
1. Wprowadzenie
Z tego ćwiczenia dowiesz się, jak utworzyć demonstrację Living Memory, czyli asystenta opartego na AI, który śledzi „wspomnienia” z Twojej rozmowy, aby zapewnić spersonalizowane działanie.
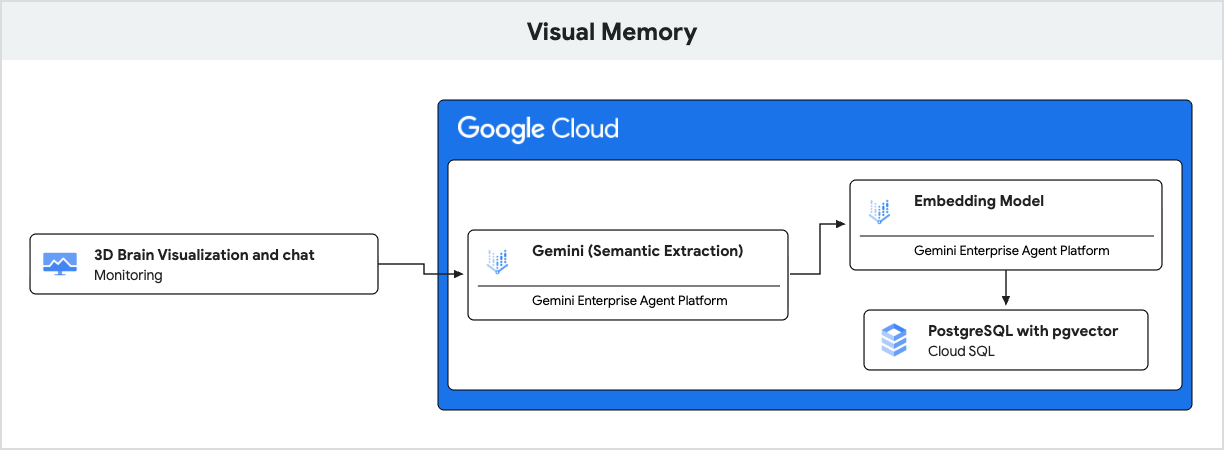
Aplikacja korzysta z Gemini do rozumienia języka naturalnego i Cloud SQL for PostgreSQL z rozszerzeniem pgvector do przechowywania i pobierania tych wspomnień na podstawie podobieństwa semantycznego.
Te warsztaty są przeznaczone dla programistów o różnym poziomie umiejętności, którzy interesują się AI i bazami danych. Ich ukończenie powinno zająć około 60 minut. Utworzone zasoby powinny kosztować mniej niż 5 USD.
Jakie zadania wykonasz
- Jak skonfigurować instancję Cloud SQL for PostgreSQL z obsługą
pgvector. - Jak używać Gemini do interaktywnego wyodrębniania „wspomnień” z wiadomości użytkownika.
- Jak przeprowadzać wyszukiwania wektorowe w PostgreSQL, aby uzyskać odpowiedni kontekst dla odpowiedzi AI.
Czego potrzebujesz
- Projekt Google Cloud z włączonymi płatnościami.
- Podstawowa znajomość wiersza poleceń i Node.js.
2. Zanim zaczniesz
Konfigurowanie projektu
Tworzenie projektu Google Cloud
- W konsoli Google Cloud na stronie selektora projektu wybierz lub utwórz projekt w chmurze Google.
- Sprawdź, czy w projekcie Cloud włączone są płatności. Dowiedz się, jak sprawdzić, czy w projekcie są włączone płatności.
Uruchamianie Cloud Shell
Cloud Shell to środowisko wiersza poleceń działające w Google Cloud, które zawiera niezbędne narzędzia.
- Kliknij Aktywuj Cloud Shell u góry konsoli Google Cloud.
