
1. はじめに
ステップごとのチュートリアルを行わずに、パッケージ化されたスクリプトを直接実行する場合は、GoogleCloudPlatform/devrel-demos リポジトリで確認できます。
この Codelab では、Google Kubernetes Engine(GKE) と Managed Lustre を使用して、強化学習(RL)用の高性能トレーニング パイプラインをデプロイする方法について説明します。
強化学習ワークロード、特に Group Relative Policy Optimization(GRPO)などのアルゴリズムを使用するワークロードは、「エクスペリエンス生成」中に大量のデータを生成し、頻繁なチェックポイント処理を必要とします。標準のオブジェクト ストレージでは、このような I/O バースト時にボトルネックが発生し、高価なアクセラレータがアイドル状態になる可能性があります。
並列ファイル システムである Managed Lustre を使用すると、これらのボトルネックを解消し、トレーニングのスループットを向上させることができます。
演習内容
- GPU ベースの Ray クラスタの環境変数を構成します。
- XPK ツールを使用して、GKE に Spot GPU クラスタ をプロビジョニングします。
- Managed Lustre インスタンスを作成します。
- KubeRay クラスタをデプロイし、Lustre ファイル システムをマウントします。
- NeMo-RL トレーニング ワークロードを送信します。
- Cloud Monitoring を使用して高スループットと低チェックポイント レイテンシを確認 します。

必要なもの
- Chrome などのウェブブラウザ。
- 課金を有効にした Google Cloud プロジェクト
この Codelab は、GKE とストレージのコンセプトに精通している上級技術ユーザー、プラットフォーム エンジニア、AI 研究者を対象としています。
合計所要時間(推定): 45 ~ 60 分 と 2 時間のトレーニング時間
2. 始める前に
Google Cloud プロジェクトの作成
- Google Cloud コンソールで、Google Cloud プロジェクトを作成または選択 します。
- Cloud プロジェクトで課金が有効になっていることを確認します。
Cloud Shell の起動
Cloud Shell は、必要なツールがプリロードされた Google Cloud 上で動作するコマンドライン環境です。
- Google Cloud コンソールの上部にある「Cloud Shell をアクティブにする 」アイコン をクリックします。
- Cloud Shell に接続したら、認証を確認します。
gcloud auth list - プロジェクトが構成されていることを確認します。
gcloud config get project - プロジェクトが想定どおりに設定されていない場合は、次のように設定します。
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
XPK をインストールする
この Codelab では、xpk を使用して GKE クラスタをプロビジョニングします。xpk のインストール方法については、xpk のインストール ガイドをご覧ください。
Cloud Shell で、次のコマンドを使用してインストールできます。
pip install xpk
API を有効にする
Cloud Shell で次のコマンドを実行して、必要な API をすべて有効にします。
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3. 環境変数を構成する
この Codelab のコマンドの一貫性を保つため、いくつかの環境変数を設定します。
env.sh という名前のファイルを作成し、構成を入力します。次のテンプレートを使用できます。
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
<YOUR_PROJECT_ID> と <YOUR_HF_TOKEN> を実際の値に置き換えます。
ファイルをソースして、現在のセッションに変数を読み込みます。
source env.sh
4. XPK を使用して GKE クラスタを作成する
このステップでは、xpk を使用して Spot GPU を使用する GKE クラスタをプロビジョニングします。
xpk は、自動化されたワークロードの GKE クラスタ作成を簡素化する AI Hypercomputer プロビジョニング ツールです。デバイスタイプとノード数を指定すると、必要な VPC、サブネット、ノードプールが作成されます。
クラスタ作成コマンドを実行します。
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
