
1. מבוא
אם אתם מעדיפים להפעיל את הסקריפטים הארוזים ישירות בלי להשתמש במדריך המפורט, תוכלו למצוא אותם במאגר GoogleCloudPlatform/devrel-demos.
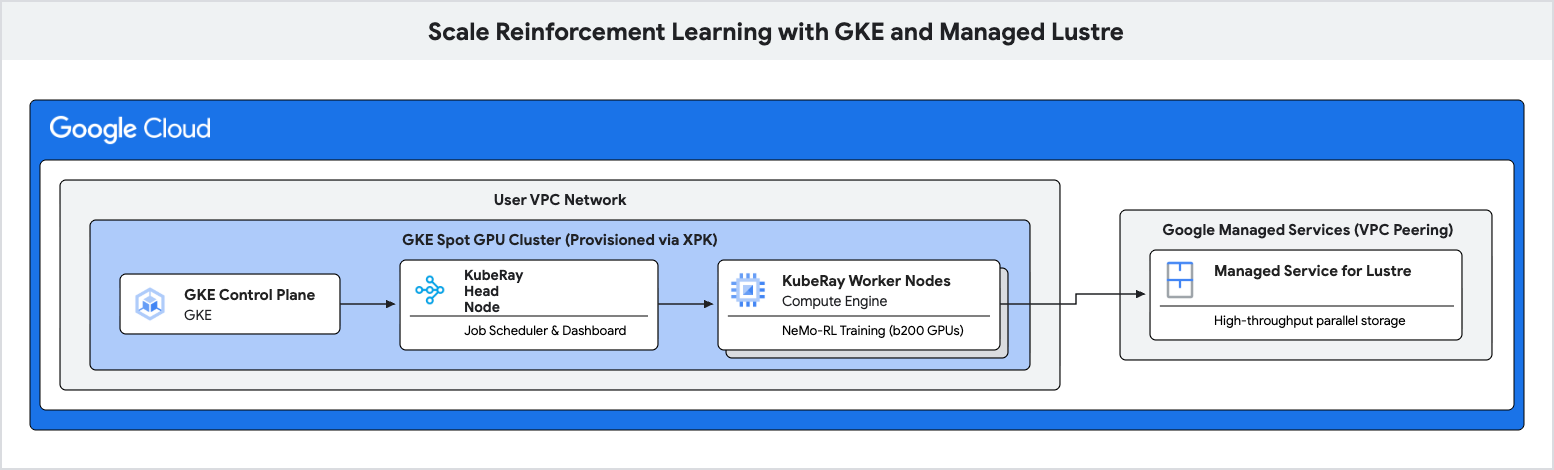
ב-Codelab הזה תלמדו איך לפרוס צינור עיבוד נתונים לאימון ביצועים גבוהים ללמידת חיזוק (RL) באמצעות Google Kubernetes Engine (GKE) ו-Managed Lustre.
עומסי עבודה של למידת חיזוק, במיוחד כאלה שמשתמשים באלגוריתמים כמו Group Relative Policy Optimization (GRPO), יוצרים כמויות עצומות של נתונים במהלך 'יצירת חוויה' ודורשים יצירת נקודות ביקורת תכופות. אחסון אובייקטים רגיל עלול לגרום לצווארי בקבוק במהלך פרצי קלט/פלט כאלה, ולהשאיר מאיצים יקרים ללא פעולה.
כדי למנוע את צווארי הבקבוק האלה ולהשיג תפוקת אימון גבוהה יותר, תשתמשו ב-Managed Lustre, מערכת קבצים מקבילה.
הפעולות שתבצעו:
- הגדרת משתני סביבה עבור אשכול Ray מבוסס-GPU.
- הקצאת אשכול GPU מסוג Spot ב-GKE באמצעות הכלי XPK.
- יוצרים מכונה של Managed Lustre.
- פורסים אשכול KubeRay ומטמיעים את מערכת הקבצים של Lustre.
- שליחה של עומס עבודה לאימון NeMo-RL.
- מעקב אחרי תפוקה גבוהה וחביון נמוך של נקודות ביקורת באמצעות Cloud Monitoring.
הדרישות
- דפדפן אינטרנט כמו Chrome.