- Po połączeniu z Cloud Shell sprawdź uwierzytelnianie:
gcloud auth list - Sprawdź, czy projekt jest skonfigurowany:
gcloud config get project - Jeśli projekt nie jest ustawiony zgodnie z oczekiwaniami, ustaw go:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Włącz interfejsy API
Aby włączyć wymagane interfejsy API, uruchom to polecenie w Cloud Shell:
gcloud services enable sqladmin.googleapis.com \
aiplatform.googleapis.com
3. Klonowanie repozytorium demonstracyjnego
Teraz pobierz kod wersji demonstracyjnej Living Memory.
- Sklonuj repozytorium do środowiska Cloud Shell:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git cd devrel-demos/codelabs/visual-memory-postgres-demo - Zainstaluj zależności:
npm install
4. Tworzenie i konfigurowanie bazy danych Cloud SQL
W tej sekcji utworzysz instancję Cloud SQL, zainicjujesz bazę danych i skonfigurujesz schemat.
- Aplikacja używa zmiennych środowiskowych do konfiguracji. Aby ustawić wymagane zmienne dla tej sesji, uruchom w terminalu Cloud Shell ten blok:
export REGION="us-central1" export INSTANCE_NAME="living-memory-db" export DB_HOST=127.0.0.1 export DB_PORT=5432 export DB_USER=memory_app export DB_PASS=memory_app_password export DB_NAME=living_memory export PGPASSWORD=$DB_PASS - Utwórz instancję. Ten etap zwykle zajmuje 5–10 minut.
gcloud sql instances create $INSTANCE_NAME \ --database-version=POSTGRES_16 \ --cpu=1 \ --memory=3840MB \ --region=$REGION \ --root-password=$DB_PASS \ --edition=ENTERPRISEvectori tworzy kilka tabel na potrzeby aplikacji:
users,conversations,messages: standardowe tabele do przechowywania profili użytkowników i historii rozmów.memories: to podstawowa tabela do generowania wspomaganego wyszukiwaniem (RAG). Każdy wiersz zawiera informacje wyodrębnione z rozmowy (np. „Użytkownik lubi wędrówki”). Zawiera ona:content: tekst pamięci.memory_type: typ pamięci (FACT,PREFlubIMPLICIT).embedding: kolumnavectoro wymiarze 768 zawierająca reprezentację semantyczną treści wygenerowaną przez Gemini.
pgvectorIndeks: w kolumnieembeddingtworzony jestHNSW(Hierarchical Navigable Small World). Jest to kluczowe w przypadku optymalizacji wyszukiwania k-najbliższych sąsiadów (k-NN), co pozwalapgvectorszybko znajdować najbardziej podobne semantycznie wspomnienia za pomocą operatora odległości kosinusowej (<=>).
- Tworzenie bazy danych
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME - Tworzenie użytkownika aplikacji
gcloud sql users create $DB_USER --instance=$INSTANCE_NAME --password=$DB_PASS - Uruchom serwer proxy uwierzytelniania Cloud SQL. Serwer proxy zapewnia bezpieczny dostęp do instancji bez konieczności konfigurowania listy dozwolonych adresów IP.
(cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:us-central1:living-memory-db &) && sleep 2 && echo ""The proxy has started successfully and is ready for new connections!. - Zastosuj
schema.sql, aby włączyć rozszerzenievectori utworzyć niezbędne tabele. Serwer proxy działa, więc możesz teraz połączyć się z instancją pod adresem127.0.0.1.psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME < schema.sql - Sprawdź, czy schemat został utworzony.
psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME -c "\dt"conversations,memories,messagesiusers.List of relations Schema | Name | Type | Owner --------+---------------+-------+------------ public | conversations | table | memory_app public | memories | table | memory_app public | messages | table | memory_app public | queries_log | table | memory_app public | users | table | memory_app (5 rows)
5. Zrozumienie wyszukiwania semantycznego za pomocą pgvector
W tej sekcji dowiesz się, jak aplikacja pobiera odpowiedni kontekst dla AI przed wygenerowaniem odpowiedzi. Poniższy fragment kodu z server.js pokazuje kod odpowiedzialny za to w punkcie końcowym /api/chat:
// Retrieve Similar Memories for Context (Using pgvector)
const promptEmbeddingRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: message,
config: { outputDimensionality: 768 },
});
const promptEmbedding = promptEmbeddingRes.embeddings[0].values;
const embeddingStr = `[${promptEmbedding.join(',')}]`;
// Query DB for top 5 closest memories
const relevantMemories = await pool.query(
`SELECT id, content, memory_type, category
FROM memories
WHERE user_id = $1
ORDER BY embedding <=> $2::vector
LIMIT 5`,
[userId, embeddingStr]
);
Jak to działa
- Generatywna AI (wektory dystrybucyjne): aplikacja pobiera przychodzącą wiadomość użytkownika i za pomocą modelu
gemini-embedding-001przekształca tekst w 768-wymiarowy wektor. Ten wektor reprezentuje znaczenie semantyczne wiadomości. - Cloud SQL (pgvector): aplikacja przekazuje ten wektor do Cloud SQL. Za pomocą operatora
<=>(odległość cosinusowa) udostępnianego przez rozszerzeniepgvectorCloud SQL znajduje 5 pamięci najbardziej podobnych semantycznie do promptu. - Wynik: jest to generowanie wspomagane wyszukiwaniem (RAG). AI uzyskuje dostęp do konkretnych, istotnych wspomnień z bazy danych, aby spersonalizować odpowiedź bez konieczności wczytywania całej historii.
6. Informacje o wyodrębnianiu pamięci
Następnie sprawdź, jak aplikacja uczy się na podstawie rozmowy. Poniższy fragment pochodzi z funkcji extractMemoriesAsync w server.js:
// MEMORY EXTRACTION LOGIC
async function extractMemoriesAsync(userMessage, userId, messageId) {
const extractionPrompt = `
Analyze the following user message. A memory profile is being built for this user.
Extract ANY explicit facts (Facts), preferences (Pref), or implicit behavioral traits/styles (Implicit).
Return the result as a raw JSON array of objects (NO Markdown blocks, just the JSON array).
Format: [{"content": "string fact/sentence", "type": "FACT|PREF|IMPLICIT", "category": "General|Travel|Hobby|Persona"}]
If nothing is found, return [].
Message: "${userMessage}"
`;
const result = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: extractionPrompt
});
let rawJson = result.text.replace(/^```json/g, '').replace(/```$/g, '').trim();
let extracted;
try {
extracted = JSON.parse(rawJson);
} catch (e) {
console.warn("Could not parse extracted JSON:", rawJson);
return;
}
if (Array.isArray(extracted) && extracted.length > 0) {
// Compute embeddings and save each to the DB
for (const memory of extracted) {
const embedRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: memory.content,
config: { outputDimensionality: 768 },
});
const vectorData = `[${embedRes.embeddings[0].values.join(',')}]`;
await pool.query(
`INSERT INTO memories (user_id, content, memory_type, category, embedding, source_message_id)
VALUES ($1, $2, $3, $4, $5, $6)`,
[userId, memory.content, memory.type.toUpperCase(), memory.category, vectorData, messageId]
);
console.log(`Saved new memory: ${memory.content}`);
}
}
}
Jak to działa
- Generatywna AI (dane wyjściowe w formacie strukturalnym): aplikacja używa ultraszybkiego modelu
gemini-2.5-flashdo analizowania wiadomości użytkownika i wyodrębniania strukturalnych faktów i preferencji w postaci tablicy JSON. - Cloud SQL (pamięć hybrydowa): po wygenerowaniu wektorów dystrybucyjnych dla tych nowych faktów są one przechowywane w Cloud SQL. Zwróć uwagę, że standardowe dane relacyjne (identyfikator użytkownika, treść tekstowa, kategorie) są przechowywane w jednym wierszu obok wielowymiarowych danych wektorowych.
