
۱. مقدمه
اگر ترجیح میدهید اسکریپتهای بستهبندیشده را مستقیماً و بدون آموزش گامبهگام اجرا کنید، میتوانید آنها را در مخزن GoogleCloudPlatform/devrel-demos پیدا کنید.
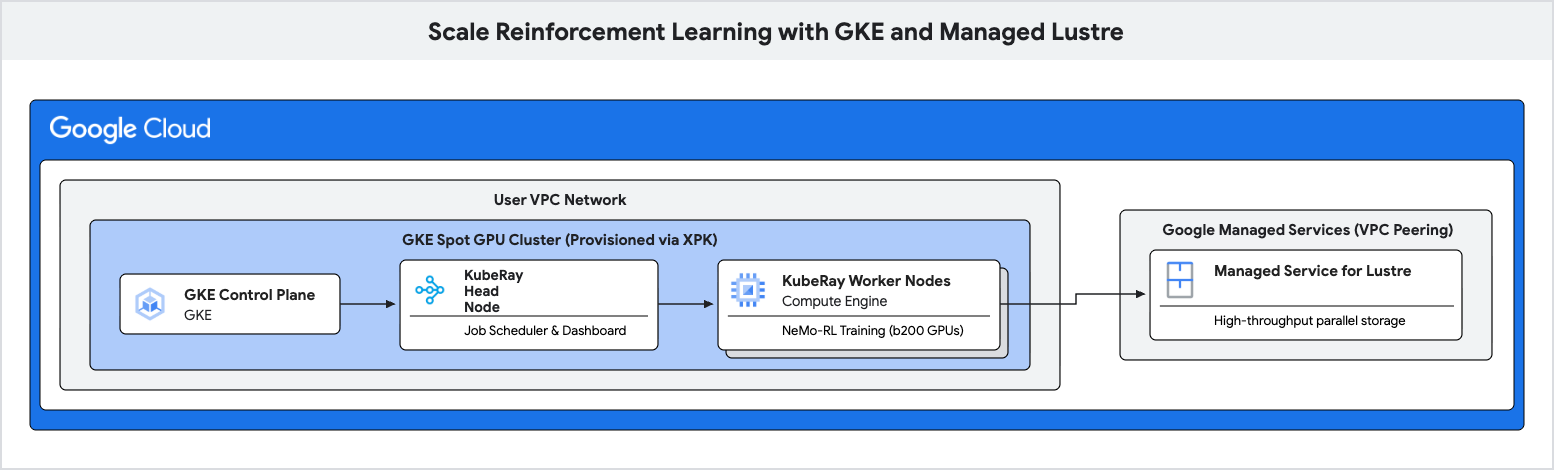
در این آزمایشگاه کد، شما یاد خواهید گرفت که چگونه یک خط لوله آموزشی با کارایی بالا برای یادگیری تقویتی (RL) با استفاده از موتور گوگل کوبرنتیز (GKE) و Managed Lustre مستقر کنید.
بارهای کاری یادگیری تقویتی، به ویژه آنهایی که از الگوریتمهایی مانند بهینهسازی سیاست نسبی گروهی (GRPO) استفاده میکنند، حجم عظیمی از دادهها را در طول "تولید تجربه" تولید میکنند و نیاز به بررسیهای مکرر دارند. ذخیرهسازی شیء استاندارد میتواند در طول این انفجارهای ورودی/خروجی باعث ایجاد گلوگاه شود و شتابدهندههای گرانقیمت را بیکار بگذارد.
شما از Managed Lustre ، یک سیستم فایل موازی، برای از بین بردن این گلوگاهها و دستیابی به توان عملیاتی بالاتر در آموزش استفاده خواهید کرد.
کاری که انجام خواهید داد
- متغیرهای محیطی را برای یک کلاستر Ray مبتنی بر GPU پیکربندی کنید.
- با استفاده از ابزار XPK، یک کلاستر پردازنده گرافیکی نقطهای (Spot GPU) روی GKE ایجاد کنید.
- یک نمونه Managed Lustre ایجاد کنید.
- یک کلاستر KubeRay را مستقر کرده و سیستم فایل Lustre را مانت کنید.
- حجم کار آموزشی NeMo-RL را ارسال کنید.
- با استفاده از Cloud Monitoring، شاهد توان عملیاتی بالا و تأخیر کم در Checkpointها باشید .
آنچه نیاز دارید
- یک مرورگر وب مانند کروم .
- یک پروژه گوگل کلود با قابلیت پرداخت.
