
1. Introduzione
In questo codelab imparerai a creare la Living Memory Demo, un assistente basato sull'AI che tiene traccia dei "ricordi" della tua conversazione per fornire un'esperienza personalizzata.
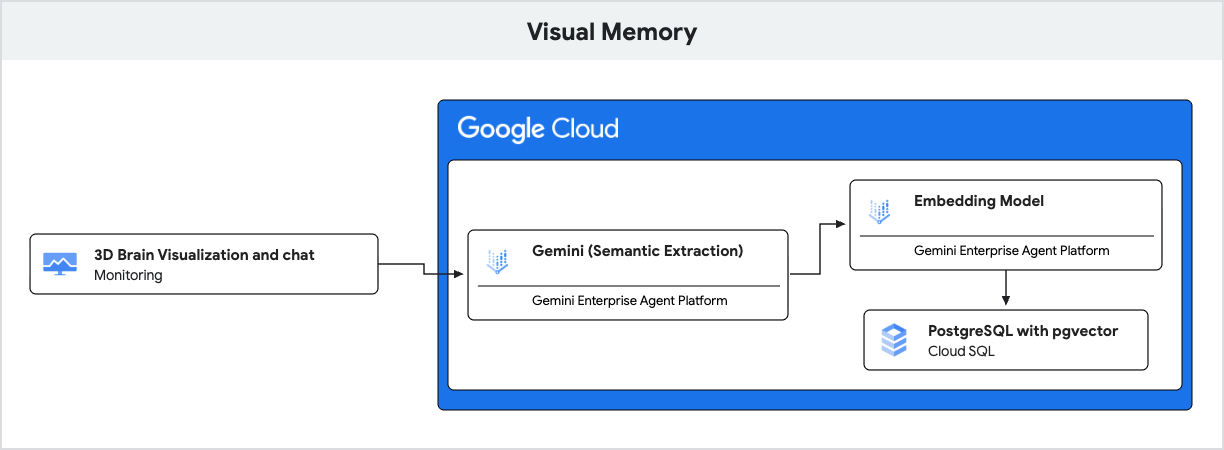
L'applicazione utilizza Gemini per la comprensione del linguaggio naturale e Cloud SQL per PostgreSQL con l'estensione pgvector per archiviare e recuperare questi ricordi in base alla similarità semantica.
Questo codelab è destinato agli sviluppatori di tutti i livelli di abilità interessati all'AI e ai database e dovrebbe richiedere circa 60 minuti. Le risorse create dovrebbero costare meno di 5 $.
In questo lab proverai a:
- Come configurare un'istanza Cloud SQL per PostgreSQL con supporto
pgvector. - Come utilizzare Gemini per estrarre in modo interattivo i "ricordi" dai messaggi degli utenti.
- Come eseguire ricerche vettoriali in PostgreSQL per recuperare il contesto pertinente per le risposte dell'AI.
Che cosa ti serve
- Un progetto Google Cloud con la fatturazione abilitata.
- Conoscenza di base della riga di comando e di Node.js.
2. Prima di iniziare
Configurazione del progetto
Crea un progetto Google Cloud
- Nella console Google Cloud, nella pagina di selezione del progetto, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud. Scopri come verificare se la fatturazione è abilitata per un progetto.
Avvia Cloud Shell
Cloud Shell è un ambiente a riga di comando in esecuzione in Google Cloud che viene fornito con gli strumenti necessari precaricati.
- Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.
- Una volta eseguita la connessione a Cloud Shell, verifica l'autenticazione:
gcloud auth list - Verifica che il progetto sia configurato:
gcloud config get project - Se il progetto non è impostato come previsto, impostalo:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Abilita API
Esegui il comando seguente in Cloud Shell per abilitare le API richieste:
gcloud services enable sqladmin.googleapis.com \
aiplatform.googleapis.com
3. Clona il repository della demo
Ora recupera il codice per la Living Memory Demo.
- Clona il repository nel tuo ambiente Cloud Shell:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git cd devrel-demos/codelabs/visual-memory-postgres-demo - Installa le dipendenze:
npm install
4. Crea e configura il database Cloud SQL
In questa sezione creerai un'istanza Cloud SQL, inizializzerai un database e configurerai lo schema.
