
1. مقدمة
إذا كنت تفضّل تشغيل النصوص البرمجية المجمّعة مباشرةً بدون البرنامج التعليمي المفصّل، يمكنك العثور عليها في مستودع GoogleCloudPlatform/devrel-demos.
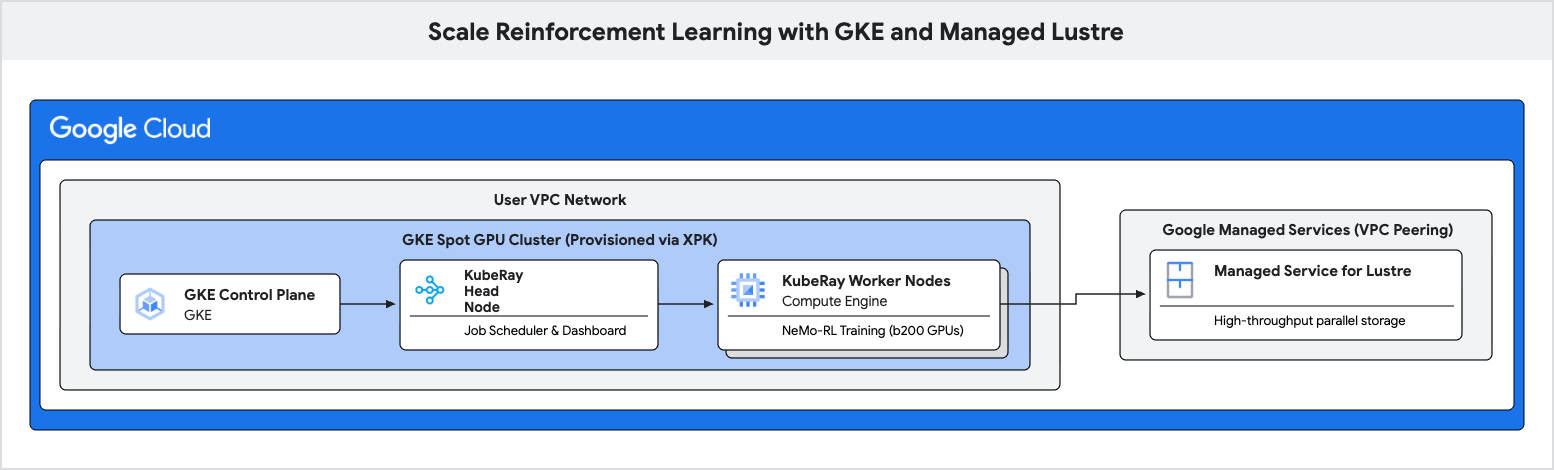
في هذا الدرس التطبيقي حول الترميز، ستتعرّف على كيفية تفعيل مسار تدريب عالي الأداء لـ "التعلّم المعزّز" (RL) باستخدام Google Kubernetes Engine (GKE) وManaged Lustre.
تنتج أحمال عمل التعلّم المعزّز، لا سيما تلك التي تستخدم خوارزميات مثل Group Relative Policy Optimization (GRPO)، كميات هائلة من البيانات أثناء "إنشاء التجربة" وتتطلّب إنشاء نقاط مرجعية متكرّرة. يمكن أن يتسبب تخزين الكائنات العادي في حدوث مؤثِّرات سلبية أثناء وحدات الإدخال والإخراج المكثّفة هذه، ما يؤدي إلى عدم استخدام أدوات التسريع باهظة الثمن.
ستستخدم Managed Lustre، وهو نظام ملفات متوازٍ، لإزالة هذه المؤثِّرات السلبية وتحقيق سرعة معالجة بيانات أعلى للتدريب.
الإجراءات التي ستنفذّها
- ضبط متغيرات البيئة لمجموعة Ray مستندة إلى وحدة معالجة الرسومات
- توفير مجموعة أجهزة GPU مؤقتة على GKE باستخدام أداة XPK
- أنشئ مثيلاً من Managed Lustre.
- نشر مجموعة KubeRay وتحميل نظام ملفات Lustre
- أرسِل عبء عمل تدريب NeMo-RL.
- مراقبة معدّل أعلى لنقل البيانات ووقت الاستجابة المنخفض لنقاط التوقف باستخدام Cloud Monitoring
المتطلبات
- متصفّح ويب، مثل Chrome
- مشروع Google Cloud تم تفعيل الفوترة فيه
هذا الدرس التطبيقي حول الترميز مخصّص للمستخدمين التقنيين المتقدّمين ومهندسي المنصات وباحثي الذكاء الاصطناعي الذين يعرفون مفاهيم GKE والتخزين.
