
1. Wprowadzenie
Jeśli wolisz uruchamiać spakowane skrypty bezpośrednio bez samouczka krok po kroku, znajdziesz je w repozytorium GoogleCloudPlatform/devrel-demos.
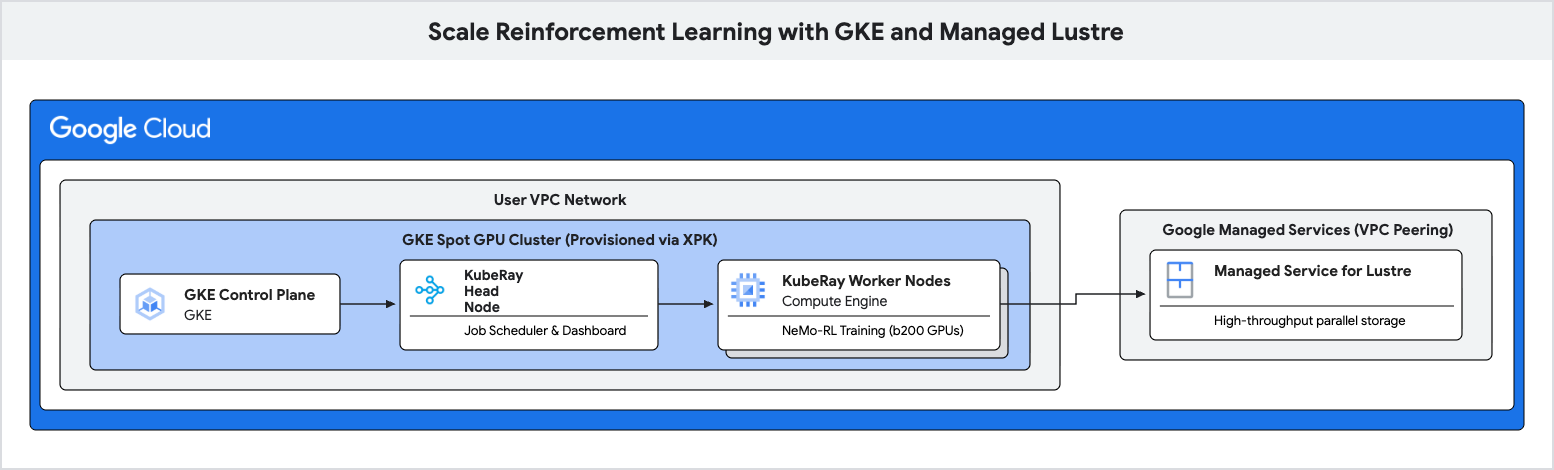
Z tego ćwiczenia dowiesz się, jak wdrożyć wydajny potok trenowania do uczenia ze wzmocnieniem (RL) przy użyciu Google Kubernetes Engine (GKE) i Managed Lustre.
Obciążenia związane z uczeniem ze wzmocnieniem, zwłaszcza te, które korzystają z algorytmów takich jak Group Relative Policy Optimization (GRPO), generują ogromne ilości danych podczas „generowania doświadczeń” i wymagają częstego tworzenia punktów kontrolnych. Standardowa pamięć obiektowa może powodować wąskie gardła podczas tych skoków operacji wejścia/wyjścia, pozostawiając drogie akceleratory bezczynne.
Aby wyeliminować te wąskie gardła i zwiększyć przepustowość trenowania, użyjesz Managed Lustre, czyli równoległego systemu plików.
Jakie zadania wykonasz
- Skonfiguruj zmienne środowiskowe dla klastra Ray opartego na GPU.
- Zarezerwuj klaster GPU typu spot w GKE za pomocą narzędzia XPK.
- Utwórz instancję Managed Lustre.
- Wdróż klaster KubeRay i zamontuj system plików Lustre.
- Prześlij zadanie trenowania NeMo-RL.
- Obserwuj wysoką przepustowość i krótkie czasy oczekiwania na punkty kontrolne za pomocą Cloud Monitoring.
Czego potrzebujesz
- przeglądarka, np. Chrome;
- Projekt Google Cloud z włączonymi płatnościami.