- פרויקט ב-Google Cloud שהחיוב בו מופעל.
ה-Codelab הזה מיועד למשתמשים טכניים מתקדמים, למהנדסי פלטפורמות ולחוקרי AI שמכירים את GKE ואת מושגי האחסון.
משך כולל משוער: 45 עד 60 דקות בתוספת שעתיים של זמן הדרכה
2. לפני שמתחילים
יצירת פרויקט ב-Google Cloud
- במסוף Google Cloud, בוחרים פרויקט או יוצרים פרויקט חדש ב-Google Cloud.
- הקפידו לוודא שהחיוב מופעל בפרויקט שלכם ב-Cloud.
הפעלת Cloud Shell
Cloud Shell היא סביבת שורת פקודה שפועלת ב-Google Cloud, וכוללת מראש את הכלים הדרושים.
- לוחצים על Activate Cloud Shell בחלק העליון של מסוף Google Cloud.
- אחרי שמתחברים ל-Cloud Shell, מאמתים את האימות:
gcloud auth list - מוודאים שהפרויקט מוגדר:
gcloud config get project - אם הפרויקט לא מוגדר כמו שציפיתם, מגדירים אותו:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
התקנת XPK
ב-Codelab הזה משתמשים ב-xpk כדי להקצות את אשכול GKE. הוראות להתקנה של xpk מופיעות במדריך להתקנת xpk.
ב-Cloud Shell, אפשר להתקין אותו באמצעות הפקודה:
pip install xpk
הפעלת ממשקי ה-API
מריצים את הפקודה הזו ב-Cloud Shell כדי להפעיל את כל ממשקי ה-API הנדרשים:
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3. הגדרת משתני סביבה
כדי לשמור על עקביות הפקודות ב-codelab הזה, צריך להגדיר כמה משתני סביבה.
יוצרים קובץ בשם env.sh וממלאים אותו בהגדרות. אפשר להשתמש בתבנית הבאה:
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
מחליפים את <YOUR_PROJECT_ID> ואת <YOUR_HF_TOKEN> בערכים בפועל.
מריצים את הקובץ כדי לטעון את המשתנים לסשן הנוכחי:
source env.sh
4. יצירת אשכול GKE באמצעות XPK
בשלב הזה, משתמשים ב-xpk כדי להקצות אשכול GKE עם GPU מסוג Spot.
xpk הוא כלי להקצאת AI Hypercomputer שמפשט את יצירת אשכולות GKE לעומסי עבודה אוטומטיים. על ידי ציון סוג המכשיר ומספר הצמתים, המערכת יוצרת את ה-VPC, תת-הרשת ומאגרי הצמתים הנדרשים.
מריצים את הפקודה ליצירת האשכול:
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
ממתינים ליצירת האשכול. הפעולה יכולה להימשך כמה דקות.
הפעלת התוסף RayOperator
אחרי שיוצרים את האשכול, מפעילים את התוסף RayOperator כדי לנהל את אשכולות KubeRay:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
אימות מנהל התקן Lustre CSI
XPK אמור להפעיל את מנהל ההתקן של Lustre CSI באופן אוטומטי באמצעות הדגל --enable-lustre-csi-driver. מוודאים שהיא מופעלת:
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
אם הפקודה מחזירה false, מריצים את פקודת הגיבוי להפעלה:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5. הקצאת מכונה ב-Managed Lustre
בשלב הזה יוצרים מכונה ב-Managed Service for Lustre. Lustre היא מערכת קבצים מקבילה שמספקת תפוקה גבוהה ליצירת נקודות ביקורת.
הקצאת טווח כתובות IP לשירותים מנוהלים
כדי להשתמש ב-Lustre, צריך חיבור VPC peering לשירותים מנוהלים של Google. קודם כול, מקצים טווח IP גלובלי:
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
יצירת קישור בין רשתות VPC שכנות (peering)
חיבור ה-VPC ל-Service Networking:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
יצירת מכונת Lustre
עכשיו יוצרים את מכונת Lustre. הפקודה הזו מופעלת באופן אסינכרוני.
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
אימות הסטטוס של Lustre
תהליך ההכנה של מופע Lustre נמשך בערך 10-15 דקות. אפשר לבדוק את הסטטוס באמצעות:
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
לפני שממשיכים, צריך להמתין עד שהסטטוס יהיה ACTIVE.