المدة الإجمالية المقدَّرة: من 45 إلى 60 دقيقة بالإضافة إلى ساعتين من وقت التدريب
2. قبل البدء
إنشاء مشروع على Google Cloud
- في Google Cloud Console، اختَر مشروعًا على Google Cloud أو أنشِئ مشروعًا.
- تأكَّد من تفعيل الفوترة لمشروعك على السحابة الإلكترونية.
بدء Cloud Shell
Cloud Shell هي بيئة سطر أوامر تعمل في Google Cloud ومحمّلة مسبقًا بالأدوات اللازمة.
- انقر على تفعيل Cloud Shell في أعلى "وحدة تحكّم Google Cloud".
- بعد الاتصال بـ Cloud Shell، تحقَّق من مصادقتك باتّباع الخطوات التالية:
gcloud auth list - تأكَّد من إعداد مشروعك باتّباع الخطوات التالية:
gcloud config get project - إذا لم يتم ضبط مشروعك على النحو المتوقّع، اضبطه باتّباع الخطوات التالية:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
تثبيت حزمة XPK
يستخدم هذا الدرس التطبيقي حول الترميز xpk لتوفير مجموعة GKE. للحصول على تعليمات حول كيفية تثبيت xpk، يُرجى الاطّلاع على دليل تثبيت ملفات xpk.
في Cloud Shell، يمكنك تثبيته باستخدام:
pip install xpk
تفعيل واجهات برمجة التطبيقات
نفِّذ هذا الأمر في Cloud Shell لتفعيل جميع واجهات برمجة التطبيقات المطلوبة:
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3- ضبط متغيرات البيئة
للحفاظ على اتساق الأوامر في هذا الدرس التطبيقي حول الترميز، عليك إعداد بعض متغيّرات البيئة.
أنشئ ملفًا باسم env.sh واملأه بإعداداتك. يمكنك استخدام النموذج التالي:
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
استبدِل <YOUR_PROJECT_ID> و <YOUR_HF_TOKEN> بالقيم الفعلية.
استخدِم الملف لتحميل المتغيرات إلى جلستك الحالية:
source env.sh
4. إنشاء مجموعة GKE باستخدام XPK
في هذه الخطوة، ستستخدم xpk لتوفير مجموعة GKE مع وحدات معالجة الرسومات Spot.
xpk هي أداة توفير AI Hypercomputer التي تبسّط عملية إنشاء مجموعات GKE لأحمال العمل المبرمَجة. من خلال تحديد نوع الجهاز وعدد العُقد، يتم إنشاء شبكة VPC المطلوبة والشبكة الفرعية ومجموعات العُقد.
نفِّذ أمر إنشاء المجموعة:
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
انتظِر إلى حين إنشاء المجموعة. قد يستغرق هذا الإجراء بضع دقائق.
تفعيل إضافة RayOperator
بعد إنشاء المجموعة، فعِّل إضافة RayOperator لإدارة مجموعات KubeRay:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
التحقّق من برنامج تشغيل CSI الخاص بنظام Lustre
يجب أن يفعّل XPK برنامج تشغيل Lustre CSI تلقائيًا من خلال العلامة --enable-lustre-csi-driver. تأكَّد من تفعيلها:
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
إذا عرضت false، شغِّل أمر التفعيل الاحتياطي:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5- توفير مثيل Managed Lustre
في هذه الخطوة، عليك إنشاء مثيل من "الخدمة المُدارة لنظام Lustre". Lustre هو نظام ملفات متوازٍ يوفّر معدّل أعلى لنقل البيانات لإنشاء نقاط التحقّق.
تخصيص نطاق عناوين IP للخدمات المُدارة
يتطلّب Lustre اتصال ربط شبكة VPC بخدمات Google المُدارة. أولاً، خصِّص نطاق IP عالميًا:
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
إنشاء تبادل المعلومات بين شبكات VPC
ربط شبكة VPC بخدمة Service Networking:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
إنشاء مثيل Lustre
الآن، أنشئ مثيل Lustre. يتم تنفيذ هذا الأمر بشكل غير متزامن.
