
1. Einführung
Wenn Sie die verpackten Skripts lieber direkt ohne die Schritt-für-Schritt-Anleitung ausführen möchten, finden Sie sie im Repository GoogleCloudPlatform/devrel-demos.
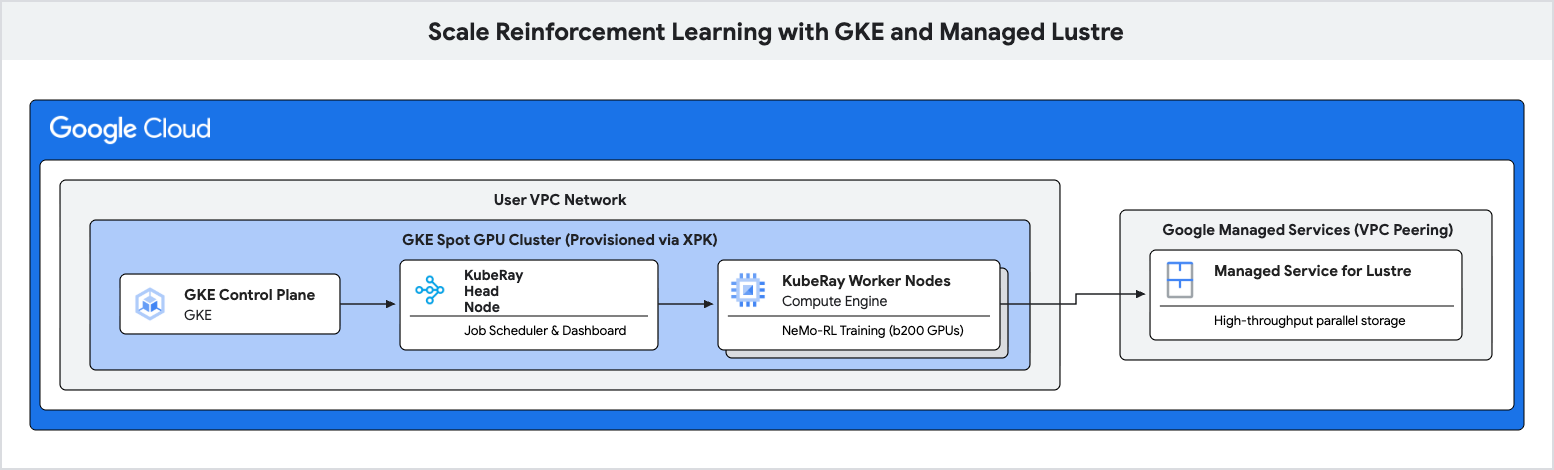
In diesem Codelab erfahren Sie, wie Sie eine leistungsstarke Trainingspipeline für Reinforcement Learning (RL) mit Google Kubernetes Engine (GKE) und Managed Lustre bereitstellen.
Arbeitslasten für Reinforcement Learning, insbesondere solche, die Algorithmen wie Group Relative Policy Optimization (GRPO) verwenden, generieren während der „Experience Generation“ riesige Datenmengen und erfordern häufige Prüfpunkte. Standardmäßiger Objektspeicher kann bei diesen I/O-Bursts zu Engpässen führen, sodass teure Beschleuniger im Leerlauf bleiben.
Sie verwenden Managed Lustre, ein paralleles Dateisystem, um diese Engpässe zu beseitigen und einen höheren Trainingsdurchsatz zu erzielen.
Aufgaben
- Umgebungsvariablen für einen GPU-basierten Ray-Cluster konfigurieren.
- Mit dem Tool XPK einen Spot-GPU-Cluster in GKE bereitstellen.
- Eine Managed Lustre -Instanz erstellen.
- Einen KubeRay -Cluster bereitstellen und das Lustre-Dateisystem einbinden.
- Eine NeMo-RL -Trainingsarbeitslast senden.
- Mit Cloud Monitoring hohen Durchsatz und niedrige Prüfpunktlatenz beobachten.
Voraussetzungen
- Ein Webbrowser wie Chrome.
- Google Cloud-Projekt mit aktivierter Abrechnungsfunktion.
Dieses Codelab richtet sich an fortgeschrittene technische Nutzer, Plattformtechniker und KI-Forscher, die mit GKE und Speicherkonzepten vertraut sind.
