
1. Introdução
Se você preferir executar os scripts empacotados diretamente sem o tutorial detalhado, encontre-os no repositório GoogleCloudPlatform/devrel-demos.
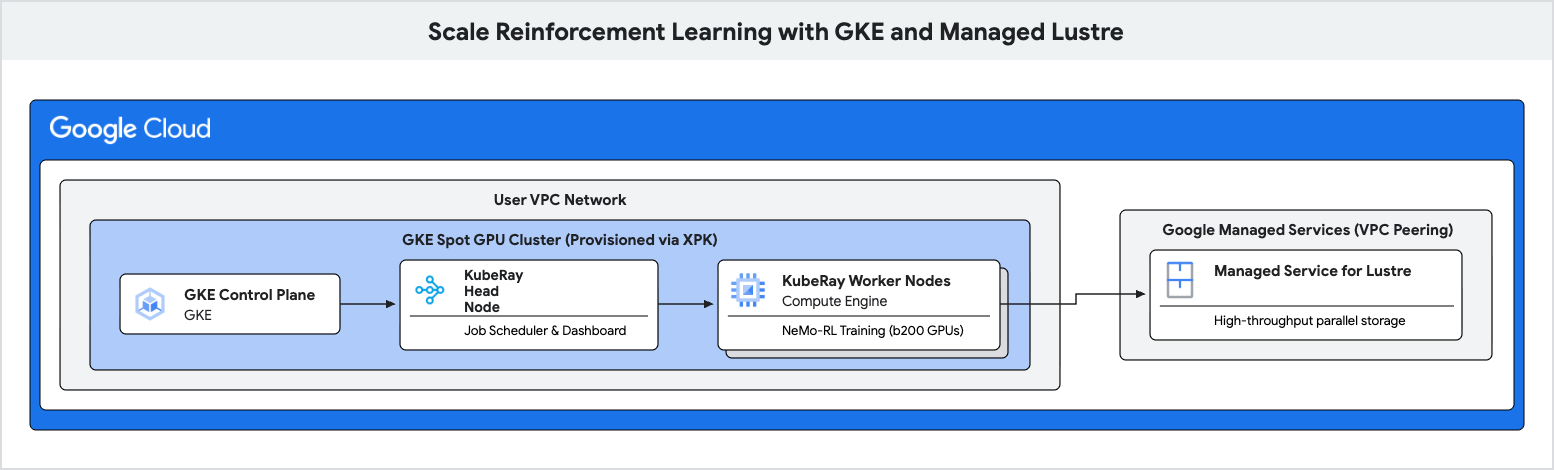
Neste codelab, você vai aprender a implantar um pipeline de treinamento de alta performance para aprendizado por reforço (RL, na sigla em inglês) usando o Google Kubernetes Engine (GKE) e o Managed Lustre.
As cargas de trabalho de aprendizado por reforço, principalmente aquelas que usam algoritmos como a otimização de políticas relativas de grupo (GRPO, na sigla em inglês), geram grandes quantidades de dados durante a "geração de experiência" e exigem checkpoints frequentes. O armazenamento de objetos padrão pode causar gargalos durante esses picos de E/S, deixando aceleradores caros ociosos.
Você vai usar o Managed Lustre, um sistema de arquivos paralelo, para eliminar esses gargalos e alcançar maior capacidade de processamento de treinamento.
Atividades deste laboratório
- Definir variáveis de ambiente para um cluster do Ray baseado em GPU.
- Provisionar um cluster de GPU spot no GKE usando a ferramenta XPK.
- Criar uma instância do Managed Lustre.
- Implantar um cluster do KubeRay e ativar o sistema de arquivos Lustre.
- Enviar uma carga de trabalho de treinamento do NeMo-RL.
- Observar alta capacidade de processamento e baixa latência de checkpoint usando o Cloud Monitoring.
O que é necessário
- Um navegador da Web, como o Chrome.
- Ter um projeto do Google Cloud com o faturamento ativado.
Este codelab é destinado a usuários técnicos avançados, engenheiros de plataforma e pesquisadores de IA familiarizados com o GKE e conceitos de armazenamento.
Duração total estimada: 45 a 60 minutos mais 2 horas de tempo de treinamento
2. Antes de começar
Criar um projeto do Google Cloud
- No Console do Google Cloud, selecione ou crie um projeto na nuvem do Google Cloud.
- Verifique se o faturamento está ativado para seu projeto na nuvem.
Iniciar o Cloud Shell
O Cloud Shell é um ambiente de linha de comando em execução no Google Cloud que vem pré-carregado com as ferramentas necessárias.