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
التحقّق من حالة Lustre
يستغرق إعداد مثيل Lustre من 10 إلى 15 دقيقة تقريبًا. يمكنك التحقّق من الحالة باستخدام:
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
انتظِر إلى أن تصبح الحالة ACTIVE قبل المتابعة.
6. تفعيل مجموعة Ray على GKE
في هذه الخطوة، ستنشئ مجموعة KubeRay على عقد GKE وتثبّت نظام ملفات Lustre باستخدام PersistentVolume (PV) وPersistentVolumeClaim (PVC).
Fetch Lustre IP
قبل إنشاء وحدة التخزين، عليك الحصول على عنوان IP لنقطة الربط في مثيل Lustre:
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
إنشاء Lustre PV وPVC
أنشئ ملفًا باسم rl-lustre-volume.yaml باستخدام الإعدادات التالية. يحدّد هذا الإعداد طريقة اتصال GKE بنسخة Lustre.
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
طبِّق إعدادات مستوى الصوت:
kubectl apply -f rl-lustre-volume.yaml
إنشاء إعدادات RayCluster
أنشئ ملفًا باسم ray-cluster.yaml. يحدّد هذا الإعداد عقدَي KubeRay الرئيسية والعاملة، باستخدام نوع المسرّع nvidia-b200 وتثبيت وحدة تخزين Lustre في /lustre.
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
طبِّق إعدادات مجموعة Ray:
kubectl apply -f ray-cluster.yaml
التحقّق من حالة المجموعة
راقِب عملية إنشاء الحاويات:
kubectl get pods -w
انتظِر إلى أن تصبح وحدات head وworker في حالة Running.
7. إرسال حمل عمل للتعلّم التعزيزي
في هذه الخطوة، سترسل مهمة تدريب GRPO في NeMo-RL إلى مجموعة Ray.
الربط بلوحة بيانات Ray
لإرسال مهام وعرض مقاييس، عليك الاتصال بلوحة بيانات Ray. بما أنّ لوحة البيانات متوفّرة في GKE، استخدِم ميزة "توجيه المنفذ" للوصول إليها من Cloud Shell:
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
إنشاء نص التنفيذ البرمجي
أنشئ ملفًا باسم run_nemo_rl.sh. سيتم تنفيذ هذا النص البرمجي على العاملين في مجموعة Ray. نستخدم cat << EOF لملء متغيرات البيئة التي ضبطتها سابقًا.
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
إنشاء ملف تجاهل Ray
أنشئ ملف .rayignore لمنع Ray من تحميل أدلة كبيرة أو غير ضرورية:
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
إنشاء إعدادات بيئة وقت التشغيل
أنشئ ملف JSON لتمرير متغيرات البيئة إلى مهمة Ray:
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
إرسال المهمة
استخدِم واجهة سطر الأوامر في Ray لإرسال المهمة إلى نقطة نهاية لوحة البيانات. إذا لم يتم العثور على الأمر ray في Cloud Shell، يمكنك تثبيته باستخدام pip install ray:
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
ستظهر لك السجلات في نافذة Cloud Shell. ستحمّل المهمة النموذج، وستبدأ العاملين في Ray، وستبدأ حلقة تدريب GRPO.
8. مراقبة أداء التدريب
في هذه الخطوة، ستلاحظ أداء نظام ملفات Lustre أثناء التدريب وإنشاء نقاط التحقّق.
التحقّق من سجلّات التدريب
مع تقدّم التدريب، ستظهر لك سجلّات تشير إلى أنّه يتم حفظ نقاط التحقّق في /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1. يُرجى العِلم أنّ عملية إنشاء نقاط التحقّق تتم بشكل غير متزامن ولا تحظر العاملين في Ray لفترة طويلة جدًا.
لعرض سرعة إنشاء نقاط التحقّق، ابحث عن أسطر السجلّ التي تشير إلى نقاط التحقّق المحفوظة.
عرض مقاييس Lustre في Cloud Console
للاطّلاع على مقاييس مثيل Lustre، اتّبِع الخطوات التالية:
- في Google Cloud Console، ابحث عن Managed Service for Lustre.
- انقر على اسم الجهاز الظاهري (
rl-demo-gpu-lustre). - انقر على علامة التبويب المراقبة.
يمكنك هنا ملاحظة ما يلي:
- معدّل نقل البيانات (بايت/ثانية): اطّلِع على الارتفاعات المفاجئة خلال عملية إنشاء نقاط التحقّق.
- السعة: يمكنك تتبُّع مقدار المساحة التي تستهلكها نقاط التحقّق.
