
1. Introdução
Neste codelab, você vai aprender a criar a Demonstração de memória viva, um assistente com tecnologia de IA que rastreia "memórias" da sua conversa para oferecer uma experiência personalizada.
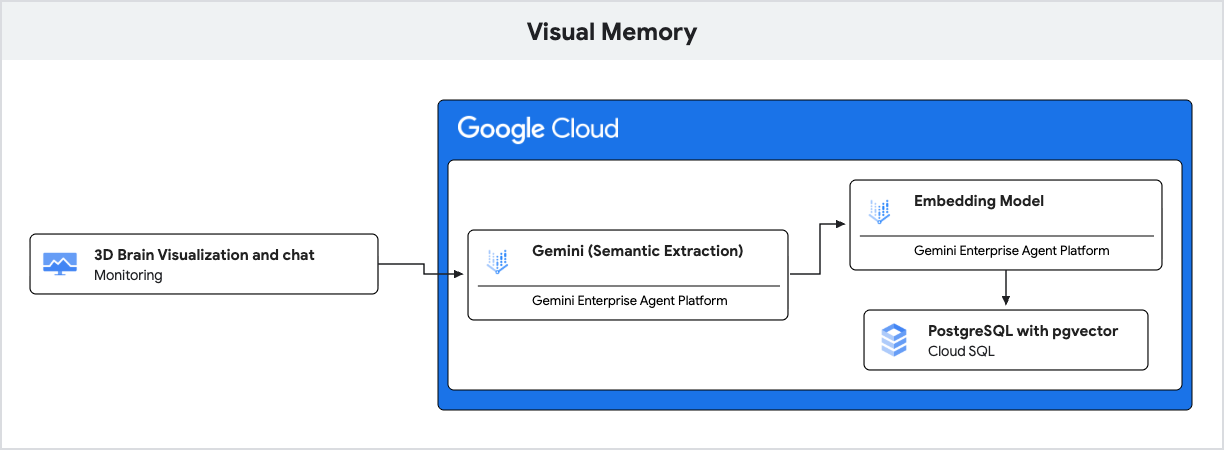
O aplicativo usa o Gemini para compreensão de linguagem natural e o Cloud SQL para PostgreSQL com a extensão pgvector para armazenar e recuperar essas memórias com base na similaridade semântica.
Este codelab é destinado a desenvolvedores de todos os níveis de habilidade interessados em IA e bancos de dados e leva cerca de 60 minutos para ser concluído. Os recursos criados devem custar menos de US $5.
Atividades deste laboratório
- Como configurar uma instância do Cloud SQL para PostgreSQL com suporte a
pgvector. - Como usar o Gemini para extrair "memórias" de mensagens do usuário de forma interativa.
- Como realizar pesquisas vetoriais no PostgreSQL para recuperar o contexto relevante das respostas de IA.
O que é necessário
- Ter um projeto do Google Cloud com o faturamento ativado.
- Conhecimento básico da linha de comando e do Node.js.
2. Antes de começar
Configurar o projeto
Criar um projeto do Google Cloud
- No console do Google Cloud, na página do seletor de projetos, selecione ou crie um projeto na nuvem do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto do Cloud. Saiba como verificar se o faturamento está ativado em um projeto.
Iniciar o Cloud Shell
O Cloud Shell é um ambiente de linha de comando executado no Google Cloud que vem pré-carregado com as ferramentas necessárias.
- Clique em Ativar o Cloud Shell na parte de cima do console do Google Cloud.
- Depois de se conectar ao Cloud Shell, verifique sua autenticação:
gcloud auth list - Confirme se o projeto está configurado:
gcloud config get project - Se o projeto não estiver definido como esperado, faça o seguinte:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Ativar APIs
Execute o comando a seguir no Cloud Shell para ativar as APIs necessárias:
gcloud services enable sqladmin.googleapis.com \
aiplatform.googleapis.com
3. Clonar o repositório de demonstração
Agora, acesse o código da demonstração de Living Memory.
- Clone o repositório no ambiente do Cloud Shell:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git cd devrel-demos/codelabs/visual-memory-postgres-demo - Instale as dependências:
npm install
4. Criar e configurar o banco de dados do Cloud SQL
Nesta seção, você vai criar uma instância do Cloud SQL, inicializar um banco de dados e configurar o esquema.
