
1. Introduction
Dans cet atelier de programmation, vous allez apprendre à créer la démonstration Living Memory, un assistant optimisé par l'IA qui suit les "souvenirs" de votre conversation pour vous offrir une expérience personnalisée.
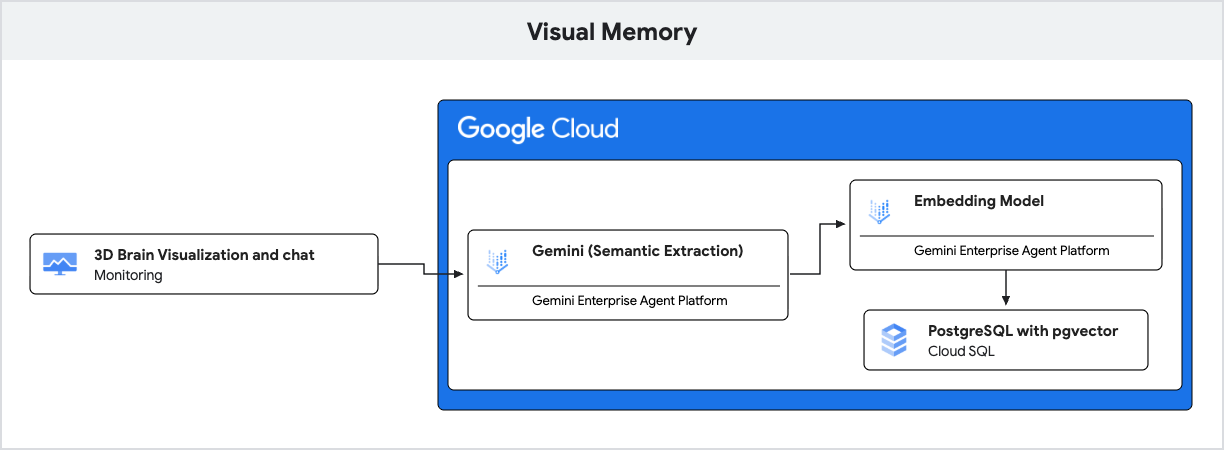
L'application utilise Gemini pour la compréhension du langage naturel et Cloud SQL pour PostgreSQL avec l'extension pgvector pour stocker et récupérer ces souvenirs en fonction de leur similarité sémantique.
Cet atelier de programmation s'adresse aux développeurs de tous niveaux qui s'intéressent à l'IA et aux bases de données. Il devrait vous prendre environ 60 minutes. Les ressources créées doivent coûter moins de 5 $.
Objectifs de l'atelier
- Configurer une instance Cloud SQL pour PostgreSQL avec la prise en charge de
pgvector - Découvrez comment utiliser Gemini pour extraire de manière interactive des "souvenirs" des messages des utilisateurs.
- Découvrez comment effectuer des recherches vectorielles dans PostgreSQL pour récupérer le contexte pertinent pour les réponses de l'IA.
Prérequis
- Un projet Google Cloud avec facturation activée.
- Connaissances de base de la ligne de commande et de Node.js
2. Avant de commencer
Configuration du projet
Créer un projet Google Cloud
- Dans la console Google Cloud, sur la page de sélection du projet, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud. Découvrez comment vérifier si la facturation est activée sur un projet.
Démarrer Cloud Shell
Cloud Shell est un environnement de ligne de commande exécuté dans Google Cloud et fourni avec les outils nécessaires.
- Cliquez sur Activer Cloud Shell en haut de la console Google Cloud.
- Une fois connecté à Cloud Shell, vérifiez votre authentification :
gcloud auth list - Vérifiez que votre projet est configuré :
gcloud config get project - Si votre projet n'est pas défini comme prévu, définissez-le :
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Activer les API
Exécutez la commande suivante dans Cloud Shell pour activer les API requises :
gcloud services enable sqladmin.googleapis.com \
aiplatform.googleapis.com
3. Cloner le dépôt de démonstration
Maintenant, récupérez le code de la démo Living Memory.
- Clonez le dépôt dans votre environnement Cloud Shell :
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git cd devrel-demos/codelabs/visual-memory-postgres-demo - Installez les dépendances :
npm install
4. Créer et configurer la base de données Cloud SQL
Dans cette section, vous allez créer une instance Cloud SQL, initialiser une base de données et configurer le schéma.
