
1. Introduction
Si vous préférez exécuter les scripts packagés directement sans le tutoriel pas à pas, vous les trouverez dans le dépôt GoogleCloudPlatform/devrel-demos.
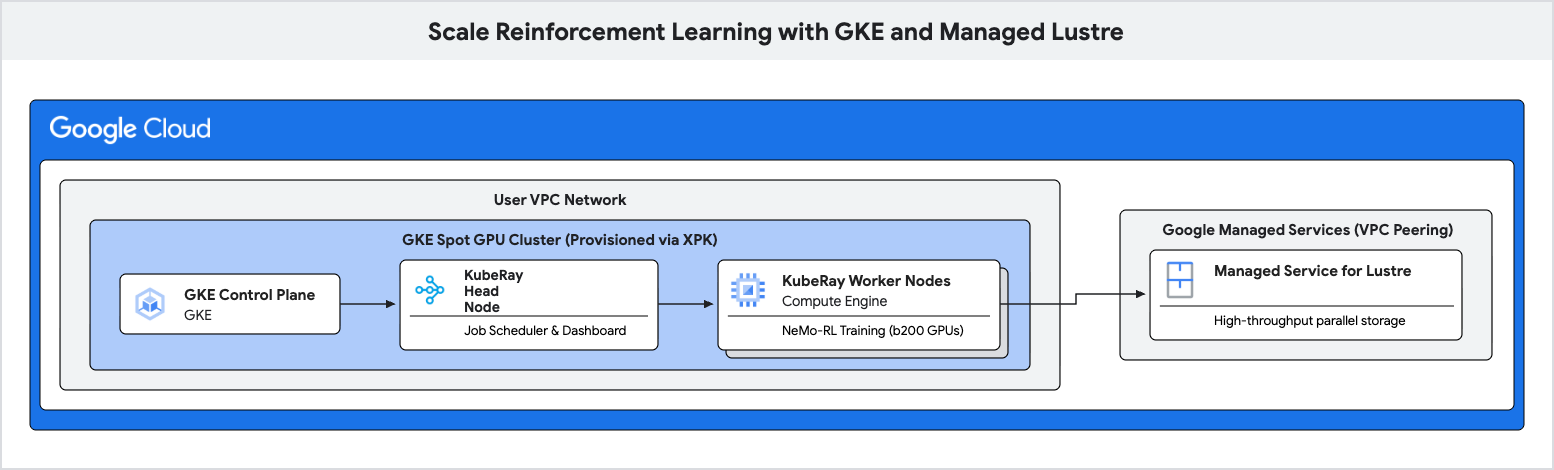
Dans cet atelier de programmation, vous allez apprendre à déployer un pipeline d'entraînement hautes performances pour l'apprentissage par renforcement (RL) à l'aide de Google Kubernetes Engine (GKE) et de Managed Lustre.
Les charges de travail d'apprentissage par renforcement, en particulier celles qui utilisent des algorithmes tels que l'optimisation des stratégies relatives aux groupes (GRPO), génèrent d'énormes quantités de données lors de la "génération d'expériences" et nécessitent des points de contrôle fréquents. Le stockage d'objets standard peut entraîner des goulots d'étranglement lors de ces pics d'E/S, laissant les accélérateurs coûteux inactifs.
Vous utiliserez Managed Lustre, un système de fichiers parallèle, pour éliminer ces goulots d'étranglement et obtenir un débit d'entraînement plus élevé.
Objectifs de l'atelier
- Configurez des variables d'environnement pour un cluster Ray basé sur GPU.
- Provisionnez un cluster GPU Spot sur GKE à l'aide de l'outil XPK.
- Créez une instance Managed Lustre.
- Déployez un cluster KubeRay et installez le système de fichiers Lustre.
- Envoyez une charge de travail d'entraînement NeMo-RL.
- Observez le débit élevé et la faible latence des points de contrôle à l'aide de Cloud Monitoring.
Prérequis
- Un navigateur Web tel que Chrome.
- Un projet Google Cloud avec facturation activée.
Cet atelier de programmation s'adresse aux utilisateurs techniques avancés, aux ingénieurs de plate-forme et aux chercheurs en IA qui connaissent les concepts de GKE et de stockage.
Durée totale estimée : 45 à 60 minutes plus 2 heures de formation
2. Avant de commencer
Créer un projet Google Cloud
- Dans la console Google Cloud, sélectionnez ou créez un projet Google Cloud.
- Assurez-vous que la facturation est activée pour votre projet Cloud.
Démarrer Cloud Shell
Cloud Shell est un environnement de ligne de commande exécuté dans Google Cloud et fourni avec les outils nécessaires.
- Cliquez sur Activer Cloud Shell en haut de la console Google Cloud.
- Une fois connecté à Cloud Shell, vérifiez votre authentification :
gcloud auth list - Vérifiez que votre projet est configuré :
gcloud config get project - Si votre projet n'est pas défini comme prévu, définissez-le :
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Installer XPK
Cet atelier de programmation utilise xpk pour provisionner le cluster GKE. Pour savoir comment installer xpk, consultez le guide d'installation de xpk.