- O aplicativo usa variáveis de ambiente para configuração. Execute o bloco a seguir no terminal do Cloud Shell para definir as variáveis necessárias para esta sessão:
export REGION="us-central1" export INSTANCE_NAME="living-memory-db" export DB_HOST=127.0.0.1 export DB_PORT=5432 export DB_USER=memory_app export DB_PASS=memory_app_password export DB_NAME=living_memory export PGPASSWORD=$DB_PASS - Crie a instância. Essa etapa geralmente leva de 5 a 10 minutos.
gcloud sql instances create $INSTANCE_NAME \ --database-version=POSTGRES_16 \ --cpu=1 \ --memory=3840MB \ --region=$REGION \ --root-password=$DB_PASS \ --edition=ENTERPRISEvectore cria várias tabelas para oferecer suporte ao aplicativo:
users,conversations,messages: tabelas padrão para armazenar perfis de usuários e histórico de conversas.memories: Esta é a tabela principal para a geração aumentada por recuperação (RAG). Cada linha representa uma informação extraída da conversa (por exemplo, "O usuário gosta de fazer caminhadas"). Ele armazena:content: o texto da recordação.memory_type: o tipo de memória (FACT,PREFouIMPLICIT).embedding: uma colunavectorde 768 dimensões que contém a representação semântica do conteúdo, gerada pelo Gemini.
- Índice
pgvector: um índiceHNSW(Hierarchical Navigable Small World) é criado na colunaembedding. Isso é fundamental para otimizar as pesquisas de vizinho k-mais próximo (k-NN), permitindo que opgvectorencontre rapidamente as memórias semanticamente mais semelhantes usando o operador de distância de cosseno (<=>).
- Criar o banco de dados
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME - Criar o usuário do aplicativo
gcloud sql users create $DB_USER --instance=$INSTANCE_NAME --password=$DB_PASS - Inicie o proxy de autenticação do Cloud SQL. O proxy oferece acesso seguro à instância sem precisar configurar a lista de permissões de IP.
(cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:us-central1:living-memory-db &) && sleep 2 && echo ""The proxy has started successfully and is ready for new connections!. - Aplique o
schema.sqlpara ativar a extensãovectore criar as tabelas necessárias. Como o proxy está em execução, agora você pode se conectar à sua instância em127.0.0.1.psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME < schema.sql - Verifique se a criação do esquema foi bem-sucedida.
psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME -c "\dt"conversations,memories,messageseusers.List of relations Schema | Name | Type | Owner --------+---------------+-------+------------ public | conversations | table | memory_app public | memories | table | memory_app public | messages | table | memory_app public | queries_log | table | memory_app public | users | table | memory_app (5 rows)
5. Entender a recuperação semântica com pgvector
Nesta seção, você vai examinar como o aplicativo recupera o contexto relevante para a IA antes de gerar uma resposta. O snippet a seguir de server.js mostra o código responsável por isso no endpoint /api/chat:
// Retrieve Similar Memories for Context (Using pgvector)
const promptEmbeddingRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: message,
config: { outputDimensionality: 768 },
});
const promptEmbedding = promptEmbeddingRes.embeddings[0].values;
const embeddingStr = `[${promptEmbedding.join(',')}]`;
// Query DB for top 5 closest memories
const relevantMemories = await pool.query(
`SELECT id, content, memory_type, category
FROM memories
WHERE user_id = $1
ORDER BY embedding <=> $2::vector
LIMIT 5`,
[userId, embeddingStr]
);
Como funciona
- IA generativa (embedding): o aplicativo recebe a mensagem recebida do usuário e usa o modelo
gemini-embedding-001para converter o texto em um vetor de 768 dimensões. Esse vetor representa o significado semântico da mensagem. - Cloud SQL (pgvector): o aplicativo transmite esse vetor para o Cloud SQL. Usando o operador
<=>(distância de cosseno) fornecido pela extensãopgvector, o Cloud SQL encontra as cinco memórias mais semanticamente semelhantes ao comando. - O resultado: isso é a geração aumentada por recuperação (RAG). A IA acessa memórias específicas e relevantes do banco de dados para personalizar a resposta, sem precisar carregar todo o histórico.