- L'application utilise des variables d'environnement pour la configuration. Exécutez le bloc suivant dans votre terminal Cloud Shell pour définir les variables requises pour cette session :
export REGION="us-central1" export INSTANCE_NAME="living-memory-db" export DB_HOST=127.0.0.1 export DB_PORT=5432 export DB_USER=memory_app export DB_PASS=memory_app_password export DB_NAME=living_memory export PGPASSWORD=$DB_PASS - Créez l'instance. Cette étape prend généralement entre cinq et dix minutes.
gcloud sql instances create $INSTANCE_NAME \ --database-version=POSTGRES_16 \ --cpu=1 \ --memory=3840MB \ --region=$REGION \ --root-password=$DB_PASS \ --edition=ENTERPRISEvectoret crée plusieurs tables pour prendre en charge l'application :
users,conversations,messages: tables standards pour stocker les profils utilisateur et l'historique des conversations.memories: il s'agit de la table principale pour la génération augmentée par récupération (RAG). Chaque ligne représente une information extraite de la conversation (par exemple, "L'utilisateur aime la randonnée"). Il stocke les informations suivantes :content: texte du souvenir.memory_type: type de mémoire (FACT,PREFouIMPLICIT).embedding: colonnevectorde 768 dimensions contenant la représentation sémantique du contenu, générée par Gemini.
pgvectorIndex : un indexHNSW(Hierarchical Navigable Small World) est créé sur la colonneembedding. C'est essentiel pour optimiser les recherches des k plus proches voisins (k-NN), ce qui permet àpgvectorde trouver rapidement les souvenirs les plus proches sur le plan sémantique à l'aide de l'opérateur de distance cosinus (<=>).
- Créer la base de données
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME - Créer l'utilisateur de l'application
gcloud sql users create $DB_USER --instance=$INSTANCE_NAME --password=$DB_PASS - Démarrez le proxy d'authentification Cloud SQL. Le proxy fournit un accès sécurisé à votre instance sans avoir besoin de configurer l'ajout d'adresses IP à la liste d'autorisation.
(cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:us-central1:living-memory-db &) && sleep 2 && echo ""The proxy has started successfully and is ready for new connections!. - Appliquez
schema.sqlpour activer l'extensionvectoret créer les tables nécessaires. Le proxy étant en cours d'exécution, vous pouvez maintenant vous connecter à votre instance à l'adresse127.0.0.1.psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME < schema.sql - Vérifiez que le schéma a bien été créé.
psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME -c "\dt"conversations,memories,messagesetusers.List of relations Schema | Name | Type | Owner --------+---------------+-------+------------ public | conversations | table | memory_app public | memories | table | memory_app public | messages | table | memory_app public | queries_log | table | memory_app public | users | table | memory_app (5 rows)
5. Comprendre la récupération sémantique avec pgvector
Dans cette section, vous allez examiner comment l'application récupère le contexte pertinent pour l'IA avant de générer une réponse. L'extrait suivant de server.js montre le code responsable de cette opération dans le point de terminaison /api/chat :
// Retrieve Similar Memories for Context (Using pgvector)
const promptEmbeddingRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: message,
config: { outputDimensionality: 768 },
});
const promptEmbedding = promptEmbeddingRes.embeddings[0].values;
const embeddingStr = `[${promptEmbedding.join(',')}]`;
// Query DB for top 5 closest memories
const relevantMemories = await pool.query(
`SELECT id, content, memory_type, category
FROM memories
WHERE user_id = $1
ORDER BY embedding <=> $2::vector
LIMIT 5`,
[userId, embeddingStr]
);
Fonctionnement
- IA générative (embedding) : l'application prend le message entrant de l'utilisateur et utilise le modèle
gemini-embedding-001pour convertir le texte en vecteur de 768 dimensions. Ce vecteur représente la signification sémantique du message. - Cloud SQL (pgvector) : l'application transmet ce vecteur à Cloud SQL. À l'aide de l'opérateur
<=>(distance cosinus) fourni par l'extensionpgvector, Cloud SQL trouve les cinq souvenirs les plus proches sémantiquement de la requête. - Résultat : il s'agit de la génération augmentée par récupération (RAG). L'IA accède à des souvenirs spécifiques et pertinents de la base de données pour personnaliser sa réponse, sans avoir besoin de charger l'intégralité de l'historique.
6. Comprendre l'extraction de mémoire
Ensuite, examinez comment l'application apprend de la conversation. L'extrait suivant provient de la fonction extractMemoriesAsync dans server.js :
// MEMORY EXTRACTION LOGIC
async function extractMemoriesAsync(userMessage, userId, messageId) {
const extractionPrompt = `
Analyze the following user message. A memory profile is being built for this user.
