
1. 소개
단계별 튜토리얼 없이 패키지 스크립트를 직접 실행하려면 GoogleCloudPlatform/devrel-demos 저장소에서 스크립트를 찾으세요.
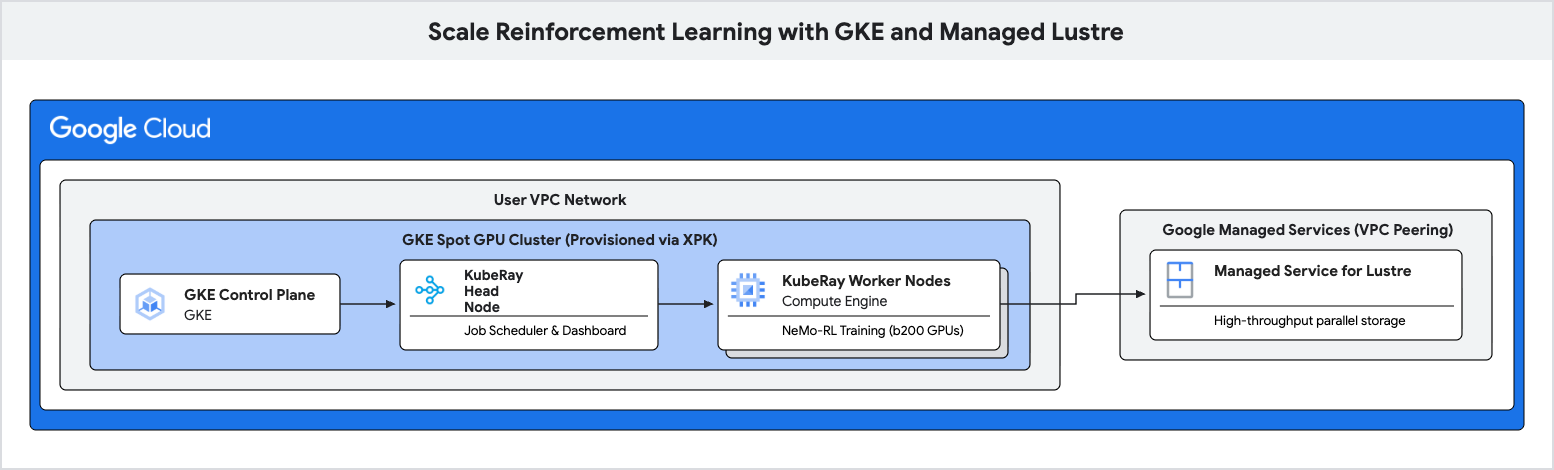
이 Codelab에서는 Google Kubernetes Engine (GKE) 및 Managed Lustre를 사용하여 강화 학습 (RL)을 위한 고성능 학습 파이프라인을 배포하는 방법을 알아봅니다.
강화 학습 워크로드, 특히 그룹 상대 정책 최적화 (GRPO)와 같은 알고리즘을 사용하는 워크로드는 '경험 생성' 중에 엄청난 양의 데이터를 생성하며 자주 체크포인트를 생성해야 합니다. 표준 객체 스토리지는 이러한 I/O 버스트 중에 병목 현상을 일으켜 비용이 많이 드는 가속기가 유휴 상태로 남을 수 있습니다.
병렬 파일 시스템인 Managed Lustre를 사용하여 이러한 병목 현상을 없애고 더 높은 학습 처리량을 달성합니다.
실습할 내용
- GPU 기반 Ray 클러스터의 환경 변수를 구성합니다.
- XPK 도구를 사용하여 GKE에서 스팟 GPU 클러스터 를 프로비저닝합니다.
- Managed Lustre 인스턴스를 만듭니다.
- KubeRay 클러스터를 배포하고 Lustre 파일 시스템을 마운트합니다.
- NeMo-RL 학습 워크로드를 제출합니다.
- Cloud Monitoring을 사용하여 높은 처리량과 짧은 체크포인트 지연 시간 을 관찰합니다.
필요한 항목
- Chrome과 같은 웹브라우저
- 결제가 사용 설정된 Google Cloud 프로젝트.