クラスタが作成されるまで待ちます。これには数分かかることがあります。
RayOperator アドオンを有効にする
クラスタが作成されたら、RayOperator アドオンを有効にして KubeRay クラスタを管理します。
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
Lustre CSI ドライバを確認する
XPK は、--enable-lustre-csi-driver フラグを使用して、Lustre CSI ドライバを自動的に有効にします。有効になっていることを確認します。
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
false が返された場合は、フォールバック有効化コマンドを実行します。
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5. Managed Lustre インスタンスをプロビジョニングする
このステップでは、Managed Service for Lustre インスタンスを作成します。Lustre は、チェックポイント処理に高スループットを提供する並列ファイル システムです。
マネージド サービスの IP 範囲を割り振る
Lustre には、Google マネージド サービスへの VPC ピアリング接続が必要です。まず、グローバル IP 範囲を割り振ります。
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
VPC ピアリングを確立する
VPC を Service Networking に接続します。
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
Lustre インスタンスを作成する
次に、Lustre インスタンスを作成します。このコマンドは非同期で実行されます。
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
Lustre のステータスを確認する
Lustre インスタンスが準備完了になるまでには、10 ~ 15 分 ほどかかります。ステータスは次のコマンドで確認できます。
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
状態が ACTIVE になるまで待ってから続行します。
6. GKE に Ray クラスタをデプロイする
このステップでは、GKE ノードに KubeRay クラスタをデプロイし、PersistentVolume(PV)と PersistentVolumeClaim(PVC)を使用して Lustre ファイル システムをマウントします。
Lustre IP を取得する
ボリュームを作成する前に、Lustre インスタンスのマウント ポイント IP を取得する必要があります。
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
Lustre PV と PVC を作成する
次の構成を使用して、rl-lustre-volume.yaml という名前のファイルを作成します。これにより、GKE が Lustre インスタンスに接続する方法が定義されます。
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
ボリューム構成を適用します。
kubectl apply -f rl-lustre-volume.yaml
RayCluster 構成を作成する
ray-cluster.yaml という名前のファイルを作成します。これにより、nvidia-b200 アクセラレータ タイプを使用して、KubeRay ヘッドノードとワーカーノードを指定し、/lustre に Lustre ボリュームをマウントします。
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
Ray クラスタ構成を適用します。
kubectl apply -f ray-cluster.yaml
クラスタのステータスを確認する
Pod の作成をモニタリングします。
kubectl get pods -w
ヘッド Pod とワーカー Pod が Running になるまで待ちます。
7. 強化学習ワークロードを送信する
このステップでは、NeMo-RL GRPO トレーニング ジョブを Ray クラスタに送信します。
Ray ダッシュボードに接続する
ジョブを送信して指標を表示するには、Ray ダッシュボードに接続する必要があります。ダッシュボードは GKE にあるため、ポート転送を使用して Cloud Shell からアクセスします。
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
実行スクリプトを作成する
