
১. ভূমিকা
আপনি যদি ধাপে ধাপে টিউটোরিয়ালটি ছাড়াই সরাসরি প্যাকেজ করা স্ক্রিপ্টগুলো চালাতে চান, তাহলে সেগুলো GoogleCloudPlatform/devrel-demos রিপোজিটরিতে খুঁজে পাবেন।
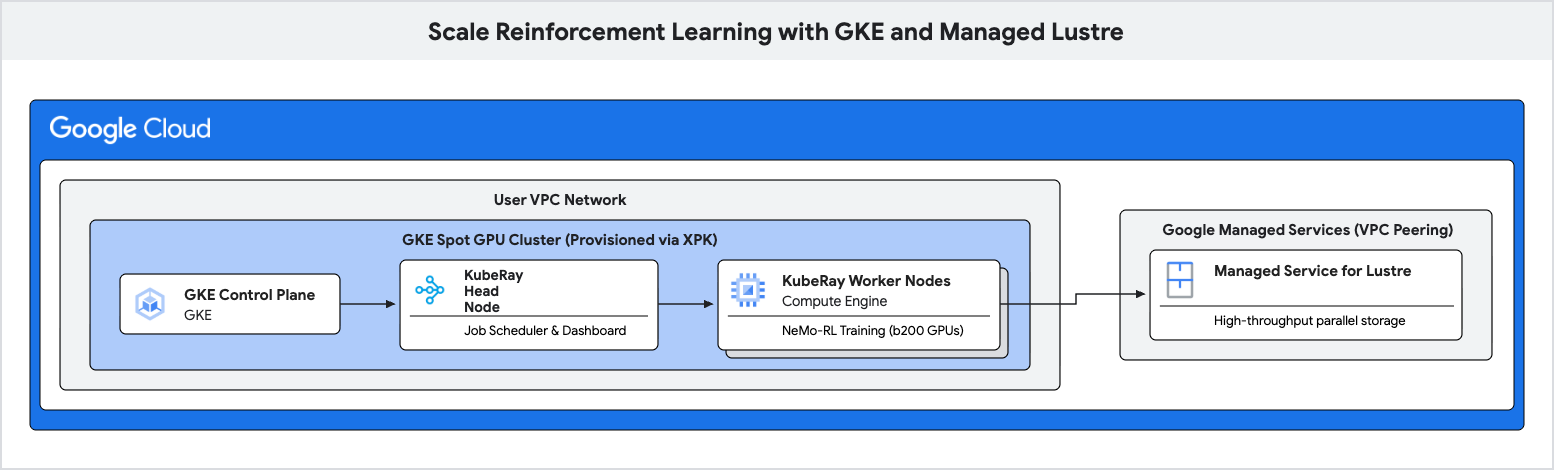
এই কোডল্যাবে, আপনি শিখবেন কিভাবে গুগল কুবারনেটিস ইঞ্জিন (GKE) এবং ম্যানেজড লাস্টার ব্যবহার করে রিইনফোর্সমেন্ট লার্নিং (RL)-এর জন্য একটি উচ্চ-পারফরম্যান্স প্রশিক্ষণ পাইপলাইন স্থাপন করতে হয়।
রিইনফোর্সমেন্ট লার্নিং ওয়ার্কলোড, বিশেষ করে যেগুলো গ্রুপ রিলেটিভ পলিসি অপটিমাইজেশন (GRPO)-এর মতো অ্যালগরিদম ব্যবহার করে, সেগুলো "এক্সপেরিয়েন্স জেনারেশন" চলাকালীন বিপুল পরিমাণ ডেটা তৈরি করে এবং ঘন ঘন চেকপয়েন্টিংয়ের প্রয়োজন হয়। এই I/O প্রবাহের সময় স্ট্যান্ডার্ড অবজেক্ট স্টোরেজ প্রতিবন্ধকতা সৃষ্টি করতে পারে, যার ফলে ব্যয়বহুল অ্যাক্সিলারেটরগুলো নিষ্ক্রিয় হয়ে পড়ে।
এই প্রতিবন্ধকতাগুলো দূর করতে এবং প্রশিক্ষণের উচ্চতর থ্রুপুট অর্জন করতে আপনি ম্যানেজড লাস্টার (Managed Lustre) নামক একটি প্যারালাল ফাইল সিস্টেম ব্যবহার করবেন।
আপনি যা করবেন
- GPU-ভিত্তিক Ray ক্লাস্টারের জন্য এনভায়রনমেন্ট ভেরিয়েবল কনফিগার করুন।
- XPK টুল ব্যবহার করে GKE-তে একটি স্পট GPU ক্লাস্টার প্রস্তুত করুন।
- একটি ম্যানেজড লাস্টার ইনস্ট্যান্স তৈরি করুন।
- একটি KubeRay ক্লাস্টার স্থাপন করুন এবং Lustre ফাইলসিস্টেমটি মাউন্ট করুন।
- একটি NeMo-RL প্রশিক্ষণ ওয়ার্কলোড জমা দিন।
- ক্লাউড মনিটরিং ব্যবহার করে উচ্চ থ্রুপুট এবং কম চেকপয়েন্ট ল্যাটেন্সি পর্যবেক্ষণ করুন ।
আপনার যা যা লাগবে
- ক্রোমের মতো একটি ওয়েব ব্রাউজার।
- বিলিং সক্ষম একটি গুগল ক্লাউড প্রজেক্ট।
এই কোডল্যাবটি উন্নত প্রযুক্তি ব্যবহারকারী, প্ল্যাটফর্ম ইঞ্জিনিয়ার এবং এআই গবেষকদের জন্য, যারা GKE এবং স্টোরেজ ধারণাগুলির সাথে পরিচিত।
আনুমানিক মোট সময়কাল: ৪৫ থেকে ৬০ মিনিট এবং এর সাথে ২ ঘণ্টার প্রশিক্ষণের সময়
২. শুরু করার আগে
একটি গুগল ক্লাউড প্রজেক্ট তৈরি করুন
