
1. מבוא
בשיעור Codelab הזה נסביר איך ליצור את הדמו של Living Memory, עוזר וירטואלי מבוסס-AI שעוקב אחרי 'זיכרונות' מהשיחה כדי לספק חוויה בהתאמה אישית.
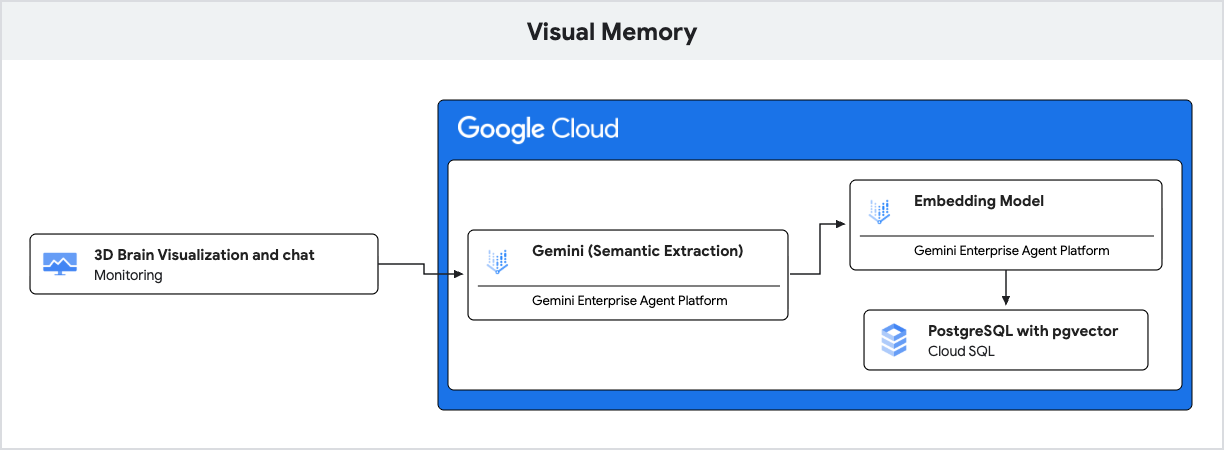
האפליקציה משתמשת ב-Gemini להבנת שפה טבעית וב-Cloud SQL ל-PostgreSQL עם התוסף pgvector כדי לאחסן את הזיכרונות האלה ולאחזר אותם על סמך דמיון סמנטי.
ה-Codelab הזה מיועד למפתחים בכל רמות המיומנות שמתעניינים ב-AI ובמסדי נתונים, והוא אמור להימשך כ-60 דקות. העלות של המשאבים שנוצרו צריכה להיות פחות מ-5$.
הפעולות שתבצעו:
- איך מגדירים מכונת Cloud SQL ל-PostgreSQL עם תמיכה ב-
pgvector. - איך משתמשים ב-Gemini כדי לחלץ באופן אינטראקטיבי 'זיכרונות' מהודעות של משתמשים.
- איך מבצעים חיפושי וקטורים ב-PostgreSQL כדי לאחזר הקשר רלוונטי לתשובות מבוססות-AI.
הדרישות
- פרויקט ב-Google Cloud שהחיוב בו מופעל.
- ידע בסיסי בשורת הפקודה וב-Node.js.
2. לפני שמתחילים
הגדרת הפרויקט
יצירת פרויקט ב-Google Cloud
- במסוף Google Cloud, בדף לבחירת הפרויקט, בוחרים פרויקט ב-Google Cloud או יוצרים פרויקט.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud. כך בודקים אם החיוב מופעל בפרויקט
הפעלת Cloud Shell
Cloud Shell היא סביבת שורת פקודה שפועלת ב-Google Cloud, וכוללת מראש את הכלים הדרושים.
- לוחצים על Activate Cloud Shell בחלק העליון של מסוף Google Cloud.