این آزمایشگاه کد برای کاربران فنی پیشرفته، مهندسان پلتفرم و محققان هوش مصنوعی است که با GKE و مفاهیم ذخیرهسازی آشنا هستند.
مدت زمان تخمینی کل: ۴۵ تا ۶۰ دقیقه به علاوه ۲ ساعت زمان آموزش
۲. قبل از شروع
ایجاد یک پروژه ابری گوگل
- در کنسول گوگل کلود ، یک پروژه گوگل کلود انتخاب یا ایجاد کنید .
- مطمئن شوید که پرداخت برای پروژه ابری شما فعال است.
شروع پوسته ابری
Cloud Shell یک محیط خط فرمان است که در Google Cloud اجرا میشود و ابزارهای لازم از قبل روی آن بارگذاری شدهاند.
- روی فعال کردن Cloud Shell در بالای کنسول Google Cloud کلیک کنید.
- پس از اتصال به Cloud Shell، احراز هویت خود را تأیید کنید:
gcloud auth list - تأیید کنید که پروژه شما پیکربندی شده است:
gcloud config get project - اگر پروژه شما مطابق انتظار تنظیم نشده است، آن را تنظیم کنید:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
نصب XPK
این آزمایشگاه کد از xpk برای آمادهسازی کلاستر GKE استفاده میکند. برای دستورالعمل نحوه نصب xpk ، به راهنمای نصب xpk مراجعه کنید.
در Cloud Shell، میتوانید آن را با دستور زیر نصب کنید:
pip install xpk
فعال کردن APIها
برای فعال کردن تمام API های مورد نیاز، این دستور را در Cloud Shell اجرا کنید:
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
۳. پیکربندی متغیرهای محیطی
برای اینکه دستورات موجود در این codelab ثابت بمانند، چند متغیر محیطی تنظیم کنید.
یک فایل با نام env.sh ایجاد کنید و تنظیمات خود را در آن وارد کنید. میتوانید از الگوی زیر استفاده کنید:
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
<YOUR_PROJECT_ID> و <YOUR_HF_TOKEN> را با مقادیر واقعی خود جایگزین کنید.
فایل را برای بارگذاری متغیرها در جلسه فعلی خود، منبعیابی کنید:
source env.sh
۴. ایجاد خوشه GKE با استفاده از XPK
در این مرحله، شما از xpk برای آمادهسازی یک کلاستر GKE با پردازندههای گرافیکی Spot استفاده میکنید.
xpk ابزار آمادهسازی ابررایانه هوش مصنوعی است که ایجاد خوشه GKE را برای بارهای کاری خودکار ساده میکند. با مشخص کردن نوع دستگاه و تعداد گرهها، VPC، زیرشبکه و مجموعه گرههای مورد نیاز را ایجاد میکند.
دستور ایجاد خوشه را اجرا کنید:
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
صبر کنید تا خوشه ایجاد شود. این ممکن است چند دقیقه طول بکشد.
افزونه RayOperator را فعال کنید
پس از ایجاد خوشه، افزونه RayOperator را برای مدیریت خوشههای KubeRay فعال کنید:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
درایور Lustr CSI را تأیید کنید
XPK باید درایور Lustre CSI را به طور خودکار از طریق فلگ --enable-lustre-csi-driver فعال کند. تأیید کنید که فعال است:
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
اگر false را برگرداند، دستور fallback enable را اجرا کنید:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
۵. نمونهی لوستر مدیریتشدهی تأمین
در این مرحله، شما یک نمونه سرویس مدیریتشده برای Lustre ایجاد میکنید. Lustre یک سیستم فایل موازی است که توان عملیاتی بالایی را برای بررسیهای امنیتی فراهم میکند.
اختصاص محدوده IP برای سرویسهای مدیریتشده
لوستر به یک اتصال همتا به VPC با سرویسهای مدیریتشدهی گوگل نیاز دارد. ابتدا، یک محدودهی IP سراسری اختصاص دهید:
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
ایجاد VPC Peering
VPC خود را به شبکه سرویس متصل کنید:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
ایجاد نمونه لوستر
حالا، نمونه Lustre را ایجاد کنید. این دستور به صورت ناهمگام اجرا میشود.
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
وضعیت درخشش را تأیید کنید
تقریباً ۱۰ تا ۱۵ دقیقه طول میکشد تا نمونه لوستر آماده شود. میتوانید وضعیت را با موارد زیر بررسی کنید:
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
قبل از ادامه، صبر کنید تا ایالت ACTIVE شود.