이 Codelab은 GKE 및 스토리지 개념에 익숙한 고급 기술 사용자, 플랫폼 엔지니어, AI 연구원을 대상으로 합니다.
예상 총 소요 시간: 45~60분 + 2시간의 학습 시간
2. 시작하기 전에
Google Cloud 프로젝트 만들기
- Google Cloud Console에서 Google Cloud 프로젝트를 선택하거나 만듭니다.
- Cloud 프로젝트에 결제가 사용 설정되어 있는지 확인합니다.
Cloud Shell 시작
Cloud Shell 은 Google Cloud에서 실행되는 명령줄 환경으로, 필요한 도구가 미리 로드되어 있습니다.
- Google Cloud 콘솔 상단에서 Cloud Shell 활성화 를 클릭합니다.
- Cloud Shell에 연결되면 인증을 확인합니다.
gcloud auth list - 프로젝트가 구성되었는지 확인합니다.
gcloud config get project - 프로젝트가 예상대로 설정되지 않은 경우 설정합니다.
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
XPK 설치
이 Codelab에서는 xpk를 사용하여 GKE 클러스터를 프로비저닝합니다. xpk를 설치하는 방법은 xpk 설치 가이드를 참고하세요.
Cloud Shell에서 다음을 사용하여 설치할 수 있습니다.
pip install xpk
API 사용 설정
Cloud Shell에서 이 명령어를 실행하여 필요한 모든 API를 사용 설정합니다.
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3. 환경 변수 구성
이 Codelab의 명령어를 일관되게 유지하려면 몇 가지 환경 변수를 설정하세요.
env.sh라는 파일을 만들고 구성으로 채웁니다. 다음 템플릿을 사용할 수 있습니다.
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
<YOUR_PROJECT_ID> 및 <YOUR_HF_TOKEN>을 실제 값으로 바꿉니다.
파일을 소싱하여 변수를 현재 세션에 로드합니다.
source env.sh
4. XPK를 사용하여 GKE 클러스터 만들기
이 단계에서는 xpk를 사용하여 스팟 GPU가 포함된 GKE 클러스터를 프로비저닝합니다.
xpk는 자동화된 워크로드의 GKE 클러스터 생성을 간소화하는 AI 하이퍼컴퓨터 프로비저닝 도구입니다. 기기 유형과 노드 수를 지정하면 필요한 VPC, 서브넷, 노드 풀이 생성됩니다.
클러스터 생성 명령어를 실행합니다.
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
클러스터가 생성될 때까지 기다립니다. 이 작업이 완료되는 데 몇 분 정도 걸릴 수 있습니다.
RayOperator 부가기능 사용 설정
클러스터가 생성되면 RayOperator 부가기능을 사용 설정하여 KubeRay 클러스터를 관리합니다.
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
Lustre CSI 드라이버 확인
XPK는 --enable-lustre-csi-driver 플래그를 통해 Lustre CSI 드라이버를 자동으로 사용 설정해야 합니다. 사용 설정되었는지 확인합니다.
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
false를 반환하면 대체 사용 설정 명령어를 실행합니다.
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5. Managed Lustre 인스턴스 프로비저닝
이 단계에서는 Lustre 인스턴스의 관리형 서비스를 만듭니다. Lustre는 체크포인트 생성을 위한 높은 처리량을 제공하는 병렬 파일 시스템입니다.
관리형 서비스의 IP 범위 할당
Lustre에는 Google 관리형 서비스에 대한 VPC 피어링 연결이 필요합니다. 먼저 전역 IP 범위를 할당합니다.
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
VPC 피어링 설정
VPC를 서비스 네트워킹에 연결합니다.
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
Lustre 인스턴스 만들기
이제 Lustre 인스턴스를 만듭니다. 이 명령어는 비동기식으로 실행됩니다.
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
Lustre 상태 확인
Lustre 인스턴스가 준비되는 데 10~15분 정도 걸립니다. 다음을 사용하여 상태를 확인할 수 있습니다.
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
상태가 ACTIVE가 될 때까지 기다린 후 계속 진행합니다.
