
1. Introducción
Si prefieres ejecutar las secuencias de comandos empaquetadas directamente sin el instructivo paso a paso, puedes encontrarlas en el repositorio GoogleCloudPlatform/devrel-demos.
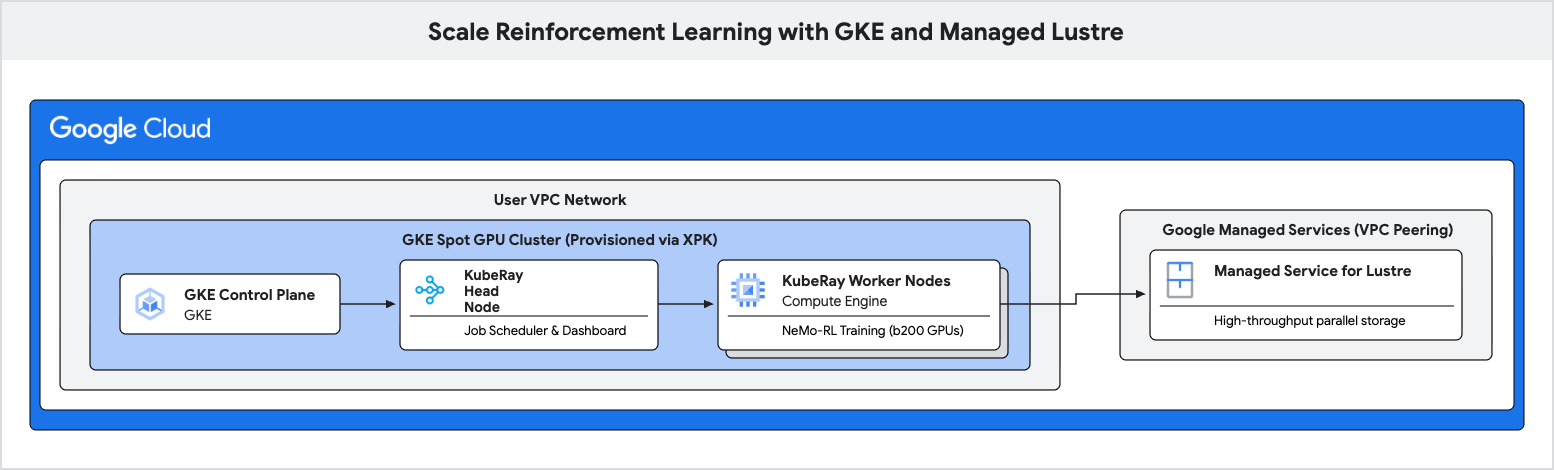
En este codelab, aprenderás a implementar una canalización de entrenamiento de alto rendimiento para el aprendizaje por refuerzo (RL) con Google Kubernetes Engine (GKE) y Managed Lustre.
Las cargas de trabajo de aprendizaje por refuerzo, en particular las que usan algoritmos como la optimización de políticas relativas grupales (GRPO), generan grandes cantidades de datos durante la "generación de experiencia" y requieren la creación de puntos de control frecuentes. El almacenamiento de objetos estándar puede causar cuellos de botella durante estas ráfagas de E/S, lo que deja inactivos los aceleradores costosos.
Usarás Managed Lustre, un sistema de archivos paralelos, para eliminar estos cuellos de botella y lograr una mayor capacidad de procesamiento de entrenamiento.
Actividades
- Configura las variables de entorno para un clúster de Ray basado en GPU.
- Aprovisiona un clúster de GPU Spot en GKE con la herramienta XPK.
- Crea una instancia de Managed Lustre.
- Implementa un clúster de KubeRay y activa el sistema de archivos Lustre.
- Envía una carga de trabajo de entrenamiento de NeMo-RL.
- Observa la alta capacidad de procesamiento y la baja latencia de los puntos de control con Cloud Monitoring.
Requisitos
- Un navegador web, como Chrome.
- Un proyecto de Google Cloud con facturación habilitada.
Este codelab está destinado a usuarios técnicos avanzados, ingenieros de plataformas y investigadores de IA que estén familiarizados con GKE y los conceptos de almacenamiento.
Duración total estimada: 45 a 60 minutos más 2 horas de tiempo de entrenamiento
2. Antes de comenzar
Cómo crear un proyecto de Google Cloud
- En la consola de Google Cloud, selecciona o crea un proyecto de Google Cloud.
- Asegúrate de que la facturación esté habilitada para tu proyecto de Cloud.
Inicie Cloud Shell
Cloud Shell es un entorno de línea de comandos que se ejecuta en Google Cloud y que viene precargado con las herramientas necesarias.
- Haz clic en Activar Cloud Shell en la parte superior de la consola de Google Cloud.
- Una vez que te conectes a Cloud Shell, verifica tu autenticación:
gcloud auth list - Confirma que tu proyecto esté configurado:
gcloud config get project - Si tu proyecto no está configurado como se espera, configúralo:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Instala XPK
En este codelab, se usa xpk para aprovisionar el clúster de GKE. Para obtener instrucciones sobre cómo instalar xpk, consulta la guía de instalación de xpk.
