
1. Introduction
If you prefer to run the packaged scripts directly without the step-by-step tutorial, you can find them in the GoogleCloudPlatform/devrel-demos repository.
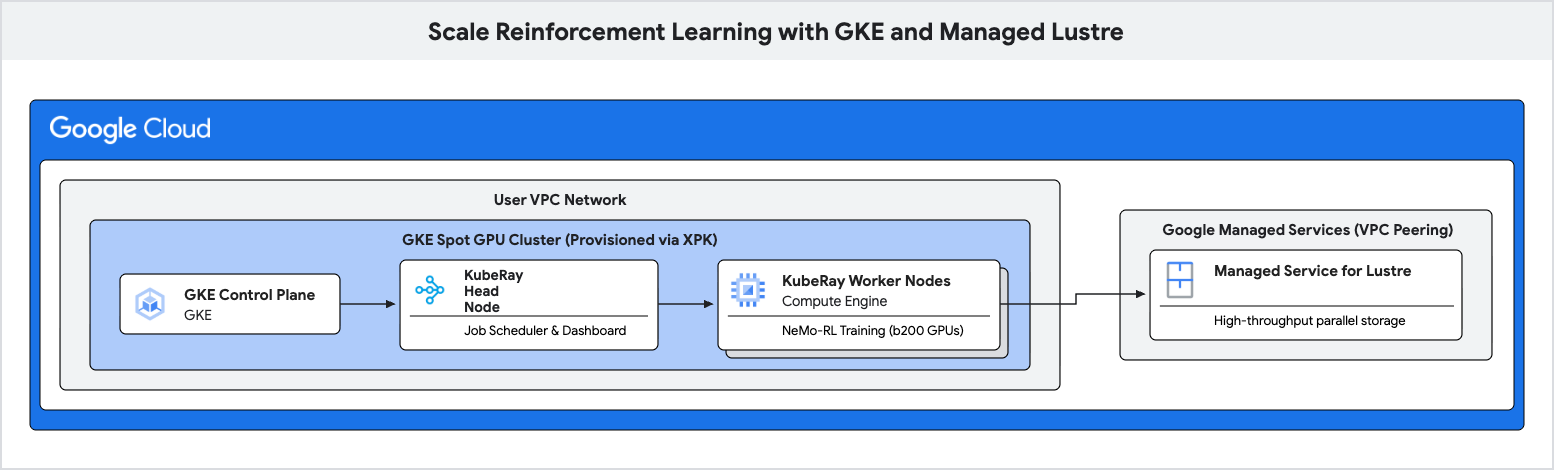
In this codelab, you will learn how to deploy a high-performance training pipeline for Reinforcement Learning (RL) using Google Kubernetes Engine (GKE) and Managed Lustre.
Reinforcement Learning workloads, particularly those using algorithms like Group Relative Policy Optimization (GRPO), generate massive amounts of data during "Experience Generation" and require frequent checkpointing. Standard object storage can cause bottlenecks during these I/O bursts, leaving expensive accelerators idle.
You will use Managed Lustre, a parallel file system, to eliminate these bottlenecks and achieve higher training throughput.
What you'll do
- Configure environment variables for a GPU-based Ray cluster.
- Provision a Spot GPU cluster on GKE using the XPK tool.
- Create a Managed Lustre instance.
- Deploy a KubeRay cluster and mount the Lustre filesystem.
- Submit a NeMo-RL training workload.
- Observe high throughput and low checkpoint latency using Cloud Monitoring.
What you'll need
- A web browser such as Chrome.
- A Google Cloud project with billing enabled.
This codelab is for advanced technical users, platform engineers, and AI researchers who are familiar with GKE and storage concepts.
Estimated Total Duration: 45 to 60 minutes plus 2 hours of training time
2. Before you begin
Create a Google Cloud Project
- In the Google Cloud Console, select or create a Google Cloud project.
- Make sure that billing is enabled for your Cloud project.
Start Cloud Shell
Cloud Shell is a command-line environment running in Google Cloud that comes preloaded with necessary tools.
- Click Activate Cloud Shell at the top of the Google Cloud console.
