
1. บทนำ
ใน Codelab นี้ คุณจะได้เรียนรู้วิธีสร้างเดโม Living Memory ซึ่งเป็นผู้ช่วยที่ทำงานด้วยระบบ AI ที่ติดตาม "ความทรงจำ" ของการสนทนาเพื่อมอบประสบการณ์การใช้งานที่ปรับเปลี่ยนในแบบของคุณ
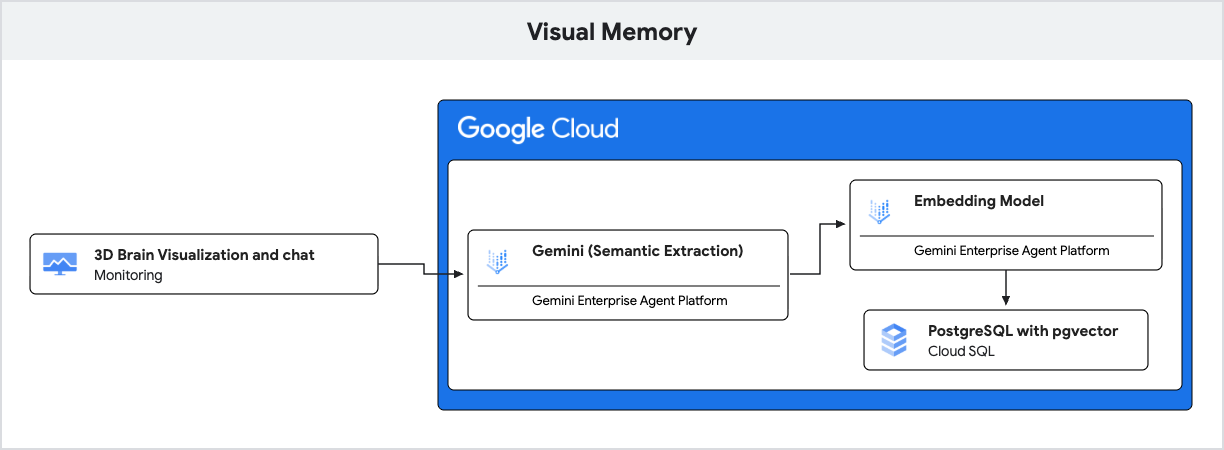
แอปพลิเคชันใช้ Gemini สำหรับความเข้าใจภาษาธรรมชาติ และ Cloud SQL สำหรับ PostgreSQL ที่มีส่วนขยาย pgvector เพื่อจัดเก็บและดึงข้อมูลความทรงจำเหล่านี้ตามความคล้ายคลึงเชิงความหมาย
Codelab นี้มีไว้สำหรับนักพัฒนาซอฟต์แวร์ทุกระดับทักษะที่สนใจ AI และฐานข้อมูล และควรใช้เวลาประมาณ 60 นาทีในการทําให้เสร็จ ทรัพยากรที่สร้างขึ้นควรมีค่าใช้จ่ายน้อยกว่า $5
สิ่งที่คุณต้องดำเนินการ
- วิธีตั้งค่าอินสแตนซ์ Cloud SQL สำหรับ PostgreSQL ที่มี
pgvector - วิธีใช้ Gemini เพื่อดึง "ความทรงจำ" จากข้อความของผู้ใช้แบบอินเทอร์แอกทีฟ
- วิธีทำการค้นหาเวกเตอร์ใน PostgreSQL เพื่อดึงบริบทที่เกี่ยวข้องสำหรับคำตอบของ AI
สิ่งที่คุณต้องมี
- โปรเจ็กต์ Google Cloud ที่เปิดใช้การเรียกเก็บเงิน
- มีความรู้พื้นฐานเกี่ยวกับบรรทัดคำสั่งและ Node.js
2. ก่อนเริ่มต้น
การตั้งค่าโปรเจ็กต์
สร้างโปรเจ็กต์ Google Cloud
- ในคอนโซล Google Cloud ในหน้าตัวเลือกโปรเจ็กต์ ให้เลือกหรือสร้างโปรเจ็กต์ Google Cloud
- ตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินสำหรับโปรเจ็กต์ที่อยู่ในระบบคลาวด์แล้ว ดูวิธีตรวจสอบว่าได้เปิดใช้การเรียกเก็บเงินในโปรเจ็กต์แล้วหรือไม่
เริ่มต้น Cloud Shell
Cloud Shell คือสภาพแวดล้อมบรรทัดคำสั่งที่ทำงานใน Google Cloud ซึ่งโหลดเครื่องมือที่จำเป็นไว้ล่วงหน้า
- คลิกเปิดใช้งาน Cloud Shell ที่ด้านบนของคอนโซล Google Cloud
- เมื่อเชื่อมต่อกับ Cloud Shell แล้ว ให้ยืนยันการตรวจสอบสิทธิ์โดยทำดังนี้
gcloud auth list - ตรวจสอบว่าได้กำหนดค่าโปรเจ็กต์แล้ว
gcloud config get project - หากไม่ได้ตั้งค่าโปรเจ็กต์ตามที่คาดไว้ ให้ตั้งค่าดังนี้
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
เปิดใช้ API
เรียกใช้คำสั่งต่อไปนี้ใน Cloud Shell เพื่อเปิดใช้ API ที่จำเป็น
gcloud services enable sqladmin.googleapis.com \
aiplatform.googleapis.com
3. โคลนที่เก็บการสาธิต
ตอนนี้ให้รับรหัสสำหรับเดโมความทรงจำที่มีชีวิต
- โคลนที่เก็บไปยังสภาพแวดล้อม Cloud Shell
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git cd devrel-demos/codelabs/visual-memory-postgres-demo - ติดตั้งการอ้างอิง:
npm install
4. สร้างและกำหนดค่าฐานข้อมูล Cloud SQL
