
1. परिचय
इस कोडलैब में, आपको लिविंग मेमोरी डेमो बनाने का तरीका बताया जाएगा. यह एआई की मदद से काम करने वाली एक ऐसी सुविधा है जो आपकी बातचीत की "यादों" को ट्रैक करती है, ताकि आपको मनमुताबिक अनुभव दिया जा सके.
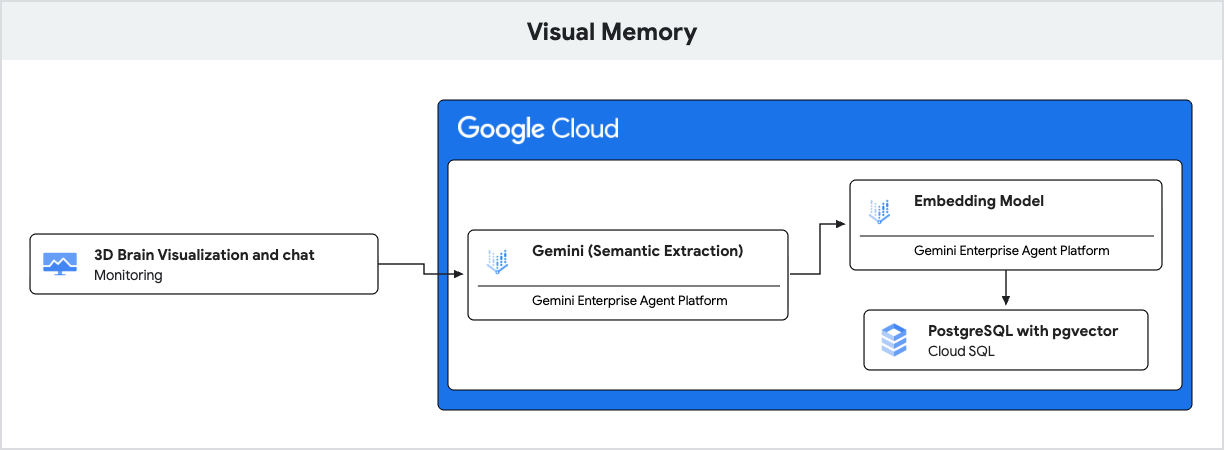
यह ऐप्लिकेशन, नैचुरल लैंग्वेज को समझने के लिए Gemini का इस्तेमाल करता है. साथ ही, Cloud SQL for PostgreSQL के साथ pgvector एक्सटेंशन का इस्तेमाल करके, इन यादों को सेव करता है और सिमैंटिक समानता के आधार पर उन्हें वापस पाता है.
यह कोडलैब, एआई और डेटाबेस में दिलचस्पी रखने वाले सभी डेवलपर के लिए है. इसे पूरा करने में करीब 60 मिनट लगेंगे. बनाए गए संसाधनों की लागत पांच डॉलर से कम होनी चाहिए.
आपको क्या करना होगा
pgvectorकी सुविधा के साथ, PostgreSQL के लिए Cloud SQL इंस्टेंस सेट अप करने का तरीका.- उपयोगकर्ता के मैसेज से "यादें" निकालने के लिए, Gemini का इंटरैक्टिव तरीके से इस्तेमाल करने का तरीका.
- एआई के जवाबों के लिए काम का कॉन्टेक्स्ट पाने के लिए, PostgreSQL में वेक्टर सर्च करने का तरीका.
आपको किन चीज़ों की ज़रूरत होगी
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट.
- कमांड लाइन और Node.js की बुनियादी जानकारी.
2. शुरू करने से पहले
प्रोजेक्ट सेटअप करना
Google Cloud प्रोजेक्ट बनाना
- Google Cloud Console में, प्रोजेक्ट चुनने वाले पेज पर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो. किसी प्रोजेक्ट के लिए बिलिंग चालू है या नहीं, यह देखने का तरीका जानें.
