
1. はじめに
このコードラボでは、会話の「記憶」を追跡してパーソナライズされたエクスペリエンスを提供する AI 搭載アシスタントであるLiving Memory Demo を構築する方法について説明します。
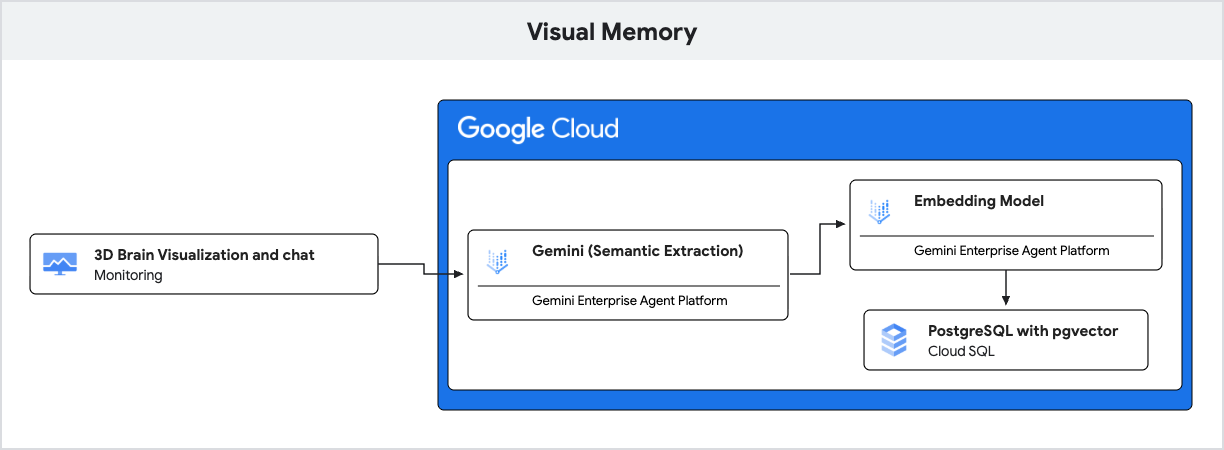
このアプリケーションでは、自然言語理解に Gemini を使用し、セマンティック類似性に基づいてこれらのメモリーを保存して取得するために Cloud SQL for PostgreSQL と pgvector 拡張機能 を使用します。
このコードラボは、AI とデータベースに関心のあるすべてのスキルレベルのデベロッパーを対象としており、完了まで約 60 分かかります。作成するリソースの費用は 5 ドル未満です。
演習内容
pgvectorをサポートする Cloud SQL for PostgreSQL インスタンスを設定する方法。- Gemini を使用してユーザー メッセージから「記憶」をインタラクティブに抽出する方法。
- PostgreSQL でベクトル検索を実行して、AI の応答に関連するコンテキストを取得する方法。
必要なもの
- 課金を有効にした Google Cloud プロジェクト
- コマンドラインと Node.js の基本的な知識。
2. 始める前に
プロジェクトの設定
Google Cloud プロジェクトの作成
- Google Cloud コンソールのプロジェクト選択ページで、Google Cloud プロジェクトを選択または作成します。
- Cloud プロジェクトに対して課金が有効になっていることを確認します。プロジェクトで課金が有効になっているかどうかを確認する方法をご覧ください。
Cloud Shell の起動
Cloud Shell は、必要なツールがプリロードされた Google Cloud 上で動作するコマンドライン環境です。
- Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする 」アイコン をクリックします。
- Cloud Shell に接続したら、認証を確認します。
gcloud auth list - プロジェクトが構成されていることを確認します。
gcloud config get project - プロジェクトが想定どおりに設定されていない場合は、設定します。
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
API を有効にする
Cloud Shell で次のコマンドを実行して、必要な API を有効にします。
gcloud services enable sqladmin.googleapis.com \
aiplatform.googleapis.com
3. デモリポジトリのクローンを作成する
次に、Living Memory Demo のコードを取得します。
- リポジトリのクローンを Cloud Shell 環境に作成します。
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git cd devrel-demos/codelabs/visual-memory-postgres-demo - 依存関係をインストールします。
npm install
4. Cloud SQL データベースを作成して構成する
このセクションでは、Cloud SQL インスタンスを作成し、データベースを初期化して、スキーマを設定します。
- このアプリケーションでは、構成に環境変数を利用します。Cloud Shell ターミナルで次のブロックを実行して、このセッションに必要な変数を設定します。
export REGION="us-central1" export INSTANCE_NAME="living-memory-db" export DB_HOST=127.0.0.1 export DB_PORT=5432 export DB_USER=memory_app export DB_PASS=memory_app_password export DB_NAME=living_memory export PGPASSWORD=$DB_PASS - インスタンスを作成します。通常、この手順には 5 ~ 10 分かかります。
gcloud sql instances create $INSTANCE_NAME \ --database-version=POSTGRES_16 \ --cpu=1 \ --memory=3840MB \ --region=$REGION \ --root-password=$DB_PASS \ --edition=ENTERPRISEvector拡張機能を有効にし、アプリケーションをサポートするいくつかのテーブルを作成します:
users、conversations、messages: ユーザー プロファイルと会話履歴を保存する標準テーブル。memories: これは、検索拡張生成(RAG)の中核となるテーブルです。各行は、会話から抽出された情報(「ユーザーはハイキングが好き」など)を表します。保存される内容は次のとおりです。content: 記憶のテキスト。memory_type: 記憶のタイプ(FACT、PREF、IMPLICIT)。embedding: Gemini によって生成されたコンテンツのセマンティック表現を含む 768 次元のvector列。
pgvectorインデックス:HNSW(Hierarchical Navigable Small World)インデックスがembedding列に作成されます。これは、k 最近傍(k-NN)検索を最適化するために不可欠です。これにより、pgvectorはコサイン距離演算子(<=>)を使用して、セマンティック的に最も類似した記憶をすばやく見つけることができます。