Dans Cloud Shell, vous pouvez l'installer avec la commande suivante :
pip install xpk
Activer les API
Exécutez cette commande dans Cloud Shell pour activer toutes les API requises :
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3. Configurer les variables d'environnement
Pour que les commandes de cet atelier de programmation soient cohérentes, configurez quelques variables d'environnement.
Créez un fichier nommé env.sh et renseignez-le avec votre configuration. Vous pouvez utiliser le modèle suivant :
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
Remplacez <YOUR_PROJECT_ID> et <YOUR_HF_TOKEN> par vos valeurs réelles.
Importez le fichier pour charger les variables dans votre session actuelle :
source env.sh
4. Créer un cluster GKE à l'aide de XPK
Dans cette étape, vous allez utiliser xpk pour provisionner un cluster GKE avec des GPU Spot.
xpk est l'outil de provisionnement AI Hypercomputer qui simplifie la création de clusters GKE pour les charges de travail automatisées. En spécifiant le type d'appareil et le nombre de nœuds, il crée le VPC, le sous-réseau et les pools de nœuds requis.
Exécutez la commande de création du cluster :
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
Attendez que le cluster soit créé. Cette opération peut prendre plusieurs minutes.
Activer le module complémentaire RayOperator
Une fois le cluster créé, activez le module complémentaire RayOperator pour gérer les clusters KubeRay :
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
Valider le pilote CSI Lustre
XPK devrait activer automatiquement le pilote CSI Lustre via l'indicateur --enable-lustre-csi-driver. Vérifiez qu'il est activé :
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
Si la commande renvoie false, exécutez la commande d'activation de secours :
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5. Provisionner une instance Managed Lustre
Au cours de cette étape, vous allez créer une instance Managed Service for Lustre. Lustre est un système de fichiers parallèle qui offre un débit élevé pour la création de points de contrôle.
Allouer une plage d'adresses IP pour les services gérés
Lustre nécessite une connexion d'appairage VPC aux services gérés par Google. Commencez par allouer une plage d'adresses IP globales :
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
Établir l'appairage de VPC
Connectez votre VPC à Service Networking :
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
Créer une instance Lustre
Créez maintenant l'instance Lustre. Cette commande s'exécute de manière asynchrone.
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
Vérifier l'état de Lustre
La préparation de l'instance Lustre prend environ 10 à 15 minutes. Vous pouvez vérifier l'état à l'aide de la commande suivante :
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
Attendez que l'état soit ACTIVE avant de continuer.
6. Déployer un cluster Ray sur GKE
Dans cette étape, vous allez déployer un cluster KubeRay sur vos nœuds GKE et monter le système de fichiers Lustre à l'aide d'un PersistentVolume (PV) et d'un PersistentVolumeClaim (PVC).
Récupérer l'adresse IP Lustre
Avant de créer le volume, vous devez obtenir l'adresse IP du point de montage de votre instance Lustre :
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
Créer un PV et une PVC Lustre
Créez un fichier nommé rl-lustre-volume.yaml à l'aide de la configuration suivante. Cela définit la façon dont GKE se connecte à votre instance Lustre.
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
Appliquez la configuration du volume :
kubectl apply -f rl-lustre-volume.yaml
Créer une configuration RayCluster
Créez un fichier nommé ray-cluster.yaml. Cela spécifie les nœuds principaux et de calcul KubeRay, en utilisant le type d'accélérateur nvidia-b200 et en montant le volume Lustre à /lustre.
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
Appliquez la configuration du cluster Ray :
kubectl apply -f ray-cluster.yaml
Vérifier l'état du cluster
Surveillez la création des pods :
kubectl get pods -w
Attendez que les pods principaux et de nœuds de calcul soient Running.
7. Envoyer une charge de travail d'apprentissage par renforcement
Dans cette étape, vous allez envoyer la tâche d'entraînement GRPO NeMo-RL à votre cluster Ray.
Se connecter au tableau de bord Ray
Pour envoyer des jobs et afficher des métriques, vous devez vous connecter au tableau de bord Ray. Comme le tableau de bord se trouve dans GKE, utilisez le transfert de port pour y accéder depuis Cloud Shell :
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
Créer le script d'exécution
Créez un fichier nommé run_nemo_rl.sh. Ce script sera exécuté sur les nœuds de calcul du cluster Ray. Nous utilisons cat << EOF pour renseigner les variables d'environnement que vous avez définies précédemment.
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
Créer un fichier Ray Ignore
Créez un fichier .rayignore pour empêcher Ray d'importer des répertoires volumineux ou inutiles :
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
Créer une configuration d'environnement d'exécution
Créez un fichier JSON pour transmettre des variables d'environnement au job Ray :
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
Envoyer le job
Utilisez la CLI Ray pour envoyer le job au point de terminaison du tableau de bord. Si la commande ray est introuvable dans Cloud Shell, vous pouvez l'installer avec pip install ray :
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
Les journaux s'affichent en streaming dans votre terminal Cloud Shell. Le job chargera le modèle, initialisera les nœuds de calcul Ray et lancera la boucle d'entraînement GRPO.