6. Entender a extração de memória
Em seguida, veja como o aplicativo aprende com a conversa. O snippet a seguir é da função extractMemoriesAsync em server.js:
// MEMORY EXTRACTION LOGIC
async function extractMemoriesAsync(userMessage, userId, messageId) {
const extractionPrompt = `
Analyze the following user message. A memory profile is being built for this user.
Extract ANY explicit facts (Facts), preferences (Pref), or implicit behavioral traits/styles (Implicit).
Return the result as a raw JSON array of objects (NO Markdown blocks, just the JSON array).
Format: [{"content": "string fact/sentence", "type": "FACT|PREF|IMPLICIT", "category": "General|Travel|Hobby|Persona"}]
If nothing is found, return [].
Message: "${userMessage}"
`;
const result = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: extractionPrompt
});
let rawJson = result.text.replace(/^```json/g, '').replace(/```$/g, '').trim();
let extracted;
try {
extracted = JSON.parse(rawJson);
} catch (e) {
console.warn("Could not parse extracted JSON:", rawJson);
return;
}
if (Array.isArray(extracted) && extracted.length > 0) {
// Compute embeddings and save each to the DB
for (const memory of extracted) {
const embedRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: memory.content,
config: { outputDimensionality: 768 },
});
const vectorData = `[${embedRes.embeddings[0].values.join(',')}]`;
await pool.query(
`INSERT INTO memories (user_id, content, memory_type, category, embedding, source_message_id)
VALUES ($1, $2, $3, $4, $5, $6)`,
[userId, memory.content, memory.type.toUpperCase(), memory.category, vectorData, messageId]
);
console.log(`Saved new memory: ${memory.content}`);
}
}
}
Como funciona
- IA generativa (saída estruturada): o aplicativo usa o modelo