To ćwiczenie jest przeznaczone dla zaawansowanych użytkowników technicznych, inżynierów platform i badaczy AI, którzy znają GKE i koncepcje związane z pamięcią masową.
Szacowany łączny czas trwania: 45–60 minut plus 2 godziny szkolenia
2. Zanim zaczniesz
Tworzenie projektu Google Cloud
- W konsoli Google Cloud wybierz lub utwórz projekt w chmurze Google Cloud.
- Sprawdź, czy w projekcie Cloud włączone są płatności.
Uruchamianie Cloud Shell
Cloud Shell to środowisko wiersza poleceń działające w Google Cloud, które zawiera niezbędne narzędzia.
- Kliknij Aktywuj Cloud Shell u góry konsoli Google Cloud.
- Po połączeniu z Cloud Shell sprawdź uwierzytelnianie:
gcloud auth list - Sprawdź, czy projekt jest skonfigurowany:
gcloud config get project - Jeśli projekt nie jest ustawiony zgodnie z oczekiwaniami, ustaw go:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Instalowanie XPK
W tym ćwiczeniu do udostępnienia klastra GKE używamy xpk. Instrukcje instalacji xpk znajdziesz w przewodniku instalacji xpk.
W Cloud Shell możesz zainstalować go za pomocą tego polecenia:
pip install xpk
Włącz interfejsy API
Aby włączyć wszystkie wymagane interfejsy API, uruchom to polecenie w Cloud Shell:
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3. Konfigurowanie zmiennych środowiskowych
Aby polecenia w tym samouczku były spójne, skonfiguruj kilka zmiennych środowiskowych.
Utwórz plik o nazwie env.sh i wypełnij go konfiguracją. Możesz użyć tego szablonu:
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
Zastąp <YOUR_PROJECT_ID> i <YOUR_HF_TOKEN> rzeczywistymi wartościami.
Uruchom plik, aby wczytać zmienne do bieżącej sesji:
source env.sh
4. Tworzenie klastra GKE za pomocą XPK
W tym kroku użyjesz xpk, aby udostępnić klaster GKE z GPU Spot.
xpk to narzędzie do udostępniania AI Hypercomputer, które upraszcza tworzenie klastrów GKE na potrzeby zautomatyzowanych zadań. Określając typ urządzenia i liczbę węzłów, tworzy wymagane sieci VPC, podsieci i pule węzłów.
Uruchom polecenie tworzenia klastra:
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
Poczekaj, aż klaster zostanie utworzony. Może to potrwać kilka minut.
Włącz dodatek RayOperator
Po utworzeniu klastra włącz dodatek RayOperator, aby zarządzać klastrami KubeRay:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
Weryfikowanie sterownika CSI Lustre
XPK powinien automatycznie włączać sterownik CSI Lustre za pomocą flagi --enable-lustre-csi-driver. Sprawdź, czy jest włączona:
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
Jeśli zwróci wartość false, uruchom polecenie włączania rezerwowego:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5. Udostępnianie instancji Managed Lustre
W tym kroku utworzysz instancję Managed Service for Lustre. Lustre to równoległy system plików, który zapewnia wysoką przepustowość na potrzeby tworzenia punktów kontrolnych.
Przydzielanie zakresu adresów IP usługom zarządzanym
Lustre wymaga połączenia równorzędnego VPC z usługami zarządzanymi Google. Najpierw przydziel globalny zakres adresów IP:
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
Nawiązywanie połączenia równorzędnego VPC
Połącz sieć VPC z siecią usług:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
Tworzenie instancji Lustre
Teraz utwórz instancję Lustre. To polecenie jest wykonywane asynchronicznie.
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
Sprawdzanie stanu Lustre
Przygotowanie instancji Lustre zajmuje około 10–15 minut. Stan możesz sprawdzić w ten sposób:
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
Zanim przejdziesz dalej, poczekaj, aż stan zmieni się na ACTIVE.