6. פריסת אשכול Ray ב-GKE
בשלב הזה תפרסו אשכול KubeRay בצמתי GKE ותטענו את מערכת הקבצים של Lustre באמצעות PersistentVolume (PV) ו-PersistentVolumeClaim (PVC).
שליפת כתובת ה-IP של Lustre
לפני שיוצרים את אמצעי האחסון, צריך לקבל את כתובת ה-IP של נקודת הגישה של מופע Lustre:
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
יצירה של Lustre PV ו-PVC
יוצרים קובץ בשם rl-lustre-volume.yaml עם ההגדרות הבאות. ההגדרה הזו מגדירה איך GKE מתחבר למכונת Lustre.
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
החלת הגדרת עוצמת הקול:
kubectl apply -f rl-lustre-volume.yaml
יצירת הגדרת RayCluster
יוצרים קובץ בשם ray-cluster.yaml. הפקודה הזו מציינת את הצמתים הראשיים ואת צומתי העובדים ב-KubeRay, באמצעות סוג המאיץ nvidia-b200, ומטמיעה את נפח האחסון של Lustre ב-/lustre.
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
מחילים את ההגדרה של אשכול Ray:
kubectl apply -f ray-cluster.yaml
אימות סטטוס האשכול
עוקבים אחרי יצירת ה-Pods:
kubectl get pods -w
מחכים עד שהפודים של ה-head וה-worker יהיו Running.
7. שליחת עומס עבודה של למידת חיזוק
בשלב הזה, תגישו את משימת האימון של NeMo-RL GRPO לאשכול Ray.
התחברות ללוח הבקרה של Ray
כדי לשלוח משימות ולראות מדדים, צריך להתחבר ללוח הבקרה של Ray. מכיוון שהלוח נמצא ב-GKE, צריך להשתמש בהעברת פורטים כדי לגשת אליו מ-Cloud Shell:
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
יצירת סקריפט ההפעלה
יוצרים קובץ בשם run_nemo_rl.sh. הסקריפט הזה יופעל על העובדים של אשכול Ray. אנחנו משתמשים ב-cat << EOF כדי למלא את משתני הסביבה שהגדרתם קודם.
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
יצירת קובץ להתעלמות מ-Ray
כדי למנוע מ-Ray להעלות ספריות גדולות או לא נחוצות, יוצרים קובץ .rayignore:
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
יצירת הגדרה של סביבת זמן ריצה
יוצרים קובץ JSON כדי להעביר משתני סביבה לעבודת Ray:
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
שליחת המשרה
משתמשים ב-Ray CLI כדי לשלוח את העבודה לנקודת הקצה של לוח הבקרה. אם הפקודה ray לא נמצאת ב-Cloud Shell, אפשר להתקין אותה באמצעות pip install ray:
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
יומנים יועברו בסטרימינג לטרמינל של Cloud Shell. העבודה תטען את המודל, תפעיל את עובדי Ray ותתחיל את לולאת האימון של GRPO.
8. מעקב אחר ביצועי האימון
בשלב הזה, תעקבו אחרי הביצועים של מערכת הקבצים Lustre במהלך האימון והסימון של נקודות ביקורת.
בדיקת יומני האימון
במהלך האימון, יומנים יציינו שנקודות ביקורת נשמרות ב-/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1. שימו לב ששמירת נקודות הביקורת מתבצעת באופן אסינכרוני ולא חוסמת את תהליכי העבודה של Ray למשך זמן רב מדי.
כדי לראות את מהירות יצירת נקודות הבדיקה, מחפשים שורות ביומן שמציינות נקודות בדיקה שנשמרו.
צפייה במדדי Lustre ב-Cloud Console
כדי לראות את המדדים של מכונת Lustre:
- ב-מסוף Google Cloud, מחפשים את Managed Service for Lustre.
- לוחצים על שם המכונה (
rl-demo-gpu-lustre). - לוחצים על הכרטיסייה Monitoring (מעקב).
כאן אפשר לראות:
- קצב העברת נתונים (בייט לשנייה): אפשר לראות את העליות החדות במהלך יצירת נקודת ביקורת.