Cloud Shell शुरू करना
Cloud Shell, Google Cloud में चलने वाला एक कमांड-लाइन एनवायरमेंट है. इसमें ज़रूरी टूल पहले से लोड होते हैं.
- Google Cloud कंसोल में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.
- Cloud Shell से कनेक्ट होने के बाद, अपने क्रेडेंशियल की पुष्टि करें:
gcloud auth list - पुष्टि करें कि आपका प्रोजेक्ट कॉन्फ़िगर किया गया है:
gcloud config get project - अगर आपका प्रोजेक्ट उम्मीद के मुताबिक सेट नहीं है, तो इसे सेट करें:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
एपीआई चालू करें
ज़रूरी एपीआई चालू करने के लिए, Cloud Shell में यह कमांड चलाएं:
gcloud services enable sqladmin.googleapis.com \
aiplatform.googleapis.com
3. डेमो रिपॉज़िटरी को क्लोन करना
अब लिविंग मेमोरी डेमो का कोड पाएं.
- रिपॉज़िटरी को अपने Cloud Shell एनवायरमेंट में क्लोन करें:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git cd devrel-demos/codelabs/visual-memory-postgres-demo - डिपेंडेंसी इंस्टॉल करें:
npm install
4. Cloud SQL डेटाबेस बनाना और उसे कॉन्फ़िगर करना
इस सेक्शन में, आपको Cloud SQL इंस्टेंस बनाने, डेटाबेस को शुरू करने, और स्कीमा सेट अप करने का तरीका बताया जाएगा.
- यह ऐप्लिकेशन, कॉन्फ़िगरेशन के लिए एनवायरमेंट वैरिएबल का इस्तेमाल करता है. इस सेशन के लिए ज़रूरी वैरिएबल सेट करने के लिए, Cloud Shell टर्मिनल में यह ब्लॉक चलाएं:
export REGION="us-central1" export INSTANCE_NAME="living-memory-db" export DB_HOST=127.0.0.1 export DB_PORT=5432 export DB_USER=memory_app export DB_PASS=memory_app_password export DB_NAME=living_memory export PGPASSWORD=$DB_PASS - इंस्टेंस बनाएं. आम तौर पर, इस चरण में 5 से 10 मिनट लगते हैं.
gcloud sql instances create $INSTANCE_NAME \ --database-version=POSTGRES_16 \ --cpu=1 \ --memory=3840MB \ --region=$REGION \ --root-password=$DB_PASS \ --edition=ENTERPRISEvectorएक्सटेंशन को चालू करती है और ऐप्लिकेशन के लिए कई टेबल बनाती है:
users,conversations,messages: ये स्टैंडर्ड टेबल हैं. इनका इस्तेमाल उपयोगकर्ता की प्रोफ़ाइल और बातचीत के इतिहास को सेव करने के लिए किया जाता है.memories: यह, रीट्रिवल-ऑगमेंटेड जनरेशन (आरएजी) के लिए मुख्य टेबल है. हर लाइन में बातचीत से निकाली गई जानकारी होती है. जैसे, "उपयोगकर्ता को हाइकिंग पसंद है". यह कुकी इन चीज़ों को सेव करती है:content: यादों का टेक्स्ट.memory_type: यादों का टाइप (FACT,PREFयाIMPLICIT).embedding: यह 768 डाइमेंशन वालाvectorकॉलम है. इसमें Gemini से जनरेट किए गए कॉन्टेंट का सिमैंटिक रिप्रज़ेंटेशन होता है.
pgvectorइंडेक्स:embeddingकॉलम परHNSW(हायरार्किकल नेविगेबल स्मॉल वर्ल्ड) इंडेक्स बनाया जाता है. यह k-Nearest Neighbor (k-NN) खोजों को ऑप्टिमाइज़ करने के लिए ज़रूरी है. इससेpgvector, कोसाइन डिस्टेंस ऑपरेटर (<=>) का इस्तेमाल करके, सिमैंटिक तौर पर सबसे मिलती-जुलती यादों को तुरंत ढूंढने में मदद मिलती है.
