
1. Pengantar
Jika lebih suka menjalankan skrip yang dikemas secara langsung tanpa tutorial langkah demi langkah, Anda dapat menemukannya di repositori GoogleCloudPlatform/devrel-demos.
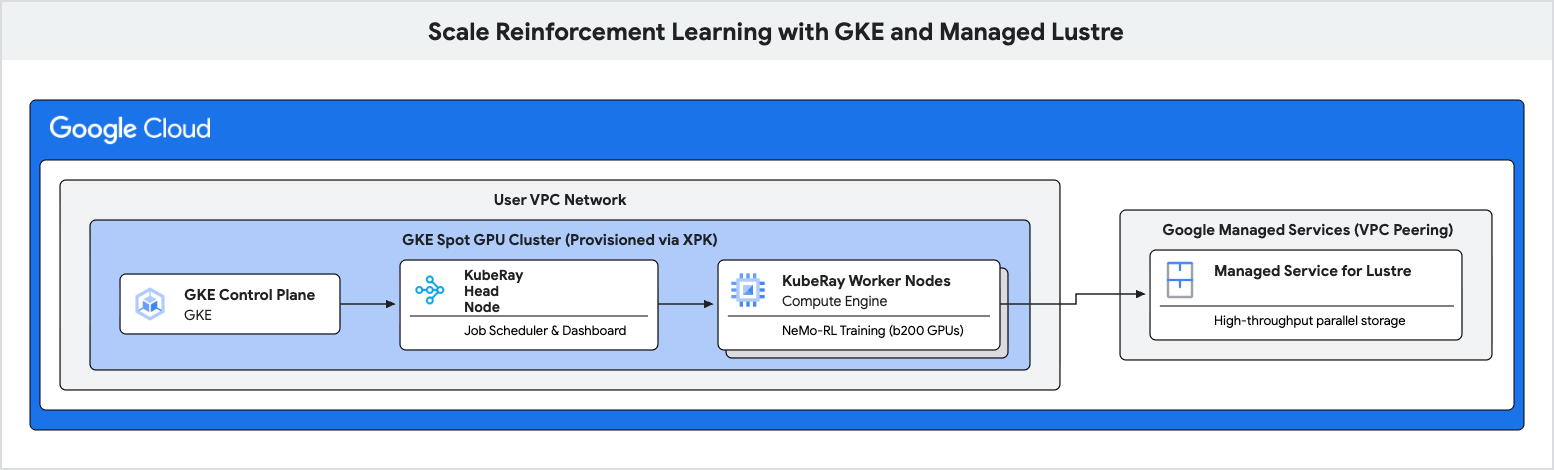
Dalam codelab ini, Anda akan mempelajari cara men-deploy pipeline pelatihan berperforma tinggi untuk Reinforcement Learning (RL) menggunakan Google Kubernetes Engine (GKE) dan Managed Lustre.
Beban kerja Reinforcement Learning, terutama yang menggunakan algoritma seperti Group Relative Policy Optimization (GRPO), menghasilkan data dalam jumlah besar selama "Pembuatan Pengalaman" dan memerlukan pembuatan titik pemeriksaan yang sering. Penyimpanan objek standar dapat menyebabkan hambatan selama lonjakan I/O ini, sehingga akselerator yang mahal menjadi tidak digunakan.
Anda akan menggunakan Managed Lustre, sistem file paralel, untuk menghilangkan hambatan ini dan mencapai throughput pelatihan yang lebih tinggi.
Yang akan Anda lakukan
- Konfigurasi variabel lingkungan untuk cluster Ray berbasis GPU.
- Sediakan cluster GPU Spot di GKE menggunakan alat XPK.
- Buat instance Managed Lustre.
- Deploy cluster KubeRay dan pasang sistem file Lustre.
- Kirimkan workload pelatihan NeMo-RL.
- Amati throughput tinggi dan latensi titik pemeriksaan rendah menggunakan Cloud Monitoring.
