > 0) {
// Compute embeddings and save each to the DB
for (const memory of extracted) {
const embedRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: memory.content,
config: { outputDimensionality: 768 },
});
const vectorData = `[${embedRes.embeddings[0].values.join(',')}]`;
await pool.query(
`INSERT INTO memories (user_id, content, memory_type, category, embedding, source_message_id)
VALUES ($1, $2, $3, $4, $5, $6)`,
[userId, memory.content, memory.type.toUpperCase(), memory.category, vectorData, messageId]
);
console.log(`Saved new memory: ${memory.content}`);
}
}
}
چگونه کار میکند؟
- هوش مصنوعی نسل بعدی (خروجی ساختاریافته) : این برنامه از مدل فوقالعاده سریع
gemini-2.5-flashبرای تجزیه و تحلیل پیام کاربر و استخراج حقایق و ترجیحات ساختاریافته به عنوان یک آرایه JSON استفاده میکند. - Cloud SQL (ذخیرهسازی ترکیبی) : پس از ایجاد جاسازیها برای این حقایق جدید، آنها در Cloud SQL ذخیره میشوند. توجه داشته باشید که دادههای رابطهای استاندارد (شناسه کاربری، محتوای متن، دستهها) درست در کنار دادههای برداری با ابعاد بالا در یک ردیف ذخیره میشوند.
- نتیجه : این برنامه یک پروفایل حافظه خود-بهروزشونده را به صورت بلادرنگ ایجاد میکند و از قدرت تحلیلی Gemini و قابلیتهای ذخیرهسازی Cloud SQL بهره میبرد.
۷. برنامه چت را اجرا کنید
- پایگاه داده را با چند کاربر نمونه راهاندازی کنید