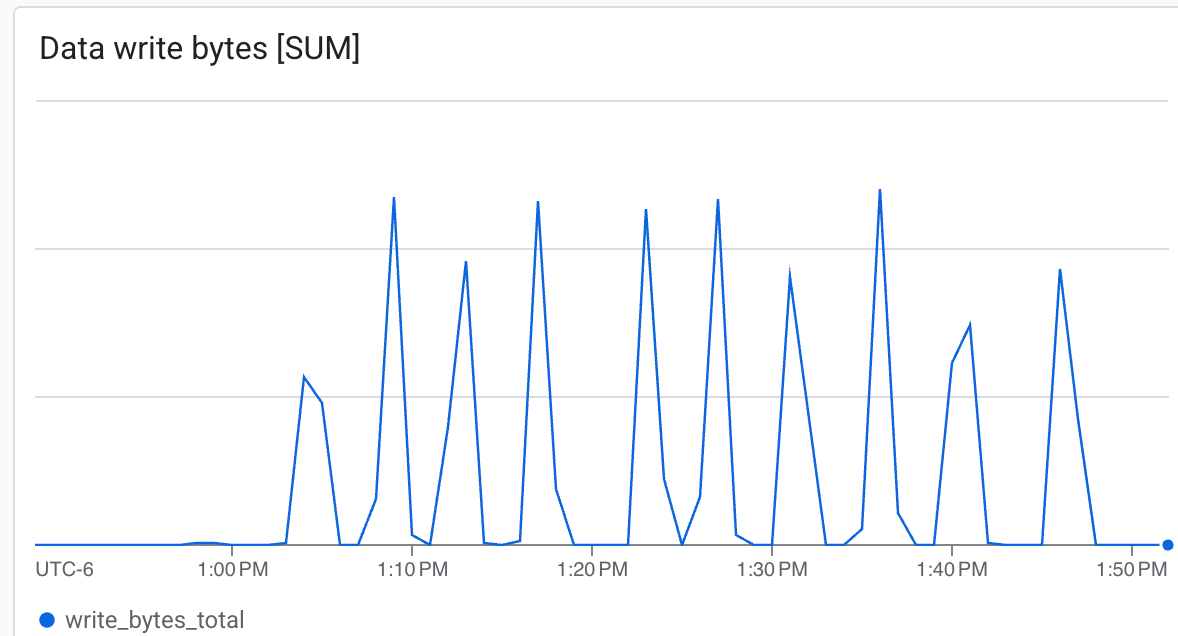 يمكن لـ Lustre الكتابة بسرعة عالية جدًا، وكتابة نقاط التحقّق في أقل وقت ممكن ab.
يمكن لـ Lustre الكتابة بسرعة عالية جدًا، وكتابة نقاط التحقّق في أقل وقت ممكن ab.
9- تنظيف الموارد
نفِّذ الأوامر التالية في Cloud Shell لحذف الموارد التي تم إنشاؤها في هذا الدرس التطبيقي حول الترميز.
حذف مثيل Lustre المُدار
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
حذف مجموعة GKE باستخدام XPK
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
تنظيف أسماء مستعارة لعنوان IP (اختياري)
إذا أردت حذف نطاقات عناوين IP التي تم إنشاؤها لإعداد نظير شبكة VPC بالكامل، اتّبِع الخطوات التالية:
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
سيتم حذف الموارد بشكل غير متزامن. يمكنك التحقّق من حالتها في Cloud Console.
10. تهانينا
لقد أكملت بنجاح الدرس التطبيقي حول الترميز Scale Reinforcement Learning with GKE and Managed Lustre.
ما تعلّمته
- كيفية استخدام
xpkلتوفير مجموعة GKE لوحدات معالجة الرسومات (GPU) مع مثيلات Spot - كيفية تفعيل برنامج تشغيل Lustre CSI وإضافات RayOperator
- كيفية توفير مثيل من Google Cloud Managed Service for Lustre
- كيفية نشر مجموعة KubeRay وتثبيت مساحة تخزين Lustre
- كيفية إرسال عبء عمل تدريب GRPO في NeMo-RL
- كيفية مراقبة أداء التخزين أثناء التدريب
الخطوات التالية
- استكشاف المزيد من ميزات NVIDIA NeMo-RL
- مزيد من المعلومات حول Google Cloud AI Hypercomputer
- راجِع مستندات Managed Service for Lustre.