۶. استقرار Ray Cluster روی GKE
در این مرحله، شما یک کلاستر KubeRay را روی گرههای GKE خود مستقر کرده و سیستم فایل Lustre را با استفاده از PersistentVolume (PV) و PersistentVolumeClaim (PVC) نصب خواهید کرد.
IP لوستر را دریافت کنید
قبل از ایجاد volume، باید IP نقطه اتصال نمونه Lustre خود را دریافت کنید:
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
ایجاد درخشندگی با PV و PVC
با استفاده از پیکربندی زیر، فایلی با نام rl-lustre-volume.yaml ایجاد کنید. این فایل نحوه اتصال GKE به نمونه Lustre شما را تعریف میکند.
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
پیکربندی حجم را اعمال کنید:
kubectl apply -f rl-lustre-volume.yaml
ایجاد پیکربندی RayCluster
فایلی با نام ray-cluster.yaml ایجاد کنید. این فایل، گرههای سر KubeRay و گرههای کارگر را با استفاده از نوع شتابدهنده nvidia-b200 و نصب درایو Lustre در /lustre مشخص میکند.
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
پیکربندی خوشه Ray را اعمال کنید:
kubectl apply -f ray-cluster.yaml
وضعیت خوشه را تأیید کنید
بر ایجاد پادها نظارت کنید:
kubectl get pods -w
صبر کنید تا پادهای سر و کارگر در Running باشند.
۷. ارسال حجم کار یادگیری تقویتی
در این مرحله، شما وظیفه آموزش NeMo-RL GRPO را به خوشه Ray خود ارسال خواهید کرد.
به داشبورد ری متصل شوید
برای ارسال کارها و مشاهده معیارها، باید به داشبورد Ray متصل شوید. از آنجایی که داشبورد در GKE است، برای دسترسی به آن از Cloud Shell از port-forwarding استفاده کنید:
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
ایجاد اسکریپت اجرایی
فایلی با نام run_nemo_rl.sh ایجاد کنید. این اسکریپت روی کارگران خوشه Ray اجرا خواهد شد. ما از cat << EOF برای پر کردن متغیرهای محیطی که قبلاً تنظیم کردهاید استفاده میکنیم.
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
ایجاد فایل نادیده گرفتن ری
برای جلوگیری از آپلود دایرکتوریهای بزرگ یا غیرضروری توسط Ray، یک فایل .rayignore ایجاد کنید:
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
ایجاد پیکربندی محیط زمان اجرا
یک فایل JSON برای ارسال متغیرهای محیطی به کار Ray ایجاد کنید:
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
ارسال شغل
از رابط خط فرمان Ray برای ارسال کار به نقطه پایانی داشبورد استفاده کنید. اگر دستور ray در Cloud Shell یافت نشد، میتوانید آن را با pip install ray نصب کنید:
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
شما گزارشها را در ترمینال Cloud Shell خود مشاهده خواهید کرد. این کار مدل را بارگذاری میکند، کارگران Ray را مقداردهی اولیه میکند و حلقه آموزش GRPO را آغاز میکند.
۸. عملکرد آموزشی را زیر نظر داشته باشید
در این مرحله، عملکرد سیستم فایل Lustre را در طول آموزش و بررسیهای اولیه مشاهده خواهید کرد.
بررسی گزارشهای آموزشی
با پیشرفت آموزش، گزارشهایی را مشاهده خواهید کرد که نشان میدهد Checkpointها در /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 ذخیره میشوند. توجه داشته باشید که Checkpointing به صورت ناهمگام اتفاق میافتد و Ray workerها را برای مدت طولانی مسدود نمیکند.
برای مشاهده سرعت بررسی نقاط کنترل، به دنبال خطوط گزارش که نشاندهنده نقاط کنترل ذخیره شده هستند، بگردید.
مشاهده معیارهای درخشندگی در کنسول ابری
برای مشاهدهی معیارهای مربوط به نمونهی Lustre خود:
- در کنسول گوگل کلود ، عبارت Managed Service for Lustre را جستجو کنید.
- روی نام نمونه خود (
rl-demo-gpu-lustre) کلیک کنید. - روی برگه نظارت کلیک کنید.
در اینجا میتوانید مشاهده کنید:
- توان عملیاتی (بایت بر ثانیه) : در طول بررسی نقاط، افزایش ناگهانی سرعت را مشاهده کنید.
