
1. 소개
이 Codelab에서는 대화의 "기억"을 추적하여 맞춤형 환경을 제공하는 AI 기반 어시스턴트인 Living Memory Demo를 빌드하는 방법을 알아봅니다.
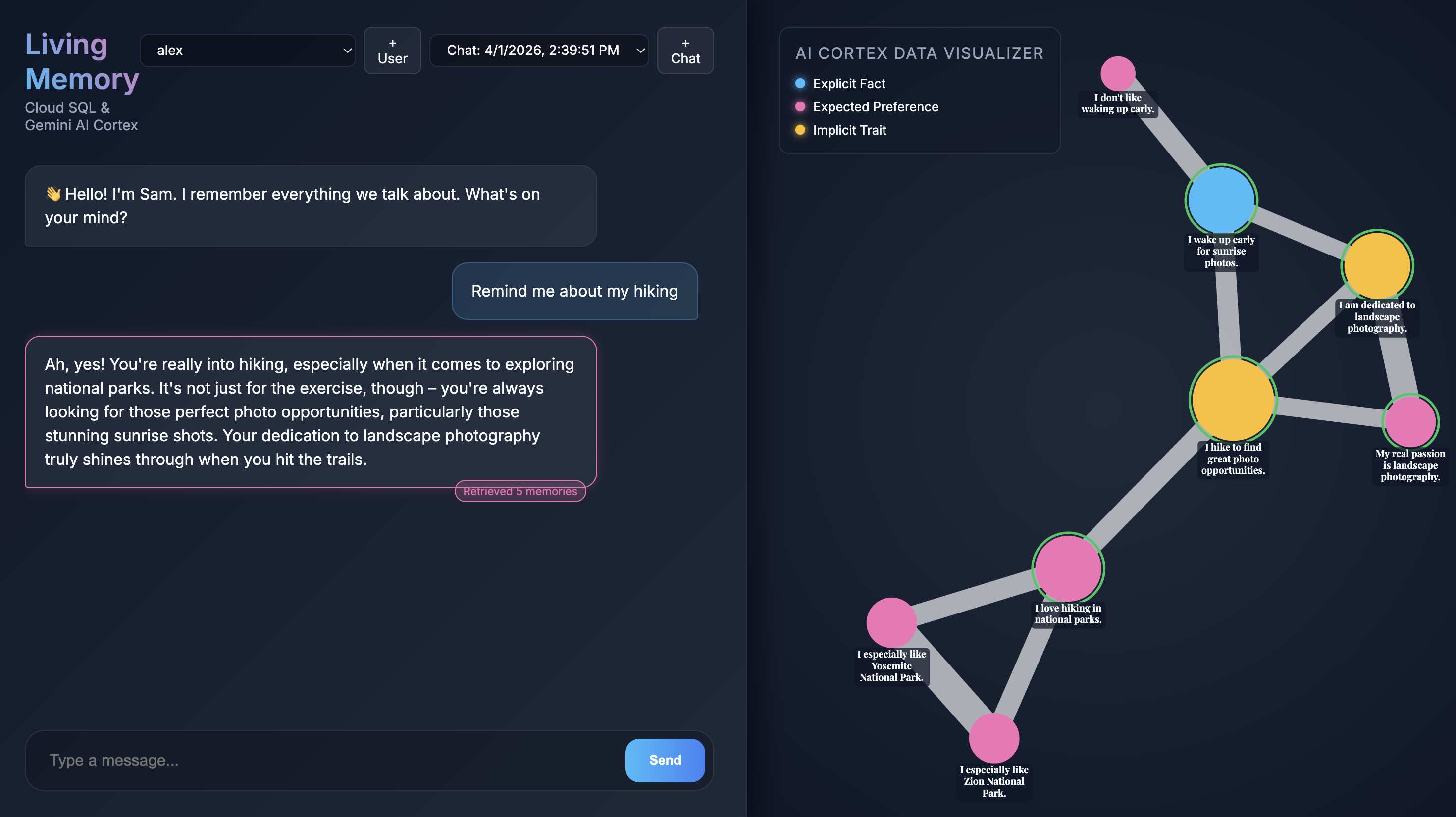
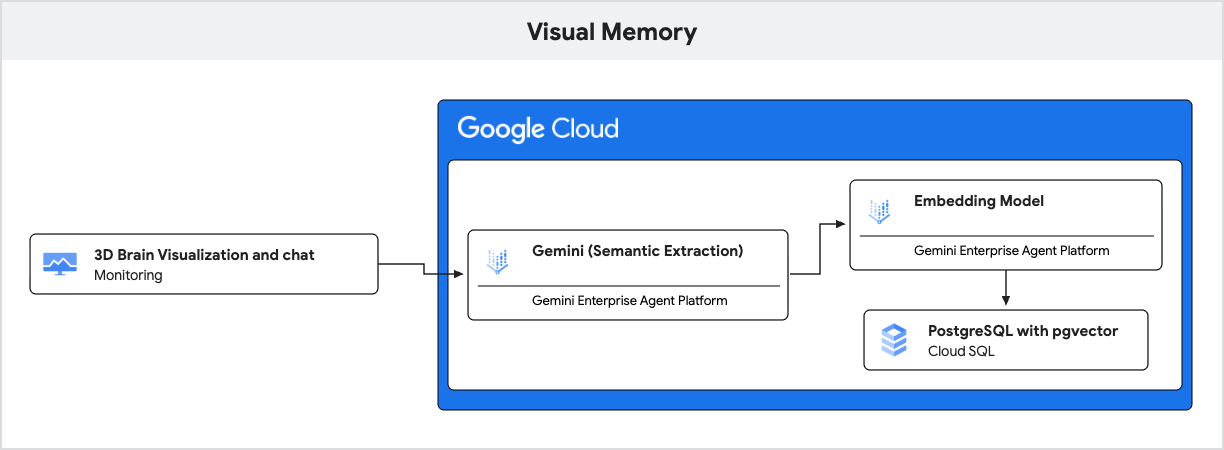
이 애플리케이션은 자연어 이해를 위해 Gemini를 사용하고 시맨틱 유사성을 기반으로 이러한 메모리를 저장하고 검색하기 위해 pgvector 확장 프로그램이 포함된 PostgreSQL용 Cloud SQL을 사용합니다.
이 Codelab은 AI 및 데이터베이스에 관심이 있는 모든 기술 수준의 개발자를 대상으로 하며 완료하는 데 약 60분이 소요됩니다. 생성된 리소스의 비용은 5달러 미만이어야 합니다.
실습할 내용
pgvector지원으로 PostgreSQL용 Cloud SQL 인스턴스를 설정하는 방법- Gemini를 사용하여 사용자 메시지에서 '기억'을 대화형으로 추출하는 방법
- PostgreSQL에서 벡터 검색을 실행하여 AI 응답과 관련된 컨텍스트를 검색하는 방법
필요한 항목
- 결제가 사용 설정된 Google Cloud 프로젝트.
- 명령줄 및 Node.js에 대한 기본 지식.
2. 시작하기 전에
프로젝트 설정
Google Cloud 프로젝트 만들기
- Google Cloud 콘솔의 프로젝트 선택기 페이지에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다. 프로젝트에 결제가 사용 설정되어 있는지 확인하는 방법을 알아보세요.
Cloud Shell 시작
Cloud Shell 은 Google Cloud에서 실행되며 필요한 도구가 사전 로드된 명령줄 환경입니다.
- Google Cloud 콘솔 상단에서 Cloud Shell 활성화 를 클릭합니다.
- Cloud Shell에 연결되면 인증을 확인합니다.
gcloud auth list - 프로젝트가 구성되었는지 확인합니다.
gcloud config get project - 프로젝트가 예상대로 설정되지 않은 경우 설정합니다.