- Clique em Ativar o Cloud Shell na parte de cima do console do Google Cloud.
- Depois de se conectar ao Cloud Shell, verifique sua autenticação:
gcloud auth list - Confirme se o projeto está configurado:
gcloud config get project - Se o projeto não estiver definido como esperado, defina-o:
export PROJECT_ID=<YOUR_PROJECT_ID> gcloud config set project $PROJECT_ID
Instalar o XPK
Este codelab usa xpk para provisionar o cluster do GKE. Para instruções sobre como instalar xpk, consulte o guia de instalação do xpk.
No Cloud Shell, é possível instalar com:
pip install xpk
Ativar APIs
Execute este comando no Cloud Shell para ativar todas as APIs necessárias:
gcloud services enable \
container.googleapis.com \
lustre.googleapis.com \
compute.googleapis.com \
servicenetworking.googleapis.com
3. Definir variáveis de ambiente
Para manter os comandos neste codelab consistentes, configure algumas variáveis de ambiente.
Crie um arquivo chamado env.sh e preencha-o com sua configuração. Você pode usar o modelo a seguir:
# Environment Variables for the RL Demo execution
export PROJECT_ID="<YOUR_PROJECT_ID>"
export ZONE="us-east1-b"
export REGION="us-east1"
export CLUSTER_NAME="ray-a4-gpu-spot"
export NETWORK_NAME="${CLUSTER_NAME}-net-0" # Implicitly targets the VPC created by XPK
export LUSTRE_INSTANCE_ID="rl-demo-gpu-lustre"
export LUSTRE_CAPACITY="9000" # Capacity in GiB
export HF_TOKEN="<YOUR_HF_TOKEN>" # Required for downloading models
export WANDB_API_KEY="<YOUR_WANDB_API_KEY>" # Optional
# Topology defaults
export NUM_NODES="8"
export GPUS_PER_NODE="8" # Fixed for A4/B200 architecture
export DEVICE_TYPE="b200-8"
Substitua <YOUR_PROJECT_ID> e <YOUR_HF_TOKEN> pelos seus valores reais.
Obtenha o arquivo para carregar as variáveis na sessão atual:
source env.sh
4. Criar cluster do GKE usando o XPK
Nesta etapa, você vai usar xpk para provisionar um cluster do GKE com GPUs spot.
xpk é a ferramenta de provisionamento do Hipercomputador de IA que simplifica a criação de clusters do GKE para cargas de trabalho automatizadas. Ao especificar o tipo de dispositivo e o número de nós, ele cria a VPC, a sub-rede e os pools de nós necessários.
Execute o comando de criação do cluster:
xpk cluster create \
--num-nodes=${NUM_NODES} \
--device-type=${DEVICE_TYPE} \
--default-pool-cpu-machine-type="e2-standard-4" \
--spot \
--enable-lustre-csi-driver \
--project=${PROJECT_ID} \
--zone=${ZONE} \
--cluster=${CLUSTER_NAME}
Aguarde a criação do cluster. Isso pode levar alguns minutos.
Ativar o complemento do RayOperator
Depois que o cluster for criado, ative o complemento RayOperator para gerenciar clusters do KubeRay:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=RayOperator=ENABLED
Verificar o driver CSI do Lustre
O XPK precisa ativar o driver CSI do Lustre automaticamente usando o flag --enable-lustre-csi-driver. Verifique se ele está ativado:
gcloud container clusters describe ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--format="value(addonsConfig.lustreCsiDriverConfig.enabled)"
Se ele retornar false, execute o comando de ativação de fallback:
gcloud container clusters update ${CLUSTER_NAME} \
--region ${REGION} \
--project ${PROJECT_ID} \
--update-addons=LustreCsiDriver=ENABLED
5. Provisionar instância do Managed Lustre
Nesta etapa, você vai criar uma instância do Managed Service for Lustre. O Lustre é um sistema de arquivos paralelo que oferece alta capacidade de processamento para checkpoints.
