
1. Giriş
Bu codelab'de, kişiselleştirilmiş bir deneyim sunmak için sohbetinizin "anılarını" takip eden yapay zeka destekli bir asistan olan Living Memory Demo'yu nasıl oluşturacağınızı öğreneceksiniz.
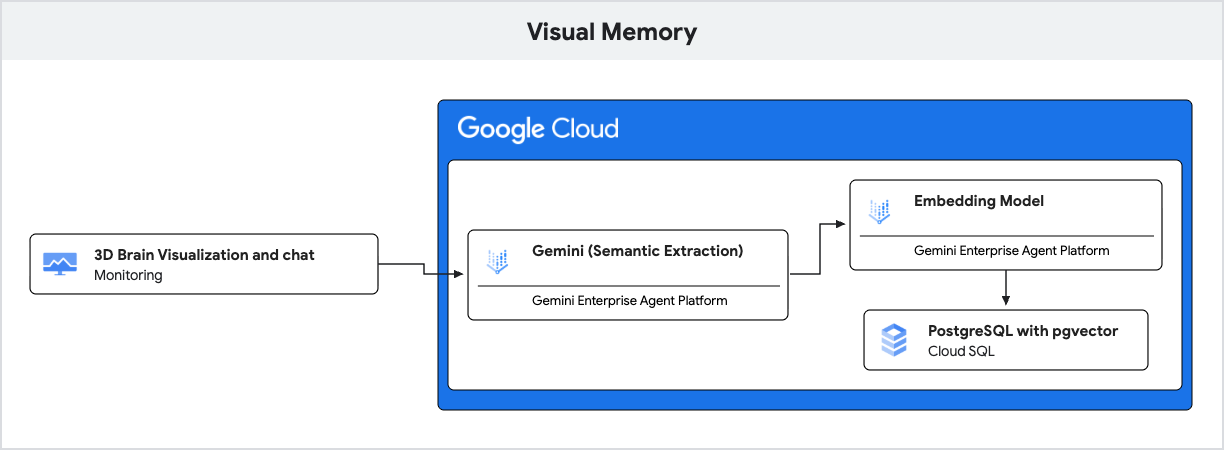
Uygulama, doğal dil anlayışı için Gemini'ı, bu anıları semantik benzerliğe göre depolamak ve almak için ise pgvector uzantısı ile PostgreSQL için Cloud SQL'i kullanır.
Bu codelab, yapay zeka ve veritabanlarıyla ilgilenen her beceri düzeyinden geliştirici için tasarlanmıştır ve yaklaşık 60 dakika içinde tamamlanabilir. Oluşturulan kaynakların maliyeti 5 ABD dolarından az olmalıdır.
Yapacaklarınız
pgvectordesteğiyle PostgreSQL için Cloud SQL örneği oluşturma- Kullanıcı mesajlarından etkileşimli olarak "anı" çıkarmak için Gemini'ı kullanma
- Yapay zeka yanıtları için alakalı bağlamı almak üzere PostgreSQL'de vektör aramaları yapma
İhtiyacınız olanlar
- Faturalandırmanın etkin olduğu bir Google Cloud projesi.
- Komut satırı ve Node.js hakkında temel bilgiler
2. Başlamadan önce
Proje ayarlama
Google Cloud projesi oluşturma
- Google Cloud Console'daki proje seçici sayfasında bir Google Cloud projesi seçin veya oluşturun.
- Cloud projeniz için faturalandırmanın etkinleştirildiğinden emin olun. Bir projede faturalandırmanın etkin olup olmadığını kontrol etmeyi öğrenin.
Cloud Shell'i Başlatma
Cloud Shell, Google Cloud'da çalışan ve gerekli araçların önceden yüklendiği bir komut satırı ortamıdır.
- Google Cloud Console'un üst kısmından Cloud Shell'i etkinleştir'i tıklayın.