- L'applicazione utilizza le variabili di ambiente per la configurazione. Esegui il seguente blocco nel terminale Cloud Shell per impostare le variabili richieste per questa sessione:
export REGION="us-central1" export INSTANCE_NAME="living-memory-db" export DB_HOST=127.0.0.1 export DB_PORT=5432 export DB_USER=memory_app export DB_PASS=memory_app_password export DB_NAME=living_memory export PGPASSWORD=$DB_PASS - Crea l'istanza. Questo passaggio richiede in genere 5-10 minuti.
gcloud sql instances create $INSTANCE_NAME \ --database-version=POSTGRES_16 \ --cpu=1 \ --memory=3840MB \ --region=$REGION \ --root-password=$DB_PASS \ --edition=ENTERPRISEvectore crea diverse tabelle per supportare l'applicazione:
users,conversations,messages: tabelle standard per archiviare i profili utente e la cronologia delle conversazioni.memories: questa è la tabella principale per la Retrieval-Augmented Generation (RAG). Ogni riga rappresenta un'informazione estratta dalla conversazione (ad es. "L'utente ama le escursioni"). Memorizza:content: il testo del ricordo.memory_type: il tipo di ricordo (FACT,PREFoIMPLICIT).embedding: una colonnavectora 768 dimensioni contenente la rappresentazione semantica dei contenuti, generata da Gemini.
pgvectorIndice: viene creato un indiceHNSW(Hierarchical Navigable Small World) nella colonnaembedding. Questo è fondamentale per ottimizzare le ricerche K-Nearest Neighbor (k-NN), consentendo apgvectordi trovare rapidamente i ricordi semanticamente più simili utilizzando l'operatore di distanza del coseno (<=>).
- Crea il database
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME - Crea l'utente dell'applicazione
gcloud sql users create $DB_USER --instance=$INSTANCE_NAME --password=$DB_PASS - Avvia il proxy di autenticazione Cloud SQL. Il proxy fornisce un accesso sicuro all'istanza senza dover configurare l'elenco consentito di indirizzi IP.
(cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:us-central1:living-memory-db &) && sleep 2 && echo ""The proxy has started successfully and is ready for new connections!. - Applica
schema.sqlper abilitare l'estensionevectore creare le tabelle necessarie. Poiché il proxy è in esecuzione, ora puoi connetterti all'istanza all'indirizzo127.0.0.1.psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME < schema.sql - Verifica che la creazione dello schema sia andata a buon fine.
psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME -c "\dt"conversations,memories,messageseusers.List of relations Schema | Name | Type | Owner --------+---------------+-------+------------ public | conversations | table | memory_app public | memories | table | memory_app public | messages | table | memory_app public | queries_log | table | memory_app public | users | table | memory_app (5 rows)
5. Informazioni sul recupero semantico con pgvector
In questa sezione esaminerai come l'applicazione recupera il contesto pertinente per l'AI prima di generare una risposta. Il seguente snippet di server.js mostra il codice responsabile di questa operazione nell'endpoint /api/chat:
// Retrieve Similar Memories for Context (Using pgvector)
const promptEmbeddingRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: message,
config: { outputDimensionality: 768 },
});
const promptEmbedding = promptEmbeddingRes.embeddings[0].values;
const embeddingStr = `[${promptEmbedding.join(',')}]`;
// Query DB for top 5 closest memories
const relevantMemories = await pool.query(
`SELECT id, content, memory_type, category
FROM memories
WHERE user_id = $1
ORDER BY embedding <=> $2::vector
LIMIT 5`,
[userId, embeddingStr]
);
Come funziona
- AI generativa (embedding): l'applicazione prende il messaggio in arrivo dell'utente e utilizza il modello
gemini-embedding-001per convertire il testo in un vettore a 768 dimensioni. Questo vettore rappresenta il significato semantico del messaggio. - Cloud SQL (pgvector): l'applicazione passa il vettore a Cloud SQL. Utilizzando l'operatore
<=>(distanza del coseno) fornito dall'estensionepgvector, Cloud SQL trova i 5 ricordi semanticamente più simili al prompt. - Il risultato: si tratta della Retrieval-Augmented Generation (RAG). L'AI ottiene l'accesso a ricordi specifici e pertinenti dal database per personalizzare la risposta, senza dover caricare l'intera cronologia.
6. Informazioni sull'estrazione dei ricordi
Ora esamina come l'applicazione apprende dalla conversazione. Il seguente snippet proviene dalla funzione extractMemoriesAsync in server.js:
// MEMORY EXTRACTION LOGIC
async function extractMemoriesAsync(userMessage, userId, messageId) {
const extractionPrompt = `
Analyze the following user message. A memory profile is being built for this user.