Alocar intervalo de IP para serviços gerenciados
O Lustre exige uma conexão de peering de VPC com os serviços gerenciados do Google. Primeiro, aloque um intervalo de IP global:
gcloud compute addresses create "google-managed-services-${NETWORK_NAME}" \
--global \
--purpose=VPC_PEERING \
--prefix-length=24 \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}"
Estabelecer peering de VPC
Conecte sua VPC ao Service Networking:
gcloud services vpc-peerings connect \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" || \
gcloud services vpc-peerings update \
--service=servicenetworking.googleapis.com \
--ranges="google-managed-services-${NETWORK_NAME}" \
--network="${NETWORK_NAME}" \
--project="${PROJECT_ID}" \
--force
Criar instância do Lustre
Agora, crie a instância do Lustre. Esse comando é executado de forma assíncrona.
gcloud lustre instances create "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--capacity-gib="${LUSTRE_CAPACITY}" \
--per-unit-storage-throughput="1000" \
--filesystem="lustre" \
--network="projects/${PROJECT_ID}/global/networks/${NETWORK_NAME}" \
--gke-support-enabled \
--async
Verificar o status do Lustre
Leva aproximadamente 10 a 15 minutos para que a instância do Lustre fique pronta. Verifique o status com:
gcloud lustre instances describe ${LUSTRE_INSTANCE_ID} \
--project ${PROJECT_ID} \
--location ${ZONE} \
--format="value(state)"
Aguarde até que o estado seja ACTIVE antes de continuar.
6. Implantar cluster do Ray no GKE
Nesta etapa, você vai implantar um cluster do KubeRay nos nós do GKE e ativar o sistema de arquivos Lustre usando um PersistentVolume (PV) e um PersistentVolumeClaim (PVC).
Buscar IP do Lustre
Antes de criar o volume, é necessário receber o IP do ponto de montagem da instância do Lustre:
export LUSTRE_IP=$(gcloud lustre instances describe "${LUSTRE_INSTANCE_ID}" --project="${PROJECT_ID}" --location="${ZONE}" --format="value(mountPoint)" | cut -d'@' -f1)
echo "Lustre IP is: ${LUSTRE_IP}"
Criar PV e PVC do Lustre
Crie um arquivo chamado rl-lustre-volume.yaml usando a configuração a seguir. Isso define como o GKE se conecta à instância do Lustre.
cat << EOF > rl-lustre-volume.yaml
apiVersion: v1
kind: PersistentVolume
metadata:
name: rl-demo-gpu-lustre-pv
spec:
capacity:
storage: ${LUSTRE_CAPACITY}Gi
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Retain
volumeMode: Filesystem
claimRef:
namespace: default
name: rl-demo-gpu-lustre-pvc
csi:
driver: lustre.csi.storage.gke.io
volumeHandle: ${PROJECT_ID}/${ZONE}/${LUSTRE_INSTANCE_ID}
volumeAttributes:
ip: ${LUSTRE_IP}
filesystem: lustre
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: rl-demo-gpu-lustre-pvc
spec:
accessModes:
- ReadWriteMany
storageClassName: ""
volumeName: rl-demo-gpu-lustre-pv
resources:
requests:
storage: ${LUSTRE_CAPACITY}Gi
EOF
Aplique a configuração de volume:
kubectl apply -f rl-lustre-volume.yaml
Criar configuração do RayCluster
Crie um arquivo chamado ray-cluster.yaml. Isso especifica os nós principais e de trabalho do KubeRay, usando o tipo de acelerador nvidia-b200 e ativando o volume do Lustre em /lustre.
cat << EOF > ray-cluster.yaml
apiVersion: ray.io/v1
kind: RayCluster
metadata:
name: ${CLUSTER_NAME}
namespace: default
spec:
rayVersion: '2.54.0'
headGroupSpec:
rayStartParams:
dashboard-host: '0.0.0.0'
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-head
image: nvcr.io/nvidia/nemo-rl:v0.4.0
ports:
- containerPort: 6379
name: gcs-server
- containerPort: 8265
name: dashboard
- containerPort: 10001
name: client
resources:
limits:
cpu: "32"
memory: "1000Gi"
requests:
cpu: "8"
memory: "64Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
workerGroupSpecs:
- groupName: gpu-worker-group
replicas: ${NUM_NODES}
minReplicas: ${NUM_NODES}
maxReplicas: ${NUM_NODES}
rayStartParams: {}
template:
spec:
nodeSelector:
cloud.google.com/gke-accelerator: nvidia-b200
tolerations:
- key: "nvidia.com/gpu"
operator: "Exists"
effect: "NoSchedule"
containers:
- name: ray-worker
image: nvcr.io/nvidia/nemo-rl:v0.4.0
resources:
limits:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
requests:
nvidia.com/gpu: "8"
cpu: "100"
memory: "1000Gi"
volumeMounts:
- mountPath: /lustre
name: lustre-storage
- mountPath: /dev/shm
name: dshm
volumes:
- name: lustre-storage
persistentVolumeClaim:
claimName: rl-demo-gpu-lustre-pvc
- name: dshm
emptyDir:
medium: Memory
EOF
Aplique a configuração do cluster do Ray:
kubectl apply -f ray-cluster.yaml
Verificar o status do cluster
Monitore a criação dos pods:
kubectl get pods -w
Aguarde até que os pods principais e de trabalho estejam Running.
