
1. Introduzione
Se preferisci eseguire gli script in pacchetto direttamente senza il tutorial passo passo, puoi trovarli nel repository GoogleCloudPlatform/devrel-demos.
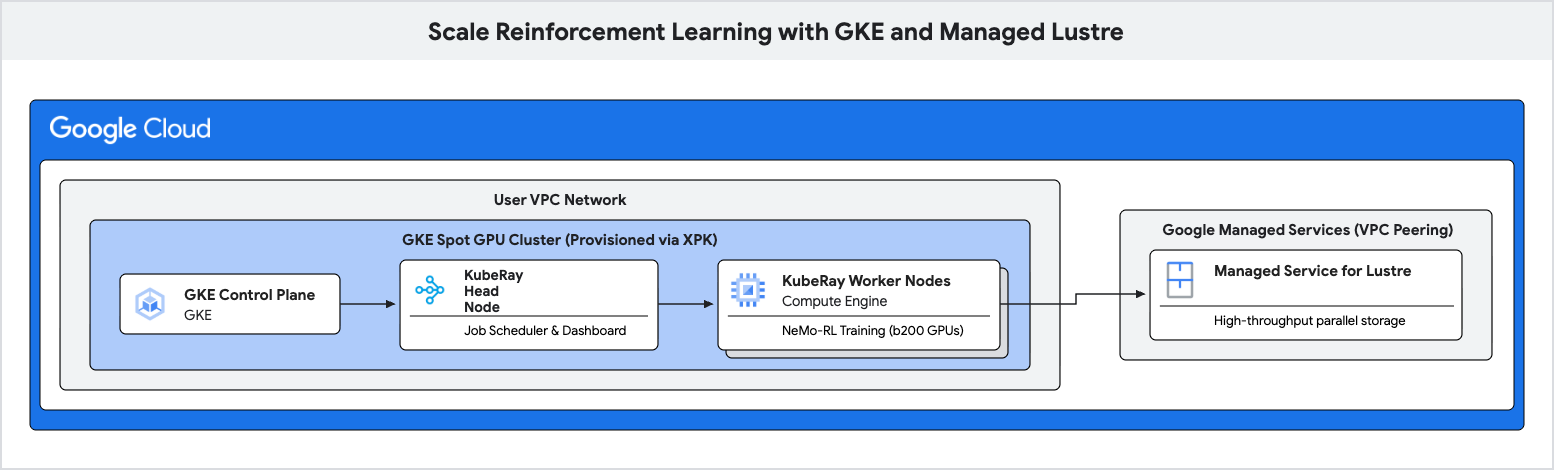
In questo codelab imparerai a eseguire il deployment di una pipeline di addestramento ad alte prestazioni per l'apprendimento per rinforzo (RL) utilizzando Google Kubernetes Engine (GKE) e Managed Lustre.
I carichi di lavoro di apprendimento per rinforzo, in particolare quelli che utilizzano algoritmi come Group Relative Policy Optimization (GRPO), generano enormi quantità di dati durante la "generazione di esperienze" e richiedono un checkpointing frequente. Lo spazio di archiviazione degli oggetti standard può causare colli di bottiglia durante questi picchi di I/O, lasciando inattivi gli acceleratori costosi.
Utilizzerai Managed Lustre, un file system parallelo, per eliminare questi colli di bottiglia e ottenere un throughput di addestramento più elevato.
In questo lab proverai a:
- Configurare le variabili di ambiente per un cluster Ray basato su GPU.
- Eseguire il provisioning di un cluster GPU spot su GKE utilizzando lo strumento XPK.
- Creare un'istanza Managed Lustre.
- Eseguire il deployment di un cluster KubeRay e montare il file system Lustre.
- Inviare un carico di lavoro di addestramento NeMo-RL.
- Osservare un throughput elevato e una bassa latenza di checkpointing utilizzando Cloud Monitoring.
Che cosa ti serve
- Un browser web come Chrome.
- Un progetto Google Cloud con la fatturazione abilitata.
Questo codelab è destinato a utenti tecnici avanzati, ingegneri di piattaforma e ricercatori di AI che hanno familiarità con i concetti di GKE e spazio di archiviazione.
Durata totale stimata: 45-60 minuti più 2 ore di addestramento
2. Prima di iniziare
Crea un progetto Google Cloud
- Nella console Google Cloud, seleziona o crea un progetto Google Cloud.
- Verifica che la fatturazione sia attivata per il tuo progetto Cloud.
Avvia Cloud Shell
Cloud Shell è un ambiente a riga di comando in esecuzione in Google Cloud che viene fornito con gli strumenti necessari precaricati.
- Fai clic su Attiva Cloud Shell nella parte superiore della console Google Cloud.
- Una volta eseguita la connessione a Cloud Shell, verifica l'autenticazione:
gcloud auth list - Verifica che il progetto sia configurato:
gcloud config get project - Se il progetto non è impostato come previsto, impostalo:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Installa XPK
Questo codelab utilizza xpk per eseguire il provisioning del cluster GKE. Per istruzioni su come installare xpk, consulta la guida all'installazione di xpk.