ในส่วนนี้ คุณจะสร้างอินสแตนซ์ Cloud SQL เริ่มต้นฐานข้อมูล และตั้งค่าสคีมา
- แอปพลิเคชันใช้ตัวแปรสภาพแวดล้อมสำหรับการกำหนดค่า เรียกใช้บล็อกต่อไปนี้ในเทอร์มินัล Cloud Shell เพื่อตั้งค่าตัวแปรที่จำเป็นสำหรับเซสชันนี้
export REGION="us-central1" export INSTANCE_NAME="living-memory-db" export DB_HOST=127.0.0.1 export DB_PORT=5432 export DB_USER=memory_app export DB_PASS=memory_app_password export DB_NAME=living_memory export PGPASSWORD=$DB_PASS - สร้างอินสแตนซ์ ขั้นตอนนี้มักใช้เวลา 5-10 นาที
gcloud sql instances create $INSTANCE_NAME \ --database-version=POSTGRES_16 \ --cpu=1 \ --memory=3840MB \ --region=$REGION \ --root-password=$DB_PASS \ --edition=ENTERPRISEvectorและสร้างตารางหลายรายการเพื่อรองรับแอปพลิเคชัน
users,conversations,messages: ตารางมาตรฐานสำหรับจัดเก็บโปรไฟล์ผู้ใช้และประวัติการสนทนาmemories: นี่คือตารางหลักสำหรับ Retrieval-Augmented Generation (RAG) แต่ละแถวแสดงข้อมูลที่ดึงมาจากการสนทนา (เช่น "ผู้ใช้ชอบเดินป่า") โดยจะเก็บข้อมูลต่อไปนี้content: ข้อความของความทรงจำmemory_type: ประเภทของหน่วยความจำ (FACT,PREFหรือIMPLICIT)embedding: คอลัมน์vectorที่มีมิติ 768 ซึ่งมีการแสดงความหมายของเนื้อหาที่ Gemini สร้างขึ้น
pgvectorดัชนี: สร้างดัชนีHNSW(Hierarchical Navigable Small World) ในคอลัมน์embeddingซึ่งมีความสําคัญอย่างยิ่งต่อการเพิ่มประสิทธิภาพการค้นหา k-Nearest Neighbor (k-NN) เพื่อให้pgvectorค้นหาความทรงจําที่คล้ายกันมากที่สุดในเชิงความหมายได้อย่างรวดเร็วโดยใช้ตัวดำเนินการระยะทางโคไซน์ (<=>)
- สร้างฐานข้อมูล
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME - สร้างผู้ใช้แอปพลิเคชัน
gcloud sql users create $DB_USER --instance=$INSTANCE_NAME --password=$DB_PASS - เริ่มพร็อกซีการตรวจสอบสิทธิ์ Cloud SQL พร็อกซีช่วยให้เข้าถึงอินสแตนซ์ได้อย่างปลอดภัยโดยไม่ต้องกำหนดค่ารายการที่อนุญาต IP
(cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:us-central1:living-memory-db &) && sleep 2 && echo ""The proxy has started successfully and is ready for new connections! - ใช้
schema.sqlเพื่อเปิดใช้ส่วนขยายvectorและสร้างตารางที่จำเป็น เนื่องจากพร็อกซีทำงานอยู่ ตอนนี้คุณจึงเชื่อมต่อกับอินสแตนซ์ได้ที่127.0.0.1psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME < schema.sql - ยืนยันว่าสร้างสคีมาสำเร็จแล้ว
psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME -c "\dt"conversations,memories,messagesและusersList of relations Schema | Name | Type | Owner --------+---------------+-------+------------ public | conversations | table | memory_app public | memories | table | memory_app public | messages | table | memory_app public | queries_log | table | memory_app public | users | table | memory_app (5 rows)
5. ทำความเข้าใจการดึงข้อมูลเชิงความหมายด้วย pgvector
ในส่วนนี้ คุณจะได้ดูว่าแอปพลิเคชันดึงบริบทที่เกี่ยวข้องสำหรับ AI ก่อนที่จะสร้างคำตอบได้อย่างไร ข้อมูลโค้ดต่อไปนี้จาก server.js แสดงโค้ดที่รับผิดชอบในส่วนนี้ในปลายทาง /api/chat
// Retrieve Similar Memories for Context (Using pgvector)
const promptEmbeddingRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: message,
config: { outputDimensionality: 768 },
});
const promptEmbedding = promptEmbeddingRes.embeddings[0].values;
const embeddingStr = `[${promptEmbedding.join(',')}]`;
// Query DB for top 5 closest memories
const relevantMemories = await pool.query(
`SELECT id, content, memory_type, category
FROM memories
WHERE user_id = $1
ORDER BY embedding <=> $2::vector
LIMIT 5`,
[userId, embeddingStr]
);
วิธีการทำงาน
- Gen AI (การฝัง): แอปพลิเคชันจะรับข้อความขาเข้าของผู้ใช้และใช้โมเดล
gemini-embedding-001เพื่อแปลงข้อความเป็นเวกเตอร์ 768 มิติ เวกเตอร์นี้แสดงความหมายเชิงความหมายของข้อความ - Cloud SQL (pgvector): แอปพลิเคชันจะส่งเวกเตอร์นั้นไปยัง Cloud SQL Cloud SQL ใช้โอเปอเรเตอร์
<=>(ระยะทางโคไซน์) ที่จัดทำโดยส่วนขยายpgvectorเพื่อค้นหาความทรงจำ 5 รายการที่มีความหมายคล้ายกับพรอมต์มากที่สุด - ผลลัพธ์: นี่คือการสร้างที่เพิ่มประสิทธิภาพการดึงข้อมูล (RAG) AI จะได้รับสิทธิ์เข้าถึงความทรงจำที่เฉพาะเจาะจงและเกี่ยวข้องจากฐานข้อมูลเพื่อปรับคำตอบในแบบของคุณโดยไม่ต้องโหลดประวัติทั้งหมด
6. ทำความเข้าใจการแยกข้อมูลหน่วยความจำ
จากนั้นดูว่าแอปพลิเคชันเรียนรู้จากการสนทนาได้อย่างไร ข้อมูลโค้ดต่อไปนี้มาจากฟังก์ชัน extractMemoriesAsync ใน server.js
// MEMORY EXTRACTION LOGIC
async function extractMemoriesAsync(userMessage, userId, messageId) {
const extractionPrompt = `
Analyze the following user message. A memory profile is being built for this user.
