
1. Введение
В этом практическом занятии вы узнаете, как создать демонстрационную версию Living Memory Demo — голосового помощника на основе искусственного интеллекта, который отслеживает «воспоминания» о ваших разговорах, чтобы обеспечить персонализированный подход.
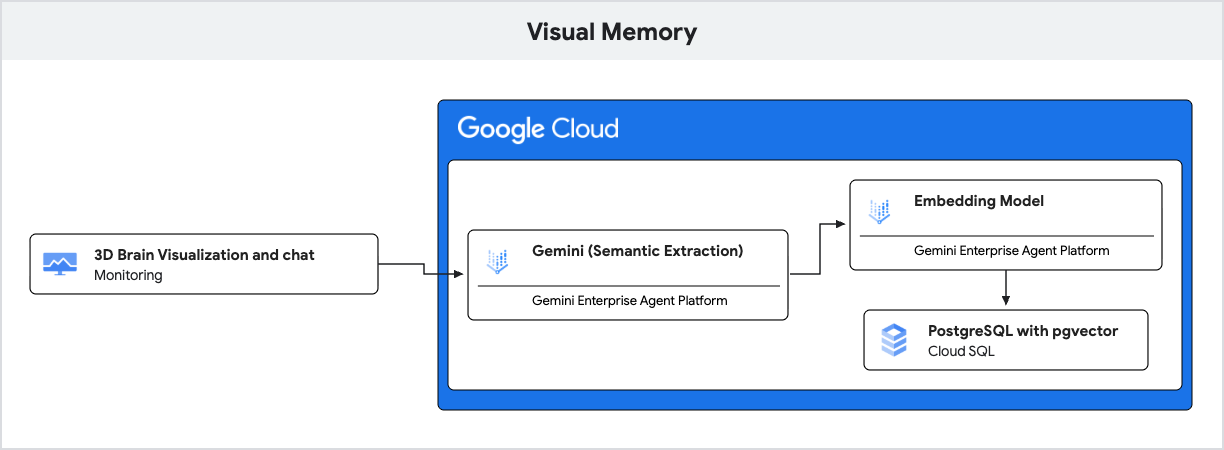
Приложение использует Gemini для обработки естественного языка и Cloud SQL для PostgreSQL с расширением pgvector для хранения и извлечения этих данных на основе семантического сходства.
Этот практический урок предназначен для разработчиков любого уровня подготовки, интересующихся искусственным интеллектом и базами данных, и должен занять около 60 минут. Стоимость созданных ресурсов должна составлять менее 5 долларов.
Что вы будете делать
- Как настроить экземпляр Cloud SQL для PostgreSQL с поддержкой
pgvector. - Как использовать Gemini для интерактивного извлечения «воспоминаний» из сообщений пользователей.
- Как выполнять векторный поиск в PostgreSQL для получения релевантного контекста для ответов ИИ.
Что вам понадобится
- Проект Google Cloud с включенной функцией выставления счетов.
- Базовые знания командной строки и Node.js.
2. Прежде чем начать
Настройка проекта
Создайте проект в Google Cloud.
- В консоли Google Cloud на странице выбора проекта выберите или создайте проект Google Cloud .
- Убедитесь, что для вашего облачного проекта включена функция выставления счетов. Узнайте, как проверить, включена ли функция выставления счетов для проекта .
Запустить Cloud Shell
Cloud Shell — это среда командной строки, работающая в Google Cloud и поставляемая с предустановленными необходимыми инструментами.
- В верхней части консоли Google Cloud нажмите кнопку «Активировать Cloud Shell» .
- После подключения к Cloud Shell подтвердите свою аутентификацию:
gcloud auth list - Убедитесь, что ваш проект настроен:
gcloud config get project - Если параметры вашего проекта заданы не так, как ожидалось, настройте их следующим образом:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Включить API
Для включения необходимых API выполните следующую команду в Cloud Shell :
gcloud services enable sqladmin.googleapis.com \
aiplatform.googleapis.com
3. Клонируйте репозиторий с демонстрационными примерами.
Теперь получите код для демоверсии Living Memory.
- Клонируйте репозиторий в свою среду Cloud Shell:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git cd devrel-demos/codelabs/visual-memory-postgres-demo - Установите зависимости:
npm install
4. Создайте и настройте базу данных Cloud SQL.
В этом разделе вы создадите экземпляр Cloud SQL, инициализируете базу данных и настроите схему.