run_nemo_rl.sh という名前のファイルを作成します。このスクリプトは、Ray クラスタ ワーカーで実行されます。cat << EOF を使用して、先ほど設定した環境変数を入力します。
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
Ray 除外ファイルを作成する
Ray が不要なディレクトリや大きなディレクトリをアップロードしないように、.rayignore ファイルを作成します。
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
ランタイム環境構成を作成する
環境変数を Ray ジョブに渡すための JSON ファイルを作成します。
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
ジョブを送信する
Ray CLI を使用して、ジョブをダッシュボード エンドポイントに送信します。Cloud Shell で ray コマンドが見つからない場合は、pip install ray でインストールできます。
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
Cloud Shell ターミナルにログがストリーミングされます。ジョブはモデルを読み込み、Ray ワーカーを初期化して、GRPO トレーニング ループを開始します。
8. トレーニング パフォーマンスをモニタリングする
このステップでは、トレーニングとチェックポイント処理中の Lustre ファイル システムのパフォーマンスを確認します。
トレーニング ログを確認する
トレーニングが進むにつれて、チェックポイントが /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 に保存されていることを示すログが表示されます。チェックポイント処理は非同期で行われ、Ray ワーカーを長時間ブロックしないことに注意してください。
チェックポイント処理の速度を確認するには、保存されたチェックポイントを示すログ行を探します。
Cloud コンソールで Lustre 指標を表示する
Lustre インスタンスの指標を表示するには:
- Google Cloud コンソールで、Managed Service for Lustre を検索します。
- インスタンス名(
rl-demo-gpu-lustre)をクリックします。 - [モニタリング] タブをクリックします。
ここでは、次のことを確認できます。
- スループット(バイト/秒): チェックポイント処理中のスパイクを確認します。
- 容量: チェックポイントで消費されている容量をモニタリングします。
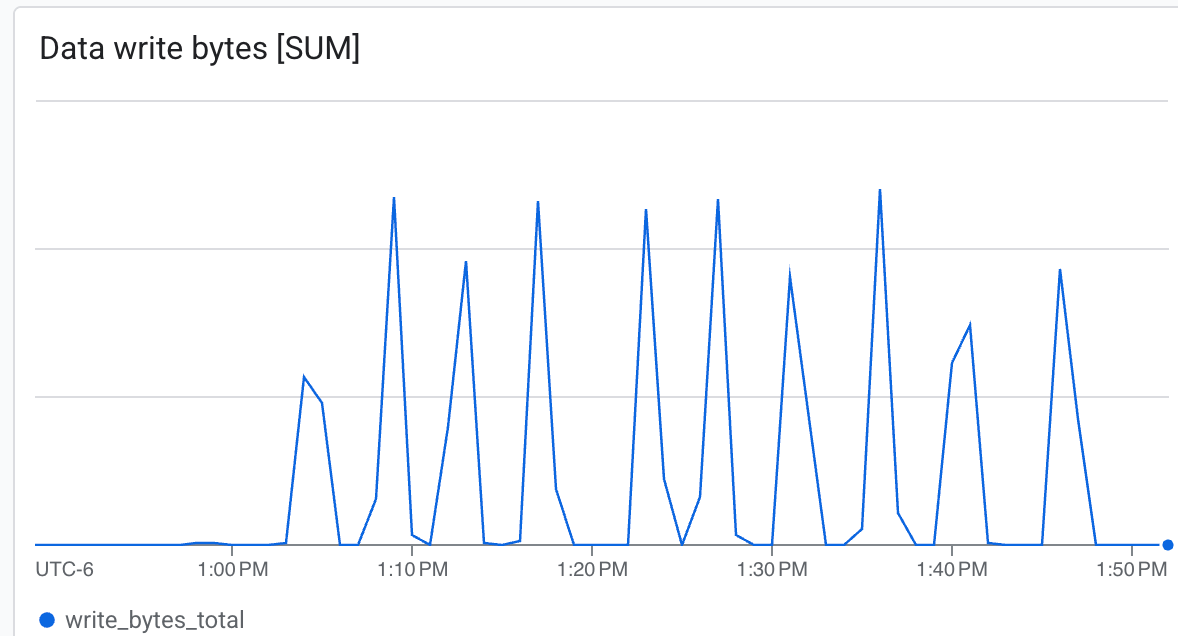 __Lustre は非常に高速で書き込みが可能で、最小限の時間でチェックポイントを書き込みます。
__Lustre は非常に高速で書き込みが可能で、最小限の時間でチェックポイントを書き込みます。
9. リソースをクリーンアップする
Cloud Shell で次のコマンドを実行して、この Codelab で作成したリソースを削除します。
Managed Lustre インスタンスを削除する
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
XPK を使用して GKE クラスタを削除する
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
IP エイリアスをクリーンアップする(省略可)
VPC ピアリング用に作成した IP 範囲を完全にクリーンアップする場合は、次の操作を行います。
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
リソースは非同期で削除されます。ステータスは Cloud コンソールで確認できます。
10. 完了
GKE と Managed Lustre を使用して強化学習をスケーリングする Codelab を無事に完了しました。
学習した内容
xpkを使用して、Spot インスタンスで GKE GPU クラスタをプロビジョニングする方法。- Lustre CSI ドライバと RayOperator アドオンを有効にする方法。
- Google Cloud Managed Service for Lustre インスタンスをプロビジョニングする方法。
- KubeRay クラスタをデプロイして Lustre ストレージをマウントする方法。
- NeMo-RL GRPO トレーニング ワークロードを送信する方法。
- トレーニング中のストレージ パフォーマンスを確認する方法。
次のステップ
- NVIDIA NeMo-RL のその他の機能を確認する。
- Google Cloud AI Hypercomputer の詳細を確認する。
- Managed Service for Lustre のドキュメントを確認する。