npm run seed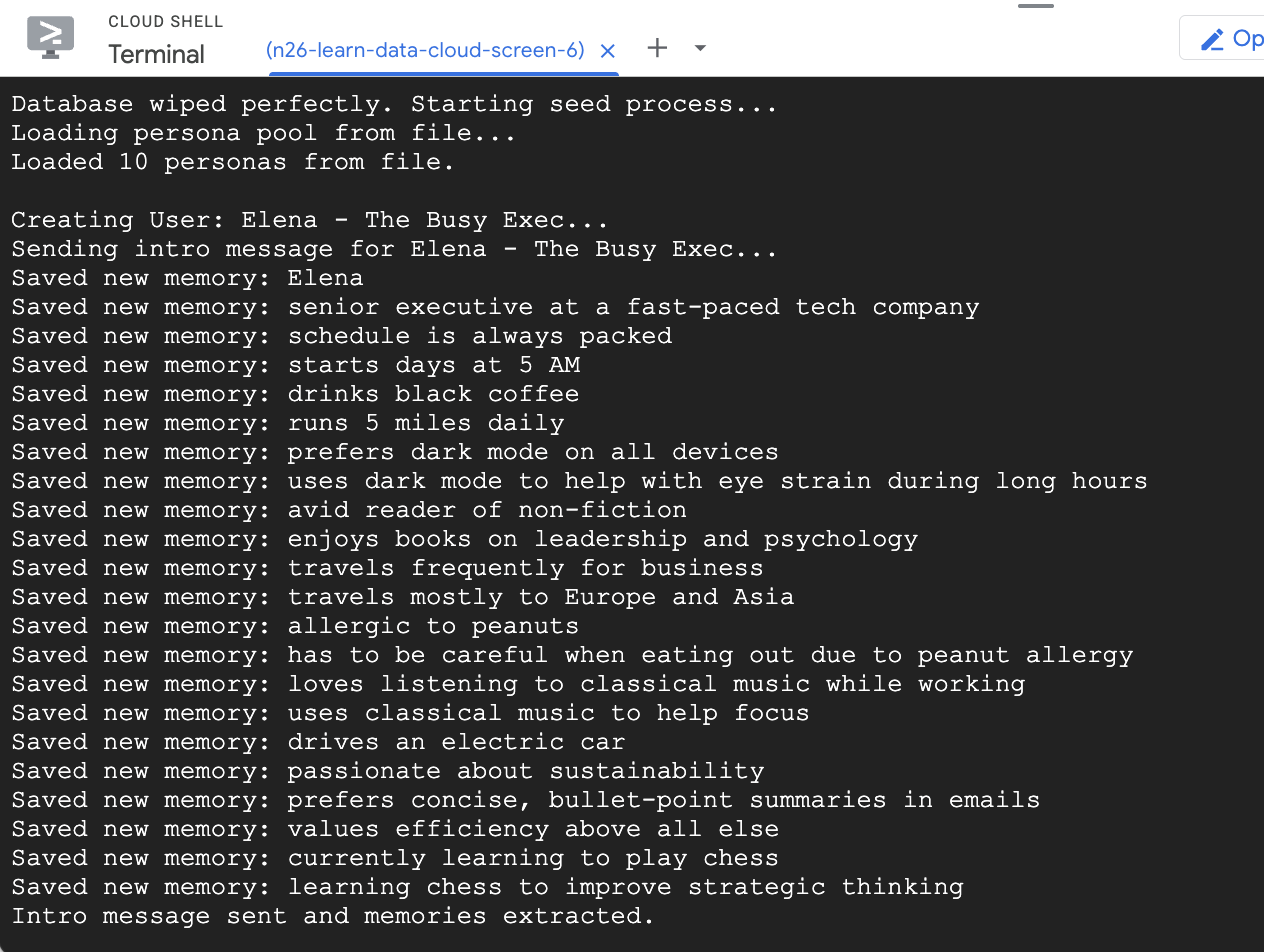
- سپس سرور را اجرا کنید
node server.js - در Cloud Shell، روی پیشنمایش وب در سمت راست بالای نوار ابزار ترمینال کلیک کنید و تغییر پورت را انتخاب کنید.
3000برای شماره پورت وارد کنید و روی تغییر و پیشنمایش کلیک کنید.
تعامل با دستیار
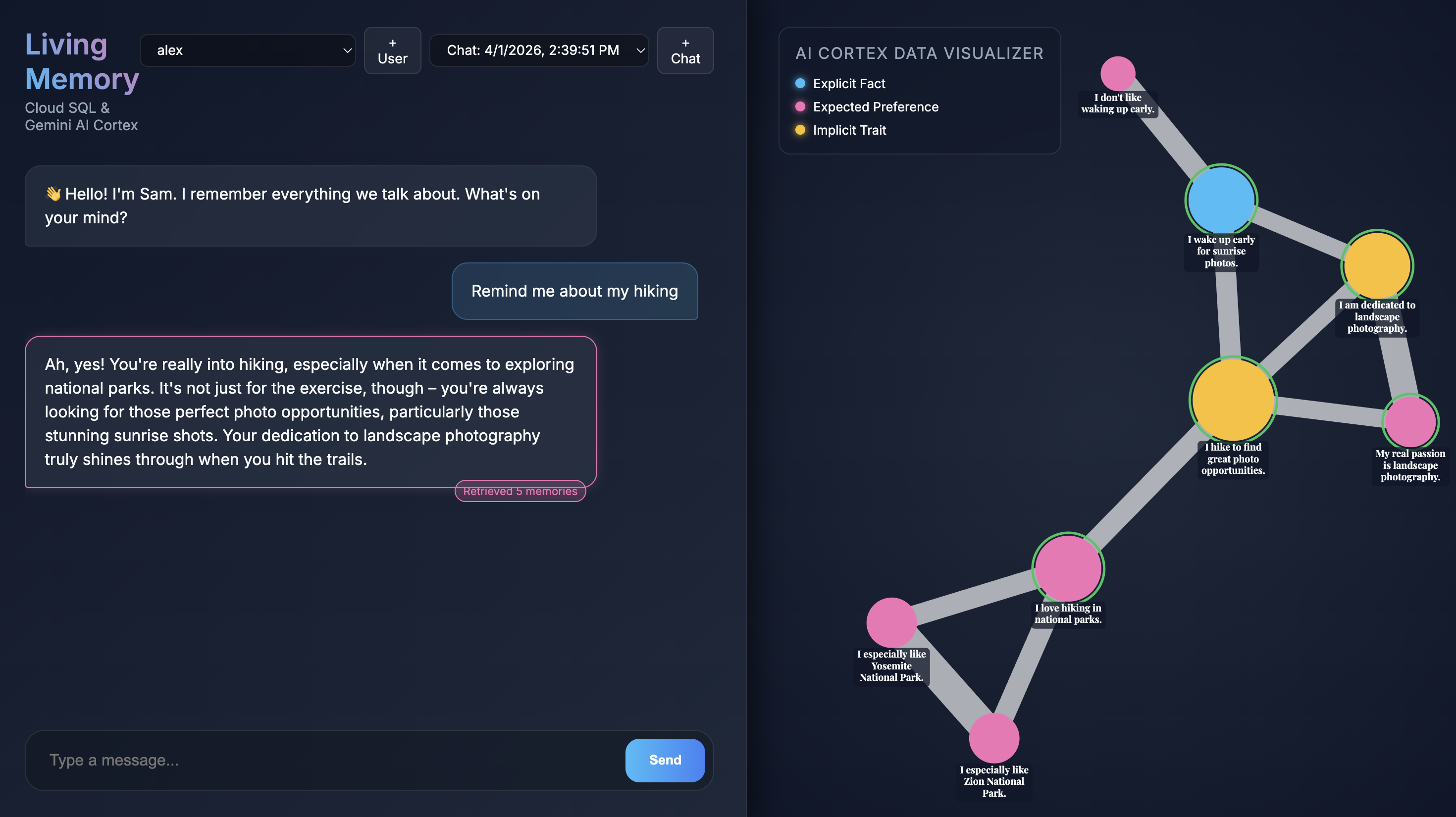
وقتی برنامه در مرورگر شما باز میشود، رابط چت Living Memory را مشاهده خواهید کرد. در سمت راست، AI Cortex Data Visualizer خاطرات را به صورت گرههایی در یک فضای برداری نمایش میدهد که بر اساس نوع (واقعیت، ترجیح، ویژگی ضمنی) با رنگ کدگذاری شدهاند. متن روی گرههای حافظه ممکن است بسته به وضوح صفحه نمایش شما کوچک باشد. برای مشاهده دقیقتر، از ماوس یا ترکپد خود برای بزرگنمایی و حرکت استفاده کنید.
پرس و جو از حافظههای موجود
اسکریپت seed که قبلاً اجرا کردید، دو کاربر نمونه با تعدادی حافظه از پیش پر شده ایجاد کرد.
- از منوی کشویی کاربر در بالا سمت چپ، یک کاربر را انتخاب کنید.
- از یکی از دکمههای چت سریع استفاده کنید یا عبارت
Give me restaurant recommendations in New York Cityرا در ورودی چت تایپ کنید و دکمه ارسال را فشار دهید. - وقتی دستیار پاسخ میدهد، میتوانید روی پیام دستیار کلیک کنید تا ببینید از کدام حافظهها استفاده کرده است. آنها با رنگ سبز هایلایت میشوند و میتوانید روی آنها زوم کنید و ببینید که چگونه به شکلگیری پاسخ کمک کردهاند.
ایجاد یک کاربر جدید
حالا، بیایید یک کاربر جدید ایجاد کنیم.