Yang Anda butuhkan
- Browser web seperti Chrome.
- Project Google Cloud yang mengaktifkan penagihan.
Codelab ini ditujukan bagi pengguna teknis tingkat lanjut, engineer platform, dan peneliti AI yang sudah memahami konsep GKE dan penyimpanan.
Perkiraan Durasi Total: 45 hingga 60 menit ditambah 2 jam waktu pelatihan
2. Sebelum memulai
Buat Project Google Cloud
- Di Konsol Google Cloud, pilih atau buat project Google Cloud.
- Pastikan penagihan diaktifkan untuk project Cloud Anda.
Mulai Cloud Shell
Cloud Shell adalah lingkungan command line yang berjalan di Google Cloud yang telah dilengkapi dengan alat yang diperlukan.
- Klik Activate Cloud Shell di bagian atas konsol Google Cloud.
- Setelah terhubung ke Cloud Shell, verifikasi autentikasi Anda:
gcloud auth list - Pastikan project Anda dikonfigurasi:
gcloud config get project - Jika project Anda tidak ditetapkan seperti yang diharapkan, tetapkan project:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Menginstal XPK
Codelab ini menggunakan xpk untuk menyediakan cluster GKE. Untuk mengetahui petunjuk cara menginstal xpk, lihat panduan penginstalan xpk.
Di Cloud Shell, Anda dapat menginstalnya dengan:
pip install xpk
Mengaktifkan API
Jalankan perintah ini di Cloud Shell untuk mengaktifkan semua API yang diperlukan:
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3. Mengonfigurasi Variabel Lingkungan
Agar perintah dalam codelab ini tetap konsisten, siapkan beberapa variabel lingkungan.
Buat file bernama env.sh dan isi dengan konfigurasi Anda. Anda dapat menggunakan template berikut:
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
Ganti <YOUR_PROJECT_ID> dan <YOUR_HF_TOKEN> dengan nilai sebenarnya.
Lakukan sourcing file untuk memuat variabel ke sesi Anda saat ini:
source env.sh
4. Membuat Cluster GKE menggunakan XPK
Pada langkah ini, Anda akan menggunakan xpk untuk menyediakan cluster GKE dengan GPU Spot.
xpk adalah alat penyediaan AI Hypercomputer yang menyederhanakan pembuatan cluster GKE untuk workload otomatis. Dengan menentukan jenis perangkat dan jumlah node, VPC, subnet, dan node pool yang diperlukan akan dibuat.
Jalankan perintah pembuatan cluster:
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
Tunggu hingga cluster selesai dibuat. Proses ini dapat memerlukan waktu beberapa menit.
Mengaktifkan Add-on RayOperator
Setelah cluster dibuat, aktifkan add-on RayOperator untuk mengelola cluster KubeRay:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
Verifikasi Driver CSI Lustre
XPK akan mengaktifkan driver CSI Lustre secara otomatis melalui flag --enable-lustre-csi-driver. Pastikan sudah diaktifkan:
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
Jika menampilkan false, jalankan perintah pengaktifan penggantian:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5. Menyediakan Instance Managed Lustre
Pada langkah ini, Anda akan membuat instance Managed Service for Lustre. Lustre adalah sistem file paralel yang menyediakan throughput tinggi untuk pembuatan checkpoint.
Mengalokasikan Rentang IP untuk Layanan Terkelola
Lustre memerlukan koneksi peering VPC ke Layanan Terkelola Google. Pertama, alokasikan rentang IP global:
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
Membuat Peering VPC
Hubungkan VPC Anda ke Service Networking:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
Membuat Instance Lustre
Sekarang, buat instance Lustre. Perintah ini berjalan secara asinkron.
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
Verifikasi Status Lustre
Perlu waktu sekitar 10-15 menit agar instance Lustre siap. Anda dapat memeriksa statusnya dengan:
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
Tunggu hingga statusnya ACTIVE sebelum melanjutkan.