Extract ANY explicit facts (Facts), preferences (Pref), or implicit behavioral traits/styles (Implicit).
Return the result as a raw JSON array of objects (NO Markdown blocks, just the JSON array).
Format: [{"content": "string fact/sentence", "type": "FACT|PREF|IMPLICIT", "category": "General|Travel|Hobby|Persona"}]
If nothing is found, return [].
Message: "${userMessage}"
`;
const result = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: extractionPrompt
});
let rawJson = result.text.replace(/^```json/g, '').replace(/```$/g, '').trim();
let extracted;
try {
extracted = JSON.parse(rawJson);
} catch (e) {
console.warn("Could not parse extracted JSON:", rawJson);
return;
}
if (Array.isArray(extracted) && extracted.length > 0) {
// Compute embeddings and save each to the DB
for (const memory of extracted) {
const embedRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: memory.content,
config: { outputDimensionality: 768 },
});
const vectorData = `[${embedRes.embeddings[0].values.join(',')}]`;
await pool.query(
`INSERT INTO memories (user_id, content, memory_type, category, embedding, source_message_id)
VALUES ($1, $2, $3, $4, $5, $6)`,
[userId, memory.content, memory.type.toUpperCase(), memory.category, vectorData, messageId]
);
console.log(`Saved new memory: ${memory.content}`);
}
}
}
วิธีการทำงาน
- Gen AI (เอาต์พุตที่มีโครงสร้าง): แอปพลิเคชันใช้โมเดล
gemini-2.5-flashที่รวดเร็วเป็นพิเศษเพื่อวิเคราะห์ข้อความของผู้ใช้ และดึงข้อเท็จจริงและความชอบที่มีโครงสร้างออกมาเป็นอาร์เรย์ JSON - Cloud SQL (พื้นที่เก็บข้อมูลแบบไฮบริด): หลังจากสร้างการฝังสำหรับข้อเท็จจริงใหม่เหล่านี้แล้ว ระบบจะจัดเก็บไว้ใน Cloud SQL โปรดทราบว่าระบบจะจัดเก็บข้อมูลเชิงสัมพันธ์มาตรฐาน (รหัสผู้ใช้ เนื้อหาข้อความ หมวดหมู่) ไว้ข้างๆ ข้อมูลเวกเตอร์ที่มีมิติสูงในแถวเดียว
- ผลลัพธ์: แอปสร้างโปรไฟล์หน่วยความจำที่อัปเดตตัวเองได้แบบเรียลไทม์ โดยใช้ทั้งความสามารถในการวิเคราะห์ของ Gemini และความสามารถในการจัดเก็บข้อมูลของ Cloud SQL
7. เรียกใช้แอปพลิเคชันแชท
- เริ่มต้นฐานข้อมูลด้วยผู้ใช้ตัวอย่าง 2-3 ราย
npm run seed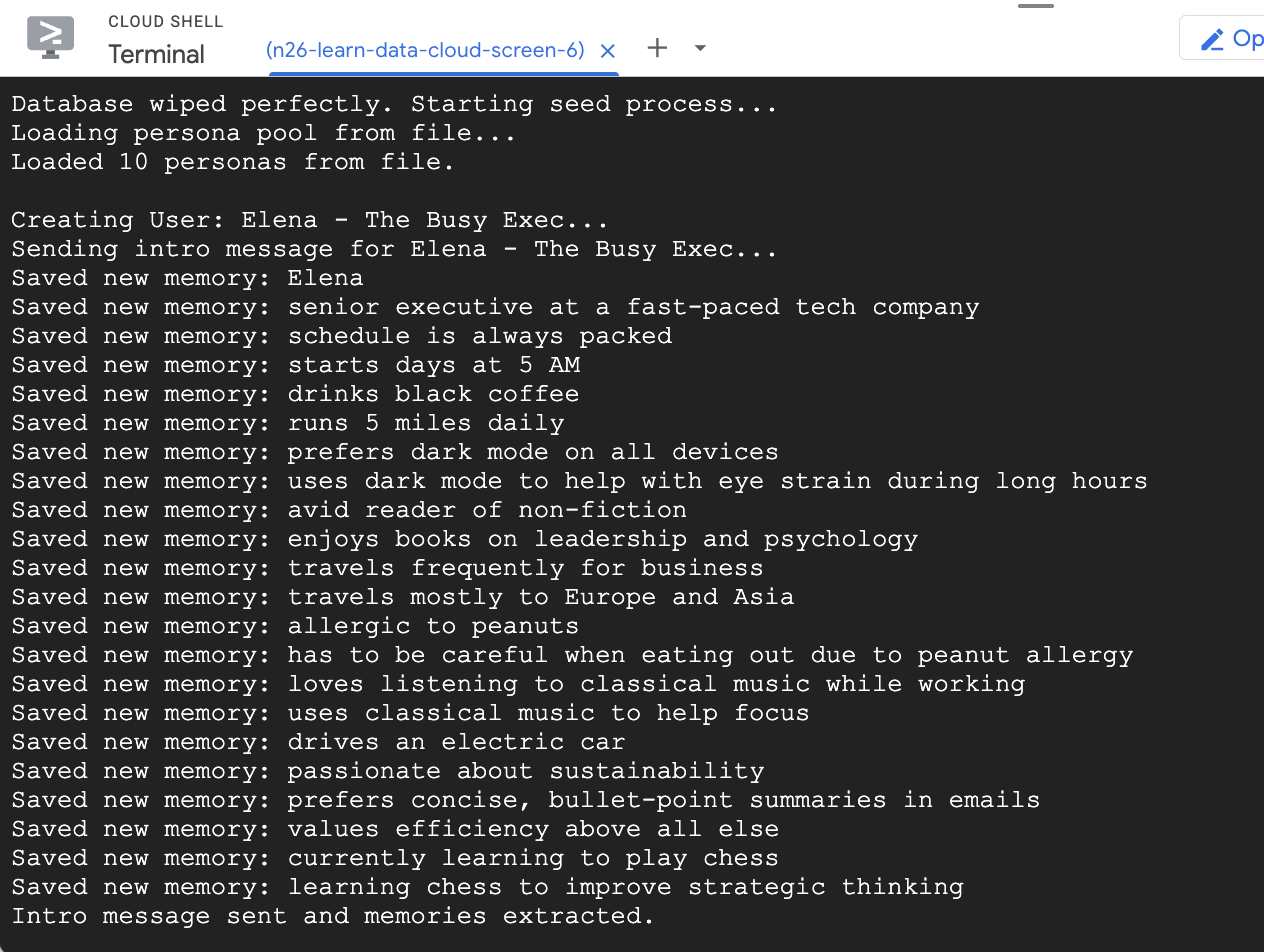
- จากนั้นเรียกใช้เซิร์ฟเวอร์
node server.js - ใน Cloud Shell ให้คลิกการแสดงตัวอย่างเว็บที่ด้านขวาบนของแถบเครื่องมือเทอร์มินัล แล้วเลือกเปลี่ยนพอร์ต ป้อน