Extract ANY explicit facts (Facts), preferences (Pref), or implicit behavioral traits/styles (Implicit).
Return the result as a raw JSON array of objects (NO Markdown blocks, just the JSON array).
Format: [{"content": "string fact/sentence", "type": "FACT|PREF|IMPLICIT", "category": "General|Travel|Hobby|Persona"}]
If nothing is found, return [].
Message: "${userMessage}"
`;
const result = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: extractionPrompt
});
let rawJson = result.text.replace(/^```json/g, '').replace(/```$/g, '').trim();
let extracted;
try {
extracted = JSON.parse(rawJson);
} catch (e) {
console.warn("Could not parse extracted JSON:", rawJson);
return;
}
if (Array.isArray(extracted) && extracted.length > 0) {
// Compute embeddings and save each to the DB
for (const memory of extracted) {
const embedRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: memory.content,
config: { outputDimensionality: 768 },
});
const vectorData = `[${embedRes.embeddings[0].values.join(',')}]`;
await pool.query(
`INSERT INTO memories (user_id, content, memory_type, category, embedding, source_message_id)
VALUES ($1, $2, $3, $4, $5, $6)`,
[userId, memory.content, memory.type.toUpperCase(), memory.category, vectorData, messageId]
);
console.log(`Saved new memory: ${memory.content}`);
}
}
}
Come funziona
- AI generativa (output strutturato): l'applicazione utilizza il modello ultraveloce
gemini-2.5-flashper analizzare il messaggio dell'utente ed estrarre fatti e preferenze strutturati come array JSON. - Cloud SQL (archiviazione ibrida): dopo aver generato gli embedding per questi nuovi fatti, vengono archiviati in Cloud SQL. Tieni presente che i dati relazionali standard (ID utente, contenuti di testo, categorie) vengono archiviati insieme ai dati vettoriali ad alta dimensione in una singola riga.