- डेटाबेस बनाना
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME - ऐप्लिकेशन उपयोगकर्ता बनाना
gcloud sql users create $DB_USER --instance=$INSTANCE_NAME --password=$DB_PASS - Cloud SQL Auth प्रॉक्सी शुरू करें. प्रॉक्सी, आपके इंस्टेंस को सुरक्षित तरीके से ऐक्सेस करने की सुविधा देता है. इसके लिए, आईपी पते को अनुमति वाली सूची में शामिल करने की ज़रूरत नहीं होती.
(cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:us-central1:living-memory-db &) && sleep 2 && echo ""The proxy has started successfully and is ready for new connections!. vectorएक्सटेंशन को चालू करने और ज़रूरी टेबल बनाने के लिए,schema.sqlको लागू करें. प्रॉक्सी चालू होने की वजह से, अब127.0.0.1पर अपने इंस्टेंस से कनेक्ट किया जा सकता है.psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME < schema.sql- पुष्टि करें कि स्कीमा बन गया है.
psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME -c "\dt"conversations,memories,messages, औरusersटेबल की सूची वाला आउटपुट दिखेगा.List of relations Schema | Name | Type | Owner --------+---------------+-------+------------ public | conversations | table | memory_app public | memories | table | memory_app public | messages | table | memory_app public | queries_log | table | memory_app public | users | table | memory_app (5 rows)
5. pgvector की मदद से सिमैंटिक जानकारी पाने के बारे में जानकारी
इस सेक्शन में, हम यह देखेंगे कि जवाब जनरेट करने से पहले, ऐप्लिकेशन एआई के लिए ज़रूरी कॉन्टेक्स्ट कैसे पाता है. server.js के इस स्निपेट में, /api/chat एंडपॉइंट में इसके लिए ज़िम्मेदार कोड दिखाया गया है:
// Retrieve Similar Memories for Context (Using pgvector)
const promptEmbeddingRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: message,
config: { outputDimensionality: 768 },
});
const promptEmbedding = promptEmbeddingRes.embeddings[0].values;
const embeddingStr = `[${promptEmbedding.join(',')}]`;
// Query DB for top 5 closest memories
const relevantMemories = await pool.query(
`SELECT id, content, memory_type, category
FROM memories
WHERE user_id = $1
ORDER BY embedding <=> $2::vector
LIMIT 5`,
[userId, embeddingStr]
);
यह कैसे काम करता है
- जेन एआई (एम्बेडिंग): यह ऐप्लिकेशन, उपयोगकर्ता के मैसेज को लेता है और
gemini-embedding-001मॉडल का इस्तेमाल करके, टेक्स्ट को 768 डाइमेंशन वाले वेक्टर में बदलता है. यह वेक्टर, मैसेज के सिमैंटिक मतलब को दिखाता है. - Cloud SQL (pgvector): ऐप्लिकेशन, उस वेक्टर को Cloud SQL को पास करता है. Cloud SQL,
pgvectorएक्सटेंशन के ज़रिए उपलब्ध कराए गए<=>(कोसाइन दूरी) ऑपरेटर का इस्तेमाल करके, प्रॉम्प्ट से मिलती-जुलती पांच यादें ढूंढता है. - नतीजा: यह रीट्रिवल-ऑगमेंटेड जनरेशन (आरएजी) है. एआई को डेटाबेस से, काम की कुछ खास यादों का ऐक्सेस मिलता है. इससे वह आपकी दिलचस्पी के हिसाब से जवाब दे पाता है. इसके लिए, उसे पूरा इतिहास लोड करने की ज़रूरत नहीं होती.
6. यादों से जानकारी निकालने की सुविधा के बारे में जानकारी
इसके बाद, देखें कि ऐप्लिकेशन बातचीत से कैसे सीखता है. यहां दिया गया स्निपेट, server.js में मौजूद extractMemoriesAsync फ़ंक्शन से लिया गया है:
// MEMORY EXTRACTION LOGIC
async function extractMemoriesAsync(userMessage, userId, messageId) {
const extractionPrompt = `
Analyze the following user message. A memory profile is being built for this user.