3000สำหรับหมายเลขพอร์ต แล้วคลิกเปลี่ยนและแสดงตัวอย่าง
โต้ตอบกับผู้ช่วย
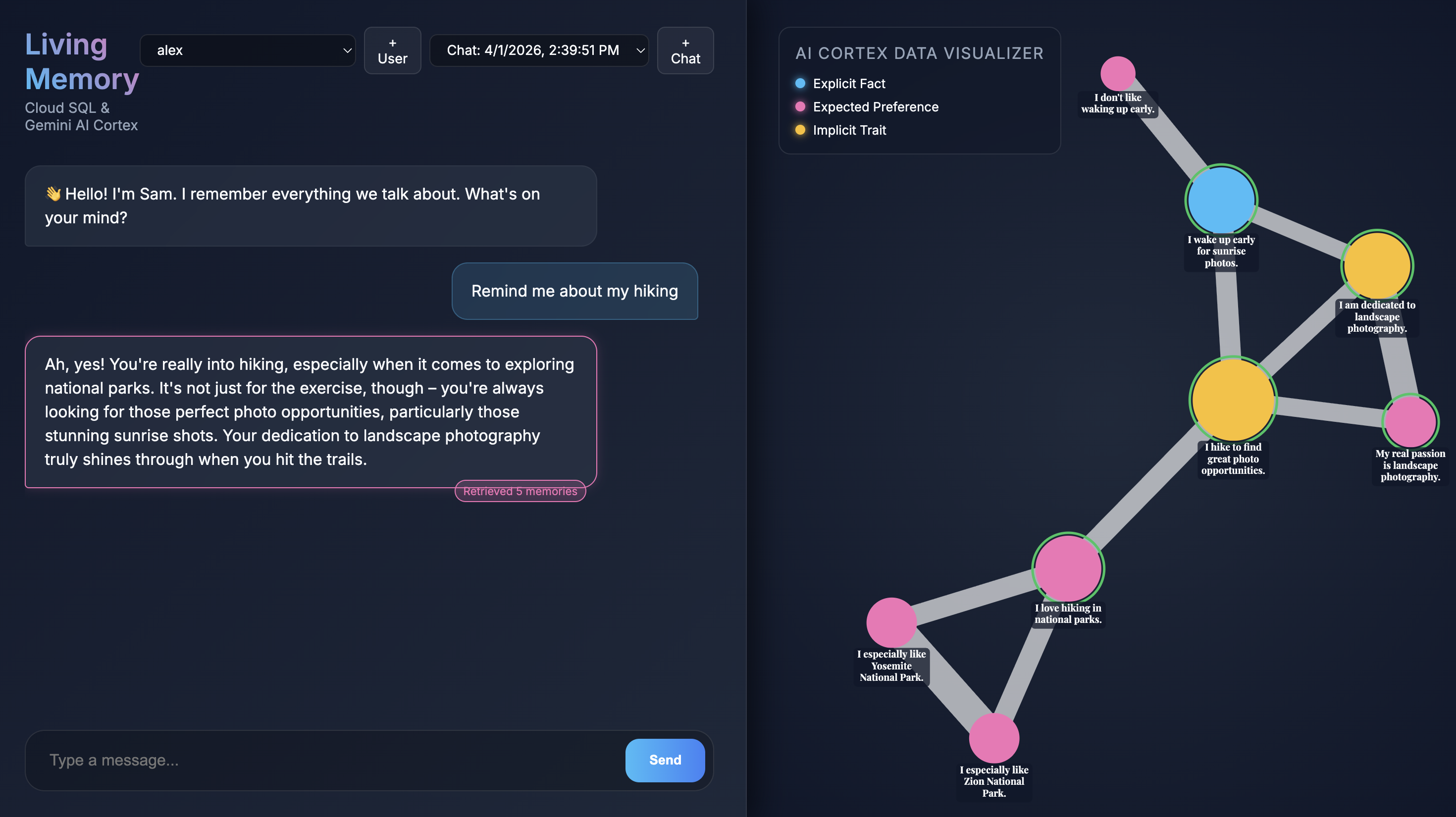
เมื่อแอปพลิเคชันเปิดขึ้นในเบราว์เซอร์ คุณจะเห็นอินเทอร์เฟซแชทของ Living Memory ทางด้านขวา AI Cortex Data Visualizer จะแสดงความทรงจำเป็นโหนดในพื้นที่เวกเตอร์ โดยมีรหัสสีตามประเภท (ข้อเท็จจริง ความชอบ ลักษณะโดยนัย) ข้อความในโหนดหน่วยความจำอาจมีขนาดเล็ก ทั้งนี้ขึ้นอยู่กับความละเอียดของหน้าจอ ให้ใช้เมาส์หรือแทร็กแพดเพื่อซูมและเลื่อนดูรายละเอียด
ค้นหาความทรงจำที่มีอยู่
seed สคริปต์ที่คุณเรียกใช้ก่อนหน้านี้ได้สร้างผู้ใช้ตัวอย่าง 2 รายที่มีความทรงจำบางส่วนที่ป้อนไว้ล่วงหน้า
- เลือกผู้ใช้จากเมนูแบบเลื่อนลงของผู้ใช้ที่ด้านซ้ายบน
- ใช้ปุ่มแชทด่วนปุ่มใดปุ่มหนึ่งหรือพิมพ์
Give me restaurant recommendations in New York Cityในช่องแชท แล้วกดส่ง - เมื่อผู้ช่วยตอบ คุณสามารถคลิกข้อความของผู้ช่วยเพื่อดูว่าผู้ช่วยใช้ความทรงจำใด โดยจะมีการไฮไลต์เป็นสีเขียว และคุณสามารถซูมดูและดูว่าคำเหล่านี้ช่วยสร้างคำตอบได้อย่างไร
สร้างผู้ใช้ใหม่
ตอนนี้มาสร้างผู้ใช้ใหม่กัน
- คลิกปุ่ม + ข้างเมนูแบบเลื่อนลงของผู้ใช้เพื่อเริ่มเซสชันการแชทใหม่
- ใช้ชื่อและคำอธิบายที่ระบบสร้างขึ้น หรือแก้ไขเพื่ออธิบายตัวคุณเอง