- গুগল ক্লাউড কনসোলে , একটি গুগল ক্লাউড প্রজেক্ট নির্বাচন করুন বা তৈরি করুন ।
- আপনার ক্লাউড প্রজেক্টের জন্য বিলিং চালু আছে কিনা তা নিশ্চিত করুন।
ক্লাউড শেল শুরু করুন
ক্লাউড শেল হলো গুগল ক্লাউডে চালিত একটি কমান্ড-লাইন পরিবেশ, যা প্রয়োজনীয় টুলস সহ আগে থেকেই লোড করা থাকে।
- Google Cloud কনসোলের শীর্ষে থাকা Activate Cloud Shell-এ ক্লিক করুন।
- ক্লাউড শেলে সংযুক্ত হওয়ার পর, আপনার প্রমাণীকরণ যাচাই করুন:
gcloud auth list - আপনার প্রজেক্টটি কনফিগার করা হয়েছে কিনা তা নিশ্চিত করুন:
gcloud config get project - আপনার প্রজেক্টটি প্রত্যাশা অনুযায়ী সেট করা না থাকলে, এটি সেট করুন:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
XPK ইনস্টল করুন
এই কোডল্যাবটি GKE ক্লাস্টার প্রোভিশন করতে xpk ব্যবহার করে। xpk কীভাবে ইনস্টল করতে হয় তার নির্দেশাবলীর জন্য, xpk ইনস্টলেশন গাইডটি দেখুন।
ক্লাউড শেলে আপনি এটি এভাবে ইনস্টল করতে পারেন:
pip install xpk
এপিআই সক্ষম করুন
প্রয়োজনীয় সকল API সক্রিয় করতে ক্লাউড শেলে এই কমান্ডটি চালান:
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
৩. পরিবেশ ভেরিয়েবল কনফিগার করুন
এই কোডল্যাবের কমান্ডগুলো সামঞ্জস্যপূর্ণ রাখতে কয়েকটি এনভায়রনমেন্ট ভেরিয়েবল সেট করুন।
env.sh নামে একটি ফাইল তৈরি করুন এবং আপনার কনফিগারেশন দিয়ে তা পূরণ করুন। আপনি নিম্নলিখিত টেমপ্লেটটি ব্যবহার করতে পারেন:
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
<YOUR_PROJECT_ID> এবং <YOUR_HF_TOKEN>-এর জায়গায় আপনার প্রকৃত মানগুলো বসান।
আপনার বর্তমান সেশনে ভেরিয়েবলগুলো লোড করতে ফাইলটি সোর্স করুন:
source env.sh
৪. XPK ব্যবহার করে GKE ক্লাস্টার তৈরি করুন
এই ধাপে, আপনি xpk ব্যবহার করে স্পট জিপিইউ সহ একটি GKE ক্লাস্টার প্রোভিশন করবেন।
xpk হলো একটি এআই হাইপারকম্পিউটার প্রোভিশনিং টুল যা স্বয়ংক্রিয় ওয়ার্কলোডের জন্য GKE ক্লাস্টার তৈরি করাকে সহজ করে। ডিভাইসের ধরন এবং নোডের সংখ্যা নির্দিষ্ট করে দিলে, এটি প্রয়োজনীয় VPC, সাবনেট এবং নোড পুল তৈরি করে।