Geschätzte Gesamtdauer: 45 bis 60 Minuten plus 2 Stunden Trainingszeit
2. Hinweis
Google Cloud-Projekt erstellen
- Wählen Sie in der Google Cloud Console ein Google Cloud-Projekt aus oder erstellen Sie eines.
- Die Abrechnung für das Cloud-Projekt muss aktiviert sein.
Cloud Shell starten
Die Cloud Shell ist eine Befehlszeilenumgebung, die in Google Cloud ausgeführt wird und in der die erforderlichen Tools vorinstalliert sind.
- Klicken Sie oben in der Google Cloud Console auf Cloud Shell aktivieren.
- Prüfen Sie nach dem Herstellen der Verbindung zur Cloud Shell Ihre Authentifizierung:
gcloud auth list - Prüfen Sie, ob Ihr Projekt konfiguriert ist:
gcloud config get project - Wenn Ihr Projekt nicht wie erwartet festgelegt ist, legen Sie es fest:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
XPK installieren
In diesem Codelab wird xpk verwendet, um den GKE-Cluster bereitzustellen. Eine Anleitung zur Installation von xpk finden Sie im Installationsleitfaden für XPK.
In Cloud Shell können Sie es mit folgendem Befehl installieren:
pip install xpk
APIs aktivieren
Führen Sie diesen Befehl in Cloud Shell aus, um alle erforderlichen APIs zu aktivieren:
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3. Umgebungsvariablen konfigurieren
Damit die Befehle in diesem Codelab einheitlich sind, richten Sie einige Umgebungsvariablen ein.
Erstellen Sie eine Datei mit dem Namen env.sh und füllen Sie sie mit Ihrer Konfiguration. Sie können die folgende Vorlage verwenden:
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
Ersetzen Sie <YOUR_PROJECT_ID> und <YOUR_HF_TOKEN> durch Ihre tatsächlichen Werte.
Rufen Sie die Datei auf, um die Variablen in die aktuelle Sitzung zu laden:
source env.sh
4. GKE-Cluster mit XPK erstellen
In diesem Schritt stellen Sie mit xpk einen GKE-Cluster mit Spot-GPUs bereit.
xpk ist das Bereitstellungstool für den AI Hypercomputer , das die Erstellung von GKE-Clustern für automatisierte Arbeitslasten vereinfacht. Durch Angabe des Gerätetyps und der Anzahl der Knoten werden die erforderlichen VPC, das Subnetz und die Knotenpools erstellt.
Führen Sie den Befehl zum Erstellen des Clusters aus:
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
Warten Sie, bis der Cluster erstellt wurde. Dieser Vorgang kann einige Minuten dauern.
RayOperator-Add-on aktivieren
Nachdem der Cluster erstellt wurde, aktivieren Sie das RayOperator -Add-on, um KubeRay-Cluster zu verwalten:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
Lustre-CSI-Treiber prüfen
XPK sollte den Lustre-CSI-Treiber automatisch über das Flag --enable-lustre-csi-driver aktivieren. Prüfen Sie, ob er aktiviert ist:
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
Wenn false zurückgegeben wird, führen Sie den Fallback-Aktivierungsbefehl aus:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5. Managed Lustre-Instanz bereitstellen
In diesem Schritt erstellen Sie einen verwalteten Dienst für die Lustre-Instanz. Lustre ist ein paralleles Dateisystem, das einen hohen Durchsatz für Prüfpunkte bietet.
IP-Bereich für verwaltete Dienste zuweisen
Für Lustre ist eine VPC-Peering-Verbindung zu verwalteten Google-Diensten erforderlich. Weisen Sie zuerst einen globalen IP-Bereich zu:
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
VPC-Peering einrichten
Verbinden Sie Ihre VPC mit Service Networking:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
Lustre-Instanz erstellen
Erstellen Sie nun die Lustre-Instanz. Dieser Befehl wird asynchron ausgeführt.
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
Lustre-Status prüfen
Es dauert etwa 10 bis 15 Minuten , bis die Lustre-Instanz bereit ist. Sie können den Status mit folgendem Befehl prüfen:
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
Warten Sie, bis der Status ACTIVE ist, bevor Sie fortfahren.