- คลิกสร้าง แล้วดูแอปพลิเคชันเริ่มแยกความทรงจำ ในอีกประมาณ 30 วินาที คุณควรเห็นโหนดใหม่ปรากฏในภาพที่แสดงทางด้านขวา ซึ่งแสดงถึงข้อเท็จจริงและความชอบที่ Gemini ดึงมาจากข้อความของคุณและจัดเก็บไว้ในฐานข้อมูล Cloud SQL
- ถามคำถามต่อเนื่อง เช่น
What food do I like?เพื่อดูว่าผู้ช่วยใช้ความทรงจำที่เพิ่งได้รับมาในการสนทนาอย่างไร
8. ล้างข้อมูล
คุณควรลบทรัพยากรที่สร้างขึ้นเพื่อหลีกเลี่ยงการเรียกเก็บเงินอย่างต่อเนื่องกับบัญชี Google Cloud สำหรับทรัพยากรที่ใช้ใน Codelab นี้
- ลบอินสแตนซ์ Cloud SQL โดยทำดังนี้
gcloud sql instances delete $INSTANCE_NAME --quiet - นำที่เก็บการสาธิตออก
rm -rf ~/devrel-demos
9. ขอแสดงความยินดี
คุณสร้างและติดตั้งใช้งานผู้ช่วย AI "ความทรงจำที่ยังมีชีวิต" เรียบร้อยแล้ว
สิ่งที่คุณได้เรียนรู้
- วิธีใช้ Cloud SQL pgvector สำหรับการค้นหาเชิงความหมาย
- วิธีใช้ Gemini เพื่อดึงข้อมูลความทรงจำแบบไดนามิก
ขั้นตอนถัดไป
- ดูเอกสารประกอบ pgvector ของ Cloud SQL
- ดูข้อมูลเพิ่มเติมเกี่ยวกับความสามารถของ Gemini API
- ดูข้อมูลเจาะลึกเกี่ยวกับพร็อกซีการตรวจสอบสิทธิ์ Cloud SQL
- ลองปรับแต่ง
extractionPromptในserver.jsเพื่อดึงข้อมูลประเภทต่างๆ
สนุกกับการสร้างด้วยความทรงจำที่มีชีวิต!