- אחרי שמתחברים ל-Cloud Shell, מאמתים את האימות:
gcloud auth list - מוודאים שהפרויקט מוגדר:
gcloud config get project - אם הפרויקט לא מוגדר כמו שציפיתם, מגדירים אותו:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
הפעלת ממשקי ה-API
מריצים את הפקודה הבאה ב-Cloud Shell כדי להפעיל את ממשקי ה-API הנדרשים:
gcloud services enable sqladmin.googleapis.com \
aiplatform.googleapis.com
3. שכפול מאגר ההדגמה
עכשיו, מעתיקים את הקוד של הדמו של הזיכרון החי.
- משכפלים את המאגר לסביבת Cloud Shell:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git cd devrel-demos/codelabs/visual-memory-postgres-demo - מתקינים את יחסי התלות:
npm install
4. יצירה והגדרה של מסד הנתונים ב-Cloud SQL
בקטע הזה תיצרו מכונה של Cloud SQL, תאתחלו מסד נתונים ותגדירו את הסכימה.
- האפליקציה משתמשת במשתני סביבה לצורך הגדרה. מריצים את הבלוק הבא במסוף Cloud Shell כדי להגדיר את המשתנים הנדרשים לסשן הזה:
export REGION="us-central1" export INSTANCE_NAME="living-memory-db" export DB_HOST=127.0.0.1 export DB_PORT=5432 export DB_USER=memory_app export DB_PASS=memory_app_password export DB_NAME=living_memory export PGPASSWORD=$DB_PASS - יוצרים את המופע. השלב הזה נמשך בדרך כלל 5-10 דקות.
gcloud sql instances create $INSTANCE_NAME \ --database-version=POSTGRES_16 \ --cpu=1 \ --memory=3840MB \ --region=$REGION \ --root-password=$DB_PASS \ --edition=ENTERPRISEvectorויוצר כמה טבלאות לתמיכה באפליקציה:
-
users,conversations,messages: טבלאות סטנדרטיות לאחסון פרופילי משתמשים והיסטוריית שיחות. -
memories: זהו טבלת הליבה של Retrieval-Augmented Generation (יצירה משולבת-אחזור, RAG). כל שורה מייצגת פיסת מידע שחולצה מהשיחה (לדוגמה, 'המשתמש אוהב טיולים'). בהיסטוריית הפעילות נשמרים:-
content: הטקסט של הזיכרון. -
memory_type: סוג הזיכרון (FACT,PREFאוIMPLICIT). -
embedding: עמודהvectorעם 768 ממדים שמכילה את הייצוג הסמנטי של התוכן, שנוצר על ידי Gemini.
-
-
pgvectorאינדקס: נוצר אינדקסHNSW(Hierarchical Navigable Small World) בעמודהembedding. הפעולה הזו חיונית לאופטימיזציה של חיפושים לפי k-Nearest Neighbor (k-NN), ומאפשרת ל-pgvectorלמצוא במהירות את הזיכרונות הכי דומים מבחינה סמנטית באמצעות האופרטור של מרחק הקוסינוס (<=>).
-
- יצירת מסד הנתונים
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME - יצירת משתמש האפליקציה
gcloud sql users create $DB_USER --instance=$INSTANCE_NAME --password=$DB_PASS - מפעילים את שרת ה-proxy ל-Cloud SQL Auth. הפרוקסי מספק גישה מאובטחת למופע בלי צורך בהגדרת רשימת כתובות IP שאפשר לגשת אליהן.
(cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:us-central1:living-memory-db &) && sleep 2 && echo ""The proxy has started successfully and is ready for new connections!. - מפעילים את התוסף
vectorבאמצעות הפקודהschema.sqlויוצרים את הטבלאות הנדרשות. שרת ה-proxy פועל, ולכן עכשיו אפשר להתחבר למופע בכתובת127.0.0.1.psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME < schema.sql - מוודאים שהסכמה נוצרה בהצלחה.
psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME -c "\dt"conversations,memories,messagesו-users.List of relations Schema | Name | Type | Owner --------+---------------+-------+------------ public | conversations | table | memory_app public | memories | table | memory_app public | messages | table | memory_app public | queries_log | table | memory_app public | users | table | memory_app (5 rows)
5. הסבר על אחזור סמנטי באמצעות pgvector
בקטע הזה נבדוק איך האפליקציה מאחזרת הקשר רלוונטי ל-AI לפני יצירת תשובה. קטע הקוד הבא מתוך server.js מציג את הקוד שאחראי לכך בנקודת הקצה /api/chat:
// Retrieve Similar Memories for Context (Using pgvector)
const promptEmbeddingRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: message,
config: { outputDimensionality: 768 },
});
const promptEmbedding = promptEmbeddingRes.embeddings[0].values;
const embeddingStr = `[${promptEmbedding.join(',')}]`;
// Query DB for top 5 closest memories
const relevantMemories = await pool.query(
`SELECT id, content, memory_type, category
FROM memories
WHERE user_id = $1
ORDER BY embedding <=> $2::vector
LIMIT 5`,
[userId, embeddingStr]
);
איך זה עובד
- AI גנרטיבי (הטמעה): האפליקציה מקבלת את ההודעה הנכנסת של המשתמש ומשתמשת במודל
gemini-embedding-001כדי להמיר את הטקסט לווקטור עם 768 ממדים. הווקטור הזה מייצג את המשמעות הסמנטית של ההודעה. - Cloud SQL (pgvector): האפליקציה מעבירה את הווקטור הזה ל-Cloud SQL. באמצעות האופרטור
<=>(מרחק קוסינוס) שסופק על ידי התוסףpgvector, Cloud SQL מוצא את 5 הזיכרונות שהכי דומים סמנטית להנחיה. - התוצאה: זהו תהליך של Retrieval-Augmented Generation (יצירה משולבת-אחזור, RAG). ה-AI מקבל גישה לזיכרונות ספציפיים ורלוונטיים ממסד הנתונים כדי להתאים אישית את התשובה שלו, בלי שהוא צריך לטעון את כל ההיסטוריה.
6. הסבר על חילוץ זיכרון
בשלב הבא, נראה איך האפליקציה לומדת מהשיחה. קטע הקוד הבא הוא מהפונקציה extractMemoriesAsync ב-server.js:
// MEMORY EXTRACTION LOGIC
async function extractMemoriesAsync(userMessage, userId, messageId) {
const extractionPrompt = `
Analyze the following user message. A memory profile is being built for this user.
Extract ANY explicit facts (Facts), preferences (Pref), or implicit behavioral traits/styles (Implicit).
Return the result as a raw JSON array of objects (NO Markdown blocks, just the JSON array).
Format: [{"content": "string fact/sentence", "type": "FACT|PREF|IMPLICIT", "category": "General|Travel|Hobby|Persona"}]
If nothing is found, return [].
Message: "${userMessage}"
`;
const result = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: extractionPrompt
});
let rawJson = result.text.replace(/^```json/g, '').replace(/```$/g, '').trim();
let extracted;
try {
extracted = JSON.parse(rawJson);
} catch (e) {
console.warn("Could not parse extracted JSON:", rawJson);
return;
}
if (Array.isArray(extracted) && extracted.length > 0) {
// Compute embeddings and save each to the DB
for (const memory of extracted) {
const embedRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: memory.content,
config: { outputDimensionality: 768 },
});
const vectorData = `[${embedRes.embeddings[0].values.join(',')}]`;
await pool.query(
`INSERT INTO memories (user_id, content, memory_type, category, embedding, source_message_id)
VALUES ($1, $2, $3, $4, $5, $6)`,
[userId, memory.content, memory.type.toUpperCase(), memory.category, vectorData, messageId]
);
console.log(`Saved new memory: ${memory.content}`);
}
}
}
איך זה עובד
- AI גנרטיבי (פלט מובנה): האפליקציה משתמשת במודל
gemini-2.5-flashהמהיר במיוחד כדי לנתח את ההודעה של המשתמש ולחלץ עובדות והעדפות מובנות כמערך JSON. - Cloud SQL (אחסון היברידי): אחרי יצירת הטמעות לעובדות החדשות האלה, הן מאוחסנות ב-Cloud SQL. שימו לב שנתונים רלציוניים רגילים (מזהה משתמש, תוכן טקסט, קטגוריות) מאוחסנים לצד נתוני הווקטורים הרב-ממדיים בשורה אחת.