Extract ANY explicit facts (Facts), preferences (Pref), or implicit behavioral traits/styles (Implicit).
Return the result as a raw JSON array of objects (NO Markdown blocks, just the JSON array).
Format: [{"content": "string fact/sentence", "type": "FACT|PREF|IMPLICIT", "category": "General|Travel|Hobby|Persona"}]
If nothing is found, return [].
Message: "${userMessage}"
`;
const result = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: extractionPrompt
});
let rawJson = result.text.replace(/^```json/g, '').replace(/```$/g, '').trim();
let extracted;
try {
extracted = JSON.parse(rawJson);
} catch (e) {
console.warn("Could not parse extracted JSON:", rawJson);
return;
}
if (Array.isArray(extracted) && extracted.length > 0) {
// Compute embeddings and save each to the DB
for (const memory of extracted) {
const embedRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: memory.content,
config: { outputDimensionality: 768 },
});
const vectorData = `[${embedRes.embeddings[0].values.join(',')}]`;
await pool.query(
`INSERT INTO memories (user_id, content, memory_type, category, embedding, source_message_id)
VALUES ($1, $2, $3, $4, $5, $6)`,
[userId, memory.content, memory.type.toUpperCase(), memory.category, vectorData, messageId]
);
console.log(`Saved new memory: ${memory.content}`);
}
}
}
यह कैसे काम करता है
- जनरेटिव एआई (स्ट्रक्चर्ड आउटपुट): यह ऐप्लिकेशन,
gemini-2.5-flashमॉडल का इस्तेमाल करके उपयोगकर्ता के मैसेज का विश्लेषण करता है. साथ ही, स्ट्रक्चर्ड फ़ैक्ट और प्राथमिकताओं को JSON ऐरे के तौर पर निकालता है. - Cloud SQL (हाइब्रिड स्टोरेज): इन नए तथ्यों के लिए एम्बेडिंग जनरेट करने के बाद, इन्हें Cloud SQL में सेव किया जाता है. ध्यान दें कि स्टैंडर्ड रिलेशनल डेटा (उपयोगकर्ता आईडी, टेक्स्ट कॉन्टेंट, कैटगरी) को एक ही लाइन में, ज़्यादा डाइमेंशन वाले वेक्टर डेटा के साथ सेव किया जाता है.
- नतीजा: यह ऐप्लिकेशन, रीयल-टाइम में अपने-आप अपडेट होने वाली मेमोरी प्रोफ़ाइल बनाता है. इसके लिए, Gemini की विश्लेषण करने की क्षमता और Cloud SQL की स्टोरेज क्षमता का इस्तेमाल किया जाता है.
