
1. 简介
在此 Codelab 中,您将学习如何构建 Living Memory Demo,这是一款由 AI 赋能的助理,可跟踪对话“记忆”,从而提供个性化体验。
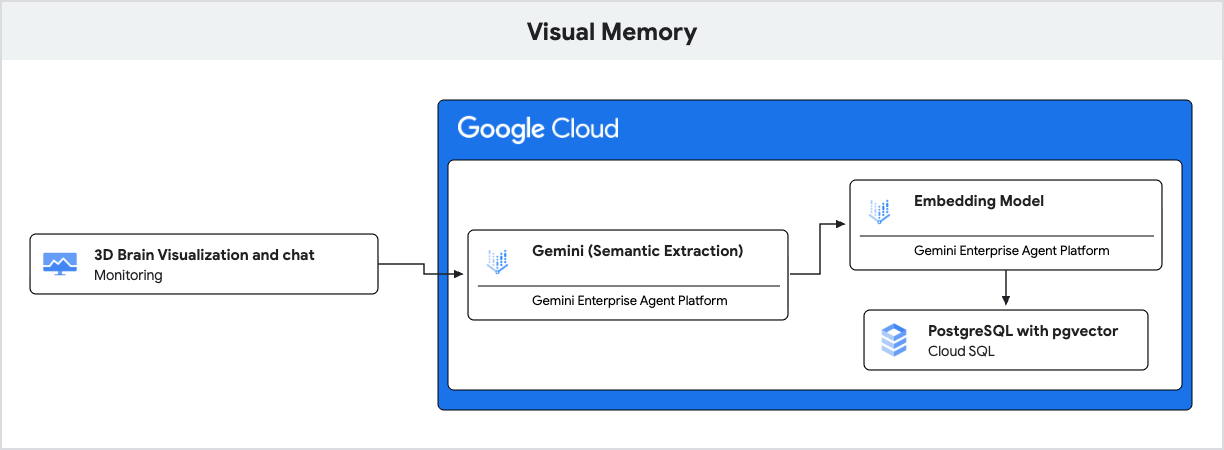
该应用使用 Gemini 进行自然语言理解,并使用 Cloud SQL for PostgreSQL 和 pgvector 扩展程序 来存储和检索这些记忆,具体依据是语义相似度。
此 Codelab 适用于对 AI 和数据库感兴趣的各种技能水平的开发者,完成时间约为 60 分钟。创建的资源费用应低于 5 美元。
您将执行的操作
- 如何设置支持
pgvector的 Cloud SQL for PostgreSQL 实例。 - 如何使用 Gemini 以交互方式从用户消息中提取“记忆”。
- 如何在 PostgreSQL 中执行向量搜索,以检索 AI 响应的相关上下文。
所需条件
- 启用了结算功能的 Google Cloud 项目。
- 具备命令行和 Node.js 的基础知识。
2. 准备工作
项目设置
创建 Google Cloud 项目
- 在 Google Cloud 控制台 的项目选择器页面上,选择或创建一个 Google Cloud 项目。
- 确保您的云项目已启用结算功能。了解如何检查项目是否已启用结算功能。
启动 Cloud Shell
Cloud Shell 是在 Google Cloud 中运行的一个命令行环境,其中预加载了必要的工具。
- 点击 Google Cloud 控制台顶部的激活 Cloud Shell 。
- 连接到 Cloud Shell 后,验证您的身份验证:
gcloud auth list - 确认您的项目已配置:
gcloud config get project - 如果您的项目未按预期设置,请进行设置:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
启用 API
在 Cloud Shell 中运行以下命令,以启用所需的 API:
gcloud services enable sqladmin.googleapis.com \
aiplatform.googleapis.com
3. 克隆演示代码库
现在,获取 Living Memory Demo 的代码。
- 将代码库克隆到 Cloud Shell 环境:
git clone https://github.com/GoogleCloudPlatform/devrel-demos.git cd devrel-demos/codelabs/visual-memory-postgres-demo - 安装依赖项:
npm install
4. 创建并配置 Cloud SQL 数据库
在本部分中,您将创建一个 Cloud SQL 实例、初始化数据库并设置架构。
- 该应用使用环境变量进行配置。在 Cloud Shell 终端中运行以下代码块,为此会话设置所需变量:
export REGION="us-central1" export INSTANCE_NAME="living-memory-db" export DB_HOST=127.0.0.1 export DB_PORT=5432 export DB_USER=memory_app export DB_PASS=memory_app_password export DB_NAME=living_memory export PGPASSWORD=$DB_PASS - 创建实例。此步骤通常需要 5-10 分钟。
gcloud sql instances create $INSTANCE_NAME \ --database-version=POSTGRES_16 \ --cpu=1 \ --memory=3840MB \ --region=$REGION \ --root-password=$DB_PASS \ --edition=ENTERPRISEvector扩展程序并创建多个表来支持该应用:
users、conversations、messages:用于存储用户个人资料和对话记录的标准表。memories:这是检索增强生成 (RAG) 的核心表。每行代表从对话中提取的一条信息(例如,“用户喜欢徒步旅行”)。它存储:content:记忆的文本。memory_type:记忆的类型(FACT、PREF或IMPLICIT)。embedding:一个 768 维的vector列,其中包含由 Gemini 生成的内容的语义表示。
pgvector索引:在embedding列上创建了一个HNSW(分层可导航小世界)索引。这对于优化 k 最近邻 (k-NN) 搜索至关重要,可让pgvector使用余弦距离运算符 (<=>) 快速找到语义最相似的记忆。
- 创建数据库