- Cloud Shell'e bağlandıktan sonra kimlik doğrulamanızı onaylayın:
gcloud auth list - Projenizin yapılandırıldığını onaylayın:
gcloud config get project - Projeniz beklendiği gibi ayarlanmamışsa şu şekilde ayarlayın:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
API'leri etkinleştir
Gerekli API'leri etkinleştirmek için Cloud Shell'de aşağıdaki komutu çalıştırın:
gcloud services enable sqladmin.googleapis.com \
aiplatform.googleapis.com
3. Demo deposunu klonlama
Şimdi Living Memory Demo'nun kodunu alın.
- Depoyu Cloud Shell ortamınıza klonlayın:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git cd devrel-demos/codelabs/visual-memory-postgres-demo - Bağımlılıkları yükleyin:
npm install
4. Cloud SQL veritabanını oluşturma ve yapılandırma
Bu bölümde bir Cloud SQL örneği oluşturacak, veritabanını başlatacak ve şemayı ayarlayacaksınız.
- Uygulama, yapılandırma için ortam değişkenlerini kullanır. Bu oturum için gerekli değişkenleri ayarlamak üzere Cloud Shell terminalinizde aşağıdaki bloğu çalıştırın:
export REGION="us-central1" export INSTANCE_NAME="living-memory-db" export DB_HOST=127.0.0.1 export DB_PORT=5432 export DB_USER=memory_app export DB_PASS=memory_app_password export DB_NAME=living_memory export PGPASSWORD=$DB_PASS - Örneği oluşturun. Bu adım genellikle 5-10 dakika sürer.
gcloud sql instances create $INSTANCE_NAME \ --database-version=POSTGRES_16 \ --cpu=1 \ --memory=3840MB \ --region=$REGION \ --root-password=$DB_PASS \ --edition=ENTERPRISEvectoruzantısını etkinleştirir ve uygulamayı desteklemek için çeşitli tablolar oluşturur:
users,conversations,messages: Kullanıcı profillerini ve görüşme geçmişini depolamak için kullanılan standart tablolar.memories: Bu, Almayla Artırılmış Üretim (RAG) için temel tablodur. Her satır, görüşmeden çıkarılan bir bilgiyi (ör. "Kullanıcı yürüyüşü seviyor") temsil eder. Şunları saklar:content: Anının metni.memory_type: Anının türü (FACT,PREFveyaIMPLICIT).embedding: İçeriğin anlamsal gösterimini içeren, Gemini tarafından oluşturulan 768 boyutluvectorsütunu.
pgvectorDizin:HNSW(Hiyerarşik Gezinilebilir Küçük Dünya) dizini,embeddingsütununda oluşturulur. Bu, k-En Yakın Komşu (k-NN) aramalarını optimize etmek için çok önemlidir. Bu sayedepgvector, kosinüs uzaklığı operatörünü (<=>) kullanarak anlamsal olarak en benzer anıları hızlı bir şekilde bulabilir.
- Veritabanını oluşturma
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME - Uygulama kullanıcısını oluşturma
gcloud sql users create $DB_USER --instance=$INSTANCE_NAME --password=$DB_PASS - Cloud SQL Auth Proxy'yi başlatın. Proxy, IP izin listesi yapılandırmanıza gerek kalmadan örneğinize güvenli erişim sağlar.
(cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:us-central1:living-memory-db &) && sleep 2 && echo ""The proxy has started successfully and is ready for new connections!. schema.sqluzantısını etkinleştirmek ve gerekli tabloları oluşturmak içinschema.sqluygulayın.vectorProxy çalıştığı için artık127.0.0.1adresinden örneğinize bağlanabilirsiniz.psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME < schema.sql- Şema oluşturma işleminin başarılı olduğunu doğrulayın.
psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME -c "\dt"conversations,memories,messagesveuserstablolarının listelendiği bir çıktı görmelisiniz.List of relations Schema | Name | Type | Owner --------+---------------+-------+------------ public | conversations | table | memory_app public | memories | table | memory_app public | messages | table | memory_app public | queries_log | table | memory_app public | users | table | memory_app (5 rows)
5. pgvector ile semantik almayı anlama
Bu bölümde, uygulamanın yanıt oluşturmadan önce yapay zeka için alakalı bağlamı nasıl aldığını inceleyeceksiniz. server.js dokümanındaki aşağıdaki snippet'te, /api/chat uç noktasında bu durumdan sorumlu kod gösterilmektedir:
// Retrieve Similar Memories for Context (Using pgvector)
const promptEmbeddingRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: message,
config: { outputDimensionality: 768 },
});
const promptEmbedding = promptEmbeddingRes.embeddings[0].values;
const embeddingStr = `[${promptEmbedding.join(',')}]`;
// Query DB for top 5 closest memories
const relevantMemories = await pool.query(
`SELECT id, content, memory_type, category
FROM memories
WHERE user_id = $1
ORDER BY embedding <=> $2::vector
LIMIT 5`,
[userId, embeddingStr]
);
İşleyiş şekli
- Üretken yapay zeka (yerleştirme): Uygulama, kullanıcının gelen mesajını alır ve metni 768 boyutlu bir vektöre dönüştürmek için
gemini-embedding-001modelini kullanır. Bu vektör, mesajın anlamsal anlamını temsil eder. - Cloud SQL (pgvector): Uygulama, bu vektörü Cloud SQL'e iletir. Cloud SQL,
<=>uzantısı tarafından sağlanan<=>(kosinüs uzaklığı) operatörünü kullanarak istemle anlamsal olarak en çok benzerlik gösteren 5 anıyı bulur.pgvector - Sonuç: Bu, almayla artırılmış üretimdir (RAG). Yapay zeka, yanıtını kişiselleştirmek için veritabanındaki belirli ve alakalı anılara erişir. Bunun için tüm geçmişi yüklemesi gerekmez.
6. Bellek çıkarma özelliğini anlama
Ardından, uygulamanın görüşmeden nasıl öğrendiğine bakın. Aşağıdaki snippet, server.js uygulamasındaki extractMemoriesAsync işlevinden alınmıştır:
// MEMORY EXTRACTION LOGIC
async function extractMemoriesAsync(userMessage, userId, messageId) {
const extractionPrompt = `
Analyze the following user message. A memory profile is being built for this user.
Extract ANY explicit facts (Facts), preferences (Pref), or implicit behavioral traits/styles (Implicit).
Return the result as a raw JSON array of objects (NO Markdown blocks, just the JSON array).
Format: [{"content": "string fact/sentence", "type": "FACT|PREF|IMPLICIT", "category": "General|Travel|Hobby|Persona"}]
If nothing is found, return [].
Message: "${userMessage}"
`;
const result = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: extractionPrompt
});
let rawJson = result.text.replace(/^```json/g, '').replace(/```$/g, '').trim();
let extracted;
try {
extracted = JSON.parse(rawJson);
} catch (e) {
console.warn("Could not parse extracted JSON:", rawJson);
return;
}
if (Array.isArray(extracted) && extracted.length > 0) {
// Compute embeddings and save each to the DB
for (const memory of extracted) {
const embedRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: memory.content,
config: { outputDimensionality: 768 },
});
const vectorData = `[${embedRes.embeddings[0].values.join(',')}]`;
await pool.query(
`INSERT INTO memories (user_id, content, memory_type, category, embedding, source_message_id)
VALUES ($1, $2, $3, $4, $5, $6)`,
[userId, memory.content, memory.type.toUpperCase(), memory.category, vectorData, messageId]
);
console.log(`Saved new memory: ${memory.content}`);
}
}
}
İşleyiş şekli
- Üretken Yapay Zeka (Yapılandırılmış Çıkış): Uygulama, kullanıcının mesajını analiz etmek ve yapılandırılmış bilgileri ve tercihleri JSON dizisi olarak ayıklamak için ultra hızlı
gemini-2.5-flashmodelini kullanır. - Cloud SQL (Hibrit Depolama): Bu yeni olgular için yerleştirmeler oluşturulduktan sonra Cloud SQL'de depolanır. Standart ilişkisel verilerin (kullanıcı kimliği, metin içeriği, kategoriler) tek bir satırda yüksek boyutlu vektör verileriyle birlikte depolandığını unutmayın.