7. चैट ऐप्लिकेशन चलाएं
- डेटाबेस में कुछ उदाहरण उपयोगकर्ताओं का डेटा जोड़ना
npm run seed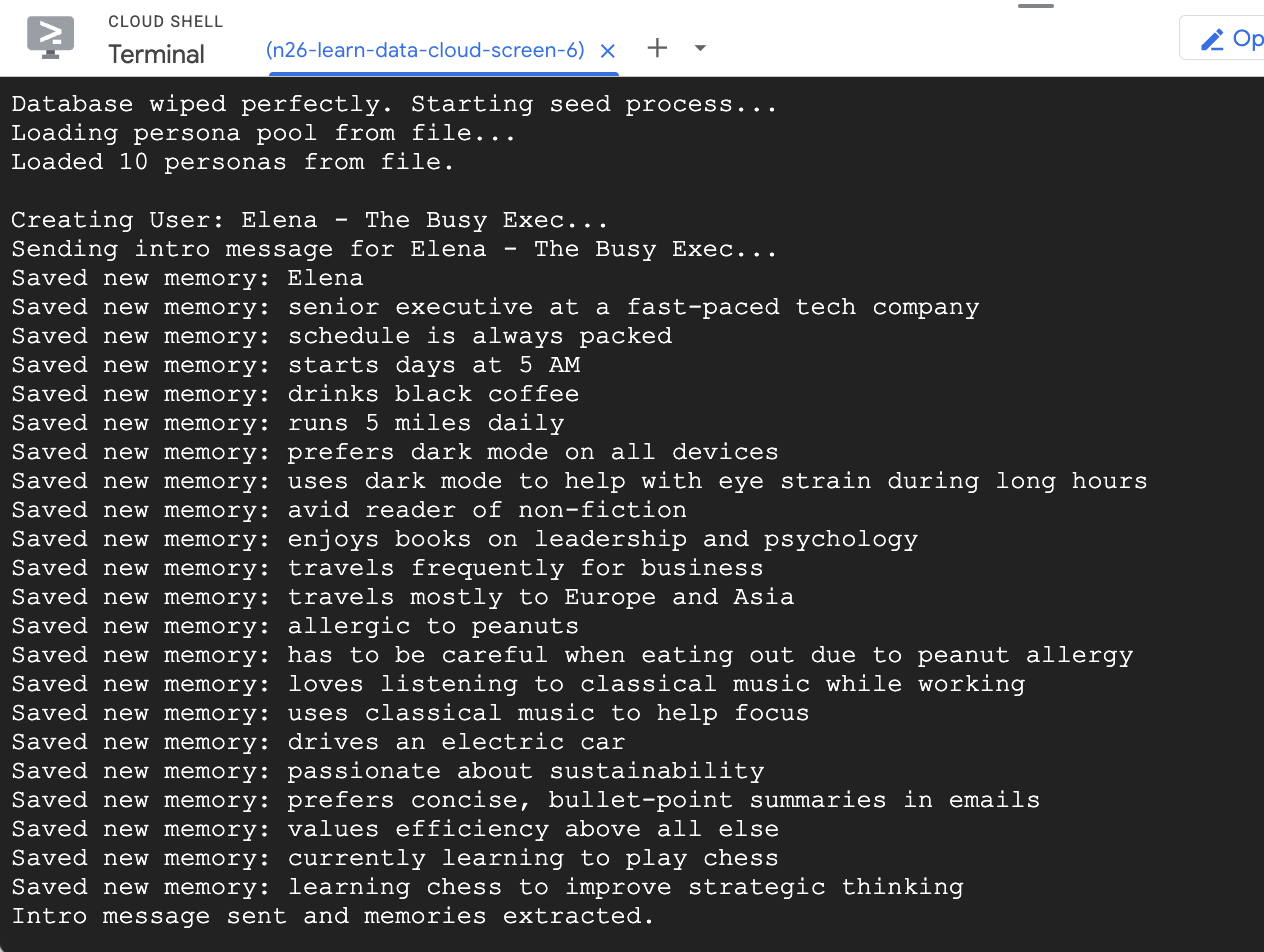
- इसके बाद, सर्वर चलाएं
node server.js - Cloud Shell में, टर्मिनल टूलबार में सबसे ऊपर दाईं ओर मौजूद वेब प्रीव्यू पर क्लिक करें. इसके बाद, पोर्ट बदलें को चुनें. पोर्ट किए जाने वाले नंबर के लिए
3000डालें. इसके बाद, बदलें और झलक देखें पर क्लिक करें.
