
1. परिचय
अगर आपको चरण-दर-चरण दिए गए ट्यूटोरियल के बिना, सीधे तौर पर पैकेज की गई स्क्रिप्ट को चलाना है, तो उन्हें GoogleCloudPlatform/devrel-demos रिपॉज़िटरी में देखा जा सकता है.
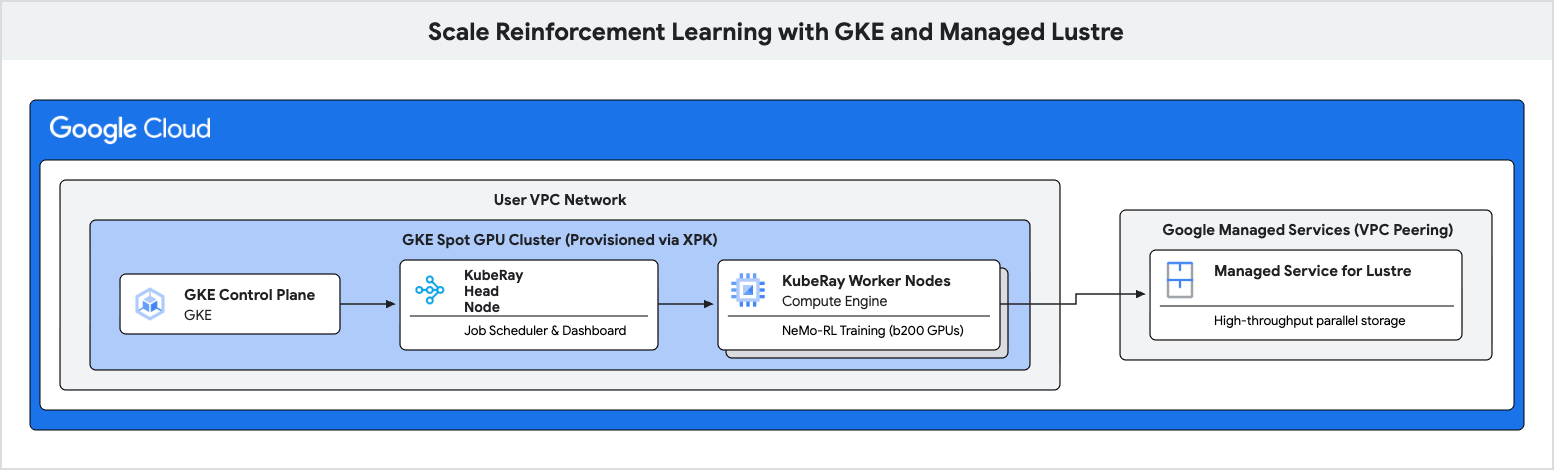
इस कोडलैब में, आपको Google Kubernetes Engine (GKE) और Managed Lustre का इस्तेमाल करके, रीइन्फ़ोर्समेंट लर्निंग (आरएल) के लिए, ज़्यादा परफ़ॉर्मेंस वाली ट्रेनिंग पाइपलाइन को डिप्लॉय करने का तरीका बताया जाएगा.
रीइन्फ़ोर्समेंट लर्निंग वर्कलोड, खास तौर पर ग्रुप रिलेटिव पॉलिसी ऑप्टिमाइज़ेशन (जीआरपीओ) जैसे एल्गोरिदम का इस्तेमाल करने वाले वर्कलोड, "एक्सपीरियंस जनरेशन" के दौरान बहुत ज़्यादा डेटा जनरेट करते हैं. साथ ही, इन्हें बार-बार चेकपॉइंट करने की ज़रूरत होती है. स्टैंडर्ड ऑब्जेक्ट स्टोरेज की वजह से, इन I/O बस्ट के दौरान परफ़ॉर्मेंस में रुकावट आ सकती है. इससे महंगे ऐक्सलरेटर का इस्तेमाल नहीं हो पाता.
इन समस्याओं को दूर करने और ट्रेनिंग के थ्रूपुट को बढ़ाने के लिए, Managed Lustre का इस्तेमाल किया जाएगा. यह एक पैरलल फ़ाइल सिस्टम है.