- Il risultato: l'app crea un profilo di memoria autoaggiornante in tempo reale, sfruttando sia la potenza analitica di Gemini sia le funzionalità di archiviazione di Cloud SQL.
7. Esegui l'applicazione di chat
- Inserisci alcuni utenti di esempio nel database
npm run seed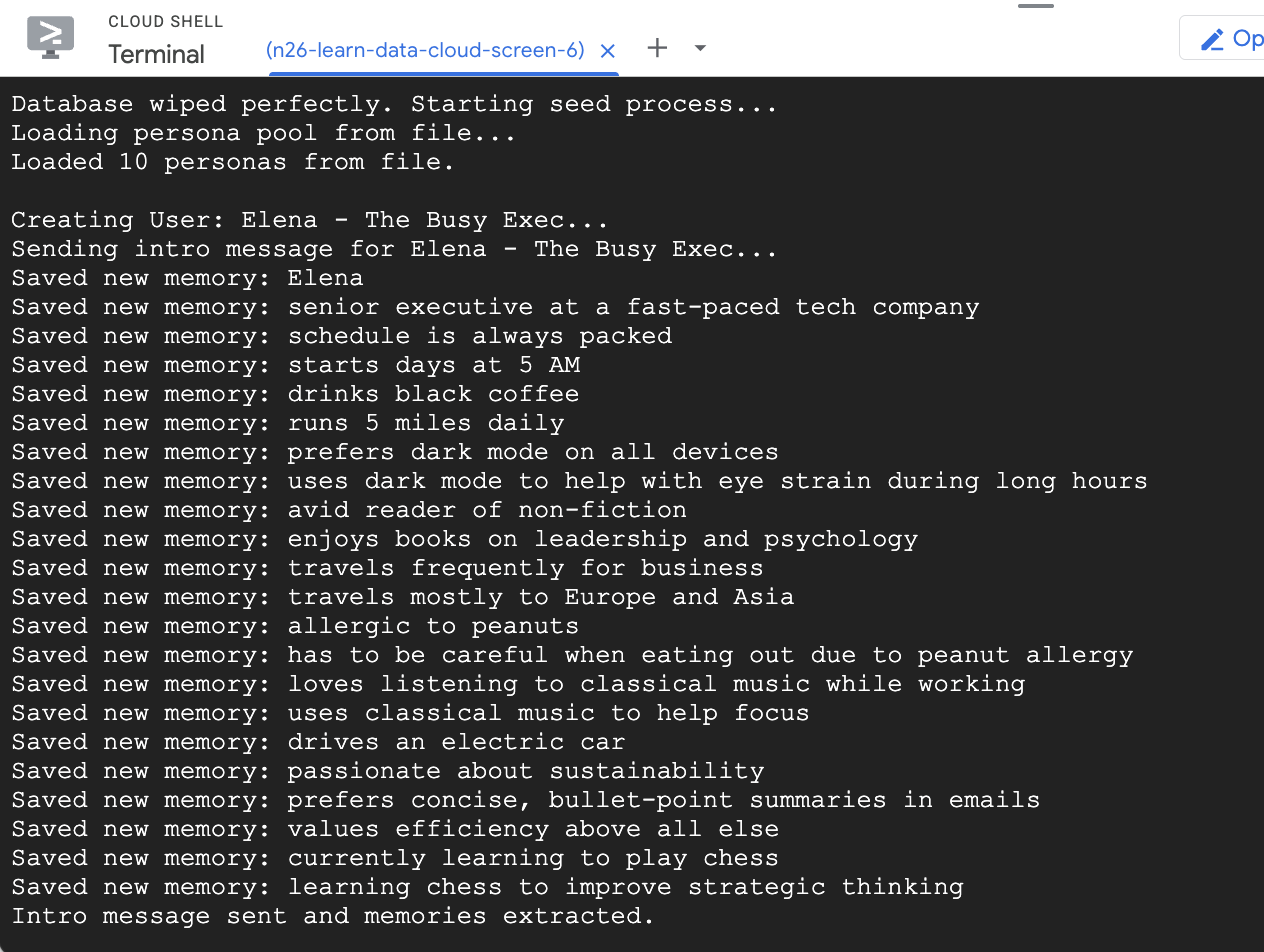
- Quindi esegui il server
node server.js - In Cloud Shell, fai clic su Anteprima web in alto a destra nella barra degli strumenti del terminale e seleziona Cambia porta. Inserisci
3000come numero di porta e fai clic su Cambia e visualizza l'anteprima.
Interagisci con l'assistente
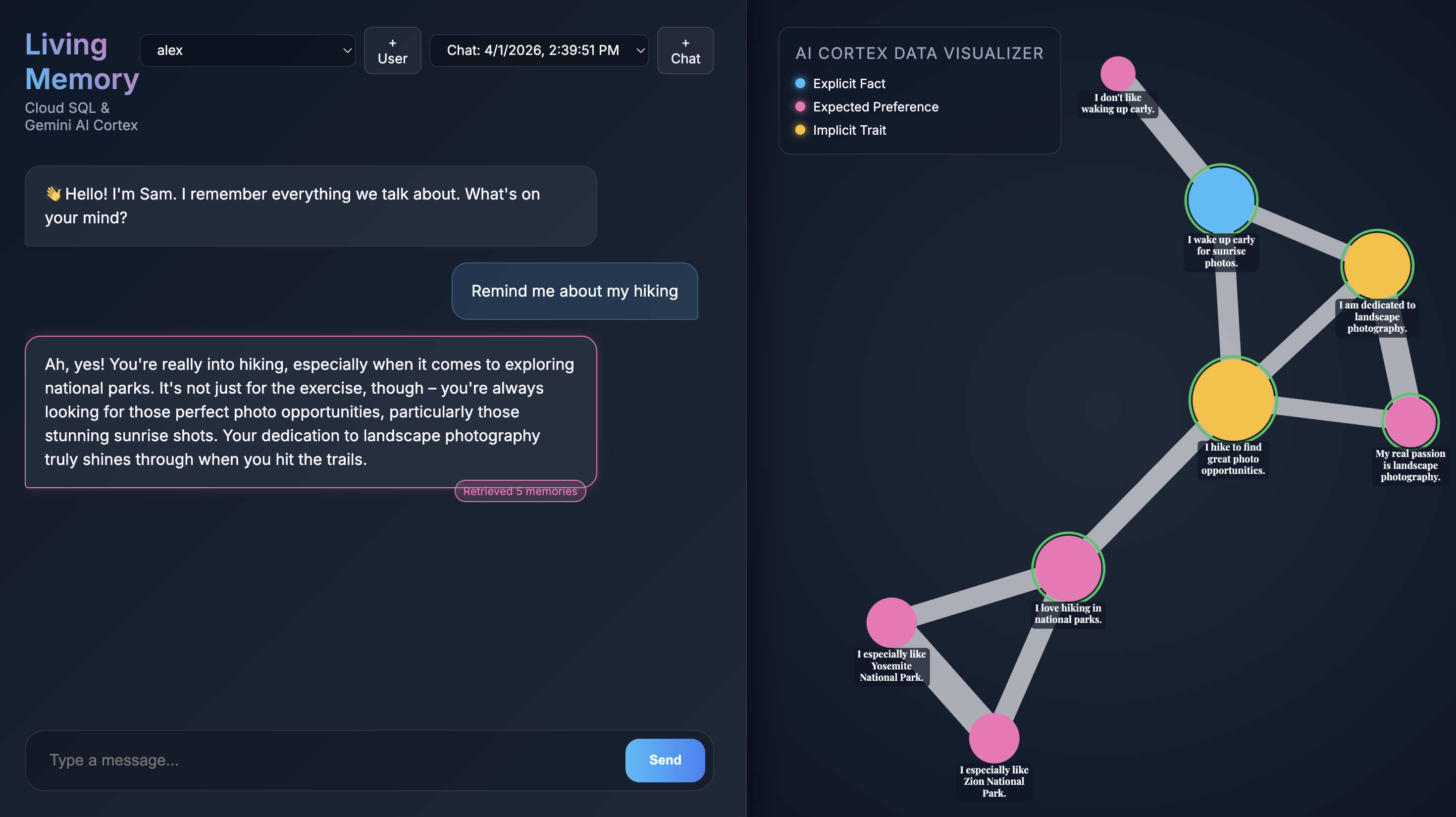
Quando l'applicazione si apre nel browser, vedrai l'interfaccia di chat di Living Memory. A destra, il visualizzatore di dati AI Cortex mostra i ricordi come nodi in uno spazio vettoriale, con codice colore in base al tipo (fatto, preferenza, tratto implicito). Il testo sui nodi di memoria potrebbe essere piccolo a seconda della risoluzione dello schermo; utilizza il mouse o il trackpad per ingrandire e spostare la visualizzazione per esaminarlo più da vicino.
Esegui query sui ricordi esistenti
Lo script seed che hai eseguito in precedenza ha creato due utenti di esempio con alcuni ricordi precompilati.
- Seleziona un utente dal menu a discesa degli utenti in alto a sinistra.
- Utilizza uno dei pulsanti di chat rapida o digita