- データベースを作成する
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME - アプリケーション ユーザーを作成する
gcloud sql users create $DB_USER --instance=$INSTANCE_NAME --password=$DB_PASS - Cloud SQL Auth Proxy を起動します。このプロキシを使用すると、IP 許可リストを構成しなくてもインスタンスに安全にアクセスできます。
(cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:us-central1:living-memory-db &) && sleep 2 && echo ""The proxy has started successfully and is ready for new connections!のようなメッセージが表示されます。 schema.sqlを適用してvector拡張機能を有効にし、必要なテーブルを作成します。プロキシが実行されているため、127.0.0.1でインスタンスに接続できるようになりました。psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME < schema.sql- スキーマが正常に作成されたことを確認します。
psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME -c "\dt"conversations、memories、messages、usersテーブルが一覧表示された出力が表示されます。List of relations Schema | Name | Type | Owner --------+---------------+-------+------------ public | conversations | table | memory_app public | memories | table | memory_app public | messages | table | memory_app public | queries_log | table | memory_app public | users | table | memory_app (5 rows)
5. pgvector を使用したセマンティック検索について
このセクションでは、アプリケーションが応答を生成する前に AI の関連コンテキストを取得する方法について説明します。server.js の次のスニペットは、/api/chat エンドポイントでこの処理を行うコードを示しています。
// Retrieve Similar Memories for Context (Using pgvector)
const promptEmbeddingRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: message,
config: { outputDimensionality: 768 },
});
const promptEmbedding = promptEmbeddingRes.embeddings[0].values;
const embeddingStr = `[${promptEmbedding.join(',')}]`;
// Query DB for top 5 closest memories
const relevantMemories = await pool.query(
`SELECT id, content, memory_type, category
FROM memories
WHERE user_id = $1
ORDER BY embedding <=> $2::vector
LIMIT 5`,
[userId, embeddingStr]
);
仕組み
- 生成 AI(エンベディング): アプリケーションは、ユーザーの着信したメッセージを受け取り、
gemini-embedding-001モデルを使用してテキストを 768 次元のベクトルに変換します。このベクトルは、メッセージのセマンティックな意味を表します。 - Cloud SQL(pgvector): アプリケーションはそのベクトルを Cloud SQL に渡します。
pgvector拡張機能によって提供される<=>(コサイン距離)演算子を使用して、Cloud SQL はプロンプトにセマンティック的に最も類似した 5 つの記憶を見つけます。 - 結果: これは検索拡張生成(RAG)です。AI は、履歴全体を読み込むことなく、データベースから特定の関連する記憶にアクセスして応答をパーソナライズします。
6. メモリ抽出について
次に、アプリケーションが会話から学習する方法について説明します。次のスニペットは、server.js の extractMemoriesAsync 関数からのものです。
// MEMORY EXTRACTION LOGIC
async function extractMemoriesAsync(userMessage, userId, messageId) {
const extractionPrompt = `
Analyze the following user message. A memory profile is being built for this user.