6. Ray-Cluster in GKE bereitstellen
In diesem Schritt stellen Sie einen KubeRay-Cluster auf Ihren GKE-Knoten bereit und binden das Lustre-Dateisystem mit einem PersistentVolume (PV) und einem PersistentVolumeClaim (PVC) ein.
Lustre-IP abrufen
Bevor Sie das Volume erstellen, müssen Sie die IP-Adresse des Bereitstellungspunkts Ihrer Lustre-Instanz abrufen:
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
Lustre-PV und -PVC erstellen
Erstellen Sie eine Datei mit dem Namen rl-lustre-volume.yaml mit der folgenden Konfiguration. Dadurch wird definiert, wie GKE eine Verbindung zu Ihrer Lustre-Instanz herstellt.
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
Wenden Sie die Volume-Konfiguration an:
kubectl apply -f rl-lustre-volume.yaml
RayCluster-Konfiguration erstellen
Erstellen Sie eine Datei mit dem Namen ray-cluster.yaml. Hier werden die KubeRay-Head- und Worker-Knoten mit dem Beschleunigertyp nvidia-b200 angegeben und das Lustre-Volume unter /lustre eingebunden.
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
Wenden Sie die Ray-Clusterkonfiguration an:
kubectl apply -f ray-cluster.yaml
Clusterstatus prüfen
Beobachten Sie die Erstellung der Pods:
kubectl get pods -w
Warten Sie, bis die Head- und Worker-Pods den Status Running haben.
7. Arbeitslast für Reinforcement Learning senden
In diesem Schritt senden Sie den NeMo-RL-GRPO-Trainingsjob an Ihren Ray-Cluster.
Verbindung zum Ray-Dashboard herstellen
Um Jobs zu senden und Messwerte aufzurufen, müssen Sie eine Verbindung zum Ray-Dashboard herstellen. Da sich das Dashboard in GKE befindet, verwenden Sie die Portweiterleitung, um von Cloud Shell aus darauf zuzugreifen:
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
Ausführungsskript erstellen
Erstellen Sie eine Datei mit dem Namen run_nemo_rl.sh. Dieses Skript wird auf den Ray-Cluster-Workern ausgeführt. Wir verwenden cat << EOF, um die zuvor festgelegten Umgebungsvariablen einzufügen.
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
Ray-Ignorierdatei erstellen
Erstellen Sie eine .rayignore-Datei, um zu verhindern, dass Ray große oder unnötige Verzeichnisse hochlädt:
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
Laufzeitumgebungskonfiguration erstellen
Erstellen Sie eine JSON-Datei, um Umgebungsvariablen an den Ray-Job zu übergeben:
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
Job senden
Verwenden Sie die Ray-Befehlszeile, um den Job an den Dashboard-Endpunkt zu senden. Wenn der Befehl ray in Cloud Shell nicht gefunden wird, können Sie ihn mit pip install ray installieren:
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
In Ihrem Cloud Shell-Terminal werden Logs gestreamt. Der Job lädt das Modell, initialisiert die Ray-Worker und startet die GRPO-Trainingsschleife.
8. Trainingsleistung beobachten
In diesem Schritt beobachten Sie die Leistung des Lustre-Dateisystems während des Trainings und der Prüfpunktausführung.
Trainingslogs prüfen
Im Laufe des Trainings werden Logs angezeigt, die darauf hinweisen, dass Prüfpunkte unter /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 gespeichert werden. Die Prüfpunktausführung erfolgt asynchron und blockiert die Ray-Worker nicht sehr lange.
Die Geschwindigkeit der Prüfpunktausführung können Sie anhand der Logzeilen mit den gespeicherten Prüfpunkten ablesen.
Lustre-Messwerte in der Cloud Console ansehen
So rufen Sie Messwerte für Ihre Lustre-Instanz auf:
- Suchen Sie in der Google Cloud Console nach Managed Service for Lustre.
- Klicken Sie auf den Namen Ihrer Instanz (
rl-demo-gpu-lustre). - Klicken Sie auf den Tab Monitoring.
Hier können Sie Folgendes beobachten:
- Durchsatz (Byte/Sek.): Sehen Sie sich die Spitzenwerte während der Prüfpunktausführung an.
- Kapazität: Beobachten Sie, wie viel Speicherplatz von Prüfpunkten belegt wird.