- התוצאה: האפליקציה יוצרת פרופיל זיכרון שמתעדכן בעצמו בזמן אמת, תוך שימוש ביכולות הניתוח של Gemini וביכולות האחסון של Cloud SQL.
7. הפעלת אפליקציית הצ'אט
- הוספת כמה משתמשים לדוגמה למסד הנתונים
npm run seed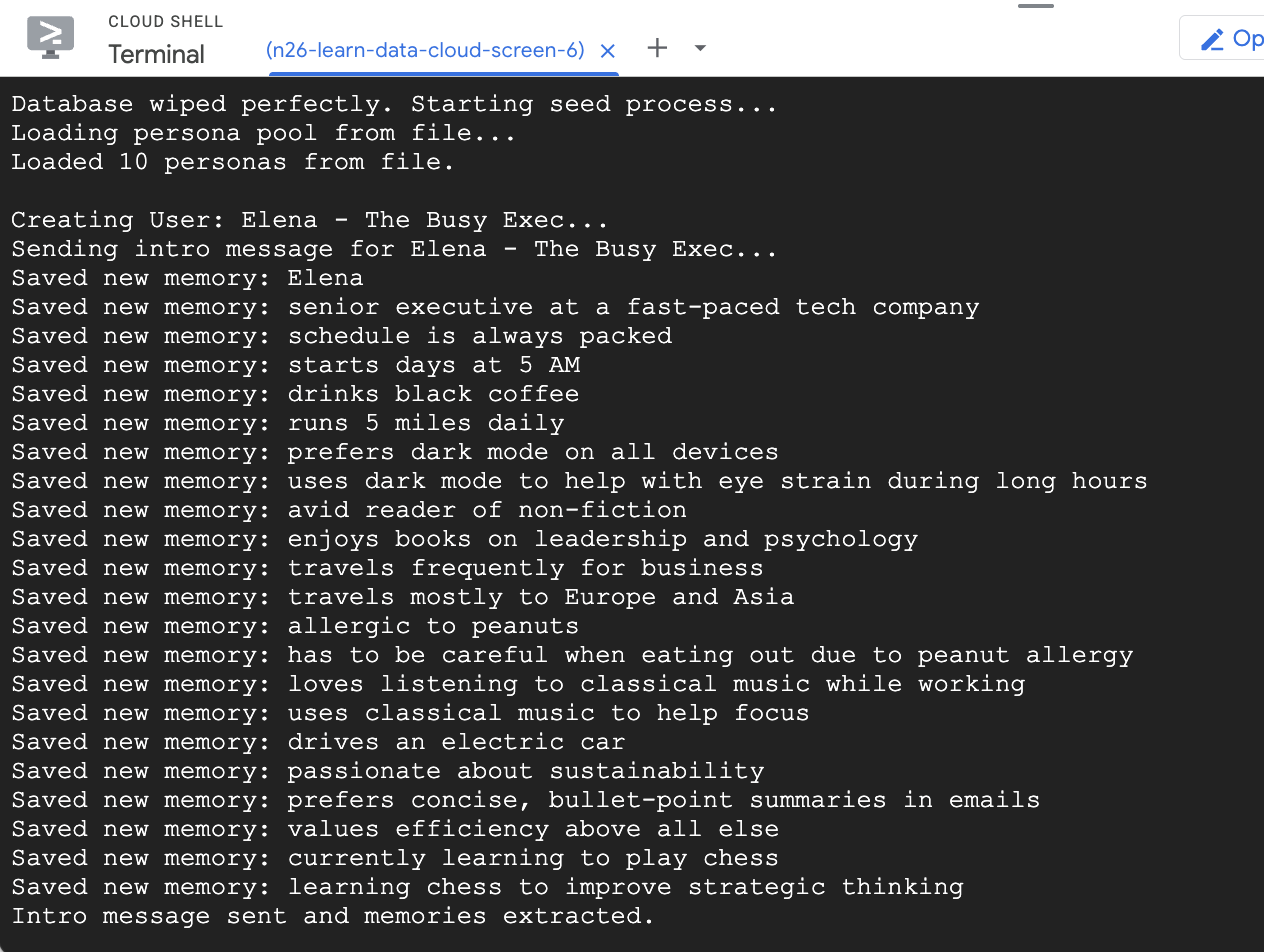
- ואז מריצים את השרת.