- Once connected to Cloud Shell, verify your authentication:
gcloud auth list - Confirm your project is configured:
gcloud config get project - If your project is not set as expected, set it:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Install XPK
This codelab uses xpk to provision the GKE cluster. For instructions on how to install xpk, see the xpk installation guide.
In Cloud Shell, you can install it with:
pip install xpk
Enable APIs
Run this command in Cloud Shell to enable all required APIs:
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3. Configure Environment Variables
To keep the commands in this codelab consistent, set up a few environment variables.
Create a file named env.sh and populate it with your configuration. You can use the following template:
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
Replace <YOUR_PROJECT_ID> and <YOUR_HF_TOKEN> with your actual values.
Source the file to load the variables into your current session:
source env.sh
4. Create GKE Cluster using XPK
In this step, you use xpk to provision a GKE cluster with Spot GPUs.
xpk is the AI Hypercomputer provisioning tool that simplifies GKE cluster creation for automated workloads. By specifying the device type and number of nodes, it creates the required VPC, subnet, and node pools.
Run the cluster creation command:
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
Wait for the cluster to be created. This can take several minutes.
Enable the RayOperator Add-on
Once the cluster is created, enable the RayOperator add-on to manage KubeRay clusters:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
Verify Lustre CSI Driver
XPK should enable the Lustre CSI driver automatically via the --enable-lustre-csi-driver flag. Verify it is enabled:
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
If it returns false, run the fallback enable command:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5. Provision Managed Lustre Instance
In this step, you create a Managed Service for Lustre instance. Lustre is a parallel file system that provides high throughput for checkpointing.
Allocate IP Range for Managed Services
Lustre requires a VPC peering connection to Google Managed Services. First, allocate a global IP range:
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
Establish VPC Peering
Connect your VPC to Service Networking:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
Create Lustre Instance
Now, create the Lustre instance. This command runs asynchronously.
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
Verify Lustre Status
It takes approximately 10-15 minutes for the Lustre instance to become ready. You can check the status with:
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
Wait until the state is ACTIVE before proceeding.
6. Deploy Ray Cluster on GKE
In this step, you will deploy a KubeRay cluster on your GKE nodes and mount the Lustre filesystem using a PersistentVolume (PV) and PersistentVolumeClaim (PVC).
Fetch Lustre IP
Before creating the volume, you need to get the mount point IP of your Lustre instance:
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
Create Lustre PV and PVC
Create a file named rl-lustre-volume.yaml using the following configuration. This defines how GKE connects to your Lustre instance.
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
Apply the volume configuration:
kubectl apply -f rl-lustre-volume.yaml
Create RayCluster Configuration
Create a file named ray-cluster.yaml. This specifies the KubeRay head and worker nodes, using the nvidia-b200 accelerator type and mounting the Lustre volume at /lustre.
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
Apply the Ray cluster configuration:
kubectl apply -f ray-cluster.yaml
Verify Cluster Status
Monitor the creation of the pods:
kubectl get pods -w
Wait until the head and worker pods are Running.
7. Submit Reinforcement Learning Workload
In this step, you will submit the NeMo-RL GRPO training job to your Ray cluster.
Connect to the Ray Dashboard
To submit jobs and view metrics, you need to connect to the Ray Dashboard. As the dashboard is in GKE, use port-forwarding to access it from Cloud Shell:
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
Create the Execution Script
Create a file named run_nemo_rl.sh. This script will be executed on the Ray cluster workers. We use cat << EOF to fill in the environment variables you set earlier.
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
Create Ray Ignore File
Create a .rayignore file to prevent Ray from uploading large or unnecessary directories:
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
Create Runtime Environment Configuration
Create a JSON file to pass environment variables to the Ray job:
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
Submit the Job
Use the Ray CLI to submit the job to the dashboard endpoint. If the ray command is not found in Cloud Shell, you can install it with pip install ray:
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
You will see logs streaming in your Cloud Shell terminal. The job will load the model, initialize the Ray workers, and begin the GRPO training loop.
8. Monitor Training Performance
In this step, you will observe the performance of the Lustre filesystem during training and checkpointing.
Check Training Logs
As the training progresses, you will see logs indicating that checkpoints are being saved to /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1. Notice that checkpointing happens asynchronously and does not block the Ray workers for very long.