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
API 사용 설정
Cloud Shell에서 다음 명령어를 실행하여 필요한 API를 사용 설정합니다.
gcloud services enable sqladmin.googleapis.com \
aiplatform.googleapis.com
3. 데모 저장소 복제
이제 Living Memory Demo의 코드를 가져옵니다.
- 저장소를 Cloud Shell 환경에 클론합니다.
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git cd devrel-demos/codelabs/visual-memory-postgres-demo - 종속 항목 설치
npm install
4. Cloud SQL 데이터베이스 만들기 및 구성
이 섹션에서는 Cloud SQL 인스턴스를 만들고, 데이터베이스를 초기화하고, 스키마를 설정합니다.
- 애플리케이션은 구성을 위해 환경 변수를 사용합니다. Cloud Shell 터미널에서 다음 블록을 실행하여 이 세션에 필요한 변수를 설정합니다.
export REGION="us-central1" export INSTANCE_NAME="living-memory-db" export DB_HOST=127.0.0.1 export DB_PORT=5432 export DB_USER=memory_app export DB_PASS=memory_app_password export DB_NAME=living_memory export PGPASSWORD=$DB_PASS - 인스턴스를 만듭니다. 이 단계는 일반적으로 5~10분이 소요됩니다.
gcloud sql instances create $INSTANCE_NAME \ --database-version=POSTGRES_16 \ --cpu=1 \ --memory=3840MB \ --region=$REGION \ --root-password=$DB_PASS \ --edition=ENTERPRISEvector확장 프로그램을 사용 설정하고 애플리케이션을 지원하기 위해 여러 테이블을 만듭니다.
users,conversations,messages: 사용자 프로필 및 대화 기록을 저장하는 표준 테이블입니다.memories: 검색 증강 생성 (RAG)의 핵심 테이블입니다. 각 행은 대화에서 추출된 정보 조각 (예: '사용자가 하이킹을 좋아함')을 나타냅니다. 다음 정보를 저장합니다.content: 기억의 텍스트입니다.memory_type: 기억의 유형 (FACT,PREF또는IMPLICIT).embedding: Gemini에서 생성한 콘텐츠의 시맨틱 표현을 포함하는 768차원vector열입니다.
pgvector색인:HNSW(Hierarchical Navigable Small World) 색인이embedding열에 생성됩니다. 이는 k-최근접 이웃 (k-NN) 검색을 최적화하는 데 매우 중요하며pgvector가 코사인 거리 연산자 (<=>)를 사용하여 의미론적으로 가장 유사한 기억을 빠르게 찾을 수 있도록 합니다.
- 데이터베이스 만들기
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME - 애플리케이션 사용자 만들기
gcloud sql users create $DB_USER --instance=$INSTANCE_NAME --password=$DB_PASS - Cloud SQL 인증 프록시를 시작합니다. 프록시는 IP 허용 목록을 구성하지 않고도 인스턴스에 안전하게 액세스할 수 있도록 합니다.
(cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:us-central1:living-memory-db &) && sleep 2 && echo ""The proxy has started successfully and is ready for new connections!와 같은 메시지가 표시됩니다. schema.sql을 적용하여vector확장 프로그램을 사용 설정하고 필요한 테이블을 만듭니다. 이제 프록시가 실행 중이므로127.0.0.1에서 인스턴스에 연결할 수 있습니다.psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME < schema.sql- 스키마가 성공적으로 생성되었는지 확인합니다.
psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME -c "\dt"conversations,memories,messages,users테이블을 나열하는 출력이 표시됩니다.List of relations Schema | Name | Type | Owner --------+---------------+-------+------------ public | conversations | table | memory_app public | memories | table | memory_app public | messages | table | memory_app public | queries_log | table | memory_app public | users | table | memory_app (5 rows)
5. pgvector를 사용한 시맨틱 검색 이해
이 섹션에서는 애플리케이션이 응답을 생성하기 전에 AI와 관련된 컨텍스트를 검색하는 방법을 살펴봅니다. 다음은 /api/chat 엔드포인트에서 이 작업을 담당하는 코드를 보여주는 server.js의 스니펫입니다.