- Sonuç: Uygulama, hem Gemini'ın analitik gücünden hem de Cloud SQL'in depolama özelliklerinden yararlanarak gerçek zamanlı olarak kendi kendini güncelleyen bir bellek profili oluşturur.
7. Sohbet uygulamasını çalıştırın
- Veritabanını birkaç örnek kullanıcıyla doldurun
npm run seed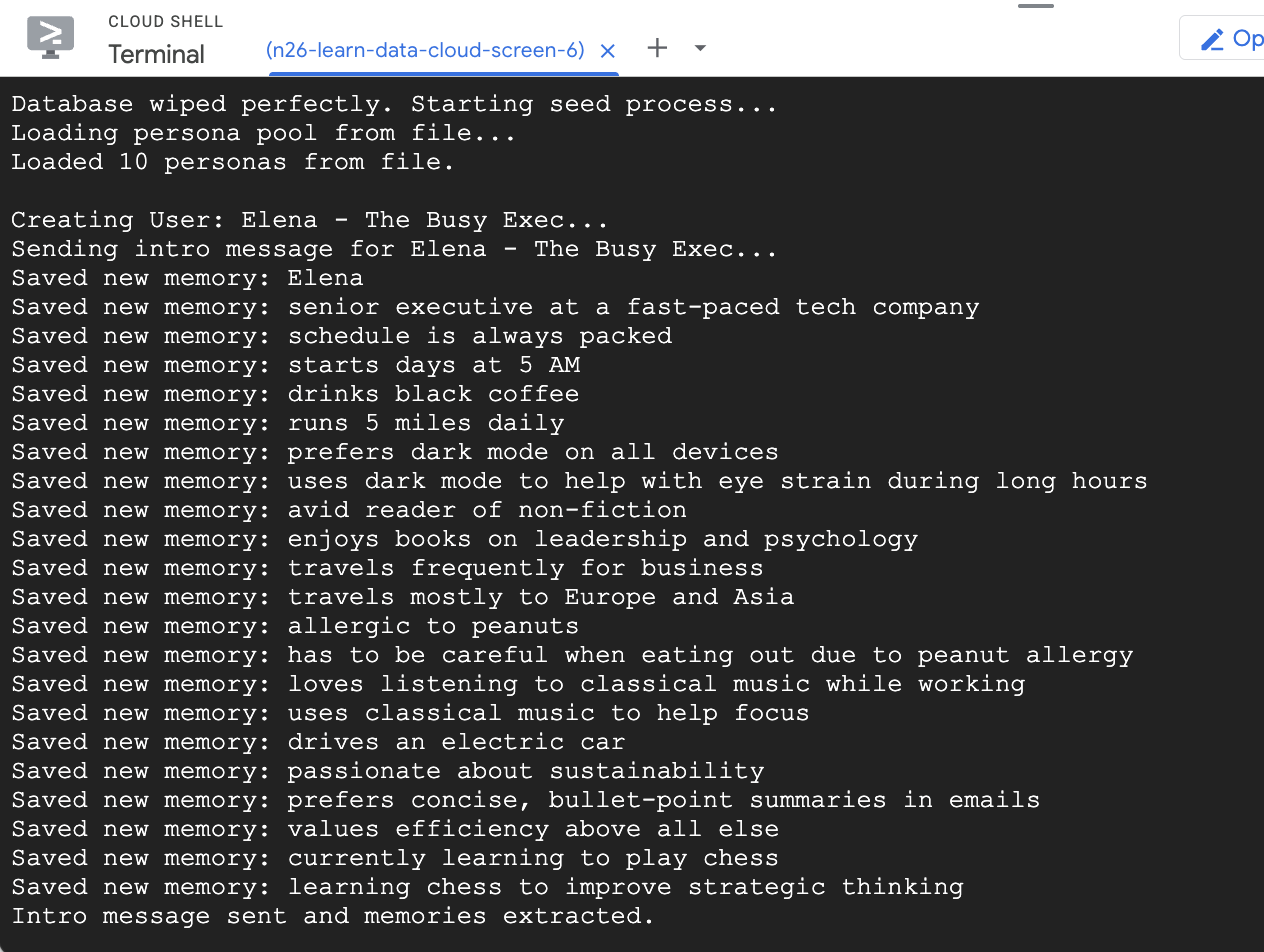
- Ardından sunucuyu çalıştırın.