- Приложение использует переменные среды для настройки. Выполните следующий блок кода в терминале Cloud Shell, чтобы установить необходимые переменные для этой сессии:
export REGION="us-central1" export INSTANCE_NAME="living-memory-db" export DB_HOST=127.0.0.1 export DB_PORT=5432 export DB_USER=memory_app export DB_PASS=memory_app_password export DB_NAME=living_memory export PGPASSWORD=$DB_PASS - Создайте экземпляр. Этот шаг обычно занимает 5-10 минут.
gcloud sql instances create $INSTANCE_NAME \ --database-version=POSTGRES_16 \ --cpu=1 \ --memory=3840MB \ --region=$REGION \ --root-password=$DB_PASS \ --edition=ENTERPRISEvectorи создает несколько таблиц для поддержки приложения:
-
users,conversations,messages: Стандартные таблицы для хранения профилей пользователей и истории бесед. -
memories: Это основная таблица для генерации информации с использованием методов дополненного поиска (Retrieval-Augmented Generation, RAG). Каждая строка представляет собой фрагмент информации, извлеченный из разговора (например, «Пользователь любит походы»). В ней хранится:-
content: Текст воспоминания. -
memory_type: Тип памяти (FACT,PREFилиIMPLICIT). -
embedding: 768-мерныйvectorстолбец, содержащий семантическое представление контента, сгенерированное Gemini.
-
- Индекс
pgvector: На столбцеembeddingсоздается индексHNSW(Hierarchical Navigable Small World) . Это имеет решающее значение для оптимизации поиска k-ближайших соседей (k-NN), позволяяpgvectorбыстро находить наиболее семантически похожие воспоминания с помощью оператора косинусного расстояния (<=>).
-
- Создайте базу данных.
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME - Создайте пользователя приложения.
gcloud sql users create $DB_USER --instance=$INSTANCE_NAME --password=$DB_PASS - Запустите прокси-сервер Cloud SQL Auth. Прокси-сервер обеспечивает безопасный доступ к вашему экземпляру без необходимости настройки списка разрешенных IP-адресов.
(cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:us-central1:living-memory-db &) && sleep 2 && echo ""The proxy has started successfully and is ready for new connections!. - Примените файл
schema.sql, чтобы включитьvectorрасширение и создать необходимые таблицы. Поскольку прокси-сервер запущен, теперь вы можете подключиться к своему экземпляру по адресу127.0.0.1.psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME < schema.sql - Убедитесь, что создание схемы прошло успешно.
psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME -c "\dt"conversations,memories,messagesиusers.List of relations Schema | Name | Type | Owner --------+---------------+-------+------------ public | conversations | table | memory_app public | memories | table | memory_app public | messages | table | memory_app public | queries_log | table | memory_app public | users | table | memory_app (5 rows)
5. Понимание семантического поиска с помощью pgvector
В этом разделе вы изучите, как приложение получает необходимый контекст для ИИ перед генерацией ответа. Следующий фрагмент кода из server.js показывает код, отвечающий за это в конечной точке /api/chat :
// Retrieve Similar Memories for Context (Using pgvector)
const promptEmbeddingRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: message,
config: { outputDimensionality: 768 },
});
const promptEmbedding = promptEmbeddingRes.embeddings[0].values;
const embeddingStr = `[${promptEmbedding.join(',')}]`;
// Query DB for top 5 closest memories
const relevantMemories = await pool.query(
`SELECT id, content, memory_type, category
FROM memories
WHERE user_id = $1
ORDER BY embedding <=> $2::vector
LIMIT 5`,
[userId, embeddingStr]
);
Как это работает
- Gen AI (Embedding) : Приложение принимает входящее сообщение от пользователя и использует модель
gemini-embedding-001для преобразования текста в 768-мерный вектор. Этот вектор представляет семантическое значение сообщения. - Cloud SQL (pgvector) : Приложение передает этот вектор в Cloud SQL. Используя оператор
<=>(косинусное расстояние), предоставляемый расширениемpgvector, Cloud SQL находит 5 ячеек памяти, наиболее семантически похожих на подсказку. - Результат : Это генерация с расширенным извлечением информации (Retrieval-Augmented Generation, RAG). Искусственный интеллект получает доступ к конкретным, релевантным воспоминаниям из базы данных, чтобы персонализировать свой ответ, без необходимости загрузки всей истории.
6. Понимание процесса извлечения информации из памяти.
Далее рассмотрим, как приложение обучается на основе диалога. Следующий фрагмент кода взят из функции extractMemoriesAsync в server.js :
// MEMORY EXTRACTION LOGIC
async function extractMemoriesAsync(userMessage, userId, messageId) {
const extractionPrompt = `
Analyze the following user message. A memory profile is being built for this user.