gcloud sql databases create $DB_NAME --instance=$INSTANCE_NAME - 创建应用用户
gcloud sql users create $DB_USER --instance=$INSTANCE_NAME --password=$DB_PASS - 启动 Cloud SQL Auth 代理。借助该代理,您无需配置 IP 许可名单即可安全地访问实例。
(cloud-sql-proxy ${GOOGLE_CLOUD_PROJECT}:us-central1:living-memory-db &) && sleep 2 && echo ""The proxy has started successfully and is ready for new connections!。 - 应用
schema.sql以启用vector扩展程序并创建必要的表。由于代理正在运行,您现在可以连接到127.0.0.1处的实例。psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME < schema.sql - 验证架构创建是否成功。
psql -h 127.0.0.1 -U $DB_USER -d $DB_NAME -c "\dt"conversations、memories、messages和users表的输出。List of relations Schema | Name | Type | Owner --------+---------------+-------+------------ public | conversations | table | memory_app public | memories | table | memory_app public | messages | table | memory_app public | queries_log | table | memory_app public | users | table | memory_app (5 rows)
5. 了解使用 pgvector 进行语义检索
在本部分中,您将了解应用如何在生成响应之前检索 AI 的相关上下文。以下 server.js 代码段显示了 /api/chat 端点中负责此操作的代码:
// Retrieve Similar Memories for Context (Using pgvector)
const promptEmbeddingRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: message,
config: { outputDimensionality: 768 },
});
const promptEmbedding = promptEmbeddingRes.embeddings[0].values;
const embeddingStr = `[${promptEmbedding.join(',')}]`;
// Query DB for top 5 closest memories
const relevantMemories = await pool.query(
`SELECT id, content, memory_type, category
FROM memories
WHERE user_id = $1
ORDER BY embedding <=> $2::vector
LIMIT 5`,
[userId, embeddingStr]
);
运作方式
- 生成式 AI(嵌入):应用会接收用户的收到的消息,并使用
gemini-embedding-001模型将文本转换为 768 维向量。此向量表示消息的语义含义。 - Cloud SQL (pgvector):应用会将该向量传递给 Cloud SQL。Cloud SQL 使用
pgvector扩展程序提供的<=>(余弦距离)运算符,找到与提示在语义上最相似的 5 个记忆。 - 结果:这就是检索增强生成 (RAG)。AI 可以访问数据库中的特定相关记忆,从而实现个性化响应,而无需加载整个历史记录。
6. 了解记忆提取
接下来,了解应用如何从对话中学习。以下代码段来自 server.js 中的 extractMemoriesAsync 函数:
// MEMORY EXTRACTION LOGIC
async function extractMemoriesAsync(userMessage, userId, messageId) {
const extractionPrompt = `
Analyze the following user message. A memory profile is being built for this user.