Assistant से बातचीत करना
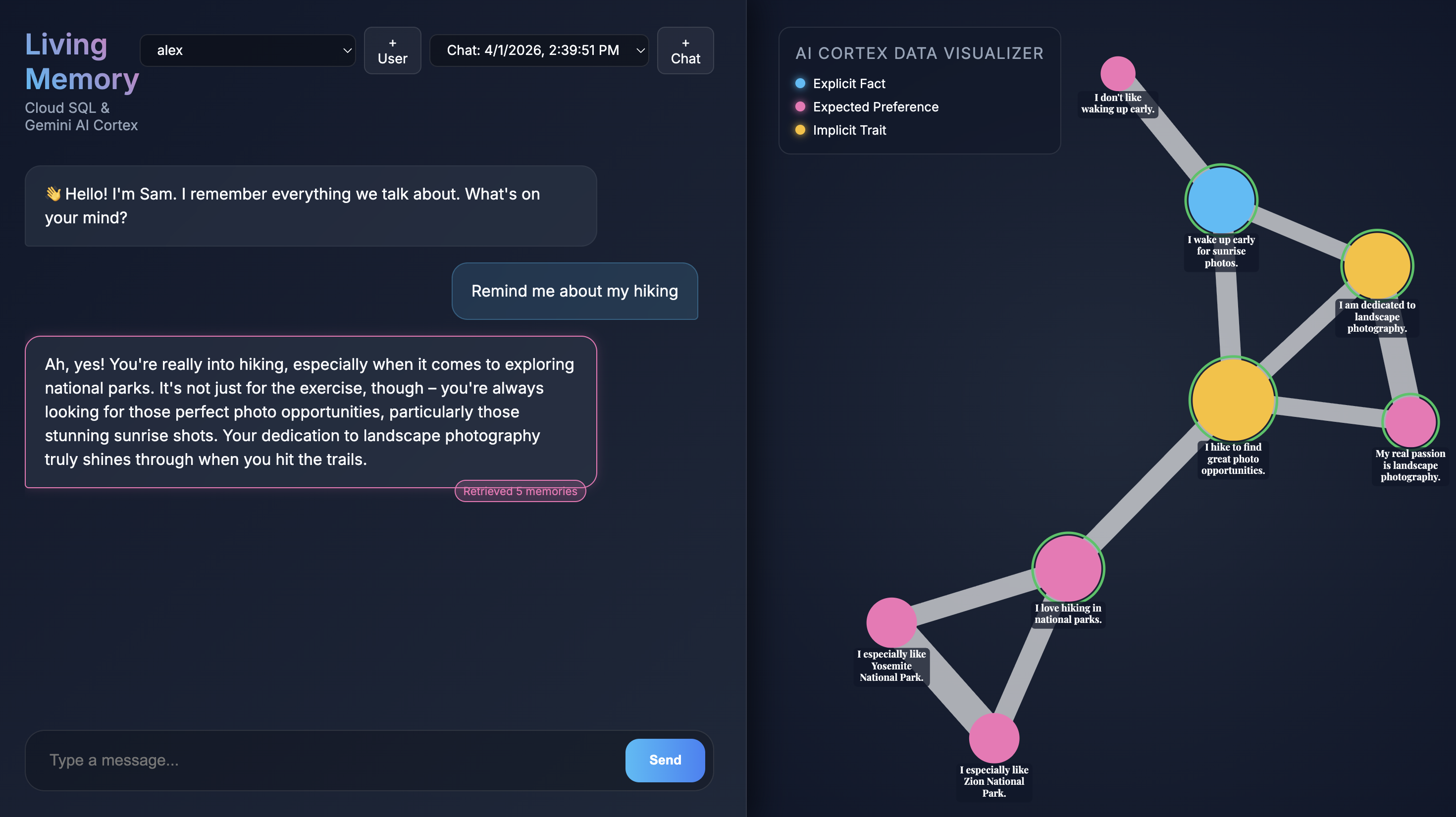
आपके ब्राउज़र में ऐप्लिकेशन खुलने पर, आपको लिविंग मेमोरी का चैट इंटरफ़ेस दिखेगा. दाईं ओर, AI Cortex Data Visualizer में, यादों को वेक्टर स्पेस में नोड के तौर पर दिखाया गया है. इन्हें टाइप के हिसाब से कलर-कोड किया गया है. जैसे, तथ्य, पसंद, और छिपी हुई विशेषता. आपकी स्क्रीन के रिज़ॉल्यूशन के हिसाब से, मेमोरी नोड पर मौजूद टेक्स्ट छोटा हो सकता है. ज़्यादा बारीकी से देखने के लिए, ज़ूम और पैन करने के लिए माउस या ट्रैकपैड का इस्तेमाल करें.