- ظرفیت : میزان فضای اشغال شده توسط ایستگاههای بازرسی را کنترل کنید.
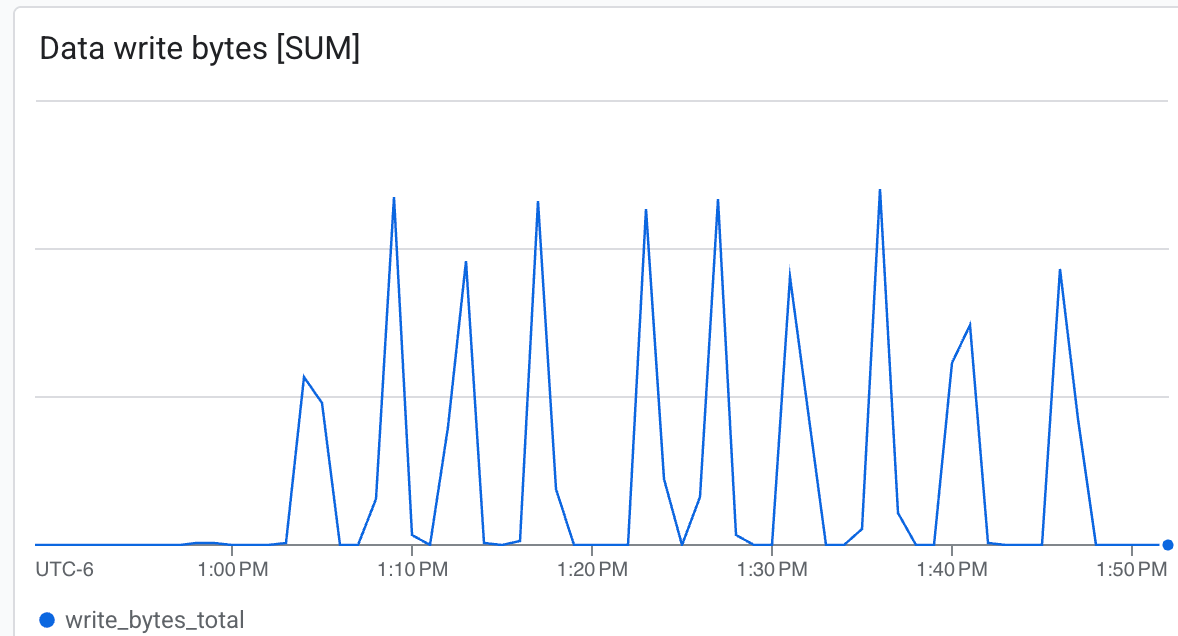 لوستر قادر به نوشتن با سرعت بسیار بالا است و نقاط کنترل را در حداقل زمان مینویسد .
لوستر قادر به نوشتن با سرعت بسیار بالا است و نقاط کنترل را در حداقل زمان مینویسد .
۹. پاکسازی منابع
دستورات زیر را در Cloud Shell اجرا کنید تا منابع ایجاد شده در این codelab حذف شوند.
حذف نمونه لوستر مدیریتشده
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
حذف خوشه GKE با استفاده از XPK
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
پاک کردن نامهای مستعار IP (اختیاری)
اگر میخواهید محدودههای IP ایجاد شده برای VPC peering را کاملاً پاک کنید:
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
منابع به صورت غیرهمزمان حذف خواهند شد. میتوانید وضعیت آنها را در کنسول ابری تأیید کنید.
۱۰. تبریک
شما با موفقیت یادگیری تقویتی مقیاس را با GKE و کدلب Managed Lustre به پایان رساندید!
آنچه آموختهاید
- نحوه استفاده از
xpkبرای آمادهسازی یک کلاستر GKE GPU با نمونههای Spot. - نحوه فعال کردن درایور Lustre CSI و افزونههای RayOperator.
- نحوه ارائه یک سرویس مدیریتشده ابری گوگل برای نمونه Lustre.
- نحوهی استقرار یک کلاستر KubeRay و نصب فضای ذخیرهسازی Lustre.
- نحوه ارسال حجم کار آموزشی NeMo-RL GRPO.
- نحوه مشاهده عملکرد ذخیرهسازی در طول آموزش.
مراحل بعدی
- ویژگیهای بیشتر NVIDIA NeMo-RL را بررسی کنید.
- درباره ابررایانه هوش مصنوعی گوگل کلود بیشتر بدانید.
- مستندات سرویس مدیریتشده برای لوستر (Lustre) را بررسی کنید.