Extract ANY explicit facts (Facts), preferences (Pref), or implicit behavioral traits/styles (Implicit).
Return the result as a raw JSON array of objects (NO Markdown blocks, just the JSON array).
Format: [{"content": "string fact/sentence", "type": "FACT|PREF|IMPLICIT", "category": "General|Travel|Hobby|Persona"}]
If nothing is found, return [].
Message: "${userMessage}"
`;
const result = await ai.models.generateContent({
model: 'gemini-2.5-flash',
contents: extractionPrompt
});
let rawJson = result.text.replace(/^```json/g, '').replace(/```$/g, '').trim();
let extracted;
try {
extracted = JSON.parse(rawJson);
} catch (e) {
console.warn("Could not parse extracted JSON:", rawJson);
return;
}
if (Array.isArray(extracted) && extracted.length > 0) {
// Compute embeddings and save each to the DB
for (const memory of extracted) {
const embedRes = await ai.models.embedContent({
model: 'gemini-embedding-001',
contents: memory.content,
config: { outputDimensionality: 768 },
});
const vectorData = `[${embedRes.embeddings[0].values.join(',')}]`;
await pool.query(
`INSERT INTO memories (user_id, content, memory_type, category, embedding, source_message_id)
VALUES ($1, $2, $3, $4, $5, $6)`,
[userId, memory.content, memory.type.toUpperCase(), memory.category, vectorData, messageId]
);
console.log(`Saved new memory: ${memory.content}`);
}
}
}
运作方式
- 生成式 AI(结构化输出):应用使用超快速
gemini-2.5-flash模型分析用户消息,并将结构化事实和偏好提取为 JSON 数组。 - Cloud SQL(混合存储):为这些新事实生成嵌入后,它们会存储在 Cloud SQL 中。请注意,标准关系型数据(用户 ID、文本内容、类别)与高维向量数据存储在同一行中。
- 结果:该应用会实时构建自动更新的记忆个人资料,同时利用 Gemini 的分析能力和 Cloud SQL 的存储能力。
7. 运行聊天应用
- 使用一些示例用户为数据库植入种子数据
npm run seed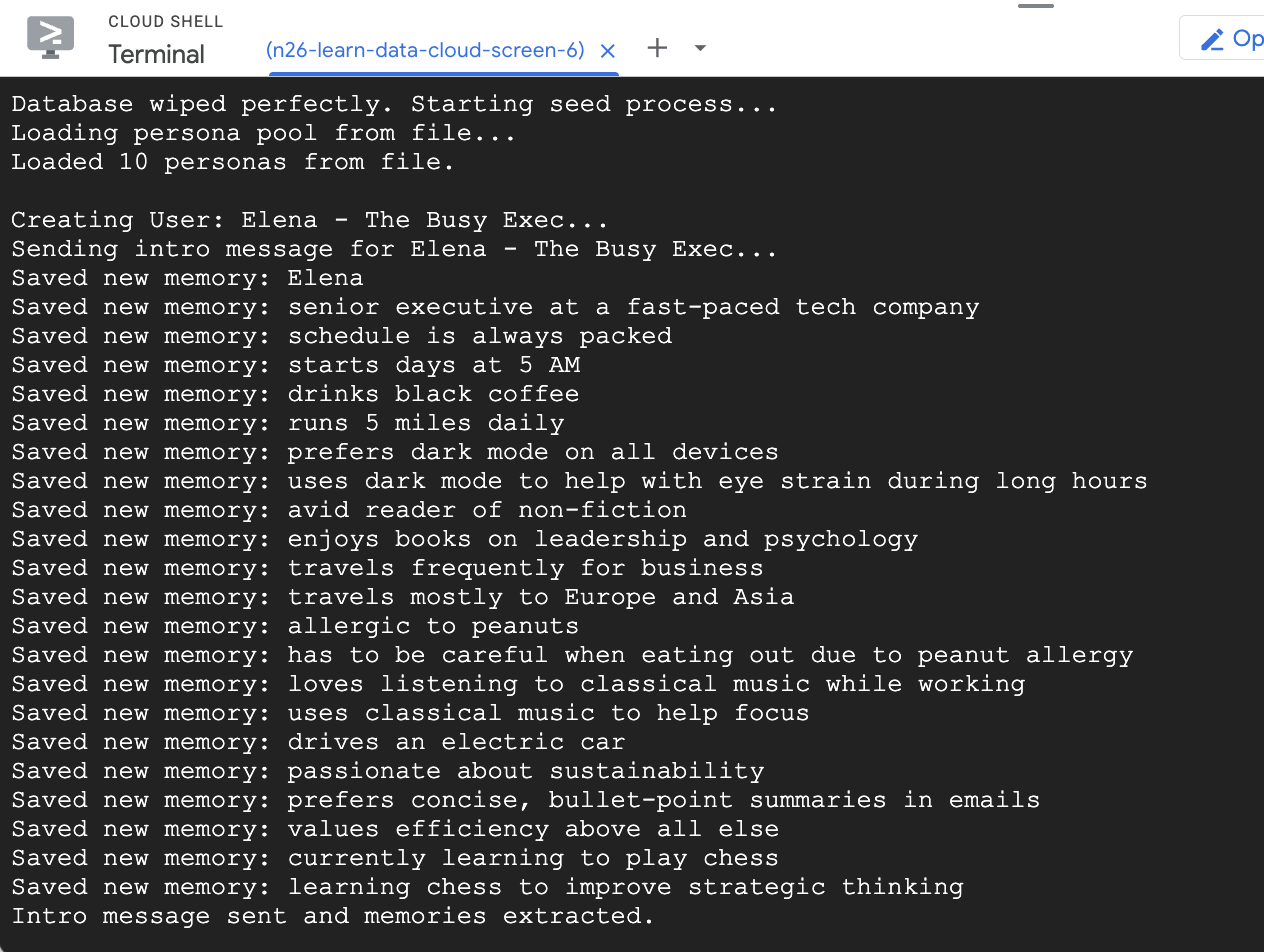
- 然后运行服务器
node server.js - 在 Cloud Shell 中,点击终端工具栏右上角的网页预览 ,然后选择更改端口 。输入端口号
3000,然后点击更改并预览 。
与助理互动
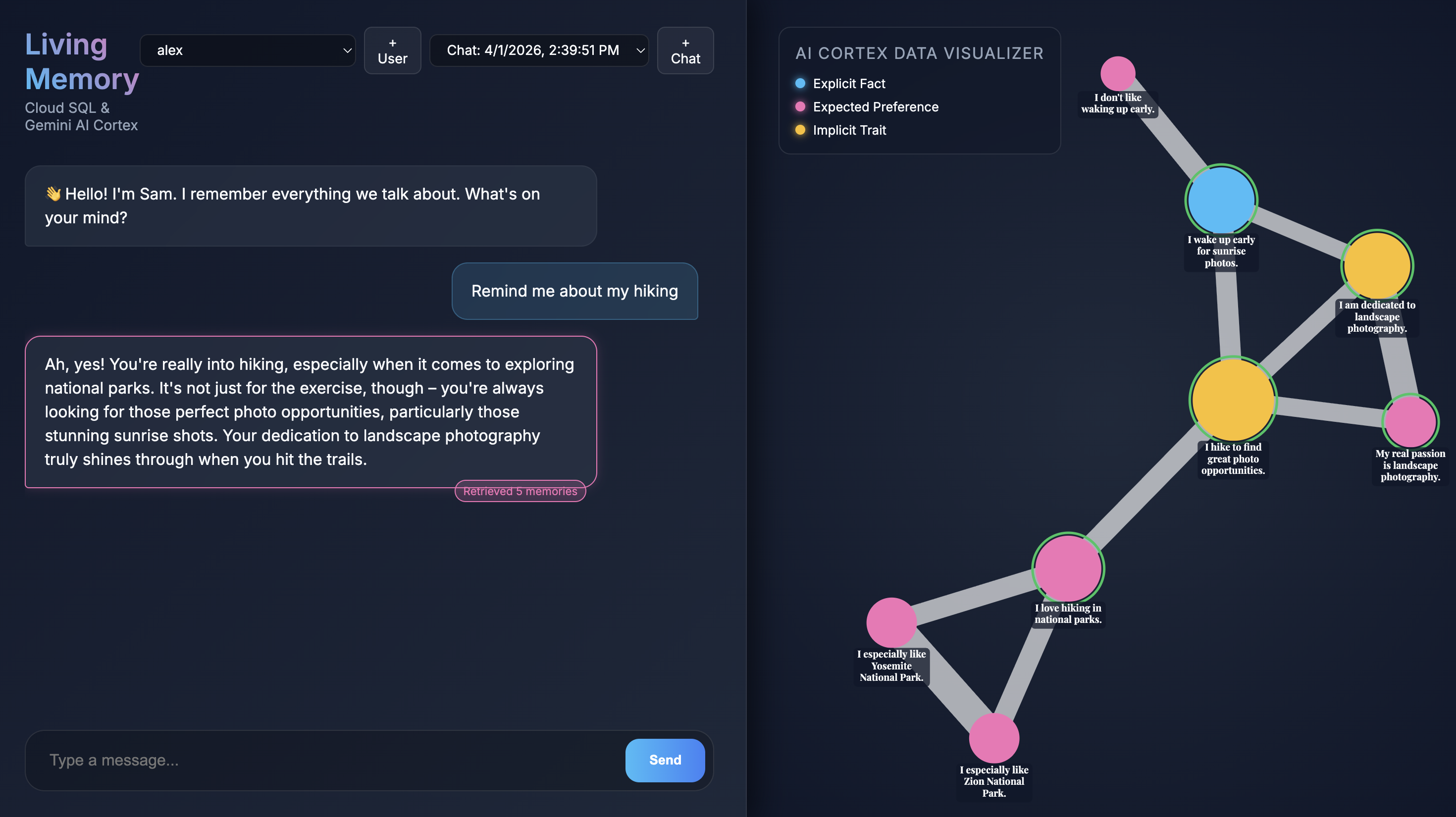
当应用在浏览器中打开时,您会看到 Living Memory 聊天界面。在右侧,AI Cortex Data Visualizer 会将记忆显示为向量空间中的节点,并按类型(事实、偏好、隐式特征)进行颜色编码。记忆节点上的文本可能会很小,具体取决于您的屏幕分辨率;您可以使用鼠标或触控板进行缩放和平移,以便仔细查看。