Extract ANY explicit facts (Facts), preferences (Pref), or implicit behavioral traits/styles (Implicit).
Return the result as a raw JSON array of objects (NO Markdown blocks, just the JSON array).
Format: [{"content": "string fact/sentence", "type": "FACT|PREF|IMPLICIT", "category": "General|Travel|Hobby|Persona"}]
If nothing is found, return [].
Message: "${userMessage}"
`;
const result = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: extractionPrompt
});
let rawJson = result.text.replace(/^```json/g, '').replace(/```$/g, '').trim();
let extracted;
try {
extracted = JSON.parse(rawJson);
} catch (e) {
console.warn("Could not parse extracted JSON:", rawJson);
return;
}
if (Array.isArray(extracted) && extracted.length > 0) {
// Compute embeddings and save each to the DB
for (const memory of extracted) {
const embedRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: memory.content,
config: { outputDimensionality: 768 },
});
const vectorData = `[${embedRes.embeddings[0].values.join(',')}]`;
await pool.query(
`INSERT INTO memories (user_id, content, memory_type, category, embedding, source_message_id)
VALUES ($1, $2, $3, $4, $5, $6)`,
[userId, memory.content, memory.type.toUpperCase(), memory.category, vectorData, messageId]
);
console.log(`Saved new memory: ${memory.content}`);
}
}
}
仕組み
- Gen AI(構造化出力): アプリケーションは、超高速の
gemini-2.5-flashモデルを使用してユーザーのメッセージを分析し、構造化された事実と設定を JSON 配列として抽出します。 - Cloud SQL(ハイブリッド ストレージ): これらの新しい事実のエンベディングを生成した後、Cloud SQL に保存されます。標準のリレーショナル データ(ユーザー ID、テキスト コンテンツ、カテゴリ)は、高次元ベクトルデータと同じ行に保存されます。
- 結果: このアプリは、Gemini の分析能力と Cloud SQL のストレージ機能を活用して、自己更新型のメモリ プロファイルをリアルタイムで構築します。