7. Enviar carga de trabalho de aprendizado por reforço
Nesta etapa, você vai enviar o job de treinamento do GRPO do NeMo-RL para o cluster do Ray.
Conectar-se ao painel do Ray
Para enviar jobs e visualizar métricas, é necessário se conectar ao painel do Ray. Como o painel está no GKE, use o encaminhamento de porta para acessá-lo no Cloud Shell:
# Run this in a separate Cloud Shell tab or in the background
kubectl port-forward service/${CLUSTER_NAME}-head-svc 8265:8265 &
Criar o script de execução
Crie um arquivo chamado run_nemo_rl.sh. Esse script será executado nos trabalhadores do cluster do Ray. Usamos cat << EOF para preencher as variáveis de ambiente definidas anteriormente.
cat << EOF > run_nemo_rl.sh
#!/bin/bash
set -ex
# Override job runtime conflicts (NeMo-RL passes os.environ to ray.init)
export RAY_OVERRIDE_JOB_RUNTIME_ENV=1
echo "--- Running on Ray Cluster ---"
cd /opt/nemo-rl
# Ensure directories exist on the high-speed Lustre drive
mkdir -p /lustre/huggingface_cache
mkdir -p /lustre/nemo_rl_qwen_72b_ds_cp
echo "Launching NeMo-RL GRPO training..."
uv run python examples/run_grpo_math.py \\
--config examples/configs/grpo_math_70B_megatron.yaml \\
policy.model_name='Qwen/Qwen2.5-72B-Instruct' \\
policy.megatron_cfg.converter_type='Qwen2ForCausalLM' \\
logger.wandb_enabled=False \\
cluster.num_nodes=${NUM_NODES} \\
cluster.gpus_per_node=${GPUS_PER_NODE} \\
logger.wandb.name='nemo-rl-grpo-test1' \\
grpo.max_num_steps=20 \\
grpo.num_generations_per_prompt=8 \\
grpo.num_prompts_per_step=32 \\
policy.train_global_batch_size=256 \\
checkpointing.enabled=True \\
checkpointing.save_period=2 \\
checkpointing.keep_top_k=2 \\
checkpointing.metric_name=null \\
checkpointing.checkpoint_dir=/lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1 \\
data.dataset_name='DeepScaler'
EOF
chmod +x run_nemo_rl.sh
Criar arquivo de ignorar do Ray
Crie um arquivo .rayignore para impedir que o Ray faça o upload de diretórios grandes ou desnecessários:
cat << EOF > .rayignore
xpkclusters/
.git/
*.sh.log
EOF
Criar configuração do ambiente de execução
Crie um arquivo JSON para transmitir variáveis de ambiente ao job do Ray:
cat << EOF > ray_runtime_env_nemo.json
{
"env_vars": {
"HF_TOKEN": "${HF_TOKEN}",
"WANDB_API_KEY": "${WANDB_API_KEY}",
"HF_HOME": "/lustre/huggingface_cache",
"GLOO_SOCKET_IFNAME": "eth0",
"NCCL_SOCKET_IFNAME": "eth0"
}
}
EOF
Enviar o job
Use a CLI do Ray para enviar o job ao endpoint do painel. Se o comando ray não for encontrado no Cloud Shell, instale-o com pip install ray:
ray job submit \
--address="http://localhost:8265" \
--working-dir . \
--runtime-env ray_runtime_env_nemo.json \
-- bash run_nemo_rl.sh
Você vai ver registros transmitidos no terminal do Cloud Shell. O job vai carregar o modelo, inicializar os trabalhadores do Ray e iniciar o loop de treinamento do GRPO.
8. Monitorar a performance do treinamento
Nesta etapa, você vai observar a performance do sistema de arquivos Lustre durante o treinamento e o checkpoint.
Verificar registros de treinamento
À medida que o treinamento avança, você vai ver registros indicando que os checkpoints estão sendo salvos em /lustre/nemo_rl_qwen_72b_ds_cp/nemo-rl-grpo-test1. Observe que o checkpoint acontece de forma assíncrona e não bloqueia os trabalhadores do Ray por muito tempo.
Para conferir a velocidade do checkpoint, procure linhas de registro que indiquem checkpoints salvos.
Ver métricas do Lustre no console do Cloud
Para conferir as métricas da instância do Lustre:
- No console do Google Cloud, pesquise Managed Service for Lustre.
- Clique no nome da instância (
rl-demo-gpu-lustre). - Clique na guia Monitoramento.