मौजूदा यादों के बारे में क्वेरी करना
आपने पहले जो seed स्क्रिप्ट चलाई थी उससे दो सैंपल उपयोगकर्ता बनाए गए थे. साथ ही, उनमें कुछ यादें पहले से मौजूद थीं.
- सबसे ऊपर बाईं ओर मौजूद, उपयोगकर्ता ड्रॉपडाउन मेन्यू से कोई उपयोगकर्ता चुनें.
- क्विक-चैट बटन में से किसी एक का इस्तेमाल करें या चैट इनपुट में
Give me restaurant recommendations in New York Cityटाइप करें और भेजें दबाएं. - जवाब मिलने के बाद, Assistant के मैसेज पर क्लिक करके देखा जा सकता है कि उसने किन यादों का इस्तेमाल किया है. इन्हें हरे रंग से हाइलाइट किया जाएगा. साथ ही, इन्हें ज़ूम करके देखा जा सकता है. इससे यह पता चलेगा कि इनकी मदद से जवाब कैसे तैयार किया गया है.
नया उपयोगकर्ता बनाना
अब, नया उपयोगकर्ता बनाते हैं.
- नया चैट सेशन शुरू करने के लिए, उपयोगकर्ता ड्रॉपडाउन के बगल में मौजूद + बटन पर क्लिक करें.
- जनरेट किए गए नाम और ब्यौरे का इस्तेमाल करें या अपने बारे में बताने के लिए, उनमें बदलाव करें.
- बनाएं पर क्लिक करें. इसके बाद, ऐप्लिकेशन को यादें एक्सट्रैक्ट करते हुए देखें. लगभग 30 सेकंड में, आपको दाईं ओर मौजूद विज़ुअलाइज़र में नए नोड दिखने चाहिए. इनमें वे तथ्य और प्राथमिकताएँ शामिल होती हैं जिन्हें Gemini ने आपके मैसेज से निकाला है और Cloud SQL डेटाबेस में सेव किया है.
- बातचीत के दौरान, Assistant से
What food do I like?जैसा कोई फ़ॉलो-अप सवाल पूछें. इससे आपको पता चलेगा कि Assistant, बातचीत के दौरान अपनी नई यादों का इस्तेमाल कर रही है या नहीं.
8. व्यवस्थित करें
इस कोडलैब में इस्तेमाल किए गए संसाधनों के लिए, Google Cloud खाते से शुल्क न लिया जाए, इसके लिए आपको बनाए गए संसाधन मिटाने चाहिए.
- Cloud SQL इंस्टेंस मिटाएं:
gcloud sql instances delete $INSTANCE_NAME --quiet - डेमो रिपॉज़िटरी हटाएं:
rm -rf ~/devrel-demos
9. बधाई हो
आपने "Living Memory" एआई असिस्टेंट को बना लिया है और उसे डिप्लॉय कर दिया है!
आपको क्या सीखने को मिला
- सिमैंटिक सर्च के लिए, Cloud SQL pgvector का इस्तेमाल करने का तरीका.
- डाइनैमिक मेमोरी एक्सट्रैक्शन के लिए, Gemini का इस्तेमाल कैसे करें.
अगले चरण
- Cloud SQL pgvector के दस्तावेज़ देखें.
- Gemini API की क्षमताओं के बारे में ज़्यादा जानें.
- Cloud SQL Auth प्रॉक्सी के बारे में ज़्यादा जानें.
- अलग-अलग तरह का डेटा निकालने के लिए,
server.jsमें जाकरextractionPromptको पसंद के मुताबिक बनाएं!
Living Memory के साथ अपनी यादें बनाएं!