node server.js - Cloud Shell'de terminal araç çubuğunun sağ üst kısmındaki Web Önizlemesi'ni tıklayın ve Bağlantı Noktasını Değiştir'i seçin. Bağlantı noktası numarası için
3000girin ve Change and Preview'u (Değiştir ve Önizle) tıklayın.
Asistanla etkileşim kurma
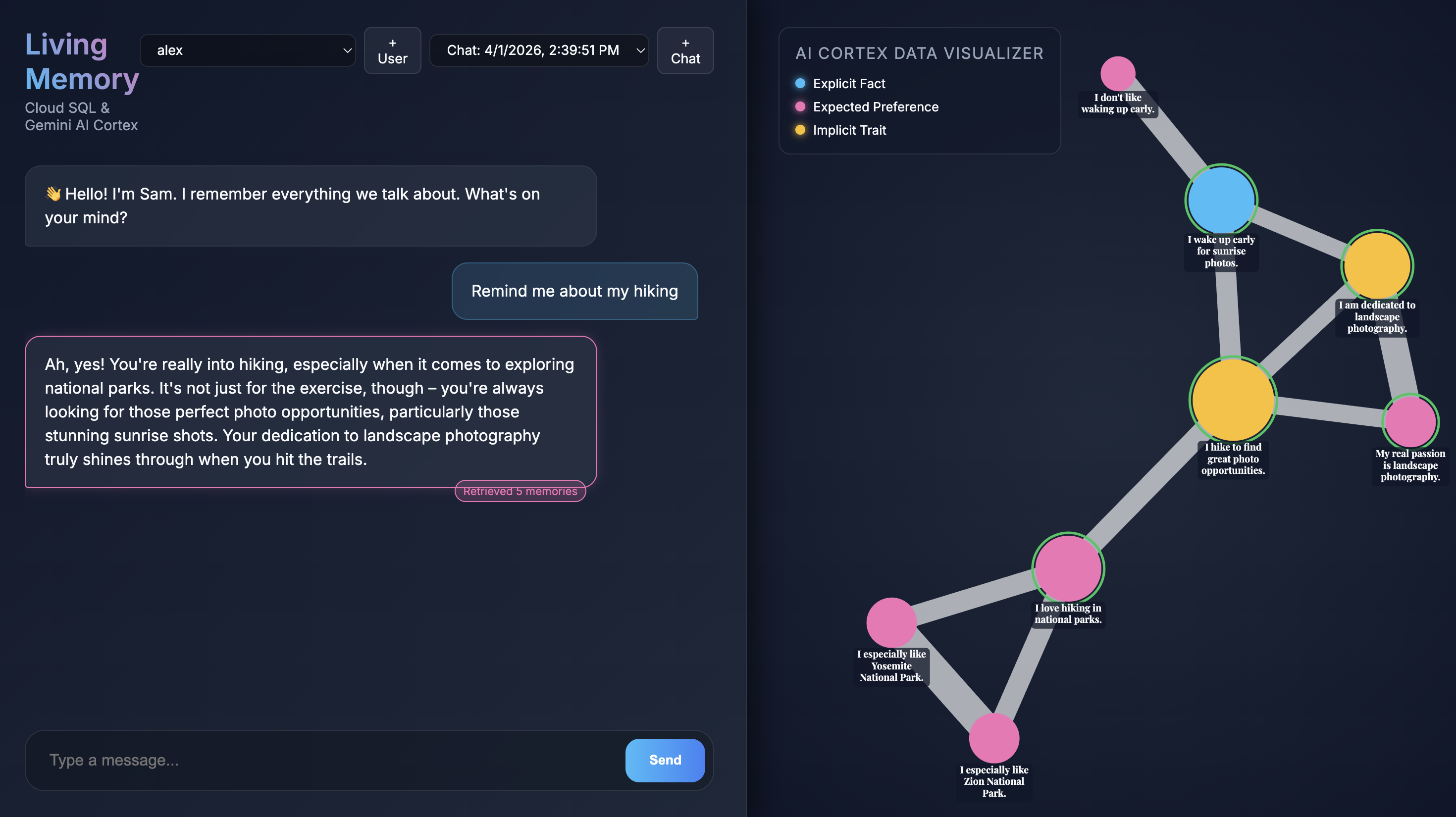
Uygulama tarayıcınızda açıldığında Living Memory sohbet arayüzünü görürsünüz. Sağ taraftaki AI Cortex Data Visualizer, anıları vektör alanında düğümler olarak gösterir. Bu düğümler, türe göre (Gerçek, Tercih, Örtülü Özellik) renk kodlarıyla ayrılır. Bellek düğümlerindeki metinler, ekran çözünürlüğünüze bağlı olarak küçük olabilir. Daha yakından bakmak için fare veya dokunmatik yüzeyinizi kullanarak yakınlaştırın ve kaydırın.
Mevcut anıları sorgulama
Daha önce çalıştırdığınız seed komut dosyası, önceden doldurulmuş bazı anılar içeren iki örnek kullanıcı oluşturdu.
- Sol üstteki kullanıcı açılır menüsünden bir kullanıcı seçin.
- Hazır sohbet düğmelerinden birini kullanın veya sohbet girişine
Give me restaurant recommendations in New York Cityyazıp Gönder'e basın. - Asistan yanıt verdiğinde, hangi anıları kullandığını görmek için asistanın mesajını tıklayabilirsiniz. Bu kısımlar yeşille vurgulanır. Bu kısımlara yakınlaştırarak yanıtın oluşturulmasına nasıl yardımcı olduklarını görebilirsiniz.
Yeni kullanıcı oluşturma
Şimdi yeni bir kullanıcı oluşturalım.