node server.js - ב-Cloud Shell, לוחצים על Web Preview (תצוגה מקדימה של אתר) בפינה השמאלית העליונה של סרגל הכלים של הטרמינל, ובוחרים באפשרות Change Port (שינוי יציאה). מזינים
3000בשדה של מספר הניוד ולוחצים על שינוי ותצוגה מקדימה.
איך משתמשים בעוזר הדיגיטלי
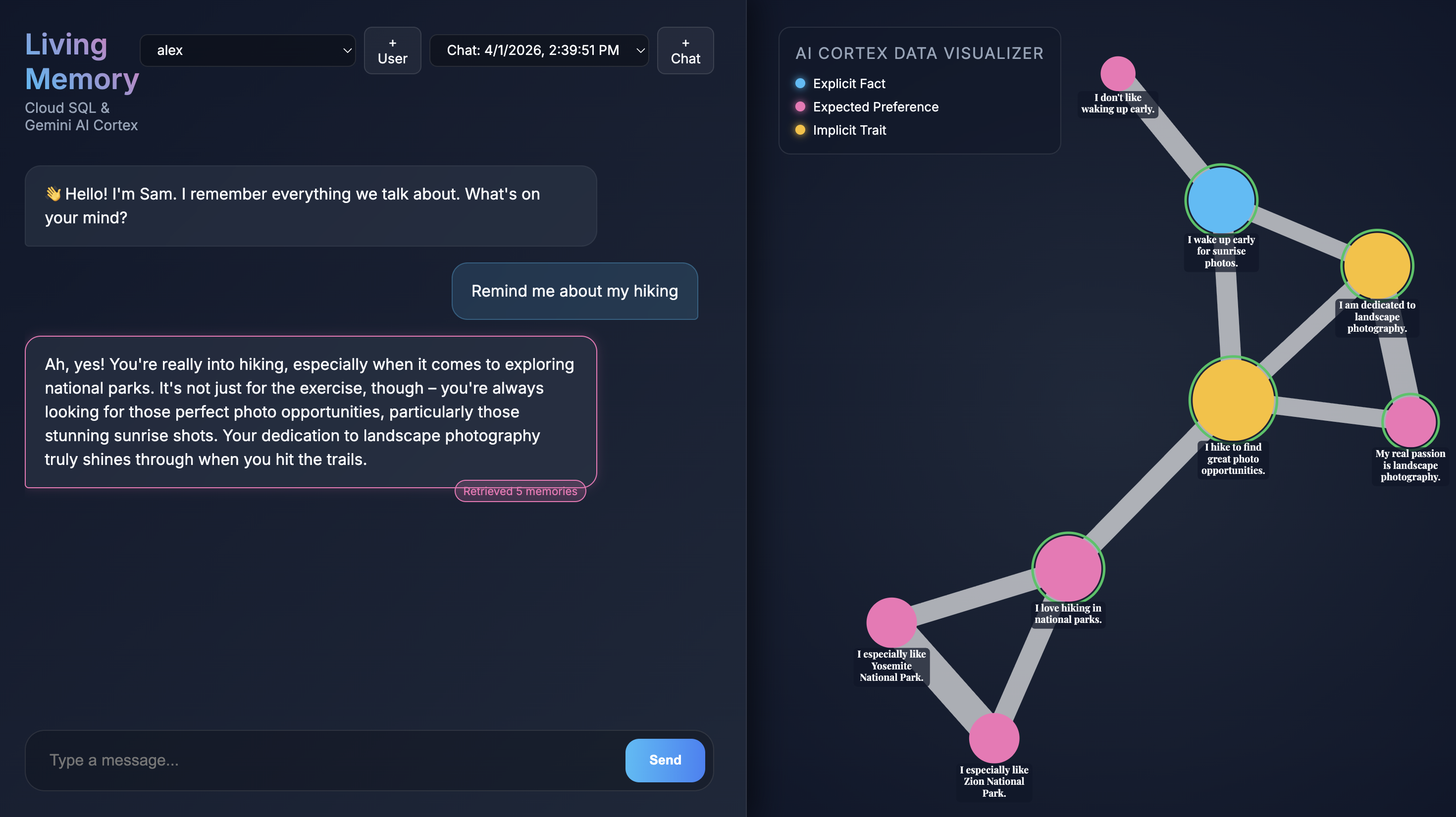
כשהאפליקציה נפתחת בדפדפן, מוצג ממשק הצ'אט של Living Memory. בצד שמאל, כלי ההמחשה של נתוני AI Cortex מציג זיכרונות כצמתים במרחב וקטורי, עם קידוד צבעים לפי סוג (עובדה, העדפה, מאפיין מרומז). הטקסט בצמתי הזיכרון עשוי להיות קטן, בהתאם לרזולוציית המסך. כדי לראות אותו מקרוב, אפשר להשתמש בעכבר או במשטח המגע כדי להתקרב ולהתרחק ולזוז בתצוגה.
שאילתות על זיכרונות קיימים
הסקריפט seed שהרצתם קודם יצר שני משתמשים לדוגמה עם זיכרונות מסוימים שאוכלסו מראש.
- בוחרים משתמש מהתפריט הנפתח של המשתמשים בפינה הימנית העליונה.
- לוחצים על אחד מהלחצנים של הצ'אט המהיר או מקלידים
Give me restaurant recommendations in New York Cityבשדה הקלט של הצ'אט ומקישים על שליחה. - כשהעוזר הדיגיטלי משיב, אפשר ללחוץ על ההודעה שלו כדי לראות באילו זיכרונות הוא השתמש. הם יסומנו בירוק ותוכלו להגדיל אותם ולראות איך הם עזרו ליצור את התשובה.
יצירת משתמש חדש
עכשיו ניצור משתמש חדש.