Give me restaurant recommendations in New York Citynell'input della chat e premi Invia. - Quando l'assistente risponde, puoi fare clic sul messaggio dell'assistente per vedere quali ricordi ha utilizzato. Verranno evidenziati in verde e potrai ingrandirli e vedere come hanno contribuito a formare la risposta.
Crea un nuovo utente
Ora creiamo un nuovo utente.
- Fai clic sul pulsante + accanto al menu a discesa degli utenti per avviare una nuova sessione di chat.
- Utilizza il nome e la descrizione generati o modificali per descriverti.
- Fai clic su Crea e guarda l'applicazione iniziare a estrarre i ricordi. Dopo circa 30 secondi, dovresti vedere nuovi nodi nel visualizzatore a destra. Questi rappresentano i fatti e le preferenze che Gemini ha estratto dal tuo messaggio e archiviato nel database Cloud SQL.
- Poni una domanda di follow-up come
What food do I like?per vedere l'assistente utilizzare i ricordi appena acquisiti nella conversazione.
8. Libera spazio
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo codelab, devi eliminare le risorse che hai creato.
- Elimina l'istanza Cloud SQL:
gcloud sql instances delete $INSTANCE_NAME --quiet - Rimuovi il repository della demo:
rm -rf ~/devrel-demos
9. Complimenti
Hai creato e sottoposto a deployment un assistente AI "Living Memory"!
Che cosa hai imparato
- Come utilizzare Cloud SQL pgvector per la ricerca semantica.
- Come utilizzare Gemini per l'estrazione dinamica dei ricordi.
Passaggi successivi
- Esplora la documentazione di Cloud SQL pgvector.
- Scopri di più sulle funzionalità dell'API Gemini.
- Approfondisci il proxy di autenticazione Cloud SQL.
- Prova a personalizzare
extractionPromptinserver.jsper estrarre diversi tipi di dati.
Buona creazione con Living Memory!