- Yeni bir sohbet oturumu başlatmak için kullanıcı açılır listesinin yanındaki + düğmesini tıklayın.
- Oluşturulan adı ve açıklamayı kullanın veya kendinizi açıklamak için bunları düzenleyin.
- Oluştur'u tıklayın. Uygulama, anıları ayıklamaya başlar. Yaklaşık 30 saniye içinde, sağdaki görselleştiricide yeni düğümlerin göründüğünü görmeniz gerekir. Bunlar, Gemini'ın mesajınızdan çıkardığı ve Cloud SQL veritabanında sakladığı gerçekleri ve tercihleri temsil eder.
- Asistanın yeni edindiği anıları sohbette kullanmasını görmek için
What food do I like?gibi bir takip sorusu sorun.
8. Temizleme
Bu codelab'de kullanılan kaynaklar için Google Cloud hesabınızın sürekli olarak ücretlendirilmesini önlemek istiyorsanız oluşturduğunuz kaynakları silmeniz gerekir.
- Cloud SQL örneğini silin:
gcloud sql instances delete $INSTANCE_NAME --quiet - Demo deposunu kaldırma:
rm -rf ~/devrel-demos
9. Tebrikler
"Living Memory" adlı yapay zeka asistanını başarıyla oluşturup dağıttınız.
Öğrendikleriniz
- Anlamsal arama için Cloud SQL pgvector'ı kullanma
- Dinamik bellek çıkarma için Gemini'ı kullanma
Sonraki adımlar
- Cloud SQL pgvector belgelerini inceleyin.
- Gemini API özellikleri hakkında daha fazla bilgi edinin.
- Cloud SQL Auth Proxy hakkında ayrıntılı bilgi edinin.
- Farklı veri türlerini ayıklamak için
server.jsiçindekiextractionPromptsimgesini özelleştirmeyi deneyin.
Living Memory ile anılarınızı bir araya getirmenin keyfini çıkarın.