To view the speed of checkpointing, look for log lines indicating saved checkpoints.
View Lustre Metrics in the Cloud Console
To see metrics for your Lustre instance:
- In the Google Cloud Console, search for Managed Service for Lustre.
- Click on your instance name (
rl-demo-gpu-lustre). - Click on the Monitoring tab.
Here you can observe:
- Throughput (Bytes/sec): See the spikes during checkpointing.
- Capacity: Monitor how much space is being consumed by checkpoints.
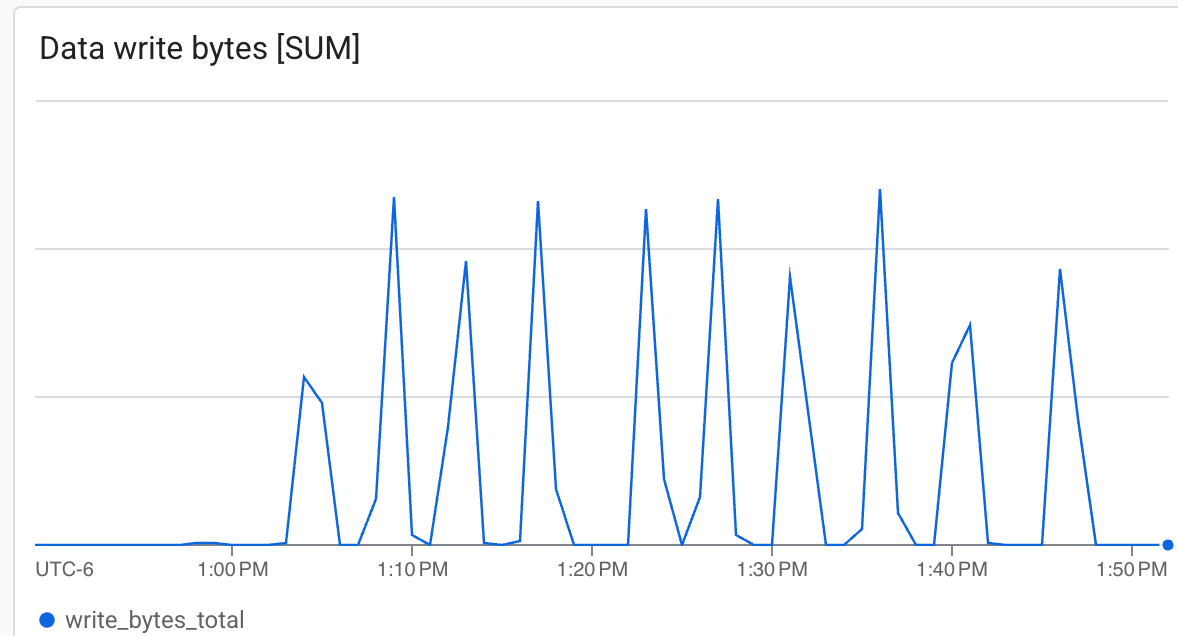 Lustre is capable of writing at very high speed, writing checkpoints in minimal time ab.
Lustre is capable of writing at very high speed, writing checkpoints in minimal time ab.
9. Clean Up Resources
Run the following commands in Cloud Shell to delete the resources created in this codelab.
Delete Managed Lustre Instance
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
Delete GKE Cluster using XPK
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
Clean up IP Aliases (Optional)
If you want to completely clean up the IP ranges created for VPC peering:
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
The resources will be deleted asynchronously. You can verify their status in the Cloud Console.
10. Congratulations
You have successfully completed the Scale Reinforcement Learning with GKE and Managed Lustre codelab!
What you've learned
- How to use
xpkto provision a GKE GPU cluster with Spot instances. - How to enable the Lustre CSI driver and RayOperator add-ons.
- How to provision a Google Cloud Managed Service for Lustre instance.
- How to deploy a KubeRay cluster and mount Lustre storage.
- How to submit a NeMo-RL GRPO training workload.
- How to observe storage performance during training.
Next steps
- Explore more NVIDIA NeMo-RL features.
- Learn more about Google Cloud AI Hypercomputer.
- Review the Managed Service for Lustre documentation.