gemini-2.5-flashultrarrápido para analisar a mensagem do usuário e extrair fatos e preferências estruturados como uma matriz JSON. - Cloud SQL (armazenamento híbrido): depois de gerar embeddings para esses novos fatos, eles são armazenados no Cloud SQL. Os dados relacionais padrão (ID do usuário, conteúdo de texto, categorias) são armazenados ao lado dos dados vetoriais de alta dimensão em uma única linha.
- O resultado: o app cria um perfil de memória com atualização automática em tempo real, aproveitando o poder analítico do Gemini e os recursos de armazenamento do Cloud SQL.
7. Executar o aplicativo de chat
- Propagar o banco de dados com alguns usuários de exemplo
npm run seed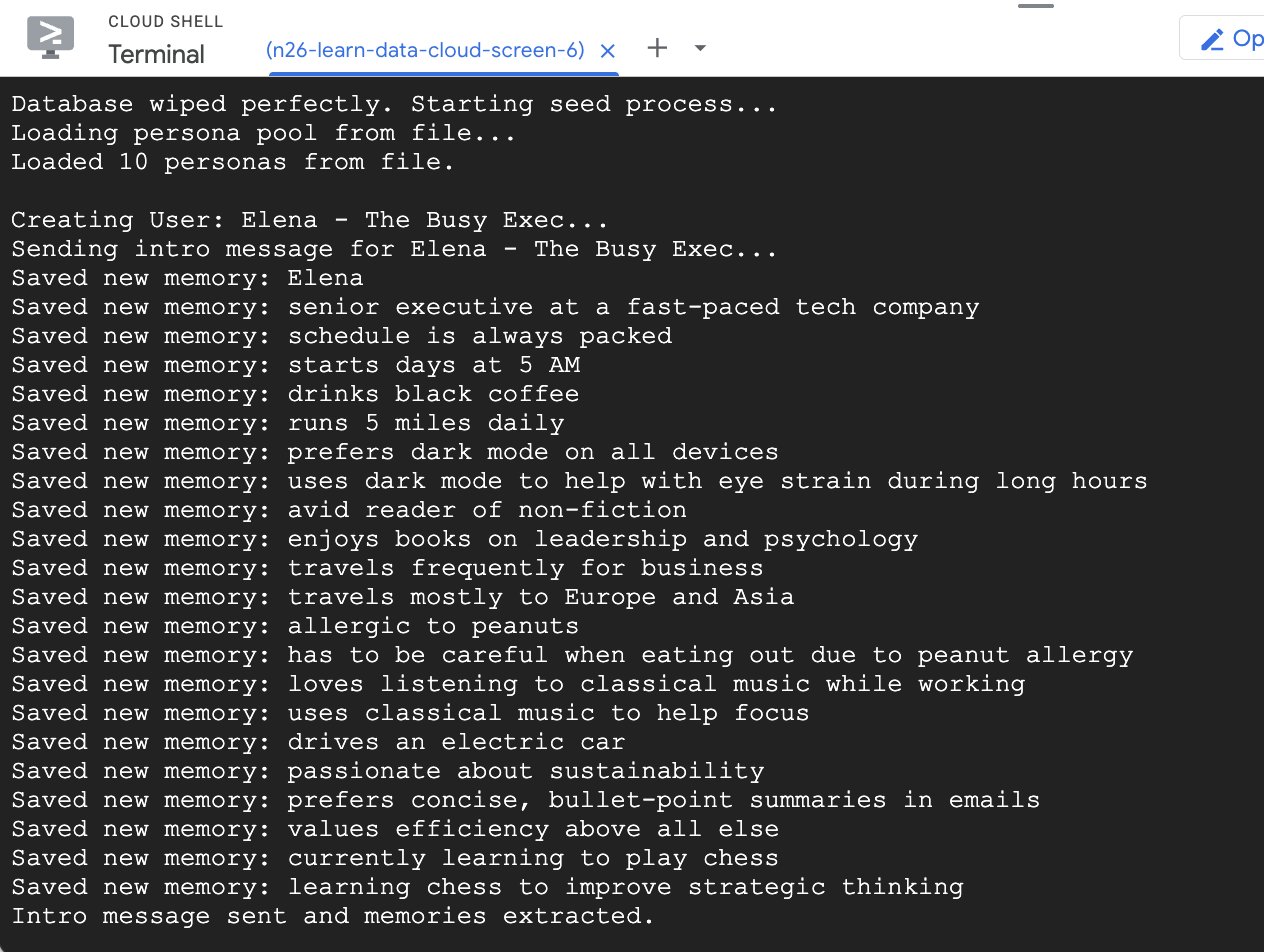
- Em seguida, execute o servidor
node server.js - No Cloud Shell, clique em Visualização da Web, no canto superior direito da barra de ferramentas do terminal, e selecione Alterar porta. Digite
3000para o número da porta e clique em Alterar e visualizar.
Interagir com o assistente
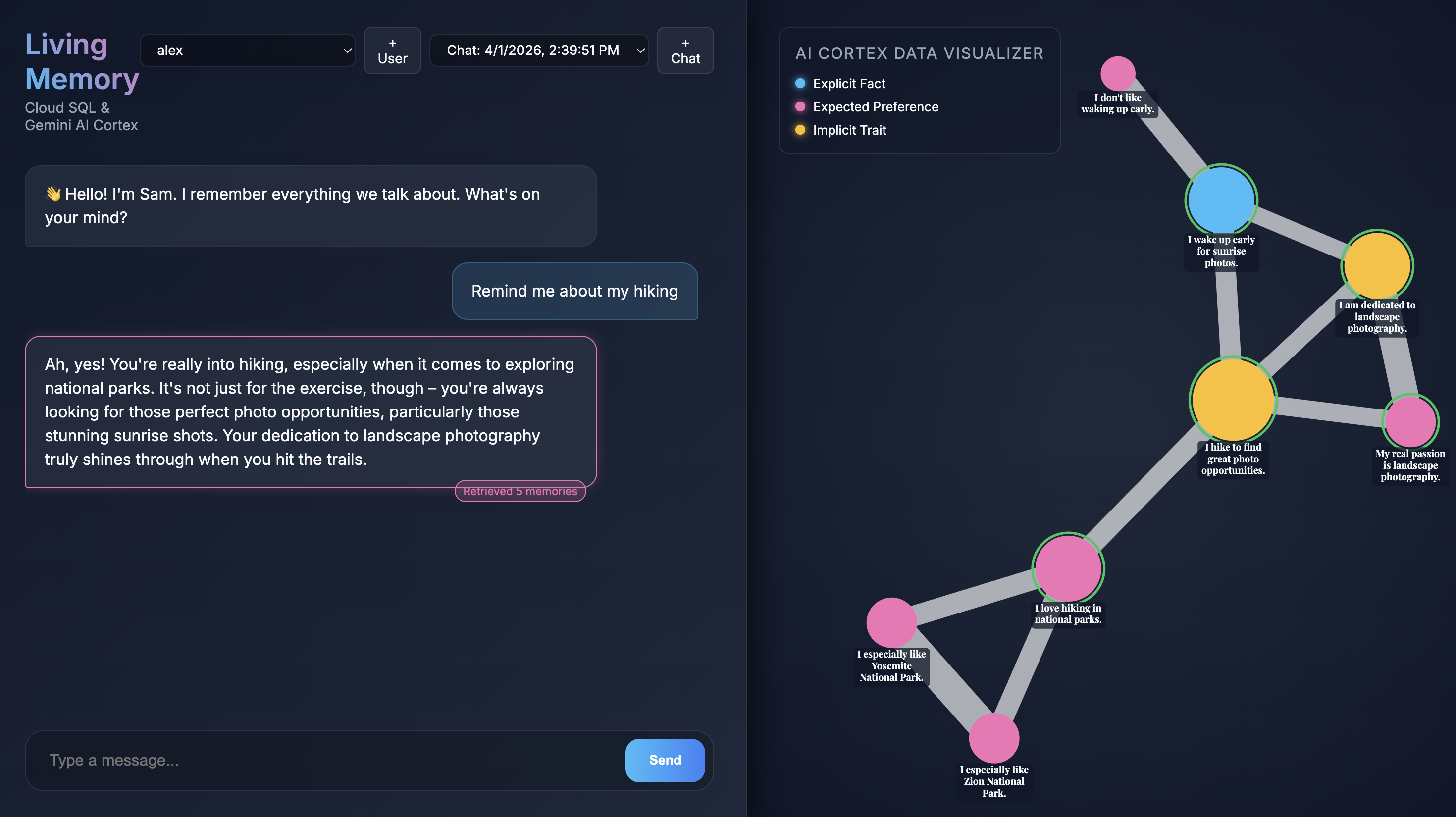
Quando o aplicativo abrir no navegador, você vai ver a interface de chat da Living Memory. À direita, o Visualizador de dados da IA do Cortex mostra as recordações como nós em um espaço vetorial, codificados por cores de acordo com o tipo (fato, preferência, característica implícita). O texto nos nós de memória pode ser pequeno, dependendo da resolução da tela. Use o mouse ou o trackpad para ampliar e mover a tela e ver melhor.
Consultar recordações
O script seed executado anteriormente criou dois usuários de amostra com algumas memórias pré-preenchidas.
- Selecione um usuário no menu suspenso de usuários no canto superior esquerdo.