7. チャット アプリケーションを実行する
- いくつかのサンプルユーザーでデータベースにシードを設定します。
npm run seed
- 次に、サーバーを実行します。
node server.js - Cloud Shell で、ターミナル ツールバーの右上にある [ウェブでプレビュー] をクリックし、[ポートを変更] を選択します。ポート番号に「
3000」と入力し、[変更してプレビュー] をクリックします。
アシスタントと対話する
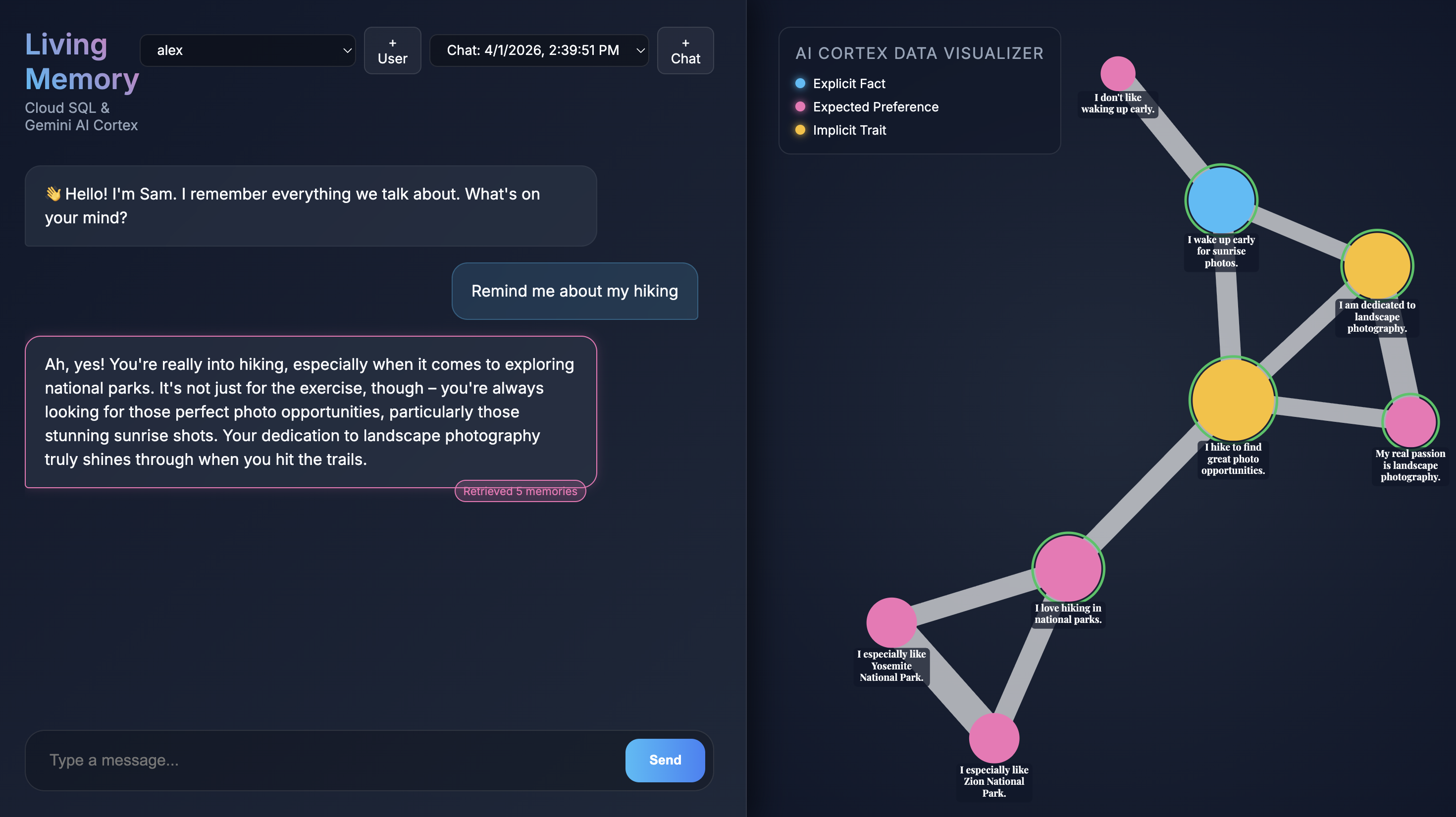
ブラウザでアプリケーションを開くと、Living Memory のチャット インターフェースが表示されます。右側の [AI Cortex Data Visualizer] には、記憶がベクトル空間のノードとして表示され、タイプ(事実、設定、暗黙的な特性)ごとに色分けされています。画面の解像度によっては、メモリノードのテキストが小さく表示されることがあります。マウスまたはトラックパッドを使用して、拡大 / 縮小やパンを行うと、詳細を確認できます。
既存の記憶をクエリする
先ほど実行した seed スクリプトにより、事前に入力された記憶を持つ 2 つのサンプルユーザーが作成されました。
- 左上のユーザー プルダウン メニューからユーザーを選択します。
- クイックチャット ボタンのいずれかを使用するか、チャット入力に「
Give me restaurant recommendations in New York City」と入力して [送信] を押します。 - アシスタントが応答したら、アシスタントのメッセージをクリックして、使用した記憶を確認できます。緑色でハイライト表示されます。ズームして、応答の作成にどのように役立ったかを確認できます。
新規ユーザーを作成する
次に、新しいユーザーを作成しましょう。
- ユーザー プルダウンの横にある [+] ボタンをクリックして、新しいチャット セッションを開始します。
- 生成された名前と説明を使用するか、編集して自己紹介を入力します。
- [作成] をクリックすると、アプリケーションが記憶の抽出を開始します。約 30 秒後に、右側のビジュアライザーに新しいノードが表示されます。これらは、Gemini がメッセージから抽出して Cloud SQL データベースに保存した事実と設定を表します。
What food do I like?などのフォローアップの質問をして、アシスタントが新しく取得した記憶を会話で使用していることを確認します。
8. クリーンアップ
このコードラボで使用したリソースについて、Google Cloud アカウントに継続的に課金されないようにするには、作成したリソースを削除します。
- Cloud SQL インスタンスを削除します。
gcloud sql instances delete $INSTANCE_NAME --quiet - デモリポジトリを削除します。
rm -rf ~/devrel-demos
9. 完了
「Living Memory」AI アシスタントの構築とデプロイが完了しました。
学習した内容
- セマンティック検索に Cloud SQL pgvector を使用する方法。
- 動的なメモリ抽出に Gemini を使用する方法。
次のステップ
- Cloud SQL pgvector のドキュメントを確認する。
- Gemini API の機能の詳細を確認する。
- Cloud SQL Auth Proxy について詳しく学ぶ。
server.jsのextractionPromptをカスタマイズして、さまざまな種類のデータを抽出してみる。
Living Memory を使用して構築をお楽しみください。