// Retrieve Similar Memories for Context (Using pgvector)
const promptEmbeddingRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: message,
config: { outputDimensionality: 768 },
});
const promptEmbedding = promptEmbeddingRes.embeddings[0].values;
const embeddingStr = `[${promptEmbedding.join(',')}]`;
// Query DB for top 5 closest memories
const relevantMemories = await pool.query(
`SELECT id, content, memory_type, category
FROM memories
WHERE user_id = $1
ORDER BY embedding <=> $2::vector
LIMIT 5`,
[userId, embeddingStr]
);
작동 방식
- 생성형 AI (임베딩): 애플리케이션은 사용자의 받은 메시지를 가져와
gemini-embedding-001모델을 사용하여 텍스트를 768차원 벡터로 변환합니다. 이 벡터는 메시지의 시맨틱 의미를 나타냅니다. - Cloud SQL (pgvector): 애플리케이션은 해당 벡터를 Cloud SQL에 전달합니다.
pgvector확장 프로그램에서 제공하는<=>(코사인 거리) 연산자를 사용하여 Cloud SQL은 프롬프트와 의미론적으로 가장 유사한 5개의 기억을 찾습니다. - 결과: 검색 증강 생성 (RAG)입니다. AI는 전체 기록을 로드할 필요 없이 데이터베이스에서 구체적이고 관련성 있는 기억에 액세스하여 응답을 맞춤설정합니다.
6. 기억 추출 이해
다음으로 애플리케이션이 대화에서 학습하는 방법을 살펴봅니다. 다음 스니펫은 server.js의 extractMemoriesAsync 함수에서 가져온 것입니다.
// MEMORY EXTRACTION LOGIC
async function extractMemoriesAsync(userMessage, userId, messageId) {
const extractionPrompt = `
Analyze the following user message. A memory profile is being built for this user.
Extract ANY explicit facts (Facts), preferences (Pref), or implicit behavioral traits/styles (Implicit).
Return the result as a raw JSON array of objects (NO Markdown blocks, just the JSON array).
Format: [{"content": "string fact/sentence", "type": "FACT|PREF|IMPLICIT", "category": "General|Travel|Hobby|Persona"}]
If nothing is found, return [].
Message: "${userMessage}"
`;
const result = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: extractionPrompt
});
let rawJson = result.text.replace(/^```json/g, '').replace(/```$/g, '').trim();
let extracted;
try {
extracted = JSON.parse(rawJson);
} catch (e) {
console.warn("Could not parse extracted JSON:", rawJson);
return;
}
if (Array.isArray(extracted) && extracted.length > 0) {
// Compute embeddings and save each to the DB
for (const memory of extracted) {
const embedRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: memory.content,
config: { outputDimensionality: 768 },
});
const vectorData = `[${embedRes.embeddings[0].values.join(',')}]`;
await pool.query(
`INSERT INTO memories (user_id, content, memory_type, category, embedding, source_message_id)
VALUES ($1, $2, $3, $4, $5, $6)`,
[userId, memory.content, memory.type.toUpperCase(), memory.category, vectorData, messageId]
);
console.log(`Saved new memory: ${memory.content}`);
}
}
}
작동 방식
- 생성형 AI (구조화된 출력): 애플리케이션은 초고속
gemini-2.5-flash모델을 사용하여 사용자의 메시지를 분석하고 구조화된 사실과 환경설정을 JSON 배열로 추출합니다. - Cloud SQL (하이브리드 스토리지): 이러한 새로운 사실에 대한 임베딩을 생성한 후 Cloud SQL에 저장됩니다. 표준 관계형 데이터 (사용자 ID, 텍스트 콘텐츠, 카테고리)가 단일 행의 고차원 벡터 데이터와 함께 저장됩니다.