- Wynik: aplikacja tworzy w czasie rzeczywistym automatycznie aktualizowany profil pamięci, wykorzystując zarówno możliwości analityczne Gemini, jak i funkcje przechowywania danych Cloud SQL.
7. Uruchamianie aplikacji do czatowania
- Wypełnij bazę danych kilkoma przykładowymi użytkownikami
npm run seed
- Następnie uruchom serwer.
node server.js - W Cloud Shell w prawym górnym rogu paska narzędzi terminala kliknij Podgląd w przeglądarce i wybierz Zmień port. Wpisz
3000jako numer portu i kliknij Zmień i wyświetl podgląd.
Interakcja z asystentem
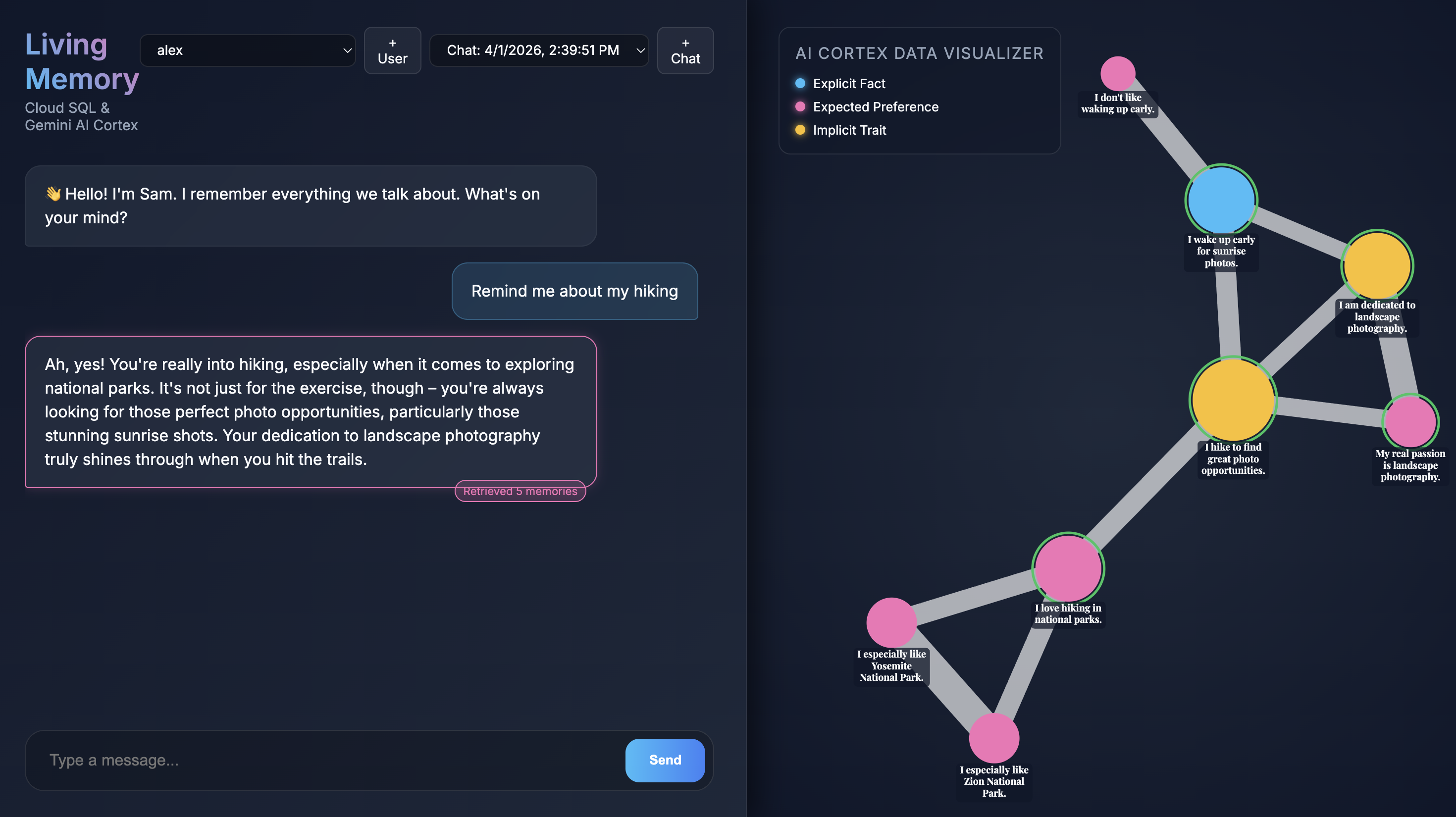
Gdy aplikacja otworzy się w przeglądarce, zobaczysz interfejs czatu Living Memory. Po prawej stronie wizualizator danych AI Cortex wyświetla pamięć jako węzły w przestrzeni wektorowej, oznaczone kolorami według typu (Fakt, Preferencje, Cechy ukryte). Tekst w węzłach pamięci może być mały w zależności od rozdzielczości ekranu. Aby przyjrzeć się mu bliżej, użyj myszy lub trackpada do powiększania i przesuwania.
Wyszukiwanie istniejących wspomnień
seed skrypt uruchomiony wcześniej utworzył 2 przykładowych użytkowników z wstępnie wypełnionymi wspomnieniami.
- W menu użytkowników w lewym górnym rogu wybierz użytkownika.
- Użyj jednego z przycisków szybkiego czatu lub wpisz
Give me restaurant recommendations in New York Cityw polu czatu i naciśnij Wyślij. - Gdy Asystent odpowie, możesz kliknąć jego wiadomość, aby zobaczyć, z których zapamiętanych informacji skorzystał. Zostaną one wyróżnione na zielono. Możesz je powiększyć i sprawdzić, jak wpłynęły na odpowiedź.