8. Surveiller les performances d'entraînement
Au cours de cette étape, vous allez observer les performances du système de fichiers Lustre pendant l'entraînement et la création de points de contrôle.
Consulter les journaux d'entraînement
Au fur et à mesure de l'entraînement, des journaux indiquant que des points de contrôle sont enregistrés dans /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 s'affichent. Notez que la création de points de contrôle se fait de manière asynchrone et ne bloque pas les workers Ray très longtemps.
Pour afficher la vitesse de checkpointing, recherchez les lignes de journal indiquant les points de contrôle enregistrés.
Afficher les métriques Lustre dans la console Cloud
Pour afficher les métriques de votre instance Lustre :
- Dans la console Google Cloud, recherchez Managed Service for Lustre.
- Cliquez sur le nom de votre instance (
rl-demo-gpu-lustre). - Cliquez sur l'onglet Surveillance.
Vous pouvez y observer les éléments suivants :
- Débit (octets/s) : observez les pics pendant la création de points de contrôle.
- Capacité : surveillez l'espace consommé par les points de contrôle.
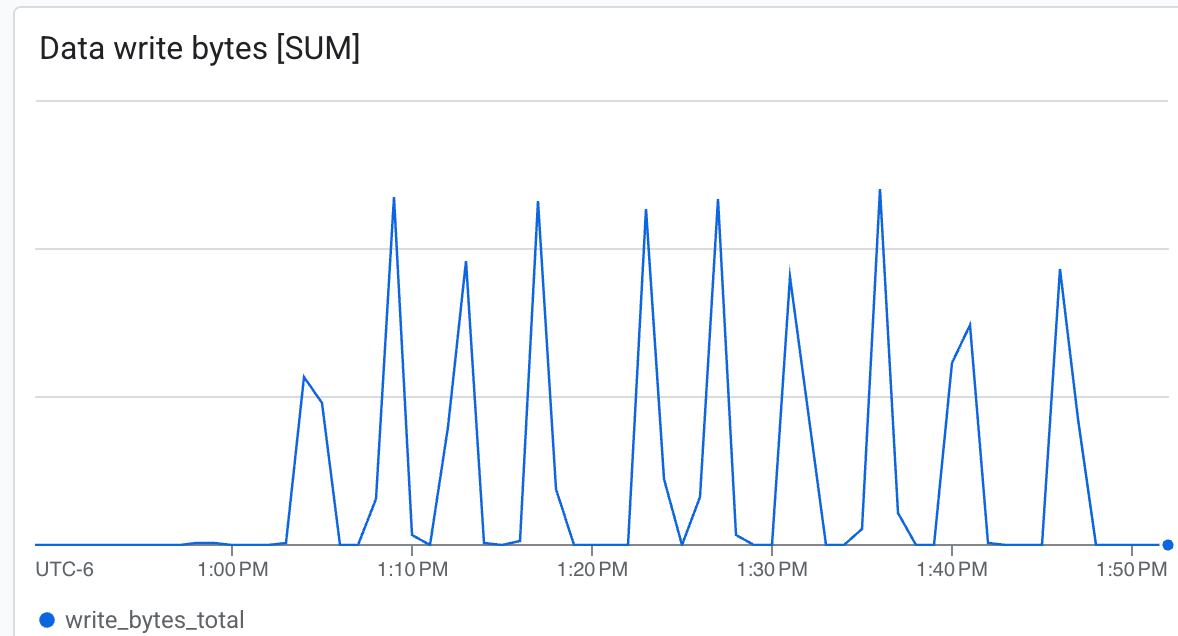 Lustre est capable d'écrire à très grande vitesse et d'écrire des points de contrôle en un minimum de temps ab.
Lustre est capable d'écrire à très grande vitesse et d'écrire des points de contrôle en un minimum de temps ab.
9. Nettoyer les ressources
Exécutez les commandes suivantes dans Cloud Shell pour supprimer les ressources créées dans cet atelier de programmation.
Supprimer une instance Managed Lustre
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
Supprimer un cluster GKE à l'aide de XPK
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
Nettoyer les alias d'adresse IP (facultatif)
Si vous souhaitez supprimer complètement les plages d'adresses IP créées pour l'appairage de VPC :
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
Les ressources seront supprimées de manière asynchrone. Vous pouvez vérifier leur état dans la console Cloud.
10. Félicitations
Vous avez terminé l'atelier de programmation Faire évoluer l'apprentissage par renforcement avec GKE et Lustre géré.
Connaissances acquises
- Utiliser
xpkpour provisionner un cluster de GPU GKE avec des instances Spot - Découvrez comment activer les modules complémentaires Lustre CSI Driver et RayOperator.
- Comment provisionner une instance Google Cloud Managed Service for Lustre.
- Découvrez comment déployer un cluster KubeRay et monter le stockage Lustre.
- Comment envoyer une charge de travail d'entraînement NeMo-RL GRPO.
- Comment observer les performances de stockage pendant l'entraînement.
Étapes suivantes
- Découvrez d'autres fonctionnalités de NVIDIA NeMo-RL.
- En savoir plus sur Google Cloud AI Hypercomputer
- Consultez la documentation du service géré pour Lustre.