Extract ANY explicit facts (Facts), preferences (Pref), or implicit behavioral traits/styles (Implicit).
Return the result as a raw JSON array of objects (NO Markdown blocks, just the JSON array).
Format: [{"content": "string fact/sentence", "type": "FACT|PREF|IMPLICIT", "category": "General|Travel|Hobby|Persona"}]
If nothing is found, return [].
Message: "${userMessage}"
`;
const result = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: extractionPrompt
});
let rawJson = result.text.replace(/^```json/g, '').replace(/```$/g, '').trim();
let extracted;
try {
extracted = JSON.parse(rawJson);
} catch (e) {
console.warn("Could not parse extracted JSON:", rawJson);
return;
}
if (Array.isArray(extracted) && extracted.length > 0) {
// Compute embeddings and save each to the DB
for (const memory of extracted) {
const embedRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: memory.content,
config: { outputDimensionality: 768 },
});
const vectorData = `[${embedRes.embeddings[0].values.join(',')}]`;
await pool.query(
`INSERT INTO memories (user_id, content, memory_type, category, embedding, source_message_id)
VALUES ($1, $2, $3, $4, $5, $6)`,
[userId, memory.content, memory.type.toUpperCase(), memory.category, vectorData, messageId]
);
console.log(`Saved new memory: ${memory.content}`);
}
}
}
Fonctionnement
- IA générative (résultat structuré) : l'application utilise le modèle
gemini-2.5-flashultra-rapide pour analyser le message de l'utilisateur et extraire les faits et préférences structurés sous forme de tableau JSON. - Cloud SQL (stockage hybride) : une fois les embeddings générés pour ces nouveaux faits, ils sont stockés dans Cloud SQL. Notez que les données relationnelles standards (ID utilisateur, contenu textuel, catégories) sont stockées juste à côté des données vectorielles de grande dimension dans une même ligne.