- 결과: 이 앱은 Gemini의 분석 기능과 Cloud SQL의 스토리지 기능을 모두 활용하여 실시간으로 자동 업데이트되는 기억 프로필을 빌드합니다.
7. 채팅 애플리케이션 실행
- 몇 가지 예시 사용자로 데이터베이스 시드
npm run seed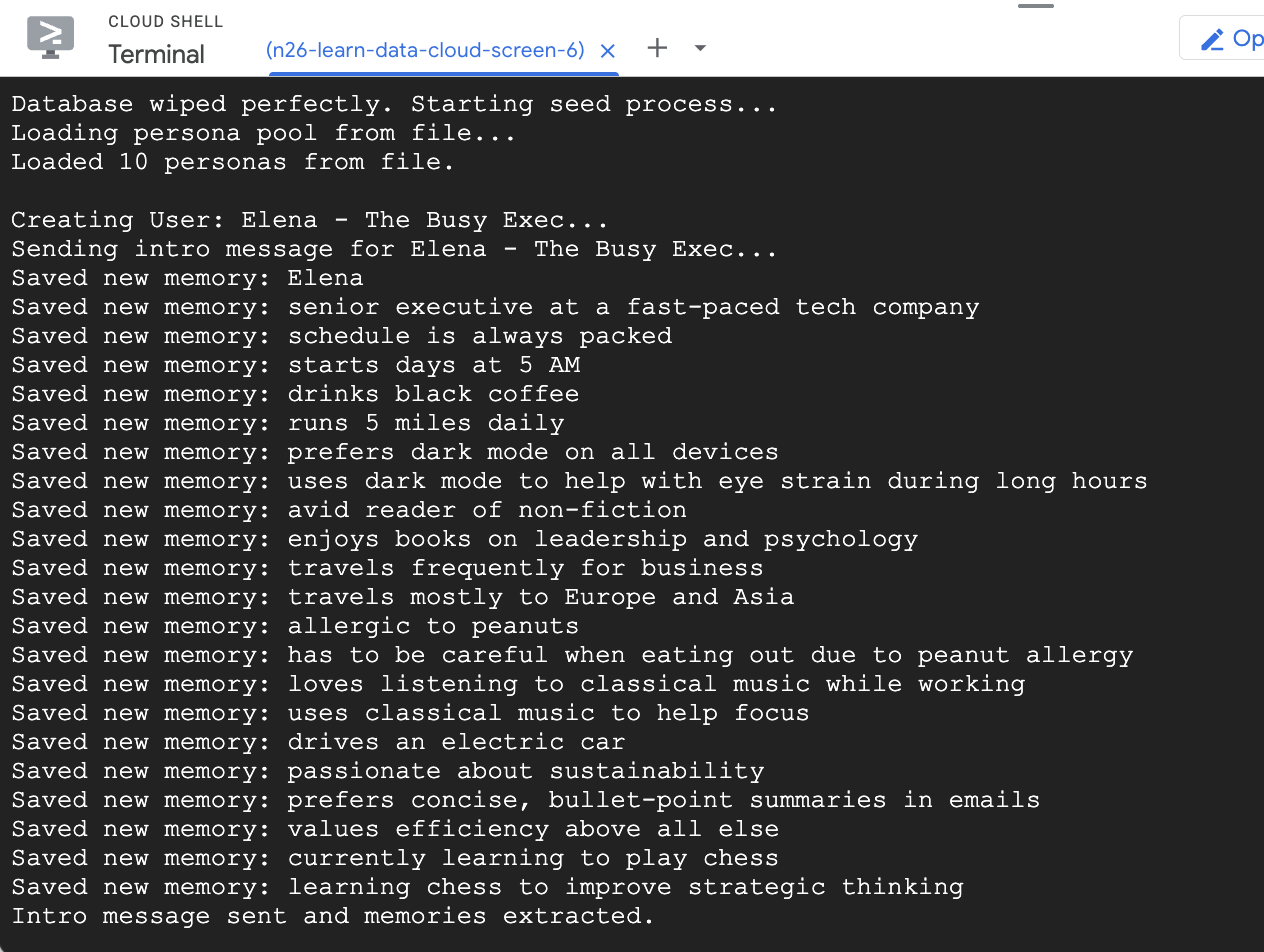
- 그런 다음 서버를 실행합니다.