Extract ANY explicit facts (Facts), preferences (Pref), or implicit behavioral traits/styles (Implicit).
Return the result as a raw JSON array of objects (NO Markdown blocks, just the JSON array).
Format: [{"content": "string fact/sentence", "type": "FACT|PREF|IMPLICIT", "category": "General|Travel|Hobby|Persona"}]
If nothing is found, return [].
Message: "${userMessage}"
`;
const result = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: extractionPrompt
});
let rawJson = result.text.replace(/^```json/g, '').replace(/```$/g, '').trim();
let extracted;
try {
extracted = JSON.parse(rawJson);
} catch (e) {
console.warn("Could not parse extracted JSON:", rawJson);
return;
}
if (Array.isArray(extracted) && extracted.length > 0) {
// Compute embeddings and save each to the DB
for (const memory of extracted) {
const embedRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: memory.content,
config: { outputDimensionality: 768 },
});
const vectorData = `[${embedRes.embeddings[0].values.join(',')}]`;
await pool.query(
`INSERT INTO memories (user_id, content, memory_type, category, embedding, source_message_id)
VALUES ($1, $2, $3, $4, $5, $6)`,
[userId, memory.content, memory.type.toUpperCase(), memory.category, vectorData, messageId]
);
console.log(`Saved new memory: ${memory.content}`);
}
}
}
Как это работает
- Генерация искусственного интеллекта (структурированный вывод) : Приложение использует сверхбыструю модель
gemini-2.5-flashдля анализа сообщений пользователя и извлечения структурированных фактов и предпочтений в виде массива JSON. - Cloud SQL (гибридное хранилище) : После генерации эмбеддингов для этих новых фактов они сохраняются в Cloud SQL. Обратите внимание, что стандартные реляционные данные (идентификатор пользователя, текстовое содержимое, категории) хранятся рядом с многомерными векторными данными в одной строке.
- Результат : приложение в режиме реального времени создает самообновляющийся профиль памяти, используя как аналитические возможности Gemini, так и возможности хранения данных Cloud SQL.
7. Запустите приложение чата.
- Заполните базу данных несколькими примерами пользователей.
npm run seed
- Затем запустите сервер.
node server.js - В Cloud Shell нажмите кнопку «Предварительный просмотр веб-страниц» в правом верхнем углу панели инструментов терминала и выберите «Изменить порт» . Введите
3000в качестве номера порта и нажмите «Изменить и просмотреть» .
Взаимодействуйте с ассистентом.
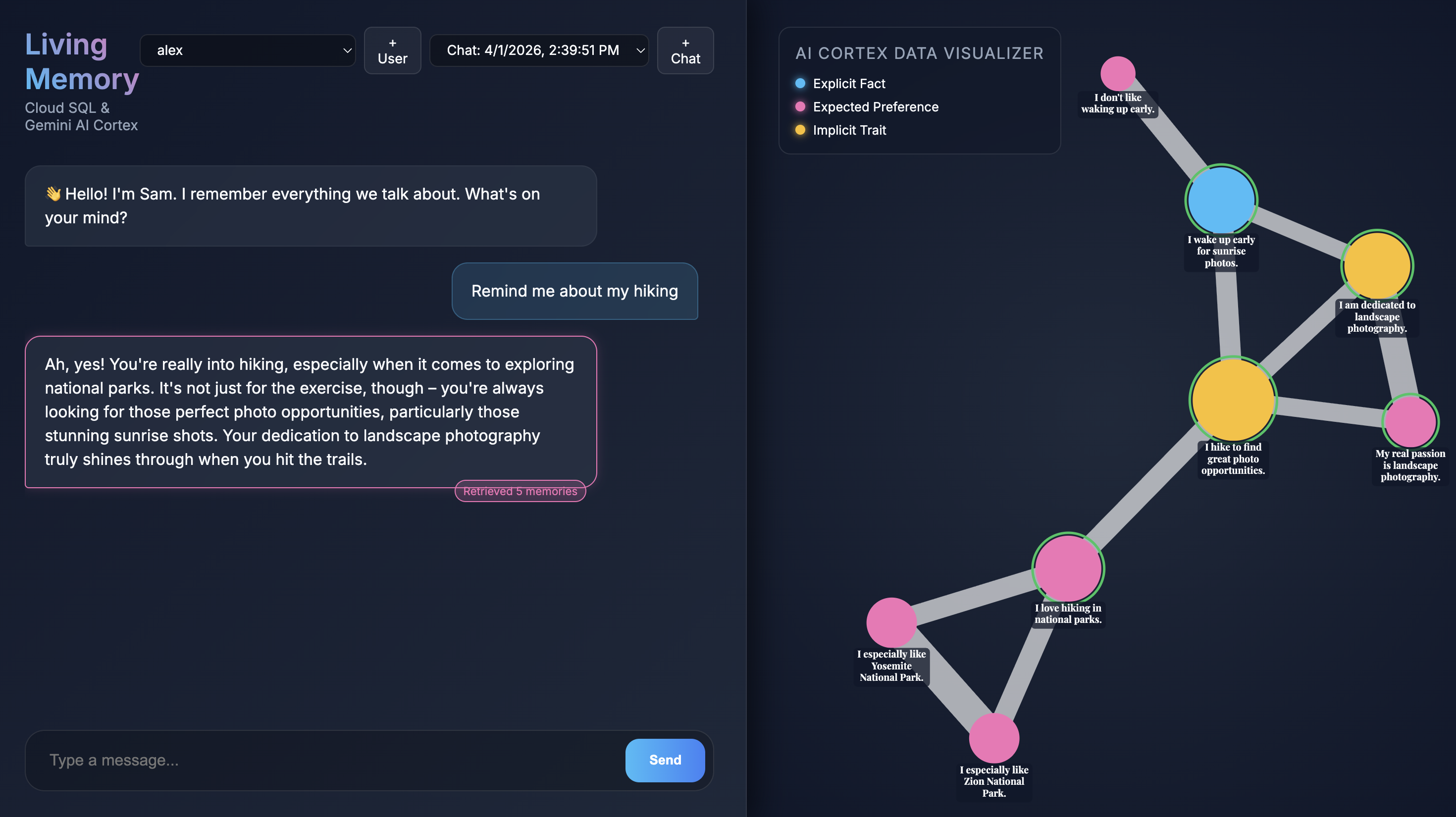