In Cloud Shell, puoi installarlo con:
pip install xpk
Abilita API
Esegui questo comando in Cloud Shell per abilitare tutte le API richieste:
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3. Configura le variabili di ambiente
Per mantenere la coerenza dei comandi in questo codelab, configura alcune variabili di ambiente.
Crea un file denominato env.sh e compilalo con la tua configurazione. Puoi utilizzare il seguente modello:
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
Sostituisci <YOUR_PROJECT_ID> e <YOUR_HF_TOKEN> con i valori effettivi.
Origina il file per caricare le variabili nella sessione corrente:
source env.sh
4. Crea un cluster GKE utilizzando XPK
In questo passaggio utilizzerai xpk per eseguire il provisioning di un cluster GKE con GPU spot.
xpk è lo strumento di provisioning AI Hypercomputer che semplifica la creazione di cluster GKE per i carichi di lavoro automatizzati. Specificando il tipo di dispositivo e il numero di nodi, crea i pool di nodi, subnet e VPC richiesti.
Esegui il comando di creazione del cluster:
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
Attendi la creazione del cluster. L'operazione può richiedere diversi minuti.
Abilita il componente aggiuntivo RayOperator
Una volta creato il cluster, abilita il componente aggiuntivo RayOperator per gestire i cluster KubeRay:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
Verifica il driver CSI Lustre
XPK dovrebbe abilitare automaticamente il driver CSI Lustre tramite il flag --enable-lustre-csi-driver. Verifica che sia abilitato:
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
Se restituisce false, esegui il comando di fallback per l'abilitazione:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5. Esegui il provisioning dell'istanza Managed Lustre
In questo passaggio creerai un'istanza di Managed Service for Lustre. Lustre è un file system parallelo che fornisce un throughput elevato per il checkpointing.
Alloca un intervallo IP per i servizi gestiti
Lustre richiede una connessione di peering VPC a Google Managed Services. Innanzitutto, alloca un intervallo IP globale:
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
Stabilisci il peering VPC
Collega il tuo VPC a Service Networking:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
Crea un'istanza Lustre
Ora crea l'istanza Lustre. Questo comando viene eseguito in modo asincrono.
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
Verifica lo stato di Lustre
L'istanza Lustre diventa pronta in circa 10-15 minuti. Puoi controllare lo stato con:
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
Attendi che lo stato sia ACTIVE prima di procedere.
6. Esegui il deployment del cluster Ray su GKE
In questo passaggio eseguirai il deployment di un cluster KubeRay sui nodi GKE e monterai il file system Lustre utilizzando un oggetto PersistentVolume (PV) e PersistentVolumeClaim (PVC).
Recupera l'IP di Lustre
Prima di creare il volume, devi recuperare l'IP del punto di montaggio dell'istanza Lustre:
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
Crea PV e PVC Lustre
Crea un file denominato rl-lustre-volume.yaml utilizzando la seguente configurazione. Definisce in che modo GKE si connette all'istanza Lustre.
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
Applica la configurazione del volume:
kubectl apply -f rl-lustre-volume.yaml
Crea la configurazione di RayCluster
Crea un file denominato ray-cluster.yaml. Specifica i nodi head e worker di KubeRay, utilizzando il tipo di acceleratore nvidia-b200 e montando il volume Lustre in /lustre.
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
Applica la configurazione del cluster Ray:
kubectl apply -f ray-cluster.yaml
Verifica lo stato del cluster
Monitora la creazione dei pod:
kubectl get pods -w
Attendi che i pod head e worker siano Running.
7. Invia un carico di lavoro di apprendimento per rinforzo
In questo passaggio invierai il job di addestramento GRPO di NeMo-RL al cluster Ray.
Connettiti alla dashboard Ray
Per inviare job e visualizzare le metriche, devi connetterti alla dashboard Ray. Poiché la dashboard si trova in GKE, utilizza il port forwarding per accedervi da Cloud Shell:
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
Crea lo script di esecuzione
Crea un file denominato run_nemo_rl.sh. Questo script verrà eseguito sui worker del cluster Ray. Utilizziamo cat << EOF per compilare le variabili di ambiente che hai impostato in precedenza.
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
Crea il file di ignoranza di Ray
Crea un file .rayignore per impedire a Ray di caricare directory di grandi dimensioni o non necessarie:
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
Crea la configurazione dell'ambiente di runtime
Crea un file JSON per passare le variabili di ambiente al job Ray:
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
Invia il job
Utilizza l'interfaccia a riga di comando Ray per inviare il job all'endpoint della dashboard. Se il comando ray non viene trovato in Cloud Shell, puoi installarlo con pip install ray:
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
Vedrai i log in streaming nel terminale Cloud Shell. Il job caricherà il modello, inizializzerà i worker Ray e inizierà il loop di addestramento GRPO.
8. Monitora il rendimento dell'addestramento
In questo passaggio osserverai il rendimento del file system Lustre durante l'addestramento e il checkpointing.