ক্লাস্টার তৈরির কমান্ডটি চালান:
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
ক্লাস্টারটি তৈরি হওয়ার জন্য অপেক্ষা করুন। এতে কয়েক মিনিট সময় লাগতে পারে।
RayOperator অ্যাড-অনটি সক্রিয় করুন
ক্লাস্টার তৈরি হয়ে গেলে, KubeRay ক্লাস্টারগুলি পরিচালনা করার জন্য RayOperator অ্যাড-অনটি সক্রিয় করুন:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
লাস্টার সিএসআই ড্রাইভার যাচাই করুন
XPK --enable-lustre-csi-driver ফ্ল্যাগের মাধ্যমে স্বয়ংক্রিয়ভাবে Lustre CSI ড্রাইভারটি সক্রিয় করবে। এটি সক্রিয় আছে কিনা তা যাচাই করুন:
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
যদি এটি false রিটার্ন করে, তাহলে fallback enable কমান্ডটি চালান:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
৫. প্রোভিশন ম্যানেজড লাস্টার ইনস্ট্যান্স
এই ধাপে, আপনি লাস্টার ইনস্ট্যান্সের জন্য একটি ম্যানেজড সার্ভিস তৈরি করবেন। লাস্টার হলো একটি প্যারালাল ফাইল সিস্টেম যা চেকপয়েন্টিংয়ের জন্য উচ্চ থ্রুপুট প্রদান করে।
পরিচালিত পরিষেবাগুলির জন্য আইপি রেঞ্জ বরাদ্দ করুন
Lustre-এর জন্য Google Managed Services-এর সাথে একটি VPC peering সংযোগ প্রয়োজন। প্রথমে, একটি গ্লোবাল আইপি রেঞ্জ বরাদ্দ করুন:
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
VPC পিয়ারিং স্থাপন করুন
আপনার VPC-কে সার্ভিস নেটওয়ার্কিং-এর সাথে সংযুক্ত করুন:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
লাস্টার ইনস্ট্যান্স তৈরি করুন
এখন, Lustre ইনস্ট্যান্সটি তৈরি করুন। এই কমান্ডটি অ্যাসিঙ্ক্রোনাসভাবে চলে।
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
ঔজ্জ্বল্যের অবস্থা যাচাই করুন
লাস্টার ইনস্ট্যান্সটি প্রস্তুত হতে প্রায় ১০-১৫ মিনিট সময় লাগে। আপনি এর স্ট্যাটাস চেক করতে পারেন:
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