- Résultat : l'application crée un profil de mémoire auto-actualisé en temps réel, en tirant parti à la fois de la puissance analytique de Gemini et des capacités de stockage de Cloud SQL.
7. Exécuter l'application de chat
- Remplir la base de données avec quelques exemples d'utilisateurs
npm run seed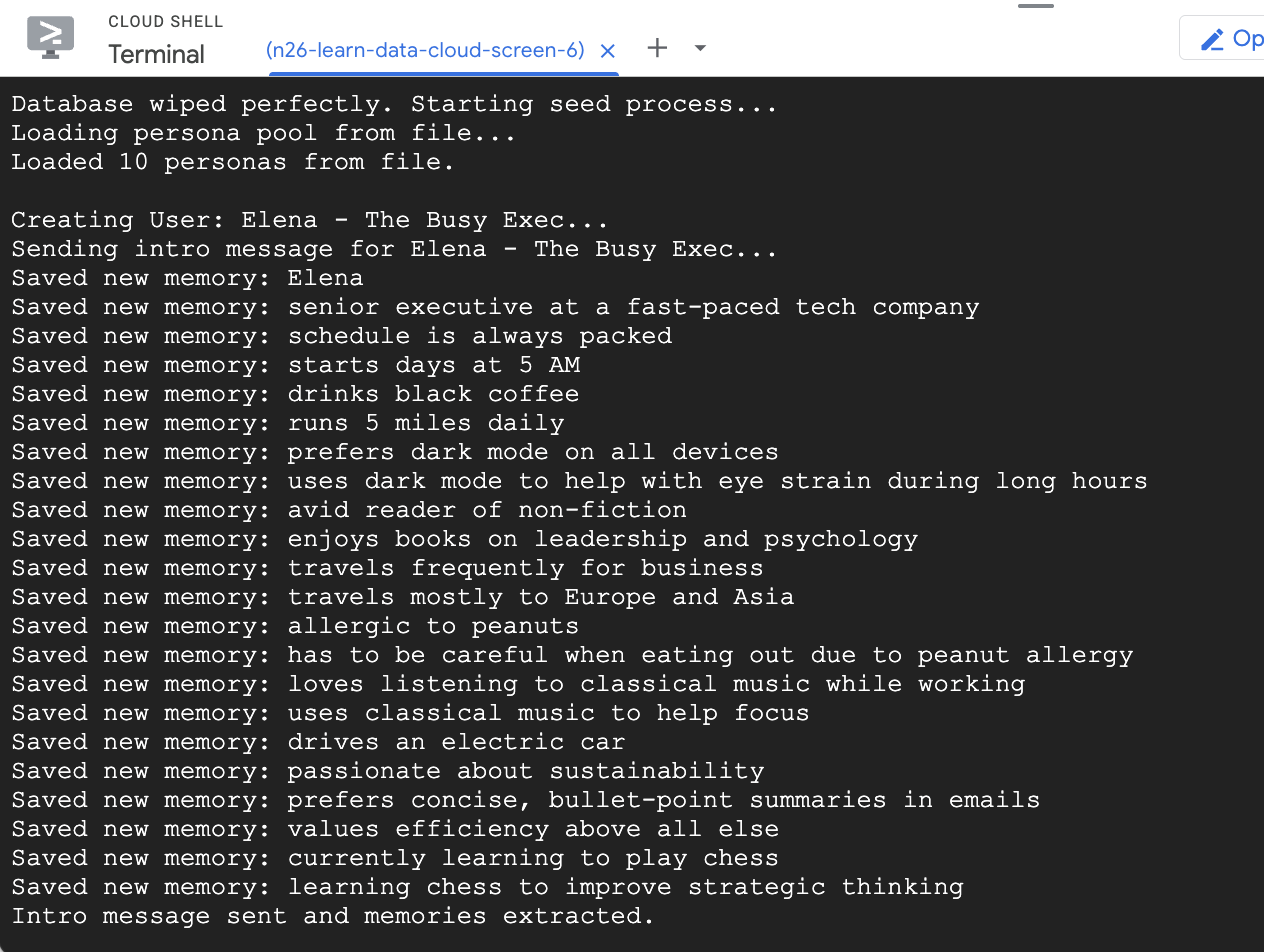
- Exécutez ensuite le serveur.
node server.js - Dans Cloud Shell, cliquez sur Aperçu sur le Web en haut à droite de la barre d'outils du terminal, puis sélectionnez Modifier le port. Saisissez
3000pour le numéro de port, puis cliquez sur Modifier et prévisualiser.
Interagir avec l'assistant
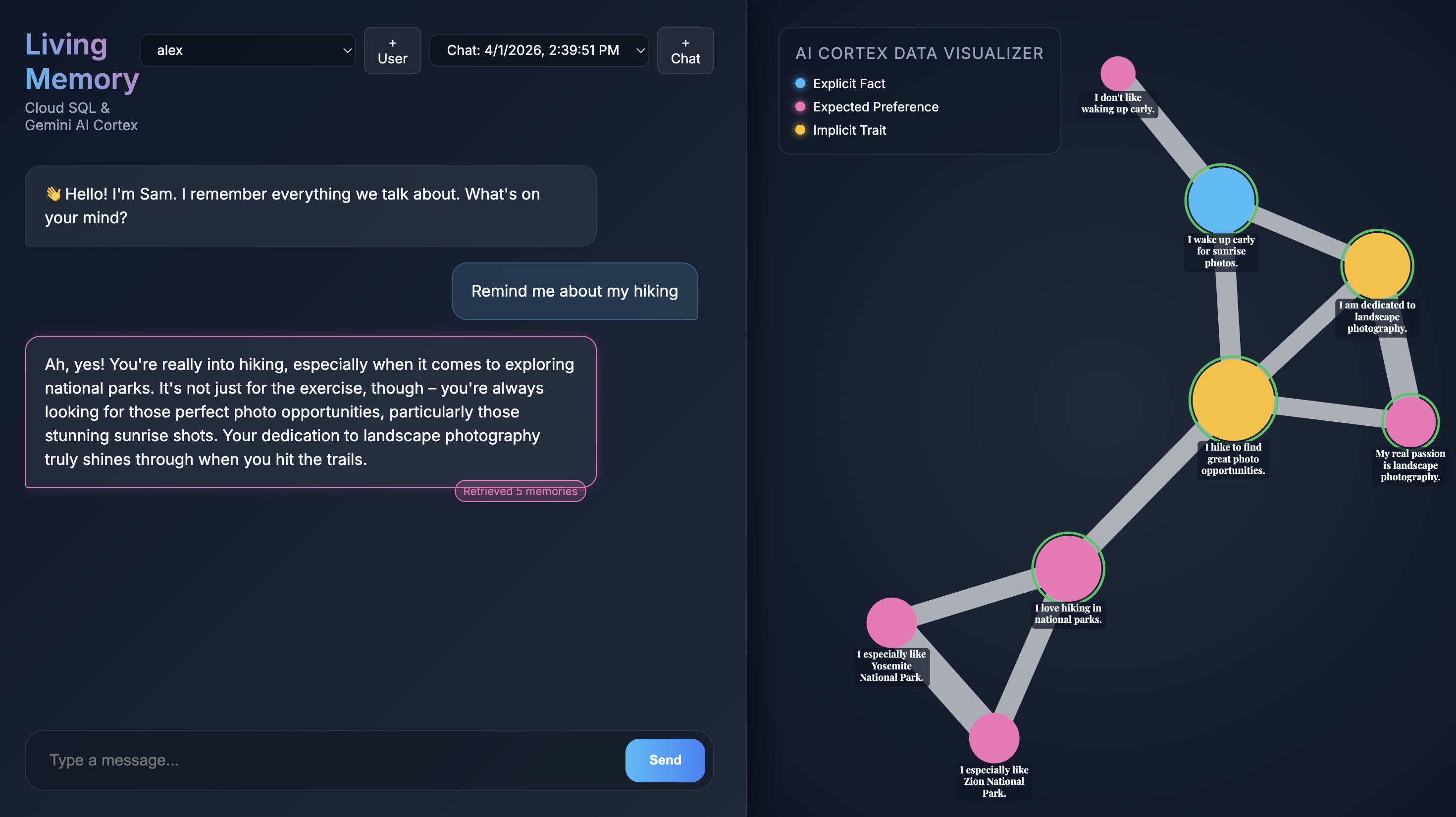
Lorsque l'application s'ouvre dans votre navigateur, l'interface de chat Living Memory s'affiche. À droite, le visualiseur de données AI Cortex affiche les souvenirs sous forme de nœuds dans un espace vectoriel, avec un code couleur en fonction du type (fait, préférence, trait implicite). Le texte sur les nœuds de mémoire peut être petit en fonction de la résolution de votre écran. Utilisez votre souris ou votre pavé tactile pour faire un zoom avant ou arrière et vous déplacer dans la vue.
Interroger les souvenirs existants
Le script seed que vous avez exécuté précédemment a créé deux exemples d'utilisateurs avec des souvenirs préremplis.
- Sélectionnez un utilisateur dans le menu déroulant en haut à gauche.
- Utilisez l'un des boutons de chat rapide ou saisissez
Give me restaurant recommendations in New York Citydans le champ de saisie du chat, puis appuyez sur Envoyer. - Lorsque l'assistant répond, vous pouvez cliquer sur son message pour voir les infos mémorisées qu'il a utilisées. Ils seront mis en évidence en vert. Vous pourrez faire un zoom avant sur eux et voir comment ils ont contribué à la réponse.