- לוחצים על הלחצן + לצד התפריט הנפתח של המשתמש כדי להתחיל שיחת צ'אט חדשה.
- אפשר להשתמש בשם ובתיאור שנוצרו או לערוך אותם כדי לתאר את עצמכם.
- לוחצים על יצירה והאפליקציה מתחילה לחלץ זיכרונות. אחרי כ-30 שניות, אמורים להופיע צמתים חדשים בכלי ההמחשה בצד שמאל. הם מייצגים את העובדות וההעדפות ש-Gemini חילץ מההודעה שלכם ושמר במסד הנתונים של Cloud SQL.
- כדי לראות את ה-Assistant משתמש בזיכרונות החדשים שלו בשיחה, אפשר לשאול שאלת המשך כמו
What food do I like?.
8. הסרת המשאבים
כדי להימנע מחיובים שוטפים בחשבון Google Cloud על המשאבים שבהם השתמשתם ב-Codelab הזה, מומלץ למחוק את המשאבים שיצרתם.
- מחיקת המכונה של Cloud SQL:
gcloud sql instances delete $INSTANCE_NAME --quiet - מסירים את מאגר ההדגמה:
rm -rf ~/devrel-demos
9. מזל טוב
יצרת והטמעת בהצלחה עוזר AI עם זיכרון דינמי.
מה למדתם
- איך משתמשים ב-Cloud SQL pgvector לחיפוש סמנטי.
- איך משתמשים ב-Gemini כדי לחלץ זיכרון דינמי.
השלבים הבאים
- מסמכי העזרה של Cloud SQL pgvector
- מידע נוסף על היכולות של Gemini API
- מידע מעמיק על שרת proxy ל-Cloud SQL Auth
- כדאי לנסות להתאים אישית את
extractionPromptב-server.jsכדי לחלץ סוגים שונים של נתונים.
תהנו מהיצירה עם הזיכרון החי!