এগিয়ে যাওয়ার আগে অবস্থাটি ACTIVE হওয়া পর্যন্ত অপেক্ষা করুন।
৬. GKE-তে রে ক্লাস্টার স্থাপন করুন
এই ধাপে, আপনি আপনার GKE নোডগুলিতে একটি KubeRay ক্লাস্টার স্থাপন করবেন এবং PersistentVolume (PV) ও PersistentVolumeClaim (PVC) ব্যবহার করে Lustre ফাইলসিস্টেম মাউন্ট করবেন।
ফেচ লাস্টার আইপি
ভলিউম তৈরি করার আগে, আপনাকে আপনার লাস্টার ইনস্ট্যান্সের মাউন্ট পয়েন্ট আইপি পেতে হবে:
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
উজ্জ্বল পিভি এবং পিভিসি তৈরি করুন
নিম্নলিখিত কনফিগারেশন ব্যবহার করে rl-lustre-volume.yaml নামে একটি ফাইল তৈরি করুন। এটি নির্ধারণ করে যে GKE কীভাবে আপনার Lustre ইনস্ট্যান্সের সাথে সংযোগ স্থাপন করবে।
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
ভলিউম কনফিগারেশন প্রয়োগ করুন:
kubectl apply -f rl-lustre-volume.yaml
রেক্লাস্টার কনফিগারেশন তৈরি করুন
ray-cluster.yaml নামে একটি ফাইল তৈরি করুন। এটি KubeRay হেড এবং ওয়ার্কার নোডগুলিকে নির্দিষ্ট করে, যেখানে nvidia-b200 অ্যাক্সিলারেটর টাইপ ব্যবহৃত হয় এবং Lustre ভলিউমটি /lustre এ মাউন্ট করা হয়।
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
রে ক্লাস্টার কনফিগারেশন প্রয়োগ করুন:
kubectl apply -f ray-cluster.yaml
ক্লাস্টারের অবস্থা যাচাই করুন
পডগুলো তৈরি হওয়া পর্যবেক্ষণ করুন:
kubectl get pods -w
হেড এবং ওয়ার্কার পডগুলো Running হওয়া পর্যন্ত অপেক্ষা করুন।
৭. রিইনফোর্সমেন্ট লার্নিং ওয়ার্কলোড জমা দিন
এই ধাপে, আপনি আপনার Ray ক্লাস্টারে NeMo-RL GRPO ট্রেনিং জবটি সাবমিট করবেন।
রে ড্যাশবোর্ডে সংযোগ করুন
জব জমা দিতে এবং মেট্রিক্স দেখতে, আপনাকে রে ড্যাশবোর্ডে সংযোগ করতে হবে। যেহেতু ড্যাশবোর্ডটি GKE-তে রয়েছে, ক্লাউড শেল থেকে এটি অ্যাক্সেস করার জন্য পোর্ট-ফরওয়ার্ডিং ব্যবহার করুন:
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
এক্সিকিউশন স্ক্রিপ্ট তৈরি করুন