आपको क्या करना होगा
- जीपीयू पर आधारित Ray क्लस्टर के लिए, एनवायरमेंट वैरिएबल कॉन्फ़िगर करें.
- XPK टूल का इस्तेमाल करके, GKE पर स्पॉट जीपीयू क्लस्टर सेट अप करें.
- Managed Lustre इंस्टेंस बनाएं.
- KubeRay क्लस्टर डिप्लॉय करें और Lustre फ़ाइल सिस्टम को माउंट करें.
- NeMo-RL ट्रेनिंग वर्कलोड सबमिट करें.
- Cloud Monitoring का इस्तेमाल करके, ज़्यादा थ्रूपुट और कम चेकपॉइंट लेटेंसी देखें.
आपको किन चीज़ों की ज़रूरत होगी
- कोई वेब ब्राउज़र, जैसे कि Chrome.
- बिलिंग की सुविधा वाला Google Cloud प्रोजेक्ट.
यह कोडलैब, ऐडवांस टेक्निकल यूज़र, प्लैटफ़ॉर्म इंजीनियर, और एआई रिसर्चर के लिए है. इन्हें GKE और स्टोरेज के कॉन्सेप्ट के बारे में जानकारी है.
कुल अनुमानित अवधि: 45 से 60 मिनट और दो घंटे की ट्रेनिंग
2. शुरू करने से पहले
Google Cloud प्रोजेक्ट बनाना
- Google Cloud Console में जाकर, Google Cloud प्रोजेक्ट चुनें या बनाएं.
- पक्का करें कि आपके Cloud प्रोजेक्ट के लिए बिलिंग चालू हो.
Cloud Shell शुरू करना
Cloud Shell, Google Cloud में चलने वाला एक कमांड-लाइन एनवायरमेंट है. इसमें ज़रूरी टूल पहले से लोड होते हैं.
- Google Cloud कंसोल में सबसे ऊपर मौजूद, Cloud Shell चालू करें पर क्लिक करें.
- Cloud Shell से कनेक्ट होने के बाद, अपने क्रेडेंशियल की पुष्टि करें:
gcloud auth list - पुष्टि करें कि आपका प्रोजेक्ट कॉन्फ़िगर किया गया है:
gcloud config get project - अगर आपका प्रोजेक्ट उम्मीद के मुताबिक सेट नहीं है, तो इसे सेट करें:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
XPK इंस्टॉल करना
इस कोडलैब में, GKE क्लस्टर को प्रोविज़न करने के लिए xpk का इस्तेमाल किया जाता है. xpk इंस्टॉल करने के निर्देशों के लिए, xpk इंस्टॉल करने से जुड़ी गाइड देखें.
Cloud Shell में, इसे इस कमांड से इंस्टॉल किया जा सकता है:
pip install xpk
एपीआई चालू करें
सभी ज़रूरी एपीआई चालू करने के लिए, Cloud Shell में यह निर्देश चलाएं:
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3. एनवायरमेंट वैरिएबल कॉन्फ़िगर करना
इस कोडलैब में दिए गए निर्देशों को एक जैसा रखने के लिए, कुछ एनवायरमेंट वैरिएबल सेट अप करें.
env.sh नाम की फ़ाइल बनाएं और उसमें अपना कॉन्फ़िगरेशन डालें. इस टेंप्लेट का इस्तेमाल किया जा सकता है:
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
<YOUR_PROJECT_ID> और <YOUR_HF_TOKEN> को अपनी असल वैल्यू से बदलें.
अपने मौजूदा सेशन में वैरिएबल लोड करने के लिए, फ़ाइल को सोर्स करें:
source env.sh
4. XPK का इस्तेमाल करके GKE क्लस्टर बनाना
इस चरण में, स्पॉट जीपीयू के साथ GKE क्लस्टर सेट अप करने के लिए, xpk का इस्तेमाल किया जाता है.
xpk, एआई हाइपरकंप्यूटर प्रोविज़निंग टूल है. यह अपने-आप होने वाले वर्कलोड के लिए, GKE क्लस्टर बनाने की प्रोसेस को आसान बनाता है. डिवाइस का टाइप और नोड की संख्या तय करने पर, यह ज़रूरी वीपीसी, सबनेट, और नोड पूल बनाता है.