Aqui, você pode observar:
- Capacidade (bytes/segundo): confira os picos durante o checkpoint.
- Capacidade: monitore quanto espaço está sendo consumido pelos checkpoints.
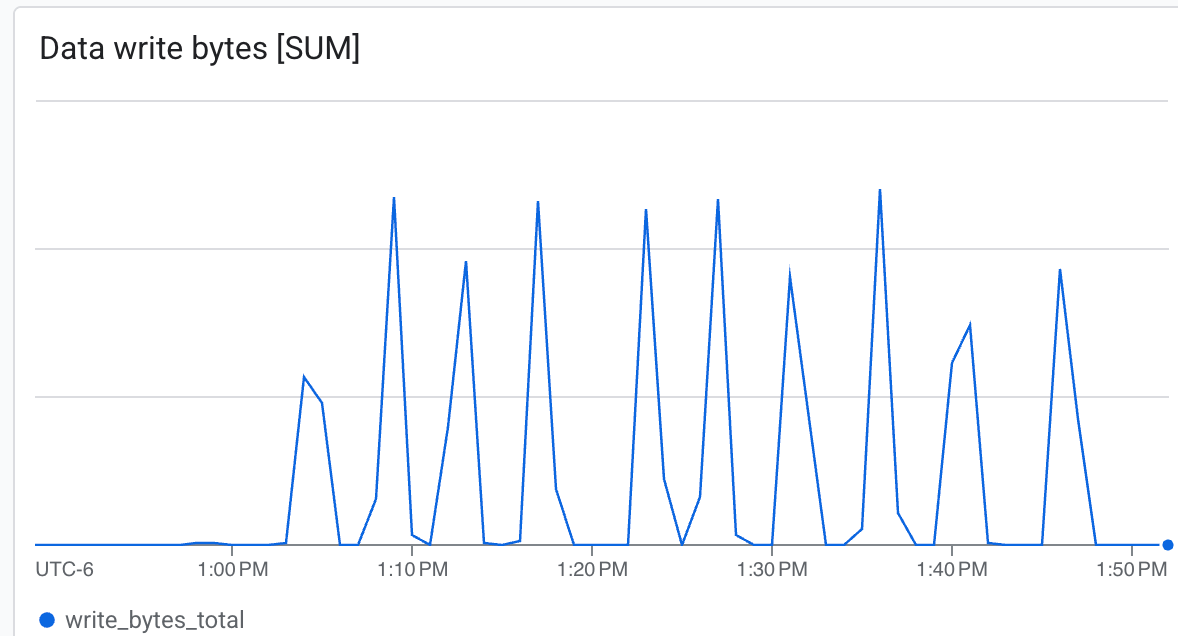 O Lustre é capaz de gravar em alta velocidade, gravando checkpoints em tempo mínimo ab.
O Lustre é capaz de gravar em alta velocidade, gravando checkpoints em tempo mínimo ab.
9. Limpar recursos
Execute os comandos a seguir no Cloud Shell para excluir os recursos criados neste codelab.
Excluir instância do Managed Lustre
gcloud lustre instances delete "${LUSTRE_INSTANCE_ID}" \
--project="${PROJECT_ID}" \
--location="${ZONE}" \
--quiet --async
Excluir cluster do GKE usando o XPK
xpk cluster delete \
--project="${PROJECT_ID}" \
--zone="${ZONE}" \
--cluster="${CLUSTER_NAME}" \
--force
Limpar aliases de IP (opcional)
Se você quiser limpar completamente os intervalos de IP criados para peering de VPC:
gcloud compute addresses delete "google-managed-services-${NETWORK_NAME}" \
--global \
--project="${PROJECT_ID}" \
--quiet
Os recursos serão excluídos de forma assíncrona. É possível verificar o status deles no console do Cloud.
10. Parabéns
Você concluiu o codelab Escalar o aprendizado por reforço com o GKE e o Managed Lustre.
O que você aprendeu
- Como usar
xpkpara provisionar um cluster de GPU do GKE com instâncias spot. - Como ativar o driver CSI do Lustre e os complementos do RayOperator.
- Como provisionar um serviço gerenciado do Google Cloud para a instância do Lustre.
- Como implantar um cluster do KubeRay e ativar o armazenamento do Lustre.
- Como enviar uma carga de trabalho de treinamento do GRPO do NeMo-RL.
- Como observar a performance do armazenamento durante o treinamento.
Próximas etapas
- Conheça mais recursos do NVIDIA NeMo-RL.
- Saiba mais sobre o Hipercomputador de IA do Google Cloud.
- Consulte a documentação do Managed Service for Lustre.