6. Wdrażanie klastra Ray w GKE
W tym kroku wdrożysz klaster KubeRay na węzłach GKE i zamontujesz system plików Lustre za pomocą zasobu PersistentVolume (PV) i żądania PersistentVolumeClaim (PVC).
Pobieranie adresu IP Lustre
Zanim utworzysz wolumin, musisz uzyskać adres IP punktu podłączania instancji Lustre:
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
Tworzenie woluminu stałego Lustre i żądania woluminu stałego
Utwórz plik o nazwie rl-lustre-volume.yaml z tą konfiguracją. Określa sposób, w jaki GKE łączy się z instancją Lustre.
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
Zastosuj konfigurację woluminu:
kubectl apply -f rl-lustre-volume.yaml
Tworzenie konfiguracji RayCluster
Utwórz plik o nazwie ray-cluster.yaml. Określa węzły główne i robocze KubeRay, używając nvidia-b200 typu akceleratora i montując wolumin Lustre w /lustre.
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
Zastosuj konfigurację klastra Ray:
kubectl apply -f ray-cluster.yaml
Sprawdzanie stanu klastra
Monitoruj tworzenie podów:
kubectl get pods -w
Poczekaj, aż pody główne i procesów roboczych będą w stanie Running.
7. Przesyłanie zadania uczenia się przez wzmacnianie
W tym kroku prześlesz zadanie trenowania NeMo-RL GRPO do klastra Ray.
Łączenie z panelem Ray
Aby przesyłać zadania i wyświetlać dane, musisz połączyć się z panelem Ray. Ponieważ panel znajduje się w GKE, użyj przekierowania portów, aby uzyskać do niego dostęp z Cloud Shell:
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
Tworzenie skryptu wykonania
Utwórz plik o nazwie run_nemo_rl.sh. Ten skrypt zostanie wykonany na procesach roboczych klastra Ray. Używamy cat << EOF, aby wypełnić zmienne środowiskowe ustawione wcześniej.
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
Tworzenie pliku ignorowania Ray
Utwórz plik .rayignore, aby zapobiec przesyłaniu przez Ray dużych lub niepotrzebnych katalogów:
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
Tworzenie konfiguracji środowiska wykonawczego
Utwórz plik JSON, aby przekazać zmienne środowiskowe do zadania Ray:
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
Przesyłanie zadania
Użyj interfejsu wiersza poleceń Ray, aby przesłać zadanie do punktu końcowego panelu. Jeśli polecenie ray nie zostanie znalezione w Cloud Shell, możesz je zainstalować za pomocą polecenia pip install ray:
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
W terminalu Cloud Shell zobaczysz przesyłane strumieniowo logi. Zadanie wczyta model, zainicjuje instancje robocze Ray i rozpocznie pętlę trenowania GRPO.
8. Monitorowanie wydajności trenowania
Na tym etapie obserwujesz wydajność systemu plików Lustre podczas trenowania i tworzenia punktów kontrolnych.
Sprawdzanie dzienników trenowania
W trakcie trenowania zobaczysz logi wskazujące, że punkty kontrolne są zapisywane w /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1. Zwróć uwagę, że zapisywanie punktów kontrolnych odbywa się asynchronicznie i nie blokuje procesów roboczych Ray przez zbyt długi czas.
Aby sprawdzić szybkość tworzenia punktów kontrolnych, poszukaj wierszy dziennika wskazujących zapisane punkty kontrolne.
Wyświetlanie wskaźników Lustre w konsoli Cloud
Aby wyświetlić dane instancji Lustre:
- W konsoli Google Cloud wyszukaj Managed Service for Lustre.
- Kliknij nazwę instancji (
rl-demo-gpu-lustre). - Kliknij kartę Monitorowanie.
Możesz tu zobaczyć:
- Przepustowość (bajty/s): obserwuj skoki podczas tworzenia punktów kontrolnych.
- Pojemność: monitoruj ilość miejsca zajmowanego przez punkty kontrolne.