क्लस्टर बनाने की कमांड चलाएं:
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
क्लस्टर बनने तक इंतज़ार करें. इसमें कुछ मिनट लग सकते हैं.
RayOperator ऐड-ऑन चालू करना
क्लस्टर बन जाने के बाद, KubeRay क्लस्टर मैनेज करने के लिए RayOperator ऐड-ऑन चालू करें:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
Lustre CSI ड्राइवर की पुष्टि करना
XPK को --enable-lustre-csi-driver फ़्लैग के ज़रिए, Lustre CSI ड्राइवर को अपने-आप चालू करना चाहिए. पुष्टि करें कि यह सुविधा चालू है:
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
अगर यह false दिखाता है, तो फ़ॉलबैक को चालू करने वाली कमांड चलाएं:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5. Managed Lustre इंस्टेंस को प्रोविज़न करना
इस चरण में, Managed Service for Lustre इंस्टेंस बनाया जाता है. Lustre, एक पैरलल फ़ाइल सिस्टम है. यह चेकपॉइंटिंग के लिए हाई थ्रूपुट उपलब्ध कराता है.
मैनेज की जा रही सेवाओं के लिए आईपी रेंज असाइन करना
Lustre को Google की मैनेज की गई सेवाओं से कनेक्ट करने के लिए, वीपीसी पियरिंग कनेक्शन की ज़रूरत होती है. सबसे पहले, ग्लोबल आईपी रेंज असाइन करें:
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
VPC पीयरिंग सेट अप करना
अपने वीपीसी को सर्विस नेटवर्किंग से कनेक्ट करें:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
Lustre इंस्टेंस बनाना
अब, Lustre इंस्टेंस बनाएं. यह निर्देश एसिंक्रोनस तरीके से काम करता है.
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
Lustre के स्टेटस की पुष्टि करना
Lustre इंस्टेंस को तैयार होने में करीब 10 से 15 मिनट लगते हैं. इनकी मदद से स्टेटस देखा जा सकता है:
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
आगे बढ़ने से पहले, ACTIVE होने तक इंतज़ार करें.
6. GKE पर Ray क्लस्टर डिप्लॉय करना
इस चरण में, आपको अपने GKE नोड पर KubeRay क्लस्टर डिप्लॉय करना होगा. साथ ही, PersistentVolume (PV) और PersistentVolumeClaim (PVC) का इस्तेमाल करके Lustre फ़ाइल सिस्टम को माउंट करना होगा.
Lustre का आईपी पता फ़ेच करना
वॉल्यूम बनाने से पहले, आपको अपने Lustre इंस्टेंस का माउंट पॉइंट आईपी पता करना होगा:
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
Lustre PV और PVC बनाना
नीचे दिए गए कॉन्फ़िगरेशन का इस्तेमाल करके, rl-lustre-volume.yaml नाम की फ़ाइल बनाएं. इससे यह तय होता है कि GKE, आपके Lustre इंस्टेंस से कैसे कनेक्ट होता है.
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
वॉल्यूम कॉन्फ़िगरेशन लागू करें:
kubectl apply -f rl-lustre-volume.yaml
RayCluster कॉन्फ़िगरेशन बनाना
ray-cluster.yaml नाम की फ़ाइल बनाएं. इससे KubeRay के हेड और वर्कर नोड के बारे में पता चलता है. इसमें nvidia-b200 एक्सेलरेटर टाइप का इस्तेमाल किया जाता है और Lustre वॉल्यूम को /lustre पर माउंट किया जाता है.
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
Ray क्लस्टर कॉन्फ़िगरेशन लागू करें:
kubectl apply -f ray-cluster.yaml
क्लस्टर के स्टेटस की पुष्टि करना
पॉड बनने की प्रोसेस को मॉनिटर करें:
kubectl get pods -w
जब तक हेड और वर्कर पॉड Running न हो जाएं, तब तक इंतज़ार करें.
7. रीइन्फ़ोर्समेंट लर्निंग वर्कलोड सबमिट करना
इस चरण में, आपको NeMo-RL GRPO ट्रेनिंग जॉब को अपने Ray क्लस्टर पर सबमिट करना होगा.