6. GKE에 Ray 클러스터 배포
이 단계에서는 GKE 노드에 KubeRay 클러스터를 배포하고 PersistentVolume (PV) 및 PersistentVolumeClaim (PVC)을 사용하여 Lustre 파일 시스템을 마운트합니다.
Lustre IP 가져오기
볼륨을 만들기 전에 Lustre 인스턴스의 마운트 지점 IP를 가져와야 합니다.
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
Lustre PV 및 PVC 만들기
다음 구성을 사용하여 rl-lustre-volume.yaml이라는 파일을 만듭니다. 이렇게 하면 GKE가 Lustre 인스턴스에 연결되는 방식이 정의됩니다.
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
볼륨 구성을 적용합니다.
kubectl apply -f rl-lustre-volume.yaml
RayCluster 구성 만들기
ray-cluster.yaml이라는 파일을 만듭니다. 이렇게 하면 nvidia-b200 가속기 유형을 사용하여 KubeRay 헤드 및 작업자 노드를 지정하고 /lustre에 Lustre 볼륨을 마운트합니다.
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
Ray 클러스터 구성을 적용합니다.
kubectl apply -f ray-cluster.yaml
클러스터 상태 확인
포드 생성을 모니터링합니다.
kubectl get pods -w
헤드 및 작업자 포드가 Running 상태가 될 때까지 기다립니다.
7. 강화 학습 워크로드 제출
이 단계에서는 NeMo-RL GRPO 학습 작업을 Ray 클러스터에 제출합니다.
Ray 대시보드에 연결
작업을 제출하고 측정항목을 보려면 Ray 대시보드에 연결해야 합니다. 대시보드가 GKE에 있으므로 포트 전달을 사용하여 Cloud Shell에서 액세스합니다.
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
실행 스크립트 만들기
run_nemo_rl.sh라는 파일을 만듭니다. 이 스크립트는 Ray 클러스터 작업자에서 실행됩니다. cat << EOF를 사용하여 이전에 설정한 환경 변수를 채웁니다.
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
Ray 무시 파일 만들기
Ray가 크거나 불필요한 디렉터리를 업로드하지 못하도록 .rayignore 파일을 만듭니다.
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
런타임 환경 구성 만들기
환경 변수를 Ray 작업에 전달할 JSON 파일을 만듭니다.
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
작업 제출
Ray CLI를 사용하여 작업을 대시보드 엔드포인트에 제출합니다. Cloud Shell에서 ray 명령어를 찾을 수 없는 경우 pip install ray를 사용하여 설치할 수 있습니다.
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
Cloud Shell 터미널에 로그 스트리밍이 표시됩니다. 작업은 모델을 로드하고 Ray 작업자를 초기화하며 GRPO 학습 루프를 시작합니다.
8. 학습 성능 모니터링
이 단계에서는 학습 및 체크포인트 생성 중에 Lustre 파일 시스템의 성능을 관찰합니다.
학습 로그 확인
학습이 진행됨에 따라 체크포인트가 /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1에 저장되고 있음을 나타내는 로그가 표시됩니다. 체크포인트 생성은 비동기식으로 발생하며 Ray 작업자를 매우 오랫동안 차단하지 않습니다.
체크포인트 생성 속도를 보려면 저장된 체크포인트를 나타내는 로그 줄을 찾습니다.
Cloud 콘솔에서 Lustre 측정항목 보기
Lustre 인스턴스의 측정항목을 보려면 다음 단계를 따르세요.
- Google Cloud Console에서 Lustre 관리형 서비스를 검색합니다.
- 인스턴스 이름 (
rl-demo-gpu-lustre)을 클릭합니다. - 모니터링 탭을 클릭합니다.
여기에서 다음을 관찰할 수 있습니다.
- 처리량 (바이트/초): 체크포인트 생성 중에 급증을 확인합니다.
- 용량: 체크포인트에서 사용 중인 공간을 모니터링합니다.