En Cloud Shell, puedes instalarlo con:
pip install xpk
Habilita las APIs
Ejecuta este comando en Cloud Shell para habilitar todas las APIs requeridas:
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3. Configura las variables de entorno
Para mantener la coherencia de los comandos en este codelab, configura algunas variables de entorno.
Crea un archivo llamado env.sh y propágalo con tu configuración. Puedes usar la siguiente plantilla:
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
Reemplaza <YOUR_PROJECT_ID> y <YOUR_HF_TOKEN> con tus valores reales.
Obtén el archivo para cargar las variables en tu sesión actual:
source env.sh
4. Crea un clúster de GKE con XPK
En este paso, usarás xpk para aprovisionar un clúster de GKE con GPU Spot.
xpk es la herramienta de aprovisionamiento de AI Hypercomputer que simplifica la creación de clústeres de GKE para cargas de trabajo automatizadas. Si especificas el tipo de dispositivo y la cantidad de nodos, se crean la VPC, la subred y los grupos de nodos requeridos.
Ejecuta el comando de creación del clúster:
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
Espera a que se cree el clúster. Esto puede tomar varios minutos.
Habilita el complemento RayOperator
Una vez que se cree el clúster, habilita el complemento RayOperator para administrar los clústeres de KubeRay:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
Verifica el controlador Lustre CSI
XPK debería habilitar el controlador Lustre CSI automáticamente a través de la marca --enable-lustre-csi-driver. Verifica que esté habilitado:
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
Si muestra false, ejecuta el comando de habilitación de resguardo:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5. Aprovisiona la instancia de Managed Lustre
En este paso, crearás un servicio administrado para la instancia de Lustre. Lustre es un sistema de archivos paralelos que proporciona una alta capacidad de procesamiento para la creación de puntos de control.
Asigna un rango de IP para los servicios administrados
Lustre requiere una conexión de intercambio de tráfico de VPC a los servicios administrados de Google. Primero, asigna un rango de IP global:
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
Establece el intercambio de tráfico de VPC
Conecta tu VPC a Service Networking:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
Crea una instancia de Lustre
Ahora, crea la instancia de Lustre. Este comando se ejecuta de forma asíncrona.
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
Verifica el estado de Lustre
La instancia de Lustre tarda aproximadamente 10 a 15 minutos en estar lista. Puedes verificar el estado con:
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
Espera hasta que el estado sea ACTIVE antes de continuar.
6. Implementa el clúster de Ray en GKE
En este paso, implementarás un clúster de KubeRay en tus nodos de GKE y activarás el sistema de archivos Lustre con un PersistentVolume (PV) y un PersistentVolumeClaim (PVC).
Recupera la IP de Lustre
Antes de crear el volumen, debes obtener la IP del punto de activación de tu instancia de Lustre:
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
Crea PV y PVC de Lustre
Crea un archivo llamado rl-lustre-volume.yaml con la siguiente configuración. Esto define cómo GKE se conecta a tu instancia de Lustre.
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
Aplica la configuración del volumen:
kubectl apply -f rl-lustre-volume.yaml
Crea la configuración de RayCluster
Crea un archivo llamado ray-cluster.yaml. Esto especifica los nodos principales y de trabajador de KubeRay, con el tipo de acelerador nvidia-b200 y la activación del volumen de Lustre en /lustre.
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
Aplica la configuración del clúster de Ray:
kubectl apply -f ray-cluster.yaml
Verifica el estado del clúster
Supervisa la creación de los pods:
kubectl get pods -w
Espera hasta que los pods principales y de trabajador estén Running.
7. Envía la carga de trabajo de aprendizaje por refuerzo
En este paso, enviarás el trabajo de entrenamiento de GRPO de NeMo-RL a tu clúster de Ray.
Conéctate al panel de Ray
Para enviar trabajos y ver métricas, debes conectarte al panel de Ray. Como el panel está en GKE, usa el reenvío de puertos para acceder a él desde Cloud Shell:
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
Crea la secuencia de comandos de ejecución
Crea un archivo llamado run_nemo_rl.sh. Esta secuencia de comandos se ejecutará en los trabajadores del clúster de Ray. Usamos cat << EOF para completar las variables de entorno que configuraste antes.
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
Crea el archivo de omisión de Ray
Crea un archivo .rayignore para evitar que Ray suba directorios grandes o innecesarios:
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
Crea la configuración del entorno de ejecución
Crea un archivo JSON para pasar variables de entorno al trabajo de Ray:
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
Envía el trabajo
Usa la CLI de Ray para enviar el trabajo al extremo del panel. Si no se encuentra el comando ray en Cloud Shell, puedes instalarlo con pip install ray:
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
Verás registros transmitidos en tu terminal de Cloud Shell. El trabajo cargará el modelo, inicializará los trabajadores de Ray y comenzará el bucle de entrenamiento de GRPO.
8. Supervisa el rendimiento del entrenamiento
En este paso, observarás el rendimiento del sistema de archivos Lustre durante el entrenamiento y la creación de puntos de control.