- برای شروع یک جلسه چت جدید، روی دکمه + در کنار منوی کشویی کاربر کلیک کنید.
- از نام و توضیحات تولید شده استفاده کنید یا آنها را برای توصیف خودتان ویرایش کنید.
- روی ایجاد کلیک کنید و ببینید که برنامه شروع به استخراج خاطرات میکند. در حدود 30 ثانیه، باید گرههای جدیدی را در تصویرساز سمت راست مشاهده کنید. این گرهها نشاندهنده حقایق و ترجیحاتی هستند که Gemini از پیام شما استخراج کرده و در پایگاه داده Cloud SQL ذخیره کرده است.
- یک سوال تکمیلی مانند
What food do I like?بپرسید تا ببینید دستیار از خاطرات تازه به دست آمده خود در مکالمه استفاده میکند.
۸. تمیز کردن
برای جلوگیری از هزینههای مداوم برای حساب Google Cloud خود برای منابع استفاده شده در این آزمایشگاه کد، باید منابعی را که ایجاد کردهاید حذف کنید.
- نمونه Cloud SQL را حذف کنید:
gcloud sql instances delete $INSTANCE_NAME --quiet - مخزن نسخه آزمایشی را حذف کنید:
rm -rf ~/devrel-demos
۹. تبریک
شما با موفقیت یک دستیار هوش مصنوعی «حافظه زنده» ساختید و مستقر کردید!
آنچه آموختهاید
- نحوه استفاده از Cloud SQL pgvector برای جستجوی معنایی.
- نحوه استفاده از Gemini برای استخراج حافظه پویا.
مراحل بعدی
- مستندات Cloud SQL pgvector را بررسی کنید.
- درباره قابلیتهای API جمینی بیشتر بدانید.
- بررسی عمیق پروکسی احراز هویت Cloud SQL .
- سعی کنید
extractionPromptرا درserver.jsسفارشی کنید تا انواع مختلف داده را استخراج کنید!
از ساختن با Living Memory لذت ببرید!