- קיבולת: מעקב אחרי נפח האחסון שמשמש לנקודות בקרה.
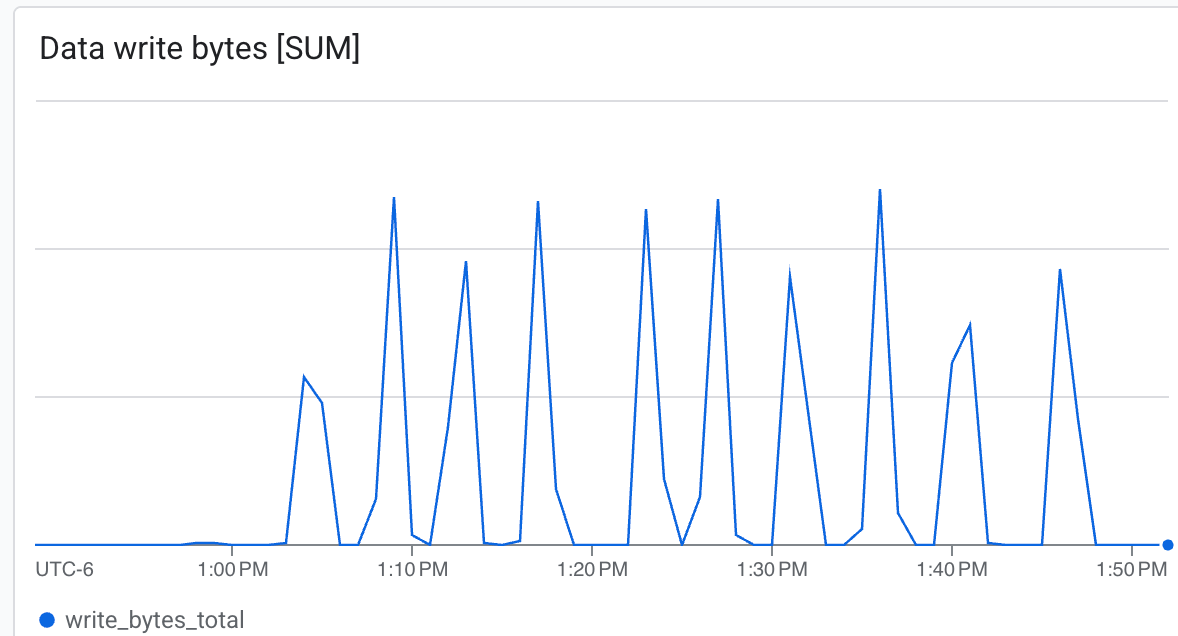 Lustre יכול לכתוב במהירות גבוהה מאוד, ולכתוב נקודות ביקורת בזמן מינימלי ab.
Lustre יכול לכתוב במהירות גבוהה מאוד, ולכתוב נקודות ביקורת בזמן מינימלי ab.
9. מחיקת משאבי הבדיקה
מריצים את הפקודות הבאות ב-Cloud Shell כדי למחוק את המשאבים שנוצרו ב-Codelab הזה.
מחיקה של מכונת Managed Lustre
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
מחיקת אשכול GKE באמצעות XPK
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
ניקוי של כינויי IP (אופציונלי)
אם רוצים לנקות לחלוטין את טווחי כתובות ה-IP שנוצרו עבור קישור בין רשתות VPC שכנות (peering):
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
המשאבים יימחקו באופן אסינכרוני. אפשר לבדוק את הסטטוס שלהם ב-Cloud Console.
10. מזל טוב
סיימת בהצלחה את ה-codelab Scale Reinforcement Learning with GKE and Managed Lustre.
מה למדתם
- איך משתמשים ב-
xpkכדי להקצות אשכול GPU ב-GKE עם מופעי Spot. - איך מפעילים את התוספים Lustre CSI driver ו-RayOperator.
- איך להקצות מופע של שירות מנוהל של Google Cloud ל-Lustre.
- איך פורסים אשכול KubeRay וטוענים אחסון Lustre.
- איך שולחים עומס עבודה לאימון של NeMo-RL GRPO.
- איך בודקים את ביצועי האחסון במהלך האימון.