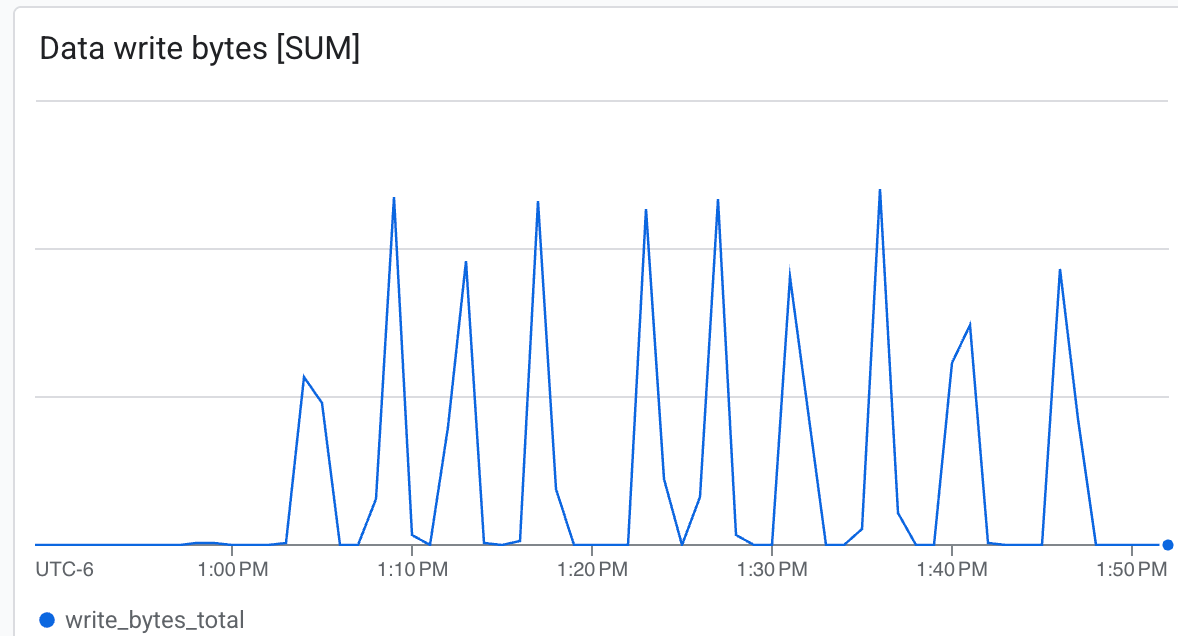 Lustre kann mit sehr hoher Geschwindigkeit schreiben und Prüfpunkte in kürzester Zeit speichern.
Lustre kann mit sehr hoher Geschwindigkeit schreiben und Prüfpunkte in kürzester Zeit speichern.
9. Ressourcen bereinigen
Führen Sie die folgenden Befehle in Cloud Shell aus, um die in diesem Codelab erstellten Ressourcen zu löschen.
Managed Lustre-Instanz löschen
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
GKE-Cluster mit XPK löschen
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
IP-Aliase bereinigen (optional)
Wenn Sie die für das VPC-Peering erstellten IP-Bereiche vollständig bereinigen möchten, gehen Sie so vor:
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
Die Ressourcen werden asynchron gelöscht. Sie können ihren Status in der Cloud Console prüfen.
10. Glückwunsch
Sie haben das Codelab Reinforcement Learning mit GKE und Managed Lustre skalieren abgeschlossen.
Lerninhalte
- So stellen Sie mit
xpkeinen GKE-GPU-Cluster mit Spot-Instanzen bereit. - So aktivieren Sie die Add-ons Lustre-CSI-Treiber und RayOperator.
- So stellen Sie eine Managed Service for Lustre-Instanz von Google Cloud bereit.
- So stellen Sie einen KubeRay-Cluster bereit und binden Lustre-Speicher ein.
- So senden Sie eine NeMo-RL-GRPO-Trainingsarbeitslast.
- So beobachten Sie die Speicherleistung während des Trainings.
Nächste Schritte
- Weitere Funktionen von NVIDIA NeMo-RL kennenlernen.
- Weitere Informationen zum AI Hypercomputer von Google Cloud.
- Dokumentation zu Managed Service for Lustre lesen.