Créer un utilisateur
Maintenant, créons un utilisateur.
- Cliquez sur le bouton + à côté du menu déroulant des utilisateurs pour démarrer une session de chat.
- Utilisez le nom et la description générés, ou modifiez-les pour vous décrire.
- Cliquez sur Créer et regardez l'application commencer à extraire des souvenirs. Au bout d'environ 30 secondes, de nouveaux nœuds devraient apparaître dans le visualiseur à droite. Elles représentent les faits et les préférences que Gemini a extraits de votre message et stockés dans la base de données Cloud SQL.
- Posez une question complémentaire, comme
What food do I like?, pour voir l'assistant utiliser ses nouvelles connaissances dans la conversation.
8. Effectuer un nettoyage
Pour éviter que les ressources utilisées dans cet atelier de programmation soient facturées en permanence sur votre compte Google Cloud, supprimez celles que vous avez créées.
- Supprimez l'instance Cloud SQL :
gcloud sql instances delete $INSTANCE_NAME --quiet - Supprimez le dépôt de démonstration :
rm -rf ~/devrel-demos
9. Félicitations
Vous avez réussi à créer et à déployer un assistant IA "Living Memory" !
Connaissances acquises
- Utiliser Cloud SQL pgvector pour la recherche sémantique
- Découvrez comment utiliser Gemini pour extraire la mémoire dynamique.
Étapes suivantes
- Consultez la documentation Cloud SQL pgvector.
- En savoir plus sur les fonctionnalités de l'API Gemini
- Découvrez en détail le proxy d'authentification Cloud SQL.
- Essayez de personnaliser
extractionPromptdansserver.jspour extraire différents types de données.
Profitez de la construction avec Living Memory !