Tworzenie nowego użytkownika
Teraz utwórzmy nowego użytkownika.
- Kliknij przycisk + obok menu użytkownika, aby rozpocząć nową sesję czatu.
- Użyj wygenerowanej nazwy i opisu lub zmień je, aby opisać siebie.
- Kliknij Utwórz, aby rozpocząć wyodrębnianie wspomnień przez aplikację. Po około 30 sekundach w wizualizatorze po prawej stronie powinny pojawić się nowe węzły. Są to fakty i preferencje wyodrębnione przez Gemini z Twojej wiadomości i przechowywane w bazie danych Cloud SQL.
- Zadaj pytanie uzupełniające, np.
What food do I like?, aby zobaczyć, jak Asystent wykorzystuje w rozmowie nowo zdobyte informacje.
8. Czyszczenie danych
Aby uniknąć obciążenia konta Google Cloud bieżącymi opłatami za zasoby użyte w tym ćwiczeniu, usuń utworzone zasoby.
- Usuń instancję Cloud SQL:
gcloud sql instances delete $INSTANCE_NAME --quiet - Usuń repozytorium demonstracyjne:
rm -rf ~/devrel-demos
9. Gratulacje
Udało Ci się utworzyć i wdrożyć asystenta AI „Living Memory”.
Czego się dowiedziałeś(-aś)
- Jak używać Cloud SQL pgvector do wyszukiwania semantycznego.
- Jak używać Gemini do dynamicznego wyodrębniania zapamiętanych informacji.
Dalsze kroki
- Zapoznaj się z dokumentacją Cloud SQL pgvector.
- Dowiedz się więcej o funkcjach Gemini API.
- Szczegółowe informacje o serwerze proxy uwierzytelniania Cloud SQL.
- Spróbuj dostosować
extractionPromptwserver.js, aby wyodrębnić różne typy danych.
Ciesz się budowaniem dzięki funkcji Żywe wspomnienia.