run_nemo_rl.sh নামে একটি ফাইল তৈরি করুন। এই স্ক্রিপ্টটি Ray ক্লাস্টারের ওয়ার্কারদের উপর চালানো হবে। আপনার আগে সেট করা এনভায়রনমেন্ট ভেরিয়েবলগুলো পূরণ করার জন্য আমরা cat << EOF ব্যবহার করি।
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
রে ইগনোর ফাইল তৈরি করুন
রে-কে বড় বা অপ্রয়োজনীয় ডিরেক্টরি আপলোড করা থেকে বিরত রাখতে একটি .rayignore ফাইল তৈরি করুন:
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
রানটাইম এনভায়রনমেন্ট কনফিগারেশন তৈরি করুন
Ray জবে এনভায়রনমেন্ট ভেরিয়েবল পাস করার জন্য একটি JSON ফাইল তৈরি করুন:
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
চাকরিটি জমা দিন
ড্যাশবোর্ড এন্ডপয়েন্টে জবটি জমা দিতে Ray CLI ব্যবহার করুন। যদি ক্লাউড শেলে ray কমান্ডটি খুঁজে না পাওয়া যায়, তাহলে আপনি pip install ray মাধ্যমে এটি ইনস্টল করতে পারেন।
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
আপনি আপনার ক্লাউড শেল টার্মিনালে লগগুলো চলতে দেখবেন। জবটি মডেলটি লোড করবে, রে ওয়ার্কারগুলোকে ইনিশিয়ালাইজ করবে এবং জিআরপিও ট্রেনিং লুপ শুরু করবে।
৮. প্রশিক্ষণের কার্যকারিতা পর্যবেক্ষণ করুন
এই ধাপে, আপনি ট্রেনিং এবং চেকপয়েন্টিং চলাকালীন লাস্টার ফাইলসিস্টেমের পারফরম্যান্স পর্যবেক্ষণ করবেন।
প্রশিক্ষণ লগ পরীক্ষা করুন
প্রশিক্ষণ চলাকালীন, আপনি লগ দেখতে পাবেন যা নির্দেশ করে যে চেকপয়েন্টগুলি /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 এ সংরক্ষিত হচ্ছে। লক্ষ্য করুন যে চেকপয়েন্টিং অ্যাসিঙ্ক্রোনাসভাবে ঘটে এবং এটি রে ওয়ার্কারদের খুব বেশি সময়ের জন্য ব্লক করে না।
চেকপয়েন্টিংয়ের গতি দেখতে, সংরক্ষিত চেকপয়েন্ট নির্দেশকারী লগ লাইনগুলো দেখুন।
ক্লাউড কনসোলে লাস্টার মেট্রিক্স দেখুন
আপনার Lustre ইনস্ট্যান্সের মেট্রিক্স দেখতে:
- গুগল ক্লাউড কনসোলে , Lustre-এর জন্য Managed Service অনুসন্ধান করুন।
- আপনার ইনস্ট্যান্সের নামে (
rl-demo-gpu-lustre) ক্লিক করুন। - মনিটরিং ট্যাবে ক্লিক করুন।
এখানে আপনি পর্যবেক্ষণ করতে পারেন:
- থ্রুপুট (বাইট/সেকেন্ড) : চেকপয়েন্টিং চলাকালীন আকস্মিক বৃদ্ধি দেখুন।
- ধারণক্ষমতা : চেকপয়েন্টগুলো কী পরিমাণ জায়গা ব্যবহার করছে তা পর্যবেক্ষণ করুন।
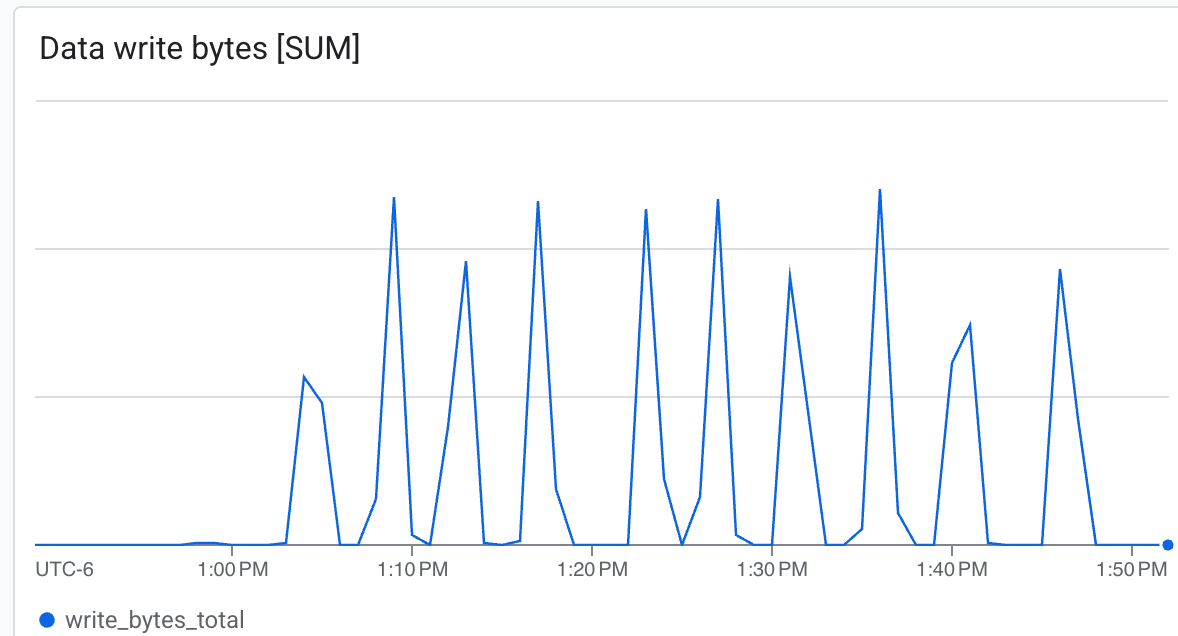 লাস্টার অত্যন্ত দ্রুত গতিতে লিখতে সক্ষম এবং ন্যূনতম সময়ে চেকপয়েন্ট তৈরি করতে পারে ।
লাস্টার অত্যন্ত দ্রুত গতিতে লিখতে সক্ষম এবং ন্যূনতম সময়ে চেকপয়েন্ট তৈরি করতে পারে ।
৯. সম্পদ পরিষ্কার করুন
এই কোডল্যাবে তৈরি করা রিসোর্সগুলো মুছে ফেলার জন্য ক্লাউড শেলে নিম্নলিখিত কমান্ডগুলো চালান।
পরিচালিত লাস্টার ইনস্ট্যান্স মুছুন
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
XPK ব্যবহার করে GKE ক্লাস্টার মুছুন
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
আইপি অ্যালিয়াসগুলি পরিষ্কার করুন (ঐচ্ছিক)
আপনি যদি VPC পিয়ারিং-এর জন্য তৈরি করা IP রেঞ্জগুলো সম্পূর্ণরূপে পরিষ্কার করতে চান:
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
রিসোর্সগুলো অ্যাসিঙ্ক্রোনাসভাবে মুছে ফেলা হবে। আপনি ক্লাউড কনসোলে সেগুলোর অবস্থা যাচাই করতে পারবেন।
১০. অভিনন্দন
আপনি সফলভাবে 'Scale Reinforcement Learning with GKE and Managed Lustre' কোডল্যাবটি সম্পন্ন করেছেন!
আপনি যা শিখেছেন
-
xpkব্যবহার করে কীভাবে স্পট ইনস্ট্যান্স সহ একটি GKE GPU ক্লাস্টার প্রোভিশন করতে হয়। - Lustre CSI ড্রাইভার এবং RayOperator অ্যাড-অনগুলি কীভাবে সক্রিয় করবেন
- Lustre ইনস্ট্যান্সের জন্য কীভাবে একটি Google Cloud Managed Service প্রোভিশন করবেন।
- কিভাবে একটি KubeRay ক্লাস্টার স্থাপন করতে হয় এবং Lustre স্টোরেজ মাউন্ট করতে হয়।
- NeMo-RL GRPO প্রশিক্ষণের ওয়ার্কলোড কীভাবে জমা দিতে হয়।
- ট্রেনিং চলাকালীন স্টোরেজ পারফরম্যান্স কীভাবে পর্যবেক্ষণ করবেন।
পরবর্তী পদক্ষেপ
- NVIDIA NeMo-RL-এর আরও বৈশিষ্ট্য সম্পর্কে জানুন।
- গুগল ক্লাউড এআই হাইপারকম্পিউটার সম্পর্কে আরও জানুন।
- Lustre-এর ম্যানেজড সার্ভিস সংক্রান্ত ডকুমেন্টেশন পর্যালোচনা করুন।