Ray Dashboard से कनेक्ट करना
जॉब सबमिट करने और मेट्रिक देखने के लिए, आपको Ray डैशबोर्ड से कनेक्ट करना होगा. डैशबोर्ड GKE में है. इसलिए, इसे Cloud Shell से ऐक्सेस करने के लिए पोर्ट-फ़ॉरवर्डिंग का इस्तेमाल करें:
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
एक्ज़ीक्यूशन स्क्रिप्ट बनाना
run_nemo_rl.sh नाम की फ़ाइल बनाएं. यह स्क्रिप्ट, Ray क्लस्टर वर्कर पर एक्ज़ीक्यूट की जाएगी. हम cat << EOF का इस्तेमाल करके, आपके सेट किए गए एनवायरमेंट वैरिएबल भरते हैं.
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
Ray Ignore फ़ाइल बनाना
बड़ी या गैर-ज़रूरी डायरेक्ट्री को अपलोड करने से Ray को रोकने के लिए, .rayignore फ़ाइल बनाएं:
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
रनटाइम एनवायरमेंट कॉन्फ़िगरेशन बनाना
Ray जॉब को एनवायरमेंट वैरिएबल पास करने के लिए, एक JSON फ़ाइल बनाएं:
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
नौकरी का विज्ञापन सबमिट करना
जॉब को डैशबोर्ड एंडपॉइंट पर सबमिट करने के लिए, Ray CLI का इस्तेमाल करें. अगर Cloud Shell में ray निर्देश नहीं मिलता है, तो इसे pip install ray की मदद से इंस्टॉल किया जा सकता है:
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
आपको Cloud Shell टर्मिनल में लॉग स्ट्रीम होते हुए दिखेंगे. यह जॉब, मॉडल को लोड करेगी, Ray वर्कर को शुरू करेगी, और GRPO ट्रेनिंग लूप शुरू करेगी.
8. ट्रेनिंग की परफ़ॉर्मेंस को मॉनिटर करना
इस चरण में, ट्रेनिंग और चेकपॉइंटिंग के दौरान Lustre फ़ाइल सिस्टम की परफ़ॉर्मेंस देखी जाएगी.
ट्रेनिंग के लॉग देखना
ट्रेनिंग के दौरान, आपको ऐसे लॉग दिखेंगे जिनसे पता चलेगा कि चेकपॉइंट /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 में सेव किए जा रहे हैं. ध्यान दें कि चेकपॉइंटिंग एसिंक्रोनस तरीके से होती है और इससे Ray वर्कर लंबे समय तक ब्लॉक नहीं होते.
चेकपॉइंटिंग की स्पीड देखने के लिए, उन लॉग लाइनों को देखें जिनमें सेव किए गए चेकपॉइंट के बारे में बताया गया हो.
Cloud Console में Lustre मेट्रिक देखना
अपने Lustre इंस्टेंस के लिए मेट्रिक देखने के लिए:
- Google Cloud Console में, Managed Service for Lustre खोजें.
- अपने इंस्टेंस के नाम (
rl-demo-gpu-lustre) पर क्लिक करें. - निगरानी टैब पर क्लिक करें.
यहां आपको यह जानकारी दिखेगी:
- थ्रूपुट (बाइट/सेकंड): चेकपॉइंटिंग के दौरान स्पाइक देखें.
- क्षमता: देखें कि चेकपॉइंट कितना स्टोरेज इस्तेमाल कर रहे हैं.