Consulta los registros de entrenamiento
A medida que avanza el entrenamiento, verás registros que indican que los puntos de control se guardan en /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1. Ten en cuenta que la creación de puntos de control se realiza de forma asíncrona y no bloquea a los trabajadores de Ray durante mucho tiempo.
Para ver la velocidad de la creación de puntos de control, busca líneas de registro que indiquen los puntos de control guardados.
Visualiza las métricas de Lustre en la consola de Cloud
Para ver las métricas de tu instancia de Lustre, haz lo siguiente:
- En la consola de Google Cloud, busca Servicio administrado para Lustre.
- Haz clic en el nombre de tu instancia (
rl-demo-gpu-lustre). - Haz clic en la pestaña Monitoring.
Aquí puedes observar lo siguiente:
- Capacidad de procesamiento (bytes/s): Observa los picos durante la creación de puntos de control.
- Capacidad: Supervisa cuánto espacio consumen los puntos de control.
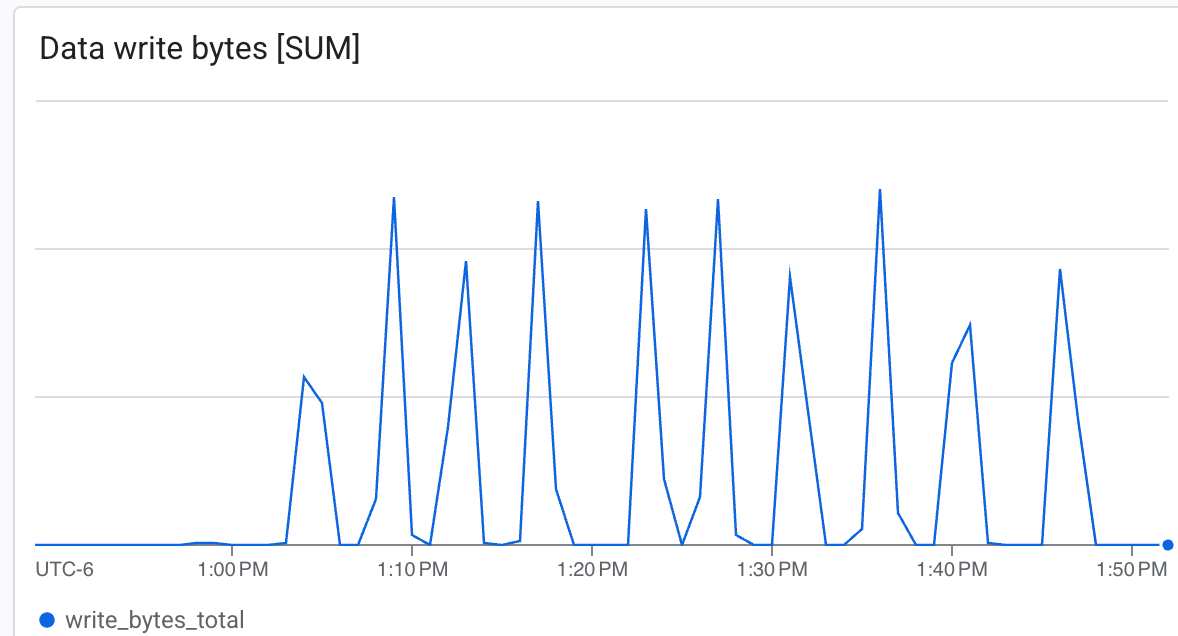 Lustre puede escribir a una velocidad muy alta y escribir puntos de control en un tiempo mínimo ab.
Lustre puede escribir a una velocidad muy alta y escribir puntos de control en un tiempo mínimo ab.
9. Limpia los recursos
Ejecuta los siguientes comandos en Cloud Shell para borrar los recursos creados en este codelab.
Borra la instancia de Managed Lustre
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
Borra el clúster de GKE con XPK
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
Limpia los alias de IP (opcional)
Si deseas limpiar por completo los rangos de IP creados para el intercambio de tráfico de VPC, haz lo siguiente:
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
Los recursos se borrarán de forma asíncrona. Puedes verificar su estado en la consola de Cloud.
10. Felicitaciones
Completaste correctamente el codelab Escala el aprendizaje por refuerzo con GKE y Managed Lustre.
Qué aprendiste
- Cómo usar
xpkpara aprovisionar un clúster de GPU de GKE con instancias Spot - Cómo habilitar el controlador Lustre CSI y los complementos de RayOperator
- Cómo aprovisionar un servicio administrado de Google Cloud para la instancia de Lustre
- Cómo implementar un clúster de KubeRay y activar el almacenamiento de Lustre
- Cómo enviar una carga de trabajo de entrenamiento de GRPO de NeMo-RL
- Cómo observar el rendimiento del almacenamiento durante el entrenamiento
Próximos pasos
- Explora más funciones de NVIDIA NeMo-RL.
- Obtén más información sobre AI Hypercomputer de Google Cloud.
- Revisa la documentación del servicio administrado para Lustre.