6. Men-deploy Cluster Ray di GKE
Pada langkah ini, Anda akan men-deploy cluster KubeRay di node GKE dan memasang sistem file Lustre menggunakan PersistentVolume (PV) dan PersistentVolumeClaim (PVC).
Mengambil IP Lustre
Sebelum membuat volume, Anda harus mendapatkan IP titik pemasangan instance Lustre Anda:
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
Buat PV dan PVC Lustre
Buat file bernama rl-lustre-volume.yaml menggunakan konfigurasi berikut. Ini menentukan cara GKE terhubung ke instance Lustre Anda.
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
Terapkan konfigurasi volume:
kubectl apply -f rl-lustre-volume.yaml
Membuat Konfigurasi RayCluster
Buat file bernama ray-cluster.yaml. Ini menentukan node head dan worker KubeRay, menggunakan jenis akselerator nvidia-b200 dan memasang volume Lustre di /lustre.
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
Terapkan konfigurasi cluster Ray:
kubectl apply -f ray-cluster.yaml
Memverifikasi Status Cluster
Pantau pembuatan pod:
kubectl get pods -w
Tunggu hingga pod head dan pekerja berstatus Running.
7. Mengirimkan Beban Kerja Reinforcement Learning
Pada langkah ini, Anda akan mengirimkan tugas pelatihan NeMo-RL GRPO ke cluster Ray.
Menghubungkan ke Dasbor Ray
Untuk mengirimkan tugas dan melihat metrik, Anda harus terhubung ke Dasbor Ray. Karena dasbor berada di GKE, gunakan penerusan port untuk mengaksesnya dari Cloud Shell:
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
Membuat Skrip Eksekusi
Buat file bernama run_nemo_rl.sh. Skrip ini akan dieksekusi di pekerja cluster Ray. Kita menggunakan cat << EOF untuk mengisi variabel lingkungan yang Anda tetapkan sebelumnya.
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
Membuat File Pengabaian Ray
Buat file .rayignore untuk mencegah Ray mengupload direktori berukuran besar atau yang tidak perlu:
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
Membuat Konfigurasi Lingkungan Runtime
Buat file JSON untuk meneruskan variabel lingkungan ke tugas Ray:
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
Kirimkan Tugas
Gunakan Ray CLI untuk mengirimkan tugas ke endpoint dasbor. Jika perintah ray tidak ditemukan di Cloud Shell, Anda dapat menginstalnya dengan pip install ray:
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
Anda akan melihat streaming log di terminal Cloud Shell. Tugas ini akan memuat model, menginisialisasi pekerja Ray, dan memulai loop pelatihan GRPO.
8. Memantau Performa Pelatihan
Pada langkah ini, Anda akan mengamati performa sistem file Lustre selama pelatihan dan pembuatan titik pemeriksaan.
Memeriksa Log Pelatihan
Seiring progres pelatihan, Anda akan melihat log yang menunjukkan bahwa titik pemeriksaan sedang disimpan ke /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1. Perhatikan bahwa pembuatan titik pemeriksaan terjadi secara asinkron dan tidak memblokir pekerja Ray terlalu lama.
Untuk melihat kecepatan pembuatan titik pemeriksaan, cari baris log yang menunjukkan titik pemeriksaan yang disimpan.
Melihat Metrik Lustre di Cloud Console
Untuk melihat metrik instance Lustre Anda:
- Di Konsol Google Cloud, telusuri Managed Service for Lustre.
- Klik nama instance Anda (
rl-demo-gpu-lustre). - Klik tab Monitoring.
Di sini, Anda dapat mengamati:
- Throughput (Byte/dtk): Lihat lonjakan selama pembuatan titik pemeriksaan.
- Kapasitas: Memantau seberapa banyak ruang yang digunakan oleh titik pemeriksaan.