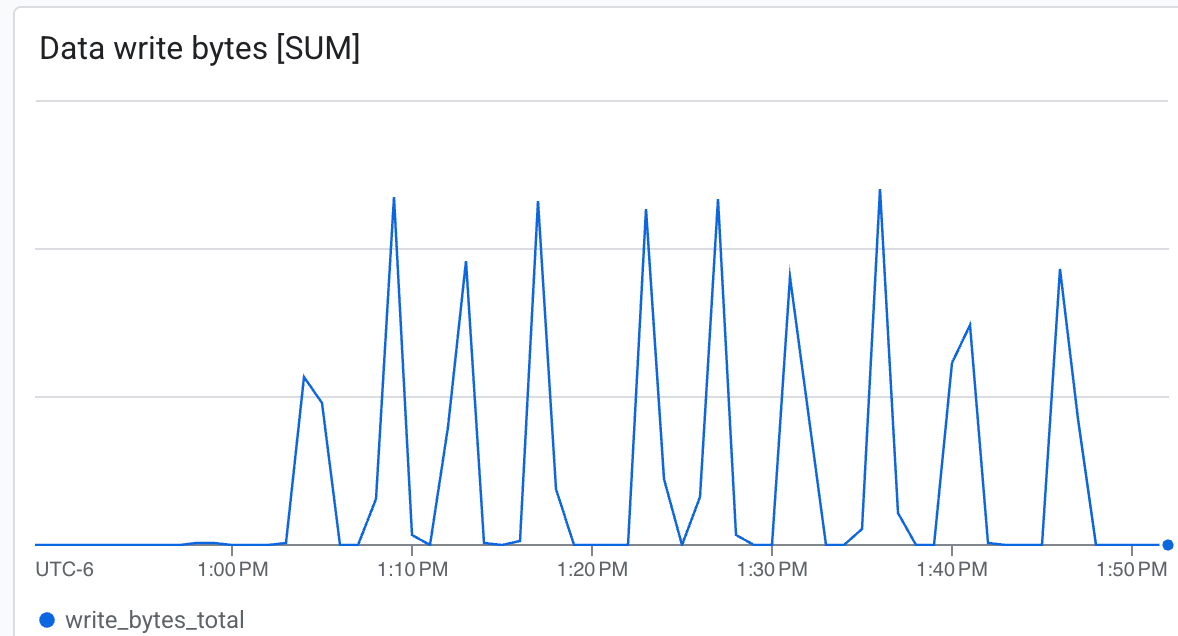 Lustre बहुत तेज़ी से लिख सकता है. साथ ही, यह कम समय में चेकपॉइंट लिख सकता है.
Lustre बहुत तेज़ी से लिख सकता है. साथ ही, यह कम समय में चेकपॉइंट लिख सकता है.
9. संसाधन मिटाएं
इस कोडलैब में बनाए गए संसाधनों को मिटाने के लिए, Cloud Shell में ये कमांड चलाएं.
मैनेज किए गए Lustre इंस्टेंस को मिटाना
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
XPK का इस्तेमाल करके GKE क्लस्टर मिटाना
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
आईपी पतों के उपनामों को हटाना (ज़रूरी नहीं)
अगर आपको वीपीसी पियरिंग के लिए बनाई गई आईपी रेंज को पूरी तरह से मिटाना है, तो:
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
संसाधन एसिंक्रोनस तरीके से मिटाए जाएंगे. Cloud Console में जाकर, उनके स्टेटस की पुष्टि की जा सकती है.
10. बधाई हो
आपने GKE और मैनेज किए गए Lustre की मदद से, रीइन्फ़ोर्समेंट लर्निंग को स्केल करना कोडलैब पूरा कर लिया है!
आपको क्या सीखने को मिला
- स्पॉट इंस्टेंस के साथ GKE GPU क्लस्टर को प्रोविज़न करने के लिए,
xpkका इस्तेमाल कैसे करें. - Lustre CSI ड्राइवर और RayOperator ऐड-ऑन को चालू करने का तरीका.
- Google Cloud Managed Service for Lustre इंस्टेंस को कैसे सेट अप करें.
- KubeRay क्लस्टर को डिप्लॉय करने और Lustre स्टोरेज को माउंट करने का तरीका.
- NeMo-RL GRPO ट्रेनिंग वर्कलोड सबमिट करने का तरीका.
- ट्रेनिंग के दौरान स्टोरेज की परफ़ॉर्मेंस को मॉनिटर करने का तरीका.
अगले चरण
- NVIDIA NeMo-RL की अन्य सुविधाओं के बारे में जानें.
- Google Cloud AI Hypercomputer के बारे में ज़्यादा जानें.
- Managed Service for Lustre के दस्तावेज़ पढ़ें.