查询现有记忆
您之前运行的 seed 脚本创建了两个示例用户,并预先填充了一些记忆。
- 从左上角的用户下拉菜单中选择一个用户。
- 使用其中一个快速聊天按钮,或在聊天输入中输入
Give me restaurant recommendations in New York City,然后按发送 。 - 当助理做出响应时,您可以点击助理的消息,查看它使用了哪些记忆。这些记忆将以绿色突出显示,您可以缩放查看它们,了解它们如何帮助形成响应。
创建新用户
现在,我们来创建一个新用户。
- 点击用户下拉菜单旁边的 + 按钮,开始新的聊天会话。
- 使用生成的名称和说明,或对其进行修改以描述您自己。
- 点击创建 ,查看应用开始提取记忆。大约 30 秒后,您应该会在右侧的可视化工具中看到新节点。这些节点表示 Gemini 从您的消息中提取并存储在 Cloud SQL 数据库中的事实和偏好。
- 提出后续问题,例如
What food do I like?,查看助理如何在对话中使用新获得的记忆。
8. 清理
为避免系统因本 Codelab 中使用的资源而持续向您的 Google Cloud 账号收取费用,您应该删除您创建的资源。
- 删除 Cloud SQL 实例:
gcloud sql instances delete $INSTANCE_NAME --quiet - 移除演示代码库:
rm -rf ~/devrel-demos
9. 恭喜
您已成功构建并部署了“Living Memory”AI 助理!
您学到的内容
- 如何使用 Cloud SQL pgvector 进行语义搜索。
- 如何使用 Gemini 进行动态记忆提取。
后续步骤
- 探索 Cloud SQL pgvector 文档。
- 详细了解 Gemini API 功能。
- 深入了解 Cloud SQL Auth 代理。
- 尝试自定义
server.js中的extractionPrompt以提取不同类型的数据!
祝您使用 Living Memory 构建应用愉快!