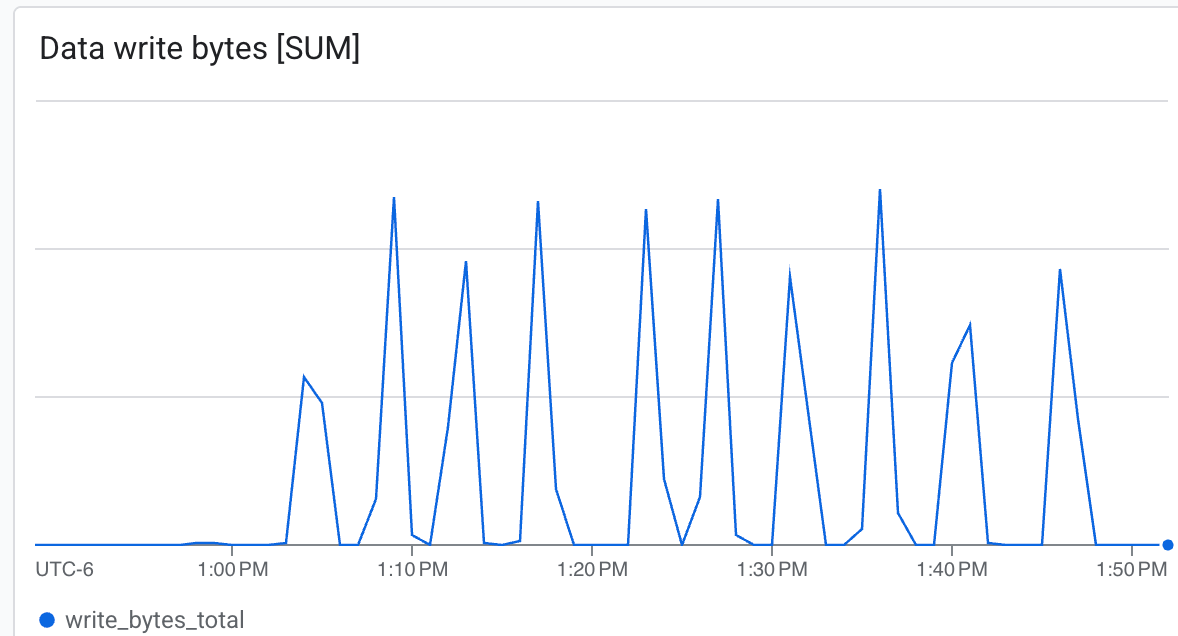 Lustre może zapisywać dane z bardzo dużą szybkością, a punkty kontrolne zapisuje w minimalnym czasie.
Lustre może zapisywać dane z bardzo dużą szybkością, a punkty kontrolne zapisuje w minimalnym czasie.
9. Usuwanie zasobów
Aby usunąć zasoby utworzone w tym laboratorium, uruchom w Cloud Shell te polecenia:
Usuwanie instancji Managed Lustre
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
Usuwanie klastra GKE za pomocą XPK
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
Usuwanie aliasów IP (opcjonalnie)
Jeśli chcesz całkowicie usunąć zakresy adresów IP utworzone na potrzeby łączenia sieci VPC:
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
Zasoby zostaną usunięte asynchronicznie. Ich stan możesz sprawdzić w konsoli Cloud.
10. Gratulacje
Udało Ci się ukończyć ćwiczenie w Codelabs Skalowanie uczenia ze wzmocnieniem za pomocą GKE i Managed Lustre.
Czego się dowiedziałeś(-aś)
- Jak używać
xpkdo udostępniania klastra GKE GPU z instancjami Spot. - Jak włączyć sterownik CSI Lustre i dodatki RayOperator.
- Jak udostępnić instancję Google Cloud Managed Service for Lustre.
- Jak wdrożyć klaster KubeRay i zamontować pamięć Lustre.
- Jak przesłać zadanie trenowania GRPO NeMo-RL.
- Jak obserwować wydajność pamięci masowej podczas trenowania.
Dalsze kroki
- Poznaj więcej funkcji NVIDIA NeMo-RL.
- Dowiedz się więcej o AI Hypercomputer w Google Cloud.
- Zapoznaj się z dokumentacją usługi zarządzanej Lustre.