- Use um dos botões de conversa rápida ou digite
Give me restaurant recommendations in New York Cityna entrada de texto do chat e pressione Enviar. - Quando o assistente responder, clique na mensagem dele para ver quais memórias foram usadas. Elas vão aparecer destacadas em verde, e você pode ampliar para ver como ajudaram a formar a resposta.
Criar um novo usuário
Agora, vamos criar um novo usuário.
- Clique no botão + ao lado do menu suspenso de usuários para iniciar uma nova sessão de chat.
- Use o nome e a descrição gerados ou edite-os para se descrever.
- Clique em Criar e veja o aplicativo começar a extrair recordações. Em cerca de 30 segundos, novos nós vão aparecer no visualizador à direita. Eles representam os fatos e as preferências que o Gemini extraiu da sua mensagem e armazenou no banco de dados do Cloud SQL.
- Faça uma pergunta complementar, como
What food do I like?, para ver o assistente usar as memórias recém-adquiridas na conversa.
8. Limpar
Para evitar cobranças contínuas na sua conta do Google Cloud pelos recursos usados neste codelab, exclua os recursos criados.
- Exclua a instância do Cloud SQL:
gcloud sql instances delete $INSTANCE_NAME --quiet - Remova o repositório de demonstração:
rm -rf ~/devrel-demos
9. Parabéns
Você criou e implantou um assistente de IA "Living Memory".
O que você aprendeu
- Como usar o pgvector do Cloud SQL para pesquisa semântica.
- Como usar o Gemini para extração dinâmica de memória.
Próximas etapas
- Confira a documentação do pgvector do Cloud SQL.
- Saiba mais sobre os recursos da API Gemini.
- Saiba mais sobre o proxy de autenticação do Cloud SQL.
- Tente personalizar o
extractionPromptemserver.jspara extrair diferentes tipos de dados.
Aproveite a construção com a Living Memory!