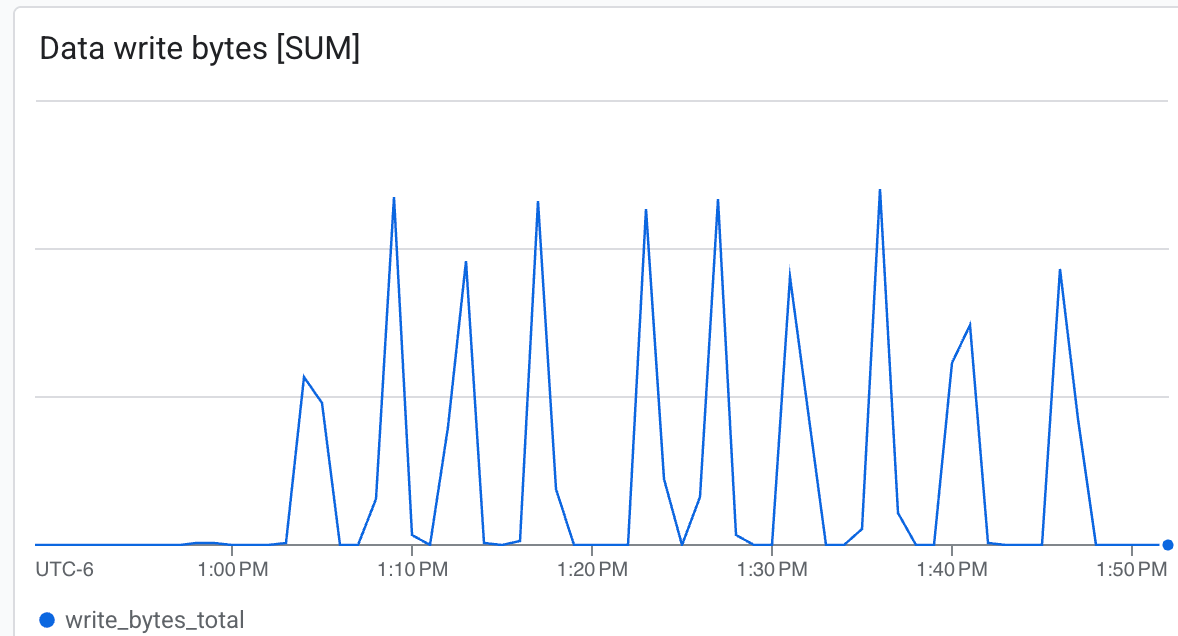 Lustre는 매우 빠른 속도로 쓸 수 있으며 최소한의 시간으로 체크포인트를 생성할 수 있습니다. ab.
Lustre는 매우 빠른 속도로 쓸 수 있으며 최소한의 시간으로 체크포인트를 생성할 수 있습니다. ab.
9. 리소스 삭제
Cloud Shell에서 다음 명령어를 실행하여 이 Codelab에서 만든 리소스를 삭제합니다.
Managed Lustre 인스턴스 삭제
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
XPK를 사용하여 GKE 클러스터 삭제
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
IP 별칭 삭제 (선택사항)
VPC 피어링을 위해 만든 IP 범위를 완전히 삭제하려면 다음 단계를 따르세요.
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
리소스가 비동기식으로 삭제됩니다. Cloud 콘솔에서 상태를 확인할 수 있습니다.
10. 축하합니다
GKE 및 Managed Lustre로 강화 학습 확장 Codelab을 완료했습니다.
학습한 내용
xpk를 사용하여 스팟 인스턴스가 포함된 GKE GPU 클러스터를 프로비저닝하는 방법- Lustre CSI 드라이버 및 RayOperator 부가기능을 사용 설정하는 방법
- Google Cloud Managed Service for Lustre 인스턴스를 프로비저닝하는 방법
- KubeRay 클러스터를 배포하고 Lustre 스토리지를 마운트하는 방법
- NeMo-RL GRPO 학습 워크로드를 제출하는 방법
- 학습 중에 스토리지 성능을 관찰하는 방법
다음 단계
- NVIDIA NeMo-RL 기능 자세히 알아보기
- Google Cloud AI 하이퍼컴퓨터 자세히 알아보기
- Managed Service for Lustre 문서 검토