Controlla i log di addestramento
Man mano che l'addestramento procede, vedrai i log che indicano che i checkpoint vengono salvati in /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1. Tieni presente che il checkpointing avviene in modo asincrono e non blocca i worker Ray per molto tempo.
Per visualizzare la velocità del checkpointing, cerca le righe di log che indicano i checkpoint salvati.
Visualizza le metriche di Lustre in Cloud Console
Per visualizzare le metriche dell'istanza Lustre:
- Nella console Google Cloud, cerca Managed Service for Lustre.
- Fai clic sul nome dell'istanza (
rl-demo-gpu-lustre). - Fai clic sulla scheda Monitoraggio.
Qui puoi osservare:
- Throughput (byte/sec): visualizza i picchi durante il checkpointing.
- Capacità: monitora la quantità di spazio consumato dai checkpoint.
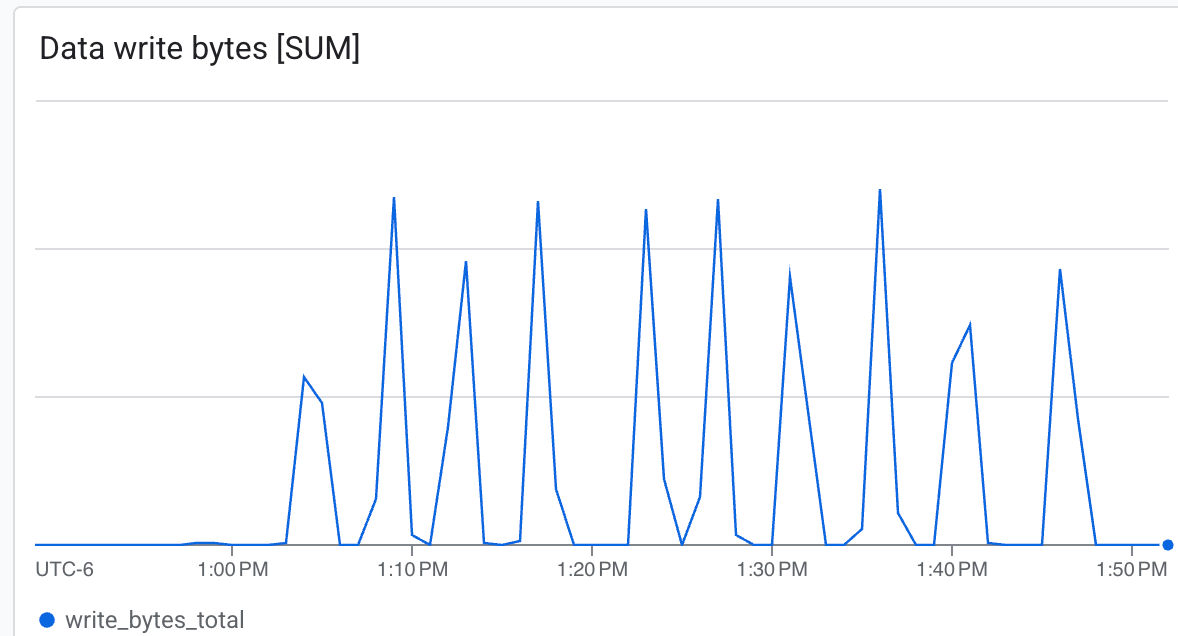 Lustre è in grado di scrivere a velocità molto elevate, scrivendo i checkpoint in un tempo minimo ab.
Lustre è in grado di scrivere a velocità molto elevate, scrivendo i checkpoint in un tempo minimo ab.
9. Pulisci le risorse
Esegui i seguenti comandi in Cloud Shell per eliminare le risorse create in questo codelab.
Elimina l'istanza Managed Lustre
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
Elimina il cluster GKE utilizzando XPK
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
Liberare spazio dagli alias IP (facoltativo)
Se vuoi pulire completamente gli intervalli IP creati per il peering VPC:
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
Le risorse verranno eliminate in modo asincrono. Puoi verificarne lo stato in Cloud Console.
10. Complimenti
Hai completato correttamente il codelab Scalare l'apprendimento per rinforzo con GKE e Managed Lustre.
Che cosa hai imparato
- Come utilizzare
xpkper eseguire il provisioning di un cluster GPU GKE con istanze spot. - Come abilitare i componenti aggiuntivi Lustre CSI Driver e RayOperator.
- Come eseguire il provisioning di un'istanza di Google Cloud Managed Service for Lustre.
- Come eseguire il deployment di un cluster KubeRay e montare lo spazio di archiviazione Lustre.
- Come inviare un carico di lavoro di addestramento GRPO di NeMo-RL.
- Come osservare il rendimento dello spazio di archiviazione durante l'addestramento.
Passaggi successivi
- Esplora altre funzionalità di NVIDIA NeMo-RL.
- Scopri di più su AI Google Cloud Hypercomputer.
- Consulta la documentazione di Managed Service for Lustre.