Когда приложение откроется в вашем браузере, вы увидите интерфейс чата Living Memory. Справа визуализатор данных AI Cortex отображает воспоминания в виде узлов в векторном пространстве, раскрашенных по типу (факт, предпочтение, неявная черта). Текст на узлах воспоминаний может быть мелким в зависимости от разрешения вашего экрана; используйте мышь или трекпад для масштабирования и перемещения, чтобы рассмотреть их подробнее.
Запрос существующих воспоминаний
Запущенный вами ранее скрипт seed создал двух тестовых пользователей с предварительно заполненными данными о состоянии памяти.
- Выберите пользователя из выпадающего меню пользователей в верхнем левом углу.
- Воспользуйтесь одной из кнопок быстрого чата или введите в поле чата запрос
Give me restaurant recommendations in New York Cityи нажмите « Отправить» . - Когда помощник отвечает, вы можете щелкнуть по его сообщению, чтобы увидеть, какие воспоминания он использовал. Они будут выделены зеленым цветом, и вы сможете увеличить масштаб, чтобы увидеть, как они помогли сформировать ответ.
Создать нового пользователя
Теперь давайте создадим нового пользователя.
- Нажмите кнопку «+» рядом с выпадающим списком пользователей, чтобы начать новую сессию чата.
- Используйте сгенерированные имя и описание или отредактируйте их, чтобы они описывали вас.
- Нажмите «Создать» , и приложение начнет извлекать воспоминания. Примерно через 30 секунд в визуализаторе справа должны появиться новые узлы. Они представляют факты и предпочтения, которые Gemini извлекло из вашего сообщения и сохранило в базе данных Cloud SQL.
- Задайте уточняющий вопрос, например:
What food do I like?чтобы увидеть, как ассистент использует свои недавно приобретенные знания в разговоре.
8. Уборка
Чтобы избежать постоянного списания средств с вашего аккаунта Google Cloud за ресурсы, использованные в этом практическом задании, вам следует удалить созданные вами ресурсы.
- Удалите экземпляр Cloud SQL:
gcloud sql instances delete $INSTANCE_NAME --quiet - Удалите репозиторий с демонстрационными примерами:
rm -rf ~/devrel-demos
9. Поздравляем!
Вы успешно создали и развернули ИИ-помощника с «живой памятью»!
Что вы узнали
- Как использовать Cloud SQL pgvector для семантического поиска.
- Как использовать Gemini для извлечения данных из динамической памяти.
Следующие шаги
- Изучите документацию Cloud SQL pgvector .
- Узнайте больше о возможностях API Gemini .
- Подробный анализ Cloud SQL Auth Proxy .
- Попробуйте настроить параметр
extractionPromptвserver.jsдля извлечения данных разных типов!
Наслаждайтесь строительством с помощью Living Memory!