node server.js - Cloud Shell에서 터미널 툴바의 오른쪽 상단에 있는 웹 미리보기 를 클릭하고 포트 변경 을 선택합니다. 포트 번호에
3000을 입력하고 변경 및 미리보기 를 클릭합니다.
어시스턴트와 상호작용
브라우저에서 애플리케이션을 열면 Living Memory 채팅 인터페이스가 표시됩니다. 오른쪽의 AI Cortex 데이터 시각화 도구 는 메모리를 벡터 공간의 노드로 표시하며 유형 (사실, 환경설정, 암시적 특성)별로 색상으로 구분됩니다. 화면 해상도에 따라 기억 노드의 텍스트가 작을 수 있습니다. 마우스 또는 트랙패드를 사용하여 확대/축소하고 패닝하여 자세히 살펴보세요.
기존 기억 쿼리
앞서 실행한 seed 스크립트는 미리 채워진 기억이 있는 두 개의 샘플 사용자를 만들었습니다.
- 왼쪽 상단의 사용자 드롭다운 메뉴에서 사용자를 선택합니다.
- 빠른 채팅 버튼 중 하나를 사용하거나 채팅 입력에
Give me restaurant recommendations in New York City를 입력하고 보내기 를 누릅니다. - 어시스턴트가 응답하면 어시스턴트의 메시지를 클릭하여 사용된 기억을 확인할 수 있습니다. 기억은 녹색으로 강조 표시되며 기억을 확대/축소하여 응답을 형성하는 데 어떻게 도움이 되었는지 확인할 수 있습니다.
신규 사용자 만들기
이제 신규 사용자를 만들어 보겠습니다.
- 사용자 드롭다운 옆에 있는 + 버튼을 클릭하여 새 채팅 세션을 시작합니다.
- 생성된 이름과 설명을 사용하거나 자신을 설명하도록 수정합니다.
- 만들기 를 클릭하고 애플리케이션이 기억 추출을 시작하는지 확인합니다. 약 30초 후에 오른쪽의 시각화 도구에 새 노드가 표시됩니다. 이는 Gemini가 메시지에서 추출하여 Cloud SQL 데이터베이스에 저장한 사실과 환경설정을 나타냅니다.
What food do I like?와 같은 후속 질문을 하여 어시스턴트가 대화에서 새로 획득한 기억을 사용하는지 확인합니다.
8. 정리
이 Codelab에서 사용한 리소스 비용이 Google Cloud 계정에 계속 청구되지 않도록 하려면 생성한 리소스를 삭제해야 합니다.
- Cloud SQL 인스턴스를 삭제합니다.
gcloud sql instances delete $INSTANCE_NAME --quiet - 데모 저장소를 삭제합니다.
rm -rf ~/devrel-demos
9. 축하합니다
'Living Memory' AI 어시스턴트를 빌드하고 배포했습니다.
학습한 내용
- 시맨틱 검색을 위해 Cloud SQL pgvector 를 사용하는 방법
- 동적 기억 추출을 위해 Gemini 를 사용하는 방법
다음 단계
- Cloud SQL pgvector 문서를 살펴봅니다.
- Gemini API 기능에 관해 자세히 알아봅니다.
- Cloud SQL 인증 프록시를 자세히 알아봅니다.
server.js에서extractionPrompt를 맞춤설정하여 다양한 유형의 데이터를 추출해 보세요.
Living Memory로 빌드해 보세요.