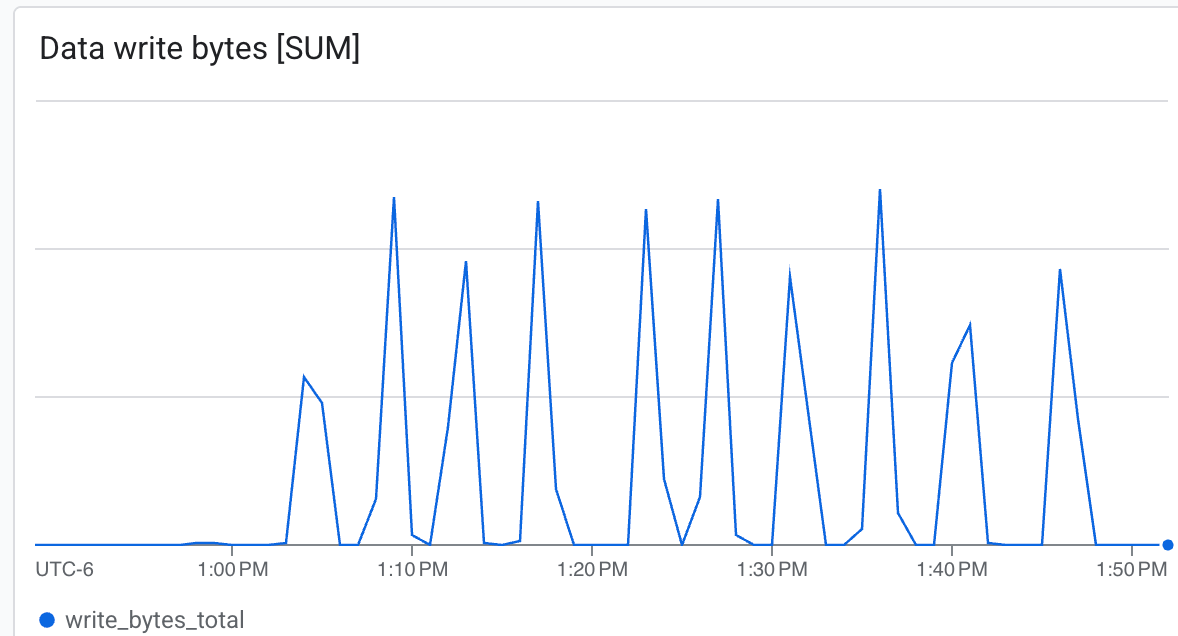 Lustre mampu menulis dengan kecepatan sangat tinggi, menulis checkpoint dalam waktu minimal ab.
Lustre mampu menulis dengan kecepatan sangat tinggi, menulis checkpoint dalam waktu minimal ab.
9. Membersihkan Resource
Jalankan perintah berikut di Cloud Shell untuk menghapus resource yang dibuat di codelab ini.
Menghapus Instance Managed Lustre
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
Menghapus Cluster GKE menggunakan XPK
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
Membersihkan Alias IP (Opsional)
Jika Anda ingin menghapus sepenuhnya rentang IP yang dibuat untuk peering VPC:
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
Resource akan dihapus secara asinkron. Anda dapat memverifikasi statusnya di Konsol Cloud.
10. Selamat
Anda telah berhasil menyelesaikan codelab Menskalakan Reinforcement Learning dengan GKE dan Managed Lustre.
Yang telah Anda pelajari
- Cara menggunakan
xpkuntuk menyediakan cluster GPU GKE dengan instance Spot. - Cara mengaktifkan add-on Lustre CSI driver dan RayOperator.
- Cara menyediakan instance Google Cloud Managed Service for Lustre.
- Cara men-deploy cluster KubeRay dan memasang penyimpanan Lustre.
- Cara mengirimkan workload pelatihan GRPO NeMo-RL.
- Cara mengamati performa penyimpanan selama pelatihan.
Langkah berikutnya
- Jelajahi fitur NVIDIA NeMo-RL lainnya.
- Pelajari lebih lanjut Hypercomputer AI Google Cloud.
- Tinjau dokumentasi Managed Service for Lustre.